摘要 :反思(Reflection)让智能体先执行再自检 :生成初版输出后,对结果做评估与批评 ,再根据反馈修订 ,形成「生成 → 评审 → 修订」的闭环。本文说明反思的动机、典型流程,以及如何用 LangGraph 的状态图 + 条件边 实现 Producer-Critic 两角色迭代打磨,配套示例为基于 LLM 的代码生成与代码评审循环。
关键词:反思;Reflection;自检;Producer-Critic;LangGraph;条件边;StateGraph;代码评审;迭代 refinement
源代码连接:Langgraph 4. Reflection 源代码
1 为什么需要「反思」?
在前几章我们已经见过:链式(Chaining) 按顺序执行步骤,路由(Routing) 按条件选路径,并行(Parallelization) 同时跑多条分支。但即便流程再复杂,智能体的第一版输出往往并不完美------可能漏掉边界情况、风格不符合要求、或与任务描述有偏差。若没有「回头看」的机制,错误会直接成为最终结果。
反思(Reflection) 就是在智能体里引入自我审视 :先完成一次执行(例如生成一段代码或一篇草稿),再评估 这份输出是否达标,然后根据评估结果修订 ,必要时多轮迭代,直到满足要求或达到上限。这样系统就从「一次生成即交付」变成「生成 → 检查 → 改进 → 再检查」,更贴近对质量有要求的场景。
💡 理解要点 :反思 = 先做出来,再挑毛病,再改好;没有反思时只有「一锤子买卖」,有了反思才能在不保证一次就对的前提下仍交出高质量结果。
2 反思在解决什么问题?
想象这些场景:
- 写代码:模型生成了一个函数,但没处理负数输入、没有 docstring、或风格不符合规范。若直接采纳,后续调试和协作成本都会增加。
- 写文案:模型写了一篇博客初稿,但逻辑跳跃、语气不统一或漏掉关键信息。若直接发布,会影响可读性和专业度。
- 做规划:模型给出一套执行计划,但某几步不可行或与资源约束冲突。若直接执行,容易中途失败。
反思模式把「该不该接受当前输出 」和「如何改进 」抽象成独立步骤:先由某一角色(或同一模型换一套指令)对当前输出做评审 ,再根据评审意见由生成角色做修订,如此循环。这样既避免「写完了就交卷」的一次性行为,又避免在单次生成里塞进过多「顺便自检」的负担,职责更清晰。
🔍 实际例子:就像写论文时的「初稿 → 自审/导师审 → 修改 → 再审」:不是写完就投,而是多轮「写-审-改」,质量才上得去。
3 反思的典型流程
反思过程通常包含以下几步(可多轮重复):
- 执行(Execution):智能体完成一次任务或生成初版输出(如代码、文案、计划)。
- 评估 / 批评(Evaluation / Critique) :对上一步结果做分析,检查是否满足事实正确性、风格、完整性、是否符合指令等。这一步常用另一轮 LLM 调用 或专门规则完成。
- 反思 / 修订(Refinement):根据评估结果决定如何改进------可能是重写一版、调整参数,或修改后续计划。
- 迭代(可选):将修订后的结果再次执行或再次送审,直到满足终止条件(如「无问题」或达到最大轮数)。
一种常见且效果较好的实现是双角色 :Producer(生产者) 只负责「出活」,Critic(批评者) 只负责「挑毛病」。这样批评者不会因为「自己写的」而手下留情,反馈更客观;生产者则专注根据反馈修改,而不是一边写一边自审,思路更清晰。
💡 理解要点 :Producer-Critic = 一个专门「写」,一个专门「审」;用 LangGraph 可以很自然地把这两个角色做成两个节点,用条件边在「继续改」和「结束」之间切换。
4 常见应用场景
反思模式在对质量、准确性或约束满足度要求高的场景中特别有用,例如:
| 场景 | 做法 | 收益 |
|---|---|---|
| 创意写作 / 内容生成 | 生成草稿 → 审阅流畅度、语气、逻辑 → 按意见重写 | 内容更 polished、更符合目标读者 |
| 代码生成与调试 | 生成代码 → 静态检查/测试/人工式评审 → 按问题修改 | 更健壮、更符合规范 |
| 复杂问题求解 | 提出一步或一个方案 → 判断是否逼近目标或产生矛盾 → 回溯或换方案 | 在复杂解空间中少走弯路 |
| 摘要与信息整合 | 生成摘要 → 对照原文检查完整性与准确性 → 补全或修正 | 摘要更准、更全 |
| 规划与策略 | 生成计划 → 评估可行性或与约束是否冲突 → 修订计划 | 计划更可执行 |
| 对话智能体 | 生成回复后回顾对话与最后一句是否连贯、是否答到点上 | 对话更自然、少跑题 |
反思为智能体增加了一层元认知:不仅「会做」,还会「检查做得对不对、好不好」,从而在相同模型能力下得到更可靠、更高质量的结果。
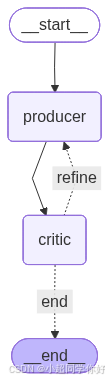
5 LangGraph 中的反思:状态图 + 条件边
LangGraph 用状态图(State Graph) 描述「生成 → 评审 → 根据结果决定是否再改」的流程:节点对应执行 与评审 ,边对应步骤之间的转移,条件边 表示在评审后根据状态选择「继续修订」或「结束」。
- 状态(State) :在图中流转的共享数据,例如
task(任务描述)、current_code(当前代码)、critique(评审意见,供 Producer 修订用)、critique_score(0--100 分数,用于路由)、iteration(当前轮次)、max_iterations(最大轮次);可选initial_code(从文件加载的待评审代码,首轮直接使用则不调 LLM)。 - Producer 节点 :首轮若有
initial_code则直接作为current_code进入 Critic(不调 LLM),否则根据task生成初版;后续轮次根据task+critique修订,并更新current_code与iteration。 - Critic 节点 :根据
task与current_code做评审,输出 JSON (score、score_reason、critiques);解析后写入critique(格式化给 Producer)与critique_score。 - 条件边 :从 Critic 出发,若
critique_score >= 阈值(默认 90)或critique含约定标记或已达最大轮次则转到END,否则回到 Producer。
这样就把「谁在什么时候生成、谁在什么时候评审、何时停止」都固化在图结构里,便于维护和扩展。
否
是
START
Producer 生成/修订
Critic 评审
通过或达上限?
END
6 配套代码结构概览
本示例实现「写一个满足若干约束的阶乘函数 」(或从文件加载待评审代码 )的反思循环:Producer 负责生成/修订代码,Critic 以「资深 Python 工程师」身份评审并输出 JSON (分数 0--100、原因、问题列表);若分数 ≥ 阈值(默认 90) 或达最大轮数则结束,否则回到 Producer 修订。运行结束后最后一版代码会写入 revised_code.py (可用 --output 指定路径)。所有 Prompt 模板在 prompt.py 中,采用 Jinja2 格式。建议与代码中的 README 对照阅读。
6.1 状态定义
图的状态用 TypedDict 定义,在 Producer 与 Critic 之间共享:
python
# 摘自 demo_codes/reflection_graph.py
class ReflectionState(TypedDict):
task: str # 原始任务说明
current_code: str # Producer 生成或修订后的代码
critique: str # Critic 的评审意见(供 Producer 修订用;JSON 解析后格式化为 score_reason + critiques)
iteration: int # 当前轮次(0 表示尚未生成)
max_iterations: int # 最大反思轮数
critique_score: int # Critic 输出的 0--100 分数,用于路由(>= 阈值则结束)
initial_code: NotRequired[str] # 可选:从文件加载的待评审代码,首轮直接使用则不调 LLM6.2 Producer 节点(生成 / 修订)
第一轮对话:如果 Producer 可以直接从从文件加载代码(我们提供的案例中,示例代码被存放在 code_to_critique.md 中,系统读取后,存放在 initial_code变量),则直接作为当前代码 进入 Critic,不调用 LLM;后续轮对话次按 task + critique 进行修订。
Producer 节点的核心代码如下:
python
def node_producer(state: ReflectionState) -> dict:
"""
Producer 节点:首轮根据任务生成代码(或使用 initial_code 跳过生成),后续轮次根据评审意见修订代码。
"""
task = state.get("task") or DEFAULT_TASK_PROMPT
critique = (state.get("critique") or "").strip()
iteration = state.get("iteration") or 0
initial_code = (state.get("initial_code") or "").strip()
# 若提供 initial_code 且为首轮:直接将其作为当前代码进入 Critic,不调用 LLM
if iteration == 0 and initial_code:
if STEP_VERBOSE:
n_lines = len(initial_code.strip().splitlines())
logger.info("[Producer] 第 1 轮:使用 initial_code(未调用 LLM),代码行数: %s", n_lines)
return {
"current_code": initial_code,
"iteration": 1,
}
chain = _producer_chain()
if iteration == 0:
if STEP_VERBOSE:
logger.info("[Producer] 第 1 轮:根据任务生成代码(调用 LLM)...")
message = task
else:
if STEP_VERBOSE:
logger.info("[Producer] 第 %s 轮:根据评审意见修订代码(调用 LLM)...", iteration + 1)
message = Template(PRODUCER_REFINE_BODY).render(task=task, critique=critique)
current_code = chain.invoke({"message": message})
current_code = (current_code or "").strip()
if STEP_VERBOSE:
n_lines = len(current_code.splitlines())
logger.info("[Producer] 本轮输出代码行数: %s", n_lines)
return {
"current_code": current_code,
"iteration": iteration + 1,
}💡 理解要点 :Producer 不关心「是谁在审」,只关心状态里的 task 和 critique;首轮有 initial_code 时跳过生成,直接送审。
6.2.1 第一轮对话
以下是运行代码后第一轮对话 producer 的相关日志:
log
2026-03-12 13:46:03 [INFO] reflection: --- Reflection 示例:从文件加载待评审代码 ---
2026-03-12 13:46:03 [INFO] reflection: 文件: code_to_critique.md
2026-03-12 13:46:03 [INFO] reflection: 已从文件加载代码,共 85 行,将作为 initial_code 传入(首轮不调用 LLM)
2026-03-12 13:46:03 [INFO] reflection: 任务: 评审并改进代码(语法、风格、边界与最佳实践)
2026-03-12 13:46:03 [INFO] reflection: [Producer] 第 1 轮:使用 initial_code(未调用 LLM),代码行数: 85如果没有 initial_code 的话,系统会通过LLM生成一段代码,相关的prompt如下:
py
# ---------------------------------------------------------------------------
# Producer 角色:生成 / 修订代码
# ---------------------------------------------------------------------------
PRODUCER_SYSTEM = """You are a Python developer. Generate or refine Python code strictly according to the user's task. If the user provides a critique of previous code, you must apply those suggestions and output only the revised code."""
# 变量:message(首轮为任务全文,后续轮为「任务 + 评审意见」拼好的内容)
PRODUCER_USER = """{{ message }}"""6.2.2 第二轮对话开始
以下是第二轮对话开始 Producer 的相关的日志。需要注意,从第二轮对话开始,Producer的输出是基于前一轮的代码(message)以及评审的结果(Critique):
py
2026-03-12 13:46:14 [INFO] reflection: [Producer] 第 2 轮:根据评审意见修订代码(调用 LLM)...
2026-03-12 13:46:35 [INFO] reflection: [Producer] 本轮输出代码行数: 156相关的 prompt 如下:
py
PRODUCER_REFINE_BODY = """Please refine the code using the critiques provided below.
Original task:
{{ task }}
Critique of the previous code:
{{ critique }}
Output only the revised Python code, no explanation."""6.3 Critic 节点与分数路由
Critic 节点的任务是对于producer节点出来的代码进行评审。更具体地说,对照 task 与 current_code 输出单一 JSON 对象 ,包含 score(0--100)、score_reason、critiques。解析后写入状态的 critique_score 与格式化后的 critique(供 Producer 修订)。
Critic 节点的核心代码如下:
python
def node_critic(state: ReflectionState) -> dict:
"""
Critic 节点:对当前代码做评审,输出 JSON(score、score_reason、critiques),
解析后写入 critique(供 Producer)与 critique_score(供路由)。
"""
task = state.get("task") or DEFAULT_TASK_PROMPT
current_code = state.get("current_code") or ""
iteration = state.get("iteration") or 0
if STEP_VERBOSE:
logger.info("[Critic] 第 %s 轮:评审中...", iteration)
chain = _critic_chain()
raw = (chain.invoke({"task": task, "code": current_code}) or "").strip()
score, critique_text = _parse_critic_json(raw)
if STEP_VERBOSE:
logger.info("[Critic] 评审分数: %s/100", score)
logger.info("[Critic] 分数原因: %s", (critique_text.split("\n")[1:2] or [""])[0][:200])
return {"critique": critique_text, "critique_score": score}案例中评审节点输出日志如下:
第一轮评审结果日志:
log
2026-03-12 13:40:36 [INFO] reflection: [Critic] 第 1 轮:评审中...
2026-03-12 13:40:48 [INFO] reflection: [Critic] 评审分数: 30/100
2026-03-12 13:40:48 [INFO] reflection: [Critic] 分数原因: Reason: Multiple syntax errors: missing colons after 'def process_data', 'if reverse', 'def clear', 'def clear_logs'; 'for i in range' has illegal line break; 'if n > max_val' missing colon and indent
2026-03-12 13:40:48 [INFO] reflection: [路由] 继续修订(分数 30 < 90,当前第 1 轮)。第二轮评审结果日志:
log
2026-03-12 13:46:35 [INFO] reflection: [Critic] 第 2 轮:评审中...
2026-03-12 13:46:37 [INFO] reflection: [Critic] 评审分数: 95/100
2026-03-12 13:46:37 [INFO] reflection: [Critic] 分数原因: Reason: Code is well-structured, handles edge cases (empty lists, missing files), uses context managers for files, avoids mutable defaults, and follows PEP 8. Only minor improvement: `find_max` could 评审相关的prompt如下:
py
# ---------------------------------------------------------------------------
# Critic 角色:代码评审(输出 JSON:score、score_reason、critiques)
# ---------------------------------------------------------------------------
# 分数达到此阈值则视为通过,不再进入下一轮修订(可被 reflection_graph 覆盖)
CRITIC_SCORE_THRESHOLD = 90
CRITIC_SYSTEM = """You are a senior software engineer and an expert in Python. Your role is to perform a strict, meticulous code review.
CRITICAL: You must output ONLY one valid JSON object. Do NOT output the code you are reviewing, do NOT add any explanation before or after the JSON. Your entire response must be exactly one line or multiple lines that form a single JSON object starting with { and ending with }.
You must output a single valid JSON object (no markdown, no code fence) with exactly these three keys:
1. "score": integer 0-100. Overall code quality score. 100 = perfect; lower for any issue below.
2. "score_reason": string. Concise explanation of why this score was given, citing specific lines or names (e.g. which variable is wrong, which line has a syntax error).
3. "critiques": string. Bulleted list of specific issues (one per line, start each with "- "). If no issues, use empty string or "None".
Scoring rules (you must follow):
- Any syntax error (missing colon after def/if/for/else, undefined variable NameError, wrong indentation): score at most 60. Cite the line or variable.
- Variable name errors: e.g. variable defined as A but code uses B (undefined), or meaningless names (single letter like d, or nonsensical like dss): score at most 70. In score_reason, name the bad variable and what it should be.
- Multiple syntax or naming errors: score at most 50.
- Logic bugs, missing edge cases, no docstrings, mutable default args: deduct points; score typically below 90 until fixed.
- Only code with no syntax errors, clear variable names, and meeting the task requirements may score 90 or above.
Evaluate against the original task. Be strict: code that cannot run (syntax/NameError) or has unclear naming must not score 90+.
Example for code with undefined variable and bad names:
{"score": 55, "score_reason": "merge_dicts: defines dss but uses undefined d; return d causes NameError. Variable names dss/d are meaningless.", "critiques": "- Line 29: use dss not d (d is undefined)\\n- Use descriptive name e.g. merged instead of dss/d"}
Remember: output ONLY the JSON object. Never output the code under review or any other text."""
# 变量:task, code
CRITIC_USER = """Original Task:
{{ task }}
Code to Review:
{{ code }}"""6.4 条件边:继续修订还是结束
路由函数根据 critique_score 、critique 中的约定标记与 iteration 决定下一跳:分数 ≥ 阈值(默认 90) 或含 CODE_IS_PERFECT 或达最大轮次则结束,否则回到 Producer:
python
def route_after_critique(state: ReflectionState) -> Literal["refine", "end"]:
"""
评审后路由:若 critique_score >= 阈值(默认 90)或已达最大轮次则结束,否则回到 Producer 修订。
兼容旧版:若 critique 中含 CODE_IS_PERFECT 也视为通过。
"""
critique = (state.get("critique") or "").strip()
score = state.get("critique_score", 0)
iteration = state.get("iteration") or 0
max_iterations = state.get("max_iterations") or DEFAULT_MAX_ITERATIONS
if CODE_IS_PERFECT_MARKER in critique:
if STEP_VERBOSE:
logger.info("[路由] 评审通过(CODE_IS_PERFECT),结束。")
return "end"
if score >= CRITIC_SCORE_THRESHOLD:
if STEP_VERBOSE:
logger.info("[路由] 评审通过(分数 %s >= 阈值 %s),结束。", score, CRITIC_SCORE_THRESHOLD)
return "end"
if iteration >= max_iterations:
if STEP_VERBOSE:
logger.info("[路由] 已达最大轮数 %s,结束。", max_iterations)
return "end"
if STEP_VERBOSE:
logger.info("[路由] 继续修订(分数 %s < %s,当前第 %s 轮)。", score, CRITIC_SCORE_THRESHOLD, iteration)
return "refine"这样,分数达标 、约定通过标记 或达到最大轮数都会结束图;否则回到 Producer 进行下一轮修订。
6.5 图结构小结
- START → producer → critic → 条件边 → producer(循环)| end → END
- Prompt :全部在
demo_codes/prompt.py,Jinja2 格式;阈值CRITIC_SCORE_THRESHOLD默认 90。
完整实现(含默认任务提示、从文件加载、LLM 与链的构建)见源代码 demo_codes/reflection_graph.py、demo_codes/main.py 与 demo_codes/prompt.py。
8 小结与延伸
- 反思 让智能体在「执行」之后多一步评估与修订,通过「生成 → 评审 → 修订」的闭环提升输出质量。
- Producer-Critic 把「写」和「审」拆成两个角色(或两套 Prompt),往往比单智能体自审更客观、更易控。
- 在 LangGraph 中:状态 承载任务、当前输出、评审意见与评审分数 (及可选的从文件加载的
initial_code),Producer / Critic 节点 负责生成与评审(Critic 输出 JSON 分数与问题列表),条件边 根据分数是否达标(默认 ≥ 90)与轮次决定继续改还是结束,结构清晰、易于扩展。 - 反思会带来更多 LLM 调用 和更长上下文(多轮代码 + 评审),在延迟与成本上需要权衡;适合对质量要求高、对实时性要求相对宽松的场景。
若要将反思与目标与监控(Goal & Monitoring) 或记忆(Memory) 结合,可以把「目标」作为评审的终极标准,把「历史对话或历史评审」纳入状态,让反思在更长上下文中累积改进。