目录
[1. 能力坐标系的困境](#1. 能力坐标系的困境)
[2. Intern S1的目标定位](#2. Intern S1的目标定位)
[1. 三大输入通道](#1. 三大输入通道)
[2. 架构优势](#2. 架构优势)
[高质量科学语料:2.5 万亿 token 的专业知识注入](#高质量科学语料:2.5 万亿 token 的专业知识注入)
[2. 六大科学领域覆盖](#2. 六大科学领域覆盖)
[1. PDF 文档解析管线](#1. PDF 文档解析管线)
[2. 网页数据召回过滤管线](#2. 网页数据召回过滤管线)
[1. 科学任务的多样性挑战](#1. 科学任务的多样性挑战)
[2. MOR 混合奖励模型](#2. MOR 混合奖励模型)
[3. 动态权重调整](#3. 动态权重调整)
[系统工程优化:全链路 FP8 精度](#系统工程优化:全链路 FP8 精度)
[1. 强化学习的成本挑战](#1. 强化学习的成本挑战)
[2. FP8 全链路支持](#2. FP8 全链路支持)
[1. 科学任务能力](#1. 科学任务能力)
[2. 轻量化版本](#2. 轻量化版本)
[1. 四大能力面](#1. 四大能力面)
[2. 科研全流程覆盖](#2. 科研全流程覆盖)
本节课由上海人工智能实验室团队授课,针对 Intern S1 科学多模态大模型------一个既具备顶尖通用智能,又拥有深厚科研素养的全能型科学基座模型展开深入讲解。
本节前置课程为《AI 模型导论与推理基础原理》《AI 模型导论与推理基础原理》,有需要的同学可以点击查看往期内容。
为什么需要专门的科学基座大模型?
1. 能力坐标系的困境
将模型能力置于二维坐标系中:
-
• 横轴:通用能力(日常对话、代码写作等)
-
• 纵轴:科学能力(数学推理、化学预测、物理建模等)
传统模型大多集中在右下角------通用能力强但科学能力弱;
专用科学模型则位于左上角------科学专业但通用性差。
2. Intern S1的目标定位
Intern S1 的目标是向右上角突破,不以牺牲通用能力为代价换取科学能力,而是通过通专融合实现两者兼顾:
-
• 全能高手:在通用多模态任务上超越现有开源模型
-
• 科学明星:在专业科学任务上超越甚至对标闭源模型
科学多模态架构:专为科研场景设计
1. 三大输入通道
Intern S1 采用专门的多模态架构,针对科学场景的三类典型输入设计了独立通道:
视觉模块
-
• 核心技术:自研 IntVIT 视觉编码器
-
• 应用场景:论文图表、气象图、显微图像等科学可视化内容
-
• 优势:专门针对科学图表的复杂结构进行优化
动态分词器
-
• 核心问题:传统静态分词器对科学符号序列处理效果差
-
• 解决方案:先识别字符串模态,再按模态选择分词策略
-
• 具体实现:
-
• SMILES分子式:
<smiles>CC1=CC=CC=C1</smiles> -
• FASTA蛋白质序列:
<fasta>MKTVRQ...</fasta>
-
-
• 效果:SMILES 数据压缩率提升70%,显著降低计算开销
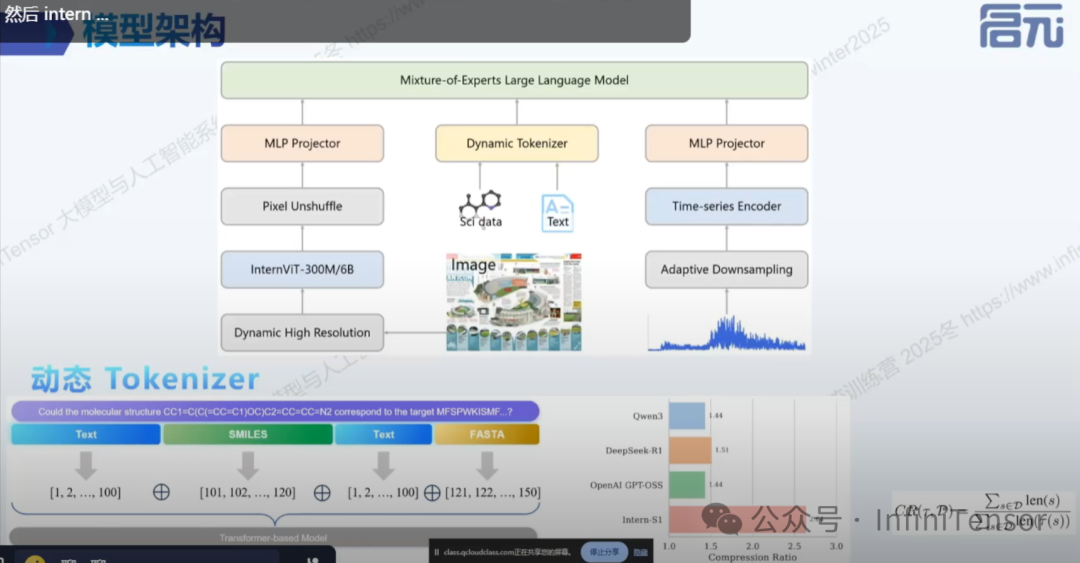
时序模块
-
• 应用场景:地震波、脑电波等连续时间序列信号
-
• 技术方案:专用时序编码器将连续信号转换为大模型可理解的 token 表示
2. 架构优势
这种分流投影的设计避免了将所有科学数据"一股脑"塞进文本 tokenizer 的问题,确保不同模态的科学数据都能得到最合适的处理。
高质量科学语料:
2.5 万亿 token 的专业知识注入
1.数据规模与构成
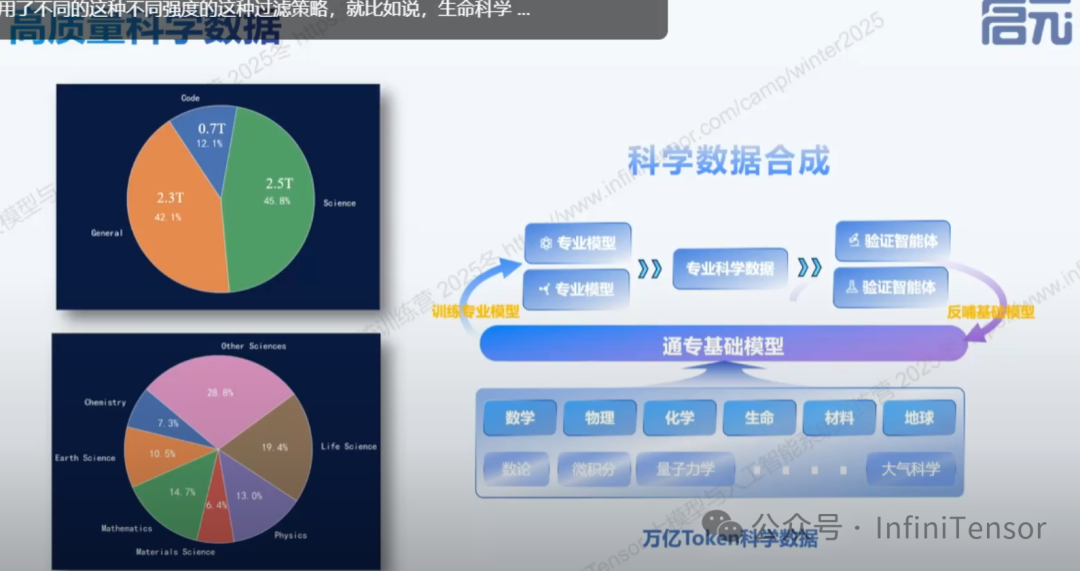
2. 六大科学领域覆盖
- • 重点调控六大科学领域的数据分布:
数学、物理、化学、生命科学、材料科学、地球科学
-
• 差异化策略:
-
• 生命科学:数据量大但噪音多,采用更严格的过滤策略
-
• 材料科学:数据相对稀缺,采用更宽松但可控的召回筛选
-
科学数据挖掘:两条核心管线
1. PDF 文档解析管线
核心挑战:科学PDF文献排版复杂,包含大量公式、符号,解析质量直接影响模型学习效果。
创新方案:页面级混合解析流水线
-
• 低成本解析器(Manus):处理大多数普通页面
-
• 高成本解析器(InterV):专门处理包含复杂公式、符号的疑难页面
-
• 智能分流:基于公式密度和复杂度自动选择解析器
-
• 统一后处理:规范化公式块边界、重排阅读顺序、修复乱码
2. 网页数据召回过滤管线
-
• 核心挑战:网页科学内容含金量低,充斥广告和非科学内容。
-
• 创新方案:域名级别智能质检
-
• 域名分组:将同一域名下的网页打包处理
-
• 抽样质检:从每个域名抽取代表性页面进行质量评估
-
• 大模型 Agent:判断网站科学价值,决定保留、丢弃或重写
-
• 标签扩展:将抽样结果扩展到整个域名
-
-
• 质量保障:通过分布内/分布外验证集不断优化质检指令,确保过滤准确率达到要求。
混合强化学习:兼顾严谨性与创造性
1. 科学任务的多样性挑战
-
• 易验证任务:数学题、化学方程式等有明确答案
-
• 难验证任务:科研计划、实验构想等开放性问题
2. MOR 混合奖励模型
针对不同类型任务采用不同的奖励机制:
-
• 易验证任务
-
• 规则验证器:直接验算答案正确性
-
• 大模型裁判:更强模型对比输出与标准答案
-
-
• 难验证任务
-
• 奖励模型:如 PPO-7B 等模型评估输出质量
-
• 评估维度:逻辑自洽性、步骤可执行性、实验设计完整性
-
3. 动态权重调整
MOR 算法会动态调整各类奖励的权重,既保持科学严谨性,又不失发散创新能力:
-
• 该硬则硬:数学题等任务强调答案准确性
-
• 该软则软:科研写作等任务注重逻辑性和创造性
系统工程优化:全链路 FP8 精度
1. 强化学习的成本挑战
-
• 主要瓶颈:Rollout 轨迹采样阶段的吞吐量和带宽压力
-
• MoE 模型特性:长序列、多专家路由增加系统负担
2. FP8 全链路支持
Intern S1 在全训练流程中采用8位浮点数精度,显著提升 Rollout 吞吐量,降低强化学习整体成本。
实际应用表现
1. 科学任务能力
-
• IMO 2025 数学竞赛:达到人类选手银牌水平,能给出完整严密的证明过程
-
• 化学文献解析:不仅能提取文字,还能完美解析复杂化学反应路径图
-
• 天文学识别:能准确识别黑洞吸积盘特征,排除猫、甜甜圈等干扰项

2. 轻量化版本
-
• Intern S1 Mini:8B 参数轻量版本
-
• 硬件要求:单张 24GB 显存消费级显卡(如 RTX 4090)
-
• 性能表现:在化学、材料等任务上超越多个 70B 大模型
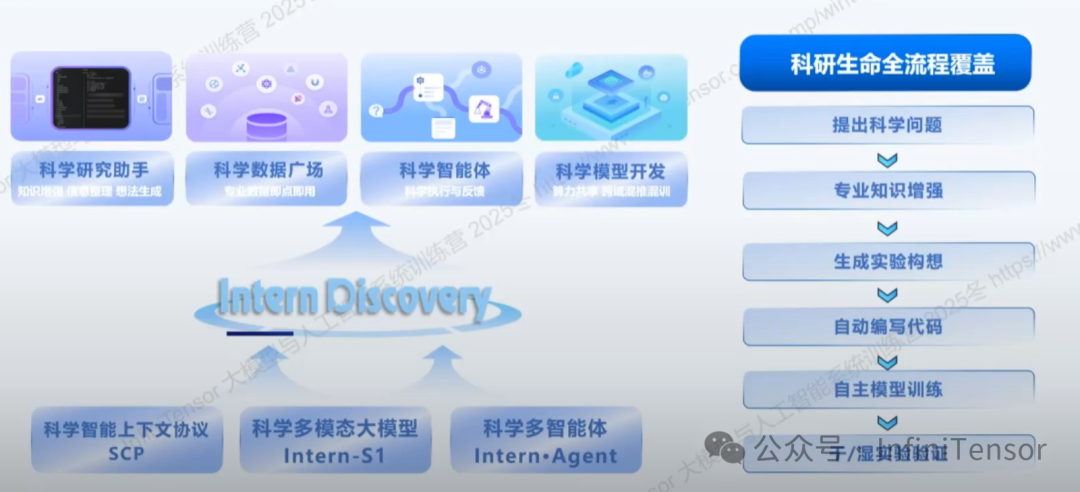
科学发现平台:从模型到科研操作系统
Intern S1 不仅是模型,更是科学发现平台的核心引擎:
1. 四大能力面
-
• 科学研究助手:文献梳理、信息整合、想法生成
-
• 科学数据广场:汇集 200PB 清洗好的 AI-ready 科学数据
-
• 科学智能体:自动拆解复杂任务,调用工具完成子任务
-
• 科学模型开发:训练、微调、评测、算力协同一体化
2. 科研全流程覆盖
总结
Intern S1科学多模态大模型代表了 AI for Science 的新范式------通过科学多模态架构 + 高质量科学语料 + 混合强化学习 + 系统工程优化的协同增益,Intern S1 成功实现了通用能力与科学能力的双重突破,为科研工作者提供了强大的 AI 助手。希望更多研究者能够掌握这一工具,在各自领域做出"很酷的成果"。