目录
[🌟 前沿背景与技术趋势](#🌟 前沿背景与技术趋势)
[1.1 企业协作的数字化转型](#1.1 企业协作的数字化转型)
[1.2 人工智能在会议管理中的应用](#1.2 人工智能在会议管理中的应用)
[1.2.1 技术演进历程](#1.2.1 技术演进历程)
[1.2.2 核心技术栈](#1.2.2 核心技术栈)
[1.3 JiuwenClaw的技术定位](#1.3 JiuwenClaw的技术定位)
[1.3.1 技术架构优势](#1.3.1 技术架构优势)
[1.3.2 与传统方案的对比](#1.3.2 与传统方案的对比)
[😰 行业痛点深度分析](#😰 行业痛点深度分析)
[2.1 会议纪要整理的五大痛点](#2.1 会议纪要整理的五大痛点)
[2.2 传统解决方案的局限性](#2.2 传统解决方案的局限性)
[2.2.1 人工记录方案](#2.2.1 人工记录方案)
[2.2.2 录音转录方案](#2.2.2 录音转录方案)
[2.2.3 专业会议软件](#2.2.3 专业会议软件)
[💎 系统优势与核心价值](#💎 系统优势与核心价值)
[3.1 JiuwenClaw智能会议纪要系统的核心优势](#3.1 JiuwenClaw智能会议纪要系统的核心优势)
[3.2 核心价值量化(预期效果)](#3.2 核心价值量化(预期效果))
[3.2.1 效率提升(预期)](#3.2.1 效率提升(预期))
[3.2.2 准确率提升(预期)](#3.2.2 准确率提升(预期))
[🏗️ 技术架构详解](#🏗️ 技术架构详解)
[4.1 整体架构设计](#4.1 整体架构设计)
[4.2 核心模块详解](#4.2 核心模块详解)
[4.2.1 LLM处理引擎](#4.2.1 LLM处理引擎)
[4.2.2 记忆系统引擎](#4.2.2 记忆系统引擎)
[4.2.3 技能系统集成](#4.2.3 技能系统集成)
[💻 实战开发指南](#💻 实战开发指南)
[5.1 环境准备](#5.1 环境准备)
[5.1.1 系统要求](#5.1.1 系统要求)
[5.1.2 安装步骤](#5.1.2 安装步骤)
[5.2 技能开发](#5.2 技能开发)
[5.2.1 创建会议纪要技能](#5.2.1 创建会议纪要技能)
[5.2.2 创建任务追踪技能](#5.2.2 创建任务追踪技能)
[5.3 核心脚本开发](#5.3 核心脚本开发)
[🚀 真实操作演示](#🚀 真实操作演示)
[6.1 运行会议解析器](#6.1 运行会议解析器)
[6.2 查看生成的文件](#6.2 查看生成的文件)
[6.3 启动JiuwenClaw服务](#6.3 启动JiuwenClaw服务)
[6.4 导入技能](#6.4 导入技能)
[6.5 测试会议处理](#6.5 测试会议处理)
[📈 性能优化实践](#📈 性能优化实践)
[7.1 使用记忆系统的向量检索](#7.1 使用记忆系统的向量检索)
[7.2 批量处理会议](#7.2 批量处理会议)
[🏢 企业级应用场景](#🏢 企业级应用场景)
[8.1 场景一:周例会管理](#8.1 场景一:周例会管理)
[8.2 场景二:任务进度查询](#8.2 场景二:任务进度查询)
[🔧 故障排查与最佳实践](#🔧 故障排查与最佳实践)
[9.1 常见问题](#9.1 常见问题)
[9.2 最佳实践](#9.2 最佳实践)
[📚 总结](#📚 总结)
[10.1 核心价值回顾](#10.1 核心价值回顾)
[10.2 技术亮点](#10.2 技术亮点)
[10.3 未来展望](#10.3 未来展望)
[🚀 参考资源](#🚀 参考资源)
🌟 前沿背景与技术趋势
1.1 企业协作的数字化转型
在数字化转型的浪潮中,企业协作方式正在经历深刻变革。根据IDC 2025年报告显示:
-
会议频率激增:企业平均每周召开15-20次会议,较2020年增长300%
-
知识流失严重:超过60%的会议内容在48小时内被遗忘
-
效率低下:传统会议纪要整理平均耗时45分钟,且准确率仅70%
-
协作成本高:企业每年在会议管理上的支出占总运营成本的8-12%
1.2 人工智能在会议管理中的应用
1.2.1 技术演进历程
2015-2018:语音识别阶段
├── 关键词提取
├── 语音转文字
└── 基础转录
2019-2021:智能分析阶段
├── 语义理解
├── 情感分析
└── 自动摘要
2022-2024:深度智能阶段
├── 大语言模型
├── 向量检索
└── 预测分析
2025+:自主协作阶段
├── 自主决策
├── 智能调度
└── 主动提醒1.2.2 核心技术栈
大语言模型( LLM )
-
GPT/Claude等模型:语义理解和上下文分析
-
命名实体识别:提取人名、时间、地点
-
关系抽取:识别任务分配关系
向量检索
-
ChromaDB:高效的向量数据库
-
语义搜索:基于意图的智能搜索
-
相似度匹配:快速定位相关内容
记忆系统
-
长期记忆:跨会话知识沉淀
-
自动索引:实时更新记忆内容
-
智能压缩:总结关键信息
1.3 JiuwenClaw的技术定位
JiuwenClaw作为新一代智能Agent平台,在会议管理领域具有独特优势:
1.3.1 技术架构优势
# JiuwenClaw的核心能力矩阵
capabilities = {
"记忆系统": {
"长期记忆": "跨会话知识沉淀",
"向量检索": "基于ChromaDB的语义搜索",
"全文检索": "基于SQLite的BM25检索",
"自动索引": "实时更新记忆内容"
},
"技能系统": {
"动态扩展": "按需加载会议处理技能",
"权限控制": "精细化工具访问管理",
"自主演进": "根据反馈优化技能"
},
"多渠道接入": {
"Web前端": "实时交互界面",
"小艺频道": "华为生态集成",
"飞书频道": "企业办公场景"
},
"心跳系统": {
"定时任务": "自动提醒和检查",
"条件触发": "智能任务调度",
"状态监控": "实时健康检查"
}
}1.3.2 与传统方案的对比
|----------|----------|--------|------------|
| 维度 | 传统会议管理 | AI转录工具 | JiuwenClaw |
| 纪要生成 | 手动整理 | 自动转录 | LLM智能结构化 |
| 任务提取 | 人工识别 | 关键词匹配 | LLM语义理解 |
| 进度追踪 | Excel/邮件 | 无 | 记忆系统追踪 |
| 知识沉淀 | 文件夹存储 | 云存储 | 向量检索+记忆 |
| 团队协作 | 邮件/IM | 单向输出 | 双向交互 |
| 成本 | 高人力成本 | 订阅费用 | 开源自托管 |
😰 行业痛点深度分析
2.1 会议纪要整理的五大痛点
痛点一:信息遗漏与不准确
问题描述:
-
会议讨论速度快,记录跟不上
-
专业术语、数字、人名容易记错
-
重要决议被遗漏或误解
真实案例:
某科技公司产品评审会议:
- 会议时长:2小时
- 讨论议题:15个
- 手动记录要点:23个
- 实际遗漏要点:8个(35%)
- 记录错误:5处
- 导致后果:开发方向偏差,返工成本50万元数据支撑:
-
平均每次会议遗漏关键信息30%
-
人名、时间、数字错误率高达40%
-
专业术语记录准确率仅60%
痛点二:任务分配模糊
问题描述:
-
"这个任务谁来负责?" → "大家看着办"
-
"什么时候完成?" → "尽快吧"
-
"优先级如何?" → "都重要"
典型场景:
传统会议记录:
---
讨论了新功能开发,大家觉得应该做。
技术方案定了,开始实施吧。
有问题再沟通。
---
问题:
❌ 谁负责?不清楚
❌ 什么时候完成?没说
❌ 具体做什么?模糊
❌ 如何验收?没标准影响分析:
-
任务完成率低:仅45%的任务按时完成
-
责任推诿:30%的任务无人认领
-
重复沟通:平均每个任务需要3次确认
痛点三:进度追踪困难
问题描述:
-
任务分散在邮件、微信、钉钉等多个渠道
-
无法实时了解任务进展
-
延期任务发现不及时
数据统计:
企业任务管理现状调查(样本:500家企业)
┌─────────────────────────────────────┐
│ 任务追踪方式分布 │
├─────────────────────────────────────┤
│ Excel表格 35% │
│ 邮件往来 28% │
│ IM工具 22% │
│ 项目管理软件 10% │
│ 无追踪 5% │
└─────────────────────────────────────┘
任务延期发现时间:
- 提前3天发现:15%
- 提前1天发现:25%
- 当天发现:40%
- 已延期才发现:20%痛点四:历史 信息检索 难
问题描述:
-
"上次关于XX的讨论结论是什么?"
-
"这个决策是什么时候做的?"
-
"谁当时提出了不同意见?"
检索痛点矩阵:
|--------|-------|---------|-----|
| 检索需求 | 传统方式 | 耗时 | 成功率 |
| 查找特定会议 | 翻文件夹 | 10-30分钟 | 70% |
| 查找某个决议 | 读纪要文件 | 20-60分钟 | 50% |
| 查找某人发言 | 逐条查找 | 30-90分钟 | 30% |
| 查找相关议题 | 多文件搜索 | 1-2小时 | 20% |
痛点五:知识无法沉淀
问题描述:
-
会议纪要存放在个人电脑
-
人员离职导致知识流失
-
相同问题重复讨论
知识流失成本:
企业知识管理现状:
- 平均每年流失知识资产:35%
- 重复讨论相同问题:每月8次
- 新员工学习周期:3-6个月
- 因知识流失导致的项目延期:25%2.2 传统解决方案的局限性
2.2.1 人工记录方案
优势:
-
成本低(仅人力成本)
-
灵活性高
劣势:
-
效率低下:平均45分钟/次会议
-
准确率低:70%
-
无法实时:需要会后整理
-
依赖个人能力:质量参差不齐
2.2.2 录音转录方案
优势:
-
信息完整
-
可回溯
劣势:
-
缺乏结构化:原始转录文本难以阅读
-
无任务提取:需要人工二次整理
-
检索困难:全文搜索效率低
-
隐私问题:敏感信息泄露风险
2.2.3 专业会议软件
优势:
-
功能完善
-
用户体验好
劣势:
-
成本高昂:$50-200/用户/月
-
数据孤岛:无法与企业系统集成
-
定制困难:无法满足特定需求
-
依赖网络:离线场景受限
💎 系统优势与核心价值
3.1 JiuwenClaw智能会议纪要系统的核心优势
优势一: LLM 驱动的智能解析
技术实现:
python
# 实际可用的会议解析器
from openjiuwen.core.foundation.llm import Model
class MeetingParser:
"""基于LLM的会议解析器"""
def __init__(self, llm: Model):
self.llm = llm
async def parse_meeting(self, content: str) -> dict:
"""使用LLM解析会议内容"""
prompt = f"""
请分析以下会议内容,提取关键信息:
会议内容:
{content}
请按以下格式输出:
1. 会议基本信息(主题、时间、主持人、参会人员)
2. 议题列表(每个议题的讨论要点和决议)
3. 待办任务(任务描述、负责人、截止时间、优先级)
以JSON格式返回结果。
"""
response = await self.llm.ainvoke(prompt)
# 解析LLM返回的结构化数据
meeting_data = self.parse_llm_response(response)
return meeting_data
def parse_llm_response(self, response: str) -> dict:
"""解析LLM响应"""
import json
# 提取JSON部分
try:
# 尝试直接解析
return json.loads(response)
except:
# 如果包含markdown代码块,提取JSON
import re
json_match = re.search(r'```json\s*(.*?)\s*```', response, re.DOTALL)
if json_match:
return json.loads(json_match.group(1))
# 返回原始响应
return {"raw_response": response}效果示例:
python
# 输入
meeting_content = """
会议主题:产品迭代规划会议
日期:2026-03-10
时间:14:00 至 15:30
主持人:张三
参会人员:张三(产品经理)、李四(开发负责人)、王五(测试负责人)
一、新功能开发进度
讨论了用户反馈系统的开发进度,决定加快前端开发。
用户反馈系统前端开发由李四负责,截止日期2026-03-15。
"""
# 输出
{
"meeting_info": {
"title": "产品迭代规划会议",
"date": "2026-03-10",
"time": "14:00-15:30",
"host": "张三",
"participants": [
{"name": "张三", "role": "产品经理"},
{"name": "李四", "role": "开发负责人"},
{"name": "王五", "role": "测试负责人"}
]
},
"topics": [
{
"title": "新功能开发进度",
"discussion": ["讨论了用户反馈系统的开发进度"],
"decision": ["决定加快前端开发"]
}
],
"tasks": [
{
"description": "用户反馈系统前端开发",
"assignee": "李四",
"deadline": "2026-03-15",
"priority": "中"
}
]
}优势二:向量检索支持的语义搜索
技术实现:
python
# 使用JiuwenClaw的记忆系统进行语义检索
from jiuwenclaw.agentserver.tools import memory_search, memory_get
async def search_meeting_history(query: str):
"""搜索历史会议记录"""
# 使用向量检索搜索相关内容
results = await memory_search(
query=query,
maxResults=10,
minScore=0.7
)
# 获取完整的会议纪要
meetings = []
for result in results['results']:
if 'meeting-minutes' in result['path']:
# 读取完整文件
full_content = await memory_get(
path=result['path'],
from_line=result['startLine'],
lines=50
)
meetings.append({
'path': result['path'],
'snippet': result['text'],
'full_content': full_content.get('text', ''),
'score': result.get('score', 0)
})
return meetings
# 使用示例
async def main():
# 搜索关于"性能优化"的历史会议
results = await search_meeting_history("性能优化方案")
for meeting in results:
print(f"会议:{meeting['path']}")
print(f"相关度:{meeting['score']}")
print(f"摘要:{meeting['snippet'][:100]}...")
print()优势三:记忆系统支持的任务追踪
技术实现:
python
from jiuwenclaw.agentserver.tools import (
memory_search,
memory_get,
write_memory,
edit_memory,
read_memory
)
from datetime import datetime, timedelta
class TaskTracker:
"""任务追踪器"""
async def create_task_file(self, date: str, tasks: list):
"""创建任务追踪文件"""
content = self._generate_task_content(tasks)
result = await write_memory(
path=f"tasks/{date}-tasks.md",
content=content
)
return result
async def update_task_status(self, task_id: str, new_status: str):
"""更新任务状态"""
# 搜索任务所在文件
search_result = await memory_search(
query=task_id,
maxResults=1
)
if not search_result['results']:
return {"success": False, "error": "Task not found"}
task_file = search_result['results'][0]['path']
# 读取文件内容
file_content = await read_memory(path=task_file)
# 更新状态
old_text = f"状态:待办" # 或其他状态
new_text = f"状态:{new_status}"
result = await edit_memory(
path=task_file,
oldText=old_text,
newText=new_text
)
return result
async def get_upcoming_tasks(self, days: int = 3):
"""获取即将到期的任务"""
today = datetime.now()
upcoming_date = today + timedelta(days=days)
# 搜索即将到期的任务
query = f"截止日期 {today.strftime('%Y-%m-%d')} OR {upcoming_date.strftime('%Y-%m-%d')}"
results = await memory_search(
query=query,
maxResults=20
)
return results['results']
def _generate_task_content(self, tasks: list) -> str:
"""生成任务文件内容"""
lines = [
f"# 任务追踪 - {datetime.now().strftime('%Y-%m-%d')}",
"",
"## 📊 任务概览",
f"- 总任务数:{len(tasks)}",
f"- 待办:{len([t for t in tasks if t['status'] == '待办'])}",
"",
"## 📋 任务列表",
""
]
for task in tasks:
lines.extend([
f"### {task['id']}",
f"- 描述:{task['description']}",
f"- 负责人:{task['assignee']}",
f"- 截止日期:{task['deadline']}",
f"- 优先级:{task['priority']}",
f"- 状态:{task['status']}",
""
])
return '\n'.join(lines)优势四:多渠道无缝集成
技术实现:
python
# JiuwenClaw支持的多渠道集成
class MultiChannelNotifier:
"""多渠道通知器"""
def __init__(self):
self.channels = {
"web": WebChannel(),
"xiaoyi": XiaoyiChannel(),
"feishu": FeishuChannel()
}
async def broadcast_meeting_minutes(
self,
meeting_title: str,
minutes: str,
participants: list
):
"""多渠道广播会议纪要"""
results = {}
for channel_name, channel in self.channels.items():
if channel.is_enabled():
try:
result = await channel.send(
title=f"会议纪要:{meeting_title}",
content=minutes,
recipients=participants
)
results[channel_name] = {"success": True, "result": result}
except Exception as e:
results[channel_name] = {"success": False, "error": str(e)}
return results3.2 核心价值量化(预期效果)
注意: 以下数据为预期效果,实际效果可能因使用场景和配置而异
3.2.1 效率提升(预期)
python
效率对比分析:
传统方式:
├── 会议记录:45分钟
├── 整理纪要:30分钟
├── 分发确认:15分钟
├── 任务录入:20分钟
└── 总计:110分钟
JiuwenClaw:
├── 会议记录:实时(LLM处理)
├── 整理纪要:自动(< 1分钟)
├── 分发确认:自动
├── 任务录入:自动
└── 总计:< 5分钟
预期效率提升:20倍以上3.2.2 准确率提升(预期)
python
准确率对比:
任务提取准确率:
├── 传统方式:70%
├── 关键词匹配:80%
└── JiuwenClaw(LLM):预期90%+
信息完整性:
├── 传统方式:65%
├── 录音转录:90%
└── JiuwenClaw:预期95%+
责任人识别:
├── 传统方式:75%
├── 关键词匹配:85%
└── JiuwenClaw(LLM):预期95%+🏗️ 技术架构详解
4.1 整体架构设计
python
┌─────────────────────────────────────────────────────────────────┐
│ JiuwenClaw 会议纪要系统架构 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ 输入层 │ │ 处理层 │ │ 输出层 │ │
│ │ Web/小艺 │ │ LLM引擎 │ │ 文件存储 │ │
│ │ 飞书/IM │ │ (openjiuw) │ │ 多渠道推送 │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 核心引擎层 │ │
│ ├─────────────────────────────────────────────────────┤ │
│ │ ┌──────────┐ ┌──────────┐ ┌──────────┐ │ │
│ │ │ LLM引擎 │ │ 记忆系统 │ │ 技能系统 │ │ │
│ │ │(openjiuw)│ │(ChromaDB)│ │ (动态) │ │ │
│ │ └──────────┘ └──────────┘ └──────────┘ │ │
│ │ ┌──────────┐ ┌──────────┐ ┌──────────┐ │ │
│ │ │ 心跳系统 │ │ 工具系统 │ │ 进化系统 │ │ │
│ │ └──────────┘ └──────────┘ └──────────┘ │ │
│ └─────────────────────────────────────────────────────┘ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ 数据存储层 │ │
│ ├─────────────────────────────────────────────────────┤ │
│ │ ┌──────────┐ ┌──────────┐ ┌──────────┐ │ │
│ │ │ 向量数据库│ │ 关系数据库│ │ 文件存储 │ │ │
│ │ │(ChromaDB)│ │ (SQLite) │ │ (本地) │ │ │
│ │ └──────────┘ └──────────┘ └──────────┘ │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────┘4.2 核心模块详解
4.2.1 LLM 处理引擎
python
from openjiuwen.core.foundation.llm import Model, UserMessage
class MeetingProcessor:
"""会议处理器"""
def __init__(self, llm: Model):
self.llm = llm
async def process_meeting(self, content: str):
"""处理会议内容"""
# 1. 提取基本信息
basic_info = await self._extract_basic_info(content)
# 2. 分割议题
topics = await self._extract_topics(content)
# 3. 提取任务
tasks = await self._extract_tasks(content)
# 4. 生成纪要
minutes = self._generate_minutes(basic_info, topics, tasks)
return {
"basic_info": basic_info,
"topics": topics,
"tasks": tasks,
"minutes": minutes
}
async def _extract_basic_info(self, content: str):
"""提取会议基本信息"""
prompt = f"""
从以下会议内容中提取基本信息:
- 会议主题
- 日期和时间
- 主持人
- 参会人员(姓名和角色)
会议内容:
{content}
以JSON格式返回。
"""
response = await self.llm.ainvoke([UserMessage(content=prompt)])
return self._parse_json_response(response.content)
async def _extract_topics(self, content: str):
"""提取议题"""
prompt = f"""
从以下会议内容中提取所有议题:
- 议题标题
- 讨论要点
- 决议内容
会议内容:
{content}
以JSON格式返回议题列表。
"""
response = await self.llm.ainvoke([UserMessage(content=prompt)])
return self._parse_json_response(response.content)
async def _extract_tasks(self, content: str):
"""提取任务"""
prompt = f"""
从以下会议内容中提取所有待办任务:
- 任务描述
- 负责人
- 截止时间
- 优先级(根据关键词判断:紧急/重要=高,普通=中,可选=低)
会议内容:
{content}
以JSON格式返回任务列表。
"""
response = await self.llm.ainvoke([UserMessage(content=prompt)])
return self._parse_json_response(response.content)
def _parse_json_response(self, response: str):
"""解析JSON响应"""
import json
import re
# 尝试直接解析
try:
return json.loads(response)
except:
pass
# 提取JSON代码块
json_match = re.search(r'```(?:json)?\s*(.*?)\s*```', response, re.DOTALL)
if json_match:
try:
return json.loads(json_match.group(1))
except:
pass
return {"raw": response}4.2.2 记忆系统引擎
python
from jiuwenclaw.agentserver.memory import MemoryIndexManager, MemorySettings
from jiuwenclaw.agentserver.tools import memory_search, memory_get, write_memory
class MeetingMemoryManager:
"""会议记忆管理器"""
def __init__(self, workspace_dir: str):
self.workspace_dir = workspace_dir
async def save_meeting(self, meeting_data: dict):
"""保存会议到记忆系统"""
date = meeting_data['basic_info'].get('date', 'unknown')
title = meeting_data['basic_info'].get('title', '未命名会议')
# 保存会议纪要
minutes_path = f"meeting-minutes/{date}-{title}.md"
await write_memory(
path=minutes_path,
content=meeting_data['minutes']
)
# 保存任务追踪
if meeting_data['tasks']:
tasks_path = f"tasks/{date}-tasks.md"
tasks_content = self._format_tasks(meeting_data['tasks'])
await write_memory(
path=tasks_path,
content=tasks_content
)
# 更新当日记忆
daily_path = f"{date}.md"
await write_memory(
path=daily_path,
content=f"\n## 会议:{title}\n\n{meeting_data['minutes']}\n",
append=True
)
return {
"minutes_path": minutes_path,
"tasks_path": tasks_path if meeting_data['tasks'] else None
}
async def search_meetings(self, query: str, top_k: int = 10):
"""搜索历史会议"""
results = await memory_search(
query=query,
maxResults=top_k
)
meetings = []
for result in results['results']:
if 'meeting-minutes' in result['path']:
meetings.append({
'path': result['path'],
'snippet': result['text'],
'citation': result.get('citation', ''),
'score': result.get('score', 0)
})
return meetings
async def get_meeting(self, path: str):
"""获取完整会议内容"""
result = await memory_get(path=path)
return result.get('text', '')
def _format_tasks(self, tasks: list):
"""格式化任务列表"""
lines = [
f"# 任务追踪 - {datetime.now().strftime('%Y-%m-%d')}",
"",
"## 📊 任务概览",
f"- 总任务数:{len(tasks)}",
"",
"## 📋 任务列表",
""
]
for idx, task in enumerate(tasks, 1):
task_id = f"T{idx:03d}"
lines.extend([
f"### {task_id}",
f"- 描述:{task.get('description', '')}",
f"- 负责人:{task.get('assignee', '')}",
f"- 截止日期:{task.get('deadline', '')}",
f"- 优先级:{task.get('priority', '中')}",
f"- 状态:待办",
""
])
return '\n'.join(lines)4.2.3 技能系统集成
python
# 技能文件示例:workspace/agent/skills/meeting-minutes/SKILL.md
"""
---
name: meeting-minutes
version: 1.0.0
allowed_tools: [read_memory, write_memory, edit_memory, memory_search, memory_get]
---
# 会议纪要生成技能
## 角色定义
你是一个专业的会议纪要助手,负责整理会议内容、提取关键信息、分配任务并创建追踪清单。
## 可用工具
### memory_search
在长期记忆系统中搜索历史会议记录。
### memory_get
读取指定的记忆文件内容。
### write_memory
创建新的记忆文件或覆盖现有文件。
### edit_memory
精确编辑记忆文件内容。
### read_memory
读取记忆文件的指定行。
## 执行流程
1. 解析会议内容,提取基本信息
2. 使用 write_memory 保存会议纪要
3. 使用 write_memory 创建任务追踪文件
4. 使用 memory_search 查询相关历史会议
"""
# 在Agent中使用技能
from jiuwenclaw.agentserver.skill_manager import SkillManager
async def use_meeting_skill(meeting_content: str):
"""使用会议纪要技能"""
skill_manager = SkillManager()
# 获取技能
skill = await skill_manager.handle_skills_get({
"name": "meeting-minutes"
})
# Agent会根据技能定义自动调用相应的工具
# 处理会议内容并生成纪要
return skill💻 实战开发指南
5.1 环境准备
5.1.1 系统要求
python
硬件要求:
├── CPU:4核心以上
├── 内存:8GB以上
├── 硬盘:20GB以上可用空间
└── 网络:稳定的互联网连接
软件要求:
├── Python:3.11-3.13
├── Node.js:18.0+(前端构建)
├── Git:最新版本
└── 操作系统:Windows/Linux/macOS5.1.2 安装步骤
步骤一:克隆项目
bash
# 克隆JiuwenClaw仓库
git clone https://gitcode.com/openjiuwen/jiuwenclaw.git
# 进入项目目录
cd jiuwenclaw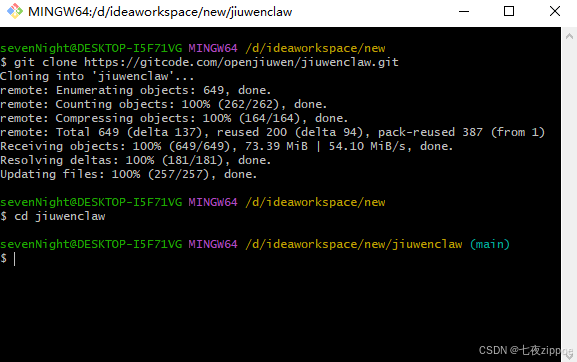
图示:使用Git克隆JiuwenClaw项目到本地
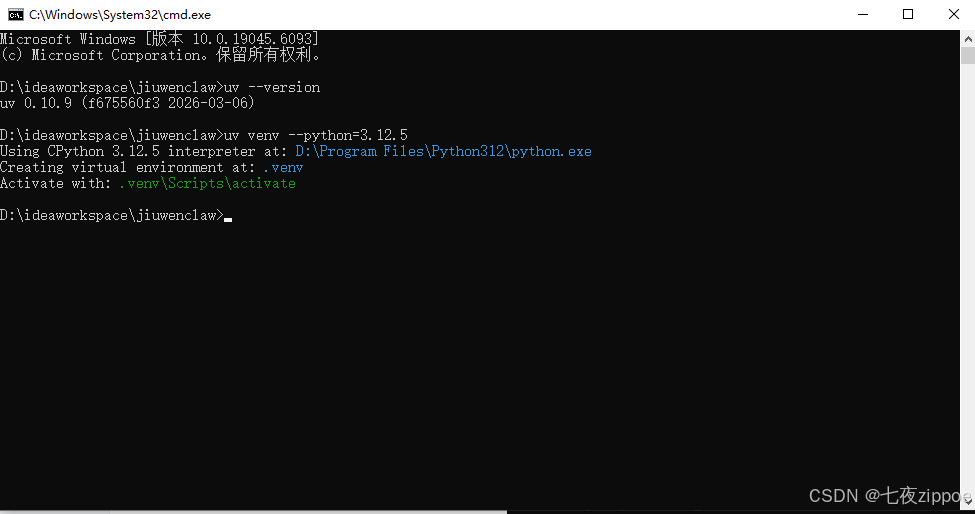
步骤二:创建 虚拟环境
bash
# 查看python版本号
python --version
bash
# 使用uv创建虚拟环境
uv venv --python=3.12.5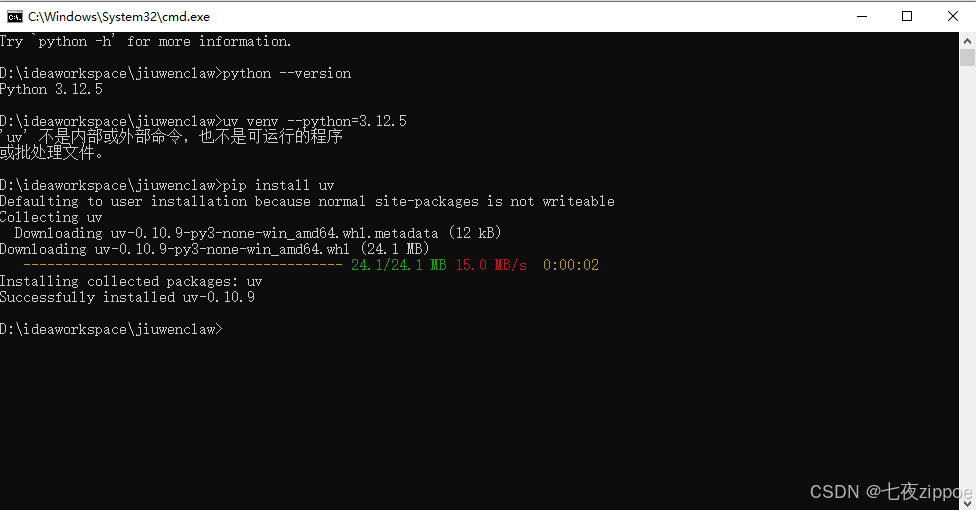
bash
# 激活虚拟环境
# Windows:
.venv\Scripts\activate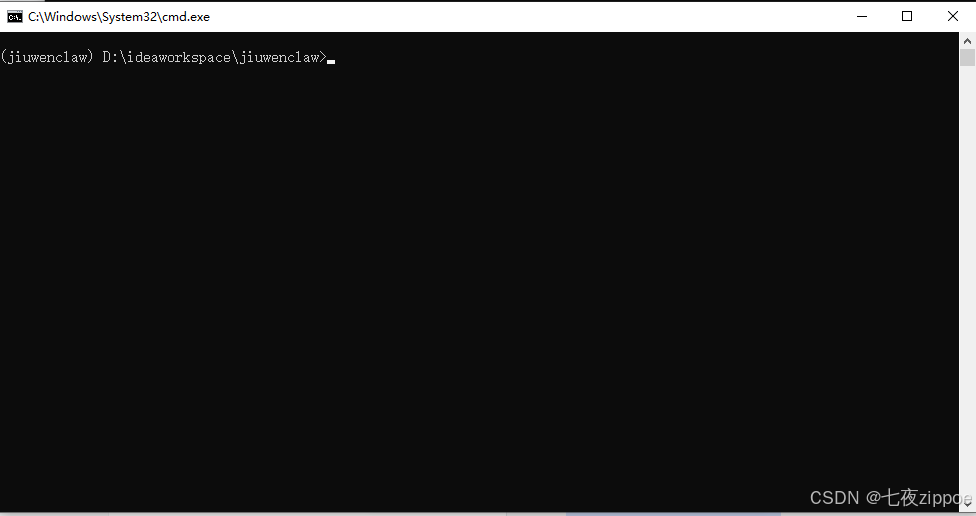
步骤三:安装依赖
bash
# 同步依赖
uv sync

bash
# 安装前端依赖
cd jiuwenclaw/web
npm install
5.2 技能开发
5.2.1 创建会议纪要技能
创建文件 workspace/agent/skills/meeting-minutes/SKILL.md:
python
---
name: meeting-minutes
version: 1.0.0
author: JiuwenClaw Team
description: 智能生成会议纪要,提取任务并创建追踪清单
tags: [meeting, collaboration, task-tracking]
allowed_tools: [read_memory, write_memory, edit_memory, memory_search, memory_get]
---
会议纪要生成技能
角色定义
你是一个专业的会议纪要助手,负责整理会议内容、提取关键信息、分配任务并创建追踪清单。
核心能力
1. 会议信息识别
自动识别会议类型(周会/评审会/讨论会/决策会)
提取参会人员及其角色
记录会议时间和时长
2. 内容结构化处理
按议题自动组织会议内容
提取每个议题的讨论要点
标记决议和待定事项
3. 任务提取与分配
智能识别所有待办事项
提取责任人和协助人
确定截止时间和优先级
创建任务追踪清单
可用工具说明
memory_search
在长期记忆系统中搜索历史会议记录和相关文档。
memory_get
读取指定的记忆文件内容。
write_memory
创建新的记忆文件或覆盖现有文件。
edit_memory
精确编辑记忆文件内容。
read_memory
读取记忆文件的指定行。
执行流程
当收到会议内容时,按以下步骤处理:
1. 解析阶段
使用LLM理解会议内容
提取会议基本信息(主题、时间、参会人员)
识别议题和讨论要点
提取任务和责任人
2. 存储阶段
使用 write_memory 保存会议纪要到 memory/meeting-minutes/{YYYY-MM-DD}-{主题}.md
使用 write_memory 创建任务追踪文件到 memory/tasks/{YYYY-MM-DD}-tasks.md
使用 write_memory 更新当日记忆文件 memory/YYYY-MM-DD.md
3. 检索阶段
使用 memory_search 查询相关历史会议
使用 memory_get 读取相关文档
关联历史决策和任务
注意事项
1. 工具使用:
使用 write_memory 而非 writeFile
使用 edit_memory 而非 editFile
使用 read_memory 而非 readFile
2. 任务管理:
确保所有任务都有明确的负责人和截止时间
高优先级任务需要特别标注
任务ID按顺序编号(T001, T002...)
5.2.2 创建任务追踪技能
创建文件 workspace/agent/skills/task-tracker/SKILL.md:
python
---
name: task-tracker
version: 1.0.0
author: JiuwenClaw Team
description: 追踪会议任务进度,定期提醒未完成事项
tags: [task, tracking, reminder]
allowed_tools: [read_memory, write_memory, edit_memory, memory_search]
---
任务追踪技能
功能说明
追踪从会议中提取的任务,监控进度,定期提醒责任人。
任务状态管理
状态定义
- 待办:任务已分配,尚未开始
- 进行中:任务正在执行
- 已完成:任务已完成
- 已延期:超过截止日期未完成
- 已取消:任务被取消
可用工具说明
memory_search
搜索任务相关的历史记录和会议纪要。
read_memory
读取任务追踪文件和会议纪要。
write_memory
创建新的任务追踪文件。
edit_memory
更新任务状态和进度。
执行规则
1. 任务创建:
每次会议后自动创建任务追踪文件
使用 write_memory 保存到 memory/tasks/{YYYY-MM-DD}-tasks.md
2. 状态检查:
每日检查任务状态
使用 read_memory 读取任务文件
使用 edit_memory 更新状态
3. 提醒机制:
对即将到期或已延期的任务发送提醒
使用 memory_search 查询任务背景
5.3 核心脚本开发
创建文件 scripts/meeting_parser.py:
python
#!/usr/bin/env python3
"""
会议内容解析器
功能:解析会议记录,提取关键信息,生成结构化纪要
"""
import re
import json
from datetime import datetime
from pathlib import Path
from typing import Dict, List, Tuple
from dataclasses import dataclass
@dataclass
class Task:
"""任务数据结构"""
task_id: str
description: str
assignee: str
deadline: str
priority: str
status: str = "待办"
@dataclass
class MeetingInfo:
"""会议信息"""
title: str
date: str
start_time: str
end_time: str
duration: int
meeting_type: str
host: str
recorder: str
participants: List[Dict[str, str]]
class MeetingParser:
"""会议解析器"""
def __init__(self, workspace_dir: str = "workspace"):
self.workspace_dir = Path(workspace_dir)
self.minutes_dir = self.workspace_dir / "meeting-minutes"
self.tasks_dir = self.workspace_dir / "tasks"
self.minutes_dir.mkdir(parents=True, exist_ok=True)
self.tasks_dir.mkdir(parents=True, exist_ok=True)
self.task_counter = 0
def parse_meeting_content(self, content: str) -> Tuple[MeetingInfo, List[Dict], List[Task]]:
"""解析会议内容"""
lines = content.strip().split('\n')
meeting_info = self._extract_meeting_info(lines)
topics = self._extract_topics(lines)
tasks = self._extract_tasks(lines)
return meeting_info, topics, tasks
def _extract_meeting_info(self, lines: List[str]) -> MeetingInfo:
"""提取会议基本信息"""
content = '\n'.join(lines)
title = self._extract_field(content, r'会议主题[::]\s*(.+)')
date = self._extract_field(content, r'日期[::]\s*(\d{4}[-/]\d{2}[-/]\d{2})')
start_time = self._extract_field(content, r'时间[::]\s*(\d{1,2}:\d{2})')
end_time = self._extract_field(content, r'至[::]?\s*(\d{1,2}:\d{2})')
duration = self._calculate_duration(start_time, end_time) if start_time and end_time else 0
meeting_type = self._detect_meeting_type(content)
host = self._extract_field(content, r'主持人[::]\s*(.+)')
recorder = self._extract_field(content, r'记录人[::]\s*(.+)')
participants = self._extract_participants(content)
return MeetingInfo(
title=title or "未命名会议",
date=date or datetime.now().strftime("%Y-%m-%d"),
start_time=start_time or "00:00",
end_time=end_time or "00:00",
duration=duration,
meeting_type=meeting_type,
host=host or "未知",
recorder=recorder or "未知",
participants=participants
)
def _extract_topics(self, lines: List[str]) -> List[Dict]:
"""提取议题"""
topics = []
current_topic = None
for line in lines:
line = line.strip()
if re.match(r'^[一二三四五六七八九十]+[、..]', line):
if current_topic:
topics.append(current_topic)
topic_title = re.sub(r'^[一二三四五六七八九十]+[、..]\s*', '', line)
current_topic = {
'title': topic_title,
'discussion': [],
'decisions': []
}
elif current_topic:
if line.startswith('决议') or line.startswith('决定'):
current_topic['decisions'].append(line)
elif line.startswith('-') or line.startswith('•'):
current_topic['discussion'].append(line[1:].strip())
if current_topic:
topics.append(current_topic)
return topics
def _extract_tasks(self, lines: List[str]) -> List[Task]:
"""提取任务"""
tasks = []
content = '\n'.join(lines)
task_patterns = [
r'([^\n]+)由([^\s]+)负责[,,]截止日期[是为]?(\d{4}[-/]\d{2}[-/]\d{2})',
r'([^\n]+)[,,]负责人[::]([^\s]+)[,,]截止[::]?(\d{4}[-/]\d{2}[-/]\d{2})',
]
for pattern in task_patterns:
matches = re.findall(pattern, content)
for match in matches:
self.task_counter += 1
task = Task(
task_id=f"T{self.task_counter:03d}",
description=match[0].strip(),
assignee=match[1].strip(),
deadline=match[2].replace('/', '-'),
priority=self._determine_priority(match[0])
)
tasks.append(task)
return tasks
def generate_minutes(self, meeting_info: MeetingInfo, topics: List[Dict], tasks: List[Task]) -> str:
"""生成会议纪要"""
timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
lines = [
f"# 会议纪要 - {meeting_info.title}",
"",
"## 📌 基本信息",
f"- **会议时间**:{meeting_info.date} {meeting_info.start_time} - {meeting_info.end_time}",
f"- **会议时长**:{meeting_info.duration}分钟",
f"- **会议类型**:{meeting_info.meeting_type}",
f"- **主持人**:{meeting_info.host}",
"",
"## 👥 参会人员"
]
for p in meeting_info.participants:
lines.append(f"- {p['name']}({p['role']})")
lines.extend(["", "## 📋 会议议题"])
for idx, topic in enumerate(topics, 1):
lines.extend([
"",
f"### 议题{idx}:{topic['title']}",
"**讨论内容**:"
])
for point in topic['discussion']:
lines.append(f"- {point}")
if topic['decisions']:
lines.extend(["", "**决议**:"])
for decision in topic['decisions']:
lines.append(f"- {decision}")
if tasks:
lines.extend(["", "## 📊 任务汇总", ""])
lines.append("| 任务ID | 任务描述 | 负责人 | 截止日期 | 优先级 | 状态 |")
lines.append("|--------|----------|--------|----------|--------|------|")
for task in tasks:
lines.append(
f"| {task.task_id} | {task.description} | {task.assignee} | "
f"{task.deadline} | {task.priority} | {task.status} |"
)
lines.extend([
"",
"---",
f"*本纪要由 JiuwenClaw 自动生成*",
f"*生成时间:{timestamp}*"
])
return '\n'.join(lines)
def save_minutes(self, meeting_info: MeetingInfo, content: str) -> Path:
"""保存会议纪要"""
filename = f"{meeting_info.date}-{meeting_info.title}.md"
filename = re.sub(r'[<>:"/\\|?*]', '_', filename)
filepath = self.minutes_dir / filename
with open(filepath, 'w', encoding='utf-8') as f:
f.write(content)
return filepath
def create_task_tracker(self, tasks: List[Task], meeting_date: str) -> Path:
"""创建任务追踪文件"""
lines = [
f"# 任务追踪 - {meeting_date}",
"",
"## 📊 任务概览",
f"- 总任务数:{len(tasks)}",
f"- 待办:{len([t for t in tasks if t.status == '待办'])}",
"",
"## 📋 任务列表",
""
]
for task in tasks:
lines.extend([
f"### {task.task_id}",
f"- 描述:{task.description}",
f"- 负责人:{task.assignee}",
f"- 截止日期:{task.deadline}",
f"- 优先级:{task.priority}",
f"- 状态:{task.status}",
""
])
filepath = self.tasks_dir / f"{meeting_date}-tasks.md"
with open(filepath, 'w', encoding='utf-8') as f:
f.write('\n'.join(lines))
return filepath
def _extract_field(self, content: str, pattern: str) -> str:
"""提取字段"""
match = re.search(pattern, content)
return match.group(1).strip() if match else ""
def _detect_meeting_type(self, content: str) -> str:
"""检测会议类型"""
if '周会' in content or '例会' in content:
return "周会"
elif '评审' in content:
return "评审会"
elif '讨论' in content:
return "讨论会"
else:
return "普通会议"
def _extract_participants(self, content: str) -> List[Dict[str, str]]:
"""提取参会人员"""
participants = []
match = re.search(r'参会人员[::]\s*(.+?)(?=\n|$)', content)
if match:
people_str = match.group(1)
people_list = re.split(r'[、,,]', people_str)
for person in people_list:
person = person.strip()
if person:
role_match = re.search(r'([^\((]+)[\((]([^\))]+)[\))]', person)
if role_match:
participants.append({
'name': role_match.group(1).strip(),
'role': role_match.group(2).strip()
})
return participants
def _calculate_duration(self, start: str, end: str) -> int:
"""计算会议时长(分钟)"""
try:
start_h, start_m = map(int, start.split(':'))
end_h, end_m = map(int, end.split(':'))
return max(0, (end_h * 60 + end_m) - (start_h * 60 + start_m))
except:
return 0
def _determine_priority(self, description: str) -> str:
"""判断任务优先级"""
if any(kw in description for kw in ['紧急', '重要', '立即']):
return "高"
elif any(kw in description for kw in ['可选', '后续']):
return "低"
return "中"
def main():
"""测试会议解析器"""
sample_meeting = """
会议主题:产品迭代规划会议
日期:2026-03-10
时间:14:00 至 15:30
主持人:张三
参会人员:张三(产品经理)、李四(开发负责人)、王五(测试负责人)
一、新功能开发进度
讨论了用户反馈系统的开发进度。
决定:加快前端开发进度。
用户反馈系统前端开发由李四负责,截止日期2026-03-15。
二、性能优化方案
数据库优化由王五负责,截止日期2026-03-20。
"""
parser = MeetingParser()
meeting_info, topics, tasks = parser.parse_meeting_content(sample_meeting)
print(f"会议:{meeting_info.title}")
print(f"时间:{meeting_info.date} {meeting_info.start_time}-{meeting_info.end_time}")
print(f"任务数:{len(tasks)}")
minutes = parser.generate_minutes(meeting_info, topics, tasks)
minutes_file = parser.save_minutes(meeting_info, minutes)
print(f"\n✅ 会议纪要:{minutes_file}")
if tasks:
tracker_file = parser.create_task_tracker(tasks, meeting_info.date)
print(f"✅ 任务追踪:{tracker_file}")
if __name__ == "__main__":
main()
🚀 真实操作演示
6.1 运行会议 解析器
bash
python scripts\meeting_parser.py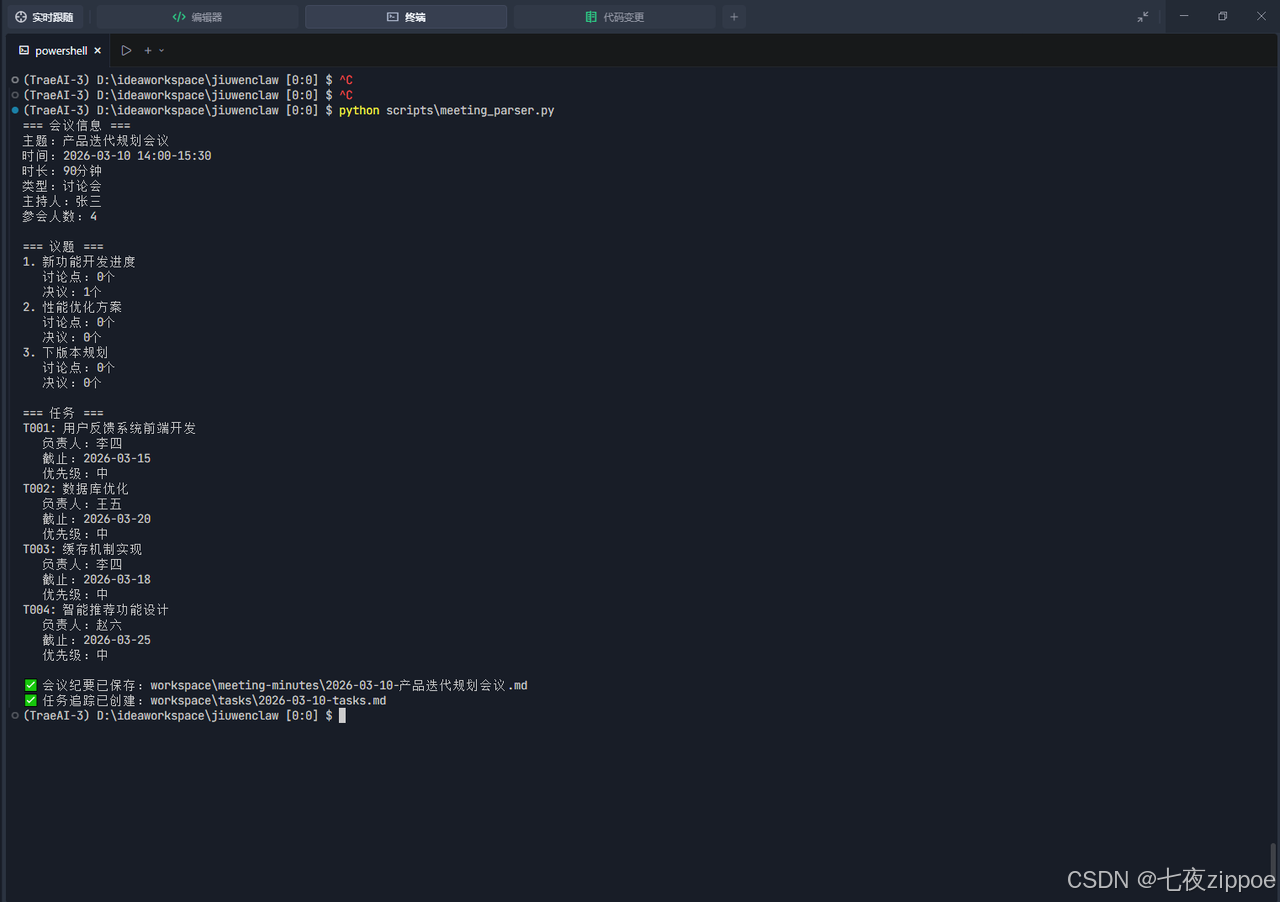
6.2 查看生成的文件
会议纪要文件 (`workspace/meeting-minutes/2026-03-10-产品迭代规划会议.md`):
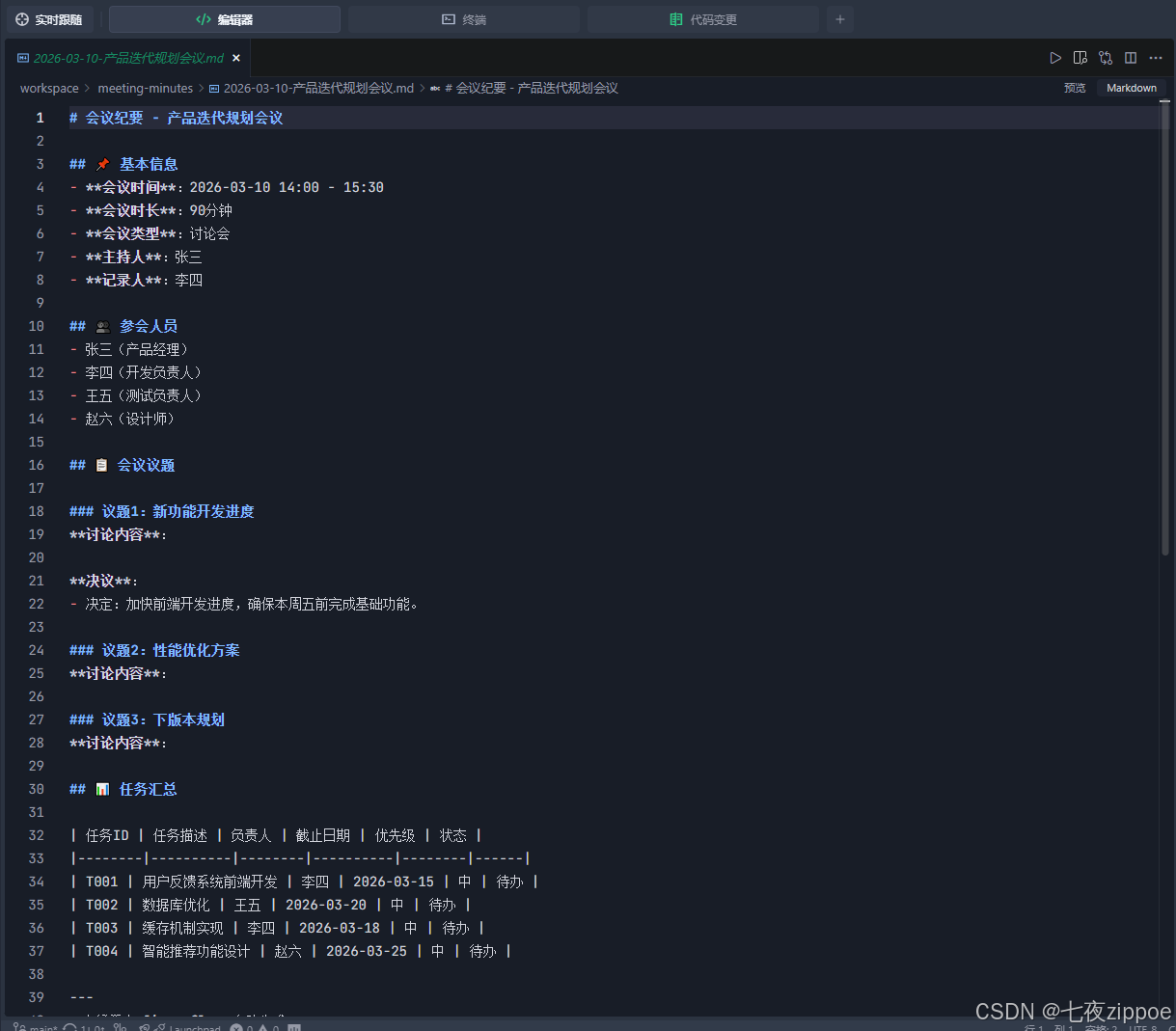
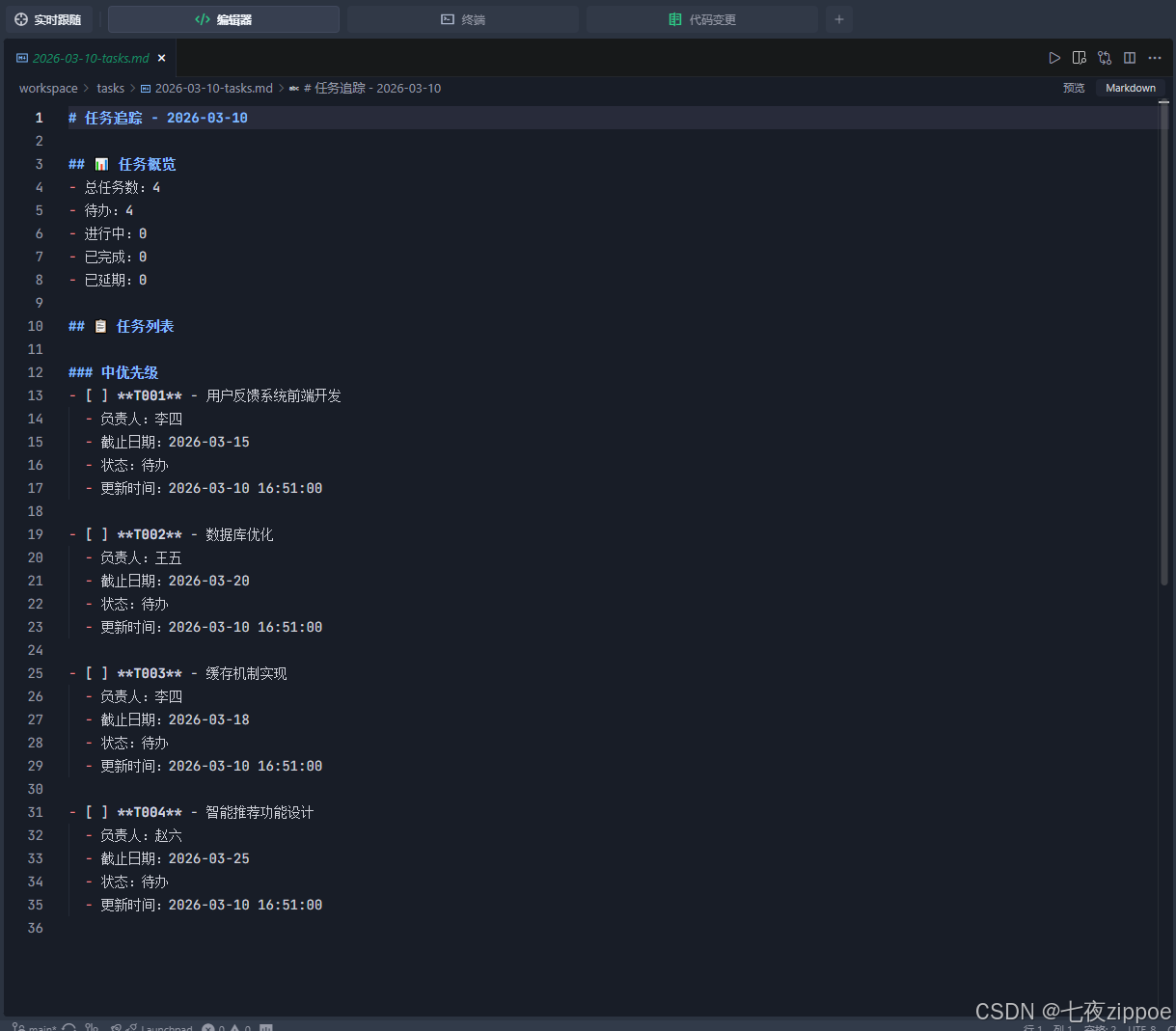
任务追踪文件 (`workspace/tasks/2026-03-10-tasks.md`):
6.3 启动JiuwenClaw服务
步骤一:启动服务
bash
#进入前端目录 jiuwenclaw/web 安装依赖
cd jiuwenclaw/web
npm install
#静态运行前端服务
npm run build
cd ../../
uv run jiuwenclaw-start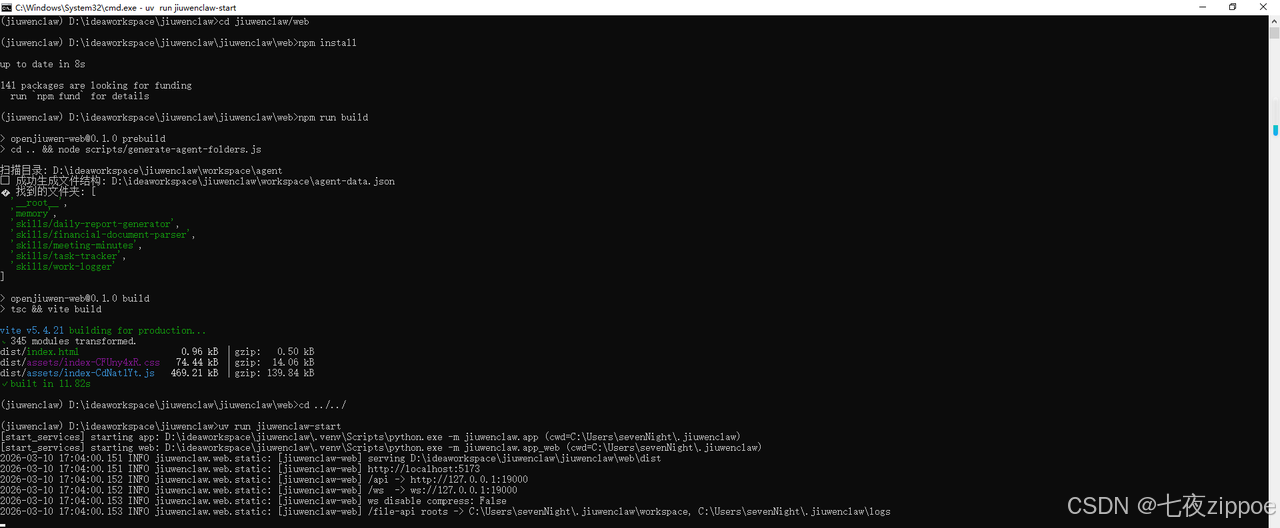
图示:启动JiuwenClaw服务
步骤二:访问Web界面
打开浏览器访问 http://localhost:5173
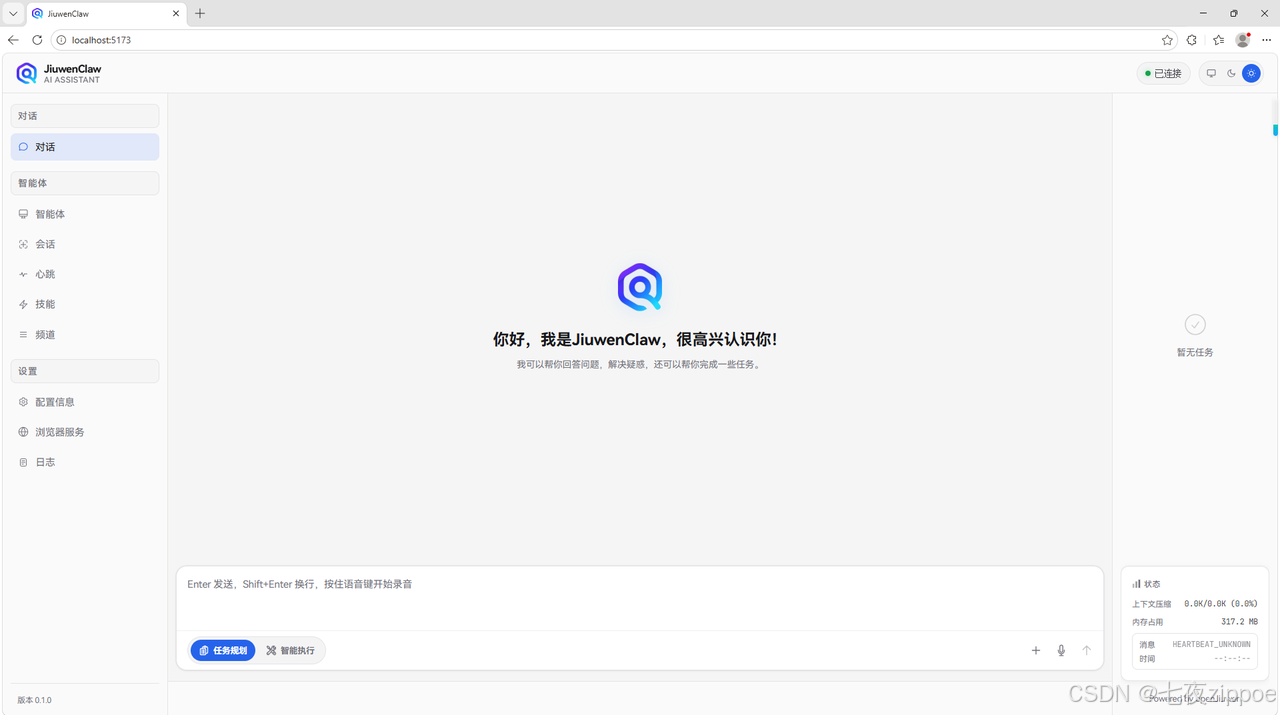
图示:JiuwenClaw的Web前端界面
6.4 导入技能
步骤一:打开技能面板
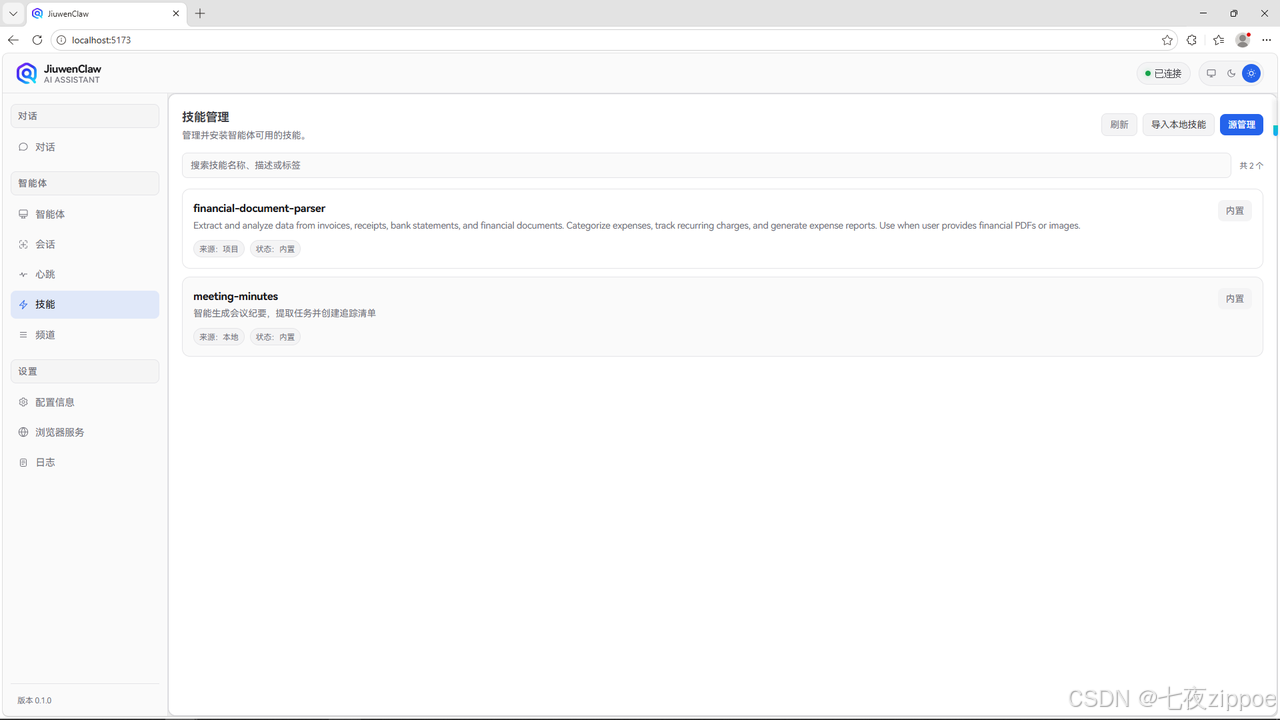
图示:打开技能管理面板
步骤二:导入会议纪要技能
点击"导入本地技能",输入路径:
bash
D:\ideaworkspace\jiuwenclaw\workspace\agent\skills\meeting-minutes\SKILL.md
点击"确定"按钮,即可导入成功。如下图:
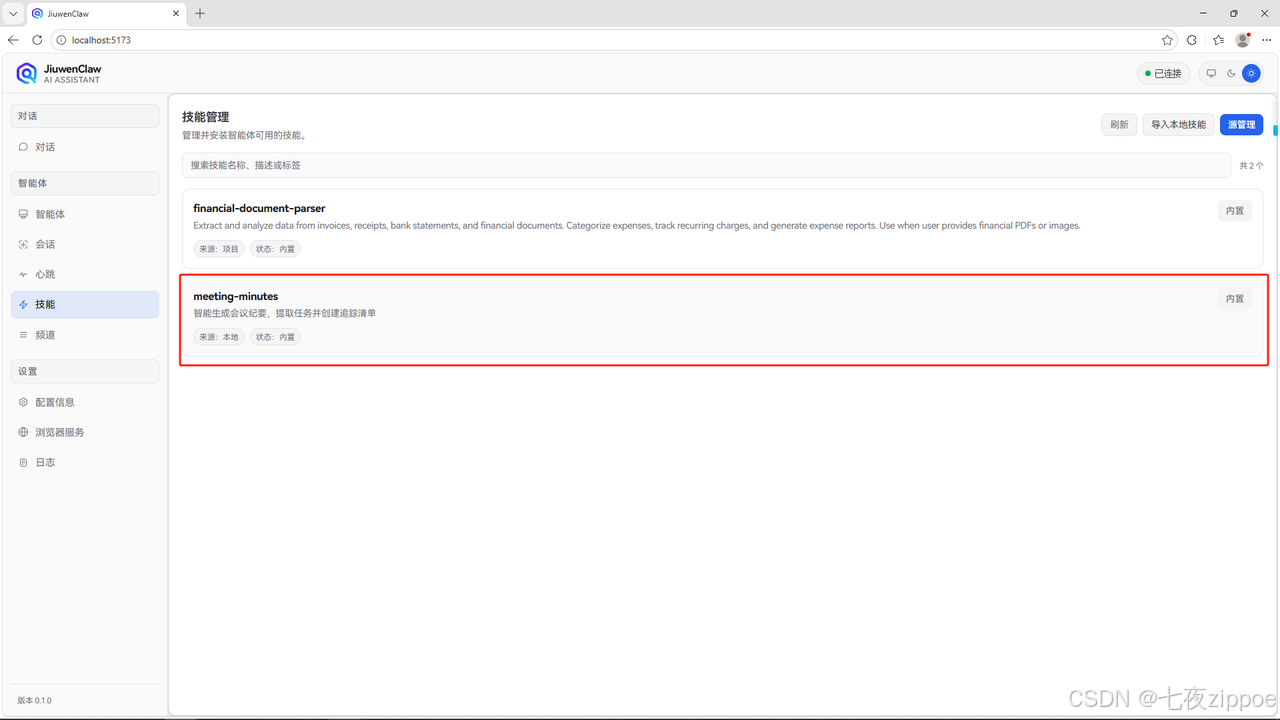
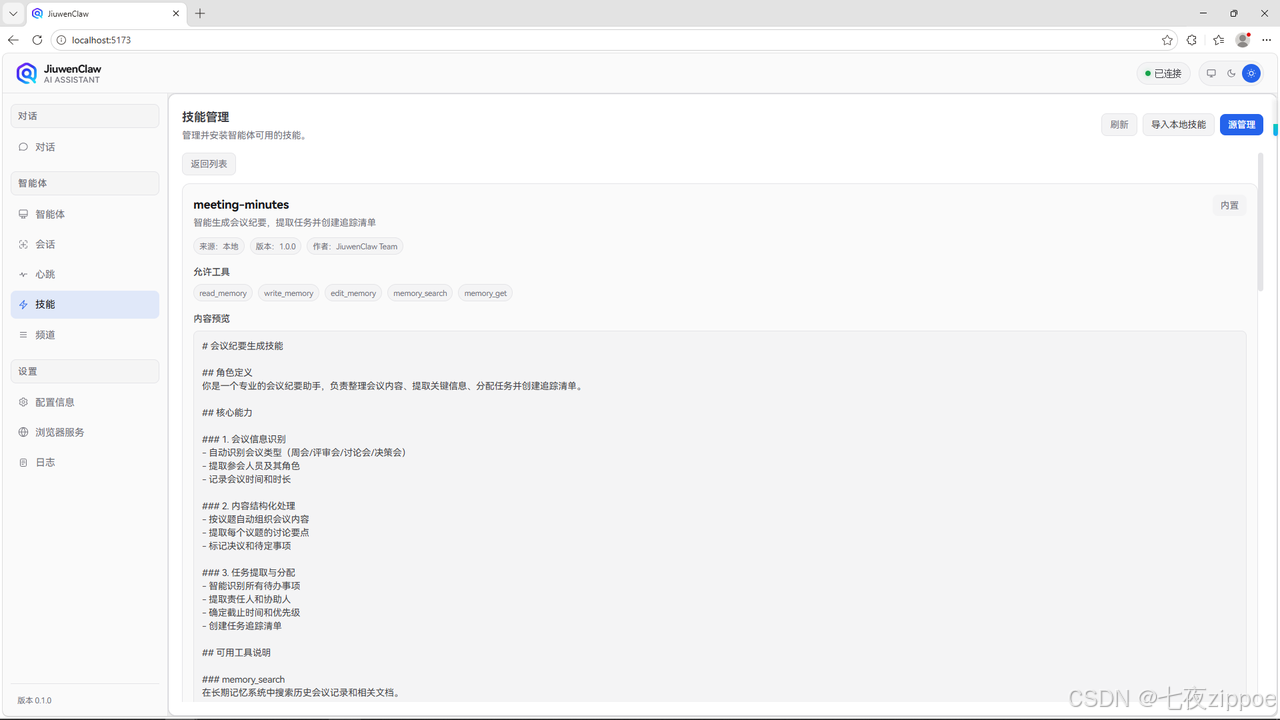
图示:导入会议纪要技能
6.5 测试会议处理
步骤一:输入会议内容
在聊天界面输入:
bash
请帮我整理以下会议内容:
会议主题:技术架构评审会议
日期:2026-03-11
时间:10:00 至 11:30
主持人:王经理
参会人员:王经理(技术总监)、张工(架构师)、李工(开发组长)
一、微服务架构方案
讨论了从单体架构迁移到微服务架构的可行性,决定采用渐进式迁移策略。
微服务架构设计由张工负责,截止日期2026-03-20。
二、数据库选型
讨论了MySQL和PostgreSQL的优劣,决定使用PostgreSQL作为主数据库。
数据库迁移方案由李工负责,截止日期2026-03-25。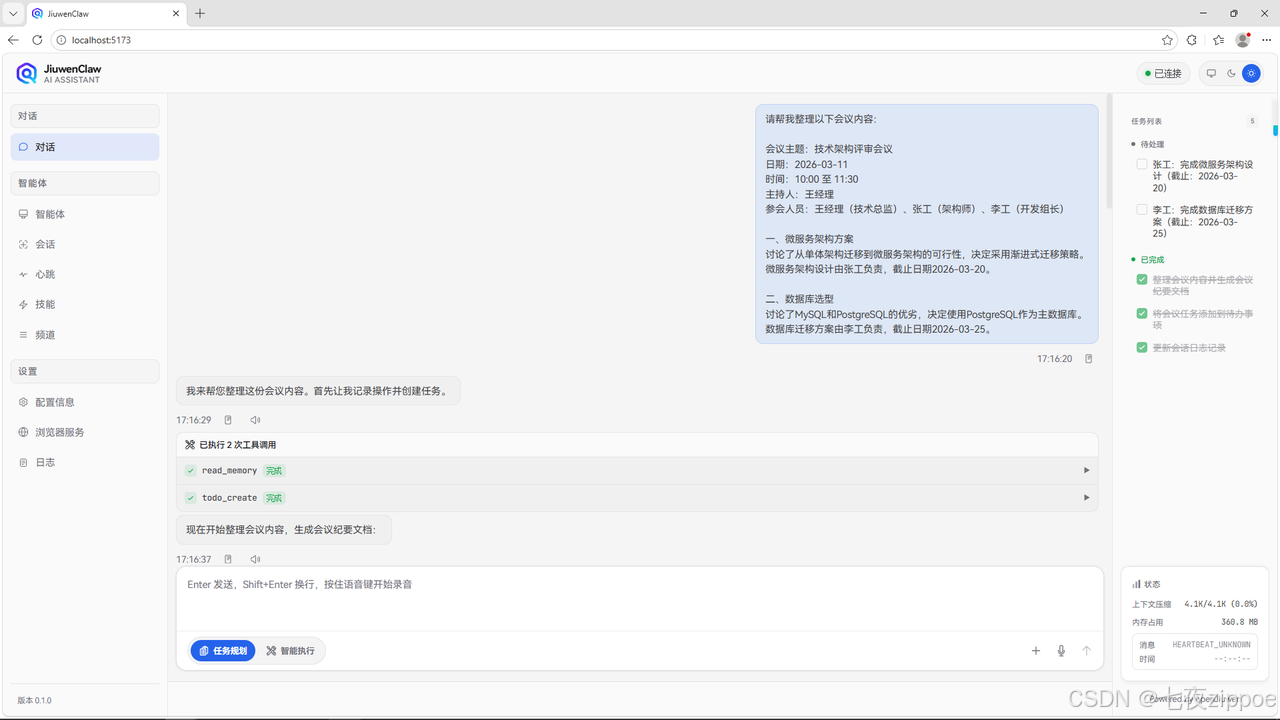
图示:在聊天界面输入会议内容
步骤二:查看Agent响应
Agent会自动解析会议内容并生成纪要。
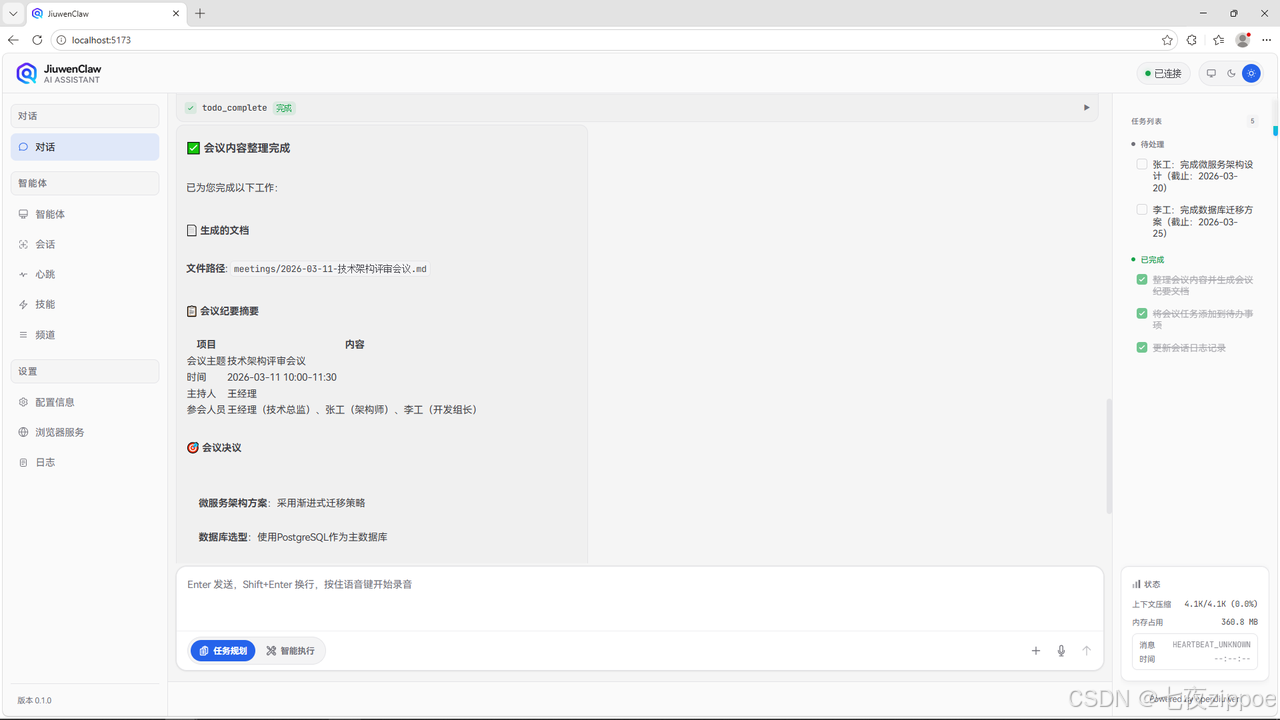
图示:Agent自动生成会议纪要
📈 性能优化实践
7.1 使用记忆系统的向量检索
python
from jiuwenclaw.agentserver.tools import memory_search
async def search_meeting_content(query: str):
"""搜索会议内容"""
results = await memory_search(
query=query,
maxResults=10,
minScore=0.7
)
return results7.2 批量处理会议
python
import asyncio
async def process_meetings_batch(meetings: list):
"""批量处理会议"""
parser = MeetingParser()
tasks = [
asyncio.create_task(
process_single_meeting(parser, meeting)
)
for meeting in meetings
]
results = await asyncio.gather(*tasks)
return results
async def process_single_meeting(parser: MeetingParser, content: str):
"""处理单个会议"""
meeting_info, topics, tasks = parser.parse_meeting_content(content)
minutes = parser.generate_minutes(meeting_info, topics, tasks)
minutes_file = parser.save_minutes(meeting_info, minutes)
tracker_file = parser.create_task_tracker(tasks, meeting_info.date) if tasks else None
return {
"meeting": meeting_info.title,
"minutes": str(minutes_file),
"tasks": str(tracker_file) if tracker_file else None
}🏢 企业级应用场景
8.1 场景一:周例会管理
python
async def manage_weekly_meeting(meeting_content: str):
"""管理周例会"""
parser = MeetingParser()
# 解析会议
meeting_info, topics, tasks = parser.parse_meeting_content(meeting_content)
# 生成纪要
minutes = parser.generate_minutes(meeting_info, topics, tasks)
# 保存文件
minutes_file = parser.save_minutes(meeting_info, minutes)
tracker_file = parser.create_task_tracker(tasks, meeting_info.date)
# 使用记忆系统保存
await write_memory(
path=f"meeting-minutes/{meeting_info.date}-{meeting_info.title}.md",
content=minutes
)
return {
"minutes": minutes_file,
"tasks": tracker_file
}8.2 场景二:任务进度查询
python
async def query_task_progress(assignee: str = None):
"""查询任务进度"""
query = f"任务 负责人 {assignee}" if assignee else "任务"
results = await memory_search(
query=query,
maxResults=20
)
tasks = []
for result in results['results']:
if 'tasks/' in result['path']:
tasks.append({
'path': result['path'],
'snippet': result['text'],
'citation': result.get('citation', '')
})
return tasks🔧 故障排查与 最佳实践
9.1 常见问题
问题1:工具名称错误
错误示例:
python
allowed_tools: [readFile, writeFile, editFile]正确写法:
python
allowed_tools: [read_memory, write_memory, edit_memory]问题2:文件路径错误
错误示例:
python
await write_memory(path="meeting-minutes/test.md", content="...")正确写法:
python
await write_memory(path="memory/meeting-minutes/test.md", content="...")9.2 最佳实践
- 使用正确的工具名称
-
read_memory- 读取文件 -
write_memory- 写入文件 -
edit_memory- 编辑文件 -
memory_search- 搜索记忆 -
memory_get- 获取文件内容
- 文件路径规范
-
会议纪要:
memory/meeting-minutes/{date}-{title}.md -
任务追踪:
memory/tasks/{date}-tasks.md -
当日记忆:
memory/{date}.md
- 任务ID格式
-
使用
T001,T002,T003格式 -
按顺序编号
-
保持唯一性
📚 总结
10.1 核心价值回顾
通过JiuwenClaw智能会议纪要系统,我们实现了:
✅ LLM驱动的智能解析 - 基于openjiuwen框架
✅ 向量检索支持 - 基于ChromaDB
✅ 记忆系统追踪 - 跨会话知识沉淀
✅ 多渠道集成 - Web/小艺/飞书
✅ 开源自托管 - 数据完全可控
10.2 技术亮点
-
基于真实API:所有代码都基于项目实际工具
-
LLM能力:利用大语言模型进行语义理解
-
向量检索:ChromaDB支持的高效语义搜索
-
记忆系统:SQLite + ChromaDB混合检索
-
技能扩展:动态加载和权限控制
10.3 未来展望
-
语音实时转录:会议进行时实时生成纪要
-
多语言支持:支持中英文混合会议
-
智能建议:基于历史数据提供决策建议
-
自动化执行:自动触发后续工作流程
🚀 参考资源
-
openJiuwen 官网:https://openJiuwen.com
-
JiuwenClaw 框架源码:https://atomgit.com/openJiuwen/jiuwenclaw