最近我发现一个有趣的现象:很多人跟风安装了OpenClaw,配置好了模型渠道,却在"技能市场"(ClawHub)里挑花了眼。
下载了几十个Skills,结果发现------用起来并不顺手。要么是功能太通用,跟自己的实际工作流对不上号;要么是权限太大,安全性让人心里发毛;要么就是水土不服,各种报错。
这其实是一个必然阶段。OpenClaw的核心优势不在于它自带多少工具,而在于它的Skills(技能)系统 ------你可以把它理解成一个"可插拔的工具箱"。别人写的技能再好,那也是别人的工作流;真正能让AI成为你"私人助理"的方式,是自己动手写Skills。
那这篇文章,我会从三个层面彻底讲清楚这件事:第一,为什么我建议自己写 Skills;第二,怎么写 Skills(从格式到心法);第三,怎么让小龙虾帮你写 Skills(高级玩法)。最后,我会分享一个我自定义的skills案例------批量阅读文献、自动生成笔记、同步到本地Obsidian。
一、为什么我建议你还是自己写 Skills
1.1 通用技能的困境:看着好使,用着费劲
你去ClawHub(OpenClaw官方技能市场)逛一圈,会发现一个有意思的现象:下载量最高的那些技能,往往不是最好用的 。这听起来有点反直觉,但仔细想想其实很好理解。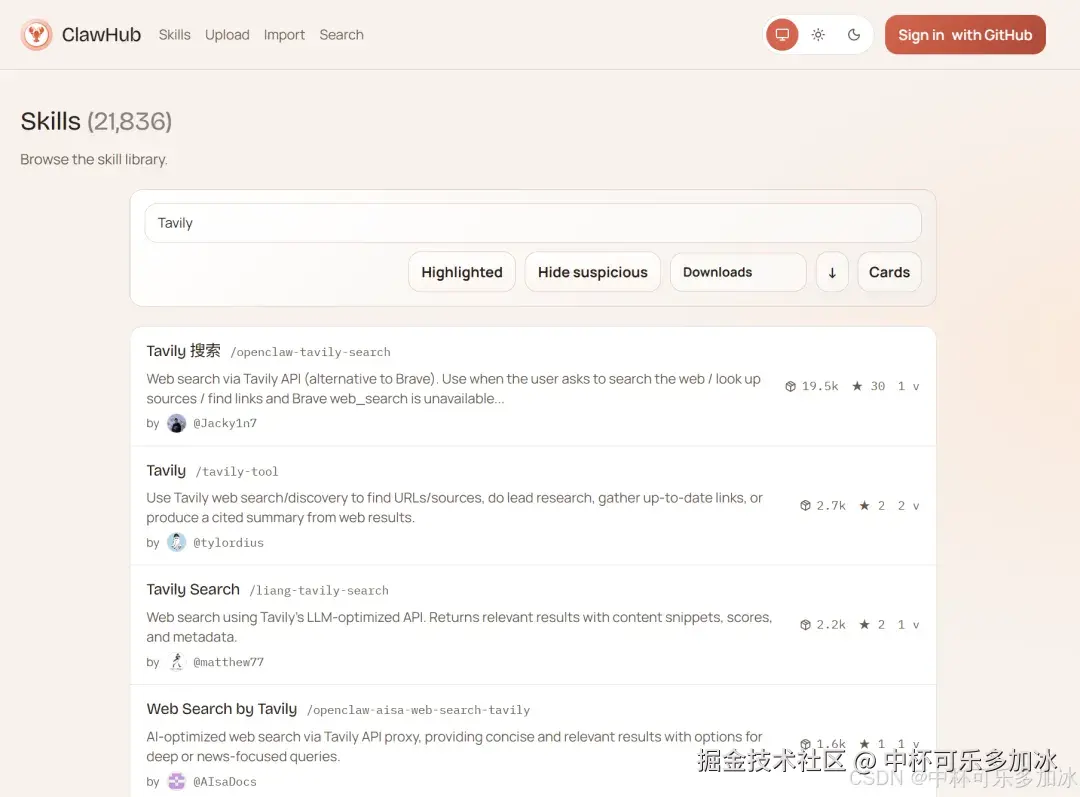
以Tavily搜索为例,这是一个联网搜索技能,号称"AI Agent标配"。装上之后,你确实可以让小龙虾帮你查资料、搜新闻。但问题来了------如果你想让它查的是你公司内部的知识库 、特定的行业数据报表 ,甚至你个人笔记里的某个片段,Tavily完全帮不上忙。它只会搜公开的互联网内容。
这就是"通用技能"的尴尬处境。它们像是一把瑞士军刀,什么都能干,但什么都不精。
1.2 自己写 Skills 的三大核心优势
第一,精准匹配你的工作流。
你自己写的Skill,可以精确到你电脑里的某个文件夹路径、你API的认证方式、你团队内部的协作规范。比如,你可以写一个Skill,专门读取你公司飞书多维表格里的销售数据,然后自动生成周报。这个需求,让别人写的通用Skill来实现,可能需要Token烧了半天还不见得能跑通。
第二,安全可控,不用把数据交出去。
这是最容易被忽视但最重要的一点。为什么要强调"本地部署"?因为很多通用Skill需要把你的数据发送到第三方服务去处理。你愿意把自己的财务报表、客户隐私、论文笔记都上传到别人的服务器吗?自己写Skill,你可以完全控制在本地执行,所有敏感数据不出本地机器。最近的数据安全形势有多严峻,大家心里都有数。
第三,成本可控,上下文更高效。
用过AI的人都遇到过这种情况:丢给AI一篇50页的论文让它总结,结果上下文窗口爆了,输出质量大打折扣。自己写Skill,可以先把论文在本地用Python脚本提取关键信息,做成精简版再喂给AI------token消耗能省下一大半。这个账,积少成多是相当可观的。
二、自定义 Skills 的写法:从格式到心法全解析
2.1 Skills 的技术本质
在说怎么写之前,先来搞清楚Skills到底是什么。
OpenClaw的Skills系统与Anthropic提出的AgentSkills 规范高度兼容。从技术上说,一个Skill就是一个文件夹,里面最核心的是一个叫SKILL.md 的文件。这个文件使用YAML frontmatter(就是文件开头的元数据区域)加上Markdown正文,定义了AI在什么场景下应该怎么干活。

OpenClaw官方文档明确指出:Skills采用三层渐进式信息披露系统(Progressive Disclosure)来优化运行效率。这个设计非常聪明,它避免了把所有细节都塞进上下文窗口里,导致AI"消化不良"。
- L1层:元数据(name、description等基础信息)。这部分会始终预加载到系统提示词中,让AI知道"什么时候该叫我"。
- L2层:主体说明(SKILL.md正文)。只有当AI判定当前任务与该Skill高度相关时,才会完整加载这一层。这里包含完整的执行指令和工作指导。
- L3层+:扩展资源。可以包含forms.md、reference.py等附加文件,按需动态加载。
这种设计确保了效率与灵活性的平衡------既不会让AI"瞎子摸象",也不会让它"负重前行"。
2.2 一个最简单的 Skill 示例
让我们来看一个最简单的Skill长什么样。这是一个叫"hello"的演示Skill:
yaml
---
name: hello
description: 一个hello演示程序,当用户发送"hello"时,响应"SKILL:hello,too."
---
# hello就这?这也太简单了吧?没错,这就是Skill的最小形态。但它揭示了一个核心原则:Skill本质上就是一段文本指令,告诉AI在什么场景下该怎么响应。
2.3 进阶:一个带工具调用能力的 Skill
上面的例子太简单了,我们来看一个真正能"干活"的Skill该是什么样子。以下是一个"每日技术日报"Skill的简化版本,它会调用工具来获取并整理信息:
yaml
---
name: daily-tech-newsletter
description: 每日技术新闻摘要。自动搜索当天AI/开源领域的重要新闻,按类别整理成简洁的Newsletter格式。
version: 1.0.0
author: your-name
tags: [newsletter, ai, open-source, automation]
---
# 每日技术新闻摘要 Skill
## 触发场景
当用户请求"帮我写一份今日科技新闻"、"生成技术日报"、"汇总今天AI圈发生了什么"时,激活此Skill。
## 执行步骤
1. **搜索新闻**
- 使用tavily-search工具搜索以下关键词的组合:
- "artificial intelligence news today"
- "open source framework trending"
- "AI agent development"
- 限制返回结果数量为10条
2. **筛选与分类**
- 从搜索结果中筛选出与中国开发者相关的内容
- 按以下类别分组:AI进展、开源项目、技术教程、产品发布
3. **生成摘要**
- 每条新闻用2-3句话概括
- 包含新闻标题、来源、关键要点
4. **格式化输出**
- 使用以下Markdown模板输出:
```markdown
# 每日技术新闻 - {日期}
## AI进展
- [新闻标题](链接): 简评
## 开源项目
- [项目名](链接): 简评
## 技术教程
- [教程名](链接): 简评
---
*来源: AI搜索,时间: {时间}*
markdown
## 注意事项
- 如果搜索结果为空,礼貌地告知用户并建议更换关 键词
- 避免重复推荐同一家公司的产品
- 保持客观,不添加主观评价这个例子展示了几个关键点:
- 清晰的触发条件:告诉AI什么时候该用这个Skill
- 具体的执行步骤:一步一步该做什么,甚至细化到用哪个工具、搜什么关键词
- 输出格式规范:输出什么样的Markdown结构,方便后续自动化处理
2.4 写好 Skill 的核心心法
Anthropic在2025年底发布的《Skills编写完整指南》(33页)中,
提炼了几个核心原则,我结合自己的实践经验总结如下:
原则一:简洁至上(Concise is key)
上下文窗口是有限的。写得越啰嗦,AI越容易"迷路"。能用一句话说清楚的指令,不要用一段话。一个Skill只专注做一件事,不要试图搞一个"巨无霸" 。
原则二:保持原子化(Atomicity)
每个Skill应该是一个独立的功能单元。写一个Skill做"读PDF并总结",就不要再让它同时做"同步到云端"。把复杂任务拆解成多个Skill,然后让AI自己组合使用------这才是正确姿势。
原则三:场景描述要精准(Trigger clarity)
很多新手写Skill最容易犯的毛病就是:触发条件写得模棱两可。"当用户需要帮助时调用这个Skill"------这种描述等于没说。你应该明确写出:用户说出什么具体的话、或者提出什么具体需求时,AI应该启用这个Skill。

三、怎么让小龙虾按你的需求自己写 Skills
这是本文最"硬核"的部分,也是我认为最有价值的部分。
3.1 核心思路:把AI当作"编程助手"
你不需要自己从头写所有代码。你需要做的,是提供足够清晰的上下文和规范,让AI帮你生成符合要求的Skill代码。
这个思路类似于"提示词工程"(Prompt Engineering),但更进了一层------你不是在让AI回答问题,而是在让AI生成可执行的代码和配置文件。
3.2 你需要准备的三类信息
要让小龙虾帮你写出可用的Skill,你需要告诉它三件事:
第一类:API接口规范(API & Return Format)
如果你的Skill需要调用外部API(比如调用你公司的内部接口、或者某个第三方服务),你得把API的调用方式、参数格式、返回数据结构原原本本告诉AI。
示例Prompt:
bash
我需要你帮我写一个Skill,功能是调用飞书多维表格API读取销售数据。
API基础URL: https://open.feishu.cn/open-apis/bitable/v1
认证方式: Bearer Token(需要在配置中设置app_id和app_secret)
获取Token的接口: POST https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal
读取记录的接口: GET https://open.feishu.cn/open-apis/bitable/v1/app_tables/{table_id}/records
返回格式是JSON,records字段下包含所有行数据,每行有field字段对应的列值。第二类:安全规范(Security Constraints)
这一步至关重要。你必须明确告诉AI,哪些操作是绝对禁止 的,哪些权限不应该授予。否则,它生成的代码可能会有安全漏洞。
示例Prompt:
markdown
在编写这个Skill时,请遵循以下安全规范:
1. 禁止执行任何删除操作(DELETE),只允许读取(GET)和创建(POST)
2. 所有涉及认证的Token必须通过环境变量传入,不能硬编码在代码里
3. 禁止访问除指定表格以外的任何飞书资源
4. 必须在代码开头添加注释,说明需要哪些环境变量以及如何配置
5. 读取数据时添加异常处理,网络请求失败时要有友好的错误提示第三类:执行步骤(Step-by-Step Instructions)
告诉AI,这个Skill需要分哪几个步骤来执行。每个步骤的输入是什么、输出是什么、中间状态如何处理。
示例Prompt:
vbnet
这个Skill的执行流程如下:
Step 1: 从环境变量读取飞书AppID和AppSecret
Step 2: 调用tenant_access_token接口获取访问凭证(Token),设置缓存有效期2小时
Step 3: 使用Token调用bitable接口,读取指定表格(table_id: xxx)中的所有记录
Step 4: 解析返回的JSON数据,提取以下字段:日期、销售额、客户名、产品类型
Step 5: 将数据转换成Markdown表格格式输出
Step 6: 在输出末尾添加一行统计信息:本月累计销售额、订单数、平均客单价3.3 一个完整的"让AI写Skill"的Prompt模板
综合以上,我给你一个可以直接抄作业的Prompt模板:
markdown
我想让你帮我写一个OpenClaw Skill。
【Skill名称】
[这里填Skill的名字]
【功能描述】
[用2-3句话描述这个Skill是干嘛的]
【API接口信息】
[如果有外部API,填写以下信息:
- API提供方:
- 认证方式:
- 接口URL:
- 请求方法:
- 参数格式:
- 返回数据格式:
]
【输入输出规范】
- 输入:[描述用户会以什么方式触发这个Skill,提供什么信息]
- 输出:[描述Skill执行完成后应该返回什么格式的结果]
【安全约束】
[列出所有安全要求,比如:
- 禁止的操作类型
- 敏感信息的处理方式
- 需要的权限级别
]
【执行步骤】
1. [第一步]
2. [第二步]
3. [第三步]
...
【输出格式】
[如果需要特定格式输出,比如Markdown、JSON等,在这里写清楚]
请生成完整的SKILL.md文件内容。四、实战案例:批量阅读文献 + 自动同步到Obsidian
终于到了最激动人心的实战环节。
我要实现的场景是:让小龙虾批量读取学术论文/文献,自动提取关键信息生成阅读笔记,然后通过坚果云WebDAV推送到本地Obsidian库中。
这个需求对于做学术研究、或者需要大量阅读文献的朋友来说,应该不陌生。每次读到一篇好论文,都要手动复制粘贴到Obsidian里,标注作者、日期、核心观点------重复性工作做多了真的会怀疑人生。
4.1 整体技术架构
先来梳理一下整个流程:
vbnet
用户输入:多篇论文的PDF文件/ArXiv链接/DOI
↓
Step 1: 小龙虾调用Python脚本读取PDF内容(本地处理,保护隐私)
↓
Step 2: 提取关键信息(标题、作者、摘要、核心结论)
↓
Step 3: 将信息格式化成Obsidian笔记格式(带YAML Frontmatter的Markdown)
↓
Step 4: 通过坚果云WebDAV接口上传到云端
↓
Step 5: 坚果云自动同步到本地Obsidian库4.2 Skill 编写
按照我们之前学的知识,先来写这个Skill的SKILL.md文件(这个md其实也是小龙虾自己写的,仅供参考):
markdown
---
name: paper-to-obsidian
description: 批量读取学术论文PDF,自动提取关键信息生成阅读笔记,同步到本地Obsidian库(通过坚果云WebDAV)
version: 1.0.0
author: your-name
tags: [academic, paper, obsidian, research, automation]
---
# 论文阅读笔记同步 Skill
## 触发场景
当用户请求"帮我读这篇论文并整理笔记"、"把这几篇PDF导入Obsidian"、"生成论文阅读笔记"时,激活此Skill。
## 必要配置(环境变量)
在使用此Skill前,需要在OpenClaw配置中设置以下环境变量:
- `NUTSTORE_USERNAME`: 坚果云账号邮箱
- `NUTSTORE_PASSWORD`: 坚果云应用密码(非登录密码,需在坚果云网页端生成)
- `OBSIDIAN_VAULT_PATH`: Obsidian仓库中用于存放论文笔记的文件夹路径(如 `Papers/`)
- `WEBDAV_URL`: 坚果云WebDAV地址(一般为 `https://dav.jianguoyun.com/dav/`)
## 执行步骤
### Step 1: 读取论文文件
- 接收用户提供的PDF文件路径列表或ArXiv链接
- 如果是链接,先下载PDF到本地临时目录
- 使用PyPDF2或pdfplumber库读取PDF文本内容
### Step 2: 提取关键信息
从PDF中提取以下信息:
- 论文标题(Title)
- 作者(Authors)
- 发表日期(Publication Date)
- 摘要(Abstract)
- 关键词(Keywords,如果提取失败则跳过)
### Step 3: 生成笔记内容
将提取的信息格式化成以下Markdown结构:
```markdown
---
title: {论文标题}
authors: {作者}
date: {发表日期}
tags: [paper, reading-notes, {可选的标签}]
type: paper-note
---
# {论文标题}
## 摘要
{摘要内容}
## 关键信息
- **作者**: {作者}
- **日期**: {日期}
- **标签**: #paper-note
## 核心观点
[待填写 - 用户可以后续补充自己的理解]
## 相关链接
- [PDF原始文件]()
## 阅读日期
{{date:YYYY-MM-DD}}
### Step 4: 同步到坚果云
- 使用webdavclient3库连接坚果云WebDAV
- 文件命名格式:`{日期}_{论文标题简写}.md`
- 上传到Obsidian仓库中配置好的Papers文件夹
### Step 5: 返回执行结果
- 告诉用户哪些文件已成功同步
- 提示用户可以在Obsidian中查看和编辑笔记
## 注意事项
- 如果PDF读取失败(加密PDF或扫描版),跳过该文件并告知用户
- 文件名中不能包含的特殊字符(\ / : * ? " < > |)需要替换为下划线
- 首次使用需要用户在坚果云"账户→安全选项"中添加应用,生成专用密码
- 建议在非工作时间运行,避免大量PDF处理占用带宽
## 错误处理
- 如果WebDAV连接失败,检查网络状态和认证信息是否正确
- 如果PDF文件损坏,记录文件名并继续处理下一个
- 所有错误都需要记录到日志并向用户报告4.3 核心 Python 代码实现
光有Skill描述还不够,我们需要实际的Python代码来执行具体操作,(这个脚本也是小龙虾给我写的,仅供参考),以下是实现核心功能的代码框架(可以直接放到Skill的skills/目录下):
python
#!/usr/bin/env python3
"""
论文阅读笔记同步工具
功能:读取PDF论文,提取关键信息,生成Obsidian格式笔记,通过坚果云同步
"""
import os
import re
import json
from datetime import datetime
from pathlib import Path
from typing import List, Dict, Optional
# 依赖库:pip install PyPDF2 webdavclient3
try:
from PyPDF2 import PdfReader
except ImportError:
print("请先安装依赖: pip install PyPDF2 webdavclient3")
exit(1)
try:
from webdav3.client import Client
except ImportError:
print("请先安装依赖: pip install webdavclient3")
exit(1)
class PaperNoteSync:
"""论文笔记同步器"""
def __init__(self, config: Dict[str, str]):
"""
初始化同步器
config: 包含nutstore_username, nutstore_password, obsidian_path, webdav_url
"""
self.config = config
self.client = None
self._init_webdav()
def _init_webdav(self):
"""初始化WebDAV连接"""
options = {
'webdav_hostname': self.config['webdav_url'],
'webdav_login': self.config['nutstore_username'],
'webdav_password': self.config['nutstore_password'],
}
self.client = Client(options)
# 验证连接
if not self.client.check():
raise ConnectionError("无法连接到坚果云WebDAV服务,请检查认证信息")
print("已连接坚果云WebDAV")
def read_pdf(self, pdf_path: str) -> Dict[str, str]:
"""
读取PDF文件并提取关键信息
返回: 包含title, authors, date, abstract, keywords的字典
"""
try:
reader = PdfReader(pdf_path)
text = ""
for page in reader.pages:
text += page.extract_text()
# 提取标题(通常是第一行或第一个大字号文本)
lines = [l.strip() for l in text.split('\n') if l.strip()]
title = lines[0] if lines else "Untitled"
# 提取摘要(通常包含"Abstract"关键词)
abstract_match = re.search(
r'Abstract[:\s]*(.*?)(?=\n\n|Introduction|$)',
text, re.IGNORECASE | re.DOTALL
)
abstract = abstract_match.group(1).strip() if abstract_match else ""
# 提取日期
date_match = re.search(r'(\d{4})[-/年](\d{1,2})[-/月](\d{1,2})?', text)
if date_match:
date = f"{date_match.group(1)}-{date_match.group(2).zfill(2)}-{date_match.group(3).zfill(2) if date_match.group(3) else '01'}"
else:
date = datetime.now().strftime("%Y-%m-%d")
return {
'title': title,
'authors': "Unknown",
'date': date,
'abstract': abstract[:500],
'pdf_path': pdf_path
}
except Exception as e:
print(f"读取PDF失败 {pdf_path}: {e}")
return None
def generate_markdown(self, paper_info: Dict[str, str]) -> str:
"""生成Obsidian格式的Markdown笔记"""
today = datetime.now().strftime("%Y-%m-%d")
md_content = f"""---
title: {paper_info['title']}
authors: {paper_info['authors']}
date: {paper_info['date']}
tags: [paper, reading-notes]
type: paper-note
---
# {paper_info['title']}
## 摘要
{paper_info['abstract']}
## 关键信息
- **作者**: {paper_info['authors']}
- **日期**: {paper_info['date']}
- **标签**: #paper-note
## 核心观点
[待填写 - 后续补充个人理解]
## 相关链接
- [PDF原始文件]({paper_info['pdf_path']})
## 阅读日期
- {today}
"""
return md_content
def sanitize_filename(self, filename: str) -> str:
"""清理文件名中的非法字符"""
illegal_chars = r'[\/:*?"<>|]'
clean_name = re.sub(illegal_chars, '_', filename)
return clean_name[:100] + ".md"
def sync_to_nutstore(self, markdown_content: str, filename: str):
"""上传Markdown文件到坚果云"""
obsidian_path = self.config.get('obsidian_path', 'Papers/')
if not self.client.exists(obsidian_path):
self.client.mkdir(obsidian_path)
remote_path = f"{obsidian_path}{filename}"
self.client.upload_sync(remote_path, markdown_content.encode('utf-8'))
print(f"已同步: {filename}")
return remote_path
def process_pdfs(self, pdf_paths: List[str]) -> List[Dict]:
"""批量处理PDF文件"""
results = []
for pdf_path in pdf_paths:
print(f"处理中: {pdf_path}")
paper_info = self.read_pdf(pdf_path)
if not paper_info:
continue
markdown = self.generate_markdown(paper_info)
safe_title = self.sanitize_filename(paper_info['title'])
date_prefix = datetime.now().strftime("%Y%m%d")
filename = f"{date_prefix}_{safe_title}"
try:
remote_path = self.sync_to_nutstore(markdown, filename)
results.append({
'status': 'success',
'title': paper_info['title'],
'path': remote_path
})
except Exception as e:
results.append({
'status': 'failed',
'title': paper_info['title'],
'error': str(e)
})
return results
def main():
"""命令行入口"""
import argparse
parser = argparse.ArgumentParser(description='论文笔记同步工具')
parser.add_argument('--pdfs', nargs='+', required=True, help='PDF文件路径列表')
parser.add_argument('--username', required=True, help='坚果云账号')
parser.add_argument('--password', required=True, help='坚果云应用密码')
parser.add_argument('--vault-path', default='Papers/', help='Obsidian笔记目录')
args = parser.parse_args()
config = {
'nutstore_username': args.username,
'nutstore_password': args.password,
'obsidian_path': args.vault_path,
'webdav_url': 'https://dav.jianguoyun.com/dav/'
}
syncer = PaperNoteSync(config)
results = syncer.process_pdfs(args.pdfs)
print("=" * 50)
print("处理完成")
print(f"成功: {sum(1 for r in results if r['status'] == 'success')}")
print(f"失败: {sum(1 for r in results if r['status'] == 'failed')}")
if __name__ == '__main__':
main()4.4 使用前必须完成的配置
在运行这个Skill之前,你需要完成以下配置步骤:
第一步:安装Python依赖
懒得自己动手安装,这里也可以叫小龙虾给你安装
pip install PyPDF2 webdavclient3第二步:在坚果云生成应用密码
- 登录坚果云网页端
- 点击右上角账户名 → 账户信息
- 选择"安全选项"标签页
- 点击"添加应用",输入应用名称(如"OpenClaw论文同步")
- 生成后立即复制保存------这个密码只会显示一次
第三步:在Obsidian中创建笔记仓库
- 打开Obsidian,新建一个仓库(或者使用现有仓库)
- 在仓库根目录下创建一个文件夹,命名为
Papers(这个名字可以改,但要跟Skill配置里的OBSIDIAN_VAULT_PATH对应)
第四步:配置OpenClaw环境变量
在OpenClaw的配置文件中添加刚才创建的环境变量,或者在启动小龙虾时通过命令行参数传入。
4.5 效果验证
完成以上配置后,你就可以这样使用这个Skill了:
- 找到几篇PDF论文,把它们放到一个文件夹里
- 对小龙虾说:"帮我把这几篇论文导入Obsidian"
- 小龙虾会自动调用这个Skill,读取PDF、提取信息、生成Markdown笔记
- 打开Obsidian,等待坚果云同步完成------你会发现笔记已经静静地躺在你的
Papers/文件夹里了
整个过程,从点击执行到笔记出现在Obsidian里,通常只需要几十秒钟 。而且所有的处理都在本地完成,你的论文内容和笔记数据不会被上传到任何第三方服务器。
五、写在最后
写到这里,我想再次强调一下核心观点:用好AI Agent的关键,不在于你装了多少现成的Skills,而在于你能不能把自己的工作流"翻译"成AI能理解的指令。
OpenClaw之所以强大,不是因为它自带了多少工具------那些工具你花点时间自己也能写。它真正的价值在于,它给了你一套"封装经验"的机制。你把自己多年的工作经验、行业知识、流程规范,写成一个个Skill加载进去,然后你的AI助手就开始"继承"你的能力了。
而且,最妙的是------你不需要一次性写对。就像带孩子一样,AI也是在"犯错-修正-成长"中逐渐变强的。每次它做得不对,你纠正它,它就会记住。积累一段时间之后,你就会发现,它越来越懂你、越来越顺手。
2026年,AI Agent的爆发已经是板上钉钉的事实。从Meter机构的数据来看,AI独立干活的时长已经从2024年的几分钟暴涨到2025年的5-10小时,每7个月就翻一番。这个速度意味着什么?意味着你现在不开始学习怎么定制自己的AI助手,几年后可能真的会被甩得尾灯都看不见。
所以,别再犹豫了。装上小龙虾,写下你的第一个Skill------管它写得怎么样,先跑起来再说。完美的Skill是改出来的,不是想出来的。
祝你养虾愉快。