前情
上一篇 讲了Langchain使用 Tool 的基本方法。今天就用一个实际小案例来回顾和巩固下Tool的使用。
需求背景
我们现在实现一个这样的需求:向大模型查询某个地区的天气,返回包括天气情况、温度、体感温度等信息。可以实现:
- 基础单个城市的天气查询
- 多个城市天气的比较查询
- 可以查询天气相关的衍生问题(🌰今天去天安门需要带伞吗?)
- 支持多轮对话
核心技术
- LLM模型技术
- Langchain Tool
- InMemorySaver记忆构建
- 公共免费的天气查询接口
项目代码
天气查询接口
- 入参:字符串,🌰:"北京"
- 出参:字典,天气相关信息
- 📢注意:实际生产环境中务必使用专用API_key,而不是公共
python
# ---------- 1. 核心天气查询工具 ----------
def get_weather_simple(city: str) -> dict:
"""
【演示用途】一个不依赖API Key的简易天气查询函数。
核心脆弱性:完全依赖于一个第三方、可随时变更或失效的公开端点。
Returns:
dict: 包含天气信息或错误的字典。
"""
# 示例使用一个理论上存在的公共API(此URL仅为示例格式,可能无效)
url = f"http://wttr.in/{city}?format=j1"
try:
# 明确设置用户代理,并设置短超时
headers = {'User-Agent': 'Mozilla/5.0 (Demo Weather Client)'}
resp = requests.get(url, headers=headers, timeout=5)
resp.raise_for_status()
data = resp.json()
# 深度解析依赖API返回结构,这里是一个假设的路径
current = data.get('current_condition', [{}])[0]
return {
'city': city,
'temp_C': current.get('temp_C'),
'temp_feels':current.get('FeelsLikeC'),
'weather': current.get('weatherDesc', [{}])[0].get('value'),
'humidity':current.get('humidity'),
'pressure':current.get('pressure'),
'source': 'wttr.in',
'last_update': datetime.now().strftime('%H:%M')
}
except Exception as e:
# 任何异常都返回一个友好的错误信息
return {
'city': city,
'error': True,
'message': f'无法获取天气。服务可能不稳定或已变更。技术信息: {type(e).__name__}'
}工具定义
WeatherTool
接着就可以构建工具,用于连接外部世界与LLM。
- _run:核心是将
get_weather_simple返回的信息转换为LLM需要的格式。
python
class WeatherTool(BaseTool):
"""天气查询工具的LangChain标准化封装"""
name: str = "get_weather"
description: str = "查询指定城市的实时天气信息,包括温度、天气状况和湿度。"
args_schema: Type[BaseModel] = WeatherQueryInput
def _run(self, city:str) -> str:
"""工具的核心执行逻辑,返回字符串结果供Agent读取"""
weather_result = get_weather_simple(city)
if weather_result.get('error'):
return f"无法获取{city}的天气:{weather_result['message']}"
return (
f"{weather_result['city']}的天气:{weather_result['weather']},"
f"温度:{weather_result['temp_C']}°C,"
f"体感温度:{weather_result['temp_feels']}°C,"
f"湿度:{weather_result['humidity']}%,"
f"大气压:{weather_result['pressure']}%,"
f"(数据来源:{weather_result['source']},更新时间:{weather_result['last_update']})"
)
def _arun(self, *args: Any, **kwargs: Any) -> Any:
raise NotImplementedError("此工具暂不支持异步调用。")WeatherQueryInput
- Field():定义入参的限制,为入参提供一份更工程化的描述
- 当大模型决定调用该工具并生成一个参数JSON(如
{"city": "北京"})后,Pydantic模型会自动进行:- 类型校验 :确保
city是字符串。 - 数据解析 :将原始JSON转换为一个
WeatherQueryInput类的实例对象。 - 错误处理:如果参数缺失或类型错误,会在工具被调用前就抛出清晰的异常,阻止无效调用,而不是将错误参数传给底层API导致更隐晦的错误。
- 类型校验 :确保
python
class WeatherQueryInput(BaseModel):
"""天气查询的输入参数模式"""
city: str = Field(description="要查询天气的城市名称,例如北京、Shanghai")Agent组装
- InMemorySaver:实现单会话的短期记忆
- checkpointer:必须配置 {"configurable": {"thread_id": "user_1"}} 表示会话唯一标识
ini
# ---------- 3. Agent组装与执行 ----------
def create_weather_agent():
"""
创建并返回一个具备天气查询能力的Agent执行器
"""
# 获取模型
model = get_lc_model_client()
# model = get_ali_model_client()
# 创建工具列表
tools = [WeatherTool()]
# 使用ReAct提示模板,让Agent具备"思考-行动"的推理能力
system_prompt = "你是人工智能助手。需要帮助用户解决各种问题。"
# 创建短期记忆实例
# 短期记忆构建:智能体中使用InMemorySaver()实现单会话的短期记忆
memory = InMemorySaver()
# 大模型客户端绑定工具
# 创建Agent
agent = create_agent(
model=model, # 聊天模型
tools=tools, # 工具列表
system_prompt=system_prompt,
checkpointer=memory # 传入记忆组件
)
return agent使用
ini
# 1. 创建Agent
weather_agent = create_weather_agent()基础查询
ini
# 2. 调用示例
print("----------" + "示例1" + "----------")
result = weather_agent.invoke(
input={"messages": [{"role": "user", "content": "北京的天气怎么样"}]},
config={"configurable": {"thread_id": "user_1"}} # 会话唯一标识,用于区分不同用户
)
print(result)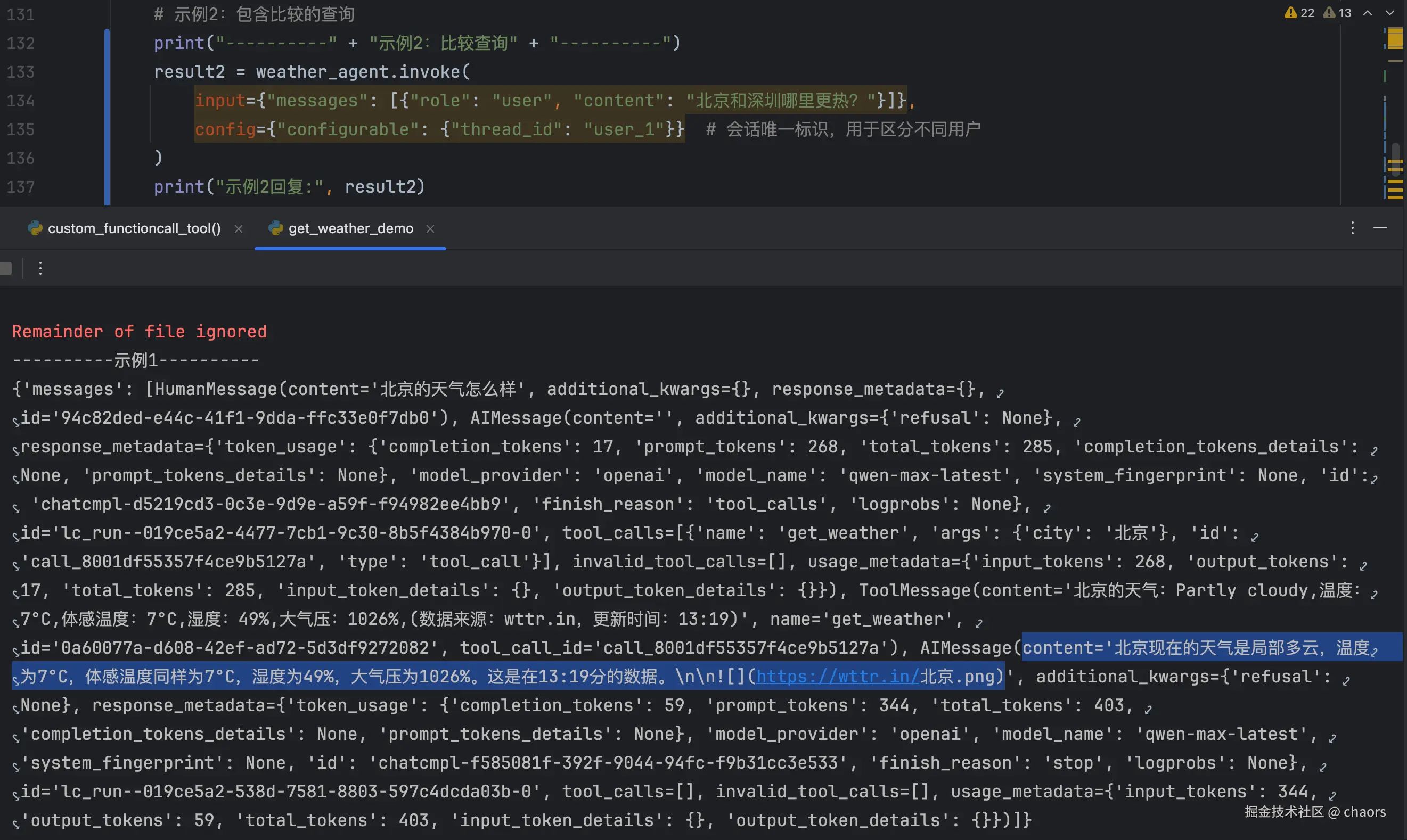
比较查询
python
# 示例2:包含比较的查询
print("----------" + "示例2:比较查询" + "----------")
result2 = weather_agent.invoke(
input={"messages": [{"role": "user", "content": "北京和深圳哪里更热?"}]},
config={"configurable": {"thread_id": "user_1"}} # 会话唯一标识,用于区分不同用户
)
print("示例2回复:", result2)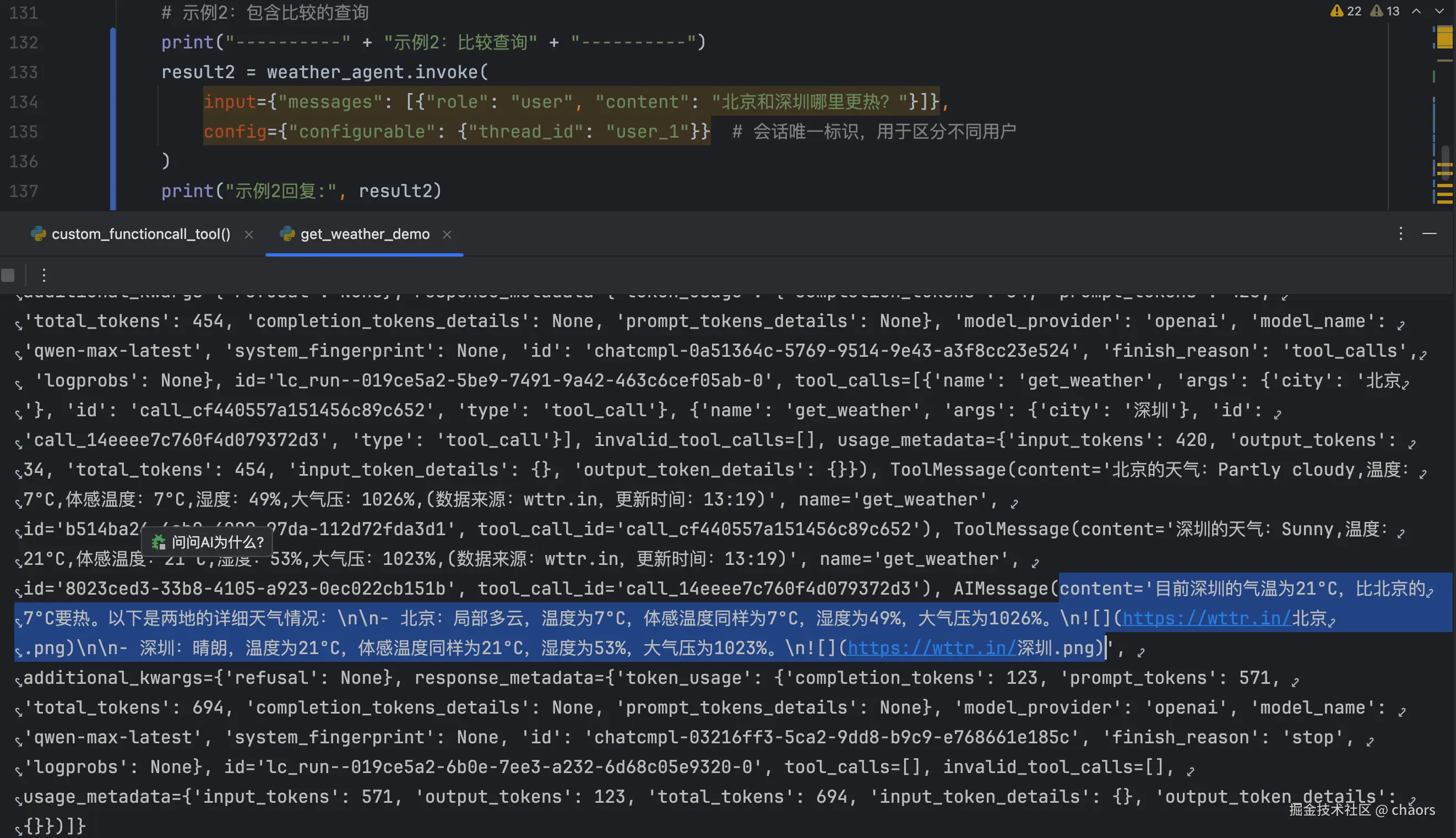
多轮对话
python
# 示例3:多轮对话
print("-------------------" + "示例3:多轮对话" + "-------------------")
# 第一步:用户发起新对话
print("******" + "第一轮对话" + "******")
result2_0 = weather_agent.invoke(
input={"messages": [{"role": "user", "content": "我想知道几个城市的天气"}]},
config={"configurable": {"thread_id": "user3_1"}} # 会话唯一标识,用于区分不同用户
)
print("AI首次回复:", result2_0["messages"][-1].content) # 输出AI的回复
# 第二步:用户继续提问,使用相同的thread_id
print("******" + "第二轮对话" + "******")
result2_1 = weather_agent.invoke(
input={"messages": [{"role": "user", "content": "先看下杭州的天气吧"}]},
config={"configurable": {"thread_id": "user3_1"}} # 会话唯一标识,用于区分不同用户
)
print("AI二轮回复:", result2_1["messages"][-1].content)
print("******" + "第三轮对话" + "******")
result2_2 = weather_agent.invoke(
input={"messages": [{"role": "user", "content": "我最开始问的啥问题?"}]},
config={"configurable": {"thread_id": "user3_1"}} # 会话唯一标识,用于区分不同用户
)
print("AI三轮回复:", result2_2["messages"][-1].content)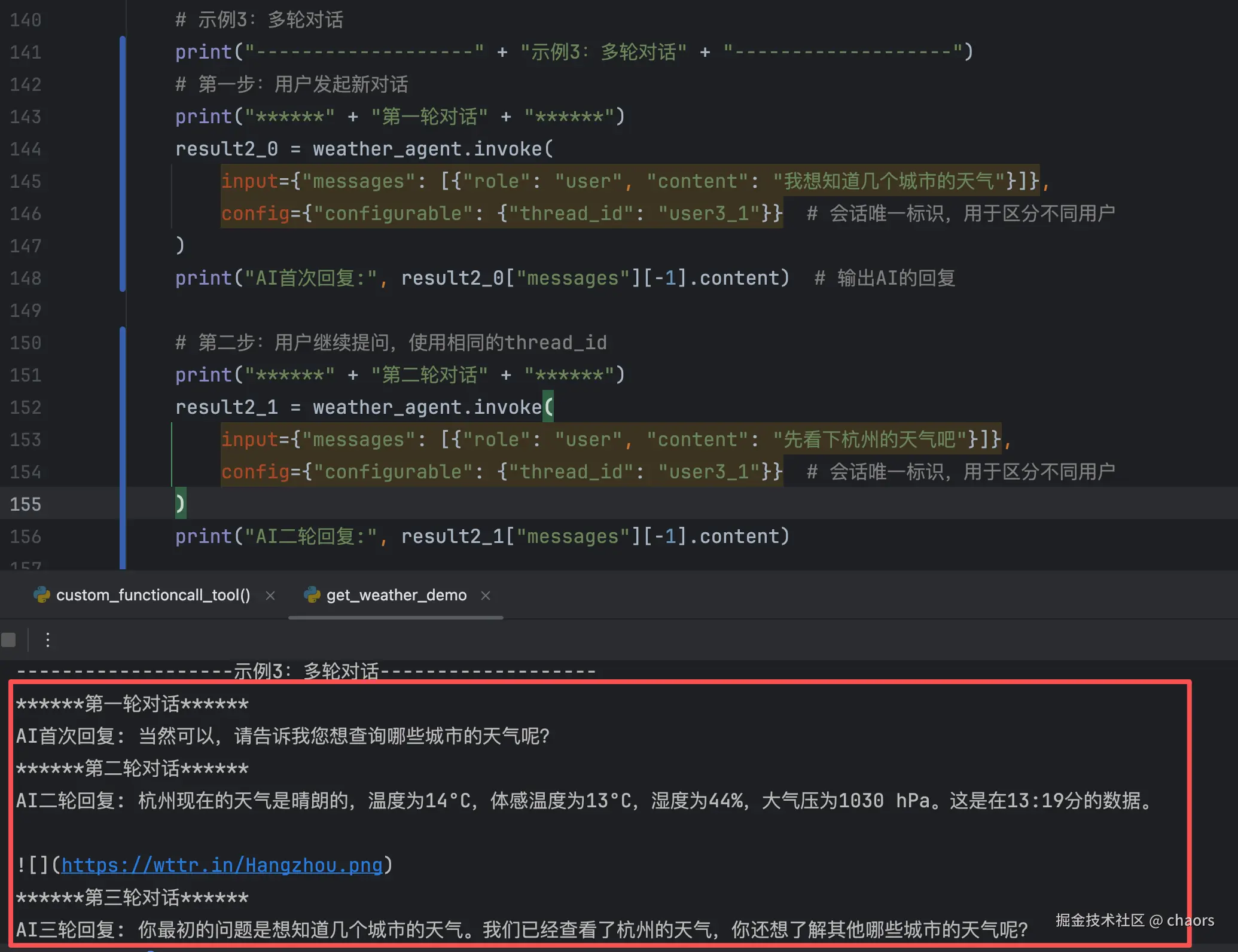
前端交互
gradio
定义
Gradio 是一个专门为机器学习模型快速构建可交互Web界面的Python库。
- 核心价值:零前端知识,几分钟内将你的模型从代码变成可分享的Web服务
- 核心逻辑:
- 函数包装 :你只需要定义一个普通的Python函数,在这个函数内部调用你的模型进行推理(如
predict(input))。 - 接口声明 :使用
gr.Interface()或gr.Blocks(),指明你的函数需要什么输入(如文本框、图片上传、麦克风)和输出什么(如标签、文本框、图表)。 - 自动生成 :Gradio会自动 将此函数和接口描述,转换成一个带有HTML/JS前端的本地Web服务器(默认
localhost:7860),并处理前后端的所有通信(基于FastAPI)。
- 函数包装 :你只需要定义一个普通的Python函数,在这个函数内部调用你的模型进行推理(如
和Streamlit对比
是不是有点熟悉,我们之前在 为PM写一个SQL语句小助手 项目中使用过一个叫streamlit的Web框架。其核心使命也是让数据科学家和机器学习工程师, 在完全不涉及前端技术(HTML/CSS/JavaScript)的情况下,能够以极快的速度将数据脚本或机器学习模型转化为可交互、可分享的Web应用。
那么他们两者有何区别呢?什么时候用gradio,什么时候用streamlit?
| 对比 | Gradio | Streamlit |
|---|---|---|
| 设计哲学 | 函数接口 (Function as UI) 核心是为一个或多个机器学习推理函数快速创建交互式输入输出界面。 | 脚本应用 (Script as App) 核心是编写一个从上到下执行的脚本,来生成一个完整的数据应用或仪表盘。 |
| 交互模型 | 事件驱动 用户与某个输入组件交互,触发与之绑定的特定函数执行,并更新对应的输出组件。 | 响应式"重跑" 任何交互(如点击、选择)都会导致整个脚本从头到尾重新执行,框架智能地差分更新界面。 |
| 心智模型 | 围绕函数调用 状态通常通过函数参数、返回值和专门的gr.State对象来管理,逻辑与界面组件绑定明确。 |
围绕会话状态 使用st.session_state字典来在脚本的多次"重跑"之间持久化数据,是构建复杂逻辑的核心。 |
| 布局风格 | 紧凑的"演示台"或"工具"风格,适合快速构建单一任务界面。 | 结构化的"数据看板"或"报告"风格,易于构建信息密度高、结构清晰的应用。 |
| 核心场景 | 模型演示与即时交互 为训练好的模型快速创建演示页面,供他人试用。典型如:Hugging Face模型Demo、文生图、语音处理、聊天机器人。 | 数据探索与分析应用 构建包含数据加载、参数调控、可视化、模型推理等多步骤的内部工具或数据仪表盘。 |
| 部署与集成倾向 | 易于"剥离"为纯API Gradio应用可以方便地转换为标准的FastAPI应用,易于被成熟的前后端架构集成。 | 通常作为整体应用部署 应用作为一个完整的服务部署,更适合作为独立的内部工具或报告系统。 |
简而言之:Gradio是 "为模型功能快速开一个交互窗口" ,而Streamlit是 "用Python脚本编写一个完整的数据应用" 。选择取决于你的核心目标是 "展示模型" 还是 "构建应用" 。
对于如何选择,一言以蔽之:
- 展示/交互一个核心模型 (Showcase a Model ) -> 优先选 Gradio
- 构建一个数据/分析应用 (Build a Data App ) -> 优先选 Streamlit
llm适配
python
# 与前端交互处理LLM响应
def process_llm_response(query, show_history):
if len(query) == 0:
return show_history + [("", "")]
try:
# 显示用户查询和等待提示
yield show_history + [(query, "正在查询大模型...")], ""
# 使用Agent处理查询
response = weather_agent.invoke(
{"messages": [{"role": "user", "content": query}]},
# 配置会话标识,用于区分不同用户
config={"configurable": {"thread_id": "user_1"}} # 会话唯一标识,用于区分不同用户
)
print(f"LLM输出:{response}")
# 正确提取回答内容 - 只显示output部分
if isinstance(response, dict) and 'messages' in response:
response = response["messages"][-1].content
else:
# 如果response不是预期的字典格式,尝试提取其他可能的字段
response = str(response)
print(f"警告: 响应格式异常: {response}")
# 返回结果
yield show_history + [(query, response)], ""
except Exception as e:
print(f"Error: {e}")
yield show_history + [(query, "AI助手出错,请重试或者检查")]-
我们发现这里有个 show_history 是把历史上下文累积到一起,但是我们的Agent命名配置了checkpointer(InMemorySaver),不应该是自动记忆吗,为什么这里还需要 show_history ?
-
checkpointer(InMemorySaver) :Agent内部的状态管理组件。它保存的是Agent在某个会话(thread_id)中完整的、结构化的"记忆",包括中间步骤、工具调用结果、内部状态等。它的核心目的是保证Agent在多次调用中具有连续性和一致性。
- 🌰你告诉Agent"我叫小明",它通过工具调用查询了信息,这个信息会通过checkpoint保存下来,影响后续的推理。
-
show_history:它是前端展示层为了渲染对话界面而维护的、格式化的对话历史记录。它通常只包含(user_query, ai_response)这样的纯文本对,不包含任何内部状态。它的核心目的是快速渲染UI,并提供给用户一个可回溯的聊天记录视图。
-
-
我们也发现这里返回值用了
yield,而不是常规的return。这又是为什么没呢?-
return:是标准的函数返回。函数执行完毕,计算出一个最终结果,一次性返回给调用者。在等待函数执行的整个过程中,调用方是阻塞的、无反馈的。
-
yield:用于定义生成器函数。它允许函数分批产出(yield)多个中间结果,在每次产出后函数会暂停,等待下次请求再继续执行。它是实现流式传输的核心机制。
-
显然,这里应该使用 yield。我们看看使用 yield 的核心作用:
-
即时状态反馈 :
yield show_history + [(query, "正在查询大模型...")]。在模型真正计算前,立即将"正在查询..."这个状态返回给前端,让界面立刻更新,给用户"已接收"的确认。这样让用户体验更好。 -
流式内容输出 :(虽然当前代码片段是等待完全生成后才
yield最终结果,但理想架构下)可以将模型实时生成的每一个token或chunk通过yield不断推送给前端,实现打字机式的输出效果,极大提升感知速度和用户体验。 -
异步友好 :生成器与异步编程模式(
async/await)完美结合,可以轻松集成到FastAPI的StreamingResponse或 WebSocket 中,构建高性能的流式API
前端适配
ini
# 前端界面展示
with gr.Blocks(title="天气查询小助手Demo演示") as demo:
gr.HTML('<center><h1>欢迎使用天气查询小助手,我将竭诚为您服务...</h1></center>')
with gr.Row():
with gr.Column(scale=10):
chatbot = gr.Chatbot(height=400)
with gr.Row():
msg = gr.Textbox(label="输入", placeholder="你想问什么有关天气的问题呢?")
with gr.Row():
example = gr.Examples(
examples=[
"河曲的天气怎么样?",
"准备现在去鄂尔多斯,该穿什么衣服?",
"今天要去天安门,需要带雨伞吗?",
"杭州和南京哪里天气更热?"
],
inputs=[msg]
)
clear = gr.ClearButton([chatbot, msg])
msg.submit(process_llm_response, inputs=[msg, chatbot], outputs=[chatbot, msg])本质是python代码(gradio)在写前端UI页面,至于服务等其他操作都在gradio框架内部自动完成。
Run
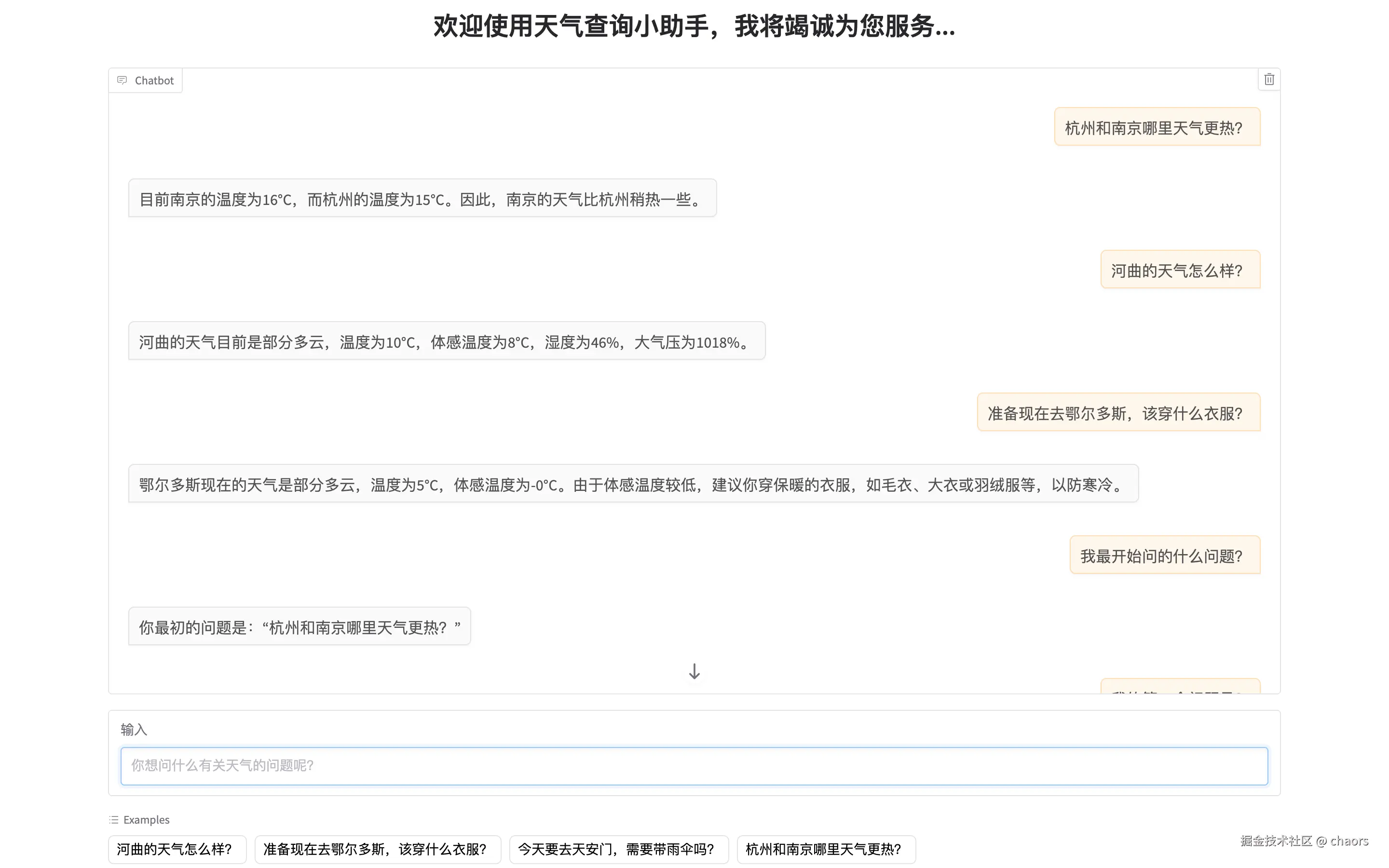
我们发现他是能记住对话上下文的。
至此,一个极简的天气查询小助手Demo就完成了。