@TOC
前言
在传统的开发流程中,编写复杂的 SQL 查询往往是一项耗时且容易出错的工作。开发者需要频繁切换文档查看表结构,小心翼翼地处理多表关联,还要担心语法错误。随着 AI 编程助手 Cursor 的普及,一种新的开发范式正在形成:自然语言即 SQL。
然而,Cursor 远不止是一个"能写 SQL 的 ChatGPT"。它深度集成在 IDE 中,通过理解项目的完整上下文------从数据模型定义到业务代码注释------实现了前所未有的智能辅助。本文将深入剖析 Cursor 实现 SQL 智能生成的底层原理,并结合实战案例与避坑技巧,助你彻底释放生产力,同时探讨这一技术背后的边界与思考。
一、 原理揭秘:Cursor 为什么比 ChatGPT 更懂你的数据库?
很多开发者尝试过用 ChatGPT 写 SQL,但效果往往不尽人意。原因在于通用大模型不知道你的业务上下文------它不知道你的表叫 t_user 还是 users,也不知道 status=1 具体代表什么业务含义。Cursor 的核心竞争力在于其深度上下文感知能力 ,而这种能力建立在检索增强生成(RAG)与代码索引技术的完美结合之上。
1. 核心架构组件
Cursor 并非简单的对话框,它由以下三个核心模块协同工作:
-
索引器(Indexer)
实时扫描项目代码,构建向量索引与符号索引。它不仅能定位 ORM 模型文件(如
models.py,schema.prisma)或建表 SQL 语句,还能解析代码中的注释、枚举定义以及数据库连接配置文件。索引器使用静态分析技术提取表名、字段名、数据类型、关系注解等元数据,并将其转化为结构化的向量表示,存储在本地向量数据库中。 -
检索增强生成(RAG)
当你提问时,Cursor 不会盲目生成,而是先去索引中"检索"最相关的上下文。这一过程分为两步:首先通过关键词匹配 快速定位可能相关的文件,然后通过向量相似度检索(通常使用余弦相似度)找出语义上最匹配的代码片段。检索到的表结构定义、字段注释、已有查询示例等被作为背景知识,动态组装成提示词的一部分,喂给大模型。这种机制保证了生成内容严格受限于项目实际,极大降低了"幻觉"。
-
推理引擎(Inference Engine)
基于检索到的上下文,结合大模型(如 Claude 3.5 Sonnet 或 GPT-4o)强大的逻辑推理能力,生成符合语法的 SQL。Cursor 还会对生成的 SQL 进行轻量级语法校验,并在 IDE 中提供实时高亮和错误提示。此外,推理引擎支持多轮对话,允许用户通过自然语言修正生成结果,形成人机协作的闭环。
2. 架构流程图解
为了更直观地理解,我们可以通过以下流程图展示 Cursor 处理 SQL 请求的全过程: 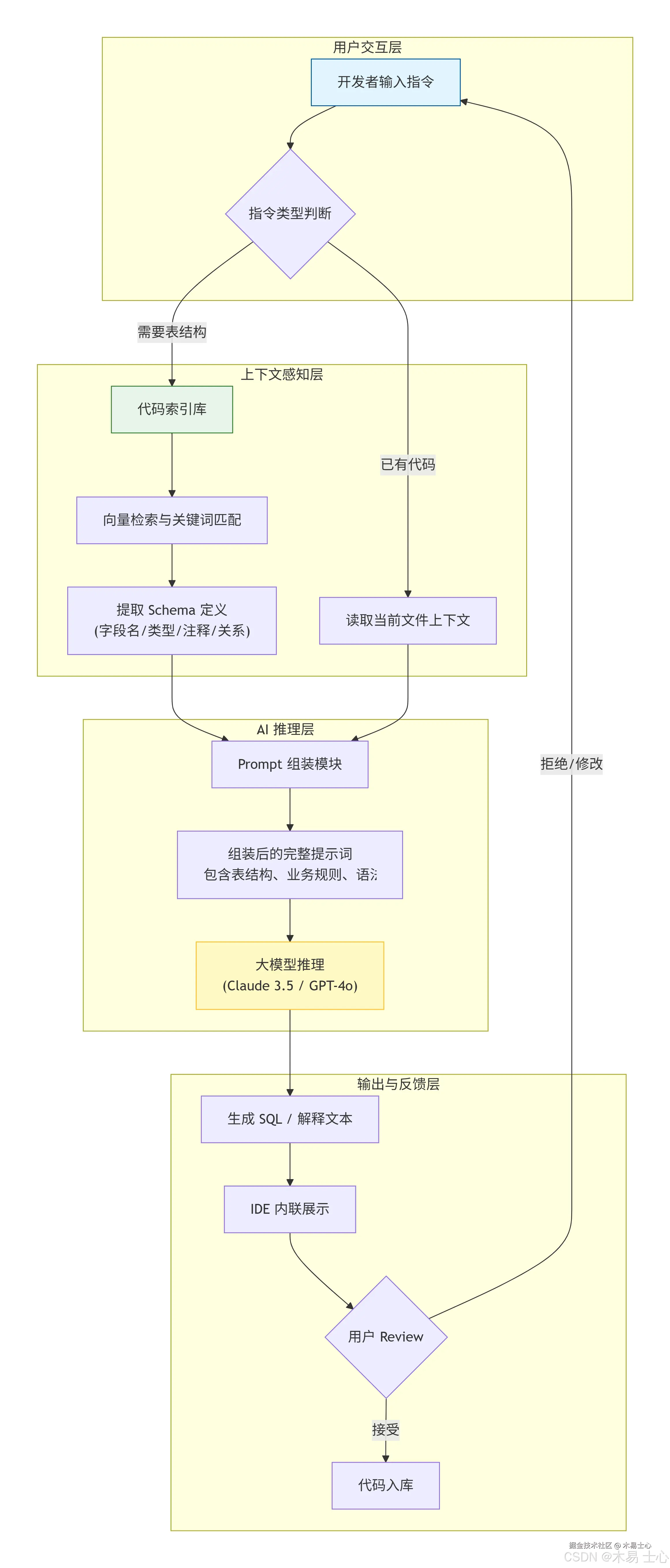
流程解析:
- 输入: 开发者按下
Cmd+K输入"查询活跃用户"。 - 检索: Cursor 在后台飞速检索项目中的
User模型,识别出last_login_time和is_active字段,并读取该模型的注释(如is_active: 1表示正常,0表示禁用)。 - 组装: 将表结构定义与用户指令拼接成一个结构化的提示词,明确告诉模型:"这是表结构及业务含义,请根据此结构写 SQL,遵循项目方言为 PostgreSQL。"
- 生成: 模型输出 SQL,并自动适配项目配置的数据库方言,同时可能附带执行计划建议。
二、 实战教学:从自然语言到高质量 SQL
场景一:自然语言生成 SQL(Text-to-SQL)
痛点: 经常忘记复杂的 JOIN 语法,或者不确定多对多关系的中间表名称。
操作步骤:
- 打开项目中用于存放查询逻辑的文件。
- 按下
Cmd+K(Windows:Ctrl+K) 唤起内联编辑框。 - 输入 Prompt: "查询最近 30 天内下单金额超过 1000 元的用户,列出用户名、总金额和订单数,按金额降序排列。"
Cursor 生成结果(自动识别了 User 与 Order 的关联,并补充了常见业务状态过滤):
sql
SELECT
u.username,
COUNT(o.id) as order_count,
SUM(o.amount) as total_amount
FROM users u
JOIN orders o ON u.id = o.user_id
WHERE o.created_at >= DATE_SUB(NOW(), INTERVAL 30 DAY)
AND o.status = 'paid' -- 自动补全了业务状态判断(从模型注释或枚举中学习)
GROUP BY u.id, u.username
HAVING total_amount > 1000
ORDER BY total_amount DESC;场景二:复杂 SQL 生成(窗口函数、CTE)
痛点: 编写窗口函数或递归查询时,语法容易出错。
Prompt:
"使用 PostgreSQL 语法,查询每个部门薪资排名前 3 的员工,输出部门名、员工名、薪资和排名。"
Cursor 生成(自动识别了 department 和 employee 表关系):
sql
WITH ranked_employees AS (
SELECT
d.name AS department_name,
e.name AS employee_name,
e.salary,
DENSE_RANK() OVER (PARTITION BY e.department_id ORDER BY e.salary DESC) AS rank
FROM employee e
JOIN department d ON e.department_id = d.id
)
SELECT department_name, employee_name, salary, rank
FROM ranked_employees
WHERE rank <= 3
ORDER BY department_name, rank;场景三:SQL 转自然语言(代码解释与优化建议)
痛点: 接手老项目,面对几百行的存储过程或复杂统计 SQL,看不懂业务逻辑。
操作步骤:
- 用鼠标选中那段复杂的 SQL 代码。
- 按下
Cmd+L打开 Chat 面板。 - 输入 Prompt: "解释这段 SQL 的业务含义,并指出潜在的性能瓶颈,给出优化建议。"
Cursor 输出(示例):
- 业务含义: 该查询统计的是上个月各地区的销售额排名,使用了子查询和聚合。
- 性能瓶颈: 注意到
WHERE条件中对create_time使用了函数DATE_FORMAT,这会导致索引失效,建议改为范围查询;另外,子查询中使用了DISTINCT可能是不必要的,可以尝试用EXISTS重写。 - 优化建议: 提供改写后的 SQL,并解释为何新写法更高效。
三、 支持范围与边界:用实例说话
Cursor 的能力边界主要取决于模型的训练数据,目前已完美支持:
- 主流关系型数据库: MySQL, PostgreSQL, SQLite, Oracle, SQL Server.
- 大数据与分析型数据库: ClickHouse, Snowflake, BigQuery, Hive.
- ORM 框架(进阶能力): 它不仅能写原生 SQL,还能直接生成 TypeORM, Prisma, GORM, Django ORM 代码,甚至根据模型定义推导出对应的 CRUD 操作。
- NoSQL 数据库(部分支持): 对于 MongoDB 等,可以生成聚合管道查询。
然而,在实际使用中,边界问题往往出现在特定数据库方言的细节处理上。下面通过两个典型案例说明:
案例 1:ClickHouse 物化视图生成的"陷阱"
需求: 在 ClickHouse 中创建一个物化视图,基于 hits 表按小时预聚合统计。
Prompt: "生成 ClickHouse 物化视图,统计每小时每个页面的访问量。"
Cursor 可能生成的初始 SQL(错误示范):
sql
CREATE MATERIALIZED VIEW hourly_page_views
ENGINE = SummingMergeTree()
PARTITION BY toYYYYMM(hour)
ORDER BY (hour, page_id)
AS SELECT
toStartOfHour(event_time) AS hour,
page_id,
count(*) AS views
FROM hits
GROUP BY hour, page_id;问题所在: ClickHouse 的物化视图必须指定 POPULATE 或使用 TO 表,并且直接使用 GROUP BY 在视图中是不允许的,需要改为使用聚合函数和 AS SELECT 的结构。Cursor 生成的语法混合了 PostgreSQL 的习惯,导致在 ClickHouse 中执行失败。
人工修正: 开发者需要在 Prompt 中明确强调"严格遵循 ClickHouse 官方文档语法",或者将 CREATE TABLE 语句一同提供,让 Cursor 学习表结构后生成更准确的代码。最终正确版本应为:
sql
CREATE MATERIALIZED VIEW hourly_page_views_mv
TO hourly_page_views -- 假设目标表已存在
AS SELECT
toStartOfHour(event_time) AS hour,
page_id,
count(*) AS views
FROM hits
GROUP BY hour, page_id;启示: 对于方言特性强的数据库,务必在 Prompt 中指定版本号或附上建表语句作为参考。
案例 2:MongoDB 聚合管道的缺失阶段
需求: 查询最近 7 天内订单金额超过 100 元的用户,返回用户姓名和总金额。
Prompt: "用 MongoDB 聚合查询,找出最近 7 天下单金额 > 100 的用户。"
Cursor 生成:
javascript
db.orders.aggregate([
{ $match: { createdAt: { $gte: new Date(Date.now() - 7*24*60*60*1000) } } },
{ $group: { _id: "$userId", totalAmount: { $sum: "$amount" } } },
{ $match: { totalAmount: { $gt: 100 } } },
{ $lookup: { from: "users", localField: "_id", foreignField: "_id", as: "user" } },
{ $unwind: "$user" },
{ $project: { name: "$user.name", totalAmount: 1 } }
])分析: 这个聚合基本正确,但缺少了对 $lookup 后的空值处理,如果某些用户被删除,$unwind 会导致文档丢失。更稳健的做法是使用 $unwind: { preserveNullAndEmptyArrays: true }。Cursor 可能不会主动考虑这种边界情况。
改进: 通过在 .cursorrules 中加入"所有 $lookup 必须配合 preserveNullAndEmptyArrays"规则,可以强制生成更安全的代码。
小结
Cursor 在主流场景下表现优异,但在方言特异性、边界条件处理上仍需要人工把关。理解这些边界,才能更好地利用工具,避免生产事故。
四、 避坑指南:如何让生成准确率达到 99%?(附真实案例)
AI 不是神,它也会犯错。以下是常见的"坑"及解决技巧,每个技巧都附有真实案例对比,让你直观感受改进前后的差异。
技巧一:拒绝"幻觉",强制指定上下文
问题场景: 项目中有两张表:user(字段:id, user_name)和 account(字段:id, user_id, balance)。你输入"查询所有用户及其账户余额",Cursor 可能生成:
sql
SELECT u.id, u.name, a.balance -- 错误:u.name 不存在
FROM user u
LEFT JOIN account a ON u.id = a.user_id;它"幻觉"出了 name 字段,而实际字段是 user_name。
解决: 使用 @ 符号强引用相关模型文件。
Prompt: "根据 @models/user.ts 和 @models/account.ts 中的定义,查询所有用户及其账户余额。"
Cursor 会读取这两个文件,准确生成 u.user_name。
技巧二:配置 .cursorrules 设定"宪法"
问题场景: 团队要求所有查询必须排除软删除数据(deleted_at IS NULL),且禁止使用 SELECT *。但 Cursor 经常生成不带软删除过滤的 SQL,且偶尔出现 SELECT *。
解决: 在项目根目录创建 .cursorrules 文件,写入:
text
# SQL 生成规范
1. 数据库方言:PostgreSQL
2. 禁止使用 SELECT *,必须明确列出所有字段。
3. 所有涉及 users、orders 等表的查询,自动追加 `deleted_at IS NULL` 条件。
4. 使用表别名,格式为表名的首字母缩写(如 users AS u)。效果对比:
- 之前:
SELECT * FROM users WHERE created_at > '2023-01-01'; - 之后:
SELECT u.id, u.name, u.email FROM users u WHERE u.created_at > '2023-01-01' AND u.deleted_at IS NULL;
技巧三:完善代码注释,提供业务语义
问题场景: 表中有一列 status,值为 0、1、2,但没有任何注释。你输入"查询已完成的订单",Cursor 不知道哪个状态代表"已完成",可能随意猜测为 1,而实际业务中 2 才是已完成。
解决: 在模型定义中添加注释或枚举。
typescript
// models/order.ts
export interface Order {
id: number;
status: number; // 订单状态: 0-待支付, 1-支付中, 2-已完成, 3-已取消
}或者在 GraphQL Schema 中使用枚举:
graphql
enum OrderStatus {
PENDING
PAID
COMPLETED
CANCELLED
}效果对比:
- 之前(无注释):
WHERE status = 1(错误) - 之后(有注释):
WHERE status = 2(正确)
技巧四:明确方言差异,避免语法错误
问题场景: 你使用 PostgreSQL,但 Cursor 生成了 MySQL 的分页语法:LIMIT 10 OFFSET 20,这在 PostgreSQL 中虽然能用,但如果你需要 OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY 这种标准语法,Cursor 可能不会主动生成。
解决: 在 Prompt 中明确指定,或确保项目配置文件中指明了方言。
Prompt: "使用 PostgreSQL 13+ 语法,查询第 2 页的 10 条订单记录。"
Cursor 会生成:SELECT ... ORDER BY id LIMIT 10 OFFSET 10;(注意 OFFSET 计算正确)
复杂案例: 需要生成 ClickHouse 的 LIMIT ... WITH TIES 语法,如果仅说"查询前 10 条",Cursor 可能不会自动加上 WITH TIES。但若在 .cursorrules 中声明"所有排序后取前 N 的查询,必须使用 WITH TIES 保留并列结果",则生成结果会符合预期。
技巧五:使用 Chain-of-Thought 引导复杂查询
问题场景: 你需要一个复杂的递归查询,例如查找某个员工的所有下属(包括间接下属)。直接 Prompt 可能生成错误的递归逻辑。
解决: 要求模型先分解步骤。
Prompt: "请按以下步骤生成 PostgreSQL 递归查询:
- 确定起始点(员工 ID = 123)。
- 递归部分:查找所有直接下属,并不断加入结果。
- 最终输出所有下属的姓名和层级。请先写出 CTE 结构,再写最终 SELECT。"
Cursor 会生成类似:
sql
WITH RECURSIVE subordinates AS (
SELECT id, name, 1 AS level
FROM employees
WHERE id = 123
UNION ALL
SELECT e.id, e.name, s.level + 1
FROM employees e
INNER JOIN subordinates s ON e.manager_id = s.id
)
SELECT * FROM subordinates;通过 Chain-of-Thought,模型更容易遵循正确的逻辑。
技巧六:结合单元测试验证生成结果
对于关键查询,可以在 Prompt 中要求 Cursor 同时生成对应的测试用例(如使用 pgTAP 或 SQL 断言),以验证结果的正确性。这虽然不是直接提高生成准确率,但能帮助你快速发现错误。
五、 结语
Cursor 并非是要取代数据库工程师,而是将开发者从枯燥的语法拼写中解放出来,专注于数据逻辑 与业务架构 。通过理解其 RAG 架构原理 ,善用 @ 引用 与 .cursorrules 配置,并结合良好的注释习惯,我们可以将 SQL 生成的准确率提升至生产可用级别。
未来,随着 AI 对代码语义理解的进一步深化,我们或许能看到更智能的交互------例如,直接通过自然语言创建数据模型、自动生成迁移脚本,甚至实时分析查询性能并给出优化方案。从今天起,试着把那些繁琐的 JOIN 交给 Cursor,你会发现,写代码从未如此丝滑,而你也将有更多时间思考真正重要的架构与业务创新。