1. 核心基础:分布函数与假设
逻辑回归的核心假设是:给定输入样本 xxx,其对应的类别标签 y∈{0,1}y \in \{0, 1\}y∈{0,1} 服从伯努利分布(Bernoulli Distribution)(即0-1分布)。
我们希望模型能够输出样本属于正类(y=1y=1y=1)的概率。假设我们有一个线性组合 θTx\theta^T xθTx(其中 θ\thetaθ 是权重参数,xxx 是特征),由于 θTx\theta^T xθTx 的取值范围是 (−∞,+∞)(-\infty, +\infty)(−∞,+∞),而概率的取值范围必须是 (0,1)(0, 1)(0,1),我们需要一个映射函数来完成转换。
2. Sigmoid 函数:连续空间到概率空间的映射
为了将线性回归的输出映射到 (0,1)(0, 1)(0,1) 之间,逻辑回归引入了 Sigmoid 函数(也叫 Logistic 函数)。
Sigmoid 函数公式:
g(z)=11+e−zg(z) = \frac{1}{1 + e^{-z}}g(z)=1+e−z1
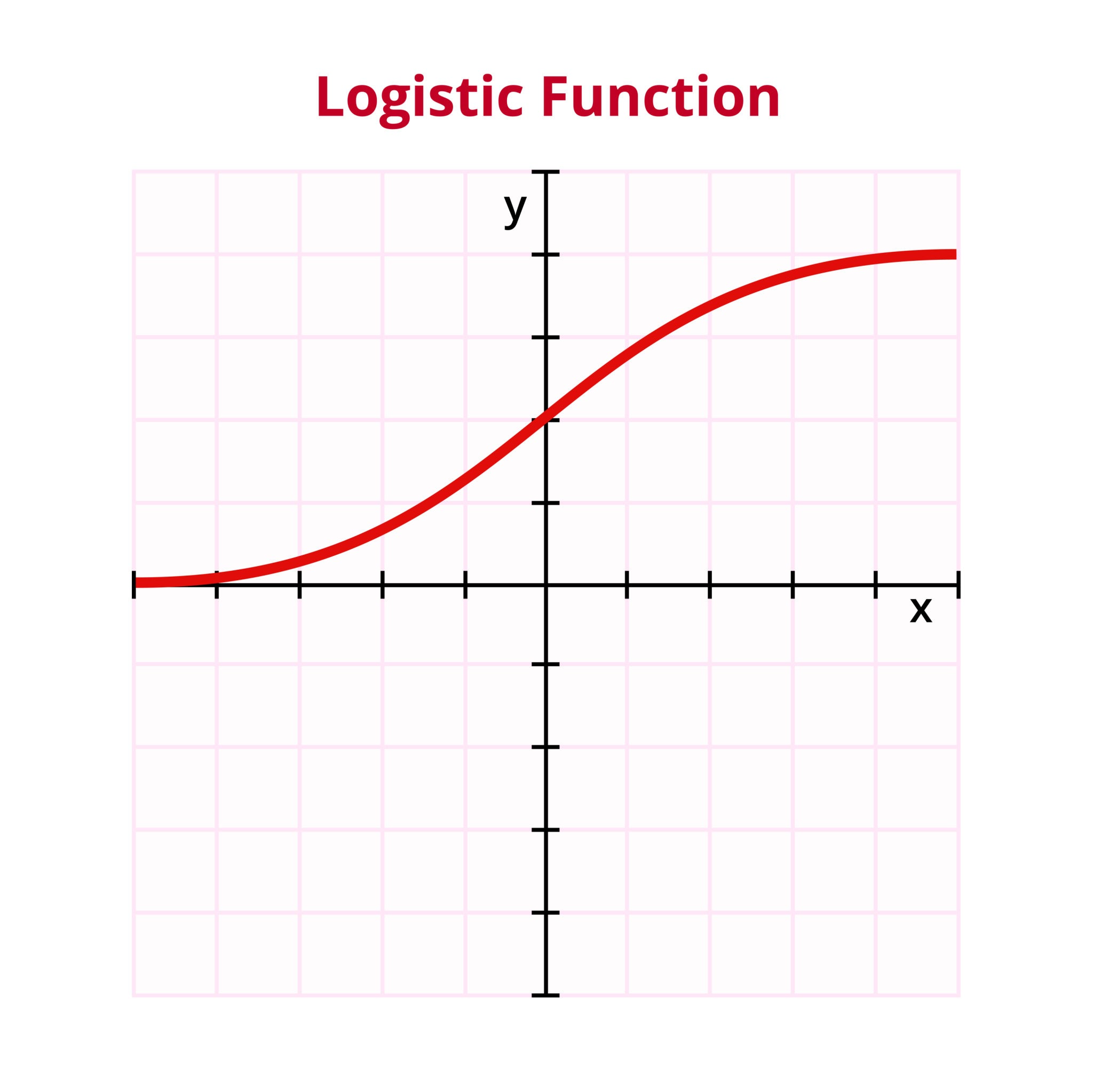
Sigmoid 函数的优良性质:
-
值域: 当 z→∞z \to \inftyz→∞ 时,g(z)→1g(z) \to 1g(z)→1;当 z→−∞z \to -\inftyz→−∞ 时,g(z)→0g(z) \to 0g(z)→0。
-
导数极其优美: 它的导数可以用它自身来表示,这为后续的梯度下降计算带来了极大的便利。
g′(z)=ddz(1+e−z)−1=−(1+e−z)−2⋅(−e−z)=e−z(1+e−z)2=11+e−z⋅e−z1+e−z=g(z)(1−g(z))g'(z) = \frac{d}{dz} (1 + e^{-z})^{-1} = -(1 + e^{-z})^{-2} \cdot (-e^{-z}) = \frac{e^{-z}}{(1 + e^{-z})^2} = \frac{1}{1 + e^{-z}} \cdot \frac{e^{-z}}{1 + e^{-z}} = g(z)(1 - g(z))g′(z)=dzd(1+e−z)−1=−(1+e−z)−2⋅(−e−z)=(1+e−z)2e−z=1+e−z1⋅1+e−ze−z=g(z)(1−g(z))
我们将线性组合 z=θTxz = \theta^T xz=θTx 代入 Sigmoid 函数,得到逻辑回归的假设函数(Hypothesis):
hθ(x)=g(θTx)=11+e−θTxh_\theta(x) = g(\theta^T x) = \frac{1}{1 + e^{-\theta^T x}}hθ(x)=g(θTx)=1+e−θTx1
它代表了给定特征 xxx 和参数 θ\thetaθ 时,y=1y=1y=1 的概率:P(y=1∣x;θ)=hθ(x)P(y=1 | x; \theta) = h_\theta(x)P(y=1∣x;θ)=hθ(x)。
3. 最大似然估计(MLE)与损失函数构造
既然我们知道了预测概率,如何寻找最优的模型参数 θ\thetaθ 呢?统计学中常用的方法是最大似然估计(Maximum Likelihood Estimation, MLE) ,即寻找一组参数 θ\thetaθ,使得当前观测到的样本数据发生的概率最大。
首先,根据伯努利分布,我们可以把 y=1y=1y=1 和 y=0y=0y=0 的概率整合为一个统一的公式:
P(y∣x;θ)=(hθ(x))y(1−hθ(x))1−yP(y | x; \theta) = (h_\theta(x))^y (1 - h_\theta(x))^{1 - y}P(y∣x;θ)=(hθ(x))y(1−hθ(x))1−y
(验证:当 y=1y=1y=1 时,结果为 hθ(x)h_\theta(x)hθ(x);当 y=0y=0y=0 时,结果为 1−hθ(x)1 - h_\theta(x)1−hθ(x)。)
似然函数(Likelihood Function):
假设有 mmm 个独立同分布的训练样本,整体的似然函数就是每个样本概率的乘积:
L(θ)=∏i=1mP(y(i)∣x(i);θ)=∏i=1m(hθ(x(i)))y(i)(1−hθ(x(i)))1−y(i)L(\theta) = \prod_{i=1}^{m} P(y^{(i)} | x^{(i)}; \theta) = \prod_{i=1}^{m} (h_\theta(x^{(i)}))^{y^{(i)}} (1 - h_\theta(x^{(i)}))^{1 - y^{(i)}}L(θ)=∏i=1mP(y(i)∣x(i);θ)=∏i=1m(hθ(x(i)))y(i)(1−hθ(x(i)))1−y(i)
对数似然函数(Log-Likelihood Function):
连乘会导致计算困难且容易发生数值下溢,因此我们两边取自然对数,将连乘转化为连加:
l(θ)=logL(θ)=∑i=1my(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))l(\theta) = \log L(\theta) = \sum_{i=1}^{m} \left y\^{(i)} \\log h_\\theta(x\^{(i)}) + (1 - y\^{(i)}) \\log (1 - h_\\theta(x\^{(i)})) \\rightl(θ)=logL(θ)=∑i=1my(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))
交叉熵损失函数(Cross-Entropy Loss):
最大化似然函数等价于最小化负对数似然函数。为了求平均值,我们通常乘以 −1m-\frac{1}{m}−m1,这就得到了逻辑回归大名鼎鼎的损失函数 J(θ)J(\theta)J(θ):
J(θ)=−1ml(θ)=−1m∑i=1my(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))J(\theta) = -\frac{1}{m} l(\theta) = -\frac{1}{m} \sum_{i=1}^{m} \left y\^{(i)} \\log h_\\theta(x\^{(i)}) + (1 - y\^{(i)}) \\log (1 - h_\\theta(x\^{(i)})) \\rightJ(θ)=−m1l(θ)=−m1∑i=1my(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))
4. 梯度求导(核心推导过程)
为了使用梯度下降法最小化损失函数 J(θ)J(\theta)J(θ),我们需要对 θj\theta_jθj 求偏导数。我们先对求和号内部的单样本损失(记为 CostCostCost)进行推导:
∂∂θjCost=∂∂θjyloghθ(x)+(1−y)log(1−hθ(x))\frac{\partial}{\partial \theta_j} Cost = \frac{\partial}{\partial \theta_j} \left y \\log h_\\theta(x) + (1 - y) \\log (1 - h_\\theta(x)) \\right∂θj∂Cost=∂θj∂yloghθ(x)+(1−y)log(1−hθ(x))
利用链式法则,并结合之前推导的 Sigmoid 导数 hθ′(x)=hθ(x)(1−hθ(x))⋅xjh'\theta(x) = h\theta(x)(1 - h_\theta(x)) \cdot x_jhθ′(x)=hθ(x)(1−hθ(x))⋅xj:
-
对第一项求导:
∂∂θjyloghθ(x)=y⋅1hθ(x)⋅hθ(x)(1−hθ(x))⋅xj=y(1−hθ(x))xj\frac{\partial}{\partial \theta_j} y \\log h_\\theta(x) = y \cdot \frac{1}{h_\theta(x)} \cdot h_\theta(x)(1 - h_\theta(x)) \cdot x_j = y (1 - h_\theta(x)) x_j∂θj∂yloghθ(x)=y⋅hθ(x)1⋅hθ(x)(1−hθ(x))⋅xj=y(1−hθ(x))xj
-
对第二项求导:
∂∂θj(1−y)log(1−hθ(x))=(1−y)⋅11−hθ(x)⋅(−1)⋅hθ(x)(1−hθ(x))⋅xj=−(1−y)hθ(x)xj\frac{\partial}{\partial \theta_j} (1 - y) \\log (1 - h_\\theta(x)) = (1 - y) \cdot \frac{1}{1 - h_\theta(x)} \cdot (-1) \cdot h_\theta(x)(1 - h_\theta(x)) \cdot x_j = -(1 - y) h_\theta(x) x_j∂θj∂(1−y)log(1−hθ(x))=(1−y)⋅1−hθ(x)1⋅(−1)⋅hθ(x)(1−hθ(x))⋅xj=−(1−y)hθ(x)xj
-
将两项相加:
y(1−hθ(x))xj−(1−y)hθ(x)xj=(y−y⋅hθ(x)−hθ(x)+y⋅hθ(x))xj=(y−hθ(x))xjy (1 - h_\theta(x)) x_j - (1 - y) h_\theta(x) x_j = (y - y \cdot h_\theta(x) - h_\theta(x) + y \cdot h_\theta(x)) x_j = (y - h_\theta(x)) x_jy(1−hθ(x))xj−(1−y)hθ(x)xj=(y−y⋅hθ(x)−hθ(x)+y⋅hθ(x))xj=(y−hθ(x))xj
注意,这是对数似然 l(θ)l(\theta)l(θ) 中单项的导数。因为我们的损失函数 J(θ)=−1ml(θ)J(\theta) = -\frac{1}{m} l(\theta)J(θ)=−m1l(θ),所以需要乘以负号并求均值:
∂J(θ)∂θj=1m∑i=1m(hθ(x(i))−y(i))xj(i)\frac{\partial J(\theta)}{\partial \theta_j} = \frac{1}{m} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y^{(i)}) x_j^{(i)}∂θj∂J(θ)=m1∑i=1m(hθ(x(i))−y(i))xj(i)
(你会发现,这个梯度公式在形式上与线性回归的均方误差梯度完全一致,这得益于广义线性模型中指数族分布的优美数学结构。)
5. 参数更新(梯度下降)
根据求得的梯度,我们使用梯度下降(Gradient Descent)算法来迭代更新参数 θ\thetaθ。
更新规则:
θj:=θj−α∂J(θ)∂θj\theta_j := \theta_j - \alpha \frac{\partial J(\theta)}{\partial \theta_j}θj:=θj−α∂θj∂J(θ)
将梯度代入后得到:
θj:=θj−α(1m∑i=1m(hθ(x(i))−y(i))xj(i))\theta_j := \theta_j - \alpha \left( \frac{1}{m} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y^{(i)}) x_j^{(i)} \right)θj:=θj−α(m1∑i=1m(hθ(x(i))−y(i))xj(i))
(其中 α\alphaα 是学习率,决定了参数更新的步长。)
每一次迭代,模型都会计算所有样本的预测误差 (hθ(x(i))−y(i))(h_\theta(x^{(i)}) - y^{(i)})(hθ(x(i))−y(i)),并将其与特征 xj(i)x_j^{(i)}xj(i) 相乘,累加后作为更新方向,直到参数收敛。
总结与知识点串联
逻辑回归不仅是机器学习的基础,也是深度学习中神经网络(尤其是在输出层处理分类问题)的基石。其知识点逻辑链路如下:
- 业务场景: 处理二分类问题。
- 数据假设: 样本服从 伯努利分布。
- 模型构建: 使用 线性组合 θTx\theta^T xθTx 提取特征,利用 Sigmoid 函数 将其非线性映射到 (0,1)(0, 1)(0,1) 的概率空间。
- 目标函数: 基于概率建立似然函数,利用 最大似然估计(MLE) 推导出 交叉熵损失函数(Log Loss)。
- 模型优化: 利用微积分的链式法则计算偏导数(梯度 ),利用 梯度下降法 进行迭代寻优,完成 参数更新。