你有没有这样的经历:在搜索引擎里输入"苹果价格",结果出来的全是苹果手机的价格?或者问AI一个问题,它自信满满地给出一段话,结果却是编造的?
这一切的根源,在于传统搜索基于关键词匹配,无法理解语义;而AI的"幻觉"则源于知识截止和缺乏事实依据。
今天,我们将揭开一项革命性技术的神秘面纱------语义搜索与RAG(检索增强生成)。它让搜索引擎真正读懂你的心思,让AI的回答有据可查,正引领着信息检索和生成的新时代。
一、语言模型如何重塑搜索?
早在2018年,谷歌就将BERT整合到搜索引擎中,称其为"搜索史上最具突破性的进步之一"。微软紧随其后,宣布必应通过大型Transformer模型获得显著体验提升。这些实践背后,正是语义搜索的崛起------它不再仅仅匹配关键词,而是通过理解语言背后的含义,精准找到用户想要的信息。
语义搜索的核心技术如今已演化为三大支柱:稠密检索、重排序、RAG。下面我们逐一拆解。
二、稠密检索:把文字变成向量,让计算机"理解"语义
传统搜索靠关键词匹配,比如搜"苹果价格",只会找包含"苹果"和"价格"这两个词的网页,却可能漏掉"iPhone售价"这样的相关结果。稠密检索则完全不同。
2.1 原理:文本嵌入的魔法
稠密检索的核心是文本嵌入(embedding)------将文本(查询或文档)转换为高维向量(一串数字)。这些向量在空间中的位置代表了语义:意思相近的文本,向量距离也近;意思相反的,距离就远。
如下图所示,当用户输入查询时,系统将查询也转为向量,然后在预先建好的文档向量库中,通过最近邻搜索找到最相似的几个文档。这个过程就像在语义空间中找邻居,完全跳过了关键词的束缚。
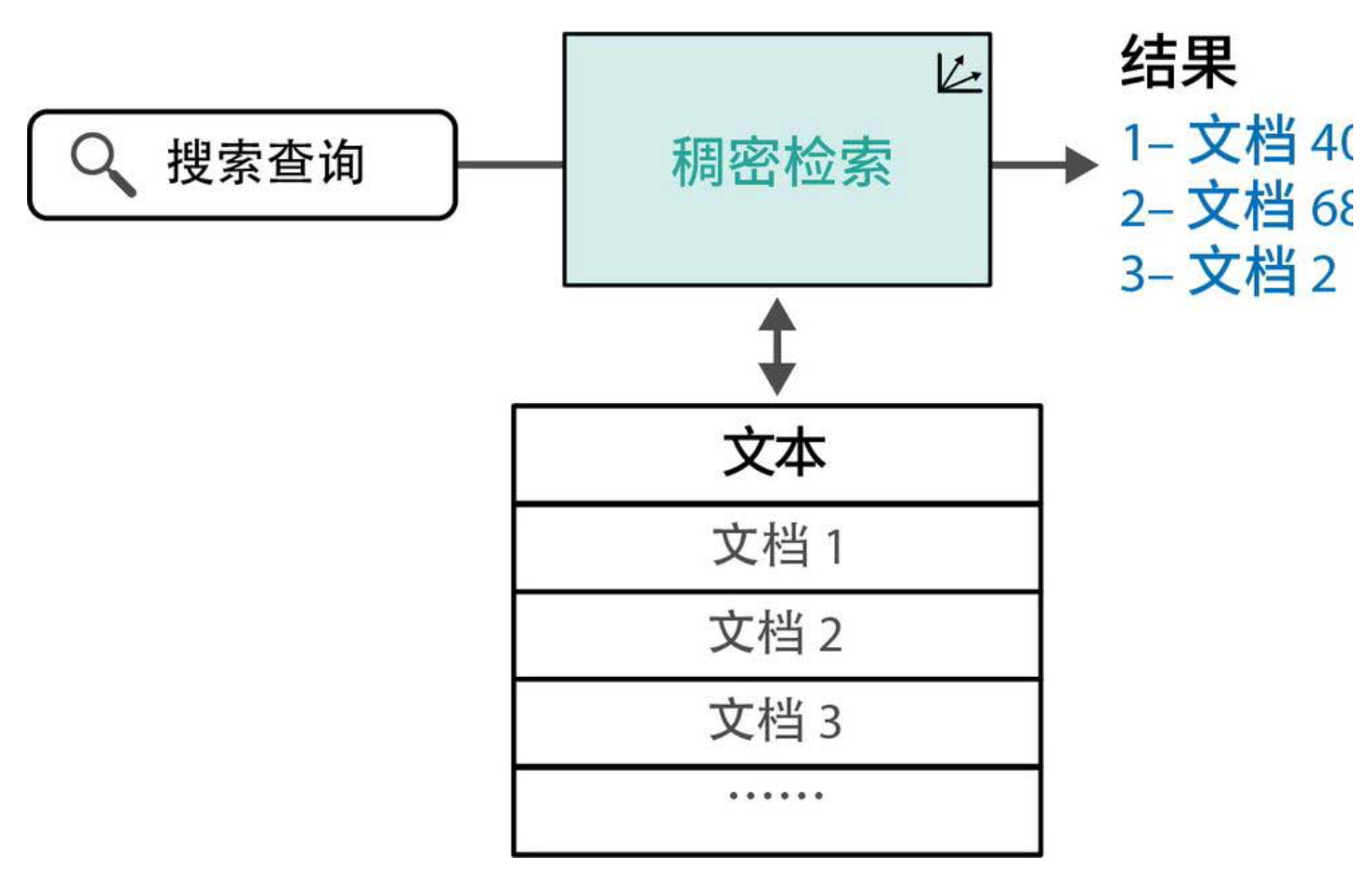
2.2 优点:语义匹配、多语言、容错强
-
语义匹配:能处理同义词、上下位词,比如"轿车"和"汽车"视为相近。
-
多语言支持:不同语言的相似语义也能对齐。
-
容错强:即便查询有错别字,向量可能仍然接近正确文档。
2.3 典型应用
稠密检索广泛用于问答系统、推荐系统、信息检索。例如,在客服系统中,用户问"怎么退货?",系统能匹配到"退换货政策"文档,即使文档中没有"怎么"二字。
三、重排序:给搜索结果来个"精加工"
稠密检索速度快,能快速从百万文档中召回几百个候选,但精度可能不够。这时就需要重排序(reranking)来精细调整。
3.1 为什么需要重排序?
初筛的结果虽然相关,但排序可能不理想。比如,最相关的文档可能排在第三位,而前两个只是部分相关。重排序模型会用更精细的算法(通常也是基于Transformer的交叉编码器)对查询和每个候选文档进行深度交互计算,重新给出相关性分数,然后按分数从高到低排序(见图8-2)。
3.2 流程
-
初筛:用稠密检索或传统关键词检索,快速得到top-N候选。
-
重排:用重排序模型逐一对查询和候选文档打分。
-
输出:按新分数排序,得到最终结果。
3.3 效果
重排序能显著提升搜索结果质量,尤其是当候选集较大时。比如,在学术搜索中,重排序可以把最相关的论文提到最前面,减少用户翻页。
四、RAG:让AI生成答案时"有据可查"
如果说前两项技术让搜索更准,那么**RAG(检索增强生成)**则让AI不仅能搜索,还能生成有事实依据的答案,彻底告别"幻觉"。
4.1 为什么需要RAG?
大语言模型(LLM)如GPT,虽然能流畅对话,但有两个致命缺点:
-
知识截止:训练数据只到某个时间点,无法回答最新问题。
-
幻觉:当不知道答案时,可能会编造看似合理但错误的内容。
RAG的解决思路很简单:在让LLM回答问题前,先从一个知识库中检索出相关的文档片段,然后把问题和这些片段一起作为提示词交给LLM。LLM基于这些事实生成答案,就像开卷考试(见下图)。
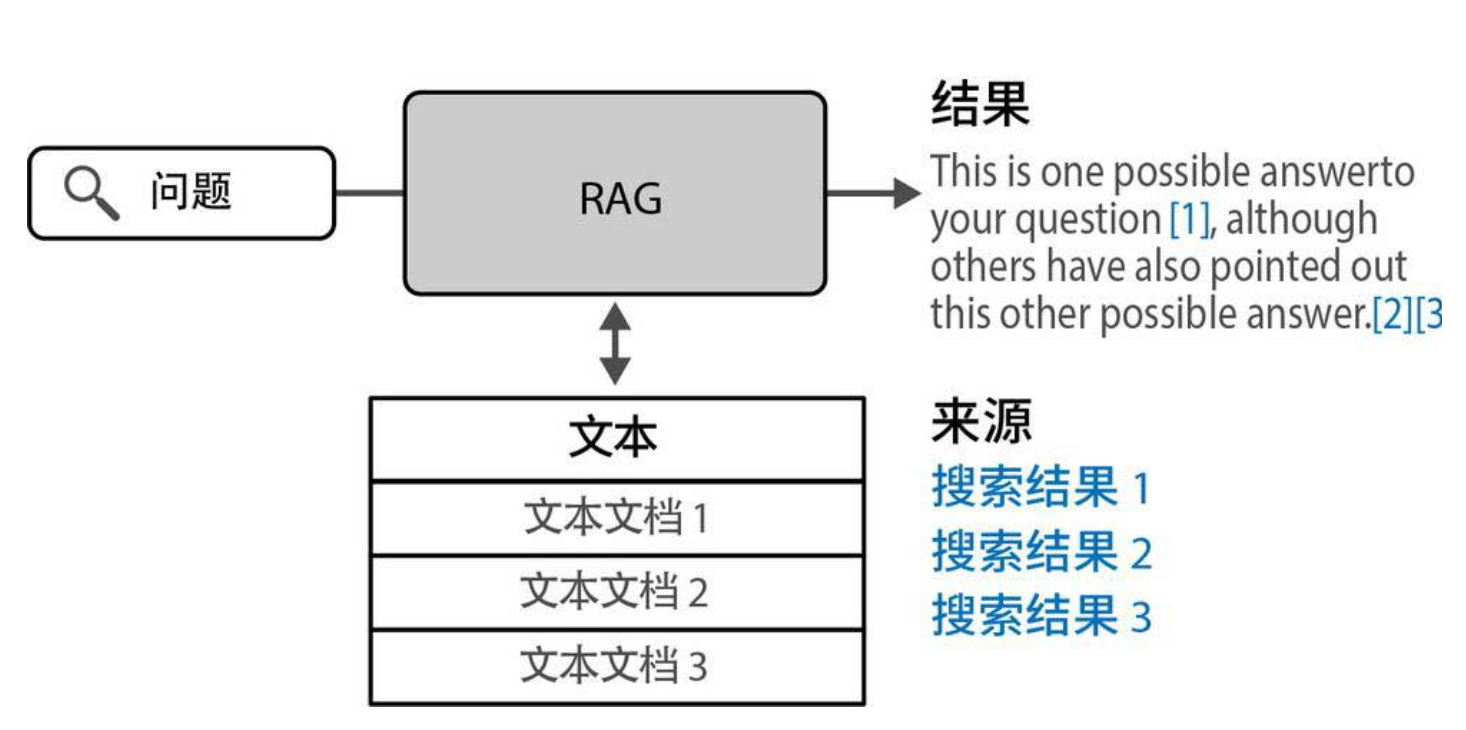
4.2 RAG的典型架构
一个RAG系统包含三个核心模块:
-
检索器:根据用户问题,从知识库中检索出最相关的top-k文档片段。
-
生成器:LLM,接收问题+检索到的文档片段,生成最终答案。
-
融合模块(可选):将检索结果和生成结果结合,甚至可以标注来源。
4.3 优势:可解释、可更新、减少幻觉
-
可解释性:答案可以附带来源链接,用户可以验证。
-
实时更新:知识库可以随时更新,无需重新训练模型。
-
减少幻觉:LLM基于事实生成,编造的概率大大降低。
4.4 案例:智能客服
传统客服机器人遇到没训练过的问题,只能回复"我不知道"。但RAG客服可以实时检索产品手册、帮助文档,然后给出准确答案,还能附上文档链接,用户满意度飙升。
五、三大技术如何协同作战?
在实际系统中,这三者常常组合使用。例如:
-
用户输入问题。
-
稠密检索快速从知识库中召回上百个相关文档片段。
-
重排序从中选出最相关的10个,精细排序。
-
RAG生成器接收问题和这10个片段,生成最终答案,并标注引用。
这种级联架构既保证了速度,又保证了质量,是目前最先进的搜索与问答系统的标配。
六、未来展望:从搜索到知识引擎
语义搜索和RAG正推动着信息获取方式的变革。未来的搜索引擎将不再是"蓝色链接列表",而是直接给出整合多个来源的答案,并能回答复杂推理问题。而RAG将让每个企业都能打造自己的专属AI助手,基于内部知识库提供精准服务。
当然,挑战依然存在:如何提高检索的准确率?如何压缩长文档而不丢失信息?如何防止模型过度依赖检索结果?但这些问题正被研究者们一步步攻克。
总结
语义搜索与RAG技术,正在重新定义我们获取信息的方式:
-
稠密检索:通过向量化文本,实现语义层面的精准匹配。
-
重排序:对初筛结果精加工,让最相关的内容排在前面。
-
RAG:结合检索与生成,让AI的回答既有依据又与时俱进。
这三大技术的融合,让搜索引擎真正理解你的意图,让AI告别"幻觉"。无论你是开发者、产品经理,还是普通用户,理解这些技术都将帮助你更好地利用这个信息爆炸的时代。
本文参考:图解大模型:生成式AI原理与实战
书籍pdf免费下载地址:https://pan.baidu.com/s/1mTaUQ5czcfGpBM8KvJuS2g?pwd=un44