引言
在上篇中,我们了解了BERT的概念和核心------Transformer,并深入拆解了Self-Attention的计算细节,知道了它如何让每个词都能"看到"整个句子。但一个完整的Transformer编码器远不止这些,它还需要解决词的顺序问题、训练稳定性问题,以及如何为具体任务准备数据。今天,我们将继续探索BERT中的位置编码。
一、位置编码:让模型知道词的先后顺序
1、为什么需要位置编码?
Self-Attention机制在设计上存在一个盲点:它本身对词语在序列中的位置完全不敏感。由于该机制仅通过计算词与词之间的语义相似度来分配注意力权重,因此它本质上是将输入视为一个无序的词袋。如果打乱一句话中所有词的顺序,只要词集合不变,Self-Attention的输出结果在数学上将是完全相同的。然而在自然语言中,语序承载着关键的语法和语义信息,例如"我爱你"与"你爱我"虽然词完全相同,但含义截然相反。为了让模型能够理解这种由顺序决定的差异,我们必须为输入序列注入位置信息,使模型能够感知每个词在句子中的具体位置,从而真正捕捉语言的序列特性。
2、两种简单尝试及其问题
在最初研究人员尝试过两种直观的方法:
1、用0~1之间的数字表示位置
将序列中的第一个词赋值为0,最后一个词赋值为1,中间的词按其在句子中的相对比例进行线性插值。例如,在6个词的句子中,第二个词的位置编码约为0.2,而在7个词的句子中则约为0.167。然而,这种方案存在明显缺陷:不同长度的句子中,相同次序的词(如第二个词)对应的编码值并不相同,导致模型无法学习到通用的"第二个词"的位置特征。由于编码值随句子长度变化,模型难以在不同句子之间建立一致的位置对应关系,限制了其对序列顺序的理解能力。
2、用1~n的正整数
直接将每个词在句子中的序号作为其位置编码,例如"我喜欢吃洋葱"这6个词的编码就是1,2,3,4,5,6,而"我真的不喜欢吃洋葱"这7个词的编码则是1,2,3,4,5,6,7。这种方法虽然简单明了,但存在两个主要问题:首先,当句子长度很大时,后面的序号会变得非常大,这些大数值可能会在模型计算中掩盖词向量本身的语义信息,其次,不同句子长度导致编码值的尺度差异很大,模型需要同时处理从1到成百上千的不同数字,这会给神经网络的训练带来不稳定性。
3、三角函数位置编码------完美的解决方案
Transformer的作者提出了一种基于正弦和余弦函数的绝对位置编码方案,通过在不同维度上使用不同频率的三角函数,为每个位置生成一个唯一的向量。这种设计既保证了编码值有界且不随句子长度增长而无限增大,又通过三角函数的和角公式,使得任意位置的编码可以表示为其他位置的线性组合,从而让模型能够轻易地学习到 token 之间的相对位置关系。这一方案解决了朴素编码方法中存在的数值过大、长度依赖以及无法捕捉相对位置信息的问题,成为后续众多 Transformer 系列模型的基础设计选择。
三角函数位置编码的公式为:
对于位置(从0开始)和维度
(从0开始),位置编码PE定义为:
当i为偶数时:
=
当i为基数时:
=
其中,是词向量的维度(比如BERT-base是768)。公式中的分母
会随着i增大而变大,使得正弦函数的频率逐渐降低,从而覆盖从快到慢的变化。
其优势有:首先,三角函数将值域严格限制在-1,1之间,避免了因序列过长而产生极大数值,保证了训练稳定性。其次,不同句子中相同绝对位置(如首个词,pos=0)的编码完全一致,均为0,1,0,1,...,这使得模型能够学习到通用的绝对位置特征。更重要的是,利用三角函数的和角公式,任意位置的编码都可以表示为其他位置的线性组合,从而使模型天然具备捕捉词间相对距离的能力,为理解语言顺序提供了有力的支持。
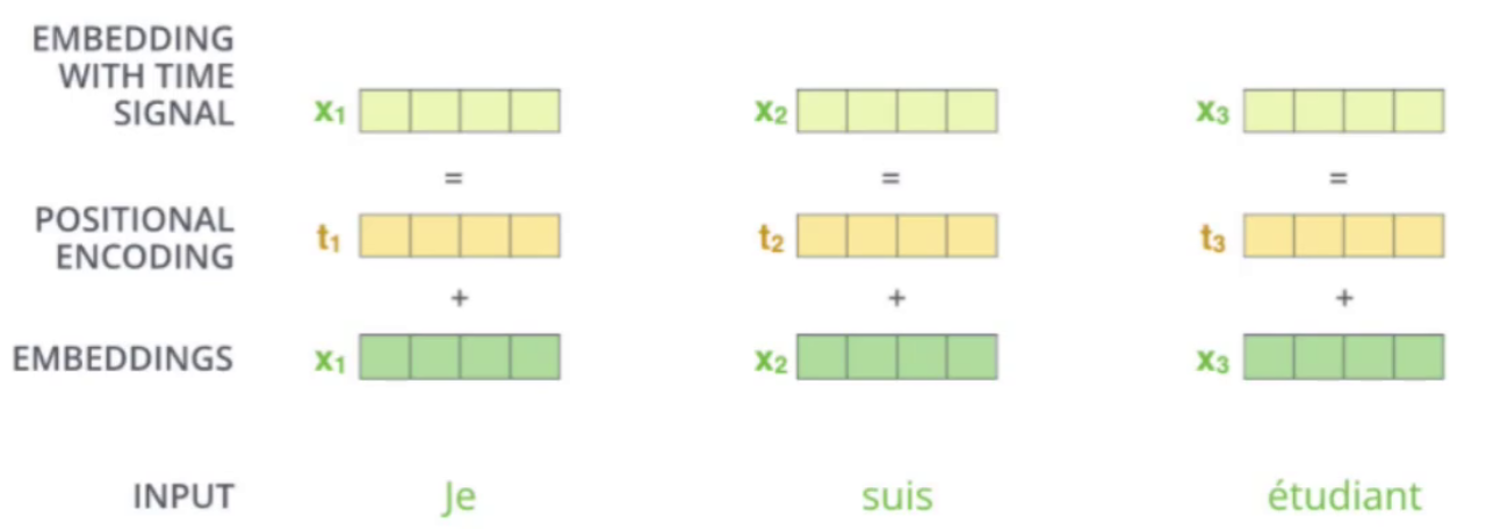
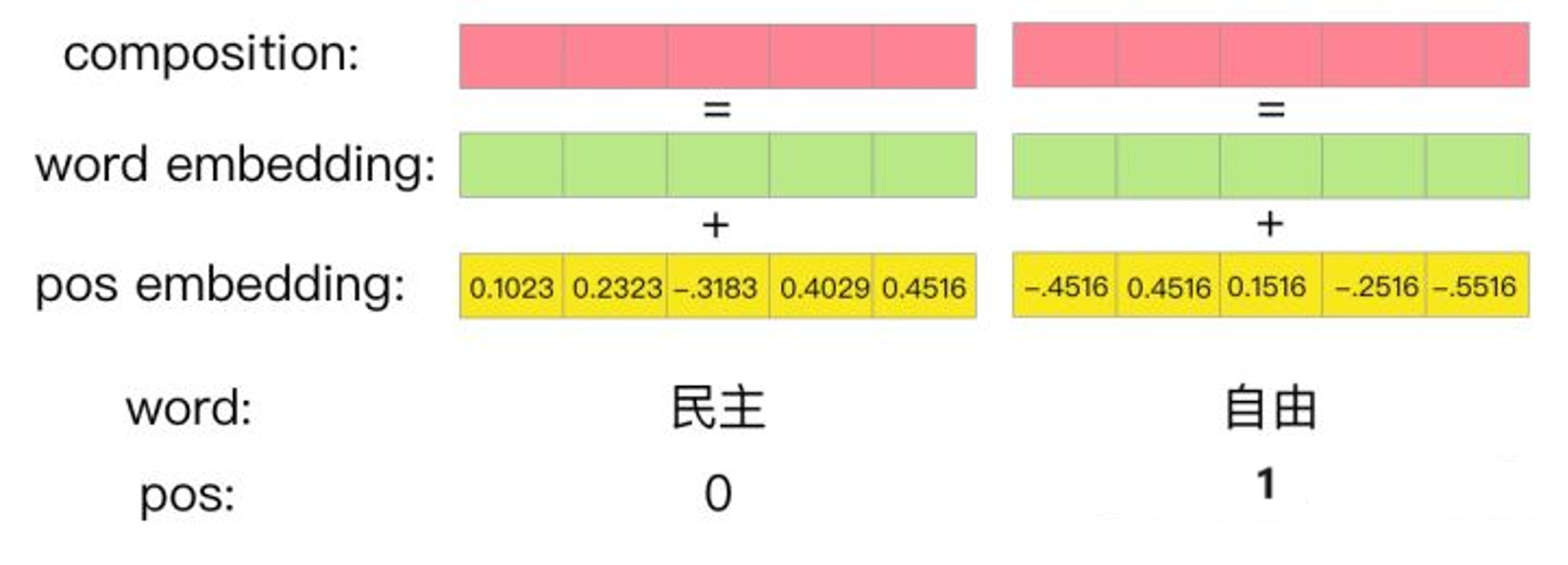
4、组合方式
在Transformer模型中,位置编码与词向量通过逐元素相加的方式进行融合,从而为每个输入词构建一个同时蕴含语义与位置信息的综合表示。这种加法操作将词向量携带的词汇含义与位置编码提供的序列顺序信息巧妙结合于同一向量空间中,使得模型在后续计算中能够同时感知"是什么词"以及"在哪个位置",从而更准确地理解自然语言的语法结构和语义关系。