事物
事务就是一组原子性的SQL查询,或者说一个独立的工作单元。如果数据库引擎能够成功地对数据库应用该组查询的全部语句,那么就执行该组查询。如果其中有任何一条语句因为崩溃或其他原因无法执行,那么所有的语句都不会执行。也就是说,事务内的语句,要么全部执行成功,要么全部执行失败。
为什么需要事物
比如一个银行业务如有借有贷,每有一次借贷业务,需要保证账目上的借方和贷方至少都记上相等的一笔帐,这两笔账要么同时成功,要么同时失败,如果只有一方帐,就会出现记错账的情况.
事物的四大特性
MySQL中的事务(Transaction)是一组操作的集合,这些操作要么全部成功,要么全部失败,是数据库操作的一个基本单位。事务具有四个关键特性,通常被称为ACID特性:
以银行借贷为例:
1.要查看支票账户的余额是否高于转账金额
2.从支票账户余额减去转账金额
3.在储蓄账户余额加上转账金额
原子性
一个事务必须被视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能只执行其中的一部分操作,这就是事务的原子性。
一致性
当事物完成时,数据必须处于一致状态,如在事物开始前数据存储数据处于一致状态,当事物执行的途中数据可能处于不同的状态,但是当事物结束后数据依旧要处于同一状态,比如,当第三条语句执行失败以后,因为事物并没有提交,所以并不会保存到数据库中
隔离性
通常来说,一个事务所做的修改在最终提交以前,对其他事务是不可见的。在前面的例子中,当执行完第三条语句、第四条语句还未开始时,此时有另外一个账户汇总程序开始运行,则其看到的支票账户的余额并没有被减去200美元。后面我们讨论隔离级别(Isolationlevel)的时候,会发现为什么我们要说"通常来说"是不可见的。
持久性
一旦事务提交,则其所做的修改就会永久保存到数据库中。此时即使系统崩溃,修改的数据也不会丢失。持久性是个有点模糊的概念,因为实际上持久性也分很多不同的级别。有些持久性策略能够提供非常强的安全保障,而有些则未必。而且不可能有能做到100%的持久性保证的策略(如果数据库本身就能做到真正的持久性,那么备份又怎么能增加持久性呢?)。在后面的一些章节中,我们会继续讨论MySQL中持久性的真正含义。
隔离级别
在SQL标准中定义了四种隔离级别,每一种级别都规定了一个事务中所做的修改,哪些在事务内和事务间是可见的,哪些是不可见的。较低级别的隔离通常可以执行更高的并发,系统的开销也更低。
读未提交
读未提交是最低的隔离级别,允许事务读取其他未提交事务的修改(脏读)。这种级别牺牲了数据一致性以换取高并发性能,适用于对数据准确性要求极低但需要快速响应的场景(如实时统计近似值),但在多数业务系统中容易导致数据不一致问题。举个栗子:还是以银行借贷为例,
事物1:A要从账户中拿出1000元给B(未提交)
事物2:查看A的账户余额(直接读到A的账户少了1000)
如果事物1突然回滚,资产没有变化,但是事物B已经读到数据并使用了,这就是脏读.
读已提交
读已提交要求事务只能读取其他已提交事务的数据,避免了脏读,但仍可能发生不可重复读(同一事务多次读取结果不同)。这是多数数据库的默认隔离级别(如Oracle),适合允许短期数据变化的场景(如账户余额查询),平衡了性能与一致性需求。
可重复读
可重复读确保同一事务中多次读取同一数据的结果一致,避免了不可重复读,但仍可能发生幻读(范围查询结果变化)。MySQL默认采用此级别并通过"间隙锁"减少幻读。适用于需要事务内数据稳定的场景(如对账操作),但可能增加锁竞争。
串行化(Serializable)
串行化是最严格的隔离级别,通过强制事务串行执行来彻底避免脏读、不可重复读和幻读。其代价是并发性能显著下降,通常仅用于对数据一致性要求极高的场景(如金融交易核验)。实际应用中需谨慎权衡,避免系统吞吐量瓶颈。
查看当前会话隔离级别
sql
mysql> SELECT @@SESSION.transaction_isolation;
+---------------------------------+
| @@SESSION.transaction_isolation |
+---------------------------------+
| REPEATABLE-READ |
+---------------------------------+
1 row in set (0.00 sec)
mysql>查看系统隔离级别
sql
mysql> SELECT @@GLOBAL.transaction_isolation;
+--------------------------------+
| @@GLOBAL.transaction_isolation |
+--------------------------------+
| REPEATABLE-READ |
+--------------------------------+
1 row in set (0.00 sec)
mysql>设置隔离级别
sql
# 设置全局隔离级别
set global transaction isolation level REPEATABLE READ;
set global transaction isolation level READ COMMITTED;
set global transaction isolation level READ UNCOMMITTED;
set global transaction isolation level SERIALIZABLE;
#设置会话隔离级别
set session transaction isolation level REPEATABLE READ;
set session transaction isolation level READ COMMITTED;
set session transaction isolation level READ UNCOMMITTED;
set session transaction isolation level SERIALIZABLE;C语言链接数据库---一种更安全的方式
在之前的学习中我们学习的注入语句mysql_query(),一般来说我们写成这个样子:
sql
// 传统拼接 SQL 的写法(不安全)
char sql[200];
sprintf(sql, "insert into empolyees(name, em_id, dp) values('%s', '%s', '%s')", name, em_id, dp);
// 执行 SQL
mysql_query(conn, sql);但是倘若有人向我们的系统中恶意输入一些构造后的sql语句如:
sql
张三'); delete from empolyees where 1=1; --那么我们的语句就会变成这样
sql
insert into empolyees(name, em_id, dp) values('张三'); delete from empolyees where 1=1; -- ', '123', '技术部');这样执行结果就会变成先向数据库中插入一条张三,然后删除所有的员工信息
这时我们就可以使用预处理语句来使用我们的sql语句
预处理语句
预处理语句(也译作 "预编译语句")是数据库编程中一种安全、高效的 SQL 执行方式,核心思想是将 SQL 语句的 "结构解析" 和 "参数赋值" 分两步进行,而非传统的一次性拼接执行,其流程如下图
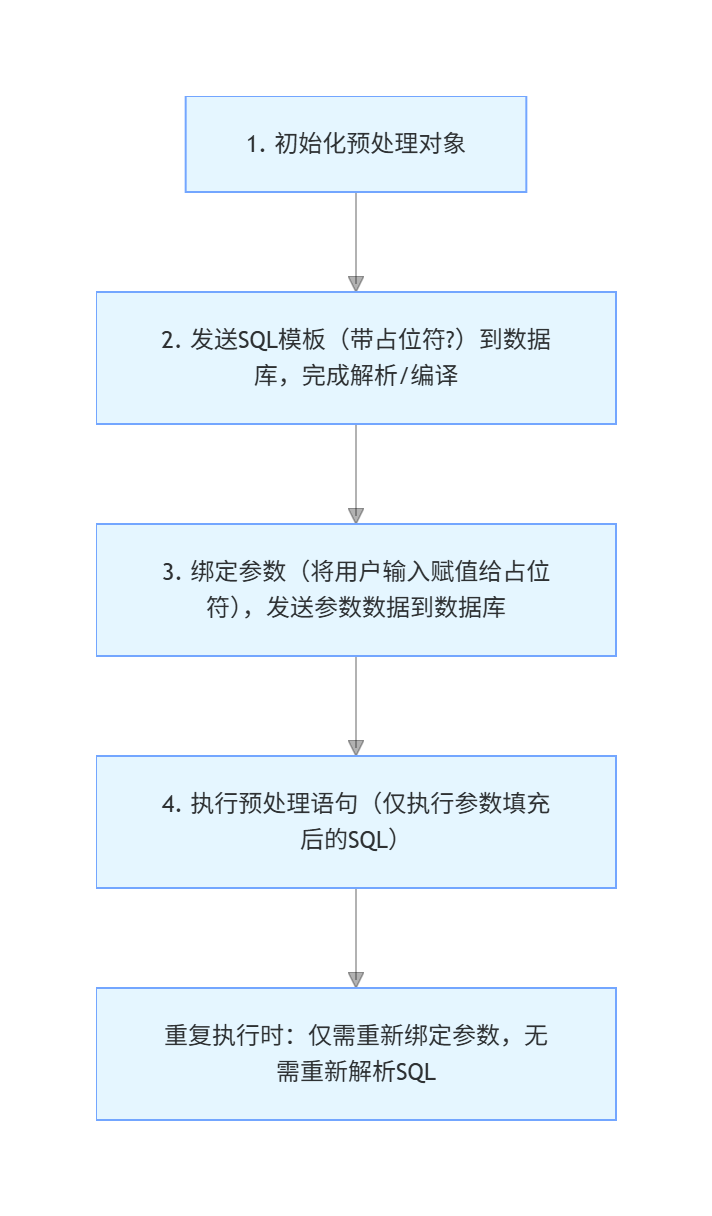
初始化预处理指令
cpp
MYSQL_STMT * stmt=mysql_stmt_init(conn);发送 SQL 模板并解析
cpp
const char *sql = "insert into empolyees(name, em_id, dp) values(?,?,?)";
mysql_stmt_prepare(stmt, sql, strlen(sql)); // 发送模板到数据库解析绑定并发送参数
cpp
mysql_stmt_bind_param(stmt, bind); // 将用户输入的参数绑定到占位符执行语句
cpp
mysql_stmt_execute(stmt); // 执行填充了参数的SQL预处理语句的核心优势
1**. 彻底杜绝 SQL 注入(最核心优势)**
这是预处理语句最关键的价值:
传统拼接 SQL:用户输入的 张三'); delete from empolyees; -- 会被当作 SQL 语法执行;
预处理语句:无论参数中包含什么字符,数据库都只会将其视为 "字符串数据",而非 SQL 指令,从根源上阻断注入。
- 执行效率更高(批量操作时 )
如果需要多次执行结构相同、参数不同的 SQL(比如批量插入 1000 条员工数据):
传统方式:每条 SQL 都要重新解析语法、生成执行计划,耗时久;
预处理语句:仅解析 1 次模板,后续只需传参数执行,节省大量解析时间。
3.简化参数处理
无需手动转义特殊字符(比如把 ' 转成 ''),数据库会自动处理参数中的特殊字符,避免手动转义遗漏导致的安全问题。
预处理语句的适用场景
所有需要接收用户输入的 SQL 操作(增 / 删 / 改 / 查),尤其是插入、更新、查询;
批量执行相同结构的 SQL(比如批量导入数据);
对安全性要求高的场景(如用户登录、数据写入、敏感信息查询)。
例子
下面以实现往员工信息表中插入语句为例:
cpp
int add_empolyees()
{
//声明函数变量
MYSQL *conn; //数据库连接对象
MYSQL_STMT * stmt; //预处理语句对象
MYSQL_BIND bind[3]; //参数绑定数组
//用户输入缓冲区
char name[50];
char em_id[50];
char dp[50];
//声明字符串长度变量
unsigned long name_len;
unsigned long em_id_len;
unsigned long dp_len;
printf("----添加员工界面----\n");
//获取员工姓名
printf("请输入员工姓名:\n");
gets();
fgets(name, sizeof(name), stdin);
name[strcspn(name ,"\n")] = 0; //移除末尾的换行符
//获取员工姓名
printf("请输入员工工号:\n");
fgets(em_id, sizeof(em_id), stdin);
em_id[strcspn(em_id ,"\n")] = 0; //移除末尾的换行符
//获取员工姓名
printf("请输入员工部门:\n");
fgets(dp, sizeof(dp), stdin);
dp[strcspn(dp ,"\n")] = 0; //移除末尾的换行符
//建立数据库的连接
conn = connect_databse();
if(conn == NULL)
return 1;
//定义sql语句,使用?作为参数占位符
const char *sql = "insert into empolyees(name, em_id, dp) values(?,?,?)";
//初始化预处理语句
stmt = mysql_stmt_init(conn);
//准备预处理语句,发送给数据库进行解析
if(mysql_stmt_prepare(stmt, sql, strlen(sql)) !=0 )
{
printf("预处理语句准备失败\n");
//close_database();
return 1;
}
//将参数绑定数组清空
memset(bind ,0 ,sizeof(bind));
//绑定姓名信息
name_len = strlen(name);
bind[0].buffer_type = MYSQL_TYPE_STRING; //指定参数类型为字符串
bind[0].buffer = name; //指定数据缓冲区
bind[0].buffer_length = sizeof(name); //指定数据缓冲区大小
bind[0].length = &name_len; //指定字符串长度指针
//绑定工号信息
em_id_len = strlen(em_id);
bind[1].buffer_type = MYSQL_TYPE_STRING; //指定参数类型为字符串
bind[1].buffer = em_id; //指定数据缓冲区
bind[1].buffer_length = sizeof(em_id); //指定数据缓冲区大小
bind[1].length = &em_id_len; //指定字符串长度指针
//绑定部门信息
dp_len = strlen(dp);
bind[2].buffer_type = MYSQL_TYPE_STRING; //指定参数类型为字符串
bind[2].buffer = dp; //指定数据缓冲区
bind[2].buffer_length = sizeof(dp); //指定数据缓冲区大小
bind[2].length = &dp_len; //指定字符串长度指针
//将参数设置到预处理语句中
if(mysql_stmt_bind_param(stmt, bind) !=0)
{
printf("参数绑定失败\n");
mysql_stmt_close(stmt);//关闭预处理语句
//close_database();
return 1;
}
//将准备好的预处理语句发送给数据库实现功能
if(mysql_stmt_execute(stmt) !=0)
{
printf("预处理语句插入失败\n");
mysql_stmt_close(stmt);//关闭预处理语句
//close_database();
return 1;
}
printf("员工信息添加成功!\n");
//释放资源
mysql_stmt_close(stmt);//关闭预处理语句
//close_database();
return 0;
}