前提背景:我们这里讲解aof的,rdb基本思路是一样的,这里是为了解决我们的项目mini-redis项目当中,多线程命令写入,而导致重写过程当中出现数据不一致问题
我们执行命令存数据到内存当中采用的是多线程的方案,所以导致我们aof重写的过程当中出现问题,我们不能直接像原生redis那样直接fork子进程,由于原生redis整个命令处理的过程是单线程,只是io部分可能采用多线程,所以可以直接fork子进程,并且维护复杂度比较低,这里我们命令处理采用了多线程,如果直接fork子进程会导致死锁等问题,最简单的解决方案就是:加全局锁,遍历全局数据,这样会导致阻塞,数据越多阻塞越严重并且会OOM,os会杀掉进程,导致全部崩溃
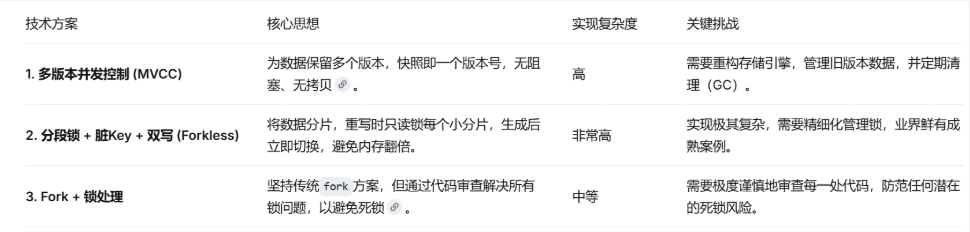
基于以上:我们将提出三种行业当中的解决方案:Multi-Version Concurrency Control(多版本并发控制)
- 全局版本号一个原子自增的数字,每次 ** 写操作(SET/DEL/HSET)** 就 + 1。
- 每个 key 存「版本链」 不是存一个值,而是存一串历史版本,最新的在头部。
- 读 / 快照 = 读「指定版本号之前」的数据 比如快照版本是
100,就只读取版本号≤100的最新数据,后面的修改完全看不见。数据会变多,但是增幅基本在百分之5到百分之30,后台可以开一个gc线程,当重写完之后,旧的版本就不需要维护了,直接删掉,这个方案是目前大厂的主流方案
Forkless 技术深度解析:美团工业级无 fork 快照实现
Forkless 的本质是用应用层的 "软快照" 替代操作系统的 "硬快照",遵循四大核心原则:
- 不创建子进程:彻底规避 fork 带来的所有问题
- 不阻塞主线程:锁持有时间控制在微秒级
- 100% 强一致性:快照数据与 fork 瞬间快照完全等价
- 内存不翻倍:只存储必要的增量数据,无全量拷贝
**前置准备:**分片化数据结构
Forkless 必须基于分片存储实现,这是保证锁粒度极细的基础:
- 将所有 key 分成 N 个独立分片(通常为 CPU 核心数的 2-4 倍)
- 每个分片有自己的独立哈希表和独立锁
- 不同分片的操作完全互不干扰
**阶段 1:**触发快照,停止 rehash
哈希表 rehash 会导致 key 在两个哈希表之间搬迁,如果快照期间发生 rehash,游标遍历会出现漏 key 或重复 key,破坏一致性。
阶段 2:后台线程分段拷贝存量数据
锁持有时间 :每次只锁一个分片,拷贝 1000 个 key,耗时约 10-100 微秒,主线程完全无感知。
**阶段 3:**全程追踪脏 key(核心一致性保障)
在整个阶段 2 分段拷贝期间,主线程的所有写操作都会自动记录被修改的 key:
脏 key 定义 :在分段拷贝期间被修改过的 key。这些 key 在快照文件中的值是旧值,需要后续修正。
**阶段 4:**原子补拷脏 key(一致性闭环)
当全部分段拷贝完成后,执行原子补拷操作
为什么这一步能保证一致性?
- 全局锁保证:补拷期间没有任何新的写操作
- 补拷完成后,快照文件中的所有 key 都是补拷瞬间的最新值
- 这一步的耗时与脏 key 数量成正比,通常在 1-10 毫秒 以内
**阶段 5:**生成最终快照,原子替换
Forkless 快照与
fork+COW快照完全等价,证明如下:
- 设
T1为分段拷贝开始时间,T2为原子补拷开始时间- 对于在
[T1, T2]期间没有被修改 的 key:分段拷贝时已经写入快照,值为T1时刻的值- 对于在
[T1, T2]期间被修改 的 key:被标记为脏 key,在T2时刻被补拷最新值- 最终快照 = 所有 key 在
T2时刻的最新值- 这与
fork在T2时刻生成的内存快照完全一致
cpp1. 开始重写:后台线程标记所有分片的 in_snapshot=true,初始化脏 keyset 2. 分段拷贝: a. 遍历每个分片 b. 加该分片的锁,拷贝该分片的当前数据,转换成最终值格式的命令写入新 AOF c. 立刻释放该分片的锁 d. 其他分片的写操作完全不受影响,写的时候顺便记录脏 key 3. 原子补拷: a. 加极短的全局锁 b. 遍历脏 keyset,把每个 key 的最新值转换成最终值格式的命令写入新 AOF c. 释放全局锁 4. 完成: a. 刷盘新 AOF 文件 b. 原子 rename 替换旧 AOF 文件 c. 重置所有分片的 in_snapshot=false,清空脏 keysetfork+锁处理(压根不可能)
父进程是多线程(A,B,C等等),线程A执行写操作,此时拥有锁,线程abc共享一个虚拟地址空间,共享内存当中锁的状态被记录为1,并且锁的持有者是线程A,但是线程B去执行重写,此时fork子进程,但是fork的子进程是去复制B的虚拟地址空间,那子进程的锁已经被锁上了,并且锁的持有者还是A,但是在子进程当中并没有其他线程,当然也不会有其他线程来解锁,锁无人拥有,变成了僵尸锁,那子进程就会一直尝试加锁,此时就会造成死锁
代码里的"明锁" :当
fork发生时,如果服务器其他工作线程正持有着代码里定义的互斥锁(比如KeyValueStore::_mutex),子进程会完完整整地复制这把锁被"锁定"的状态。但在子进程里,那个原本能解锁的线程已经"蒸发"了。这就像子进程继承了一间全是锁的房间,但钥匙都在消失的人手里。一旦子进程需要写入文件、分配内存,尝试获取被锁住的资源,就会立刻进入无限期的等待,也就是死锁。标准库里你看不到的"暗锁" :更危险的是那些隐藏在标准库里的锁。比如常见的
printf或malloc,也可能在特定时机持有你完全看不到的内部锁。这意味着,哪怕你确保自己的代码释放了所有锁,子进程仍然可能在调用看似无害的printf或new时意外死锁,排查难度极大。两种思路:
1:直接不采用任何隐形加锁的函数(包括自己的锁和任何库函数当中的锁),直接采用原生函数把内存当中的数据进行写入内存即可
- 太难保证"绝对不使用锁"。在一个大型 C++ 项目中,几乎不可能完全避免标准库的隐式锁。即使当前代码安全,也容易在后续维护中引入新问题。
2:处理锁,可以创建一个专门的后台线程,在
fork()即将发生时,它负责触发一个全局的"同步点",确保所有其他线程都完成了当前操作、释放了所有锁。当一切就绪,这个线程再安全地执行fork()。基本上是采用函数pthread_atfork(),
- fork 前:帮你加你的锁
- fork 后:父进程解锁你的锁
- fork 后:子进程重置你的锁
但是无法解决隐式锁,因为libc 开发人员没有给这些隐式锁注册 pthread_atfork,你只能解决全局的mutex等锁
所以两种思路基本大厂都不会采用,也就是直接规避多线程下fork子进程的风险
多线程redis下如何解决aof重写和rdb持久化的数据一致性问题
June`2026-05-22 17:03
相关推荐
这个DBA有点耶1 小时前
NULL不是空——数据库里最反直觉的设计,90%新人踩过的坑这个DBA有点耶3 小时前
AI写的SQL跑崩了生产库,这锅谁背?镜舟科技3 小时前
Databricks 再提 LTAP,AI 时代的数据底座为何重回大一统叙事?Databend4 小时前
从湖仓升级为 Agent 时代的数据控制面,Snowflake 和 Databricks 有哪些布局ClouGence8 小时前
SQL Server CDC 能放到 Always On 备库读吗?一文讲透原理与实践先吃饱再说1 天前
存储的进化:从 MySQL 到浏览器缓存,数据到底住在哪?Nturmoils1 天前
字段太多看不全,ksql 的展开模式和输出控制怎么用Databend1 天前
Agent 轨迹分析与归因的数据工程实践这个DBA有点耶1 天前
SQL改写进阶:标量子查询的“隐形代价”与消除实战smallyoung1 天前
数据库乐观锁深度解析:MySQL、PostgreSQL 实战 + Spring Boot 集成指南