MySql"存储引擎"与操作系统的"文件系统"
文件系统 :数据在磁盘上如何存储和管理
存储引擎 :数据在数据库 层面应该如何存储和管理
基本数据存、取:数据库事务、锁、数据备份、恢复、优化...
决定存储方式,库相当于目录没有指定存储引擎
InnoDB :数据存在**.ibd**文件中(聚簇索引结构,数据和主键索引绑定) 默认存储引擎
MyISAM : 数据存在**.MYD文件,索引存在.MYI**文件(数据和索引分离)
CSV :以逗号 为字段分隔符的纯文本文件 *.csv (Excel可以直接存为csv格式文件,直接导入到mysql)
存储引擎
InnoDB 存储引擎(默认)
1、支持完整的事务: 可通过COMMIT/ROLLBACK****回滚 ,适合金融、订单等核心业务
银行转账:A ->B(A-100,A流水,B+100,B流水)
出错=>先回滚 ->提醒
2、行级锁+表级锁: 支持行级锁(只锁修改的行),并发读写效率高(比如 100 人同时改不同订单,互不影响)
3、支持外键约束 , 且崩溃后可通过 redo/undo 日志恢复数据,保证数据不丢失
适用场景: 99% 的业务场景(电商、金融、社交)
MyISAM 存储引擎
1、高性能读操作
在执行简单查询时速度通常比InnoDB快(因为它没有事务和行级锁带来的额外开销)
2、表级锁: 只有表级锁(改一行锁整张表),并发写时性能极差(比如改 1 行数据,整张表都不能读 / 写)
3、不支持 外键约束和事务处理, 崩溃后可能出现数据损坏,需手动修复(myisamchk工具)
适应场景:以查询为主的系统(仓库系统,文本类型的)
常用命令
show engines;

SELECT @@DEFAULT_STORAGE_ENGINE;
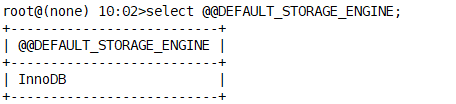
SHOW TABLE status like "course"\G; //查看表状态
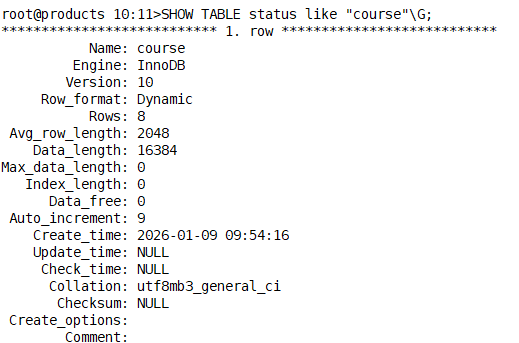
SELECT engine FROM tables GROUP BY engine; //查询当前 MySQL 实例中所有表使用的存储引擎,并按引擎类型分组展示

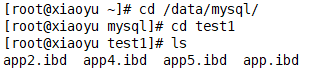

指定该表使用 MyISAM 存储引擎
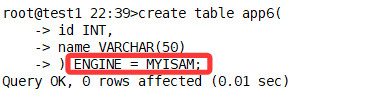
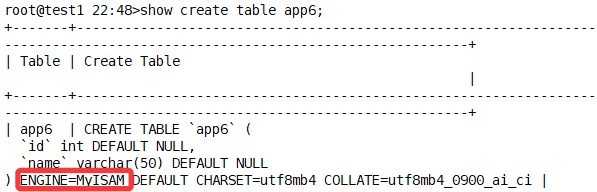
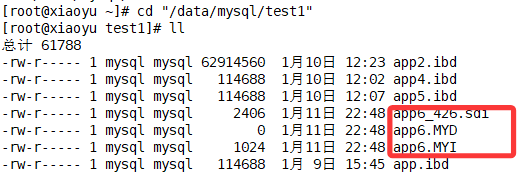
.MYD:存储表的数据内容
.MYI:存储表的索引信息
.sdi文件 : 表结构元数据文件
===============================================
MySql索引
索引 -> 目录 -> 通过目录信息帮助快速找到想要的数据
如果没有索引 ,查找数据 => 全表扫描
优:1、提升查询速度
2、降低磁盘I/O次数 (按索引字段对数据进行排序)
3、有助于服务器避免进行排序和使用临时表
缺:1、增加存储成本
2、降低写入性能(写入数据时,同步要更新索引数据)
3、索引可能失效(id,WHERE price 没用上)
索引的底层结构
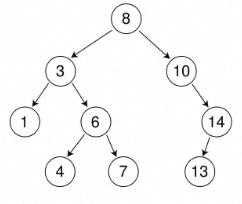
二叉搜索树
1、每个节点最多有2个子节点
2、任何节点左子节点都小于当前节点,右子节点都大于当前节点
二叉搜索树,能够有效地提升查找效率,但是:在某些情况下,树可能变成链表,层级非常多,无法提升查询效率(只有左子树或只有右子树),这种情况,树不平衡
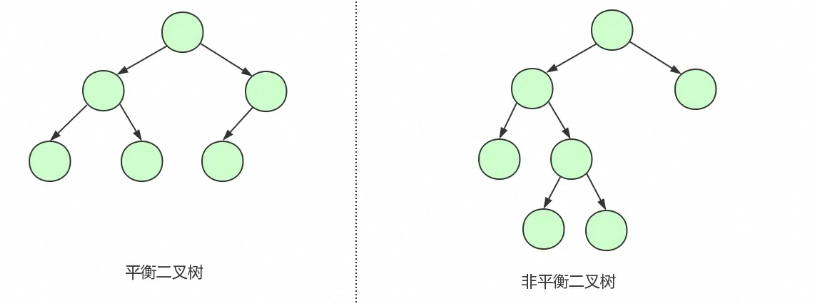
AVL树(平衡二叉树)
1、每个节点最多有2个子节点
2、任何节点左子节点都小于当前节点,右子节点都大于当前节点
3、每个节点的左右字数的高度差不能超过1(会自动调整)
数据量如果特别大时
B+Tree
找一种单节点 可以存储多个键值数据的平衡树
1、每个节点都可以有多个子节点(m>=2)
B+tree当max-degree=3
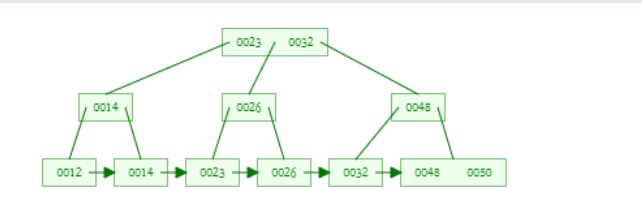
B树
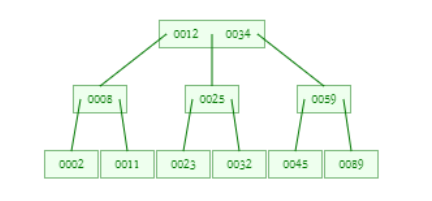
B-树:
节点存储内容:内部节点和叶子都存储数据
叶子节点结构:叶子节点没有直接连接
插入删除数据:可能影响多个层级的节点
使用场景:精确查询,不适合范围查询
B+树:
节点存储内容:内部节点内部只存储键值,叶子节点存储数据
叶子节点结构:叶子节点形成链表,支持快速遍历
插入删除数据:主要集中在叶子节点,稳定性好
使用场景:精确查找,范围查询性能都很好
========================================
创建索引-->create index 索引名 ON 表名 (列信息);
主键索引:创建主键
唯一索引:创建UNIQUE
普通索引:创建表时创建
联合索引:(多列索引)
CREATE TABLE 表名(
字段1 字段类型 ...,
字段2 字段类型 ...,
INDEX index_name 字段信息
)
create table test_index( tid INT NOT NULL, username CHAR(4), age INT, INDEX idx_age (age) );
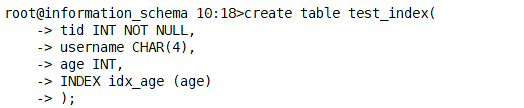
给test_index表的age字段创建名为idx_age的普通索引
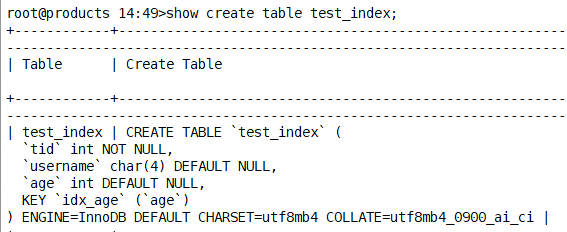
表已经创建好了,需要再增加索引
1、create index 索引名 ON 表名 (列信息);
create table test_index2(tid INT NOT NULL, username CHAR(4), age INT);
create index idx_age ontest_index2(age);
2、alter table 表名 add index 索引名(字段);
alter table test_index2add index idx_username(username);
show create table test_index2\G;
注:一般建议创建表的时候将索引创建好,如果表中的数量特别多时,创建索引会消耗很多时间
创建唯一索引
create unique index 索引名 on 表名 (字段);
show create table test_index2\G;
alter table 表名 add unique index 索引名(索引字段);
注:添加unique index时注意,如果数据库中有数据时,需要确保字段的值不能有重复,否则会创建失败
主键索引 (没有create创建)
ALTER TABLE 表名 ADD PRIMARY KEY 索引名(索引字段)
create table test_index3(tid INT NOT NULL, username CHAR(4), age INT);
alter table test_index3 add primary key idx_tid(tid);
多列索引
create index idx_name on table_name (列1,列2...)
alter table table_name add index idx_name(列1,列2...)
由多列组成的索引 ,在查询的时候,需要将第1列索引作为查询字段
例:create index idx_pname_price on product (pname,price);
查看方式:1、show create table product\G;
2、show index from product;
使用索引:创建索引时:如果数据库中有数据,确保数据符合索引要求
查询时:条件查询,条件参数必须包含第一个索引字段(使用EXPLAN、SELECT语句)
EXPLAIN****是 MySQL 提供的 "索引诊断工具",能直观告诉你 SQL 语句是否用到了索引、用了哪个索引、以及索引的使用效率如何。
执行EXPLAIN + SQL 后, 直接反映索引的使用状态
EXPLAIN SELECT * FROM product WHERE pid = 1;
删除索引-->drop index index_name on table_name;
drop index index_name on table_name;
drop index idx_pname_price on product;
MyISAM存储引擎 =>以读为主的数据库
从MySql5.6版本开始Innodb和MyISAM都支持
创建全文索引 FULLTEXT INDEX(仅适用于文本类型字段 CHAR/VARCHAR/TEXT)
create fulltext index idx_name on table_name(col);
alter table table_name add fultext index idx_name(col);
create table test_index5(tid INT NOT NULL, username CHAR(4), age INT) ENGINE=MyISAM;
create fulltext index idx_name on test_index5(name);

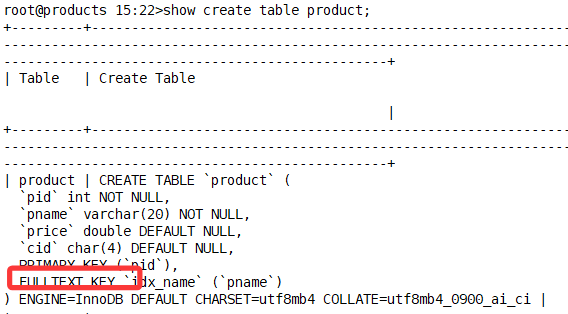
验证现有索引
show index from product;