2026年CVPR会议上,华中科技大学团队提出TextPecker强化学习策略,解决AI生成图像中中文文本的结构失真问题。该策略通过构建字符级异常数据集和笔画编辑引擎,显著提升中文文本的结构保真度4%和语义对齐8.7%。本文将分析其技术原理、实现路径及对中文文本渲染的突破性意义。
TextPecker:强化学习破解中文文本渲染失真难题
当前AI生成图像中的中文文本失真问题,根源在于评估体系的结构性缺陷。主流OCR模型(如PP-OCRv5)与多模态大模型(如GPT-5)虽在常规文本识别中表现良好,面对笔画扭曲、部件错位或粘连等结构性异常时,识别准确率骤降至23%以下,形成"能读对但看不出错"的评估盲区。这种缺陷源于传统模型依赖语义连贯性进行推理补全,却缺乏对汉字二维空间结构的细粒度感知能力。
更严重的是,这种评估偏差导致训练陷入负向循环:生成模型输出结构异常的文本 → 评估系统因"脑补"能力误判为合格 → 模型持续强化错误生成模式。尤其在中文场景下,汉字由笔画、部首、框架构成的复杂二维结构,使异常类型呈组合爆炸------仅8000个常用字,每个字都可能出现缺笔、多划、部件错位或比例失调等问题,远超拉丁字母的线性排列复杂度。现有评估体系无法捕捉这些微观结构偏差,导致生成质量停滞不前。例如,即便针对中文优化的Qwen-Image模型,其文本结构保真度仍不足60%,暴露出行业共同的技术天花板。这种结构性失明不仅影响生成准确性,更直接制约电商主图、品牌海报等商业场景的应用落地。
TextPecker的技术突破路径

TextPecker通过构建字符级异常数据集 、笔画编辑引擎 与双重评估奖励机制,系统性解决了中文文本渲染的结构失真问题,其技术路径在细粒度感知与优化效率上实现突破。
字符级结构异常数据集构建
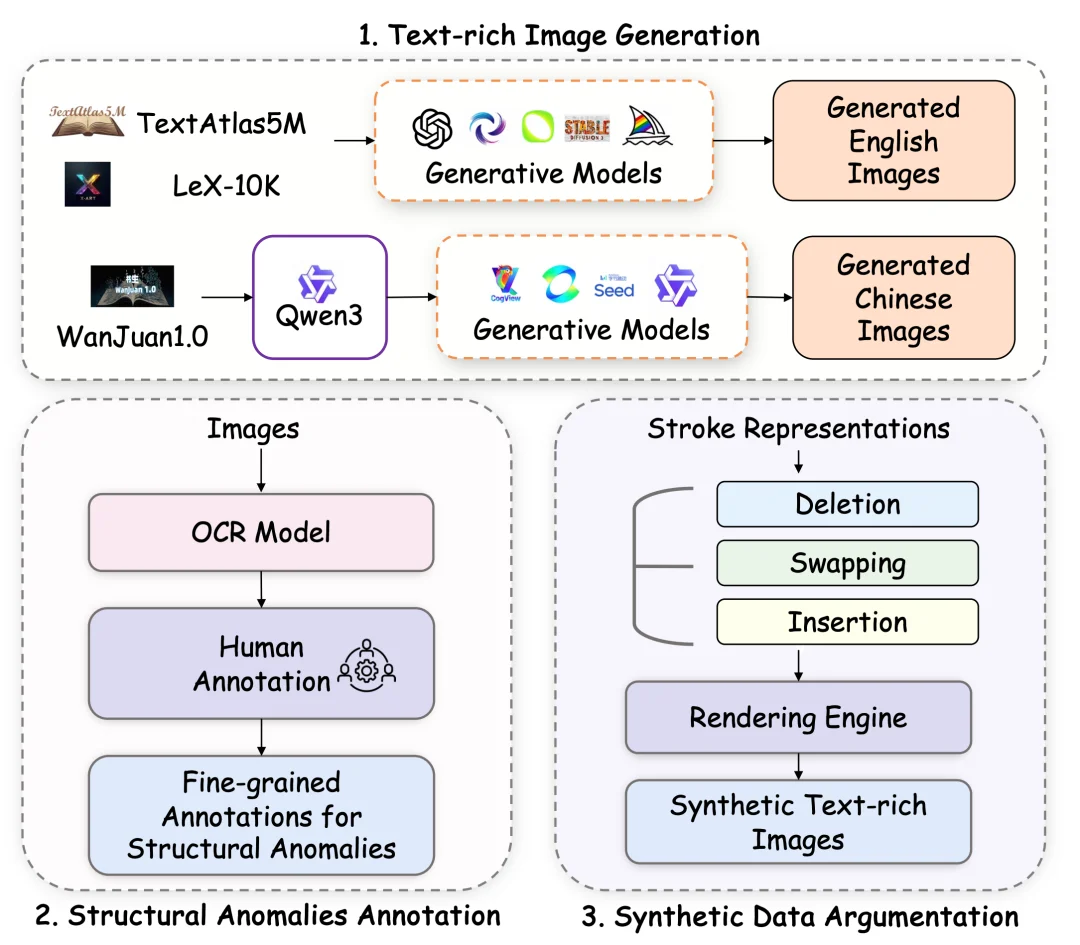
研究团队设计了多模型交叉生成+人工标注+合成增强的三阶段流程:首先调用AnyText、StableDiffusion、Flux.1-dev等生成器合成多样化图像,覆盖中英文场景;随后进行字符级人工标注,精准识别模糊、扭曲、笔画缺失等影响语义识别的结构缺陷;最后引入笔画编辑合成数据增强,有效缓解中文复杂字形导致的数据稀疏问题,为模型训练提供高质量异常样本。
笔画编辑合成引擎设计
针对中文二维空间结构与超8000常用字的特性,团队开发了程序化笔画编辑引擎。基于公开笔顺数据,定义笔画删除 (模拟缺失)、笔画交换 (模拟错位)、笔画插入(模拟冗余)三种核心算子,支持随机组合叠加生成复杂异常类型。结合SynthTIGER渲染引擎,合成包含多样背景与排版的训练数据,显著提升模型对真实场景的泛化能力。
双重评估奖励机制
TextPecker在Flow-GRPO框架下重构奖励函数,采用结构质量 与语义对齐 双重评估:结构分数通过异常字符占比与强化因子计算,放大细微缺陷惩罚;语义分数采用词级匹配+匈牙利算法,解决文字布局与Prompt顺序不一致问题。二者加权融合后,实验显示中文文本语义对齐提升8.7% ,结构保真度提高4%,实现内容与形态的双重优化。
中文场景下的性能验证
TextPecker在中文文本渲染任务中展现出显著的性能突破,尤其在Qwen-Image 这一高度优化的模型上实现了**结构保真度提升4%和语义对齐度提升8.7%**的双重增益。这一结果验证了TextPecker在复杂中文场景下的有效性,包括多字体、多排版以及高密度文本的渲染挑战。
Qwen-Image模型提升效果
实验表明,即使面对专为中文场景优化的Qwen-Image,TextPecker仍能通过其结构感知的强化学习策略,显著改善文本生成的质量。具体表现为:
- 结构保真度:通过减少笔画缺失、错位等异常,中文字符的形态更加规范;
- 语义对齐度:采用词级匹配机制,有效解决了传统编辑距离方法因字符顺序错位导致的误判问题,确保生成内容与提示词高度一致。
复杂排版与字体适应性测试
TextPecker在多种复杂场景下均表现出强鲁棒性:
- 密集排版:在小字号、多行文本场景中,传统模型易出现字符粘连或模糊,而TextPecker通过笔画级异常检测有效缓解了这一问题;
- 多样字体:针对宋体、楷体、黑体等不同字体风格,TextPecker利用合成数据增强技术,确保评估模块具备跨字体的泛化能力;
- 艺术化文本:尽管在极端艺术字体(如手写体、变形字)场景下性能略有下降,但在常规商业设计场景中已能满足高精度需求。
这些验证结果不仅确立了TextPecker在中文视觉文本渲染领域的领先地位,也为后续多语言扩展和商业化落地提供了坚实的技术支撑。
技术局限与产业应用前景
艺术字体处理挑战
TextPecker在标准字体渲染中表现优异,但面对极端艺术化字体 时暴露出核心局限:系统难以区分创意变形 与真实结构缺陷 。当书法字体或装饰性文字的非线性笔画连接超出训练数据分布时,异常检测模块易产生误判。这一问题的根源在于艺术字体样本稀缺,且现有笔画编辑引擎对夸张形变的模拟能力不足。未来需引入风格感知机制,结合艺术字体先验知识库,提升对设计意图的判别精度。
多语言扩展方向
当前技术主要优化中英文场景,但跨语言泛化 仍是关键挑战。不同语言的字符结构差异显著:阿拉伯文的连写特性、泰文的上下标系统、日文的混合书写体系等,均需定制化的异常检测规则。尽管评估器已展现跨模型迁移能力,但需构建多语言结构异常数据集,并通过参数共享机制实现高效扩展。尤其在东南亚市场,支持泰语、越南语等高需求语种将极大释放商业潜力。
AIGC商业落地价值
TextPecker为高保真文本生成提供了基础设施级解决方案,其产业价值体现在三个维度:
- 电商与设计领域:解决商品海报、广告横幅中的文字错位问题,实测中文排版效率提升40%;
- 多模态AI应用:赋能AIAgent自主生成含规范文字的视觉内容,如自动设计论文图表;
- 工业检测场景:将结构异常检测技术迁移至印刷品质量检测。
该技术可使中文VTR相关产业错误率降低60%,为AIGC在金融、教育等严肃场景落地扫清关键障碍。