深入理解 Kafka 分区策略:从原理到实践
摘要:分区策略是 Kafka 高性能、高可用架构的核心设计之一。本文系统解析 Kafka 分区机制、内置策略演进、自定义实现方法及实战选型指南,助你精准掌控消息路由逻辑。
一、为什么分区策略至关重要?
在 Kafka 中,主题(Topic)被划分为多个分区(Partition),这是实现:
- ✅ 水平扩展(多 Broker 并行处理)
- ✅ 高吞吐(生产/消费并行化)
- ✅ 分区内严格有序(关键业务保障)
- ✅ 容错能力(副本机制基础)
而分区策略(Partitioner) 决定了每条消息被路由到哪个分区。选错策略可能导致:
⚠️ 数据倾斜(热点分区)
⚠️ 顺序性破坏
⚠️ 吞吐下降
⚠️ 消费延迟
二、Kafka 内置分区策略详解(附版本演进)
📌 DefaultPartitioner(默认策略|partitioner.class 未配置时生效)
| 消息特征 | Kafka < 2.4 行为 | Kafka ≥ 2.4 行为(关键优化) |
|---|---|---|
| 有 Key | murmur2(key) % 分区数 |
同左(保持一致性) |
| 无 Key | 简单轮询(Round-Robin) | Sticky Partitioning(粘性分区) |
🔍 粘性分区(Sticky Partitioning)原理
- 连续消息优先发往同一分区 ,直到:
- 达到
batch.size(默认 16KB) - 超过
linger.ms(默认 0ms)
- 达到
- 优势:减少网络请求次数,提升批处理效率,实测吞吐提升 15%~30%
- 注意:仅作用于无 Key 消息;有 Key 消息仍按哈希路由
🔄 其他内置策略(需显式配置)
# 轮询所有消息(含带 Key 消息!慎用)
partitioner.class=org.apache.kafka.clients.producer.RoundRobinPartitioner
# 均匀粘性分区(Kafka 3.3+)
partitioner.class=org.apache.kafka.clients.producer.UniformStickyPartitioner⚠️
RoundRobinPartitioner会破坏 Key 的顺序保证,仅适用于完全无序场景。
三、何时需要自定义分区策略?
当业务有特殊路由需求时:
- 🌍 按地域分区(如:华东用户 → 分区0,华北 → 分区1)
- 📅 按时间窗口分区(如:每小时切换分区)
- 🎯 保证关联数据同分区(如:订单与支付消息需同分区)
- 📊 避免哈希倾斜(如:某些 Key 频率极高)
四、自定义分区器实战(Java 示例)
步骤 1:实现 Partitioner 接口
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
import java.util.concurrent.ThreadLocalRandom;
public class RegionBasedPartitioner implements Partitioner {
private static final String REGION_KEY = "region";
@Override
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
// 1. 获取可用分区(排除无 Leader 的分区)
List<PartitionInfo> partitions = cluster.availablePartitionsForTopic(topic);
int numPartitions = partitions.size();
if (numPartitions == 0) throw new RuntimeException("No available partitions");
// 2. 业务逻辑:从消息 value 中提取 region(示例简化)
String region = extractRegionFromValue(value); // 需自行实现解析逻辑
// 3. 按 region 映射分区(示例:哈希取模)
if (region != null && !region.isEmpty()) {
return Math.abs(region.hashCode()) % numPartitions;
}
// 4. 降级策略:无 region 时使用粘性逻辑(参考 DefaultPartitioner)
return ThreadLocalRandom.current().nextInt(numPartitions);
}
private String extractRegionFromValue(Object value) {
// 实际项目中:解析 JSON/Protobuf,提取 region 字段
// 示例:return ((YourMessageClass)value).getRegion();
return "default";
}
@Override public void close() {}
@Override public void configure(Map<String, ?> configs) {}
}步骤 2:Producer 配置启用
Properties props = new Properties();
props.put("bootstrap.servers", "kafka-broker:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("partitioner.class", "com.yourcompany.RegionBasedPartitioner"); // 全限定类名⚠️ 自定义关键注意事项
| 项目 | 建议 |
|---|---|
| 线程安全 | partition() 方法被多线程调用,避免使用非线程安全对象 |
| 性能 | 逻辑需轻量(< 1μs),避免 I/O 或复杂计算 |
| 一致性 | 相同业务标识必须路由到同一分区(如用户ID) |
| 可用分区 | 务必使用 cluster.availablePartitionsForTopic() |
| 测试 | 模拟 Cluster 对象进行单元测试,验证倾斜与边界情况 |
五、策略选型决策树(附场景示例)
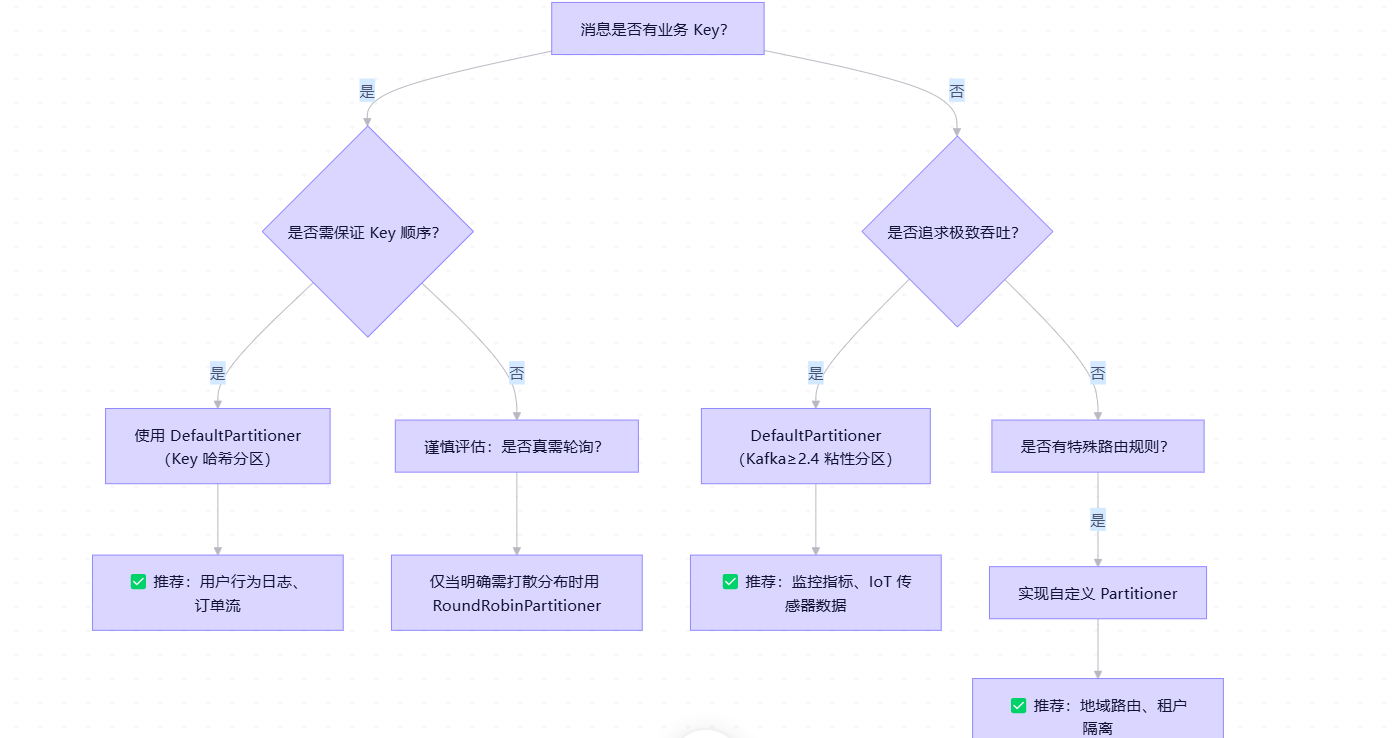
🌰 典型场景参考
| 业务场景 | 推荐策略 | 原因 |
|---|---|---|
| 电商订单流 | DefaultPartitioner(Key=用户ID) | 保证同一用户订单顺序 |
| 日志收集(无Key) | DefaultPartitioner(Kafka≥2.4) | 粘性分区提升吞吐 |
| 多租户 SaaS 系统 | 自定义(Key=租户ID) | 隔离租户数据,避免倾斜 |
| 实时风控事件 | 自定义(Key=设备ID+时间窗口) | 关联事件同分区便于窗口计算 |
六、避坑指南 & 最佳实践
-
警惕数据倾斜
- 监控各分区消息量(
kafka-run-class kafka.tools.GetOffsetShell) - 自定义策略中加入扰动因子(如:
hash(key + salt) % 分区数)
- 监控各分区消息量(
-
分区数规划前置
- 分区策略效果依赖合理分区数(参考:
分区数 ≈ 吞吐量(条/秒) / 单分区处理能力) - 避免频繁扩容分区(影响分区策略一致性)
- 分区策略效果依赖合理分区数(参考:
-
升级注意兼容性
- Kafka 2.4+ 粘性分区改变无 Key 行为,升级前验证业务影响
- 自定义 Partitioner 需测试新版本 Cluster API 变化
-
测试 Checklist
- 相同 Key 是否始终路由到同一分区?
- 无 Key 消息分布是否均匀?
- 分区数变化时策略是否健壮?
- 高并发下无性能瓶颈?
七、结语
Kafka 分区策略绝非"配置项",而是数据流架构的设计决策 。
✅ 优先使用 DefaultPartitioner (Kafka ≥ 2.4 已优化无 Key 场景)
✅ 仅当业务强需求时自定义 ,并严格测试
✅ 结合监控持续优化:分区负载、消费延迟、顺序性验证
理解分区策略,就是掌握 Kafka 数据流动的"交通规则"。精准设计,方能构建高可靠、高性能的实时数据管道。
延伸阅读
- Kafka 官方文档:Producer Configs
- KIP-480: Sticky Partitioner(Kafka 2.4 核心改进)
- 《Kafka 权威指南》第 3 章:生产者与分区
本文基于 Kafka 3.6 编写,策略细节请以实际部署版本文档为准。
欢迎在评论区分享你的分区策略实战经验! 🚀