TL;DR
- 场景:Java 开发者理解 RocketMQ 消息队列的存储架构与消息过滤机制
- 结论:RocketMQ 通过 CommitLog 顺序写保证高性能,ConsumerQueue 实现读写分离,IndexFile 提供 Hash 索引,三种过滤方式(Tag/SQL/Filter)满足不同场景
- 产出:存储结构解析、刷盘策略对比、三种过滤方式详解

版本矩阵
| 功能 | 状态 | 说明 |
|---|---|---|
| 关系型数据库存储 | ✅ 已验证 | ActiveMQ JDBC 持久化配置 |
| 文件系统存储 | ✅ 已验证 | RocketMQ/Kafka/RabbitMQ 均采用 |
| 同步刷盘 | ✅ 已验证 | SYNC_FLUSH,数据安全性最高 |
| 异步刷盘 | ✅ 已验证 | 高吞吐,存在数据丢失风险 |
| CommitLog 顺序写 | ✅ 已验证 | 单文件 1G,20 位文件名 |
| ConsumerQueue 逻辑队列 | ✅ 已验证 | 固定 20 字节条目,30 万条目/文件 |
| IndexFile 哈希索引 | ✅ 已验证 | 2000 万索引/文件,约 400MB |
| Tag 过滤 | ✅ 已验证 | 基于消息 Tag HashCode |
| SQL 过滤 | ✅ 已验证 | RocketMQ Expression 语法 |
| Filter 方式 | ✅ 已验证 | 自定义 Java 函数过滤 |
| MappedByteBuffer | ✅ 已验证 | 内存映射加速文件读写 |
| 消息发送三种方式 | ✅ 已验证 | 同步/异步/单向发送 |
消息存储
存储介质
消息队列的存储介质主要分为关系型数据库和文件系统两类,不同的存储介质在性能、可靠性和适用场景上各有优劣。
关系型数据库(DB)
Apache 下的另一款开源消息队列 ActiveMQ,默认采用 KahaDB 存储消息,也可选用 JDBC 的方式来做消息的持久化,通过简单的 XML 配置即可实现 JDBC 消息存储。
xml
<!-- ActiveMQ JDBC 持久化配置示例 -->
<beans>
<broker brokerName="test-broker">
<persistenceAdapter>
<jdbcPersistenceAdapter dataSource="#mysql-ds"/>
</persistenceAdapter>
</broker>
<bean id="mysql-ds" class="org.apache.commons.dbcp2.BasicDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/activemq"/>
<property name="username" value="root"/>
<property name="password" value="password"/>
</bean>
</beans>注意:普通关系型数据库在单表数据量达到千万级别时,其 IO 性能往往会出现瓶颈。在可靠性方面,该方法会非常依赖 DB,如果 DB 出现问题,则 MQ 的消息就无法落盘,导致线上故障。此外,数据库的事务机制也会带来额外的性能开销,因此在高吞吐场景下一般不推荐使用关系型数据库作为消息存储介质。
文件系统
目前业界较为常用的消息队列(如 RocketMQ、Kafka、RabbitMQ)均采用消息刷盘的方式。刷盘一般分为异步刷盘 和同步刷盘两种方式:
- 异步刷盘:消息写入内存缓冲区后立即返回,后台线程定期将数据刷入磁盘。这种方式吞吐量高,但存在数据丢失的风险(如机器宕机)。
- 同步刷盘:消息写入磁盘后才返回确认,数据安全性最高,但吞吐量相对较低。
消息刷盘为消息存储提供了一种高效率、高可靠性和高性能的数据持久化方式。除非部署 MQ 的机器本身或本地磁盘出现故障,否则一般不会出现无法持久化的问题。
存储和发送
消息存储
高性能磁盘一般可以达到 600MB/s ,超过了一般网卡传输的速度。但随机读写可能只有 100KB/s ,与顺序读写相差甚远。因此,好的消息队列系统会比普通的消息队列系统速度快多个数量级。RocketMQ 采用顺序写的方式写入消息,从而保证了消息存储的速度。
为什么顺序写这么快?
传统机械硬盘(HDD)的寻道时间约为 10ms,而顺序读写可以避免磁头频繁移动,充分利用磁盘的带宽。即使是 SSD,顺序写入也比随机写入快数倍,因为随机写入会触发写放大(Write Amplification)问题。
RocketMQ 的消息写入流程如下:
- Producer 发送消息到 Broker
- Broker 将消息追加到内存映射文件(MappedFile)中
- 根据刷盘策略决定何时将数据持久化到磁盘
- 返回写入结果给 Producer
消息发送流程
RocketMQ 的消息发送支持三种方式:
| 发送方式 | 特点 | 适用场景 |
|---|---|---|
| 同步发送 | 等待 Broker 确认后才返回 | 重要消息,如订单、交易 |
| 异步发送 | 立即返回,通过回调获取结果 | 高吞吐场景,如日志收集 |
| 单向发送 | 不关心结果,发送即结束 | 日志、监控等可丢失场景 |
java
// 同步发送示例
DefaultMQProducer producer = new DefaultMQProducer("producer_group");
producer.setNamesrvAddr("localhost:9876");
producer.start();
Message msg = new Message("TopicTest", "TagA", "Hello RocketMQ".getBytes());
SendResult sendResult = producer.send(msg);
System.out.printf("发送结果: %s%n", sendResult);
producer.shutdown();存储结构
RocketMQ 的消息存储由 ConsumerQueue 和 CommitLog 配合完成。消息真正的物理存储文件是 CommitLog,而 ConsumerQueue 是消费的逻辑队列,类似数据库的索引文件,存储的是指向物理存储的地址。每个 Topic 下的每个 Message Queue 都有一个对应的 ConsumerQueue 文件。
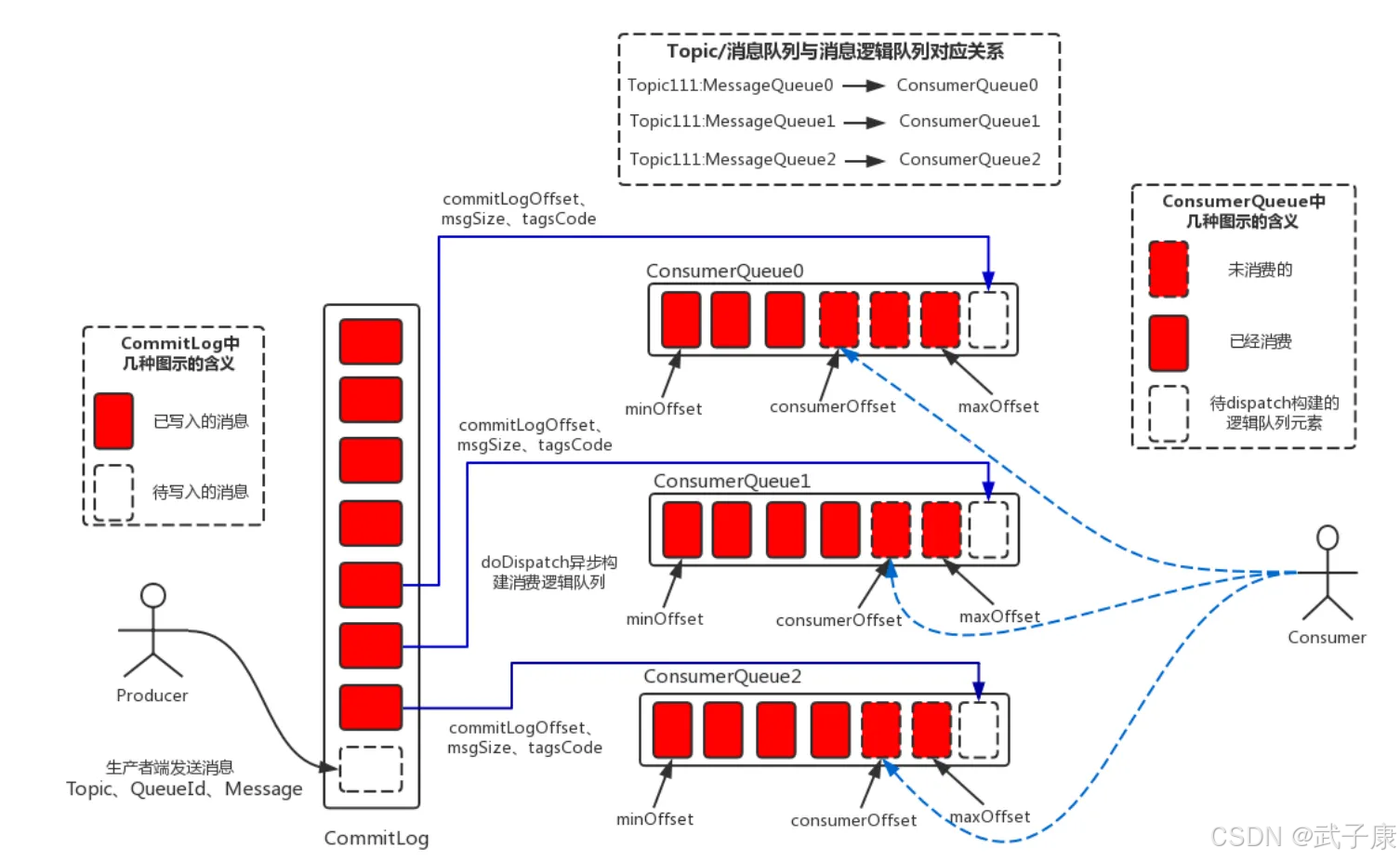
为什么采用这种双文件设计?
这种设计实现了消息写入和消费的解耦:
- CommitLog 负责顺序写入,最大化写入性能
- ConsumerQueue 负责消费索引,支持快速定位
- 即使 ConsumerQueue 损坏,也可以通过重建索引恢复
CommitLog
CommitLog 是消息主体以及元数据的存储主体,存储 Producer 端写入的消息主体内容,消息内容不是定长的。
- 单个文件大小:默认 1G
- 文件命名 :长度为 20 位,左边补 0,剩余为起始偏移量
- 例如:第一个文件为
00000000000000000000,起始偏移量为 0 - 当第一个文件写满后,第二个文件为
0000000000001073741824,起始偏移量为 1073741824
- 例如:第一个文件为
- 写入方式:主要采用顺序写入,当文件写满后,写入下一个文件
CommitLog 的内部结构:
每条消息在 CommitLog 中的存储格式如下:
| 字段 | 长度 | 说明 |
|---|---|---|
| 消息长度 | 4 字节 | 整条消息的总长度 |
| 消息体 | 变长 | 消息的实际内容 |
| 消息属性 | 变长 | 包括 Topic、Tag、Key 等 |
| 消息 ID | 8 字节 | 全局唯一消息 ID |
| 队列偏移量 | 8 字节 | 在 ConsumerQueue 中的偏移量 |
| 存储时间戳 | 8 字节 | 消息存储的时间 |
ConsumerQueue
ConsumerQueue 是消息消费队列,引入的主要目的是提高消息消费的性能。RocketMQ 是基于 Topic 的订阅模式,消息消费是针对主题进行的。如果要遍历 CommitLog 文件根据 Topic 检索消息,效率非常低下。Consumer 可以根据 ConsumerQueue 来查找待消费的消息。
ConsumerQueue 作为消费消息的索引,保存了以下信息:
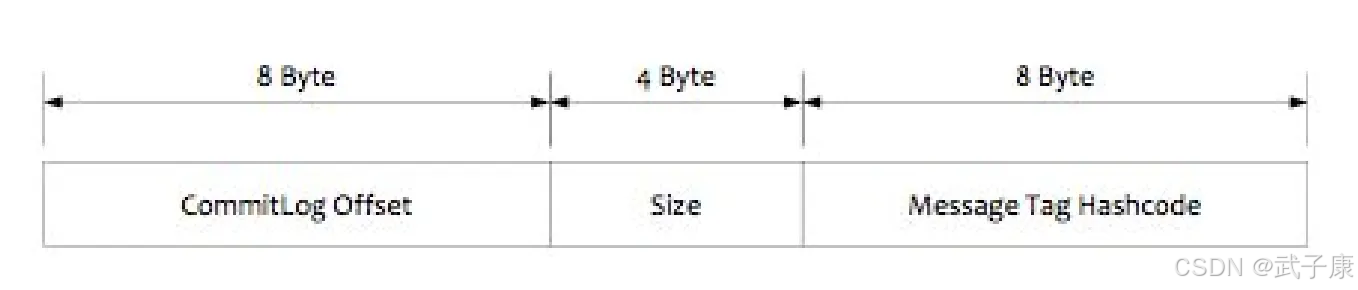
- 指定 Topic 下的队列消息在 CommitLog 的起始物理偏移量 Offset(8 字节)
- 消息大小 Size(4 字节)
- 消息 Tag 的 HashCode 值(8 字节)
ConsumerQueue 文件采用定长设计 ,每个条目固定 20 个字节。单个文件由 30 万个条目 组成,可以像数组一样随机访问每一个条目,每个 ConsumerQueue 文件大小约 5.72MB。
ConsumerQueue 的文件夹组织方式为:topic/queue/file 三层架构。
${ROCKETMQ_HOME}/store/consumequeue/
├── TopicA/
│ ├── 0/ # Queue ID 0
│ │ ├── 00000000000000000000
│ │ └── 00000000000000300000
│ └── 1/ # Queue ID 1
│ └── 00000000000000000000
└── TopicB/
└── 0/
└── 00000000000000000000IndexFile
IndexFile 是索引文件,提供了一种可以通过 Key 或时间区间来查询消息的方法。
- 存储位置 :
HOME/store/index/${FILENAME} - 文件名:以创建时的时间戳命名
- 单个文件大小:约 400MB
- 可保存索引数:2000 万个
- 底层设计 :在文件系统中实现 HashMap 结构,底层实现为 Hash 索引
IndexFile 的哈希索引结构:
IndexFile 内部结构:
┌─────────────────────────────┐
│ IndexHeader │ ← 40 字节,包含时间戳、偏移量等
├─────────────────────────────┤
│ Hash Slot 数组 │ ← 500 万个槽位,每个 4 字节
├─────────────────────────────┤
│ Index Item 数组 │ ← 2000 万个条目,每个 20 字节
│ ┌───────────────────────┐ │
│ │ Key Hash (4 字节) │ │
│ │ CommitLog Offset (8) │ │
│ │ Timestamp (4 字节) │ │
│ │ Next Index (4 字节) │ │ ← 链表指针,解决哈希冲突
│ └───────────────────────┘ │
└─────────────────────────────┘使用 IndexFile 查询消息的示例:
java
// 通过消息 Key 查询消息
DefaultMQPullConsumer consumer = new DefaultMQPullConsumer("consumer_group");
consumer.setNamesrvAddr("localhost:9876");
consumer.start();
// 设置查询时间范围(最近 3 天)
long begin = System.currentTimeMillis() - 3 * 24 * 3600 * 1000L;
long end = System.currentTimeMillis();
// 查询消息
QueryResult queryResult = consumer.queryMessage("TopicTest", "order_12345",
32, begin, end);
List<MessageExt> messages = queryResult.getMessageList();
for (MessageExt msg : messages) {
System.out.printf("消息 ID: %s, 内容: %s%n",
msg.getMsgId(), new String(msg.getBody()));
}
consumer.shutdown();过滤消息
RocketMQ 的消息过滤方式有别于其他 MQ 中间件,是在 Consumer 端订阅消息时 再做消息过滤的。RocketMQ 之所以这样做,是因为其 Producer 端写入消息和 Consumer 端订阅消息采用分离存储的机制。Consumer 端订阅消息需要通过 ConsumerQueue 拿到索引,再从 CommitLog 里读取真正的消息体内容。
ConsumerQueue 的存储结构中,有 8 个字节存储的是 Message Tag 的哈希值,基于 Tag 的消息过滤正是基于这个字段实现的。
RocketMQ 主要支持以下 3 种过滤方式:
Tag 过滤方式
Consumer 端在订阅消息时,除了指定 Topic 还可以指定 Tag。如果一个消息有多个 Tag,可以用 || 分隔。
java
// Consumer 订阅指定 Tag 的消息
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("consumer_group");
consumer.setNamesrvAddr("localhost:9876");
consumer.subscribe("TopicTest", "TagA || TagB"); // 订阅 TagA 或 TagB 的消息
consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {
for (MessageExt msg : msgs) {
System.out.printf("收到消息: %s, Tag: %s%n",
new String(msg.getBody()), msg.getTags());
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
});
consumer.start();Tag 过滤的执行流程如下:
- Consumer 端将订阅请求构建成一个
SubscriptionData,发送 Pull 消息请求给 Broker 端。 - Broker 端从 Store 读取数据之前,先用这些数据建立一个
MessageFilter,然后传给 Store。 - Store 从 ConsumerQueue 读取到一个记录后,用记录中的消息 Tag Hash 值进行过滤。
- 由于服务端仅根据 HashCode 进行判断,无法精确对 Tag 原始字符串进行过滤,因此在消息消费端拉取到消息后,还需要对消息的原始 Tag 字符串进行对比。如果不同,则丢弃该消息,不进行消息消费。
Tag 过滤的优缺点:
| 优点 | 缺点 |
|---|---|
| 过滤效率高,在服务端完成 | 仅支持精确匹配 |
| 不增加网络传输开销 | 不支持复杂逻辑 |
| 实现简单,性能稳定 | 多个 Tag 需用 ` |
SQL 过滤方式
注意:SQL 过滤方式仅对 Push 的消费者起作用。
Tag 方式虽然效率高,但支持的过滤逻辑比较简单。SQL 表达式可以更加灵活地支持复杂过滤逻辑。这种方式的大致做法与 Tag 过滤方式类似,只是在 Store 层的具体过滤过程有所不同。
java
// 使用 SQL 表达式过滤消息
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("consumer_group");
consumer.setNamesrvAddr("localhost:9876");
// 订阅消息,使用 SQL 表达式过滤
consumer.subscribe("TopicTest",
MessageSelector.bySql("(TAGS is not null and TAGS in ('TagA', 'TagB'))" +
" and age between 18 and 60"));
consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> {
for (MessageExt msg : msgs) {
System.out.printf("收到消息: %s%n", new String(msg.getBody()));
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
});
consumer.start();真正的 SQL Expression 的构建和执行由 rocketmq-filter 模块负责。每次过滤都去执行 SQL 表达式会影响效率,因此 RocketMQ 使用了 BloomFilter 来避免每次都执行。
BloomFilter 的工作原理:
- 将 SQL 表达式中的条件映射到多个哈希函数
- 在内存中维护一个位数组
- 判断消息是否可能满足条件时,检查对应位是否都为 1
- 如果某位为 0,则消息一定不满足条件,直接跳过
- 如果所有位都为 1,则消息可能满足条件,需要进一步精确判断
RocketMQ 定义了以下几种基本语法(用户可扩展):
| 类型 | 运算符 |
|---|---|
| 数字比较 | > >= < <= = |
| 字符串比较 | = <> IN IS NULL IS NOT NULL |
| 逻辑比较 | AND OR NOT |
| 常量类型 | 数字、字符串、特殊常量、布尔型 |
SQL 过滤与 Tag 过滤的对比:
| 特性 | Tag 过滤 | SQL 过滤 |
|---|---|---|
| 过滤粒度 | 仅 Tag | 任意消息属性 |
| 表达式复杂度 | 简单 | 复杂 |
| 性能 | 高 | 中等 |
| 服务端过滤 | 是 | 是 |
| 适用场景 | 简单分类 | 复杂业务规则 |
Filter 方式
Filter 方式是一种比 SQL 表达式更灵活的过滤方式,允许用户自定义 Java 函数,根据 Java 函数的逻辑对消息进行过滤。
要使用 FilterServer,首先需要在启动 Broker 前的配置文件中加上 filterServer-Nums = 3 这样的配置。Broker 启动时,会在本机启动 3 个 Filter Server。
properties
# Broker 配置文件
filterServer-Nums=3Filter Server 类似一个 RocketMQ 的 Consumer 进程,它从本机 Broker 获取消息,然后根据用户上传的 Java 函数进行过滤,过滤后的消息再传给远端的 Consumer。
自定义过滤函数示例:
java
public class OrderFilterImpl implements MessageFilter {
@Override
public boolean match(MessageExt msg, Map<String, String> properties) {
// 获取消息中的订单金额
String amountStr = msg.getProperty("amount");
if (amountStr == null) {
return false;
}
double amount = Double.parseDouble(amountStr);
// 只过滤金额大于 1000 的订单
if (amount > 1000) {
// 进一步检查订单类型
String orderType = msg.getProperty("orderType");
return "VIP".equals(orderType) || "PREMIUM".equals(orderType);
}
return false;
}
}三种过滤方式的适用场景总结:
| 过滤方式 | 推荐场景 | 示例 |
|---|---|---|
| Tag 过滤 | 简单的消息分类 | 订单消息、支付消息、物流消息 |
| SQL 过滤 | 基于属性的复杂过滤 | 金额 > 1000 且地区为华东 |
| Filter 方式 | 需要自定义业务逻辑 | 结合外部数据源判断黑白名单 |
总结
RocketMQ 的存储设计是其高性能的核心保障:
- 顺序写入:利用磁盘顺序写的高性能特性,最大化写入吞吐量
- 双文件架构:CommitLog 负责写入,ConsumerQueue 负责消费,实现读写分离
- 内存映射:使用 MappedByteBuffer 加速文件读写
- 多种过滤机制:Tag、SQL、Filter 三种方式满足不同场景需求
在实际生产环境中,建议根据业务场景选择合适的过滤方式,并合理配置刷盘策略,在性能和可靠性之间取得平衡。
错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 消息丢失 | 异步刷盘 + Broker 宕机 | 检查刷盘策略是否为同步刷盘 | 重要消息使用同步刷盘策略 |
| 消息消费延迟高 | ConsumerQueue 堆积或消费慢 | 监控消费位点,检查 ConsumeThreadMax | 增加消费线程、批量消费、优化消费逻辑 |
| Tag 过滤无效 | HashCode 碰撞 + 消费端未校验 | 检查 Tag 原始字符串是否匹配 | 消费端必须校验原始 Tag 字符串 |
| SQL 过滤不生效 | FilterServer 未启动或配置错误 | 检查 broker.conf 中 filterServer-Nums | 确保 Broker 启动时 Filter Server 就绪 |
| BloomFilter 误判 | 哈希算法假阳性 | 正常的过滤优化机制 | 消费端需二次校验,BloomFilter 只是预过滤 |
| IndexFile 查询无结果 | Key 不存在或时间范围错误 | 检查查询的 Key 和时间范围 | 确认消息已存储且在查询时间范围内 |
| CommitLog 文件损坏 | 磁盘故障或程序异常 | 检查 store 目录日志 | 通过工具恢复或重建 CommitLog |
| ConsumerQueue 与 CommitLog 不一致 | 索引构建异常 | 对比两文件的消息偏移量 | RocketMQ 支持自动重建 ConsumerQueue |
| 消息重复消费 | 自动提交 + 消费失败重试 | 检查消费逻辑是否幂等 | 实现消费幂等,或使用手动提交 |
作者:武子康的个人博客