目录
[1.1.什么是 Elasticsearch?](#1.1.什么是 Elasticsearch?)
[四.对ES 客户端API二次封装](#四.对ES 客户端API二次封装)
[4.1. 索引创建(ESIndex)](#4.1. 索引创建(ESIndex))
[4.2. 数据插入(ESInsert)](#4.2. 数据插入(ESInsert))
[4.3. 数据删除(ESRemove)](#4.3. 数据删除(ESRemove))
[4.4. 数据查询(ESSearch)](#4.4. 数据查询(ESSearch))
一.Elasticsearch
1.1.什么是 Elasticsearch?
Elasticsearch 是一个分布式搜索和分析引擎 ,简单来说,它是一个专门用来快速搜索、分析和探索大量数据的工具。
想象一下:
-
传统数据库(比如MySQL)就像图书馆的藏书目录,可以帮你找到某本书,但如果想搜索书里的某个词,或者分析所有书的内容趋势,就比较吃力。
-
Elasticsearch 则像给图书馆的每一本书的每一页都做了索引,你可以瞬间搜索到包含某个词的所有页面,还能快速统计哪些词出现最多、哪些作者最常写某个主题等。
先从你日常遇到的情况说起
场景1:你在淘宝买东西
-
你在搜索框输入"白色运动鞋"
-
淘宝瞬间给你列出了成千上万双白色运动鞋
-
而且还按"最相关"排序,甚至能按品牌、价格筛选
场景2:你在百度搜索
-
输入"北京冬奥会开幕式"
-
百度瞬间找到几百万个相关网页
-
还自动给你总结了相关新闻、视频、图片
这些背后的技术就是 Elasticsearch 擅长的事情
那么 Elasticsearch 到底是什么?
一句话定义 :Elasticsearch 是一个超级搜索引擎 ,专门用来快速找到你想要的信息。
用一个最简单的比喻
想象你有一个巨大的仓库,里面堆满了各种东西:
-
有衣服、鞋子、书、玩具、食品...
-
杂乱无章地堆着
如果没有 Elasticsearch:
你想找"红色衣服",只能满仓库翻找,翻半天可能还找不到。
有了 Elasticsearch:
就像给仓库配了一个智能管理员:
-
这个管理员提前把所有东西都分类整理好,做了详细记录
-
你一说"红色衣服",管理员瞬间告诉你:"红色衣服在左边第三个架子上,一共有50件"
-
你还能问:"哪个牌子的红色衣服最多?"管理员也能立刻回答
Elasticsearch 能做什么?
-
快速搜索
-
你写一个字,它就立刻给出搜索结果
-
比如在百度输入"北",下面马上弹出"北京天气""北京冬奥会"等建议
-
-
模糊匹配
-
即使你记不清完整内容,也能找到
-
比如只记得文章里有"冬奥"两个字,它能找出所有包含"冬奥"的文章
-
-
智能推荐
-
"买了这个商品的用户还买了..."
-
"猜你想搜..."
-
-
数据分析
-
比如电商网站能知道"今天搜'羽绒服'的人比昨天多了3倍"
-
公司能知道"服务器最近24小时出过多少次故障"
-
1.2.传统数据库明明可以查询数据,为什么还需要ES?
1.2.1.正排索引和倒排索引
- 正排索引
定义
正排索引是一种以文档为单位的索引结构。它记录了每个文档包含哪些内容(如单词、字段值等)。简单来说,就是从文档到内容的映射。
结构示例
假设有三个文档:
-
文档1: "苹果是一种水果"
-
文档2: "苹果手机是电子产品"
-
文档3: "香蕉也是一种水果"
正排索引会像这样存储:
| 文档ID | 内容(词项列表) |
|---|---|
| 1 | 苹果,是,一种,水果 |
| 2 | 苹果,手机,是,电子产品 |
| 3 | 香蕉,也,是,一种,水果 |
工作原理
当你要查询某个文档的具体内容时(比如根据文档ID获取全文),正排索引非常高效:直接通过文档ID找到对应的记录即可。但如果想找到所有包含"苹果"的文档,正排索引就需要遍历每一个文档,检查每个文档的词项列表中是否有"苹果"。这种扫描在数据量庞大时效率极低。
优点
-
结构简单,易于实现和维护。
-
对于基于文档ID的精确查找,速度极快。
缺点
-
对于关键词搜索,必须遍历所有文档,性能低下。
-
不适合全文检索场景。
常见应用
-
传统关系型数据库中的聚簇索引(数据行本身按主键顺序存储)可以看作一种正排索引。
-
文件系统的目录结构:你知道文件路径,就能直接找到文件。
- 倒排索引
定义
倒排索引是一种以词项(关键词)为单位的索引结构。它记录了每个词项出现在哪些文档中。也就是说,它是从内容到文档的映射。
结构示例
还是上面的三个文档,倒排索引会这样构建:
| 词项 | 出现该词项的文档ID列表 |
|---|---|
| 苹果 | 1, 2 |
| 是 | 1, 2, 3 |
| 一种 | 1, 3 |
| 水果 | 1, 3 |
| 手机 | 2 |
| 电子产品 | 2 |
| 香蕉 | 3 |
| 也 | 3 |
(实际应用中,倒排索引通常还会记录词项在每个文档中的出现位置、词频等信息,用于相关性计算。)
工作原理
当你搜索"苹果"时,系统直接到倒排索引中查找"苹果"这个词项,立即得到文档ID列表 1, 2,然后快速返回这两个文档。整个过程无需扫描所有文档,查找速度极快,与文档总数无关,只与词项数量有关。
优点
-
全文搜索性能极高,尤其适合关键词查询。
-
可以轻松支持复杂的查询,如布尔操作、短语匹配等。
-
通过记录词频和位置,能实现相关性评分。
缺点
-
构建和维护成本高:文档新增、删除或更新时,需要同步更新倒排列表。
-
占用存储空间较大(需要存储词项、文档ID列表、位置信息等)。
常见应用
-
搜索引擎(如 Google、百度)的核心技术。
-
Elasticsearch、Lucene 等全文检索引擎的基础数据结构。
- 为什么倒排索引适合搜索?
搜索的本质是"根据关键词找文档"。倒排索引恰好以关键词为入口,直接给出文档列表,这完全符合搜索的需求。而正排索引则需要反向遍历,不符合人类搜索的习惯。
- 正排索引与倒排索引在 Elasticsearch 中的角色
Elasticsearch 为了兼顾搜索、聚合、排序等多种需求,同时使用了这两种索引:
-
倒排索引 :主要用于全文搜索。当你执行 match 查询时,Elasticsearch 会在倒排索引中快速定位匹配的文档。
-
正排索引(Doc Values):用于排序、聚合和脚本计算。因为倒排索引对词项到文档的映射很快,但对文档到值的映射(例如统计某个字段的平均值)则效率不高。Doc Values 是一种列式存储的正排索引,它以文档ID为键,存储字段值,使得排序和聚合操作能够快速访问每个文档的字段值,避免加载整个文档。
1.2.2.ES和传统数据库的关系与对比
一、两种索引的核心差异
核心:传统数据库采用正排索引,ES使用的是倒排索引!!
- 传统数据库(如 MySQL)的索引方式(正排索引)
传统数据库最常用的索引结构是 B-Tree(平衡树)。你可以把它想象成一个高效的、有序的目录。假设有一个"用户表",你对"姓名"字段建立了 B-Tree 索引,那么索引中会存储排序后的姓名和对应的记录位置。
-
它能做什么?
-
精确查找:
WHERE name = '张三'------ 快速定位。 -
范围查找:
WHERE age BETWEEN 20 AND 30------ 快速定位起始点,然后顺序扫描。 -
前缀匹配:
WHERE name LIKE '张%'------ 也能利用索引快速找到所有以"张"开头的姓名。
-
-
它不擅长什么?
- 全文搜索 :比如要在文章内容中查找包含"苹果"一词的记录。如果使用
WHERE content LIKE '%苹果%',由于%在开头,B-Tree 索引就失效了,数据库只能进行全表扫描 ------也就是把每一行的content字段都读出来,检查是否包含"苹果"。当表里有上亿条数据时,这个速度慢得让人无法接受。
- 全文搜索 :比如要在文章内容中查找包含"苹果"一词的记录。如果使用
- Elasticsearch 的倒排索引
倒排索引的设计目标就是为了解决"根据内容找文档"这个问题。它的结构在前面的讲解中已经提到:它是一个从词项到文档ID的映射表。
-
构建过程:当文档被索引时,Elasticsearch 会对文本内容进行分词,得到一个个单词(词项),然后记录每个单词出现在哪些文档中。
-
查询过程:当搜索"苹果"时,ES 直接到倒排索引中查找"苹果"这个词项,瞬间得到所有包含它的文档ID列表,然后取出这些文档返回。
这个过程不需要扫描所有文档,查询速度与文档总数无关,只与词项的数量有关。 即使你有 10 亿条数据,搜索"苹果"也只需要毫秒级响应。
二、为什么 ES 能"碾压"传统数据库?
我们可以用一个类比来加深理解。
假设你有一个巨大的图书馆(数据库),里面有成千上万本书(文档)。现在你想找到所有**内容中提到"苹果"**的书。
-
传统数据库的做法 :它没有针对"内容中的词"建立索引。所以它只能这样做:从第一本书开始,一本一本地翻开,逐页阅读,查找是否有"苹果"这个词。读完一本,记录结果,再读下一本......直到把整个图书馆的书都翻一遍。这就是全表扫描。即使图书馆有分类目录(B-Tree 索引),那也只是按书名、作者等分类,无法告诉你哪本书的内容里写了"苹果"。
-
Elasticsearch 的做法 :它在书入库的时候,就派了很多图书管理员(分词器)把每本书的内容拆成一个个单词,并制作了一个巨大的关键词目录(倒排索引)。这个目录上写着:"苹果"这个词,出现在第 1、5、100 本书里。当你要找包含"苹果"的书时,管理员直接翻开目录,找到"苹果"这个词,然后告诉你:去 1、5、100 号书架拿书吧。整个过程不需要翻阅任何一本书的内容。
这就是倒排索引带来的"降维打击":它将一个需要遍历所有文档的"文档内容扫描"问题,转化成了一个在词项字典中快速查找的"键值查询"问题。
三、传统数据库难道没有全文索引吗?
有的。像 MySQL 从 5.6 版本开始也支持全文索引(InnoDB 引擎),它底层也是基于倒排索引的思想。那么问题来了:既然 MySQL 也有倒排索引,为什么大家还说 ES 搜索更快?
主要有以下几个原因:
-
实现深度和专业性不同 :MySQL 的全文索引只是一个附加功能,它的分词器、相关性评分算法、查询优化等方面远不如 Elasticsearch(底层是 Lucene)专业和强大。ES 是专为搜索而生的,它在这个领域深耕多年,有海量的优化细节。
-
分布式架构:ES 天生就是分布式的。当数据量巨大时,ES 可以将索引拆分成多个分片,分散到成百上千台服务器上。搜索时可以并行在多个分片上执行,然后汇总结果,实现水平扩展。而传统数据库的全文索引通常局限于单机,即使有分库分表方案,也远不如 ES 的分布式查询灵活和高效。
-
丰富的查询和分析能力:ES 不仅支持简单的关键词匹配,还支持复杂的布尔查询、短语匹配、模糊查询、地理位置查询,以及基于相关度的排序、聚合分析等。这些功能在数据库的全文索引中要么不支持,要么实现得非常简陋。
-
实时性:ES 的索引是近实时的(数据写入后默认 1 秒可被搜索),适合频繁更新的数据。而数据库的全文索引更新往往代价较高,可能会有一定延迟。
所以,即使 MySQL 有全文索引,在数据量稍大、查询复杂度稍高的情况下,性能也无法与 Elasticsearch 相提并论。
四、ES 在所有方面都比数据库强吗?
绝对不是。 "碾压"只发生在"搜索"这个特定的领域。在其他方面,传统数据库依然有不可替代的优势:
-
事务处理(ACID):数据库支持复杂的事务,保证数据的一致性和完整性。ES 在这方面非常弱,它更适合最终一致性的场景。
-
精确查询 :对于根据主键或唯一索引查找单条记录(比如
SELECT * FROM users WHERE id = 123),数据库的 B-Tree 索引可能比 ES 更快,因为 ES 还需要经过分片路由等额外步骤。 -
复杂关联查询 :数据库的
JOIN操作虽然慢,但至少能实现。ES 不鼓励做关联查询,它的数据模型更倾向于反范式化,提前将关联数据扁平化存到一个文档里。 -
数据更新和删除:数据库的更新是原地修改,效率很高。ES 的更新实际上是"标记删除旧文档 + 新建文档",在频繁更新场景下会有开销。
ES和传统数据库的互补
在技术选型时,通常会将两者结合使用:用数据库负责核心业务数据存储和事务处理,用 Elasticsearch 负责搜索和分析。这也是 Elastic Stack 如此流行的原因------它补全了传统数据库在搜索领域的短板。
1.3.Elasticsearch的核心概念讲解
Elasticsearch 中的索引(Index)、类型(Type)、字段(Field)和映射(Mapping),并且会一直和传统数据库(比如 MySQL)进行对比,这样你就能更直观地理解它们。
一、一个整体的类比
首先,你可以把 Elasticsearch 想象成一个数据库服务器 (比如 MySQL 实例),它里面可以创建多个索引 。这个结构就像 MySQL 里可以创建多个数据库一样。
接下来我们逐一拆解:
| 概念 | Elasticsearch 中的角色 | 传统数据库(如 MySQL)中的类比 |
|---|---|---|
| 索引 (Index) | 存储相关数据的逻辑容器 | 数据库 (Database) 或 表 (Table) |
| 类型 (Type) | 索引内部的逻辑分类(已废弃) | 表 (Table) |
| 文档 (Document) | 一条具体的记录 | 行 (Row) |
| 字段 (Field) | 文档中的一个属性 | 列 (Column) |
| 映射 (Mapping) | 定义字段的数据类型和索引方式 | 表结构 (Schema) |
二、索引(Index)------ 相当于数据库(Database)或表(Table)
-
定义:索引是 Elasticsearch 中存储文档的地方,是一个逻辑命名空间。它把具有相似字段的文档聚集在一起。
-
类比:
-
你可以把索引看作一个数据库,里面可以包含多种类型的数据(如果使用类型的话)。
-
也可以更直接地把它看作一张表,因为现在 Elasticsearch 推荐每个索引只存储一类数据(比如用户、订单、日志),这样索引就更贴近"表"的概念。
-
-
特点:
-
每个索引有一个名字(小写),通过这个名字进行读写。
-
索引可以被拆分成多个分片(shard)分布在集群的不同节点上,这是分布式的基础。
-
三、类型(Type)------ 曾经相当于表(Table),现在已废弃
-
历史背景:在 Elasticsearch 早期版本(6.x 之前),一个索引可以包含多个类型。你可以想象成一个数据库里有多张表,每个类型代表一类文档,它们的字段可能不同。例如,一个"商城"索引下,可以有"用户"类型和"订单"类型。
-
为什么废弃:因为这种设计会导致同一个索引下不同字段的映射混在一起,引发性能问题(比如不同字段的 Lucene 实现冲突)。从 7.x 开始,类型被移除,一个索引只能包含一种文档类型。
-
现在的做法 :如果你想存储不同类型的数据,就创建不同的索引。比如
user_index和order_index。这样更清晰,也避免了类型带来的混乱。 -
初学者理解 :你可以完全忽略"类型"这个概念,直接认为索引 = 表。
四、字段(Field)------ 相当于列(Column)
-
定义:字段是文档中的一个属性,它有一个名字和一个值。例如一篇博客文档可以有标题(title)、内容(content)、发布时间(publish_date)等字段。
-
类比:就像数据库表中的列,每一列存储一种特定类型的数据。
-
区别:Elasticsearch 的字段可以是更复杂的数据结构,比如数组、对象、嵌套对象等。而传统数据库通常要求每个列是单一值。
五、映射(Mapping)------ 相当于表结构(Schema)
-
定义:映射是用来定义索引中的文档有哪些字段、每个字段是什么数据类型(字符串、数字、日期等),以及这些字段如何被索引和存储的规则。
-
类比 :就像数据库建表时的
CREATE TABLE语句,它规定了列名、列类型、是否可为空、是否为主键等。 -
关键区别:
-
动态映射:传统数据库必须在插入数据前定义好表结构。而 Elasticsearch 默认支持动态映射:当你插入一条包含新字段的文档时,它会自动推断字段类型并添加到映射中。这带来了极大的灵活性,但也容易造成字段类型冲突,所以生产环境中常会手动定义严格的映射。
-
字段类型丰富 :Elasticsearch 的字段类型远多于数据库,除了基本的数字、字符串、日期,还有专门用于全文检索的
text类型、用于精确值的keyword类型、地理位置geo_point类型、对象object类型等。 -
索引方式:在映射中,你可以控制字段是否被索引(即是否可以被搜索)、使用什么分词器等。传统数据库的列通常都支持搜索,但效率低下。
-
不可变性 :映射一旦正式使用,通常不建议修改,特别是修改已有字段的类型。如果需要修改,一般要重建索引。这有点像数据库修改列类型需要
ALTER TABLE并且可能锁表一样,但在 Elasticsearch 中更推荐用重建索引+别名的方式实现零停机变更。
-
六、综合实例对比
假设我们要存储"商品"信息,包含商品名称、价格、上架时间。
传统数据库的做法:
-
创建一个数据库(如
shop_db)。 -
在该数据库中创建一张表(如
products)。 -
定义表结构:
name VARCHAR(100),price DECIMAL(10,2),create_time DATETIME。 -
然后向表中插入数据行。
Elasticsearch 的做法:
-
创建一个索引(如
products)------ 这相当于数据库+表的组合。 -
定义映射:规定
name字段类型为text(用于全文搜索),price类型为float,create_time类型为date。 -
向索引中添加文档(JSON 格式),每条文档就是一条商品记录。
对比可见,两者逻辑结构非常相似,只是术语不同。
二.安装ElasticStack及其配套工具
2.1.安装ElasticStack
注意这里需要安装378MB左右,所以说如果使用ElasticStack官方源的话有点可能就是安装比较慢的。
我们这里是使用了清华源来进行安装我们的ElasticStack。
清华源ElasticStack官网:https://mirrors.tuna.tsinghua.edu.cn/help/elasticstack/
安装步骤
bash
# 1. 下载并存储GPG密钥到规范位置
sudo wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo gpg --dearmor -o /usr/share/keyrings/elasticsearch-keyring.gpg
# 2. 添加清华镜像源,并绑定密钥
echo "deb [signed-by=/usr/share/keyrings/elasticsearch-keyring.gpg] https://mirrors.tuna.tsinghua.edu.cn/elasticstack/7.x/apt/ stable main" | sudo tee /etc/apt/sources.list.d/elastic-7.x.list
# 3. 更新软件包列表
sudo apt-get update
# 4. 安装Elasticsearch(安装7.17.21版本)
sudo apt-get install elasticsearch=7.17.212.2.安装IK分词器
Elasticsearch(ES)作为一个基于Lucene的搜索引擎,其核心功能之一就是分词------将文本切分成一个个词条(term),然后基于这些词条建立倒排索引。当用户搜索时,查询语句也会被同样的分词器处理,与索引中的词条进行匹配。因此,分词器的选择直接决定了搜索的准确性和召回率。
对于中文来说,ES默认的分词器(如standard、english等)存在明显的局限性,而IK分词器正是为了解决这些问题而生的。下面从几个维度详细说明为什么必须安装IK分词器。
- 中文与英文的语言结构差异
英文等西方语言有明显的单词边界------空格和标点符号天然地把句子分割成单词,比如"I love China"可以简单地通过空格分成[I, love, China]。因此,基于空格和符号的简单分词器(如standard)对英文就足够有效。
但中文不同:
-
没有空格:中文句子中词与词之间没有显式的分隔符,比如"我爱中国"是一个连续的字符串。
-
单字含义复杂:单个汉字在不同语境下可能独立成词,也可能与其他字组合成词。比如"中国"是一个词,但"中"和"国"单独看也有各自的意思。
-
歧义切分:一句话可能有多种切分方式,比如"乒乓球拍卖完了"可以切分为"乒乓球/拍卖/完了"或"乒乓球拍/卖/完了",正确的分词需要结合上下文。
因此,中文搜索必须依赖专门的中文分词算法,而不是简单的按字切分。
- 默认分词器对中文的处理方式
ES默认的standard分词器遇到中文时,会把每个汉字当作一个独立的词元 。例如,对"中华人民共和国"进行分词,结果会是[中, 华, 人, 民, 共, 和, 国]。
这种方式的缺点非常明显:
-
语义丢失:搜索"中国"时,倒排索引中只有单字"中"和"国",而文档中的"中华人民共和国"包含"中"和"国"两个字,因此能匹配到,但匹配的得分很低,因为"中"和"国"是作为两个独立字出现的,并不代表"中国"这个词的含义。
-
相关性差:如果用户搜索"中华",同样只能匹配到单字"中"和"华",无法意识到"中华"是一个整体概念。
-
索引膨胀:每个汉字都作为一个词条,导致索引体积变大,而且许多无意义的单字组合会干扰搜索结果。
实际上,按字切分的中文索引,对于用户想要搜索一个完整词语的场景,效果往往很差。
- IK分词器的核心价值
IK分词器是一个基于词典和规则的中文分词插件,它内置了丰富的词典,能够识别出中文文本中的词语。它的核心机制包括:
-
词典匹配:IK内置了一个主词典,包含了大量常用中文词汇(如"中华人民共和国""中国""人民"等)。分词时会尽可能地将文本与词典中的词条进行匹配。
-
歧义处理:通过算法解决切分歧义,比如对"乒乓球拍卖完了"能根据上下文给出合理的切分。
-
两种分词模式:
-
ik_smart :粗粒度分词,倾向于将句子切分成最少的词。例如"中华人民共和国"可能被切分为
[中华人民共和国](如果词典中有这个词)。这种模式适合在搜索时使用,减少词条数量,提高性能。 -
ik_max_word :细粒度分词,会尽可能多地切分出词语,包括组合词。例如"中华人民共和国"可能被切分为
[中华人民共和国, 中华, 华人, 人民, 共和国, 共和, 国]。这种模式适合在索引时使用,可以覆盖更多的潜在搜索词,提高召回率。
-
通过这两种模式的配合,IK分词器既能保证索引的丰富性,又能保证搜索时的精确性。
- 实际效果对比
假设我们有一个文档,内容是"中华人民共和国成立了"。
-
使用standard分词器 (按字切分):索引的词条为
[中, 华, 人, 民, 共, 和, 国, 成, 立, 了]。-
用户搜索"中国":查询被切分为
[中, 国],能匹配到文档,但相关性得分很低。 -
用户搜索"中华":查询被切分为
[中, 华],同样能匹配,但得分低。 -
用户搜索"共和国":查询切分为
[共, 和, 国],也能匹配,但依然是按字匹配。
-
-
使用IK分词器 (以ik_max_word为例):索引的词条为
[中华人民共和国, 中华, 华人, 人民, 共和国, 共和, 国, 成立, 了]。-
用户搜索"中国":如果使用ik_smart,查询切分为
[中国](假设"中国"在词典中),倒排索引中有"中华"、"华人"等,但没有"中国",所以无法匹配?这里需要说明:IK分词器会根据词典识别"中国",如果索引时没有包含"中国"这个词(因为文档中没有"中国"),那么搜索"中国"确实无法匹配到文档。但文档中有"中华人民共和国",如果用户搜索"中国",我们希望它能匹配吗?这取决于业务需求。IK分词器的优势在于,它允许我们通过配置,将"中国"作为"中华人民共和国"的一部分被搜索到吗?实际上,如果索引时使用了ik_max_word,会把"中华人民共和国"拆成多个词,其中包括"中华"和"共和国",但不一定会拆出"中国"。不过,如果用户搜索"中国",查询词被切分为"中国",而索引中并没有"中国"这个词条,那么文档就不会被召回。这种情况下,IK分词器并不能解决同义词的问题,但可以通过同义词插件或自定义词典来扩展。 -
用户搜索"中华":查询切分为
[中华],索引中有"中华",精确匹配,得分高。 -
用户搜索"共和国":查询切分为
[共和国],索引中有"共和国",精确匹配。
-
可以看出,IK分词器能让搜索词和索引词更精确地对齐,从而提高搜索质量。
- 可扩展性:自定义词典
IK分词器允许用户自定义词典,即添加业务相关的词汇。比如电商网站需要识别"苹果手机""联想电脑"等专有名词,公司内部系统需要识别项目名称、产品型号等。这些词汇可能不在默认词典中,但通过自定义词典,IK可以正确切分它们,避免被错误拆分。
此外,IK还支持远程词典热更新,使得在不重启ES的情况下动态更新词库,非常实用。
- 没有IK分词器的后果
如果在中文场景下不安装IK分词器,ES的搜索能力将大打折扣:
-
用户输入一个常见的中文词语,搜索结果可能包含大量不相关的内容,因为默认分词器把词语拆散了。
-
相关性排序完全失效,得分无法反映文档的真实匹配程度。
-
对于长文本(如文章、新闻),按字切分会导致倒排索引极其庞大,且搜索噪音极大。
总之,IK分词器是让Elasticsearch能够理解中文的关键组件。只有安装了它,ES才能像一个合格的中文搜索引擎那样工作,提供准确、高效的全文检索功能。
因此,为了在 Elasticsearch 中实现高效、准确的中文全文搜索,必须安装并配置 IK 分词器插件。
安装ik分词器插件
bash
sudo /usr/share/elasticsearch/bin/elasticsearch-plugin install https://get.infini.cloud/elasticsearch/analysis-ik/7.17.21
安装完之后我们需要启动一下我们的ES
bash
sudo systemctl start elasticsearch现在我们就可以去看看有没有安装成功
bash
curl -X GET "http://localhost:9200/"
2.3.安装Kibana
安装Kibana的主要原因是为了让Elasticsearch中的数据变得可视化、可交互和易于管理。简单来说,Elasticsearch是一个强大的搜索引擎,但它只提供RESTful API接口(即通过发送HTTP请求来查询数据),没有图形界面。如果你直接使用它,每次查询都需要手动构造JSON请求,查看结果也只是原始的JSON文本,这对于日常数据分析、监控和问题排查来说非常不方便。
Kibana正是为了解决这个问题而诞生的。它是Elastic Stack(也称ELK Stack,包括Elasticsearch、Logstash、Kibana)中的可视化工具,为Elasticsearch提供了一个图形化操作界面。下面详细说明它的核心功能和安装它的必要性。
将安装Kibana的步骤拆分为多个独立的代码块,每个步骤对应的命令如下:
安装Kibana
sudo apt install -y kibana配置Kibana
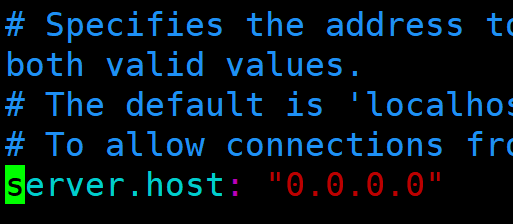
编辑配置文件:
sudo vim /etc/kibana/kibana.yml设置Elasticsearch URL(在配置文件中找到并修改):

修改成下面这样子
启动Kibana服务
sudo systemctl start kibana设置开机自启
sudo systemctl enable kibana验证安装
sudo systemctl status kibana访问Kibana
在浏览器中访问:
http://你的服务器IP地址:5601注意:如果是云服务器的话,需要先去官网去开放防火墙端口和安全组端口。
然后进入下面这个界面
后面我们主要使用的是
也就是下面这个界面来操作ES
2.4.安装ES客户端
ES C++的客户端选择并不多, 我们这里使用elasticlient库, 下面进行安装。
bash
# 克隆代码
git clone https://github.com/seznam/elasticlient
# 切换目录
cd elasticlient
# 更新子模块
git submodule update --init --recursive
# 需要安装MicroHTTPD 库
sudo apt-get install -y libmicrohttpd-dev
# 编译代码
mkdir build && cd build && cmake -DCMAKE_INSTALL_PREFIX=/usr .. && make
# 安装
sudo make install注意:这个客户端的安装是不能去github里面下载.zip安装包到云服务器上安装的。因为我们这里还需要更新子模块,我们必须使用git clone来完成安装。!!!
不过也不用太担心,也不需要多久,10分钟之内可以完成。
如果我们在make 的时候编译出错:那么就可能是子模块googletest没有编译安装
bashcollect2: error: ld returned 1 exit status make[2]: *** [external/httpmockserver/test/CMakeFiles/test server.dir/build.make:105: bin/test-server] Error 1 make[1]: *** [CMakeFiles/Makefile2:675: external/httpmockserver/test/CMakeFiles/test-server.dir/all] Error 2 make: *** [Makefile:146: all] Error 2解决:手动安装子模块
bashcd ../external/googletest/ mkdir cmake && cd cmake/ cmake -DCMAKE_INSTALL_PREFIX=/usr .. make && sudo make install安装好重新cmake即可。
三.ES的使用
3.1.类型
我来为您详细讲解 Elasticsearch 中的字段数据类型。这些类型决定了数据如何被存储、索引和搜索,是构建索引映射的核心。
字符串类型:text 与 keyword
字符串类型分为两种,主要区别在于是否被分词。
text 类型
- 特点:当您存入一段文字(如文章内容、产品描述)时,text 类型会通过分词器将其拆分成多个词项 (terms)**,并建立倒排索引。**这样搜索时,用户输入的关键词也会被分词,只要匹配到任意一个词项就能返回结果,实现全文搜索。
- 适用场景:博客内容、商品标题、评论等需要模糊匹配的文本。
- 注意:text 字段默认不支持聚合(aggregations)和排序,因为分词后的结果是无序的。如果需要聚合或排序,通常需要同时定义一个 keyword 子字段。
keyword 类型
- 特点:**不会对内容进行分词,而是将整个字符串作为一个完整的词项存入索引。**搜索时必须完全匹配(或通过通配符、正则表达式),常用于精确值查找、过滤、聚合和排序。
- 适用场景:邮箱地址、标签、状态码、身份证号等不需要拆分的精确值。
- 注意:对于过长的文本(如超过 256 字符),keyword 类型会忽略超出部分(可通过 ignore_above 参数调整),因此不适合存储大段文本。
整型数值:integer、long、short、byte
这些类型用于存储整数,区别在于取值范围和存储空间。选择合适的类型可以优化索引大小和查询性能。
- byte:有符号 8 位整数,范围 -128 ~ 127。
- short:有符号 16 位整数,范围 -32,768 ~ 32,767。
- integer:有符号 32 位整数,范围 -2^31 ~ 2^31-1(约 ±21 亿),最常用。
- long:有符号 64 位整数,范围 -2^63 ~ 2^63-1,适用于大数值(如时间戳毫秒值、宇宙星星数量)。
注意:如果存入的值超出类型范围,Elasticsearch 会报错。因此要根据实际数据范围选择最紧凑的类型。
浮点类型:float 与 double
用于存储小数。
- float:32 位单精度浮点数,大约 6-7 位有效数字。
- double:64 位双精度浮点数,大约 15 位有效数字,精度更高。
适用场景:价格、评分、测量数据等。
注意:浮点数在计算机中存储存在精度误差,对于金额等要求精确计算的场景,建议使用 scaled_float 类型(例如将金额乘以 100 后存为整数)。
逻辑类型:boolean
用于存储真/假值。可接受的字面量包括 true、
false、"true"、"false"、"on"、"off"、"yes"、"no"、"0"、"1" 等,但存入后统一转换为 true 或 false。
适用场景:是否激活、是否删除、性别(男/女)等二元状态。
日期类型:date 与 date_nanos
用于存储日期时间。
date:支持毫秒级精度。可接受多种格式:
格式化字符串,如 "2018-01-13"、"2018-01-13T12:10:30Z"。
时间戳(毫秒数,如 1515888000000)或秒数(需通过 format 指定)。
Elasticsearch 内部会将日期统一转换为 UTC 时间的毫秒数存储。
date_nanos:纳秒级精度,适用于需要极高时间分辨率的场景(如日志记录、科学实验)。存储时会占用更多空间,且排序和聚合时需注意纳秒部分。
注意:默认日期格式为 strict_date_optional_time||epoch_millis,可通过 format 参数自定义。
二进制类型:binary
用于存储 base64 编码的二进制数据,例如图片、文件的小型缩略图或加密数据。
特点:
- 字段默认 index: false,即不会被索引,因此不能用于搜索,只能通过 _source 返回原始值。
- 适合存储不需要检索的元数据或小型附件。
注意:Elasticsearch 不是专门的文件存储系统,过大的二进制数据会影响性能,建议将文件存放在对象存储(如 S3)中,仅在 ES 中保存 URL。
范围类型:range
范围类型用于表示一个值区间,包含以下子类型:
- integer_range:整数范围,如 {"gte": 10, "lte": 20}。
- float_range:浮点数范围。
- long_range:长整数范围。
- double_range:双精度浮点数范围。
- date_range:日期范围,如 {"gte": "2020-01-01", "lte": "2020-12-31"}。
- ip_range:IP 地址范围,支持 IPv4 和 IPv6。
适用场景:年龄段、价格区间、会议时间、IP 段等。查询时可以使用专门的区间查询(如 range query)来匹配落在区间内的文档。
3.2.映射
映射(Mapping)是 Elasticsearch 中定义索引结构的关键环节,它决定了每个字段如何被存储、索引和搜索。合理设置映射不仅能保证数据正确性,还能大幅提升查询性能。下面逐一解释您列出的每个参数。
enabled
- 含义:是否对字段进行索引和搜索。
- 取值:true(默认)或 false。
- 说明:当设置为 false 时,该字段不会被索引,也无法用于搜索、排序或聚合,但原始字段值仍会保存在 _source 中(如果 _source 启用)。适用于仅需存储、无需检索的元数据(如大型描述文本),可以节省索引空间和提升写入速度。
index
- 含义:是否对字段构建倒排索引。
- 取值:true(默认)或 false。
- 说明:index: true 表示该字段可以被搜索;false 表示不可搜索,但字段值仍可返回(若 _source 存储)。常用于仅用于展示、不需要参与查询的字段(例如日志中的原始消息体,但需对部分字段单独搜索时,可以关闭其他字段的索引)。
index_options
含义:控制倒排索引中存储哪些信息,影响搜索能力和索引大小。
取值:
- docs:只存储文档编号,可用于词项是否存在判断(如 term 查询)。
- freqs:存储文档编号和词频,用于评分(如 BM25)。
- positions:存储文档编号、词频和词位置,用于短语查询(match_phrase)。
- offsets:存储文档编号、词频、位置和偏移量,用于高亮显示。
说明:默认值取决于字段类型,通常 text 类型默认为 positions,keyword 类型默认为 docs。根据查询需求选择合适的级别,可以平衡性能和存储开销。
dynamic
含义:控制映射能否自动添加新字段。
取值:
- true(默认):遇到未映射的字段,自动将其加入映射。
- false:忽略新字段,不索引也不存储(但 _source 中仍保留)。
- strict:遇到新字段抛出异常,拒绝写入。
说明:生产环境建议设为 false 或 strict,避免字段爆炸或类型冲突,保持映射清晰可控。
doc_values
- 含义:是否为字段开启列式存储(用于排序、聚合、脚本访问)。
- 取值:true(默认,除 text 外)或 false。
- 说明:doc_values 是正向索引结构,适合 keyword、数值、日期等不分析的字段。当需要对这些字段进行排序、聚合或脚本计算时,必须启用(默认已启用)。text 字段不支持 doc_values,只能通过 fielddata 实现类似功能(但代价较大)。
fielddata
- 含义:是否为 text 字段启用内存中的 fielddata 结构,以支持排序、聚合或脚本。
- 取值:true 或 false(默认)。
- 说明:text 字段默认禁用 fielddata,因为加载到堆内存中极耗资源。仅在必须对分词结果进行聚合或排序时启用,且需注意内存限制。通常推荐使用多字段(fields)方案,对同一份数据同时保留 text 和 keyword 类型,用 keyword 子字段做聚合。
store
- 含义:是否独立存储字段的值(脱离 _source 单独存储)。
- 取值:true 或 false(默认)。
- 说明:默认情况下,所有字段的值都保存在 _source 字段中。设置 store: true 会将字段值额外存储一份,以便在查询时只返回该字段(节省网络开销)。适用于频繁读取的大字段(如大段文本)或禁用 _source 的场景。注意这会增加存储空间。
coerce
- 含义:是否自动清理并转换字段值以匹配映射类型。
- 取值:true(默认)或 false。
- 说明:例如,当映射为 integer 但传入字符串 "5" 时,coerce: true 会将其转换为整数 5;若为 false 则抛出异常。同样,浮点数 "1.0" 可转为整数 1。开启有助于数据清洗,但可能掩盖脏数据。
analyzer
- 含义:指定用于索引和搜索的分词器(仅对 text 字段生效)。
- 取值:内置或自定义分词器名称,如 standard、ik_max_word。
- 说明:定义如何将文本拆分为词项。可以分别设置 search_analyzer 用于搜索,若未指定则默认使用 analyzer。良好的分词器选择直接影响搜索相关性。
boost
- 含义:字段级别的权重,用于提升该字段在查询评分中的重要性。
- 取值:浮点数,默认 1.0。
- 说明:在查询时,匹配该字段的文档得分会乘以 boost 值。适用于业务上需要突出某些字段的场景(如标题比正文更重要),但需注意过度使用可能扰乱评分。
fields
含义:为同一字段定义多个不同的索引方式(多字段)。
取值:一个子字段映射对象。
说明:常见用法是对 text 字段同时添加 keyword 子字段,实现全文搜索和精确聚合两用。例如:
javascript
"name": {
"type": "text",
"fields": {
"raw": { "type": "keyword" }
}
}这样 name 用于分词搜索,name.raw 用于排序和聚合。
date_detection
- 含义:是否自动识别字符串格式的日期并映射为 date 类型。
- 取值:true(默认)或 false。
- 说明:当 dynamic: true 且遇到类似 "2015-01-01" 的字符串时,ES 会尝试将其映射为 date。若设为 false,则视为 text。可配合 dynamic_templates 精细化控制。
3.3.基于Kibana的使用示例
我们在浏览器中访问:
http://你的服务器IP地址:5601注意:如果是云服务器的话,需要先去官网去开放防火墙端口和安全组端口。
然后进入下面这个界面
后面我们主要使用的是
也就是下面这个界面来操作ES
我们把里面的内容删除,换成我们自己写好的(注意不要注释)
示例1------创建索引
这里是一个最简单的创建索引的例子,不包含任何映射定义,完全使用 Elasticsearch 的默认设置。
- 创建索引(无映射)
在 Kibana 的 Dev Tools 中执行以下命令:
javascript
PUT /my_index说明:
- 这会在 Elasticsearch 中创建一个名为 my_index 的索引。
- 没有指定 mappings,因此索引使用动态映射------当你插入文档时,Elasticsearch 会自动检测字段类型并创建相应的映射。
- 索引的设置(如分片数、副本数)也全部采用默认值(通常主分片 1,副本分片 1)。
输入进去之后点下面这个
执行是否成功需要看状态码
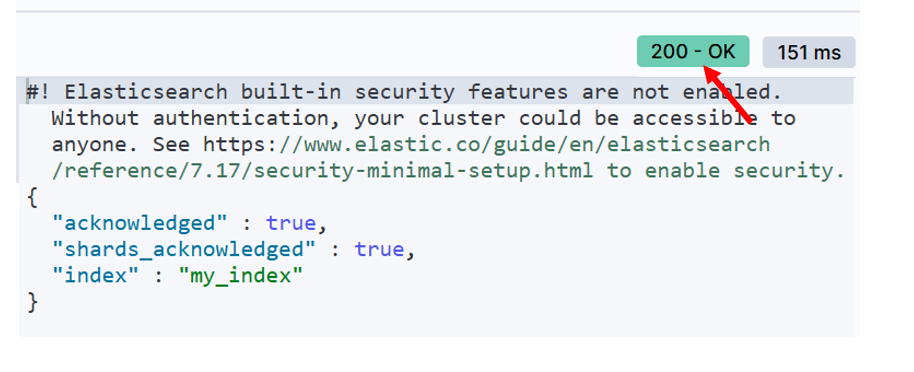
- 验证索引已创建
可以执行以下命令查看索引信息:
javascript
GET /my_index返回结果中会包含索引的基本设置和空的映射("mappings": { })。
- 添加数据(自动生成映射)
现在可以向索引中添加文档,字段类型会自动推断:
javascript
POST /my_index/_doc
{
"name": "张三",
"age": 25,
"email": "zhangsan@example.com"
}有的人可能好奇我们上面创建的索引明明是/my_index,为啥这里却往/my_index/_doc里面进行POST?
您创建了一个叫 my_index 的索引。建好之后,我们肯定要往里面放数据、查数据,或者修改它的设置。那么怎么操作呢?
其实**Elasticsearch 在创建索引的同时,就已经为这个索引自动配好了一套固定的操作入口。**这些入口就是那些带下划线的词,比如 _doc、_mapping、_settings、_search 等等。您不需要自己去创建它们,它们本来就存在,而且对每个索引都一样。
操作的方法特别简单:您只需要把索引名和操作入口名拼在一起,组成一个类似"地址"的东西,然后告诉 Elasticsearch 您想做什么就行了。
举个例子:
- 如果您想往 my_index 里添加一篇文档(也就是一条数据),就用 my_index/_doc 这个地址。
- 如果您想看看这个索引当初规定了哪些字段(比如规定了必须有姓名、年龄),就用 my_index/_mapping 这个地址。
- 如果您想修改这个索引的一些全局设置(比如把数据备份数量从1改成2),就用 my_index/_settings 这个地址。
- 如果您想从这个索引里搜索符合某些条件的数据,就用 my_index/_search 这个地址。
这些带下划线的词,就像是索引的"功能按钮"。索引本身只是一个容器,而通过这些按钮,您就能对容器本身或容器里的内容做各种操作。按钮是系统自带的,您只管用就行。
那么我们这里就是这样子的情况:
我们添加数据就必须使用**/索引名/_doc**这个地址,具体来说完整的操作入口如下:
javascript
/索引名/_doc/文档ID其中:
_doc是固定的路径段,不再代表具体的类型名,而是文档操作端点的标志。
所以:
-
POST /my_index/_doc→ 表示向my_index索引的文档集合中创建一篇新文档(不指定 ID,由 Elasticsearch 自动生成 ID)。 -
PUT /my_index/_doc/1→ 表示向my_index索引的文档集合中创建或替换 ID 为 1 的文档(指定 ID)。
为什么创建索引不用 /_doc,而创建文档要用 /_doc?
因为索引和文档是两个完全不同层级的资源:
-
索引是"数据库"本身,你可以在它上面设置全局属性(如分片数、分词器等)。
-
文档是"数据库里的一条记录",它必须归属于某个具体的索引。
类比关系型数据库:
-
PUT /my_index相当于CREATE DATABASE my_index;(但 Elasticsearch 的索引更接近于表,这里只是类比) -
POST /my_index/_doc相当于INSERT INTO my_index ...(指定了表名,但具体插入数据)
在 REST 设计中,资源的层次通过 URL 的路径层级来体现:
javascript
/my_index → 索引层(集合)
/my_index/_doc → 文档层(子集合)
/my_index/_doc/1 → 单个文档(元素)这种层次结构让 API 既统一又直观。
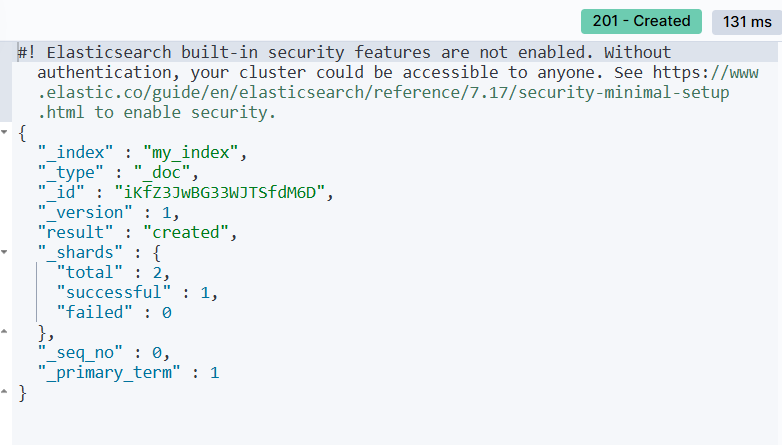
现在我们可以再去查看一下索引信息
javascript
GET /my_index

那么如果我只想观察映射呢?
javascript
GET /my_index/_mapping您创建了一个叫 my_index 的索引。建好之后,我们肯定要往里面放数据、查数据,或者修改它的设置。那么怎么操作呢?
其实**Elasticsearch 在创建索引的同时,就已经为这个索引自动配好了一套固定的操作入口。**这些入口就是那些带下划线的词,比如 _doc、_mapping、_settings、_search 等等。您不需要自己去创建它们,它们本来就存在,而且对每个索引都一样。
操作的方法特别简单:您只需要把索引名和操作入口名拼在一起,组成一个类似"地址"的东西,然后告诉 Elasticsearch 您想做什么就行了。
举个例子:
- 如果您想往 my_index 里添加一篇文档(也就是一条数据),就用 my_index/_doc 这个地址。
- 如果您想看看这个索引当初规定了哪些字段(比如规定了必须有姓名、年龄),就用 my_index/_mapping 这个地址。
- 如果您想修改这个索引的一些全局设置(比如把数据备份数量从1改成2),就用 my_index/_settings 这个地址。
- 如果您想从这个索引里搜索符合某些条件的数据,就用 my_index/_search 这个地址。
这些带下划线的词,就像是索引的"功能按钮"。索引本身只是一个容器,而通过这些按钮,您就能对容器本身或容器里的内容做各种操作。按钮是系统自带的,您只管用就行。
那么我们这里就是这样子的情况:
我们的索引是/my_index,那这里的_mapping 又是什么?
_mapping 也是一个固定的端点(endpoint),就像 _doc 一样。它们是 Elasticsearch 预定义的 API 路径,用于对索引或文档执行特定类型的操作。
- _mapping 用于操作索引的映射(mapping),即字段的定义规则。
- 通过 GET /my_index/_mapping,您可以查看 my_index 索引中所有字段的映射信息,包括字段类型、分词器、是否索引等设置。
- 如果您想更新索引的映射(例如添加一个新字段),可以使用 PUT /my_index/_mapping 并在请求体中携带新的字段定义。
你会看到 Elasticsearch 自动为 name、age、email 创建了对应的字段类型(例如 text、long、text,但 email 可能被映射为 text,如果你想要精确匹配,最好在创建时指定映射,或者使用 keyword 类型)。

可以看到就显示了我们的映射
- 删除索引
javascript
DELETE /my_index
示例2------创建索引,并同时定义映射
1. 创建索引(同时定义映射)
我们创建一个名为 my_users 的索引,包含三个字段:姓名、年龄、邮箱。使用默认分词器,不设置复杂参数。
bash
PUT /my_users
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"email": {
"type": "keyword"
}
}
}
}说明:
- name 使用 text 类型,支持全文搜索。
- age 使用 integer 类型,存储整数。
- email 使用 keyword 类型,适合精确匹配(如登录、过滤)。
那么其实我又有一个问题:mappings代表映射的话,那么为什么下面就不能直接就是字段的定义,而中间还需要加一个properties?
- mappings 的顶层结构
mappings 对象本身可以包含多种配置项,而不仅仅是字段定义。它相当于一个"映射配置容器",可以设置:
- properties:定义文档中的字段及其类型(您看到的)。
- dynamic:控制是否允许自动添加新字段(可以在索引级别设置,也可以在字段级别覆盖)。
- _source:配置原始文档的存储方式(例如是否禁用 _source)。
- dynamic_templates:动态模板,用于根据字段名或类型自动应用映射规则。
- date_detection / numeric_detection:是否自动识别日期/数字。
- routing:路由相关设置。
- meta:自定义元数据。
**如果字段定义直接放在 mappings 下(比如 mappings: { "name": { "type": "text" } }),那就会和这些顶级配置项混在一起,造成混乱。**例如,如果将来需要添加 dynamic 设置,就无法区分 dynamic 是顶级配置还是一个字段名。
因此,Elasticsearch 设计了一个专门的 properties 对象,用来集中存放所有字段的定义,这样顶级配置和字段定义就分开了,结构清晰且易于扩展。
- 为什么不能省略 properties?
假设省略 properties,直接将字段写在 mappings 下:
bash
{
"mappings": {
"name": { "type": "text" },
"age": { "type": "integer" }
}
}这时 Elasticsearch 就会困惑:name 和 age 到底是字段定义,还是像 dynamic 这样的顶级配置?如果未来增加一个新的顶级配置叫 age,岂不是冲突了?
为了避免这种歧义,Elasticsearch 强制要求所有字段定义必须放在 properties 对象内。这就像在编程中,一个类的成员变量必须放在类的内部,而不能和类的方法混在一起。
我们来看一个包含多种设置的完整映射例子:
bash
{
"mappings": {
"dynamic": false, // 顶级设置:禁止自动添加字段
"_source": { "enabled": false }, // 顶级设置:不存储原始文档
"properties": { // 字段定义都在这里
"name": { "type": "text" },
"age": { "type": "integer" },
"email": { "type": "keyword" }
}
}
}这里的层次结构一目了然:dynamic 和 _source 是映射的整体行为控制,properties 是具体的字段清单。如果字段定义直接写在顶层,就无法同时容纳这些设置。
总结一下:
- mappings 是映射的根对象,可以包含多种配置项。
- properties 是专门存放字段定义的地方,它的存在让映射结构层次分明,避免与顶级配置项混淆。
这是 Elasticsearch 设计上的一种规范,保证了映射的清晰性和可扩展性。
事实上我们的索引除了mappings也是还有其他东西的
然后我们点击下面这个
出现下面这个状态码就表示成功
2. 添加文档
我们添加三条用户记录,每条是一个独立的 JSON 文档。
bash
POST /my_users/_doc
{
"name": "张三",
"age": 25,
"email": "zhangsan@example.com"
}
POST /my_users/_doc
{
"name": "李四",
"age": 30,
"email": "lisi@example.com"
}
POST /my_users/_doc
{
"name": "王五",
"age": 28,
"email": "wangwu@example.com"
}说明:
- 每执行一次 POST 就添加一条文档。
- Elasticsearch 会自动为每个文档生成唯一 ID(也可以自己指定)。
接下来我们来了解一下
在 Elasticsearch 中,Bulk API 的标准端点格式是:
bashPOST /<索引名>/<类型名>/_bulk例如,你要对 user 索引执行批量操作,正确的请求路径应该是:
bashPOST /user/_doc/_bulk在 Elasticsearch 6.x 及之前版本,类型是必须的,因此这种带类型的路径很常见。在 Elasticsearch 7.x 中,类型概念被废弃,但为了向后兼容,仍然允许在路径中指定一个类型名(通常要求为 _doc)。此时,Elasticsearch 会忽略这个类型名,仅将其视为一种占位符,实际操作仍然针对前面的索引。
所以,POST /user/_doc/_bulk 的含义是:
- 索引名:user
- 类型名:_doc(被忽略)
- 端点:_bulk
只要你的 Elasticsearch 版本(7.x 或更高)支持这种兼容写法,这个路径就能正常工作。数据会写入 user 索引,而 _doc 仅仅是一个形式上的类型名称,不影响实际存储。
- 1. 如果让 Elasticsearch 自动生成文档 ID
你的 POST 请求没有指定 _id,Elasticsearch 会自动生成一个唯一 ID。
bashPOST /my_users/_doc { "name": "张三", "age": 25, "email": "zhangsan@example.com" }这在 Bulk API 中对应的写法是:
bashPOST /my_users/_doc/_bulk {"index":{}} // 元数据行,不指定 _id {"name":"张三","age":25,"email":"zhangsan@example.com"}
- 2. 如果你想手动指定 ID(例如 "1")
单条 API 可以使用 PUT 并指定 ID:
bashPOST /my_users/_doc/1 { "name": "张三", "age": 25, "email": "zhangsan@example.com" }对应的 Bulk 写法就是:
bashPOST /my_users/_doc/_bulk {"index":{"_id":"1"}} {"name":"张三","age":25,"email":"zhangsan@example.com"}
- 3.我们上面POST语句的等价 Bulk API 语句
事实上呢,上面这个添加文档的语句等价于下面这个
bashPOST /my_users/_doc/_bulk {"index":{}} {"name":"张三","age":25,"email":"zhangsan@example.com"} {"index":{}} {"name":"李四","age":30,"email":"lisi@example.com"} {"index":{}} {"name":"王五","age":28,"email":"wangwu@example.com"}每两行为一组,代表一个操作:
- 第一行是操作元数据:{"index":{}} 表示要执行一个索引(插入/更新)操作,且由于不指定 _id,Elasticsearch 会自动生成文档 ID。
- 第二行是实际的文档数据,即你要插入的 JSON 对象。
整个请求体是一个 文本块,每行之间必须用换行符(\n)分隔,并且最后一行也要以换行符结尾。
发送时需要设置 HTTP 头 Content-Type: application/json(或 application/x-ndjson,但 Elasticsearch 通常接受前者),并将请求发送到 Bulk API 端点,例如:
- POST /_bulk(对所有索引通用)
- POST /my_users/_bulk(指定默认索引名,这样元数据行中可以不写索引名)
3. 搜索数据
我们来搜索所有名字中包含"张"的用户。
bash
GET /my_users/_search
{
"query": {
"match": {
"name": "张"
}
}
}说明:
match 查询会在 name 字段中搜索"张",返回匹配的文档。
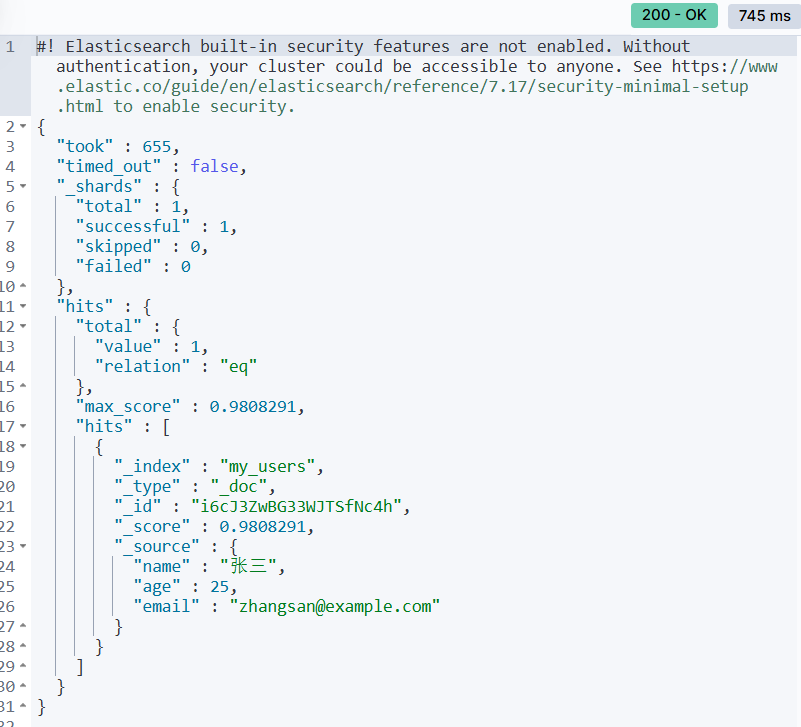
这个/my_users/_search又是什么鬼?
您创建了一个叫 my_index 的索引。建好之后,我们肯定要往里面放数据、查数据,或者修改它的设置。那么怎么操作呢?
其实**Elasticsearch 在创建索引的同时,就已经为这个索引自动配好了一套固定的操作入口。**这些入口就是那些带下划线的词,比如 _doc、_mapping、_settings、_search 等等。您不需要自己去创建它们,它们本来就存在,而且对每个索引都一样。
操作的方法特别简单:您只需要把索引名和操作入口名拼在一起,组成一个类似"地址"的东西,然后告诉 Elasticsearch 您想做什么就行了。
举个例子:
- 如果您想往 my_index 里添加一篇文档(也就是一条数据),就用 my_index/_doc 这个地址。
- 如果您想看看这个索引当初规定了哪些字段(比如规定了必须有姓名、年龄),就用 my_index/_mapping 这个地址。
- 如果您想修改这个索引的一些全局设置(比如把数据备份数量从1改成2),就用 my_index/_settings 这个地址。
- 如果您想从这个索引里搜索符合某些条件的数据,就用 my_index/_search 这个地址。
这些带下划线的词,就像是索引的"功能按钮"。索引本身只是一个容器,而通过这些按钮,您就能对容器本身或容器里的内容做各种操作。按钮是系统自带的,您只管用就行。
后面我就不再提了
4. 删除索引
如果不再需要这个索引,可以将其删除。
bash
DELETE /my_users
示例3------查询相关语句
Elasticsearch 的 bool 查询包含四种逻辑子句,它们可以灵活组合,实现复杂的搜索逻辑:
- must:子句中的条件必须全部满足(逻辑 AND)。 匹配的文档会参与相关度评分(_score),**即满足的条件越多、越匹配,得分越高。**常用于需要同时满足多个条件且希望影响评分的情况。
- filter: 子句中的条件也必须全部满足 (逻辑 AND),但与 must 不同之处在于不参与评分,仅作过滤。由于不计算评分,性能更好且结果可缓存。适合范围、状态、精确值等筛选。
- should: 子句中的条件至少满足一个 (逻辑 OR),**满足的条件越多,文档的相关度评分越高。**如果 bool 查询中没有 must 或 filter,则至少需要满足一个 should 条件(除非通过 minimum_should_match 参数另行控制)。
- must_not: 子句中的条件必须都不满足 (逻辑 NOT),用于排除文档。它也是过滤行为,不参与评分,同样可以利用缓存。
在构建 上面这4种 子句时,可以根据字段类型和查询意图选择不同的查询类型,其中最常用的是 term 和 match:
- term 查询 :用于精确匹配某个字段的确切值。它不会对查询词进行分析(即不分词),直接在倒排索引中查找与给定值完全相等的词条。适用于 keyword 类型、数值、日期等需要精确匹配的字段。
- 例如:{ "term": { "user_id": "USER4b862aaa..." } } 会精确匹配 user_id 字段为指定字符串的文档。
- match 查询 :用于全文搜索,会对查询文本进行分析**(分词)**,然后去匹配字段中的词条。它适用于 text 类型字段,会按照字段的分析器(如 IK 分词器)对查询字符串进行分词,再在倒排索引中查找这些词条。
- 例如:{ "match": { "nickname": "张三" } } 如果 nickname 是 text 类型,查询词 "张三" 会被分词为 "张" 和 "三",然后匹配包含这两个词的文档。
什么叫评分?
参与评分"是 Elasticsearch 中一个非常核心的概念。让我用最简单的生活例子来解释:
什么是评分(_score)?
评分就是 Elasticsearch 为每个匹配到的文档计算的一个"相关度分数",分数越高,代表这个文档越符合你的搜索意图,在结果中排得越靠前。
举个简单的例子
假设你有一个电影数据库,你要搜索"动作 科幻":
bash
GET /movies/_search
{
"query": {
"bool": {
"must": [
{ "match": { "title": "动作" } },
{ "match": { "title": "科幻" } }
]
}
}
}Elasticsearch 会找到所有同时包含"动作"和"科幻"的电影,并且:
-
给每部电影计算一个分数,计算方式可能包括:
-
"动作"和"科幻"这两个词在标题中出现的次数(词频)
-
这两个词在整个数据库中的稀有程度(逆向文档频率)
-
标题字段的长度等
-
结果排序:
-
电影A:《动作科幻大片》(同时包含两个词,分数最高)
-
电影B:《科幻动作冒险》(同时包含两个词,但标题稍长,分数略低)
-
电影C:《科幻电影》(只包含"科幻",不包含"动作",不会被匹配)
参与评分 vs 不参与评分
javascript
GET /movies/_search
{
"query": {
"bool": {
"must": [
{ "match": { "title": "动作" } } // 参与评分:影响排名
],
"filter": [
{ "term": { "year": 2023 } } // 不参与评分:只过滤,不计算分数
]
}
}
}- must 中的条件:不仅筛选文档,还会计算它们对相关度的贡献,影响最终排名。
- filter 中的条件**:只负责筛选(比如只要2023年的电影),不计算分数**,所以这些条件不会影响文档的排序位置,但执行更快,结果可缓存。
为什么需要不参与评分的条件?
- 性能更好:不计算分数,节省CPU。
- 可缓存:过滤条件的结果可以被缓存,相同条件再次查询更快。
- 逻辑清晰:有些条件只是筛选(如时间范围、状态),不应该影响相关性排序。
简单总结
- 参与评分 = 影响文档的排名顺序,用于决定哪个结果更相关。
- 不参与评分 = 只做筛选,不关心顺序,只要符合条件就行。
这就是为什么 must 和 should 参与评分(因为它们决定相关性),而 filter 和 must_not 不参与评分(它们只是过滤条件)。
示例
我们用一个电商商品搜索 的场景,来逐一讲解 bool 查询的四种子句。假设我们有一个 products 索引,里面存储了以下5件商品:
| ID | 名称 (name) | 品牌 (brand) | 价格 (price) | 库存 (stock) | 上架时间 (date) |
|---|---|---|---|---|---|
| 1 | 苹果手机 | Apple | 6000 | 10 | 2023-01-01 |
| 2 | 华为手机 | Huawei | 5000 | 5 | 2023-02-01 |
| 3 | 小米手机 | Xiaomi | 3000 | 0 | 2023-03-01 |
| 4 | 苹果平板 | Apple | 4000 | 8 | 2023-01-15 |
| 5 | 华为平板 | Huawei | 3500 | 3 | 2023-02-15 |
字段说明:name 是 text 类型(支持分词),brand 是 keyword 类型(精确匹配),price 和 stock 是数值类型,date 是日期类型。
must------ 必须满足,且影响评分
场景 :用户想搜索"名称包含'手机',并且品牌是'Apple'的商品"。这两个条件都必须满足,而且我们希望根据匹配程度排序(例如名称中"手机"出现次数等)。
查询:
javascript
GET /products/_search
{
"query": {
"bool": {
"must": [
{ "match": { "name": "手机" } },//分词搜索
{ "term": { "brand": "Apple" } }//不分词搜索
]
}
}
}执行结果 :只有商品1(苹果手机)满足条件。Elasticsearch 会为它计算一个 _score 分数(比如 0.8),这个分数决定了它在结果列表中的位置(虽然只有一个,但如果有多个文档,分数高的排前面)。
关键点 :must 中的条件既筛选文档 ,又贡献分数,因此结果会按相关度排序。
filter------ 必须满足,但不影响评分
场景:用户想搜索"价格在 3000 到 5000 之间,并且库存大于 0 的商品"。这些条件只是过滤,用户并不关心价格范围对排序的影响。
查询:
javascript
GET /products/_search
{
"query": {
"bool": {
"filter": [
{ "range": { "price": { "gte": 3000, "lte": 5000 } } },
{ "range": { "stock": { "gt": 0 } } }
]
}
}
}执行结果 :符合条件的商品有:商品2(华为手机)、商品4(苹果平板)、商品5(华为平板)。注意商品1价格6000超出范围,商品3库存0被排除。由于 filter 不参与评分,所有结果的 _score 都相同(例如 0.0),默认按文档插入顺序返回(实际可能按其他方式,但分数一致)。
关键点 :filter 只做筛选,不计算分数,因此性能更好,结果可以缓存。适合范围、精确值、状态等不需要影响排名的条件。
3. should ------ 至少满足一个(可选),满足越多评分越高
场景 :用户搜索"名称包含'手机'的商品",同时如果品牌是"Apple"或"Huawei"则让它们排得更靠前(因为这些品牌更受欢迎)。should 子句中的条件不是必须的,但满足会加分。
查询:
javascript
GET /products/_search
{
"query": {
"bool": {
"must": [
{ "match": { "name": "手机" } }//分词搜索
],
"should": [
{ "term": { "brand": "Apple" } },//不分词
{ "term": { "brand": "Huawei" } }//不分词
]
}
}
}执行结果:
-
所有名称包含"手机"的商品:商品1(Apple)、商品2(Huawei)、商品3(Xiaomi)都会返回。
-
商品1 满足一个
should条件(Apple),商品2 满足一个(Huawei),商品3 不满足任何should条件。 -
因此商品1和商品2的
_score会比商品3高,排在前面。
关键点 :should 用于提升相关性,满足的条件越多,分数越高。如果 bool 查询中没有 must 或 filter,那么至少需要满足一个 should 条件(除非用 minimum_should_match 修改)。
must_not------ 必须不满足,不参与评分
场景 :用户想搜索所有商品,但排除库存为0 的商品。must_not 条件用于过滤掉不需要的文档。
查询:
javascript
GET /products/_search
{
"query": {
"bool": {
"must_not": [
{ "term": { "stock": 0 } }//不分词
]
}
}
}执行结果 :返回除了商品3(小米手机)之外的所有商品。must_not 是过滤行为,不参与评分,所以所有结果的 _score 相同(或者与其他评分条件共同决定)。
关键点 :must_not 用于排除文档,同样不计算分数,结果可缓存。
综合示例:四种子句一起使用
假设我们想搜索"名称包含'手机',品牌是'Apple'或'Huawei',价格在 3000~6000 之间,排除库存为0的商品"。查询可以写成:
javascript
GET /products/_search
{
"query": {
"bool": {
"must": [
{ "match": { "name": "手机" } }//分词
],
"filter": [
{ "range": { "price": { "gte": 3000, "lte": 6000 } } }
],
"should": [
{ "term": { "brand": "Apple" } },//不分词
{ "term": { "brand": "Huawei" } }//不分词
],
"must_not": [
{ "term": { "stock": 0 } }//不分词
]
}
}
}执行逻辑:
-
must:名称必须包含"手机" → 商品1、2、3 进入候选。 -
filter:价格必须在 3000~6000 之间 → 商品1(6000)、商品2(5000)、商品3(3000)都满足(商品3价格3000在范围内)。 -
must_not:库存不能为0 → 商品3(库存0)被排除,剩下商品1和2。 -
should:如果品牌是Apple或Huawei则加分 → 商品1品牌Apple(加分),商品2品牌Huawei(加分)。两者都加分,分数可能相近,但根据具体算法可能有细微差异。
最终返回商品1和商品2,并且它们的 _score 会高于单纯 must+filter 的默认分数,因为 should 提升了它们。
返回的响应是
javascript
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 100,
"relation": "eq"
},
"max_score": 1.2,
"hits": [
{
"_index": "products",
"_type": "_doc",
"_id": "1",
"_score": 1.2,
"_source": {
"name": "苹果手机",
"brand": "Apple",
"price": 6000,
"stock": 10
}
},
{
"_index": "products",
"_type": "_doc",
"_id": "2",
"_score": 0.9,
"_source": {
"name": "华为手机",
"brand": "Huawei",
"price": 5000,
"stock": 5
}
}
]
}
}示例4------综合示例
我们现在就创建索引
在 Elasticsearch 中,POST /user/_doc 这种写法并不是用来创建索引的,而是用来索引(写入)一个文档的。 之所以你看到它能"直接创建索引",是因为 Elasticsearch 默认开启了自动创建索引的功能。
- Elasticsearch 有一个配置项 action.auto_create_index,默认值为 true(或某些特定模式),允许在写入文档时,如果目标索引不存在,就自动创建该索引。
- 因此,当你执行 POST /user/_doc(或 PUT /user/_doc/1)向一个不存在的索引写入文档时,Elasticsearch 会自动创建名为 user 的索引,然后再写入文档数据。
bash
POST /user/_doc
{
"settings": {
"analysis": {
"analyzer": {
"ik": {
"tokenizer": "ik_max_word"
}
}
}
},
"mappings": {
"dynamic": true,
"properties": {
"昵称": {
"type": "text",
"analyzer": "ik_max_word"
},
"用户ID": {
"type": "keyword",
"analyzer": "standard"
},
"手机号": {
"type": "keyword",
"analyzer": "standard"
},
"描述": {
"type": "text",
"enabled": false
},
"头像ID": {
"type": "keyword",
"enabled": false
}
}
}
}在 Elasticsearch 里创建一个名为 user 的索引,并且为这个索引设置好字段的"格式"(映射)和中文分词规则。但请求的地址用错了,所以实际效果可能和您想的不太一样。
让我用中文给您详细拆解一下:
📝 您本来想做什么(代码意图)
这个请求的"身体"部分(JSON)是正确的索引定义,它包含两大部分:
settings(设置)------ 配置中文分词器
- 定义了一个名为 ik 的自定义分析器,并指定它使用 ik_max_word 分词器。
- ik_max_word 是 IK 分词器的一种模式,它会将文本切成最细粒度的词,比如"中华人民共和国"会被切成"中华人民共和国"、"中华"、"华人"、"人民共和国"等,适合用于尽可能多地搜出结果(高召回率)。
mappings(映射)------ 定义字段的类型和行为
- dynamic: true:允许未来插入文档时,自动添加您没在这里定义的新字段(生产环境建议设为 false 或 strict 以控制字段数量)。
- 昵称:类型为 text(全文文本),并指定用刚才定义的 ik_max_word 分词器。这意味着搜索"昵称"时,会进行中文分词匹配。
- 用户ID 和 手机号:类型为 keyword(关键词),这意味着它们不会被分词,存成一个完整的字符串,适用于精确匹配(比如 用户ID: "abc123")、排序或聚合统计。但您给它们指定了 analyzer: "standard",这其实对 keyword 类型没有实际作用(keyword 本身不分词),可以忽略或删除。
- 描述 和 头像ID:这两个字段的 enabled: false 表示它们不会被索引(也就是不能用于搜索),但文档的原始数据里仍然会保留它们。这常用于存储一些不需要被搜索的辅助信息,以节省磁盘空间。
❌ 实际发生了什么(请求地址的问题)
使用的地址是 POST /user/_doc。
在 Elasticsearch 里,这个地址的标准用途是"创建一篇文档"(如果索引 user 不存在,它可能会根据动态映射自动创建,但不会读取您请求体里的 settings 和 mappings)。
因此,如果您用这个地址发送上面的 JSON,Elasticsearch 可能会:
因为找不到 user 索引,就自动创建了一个(但用的是默认设置,没有您定义的 IK 分词器)。
然后尝试把您整个 JSON(包括 settings 和 mappings 字段)当作一篇文档的内容存进去,这很可能导致错误,或者存进去一篇奇怪的文档。
然后我们点击下面这个
出现下面这个状态码就表示成功
这就算是完成了
那么我们新增数据
bash
POST /user/_doc/_bulk
{"index":{"_id":"1"}}
{"user_id":"USER4b862aaa-2df8654a-7eb4bb65e3507f66","nickname":"昵称1","phone":"手机号1","description":"签名1","avatar_id":"头像1"}
{"index":{"_id":"2"}}
{"user_id":"USER14eeeaa5-442771b9-0262e455e4663d1d","nickname":"昵称2","phone":"手机号2","description":"签名2","avatar_id":"头像2"}
{"index":{"_id":"3"}}
{"user_id":"USER484a6734-03a124f0-996c169dd05c1869","nickname":"昵称3","phone":"手机号3","description":"签名3","avatar_id":"头像3"}
{"index":{"_id":"4"}}
{"user_id":"USER186ade83-4460d4a6-8c08068f83127b5d","nickname":"昵称4","phone":"手机号4","description":"签名4","avatar_id":"头像4"}
{"index":{"_id":"5"}}
{"user_id":"USER6f19d074-c33891cf-23bf5a8357189a19","nickname":"昵称5","phone":"手机号5","description":"签名5","avatar_id":"头像5"}
{"index":{"_id":"6"}}
{"user_id":"USER97605c64-9833ebb7-d045535335a59195","nickname":"昵称6","phone":"手机号6","description":"签名6","avatar_id":"头像6"}注意这个数据插入语句等价于下面这个
bash
PUT /user/_doc/1
{"user_id":"USER4b862aaa-2df8654a-7eb4bb65e3507f66","nickname":"昵称1","phone":"手机号1","description":"签名1","avatar_id":"头像1"}
PUT /user/_doc/2
{"user_id":"USER14eeeaa5-442771b9-0262e455e4663d1d","nickname":"昵称2","phone":"手机号2","description":"签名2","avatar_id":"头像2"}
PUT /user/_doc/3
{"user_id":"USER484a6734-03a124f0-996c169dd05c1869","nickname":"昵称3","phone":"手机号3","description":"签名3","avatar_id":"头像3"}
PUT /user/_doc/4
{"user_id":"USER186ade83-4460d4a6-8c08068f83127b5d","nickname":"昵称4","phone":"手机号4","description":"签名4","avatar_id":"头像4"}
PUT /user/_doc/5
{"user_id":"USER6f19d074-c33891cf-23bf5a8357189a19","nickname":"昵称5","phone":"手机号5","description":"签名5","avatar_id":"头像5"}
PUT /user/_doc/6
{"user_id":"USER97605c64-9833ebb7-d045535335a59195","nickname":"昵称6","phone":"手机号6","description":"签名6","avatar_id":"头像6"}我们查询一下数据
bash
GET /user/_doc/_search?pretty
{
"query": {
"bool": {
"must_not": [
{
"terms": {
"user_id.keyword": [
"USER4b862aaa-2df8654a-7eb4bb65e3507f66",
"USER14eeeaa5-442771b9-0262e455e4663d1d",
"USER484a6734-03a124f0-996c169dd05c1869"
]
}
}
],
"should": [
{
"match": {
"user_id": "昵称"
}
},
{
"match": {
"nickname": "昵称"
}
},
{
"match": {
"phone": "昵称"
}
}
]
}
}
}
然后我们删除索引
bash
DELETE /user
3.4.基于ES客户端的使用示例
我们上面是在可视化界面进行操作的,但是实际上,我们在操作的时候其实是通过代码来进行操作的。所以上面的步骤我们了解一下即可。
insert.cpp
cpp
#include <elasticlient/client.h>
#include <json/json.h>
#include <iostream>
#include <cpr/cpr.h>
int main() {
// 创建一个 elasticlient::Client 对象,指定 Elasticsearch 服务的地址列表
// 这里使用本地默认端口 9200,实际部署时可替换为集群地址
elasticlient::Client client({"http://127.0.0.1:9200/"});//地址最后一定要加一个斜杠
// 构造要索引的文档(JSON 格式)
// Json::Value 是 jsoncpp 中表示任意 JSON 数据的类
Json::Value doc;
// 设置文档的 "title" 字段为字符串 "Example Document"
doc["title"] = "Example Document";
// 设置文档的 "content" 字段为字符串 "This is a simple test."
doc["content"] = "This is a simple test.";
// 设置文档的 "timestamp" 字段为字符串 "2025-03-12"
doc["timestamp"] = "2025-03-12";
// 创建一个 jsoncpp 的流式写入器生成器,用于将 Json::Value 序列化为字符串
Json::StreamWriterBuilder builder;
// 将 doc 对象序列化为 JSON 字符串,作为 HTTP 请求的请求体
std::string body = Json::writeString(builder, doc);
// 调用 index 方法(索引名:test_index,类型:_doc,文档ID:1)
// client.index() 方法用于在指定索引中创建或更新文档
// 参数依次为:索引名称、文档类型(Elasticsearch 7.x 后通常用 _doc)、文档 ID、JSON 字符串
// 如果索引不存在,默认会自动创建(但推荐预先创建索引以定义映射和分片设置)
auto response = client.index("test_index", "_doc", "1", body);
// 检查响应状态码(2xx 表示成功)
// response.status_code 是 HTTP 状态码,2xx 代表成功,4xx/5xx 代表错误
if (response.status_code >= 200 && response.status_code < 300)
{
// 输出成功信息,并打印 Elasticsearch 返回的响应体(通常包含结果信息,如 "created" 或 "updated")
std::cout << "文档索引成功!" << std::endl;
std::cout << "响应体:" << response.text << std::endl;
}
else
{
// 如果状态码不是 2xx,输出错误状态码
std::cerr << "索引失败,HTTP 状态码:" << response.status_code << std::endl;
}
return 0;
}search.cpp
cpp
#include <elasticlient/client.h>
#include <json/json.h>
#include <iostream>
#include <sstream>
#include <cpr/cpr.h>
int main() {
// 创建一个 elasticlient::Client 对象,指定 Elasticsearch 服务的地址列表
// 这里使用本地默认端口 9200,实际部署时可替换为集群地址
elasticlient::Client client({"http://127.0.0.1:9200/"});//地址最后一定要加一个斜杠
// 构造查询 DSL(Domain Specific Language),这里使用 match_all 查询所有文档
// Json::Value 是 jsoncpp 中表示任意 JSON 数据的类
Json::Value query;
// 设置 query 对象的 "query" 字段为一个对象,其内包含 "match_all" 字段(值为空对象)
// 等价于 JSON: { "query": { "match_all": {} } }
query["query"]["match_all"] = Json::objectValue;
// 创建一个 jsoncpp 的流式写入器生成器,用于将 Json::Value 序列化为字符串
Json::StreamWriterBuilder builder;
// 将 query 对象序列化为 JSON 字符串,作为 HTTP 请求的请求体
std::string requestBody = Json::writeString(builder, query);
// 执行搜索操作,指定索引名称为 "test_index",请求体为上面构造的 DSL
// 返回的 response 对象包含 HTTP 状态码、响应头、响应体等信息
auto response = client.search("test_index", "_doc", requestBody, "");
// 检查 HTTP 响应状态码是否为 200(成功)
if (response.status_code == 200)
{
// 创建一个 jsoncpp 的字符读取器生成器,用于从流中解析 JSON
Json::CharReaderBuilder readerBuilder;
// 用于存储解析后的 JSON 数据
Json::Value root;
// 用于接收解析过程中的错误信息
std::string errs;
// 将响应体的字符串包装为输入字符串流,以便 jsoncpp 从流中解析
std::istringstream iss(response.text);
// 从流中解析 JSON 数据,结果存入 root,错误信息存入 errs
if (Json::parseFromStream(readerBuilder, iss, &root, &errs))
{
// 从解析后的 JSON 中提取 "hits" 下的 "hits" 数组,该数组包含实际匹配的文档列表
auto hits = root["hits"]["hits"];
// 输出找到的文档总数(hits 数组的大小)
std::cout << "共找到 " << hits.size() << " 条文档:" << std::endl;
// 遍历每个命中的文档
for (const auto& hit : hits)
{
// 输出文档的 _id(文档唯一标识)、_score(相关性得分)以及 _source(原始文档内容)
// 使用 toStyledString() 将 JSON 对象格式化为带缩进的字符串,便于阅读
std::cout << " ID: " << hit["_id"].asString()
<< ",得分: " << hit["_score"].asFloat()
<< ",来源: " << hit["_source"].toStyledString();
}
}
else
{
// 如果 JSON 解析失败,输出错误信息
std::cerr << "解析响应失败: " << errs << std::endl;
}
}
else
{
// 如果 HTTP 状态码不是 200,输出错误状态码
std::cerr << "搜索失败,HTTP 状态码:" << response.status_code << std::endl;
}
return 0;
}remove.cpp
cpp
#include <elasticlient/client.h>
#include <iostream>
#include <cpr/cpr.h>
int main() {
elasticlient::Client client({"http://127.0.0.1:9200/"});//地址最后一定要加一个斜杠
// 删除索引 test_index 中 ID 为 1 的文档
auto response = client.remove("test_index", "_doc", "1");
/*remove() 方法根据索引、类型和文档 ID 删除文档。
成功时通常返回 200 或 204。*/
if (response.status_code >= 200 && response.status_code < 300) {
std::cout << "文档删除成功!" << std::endl;
} else {
std::cerr << "删除失败,HTTP 状态码:" << response.status_code << std::endl;
}
return 0;
}makefile
cpp
all: insert search remove
insert: insert.cpp
g++ -g -std=c++11 $^ -o $@ -lelasticlient -lcpr -ljsoncpp
search: search.cpp
g++ -std=c++11 $^ -o $@ -lelasticlient -lcpr -ljsoncpp
remove: remove.cpp
g++ -std=c++11 $^ -o $@ -lelasticlient -lcpr -ljsoncpp
.PHONY: clean
clean:
rm -f insert search remove编译测试一下
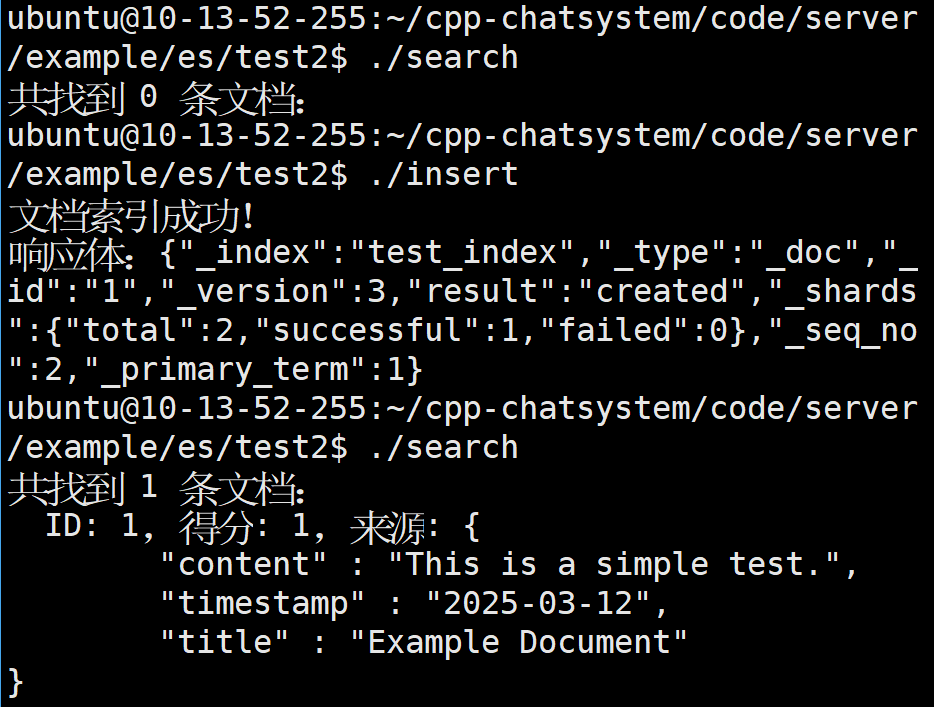
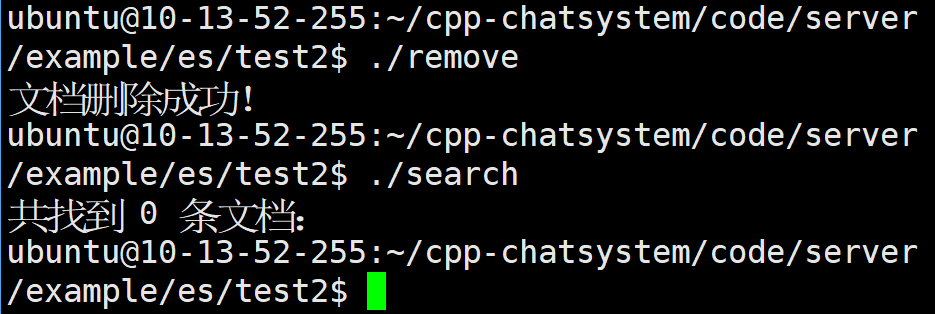
非常完美!!!
四.对ES 客户端API二次封装
Elasticsearch 原生客户端仅提供了基础的 REST API 调用能力,开发者在使用时需要自行构建复杂的 JSON 请求体,包括索引映射(mapping)的定义、文档的增删改查以及查询 DSL 的组装。这种手动拼接 JSON 的方式不仅繁琐、容易出错,而且难以复用和维护,大大降低了开发效率。
为此,我们对 Elasticsearch 客户端 API 进行了二次封装,旨在将底层的 JSON 构造细节隐藏起来,对外提供一套简洁、直观的接口。使用者无需关心具体的 JSON 格式,只需通过链式调用或生成器模式动态添加字段、设置属性即可完成索引创建、数据插入、查询构造和文档删除等操作。
封装的核心接口
-
- 索引创建(ESIndex)
-
- 数据插入(ESInsert)
-
- 数据删除(ESRemove)
-
- 数据查询(ESSearch)
那么在实现这4个核心接口之前,我们需要先完成下面这2个核心接口
- 将 Json::Value 对象序列化为字符串
- 将字符串反序列化为 Json::Value 对象
cpp
// 函数:将 Json::Value 对象序列化为字符串
// 参数 val:要序列化的 JSON 对象
// 参数 dst:输出参数,用于存储序列化后的 JSON 字符串
// 返回值:成功返回 true,失败返回 false
bool Serialize(const Json::Value &val, std::string &dst)
{
// 创建 Json::StreamWriterBuilder 工厂类,用于配置和生成 StreamWriter
Json::StreamWriterBuilder swb;
// 设置选项:emitUTF8 为 true,确保生成的 JSON 字符串中 UTF-8 字符不被转义
swb.settings_["emitUTF8"] = true;//这个是针对JSON的设置
// 通过 StreamWriterBuilder 创建一个新的 StreamWriter 对象(使用智能指针自动管理)
std::unique_ptr<Json::StreamWriter> sw(swb.newStreamWriter());
// 创建一个字符串流,用于接收序列化输出
std::stringstream ss;
// 调用 StreamWriter 的 write 方法,将 val 写入到字符串流中
int ret = sw->write(val, &ss);
if (ret != 0) {
// 如果返回值不为 0,表示序列化失败,输出错误信息
std::cout << "Json反序列化失败!\n";
return false;
}
// 将字符串流的内容赋给输出参数 dst
dst = ss.str();
return true;
}
// 函数:将字符串反序列化为 Json::Value 对象
// 参数 src:包含 JSON 数据的字符串
// 参数 val:输出参数,用于存储解析后的 JSON 对象
// 返回值:成功返回 true,失败返回 false
bool UnSerialize(const std::string &src, Json::Value &val)
{
// 创建 Json::CharReaderBuilder 工厂类,用于配置和生成 CharReader
Json::CharReaderBuilder crb;
// 通过 CharReaderBuilder 创建一个新的 CharReader 对象(使用智能指针自动管理)
std::unique_ptr<Json::CharReader> cr(crb.newCharReader());
// 用于存储解析过程中的错误信息
std::string err;
// 调用 CharReader 的 parse 方法,从字符串 src 中解析 JSON 数据
// 参数:起始指针、结束指针、输出 Json::Value、错误信息字符串
bool ret = cr->parse(src.c_str(), src.c_str() + src.size(), &val, &err);
if (ret == false) {
// 如果解析失败,输出错误信息
std::cout << "json反序列化失败: " << err << std::endl;
return false;
}
return true;
}那么为什么具体这么写?我就不在这里进行讲解了。
4.1. 索引创建(ESIndex)
这块的功能就是创建索引(定义好字段)
构造函数
我们可以借助上面是示例4来讲解我们的编写过程
bash
POST /user/_doc
{
"settings": {
"analysis": {
"analyzer": {
"ik": {
"tokenizer": "ik_max_word"
}
}
}
},
"mappings": {
"dynamic": true,
"properties": {
"昵称": {
"type": "text",
"analyzer": "ik_max_word"
},
"用户ID": {
"type": "keyword",
"analyzer": "standard"
},
"手机号": {
"type": "keyword",
"analyzer": "standard"
},
"描述": {
"type": "text",
"enabled": false
},
"头像ID": {
"type": "keyword",
"enabled": false
}
}
}
}如果我们要想写构造函数,那么就是适用于任何索引的,那么在我们这里,好像也就是settings字段是不会进行变化的,那么我们就把这一部分的编写放到构造函数里面去。
我们先看看构造函数
cpp
// 构造函数:初始化索引名称、文档类型,并设置默认的 IK 分词器配置
// 参数 client:指向 elasticlient::Client 的共享指针,用于发送 HTTP 请求
// 参数 name:索引名称
// 参数 type:文档类型,默认为 "_doc"(Elasticsearch 7.x 后推荐)
ESIndex(std::shared_ptr<elasticlient::Client> &client,
const std::string &name,
const std::string &type = "_doc"):
_name(name), _type(type), _client(client)
{
// 构建索引设置(settings)部分,配置 IK 分词器
Json::Value analysis; // analysis 对象
Json::Value analyzer; // analyzer 对象
Json::Value ik; // ik 分词器对象
Json::Value tokenizer; // tokenizer 对象
// 设置分词器为 ik_max_word(IK 分词器的最大粒度分词模式)
tokenizer["tokenizer"] = "ik_max_word";
// 将 tokenizer 赋值给 ik 对象下的 "ik" 字段
ik["ik"] = tokenizer;
// 将 ik 对象赋值给 analyzer 对象下的 "analyzer" 字段
analyzer["analyzer"] = ik;
// 将 analyzer 对象赋值给 analysis 对象下的 "analysis" 字段
analysis["analysis"] = analyzer;
// 将 analysis 对象放入 _index 的 "settings" 字段中
_index["settings"] = analysis;
}构造函数的目的是在 Elasticsearch 中配置索引的 IK 分词器,构造出的结构如下图所示
cpp
{
"settings": {
"analysis": {
"analyzer": {
"ik": {
"tokenizer": "ik_max_word"
}
}
}
}
}这段 JSON 在 Kibana 中对应创建一个索引时写在 settings 里的内容。它的意思是:定义了一个名为 ik 的分析器(analyzer),这个分析器使用 ik_max_word 分词器(这是 IK 分词插件提供的最大粒度分词模式)。之后你在字段定义中指定 "analyzer": "ik" 时,就会使用这个分析器对文本进行分词。
这个结构就是最终存放到了下面这个成员变量里面
cpp
Json::Value _index; // 完整的索引定义(包含 settings 和 mappings)properties字段的添加
我们接着来看看上面的示例4
bash
POST /user/_doc
{
"settings": {
"analysis": {
"analyzer": {
"ik": {
"tokenizer": "ik_max_word"
}
}
}
},
"mappings": {
"dynamic": true,
"properties": {
"昵称": {
"type": "text",
"analyzer": "ik_max_word"
},
"用户ID": {
"type": "keyword",
"analyzer": "standard"
},
"手机号": {
"type": "keyword",
"analyzer": "standard"
},
"描述": {
"type": "text",
"enabled": false
},
"头像ID": {
"type": "keyword",
"enabled": false
}
}
}
}在封装 Elasticsearch 索引创建功能时,我们深入理解了索引映射(mapping)的底层结构。通过分析 Elasticsearch 的索引定义可知,所有字段的真正定义都集中在 mappings 对象下的 properties 字段中------每个字段的名称、类型、分词器、索引选项等属性均以键值对形式存储于其中。
因此,为了提供最直观、最贴近 Elasticsearch 核心概念的接口,我们围绕 mappings.properties 设计了字段添加的接口。
这一设计的核心思想是:**让开发者直接针对"字段"这一核心单元进行配置,而无需关心外层的 JSON 嵌套。**用户通过链式调用添加字段时,实际上是在向内部的 _properties 对象中填充数据,最终这些数据会被准确放置到生成的索引定义 JSON 的 mappings.properties 路径下。这种设计不仅符合 Elasticsearch 的原生语义,还使得接口的使用方式与索引的实际结构一一对应,降低了学习成本。
这个结构最终都是存放到了下面这个成员变量里面
Json::Value _properties; // 存储字段定义的 JSON 对象(mapping 的 properties 部分)我们看看
cpp
// 成员函数 append:向索引的 properties 中添加一个字段定义(链式调用)
// 参数 key:字段名称
// 参数 type:字段类型,默认为 "text"
// 参数 analyzer:分词器名称,默认为 "ik_max_word"
// 参数 enabled:是否启用该字段(若为 false,则该字段不会被索引和存储)
// 返回值:返回当前对象的引用,支持链式调用
ESIndex& append(const std::string &key,
const std::string &type = "text",
const std::string &analyzer = "ik_max_word",
bool enabled = true)
{
Json::Value fields;
fields["type"] = type; // 设置字段类型
fields["analyzer"] = analyzer; // 设置分词器(仅对 text 类型有效)
if (enabled == false)
{
// 如果 enabled 为 false,则添加 "enabled": false 字段,表示该字段不参与索引和存储
fields["enabled"] = enabled;
}
// 将该字段定义添加到 _properties 对象中,键为字段名
_properties[key] = fields;
// 返回当前对象引用,以便链式调用
return *this;
}这里采用了链式调用风格
关键就在于 return *this。
- this 是指向当前对象的指针。
- *this 就是当前对象本身。
- 函数返回类型是 ESIndex&,即当前对象的引用,所以调用者得到的就是原来的那个对象。
这样一来,当你调用一次 append 后,返回值仍然是原来的 ESIndex 对象,于是可以紧接着再次调用它的 append 方法,如此反复,就形成了链式调用。
举个例子
假设你想创建一个索引,其中包含三个字段:标题、内容和浏览量。用链式调用可以这样写:
cpp
ESIndex index(client, "articles"); // 创建 ESIndex 对象
index.append("title", "text", "ik_max_word")
.append("content", "text", "ik_max_word")
.append("views", "integer")
.create(); // 最后创建索引执行过程是这样的:
- 第一个 append("title", ...) 执行完后,返回 index 本身。
- 接着对返回的 index 调用 append("content", ...),再次返回 index。
- 再对 index 调用 append("views", ...),返回 index。
- 最后调用 create(),完成索引创建。
如果不使用链式调用,你就得写成多行:
cpp
index.append("title", "text", "ik_max_word");
index.append("content", "text", "ik_max_word");
index.append("views", "integer");
index.create();链式调用的好处是代码更紧凑、可读性更强,尤其适合这种需要连续添加多个配置项的场景。很多库(如建造者模式、查询构造器)都广泛采用这种设计。
发起索引创建请求
我们还是来看示例4
bash
POST /user/_doc
{
"settings": {
"analysis": {
"analyzer": {
"ik": {
"tokenizer": "ik_max_word"
}
}
}
},
"mappings": {
"dynamic": true,
"properties": {
"昵称": {
"type": "text",
"analyzer": "ik_max_word"
},
"用户ID": {
"type": "keyword",
"analyzer": "standard"
},
"手机号": {
"type": "keyword",
"analyzer": "standard"
},
"描述": {
"type": "text",
"enabled": false
},
"头像ID": {
"type": "keyword",
"enabled": false
}
}
}
}按照上面的步骤,我们现在已经有了settings字段,mappings.properties字段。
那么我们接下来就来组织剩余的字段,并且向服务器发起创建文档的请求。
在创建文档的过程中,如果索引不存在,那么ES就会自动创建索引。
cpp
// 成员函数 create:根据已添加的字段定义,创建索引(实际发送请求到 Elasticsearch)
// 参数 index_id:可选的索引文档 ID,但这里可能用于某些特殊场景,默认为 "default_index_id"
// 注意:在 elasticlient 的 index 方法中,如果指定了 ID,会创建或更新一个文档,而不是创建索引本身。
// 但是如果索引不存在,那么就会自动触发索引的自动创建(同时设置 mapping),
bool create(const std::string &index_id = "default_index_id")
{
// 构建 mappings 部分
Json::Value mappings;
mappings["dynamic"] = true; // 允许动态添加字段(未在 mapping 中定义的字段也会被索引)
mappings["properties"] = _properties; // 将字段定义赋值给 properties
_index["mappings"] = mappings; // 将 mappings 对象放入 _index 的 "mappings" 字段
// 将整个 _index 对象序列化为字符串
std::string body;
bool ret = Serialize(_index, body);
if (ret == false) {
LOG_ERROR("索引序列化失败!");
return false;
}
LOG_DEBUG("{}", body); // 输出序列化后的请求体,便于调试
// 发起索引创建请求(实际上调用的是 index 方法,可能期望创建索引并插入一个文档)
try
{
// 调用 client->index 方法,传入索引名称、类型、文档 ID 和请求体
// 注意:这实际上是在创建或更新一个文档,而不是纯粹的创建索引。
// 如果索引不存在,Elasticsearch 会自动创建索引并使用请求体中的 mapping 作为索引的 mapping。
auto rsp = _client->index(_name, _type, index_id, body);
// 检查响应状态码是否为 2xx(成功)
if (rsp.status_code < 200 || rsp.status_code >= 300) {
LOG_ERROR("创建ES索引 {} 失败,响应状态码异常: {}", _name, rsp.status_code);
return false;
}
}
catch(std::exception &e)
{
// 捕获异常并记录错误
LOG_ERROR("创建ES索引 {} 失败: {}", _name, e.what());
return false;
}
return true;
}ESIndex::create 函数通过 _client->index 并指定了一个默认的 index_id,这相当于在创建索引的同时还插入了一条文档(ID 为 "default_index_id")。
这种做法虽然利用了自动创建机制,但不太规范:通常创建索引应该使用 Elasticsearch 的 PUT /{index} API(对应 client->createIndex(...) 之类的方法,如果 elasticlient 提供的话)。
不过在当前代码中,它也能达到目的------只要请求体中包含正确的 settings 和 mappings,Elasticsearch 就会按照这个结构创建索引。
完整代码
cpp
// 类 ESIndex:用于定义和创建 Elasticsearch 索引的映射(mapping)和设置(settings)
class ESIndex
{
public:
// 构造函数:初始化索引名称、文档类型,并设置默认的 IK 分词器配置
// 参数 client:指向 elasticlient::Client 的共享指针,用于发送 HTTP 请求
// 参数 name:索引名称
// 参数 type:文档类型,默认为 "_doc"(Elasticsearch 7.x 后推荐)
ESIndex(std::shared_ptr<elasticlient::Client> &client,
const std::string &name,
const std::string &type = "_doc"):
_name(name), _type(type), _client(client)
{
// 构建索引设置(settings)部分,配置 IK 分词器
Json::Value analysis; // analysis 对象
Json::Value analyzer; // analyzer 对象
Json::Value ik; // ik 分词器对象
Json::Value tokenizer; // tokenizer 对象
// 设置分词器为 ik_max_word(IK 分词器的最大粒度分词模式)
tokenizer["tokenizer"] = "ik_max_word";
// 将 tokenizer 赋值给 ik 对象下的 "ik" 字段
ik["ik"] = tokenizer;
// 将 ik 对象赋值给 analyzer 对象下的 "analyzer" 字段
analyzer["analyzer"] = ik;
// 将 analyzer 对象赋值给 analysis 对象下的 "analysis" 字段
analysis["analysis"] = analyzer;
// 将 analysis 对象放入 _index 的 "settings" 字段中
_index["settings"] = analysis;
}
// 成员函数 append:向索引的 properties 中添加一个字段定义(链式调用)
// 参数 key:字段名称
// 参数 type:字段类型,默认为 "text"
// 参数 analyzer:分词器名称,默认为 "ik_max_word"
// 参数 enabled:是否启用该字段(若为 false,则该字段不会被索引和存储)
// 返回值:返回当前对象的引用,支持链式调用
ESIndex& append(const std::string &key,
const std::string &type = "text",
const std::string &analyzer = "ik_max_word",
bool enabled = true)
{
Json::Value fields;
fields["type"] = type; // 设置字段类型
fields["analyzer"] = analyzer; // 设置分词器(仅对 text 类型有效)
if (enabled == false)
{
// 如果 enabled 为 false,则添加 "enabled": false 字段,表示该字段不参与索引和存储
fields["enabled"] = enabled;
}
// 将该字段定义添加到 _properties 对象中,键为字段名
_properties[key] = fields;
// 返回当前对象引用,以便链式调用
return *this;
}
// 成员函数 create:根据已添加的字段定义,创建索引(实际发送请求到 Elasticsearch)
// 参数 index_id:可选的索引文档 ID,但这里可能用于某些特殊场景,默认为 "default_index_id"
// 注意:在 elasticlient 的 index 方法中,如果指定了 ID,会创建或更新一个文档,而不是创建索引本身。
// 但是如果索引不存在,那么就会自动触发索引的自动创建(同时设置 mapping),
bool create(const std::string &index_id = "default_index_id")
{
// 构建 mappings 部分
Json::Value mappings;
mappings["dynamic"] = true; // 允许动态添加字段(未在 mapping 中定义的字段也会被索引)
mappings["properties"] = _properties; // 将字段定义赋值给 properties
_index["mappings"] = mappings; // 将 mappings 对象放入 _index 的 "mappings" 字段
// 将整个 _index 对象序列化为字符串
std::string body;
bool ret = Serialize(_index, body);
if (ret == false) {
LOG_ERROR("索引序列化失败!");
return false;
}
LOG_DEBUG("{}", body); // 输出序列化后的请求体,便于调试
// 发起索引创建请求(实际上调用的是 index 方法,可能期望创建索引并插入一个文档)
try
{
// 调用 client->index 方法,传入索引名称、类型、文档 ID 和请求体
// 注意:这实际上是在创建或更新一个文档,而不是纯粹的创建索引。
// 如果索引不存在,Elasticsearch 会自动创建索引并使用请求体中的 mapping 作为索引的 mapping。
auto rsp = _client->index(_name, _type, index_id, body);
// 检查响应状态码是否为 2xx(成功)
if (rsp.status_code < 200 || rsp.status_code >= 300) {
LOG_ERROR("创建ES索引 {} 失败,响应状态码异常: {}", _name, rsp.status_code);
return false;
}
}
catch(std::exception &e)
{
// 捕获异常并记录错误
LOG_ERROR("创建ES索引 {} 失败: {}", _name, e.what());
return false;
}
return true;
}
private:
std::string _name; // 索引名称
std::string _type; // 文档类型(通常为 "_doc")
Json::Value _properties; // 存储字段定义的 JSON 对象(mapping 的 properties 部分)
Json::Value _index; // 完整的索引定义(包含 settings 和 mappings)
std::shared_ptr<elasticlient::Client> _client; // 共享的 elasticlient 客户端指针
};那么我们就实现了这样的一个文档+索引创建。
使用方法对比
如果不调用 append 就直接调用 create,和调用 append 添加了字段后再调用 create,两者最主要的区别在于:最终创建的索引中是否包含预定义的字段映射(mapping properties)。
1. 不调用 append 直接 create
_properties 为空({})。
构建的请求体中,mappings 部分如下:
cpp
{
"mappings": {
"dynamic": true,
"properties": {}
},
"settings": { ... } // IK 分词器设置
}结果:创建的索引 没有任何预定义字段,但由于 dynamic 为 true,后续插入文档时,Elasticsearch 会根据文档内容动态推断字段类型并自动添加到 mapping 中。
缺点:动态推断的类型可能不符合预期(例如字符串可能被同时映射为 text 和 keyword,但不会自动应用 IK 分词器),且无法对特定字段设置分词器、是否索引等精细控制。
2. 调用 append 添加字段后再 create
通过多次调用 append,_properties 中会积累多个字段定义,例如:
cpp
index.append("title", "text", "ik_max_word")
.append("content", "text", "ik_max_word")
.append("views", "integer");此时 _properties 大致为:
cpp
{
"title": {"type": "text", "analyzer": "ik_max_word"},
"content": {"type": "text", "analyzer": "ik_max_word"},
"views": {"type": "integer"}
}最终请求体的 mappings.properties 就会包含这些字段定义。
结果:创建的索引 按照你定义的字段结构建立映射,每个字段都明确了类型、分词器(对 text 类型)、是否启用等。之后插入文档时,Elasticsearch 会严格按照这些定义处理字段,确保中文分词生效,数值字段正确映射等。
4.2. 数据插入(ESInsert)
这一块的功能就是向已存在的索引中插入文档数据。
那么我们这里是使用下面这种方式来进行插入的
bash
POST /my_users/_doc
{
"name": "张三",
"age": 25,
"email": "zhangsan@example.com"
}那么我们只需要组织好括号里面的数据结构即可。
那其实挺简单的,就使用一个Json::Value来保存即可
cpp
// 模板成员函数 append:向待插入的文档中添加字段(链式调用)
// 参数 key:字段名
// 参数 val:字段值,可以是任意类型(Json::Value 支持的类型)
// 返回值:返回当前对象的引用,支持链式调用
template<typename T>
ESInsert &append(const std::string &key, const T &val){
_item[key] = val; // 将键值对存入 _item 对象
return *this;
}这里也是采用了链式调用
我们拿一个Json::Value对象来存储这个样式
cpp
Json::Value _item; // 存储待插入文档的 JSON 对象有了这个,我们直接发起数据插入请求即可。
完整代码
cpp
// 类 ESInsert:用于向 Elasticsearch 索引中插入或更新文档
class ESInsert
{
public:
// 构造函数:初始化索引名称、文档类型和客户端指针
ESInsert(std::shared_ptr<elasticlient::Client> &client,
const std::string &name, //索引名称
const std::string &type = "_doc"):
_name(name),
_type(type),
_client(client){}
// 模板成员函数 append:向待插入的文档中添加字段(链式调用)
// 参数 key:字段名
// 参数 val:字段值,可以是任意类型(Json::Value 支持的类型)
// 返回值:返回当前对象的引用,支持链式调用
template<typename T>
ESInsert &append(const std::string &key, const T &val){
_item[key] = val; // 将键值对存入 _item 对象
return *this;
}
// 成员函数 insert:将构建的文档插入到 Elasticsearch 中
// 参数 id:可选,文档的 ID。如果为空字符串,Elasticsearch 会自动生成 ID。
// 返回值:成功返回 true,失败返回 false
bool insert(const std::string id = "")
{
// 将 _item 序列化为 JSON 字符串
std::string body;
bool ret = Serialize(_item, body);
if (ret == false)
{
LOG_ERROR("索引序列化失败!");
return false;
}
LOG_DEBUG("{}", body); // 输出请求体,便于调试
// 发起索引文档请求
try
{
// 调用 client->index 方法,传入索引名、类型、文档 ID 和请求体
auto rsp = _client->index(_name, _type, id, body);
// 检查响应状态码
if (rsp.status_code < 200 || rsp.status_code >= 300) {
LOG_ERROR("新增数据 {} 失败,响应状态码异常: {}", body, rsp.status_code);
return false;
}
}
catch(std::exception &e)
{
LOG_ERROR("新增数据 {} 失败: {}", body, e.what());
return false;
}
return true;
}
private:
std::string _name; // 索引名称
std::string _type; // 文档类型
Json::Value _item; // 存储待插入文档的 JSON 对象
std::shared_ptr<elasticlient::Client> _client; // 共享的客户端指针
};4.3. 数据删除(ESRemove)
该封装类简化了文档删除操作,仅需提供文档 ID 即可。
-
按 ID 删除:封装了底层的删除请求,自动处理索引名、文档类型和 ID 的拼接。
-
结果校验:检查 HTTP 响应状态码,确保删除成功或捕获异常并反馈。
cpp
// 类 ESRemove:用于从 Elasticsearch 索引中删除文档
class ESRemove
{
public:
// 构造函数:初始化索引名称、文档类型和客户端指针
ESRemove(std::shared_ptr<elasticlient::Client> &client,
const std::string &name,
const std::string &type = "_doc"):
_name(name), _type(type), _client(client){}
// 成员函数 remove:根据文档 ID 删除文档
// 参数 id:要删除的文档 ID
// 返回值:成功返回 true,失败返回 false
bool remove(const std::string &id)
{
try
{
// 调用 client->remove 方法,传入索引名、类型和文档 ID
auto rsp = _client->remove(_name, _type, id);
// 检查响应状态码
if (rsp.status_code < 200 || rsp.status_code >= 300) {
LOG_ERROR("删除数据 {} 失败,响应状态码异常: {}", id, rsp.status_code);
return false;
}
} catch(std::exception &e) {
LOG_ERROR("删除数据 {} 失败: {}", id, e.what());
return false;
}
return true;
}
private:
std::string _name; // 索引名称
std::string _type; // 文档类型
std::shared_ptr<elasticlient::Client> _client; // 共享的客户端指针
};这个说实话没什么好说的
4.4. 数据查询(ESSearch)
我们还是拿上面的示例3来作为基板
javascript
GET /products/_search
{
"query": {
"bool": {
"must": [
{ "match": { "name": "手机" } }//分词
],
"filter": [
{ "range": { "price": { "gte": 3000, "lte": 6000 } } }
],
"should": [
{ "term": { "brand": "Apple" } },//不分词
{ "term": { "brand": "Huawei" } }//不分词
],
"must_not": [
{ "term": { "stock": 0 } }//不分词
]
}
}
}首先看看这个
must_not字段
我们这里的must_not就固定死了,使用term(不分词模式)
javascript
// 成员函数 append_must_not_terms:向 bool 查询的 must_not 子句中添加一个 terms 条件
// terms 用于精确匹配多个值(相当于 SQL 的 IN)
// 参数 key:字段名
// 参数 vals:要匹配的值列表
// 返回值:返回当前对象的引用,支持链式调用
ESSearch& append_must_not_terms(const std::string &key, const std::vector<std::string> &vals)
{
Json::Value fields;
for (const auto& val : vals)
{
fields[key].append(val); // 构造 { "field": [val1, val2, ...] } 形式的 JSON
}
Json::Value terms;
terms["terms"] = fields; // 包装成 { "terms": { "field": [...] } }
_must_not.append(terms); // 将该条件添加到 must_not 数组中
return *this;
}注意这里也是链式调用结构
里面的内容全部存放到了下面这个成员变量里面
javascript
Json::Value _must_not; // 存储 must_not 子句的数组should字段
我们这里的should字段也是固定死了使用match模式(分词模式)
javascript
// 成员函数 append_should_match:向 bool 查询的 should 子句中添加一个 match 条件
// match 用于全文搜索,会对查询文本进行分词
// 参数 key:字段名
// 参数 val:要匹配的文本
// 返回值:返回当前对象的引用
ESSearch& append_should_match(const std::string &key, const std::string &val) {
Json::Value field;
field[key] = val; // 构造 { "field": "value" }
Json::Value match;
match["match"] = field; // 包装成 { "match": { "field": "value" } }
_should.append(match); // 添加到 should 数组
return *this;
}也是链式调用结构
javascript
Json::Value _should; // 存储 should 子句的数组must字段
那么针对must字段,我们提供了2种接口
- term模式(不分词模式)
- match模式(分词模式)
javascript
// 成员函数 append_must_term:向 bool 查询的 must 子句中添加一个 term 条件
// term 用于精确匹配单个值(不分析查询词)
// 参数 key:字段名
// 参数 val:要匹配的值
// 返回值:返回当前对象的引用
ESSearch& append_must_term(const std::string &key, const std::string &val) {
Json::Value field;
field[key] = val; // 构造 { "field": "value" }
Json::Value term;
term["term"] = field; // 包装成 { "term": { "field": "value" } }
_must.append(term); // 添加到 must 数组
return *this;
}
// 成员函数 append_must_match:向 bool 查询的 must 子句中添加一个 match 条件
// 参数 key:字段名
// 参数 val:要匹配的文本
// 返回值:返回当前对象的引用
ESSearch& append_must_match(const std::string &key, const std::string &val){
Json::Value field;
field[key] = val; // 构造 { "field": "value" }
Json::Value match;
match["match"] = field; // 包装成 { "match": { "field": "value" } }
_must.append(match); // 添加到 must 数组
return *this;
}这里都是链式调用结构。
它们都是存放到了下面这个成员变量里面
javascript
Json::Value _must; // 存储 must 子句的数组发起请求
我们还是拿示例3的例子来组织我们的代码
javascript
GET /products/_search
{
"query": {
"bool": {
"must": [
{ "match": { "name": "手机" } }//分词
],
"filter": [
{ "range": { "price": { "gte": 3000, "lte": 6000 } } }
],
"should": [
{ "term": { "brand": "Apple" } },//不分词
{ "term": { "brand": "Huawei" } }//不分词
],
"must_not": [
{ "term": { "stock": 0 } }//不分词
]
}
}
}那么写起来我们的代码也是很简单的
javascript
// 成员函数 search:执行搜索,返回命中的文档列表
// 返回值:Json::Value 类型,包含 "hits.hits" 数组,即所有匹配的文档
Json::Value search()
{
// 构建 bool 查询的条件对象
Json::Value cond;
if (_must_not.empty() == false) cond["must_not"] = _must_not; // 添加 must_not 条件
if (_should.empty() == false) cond["should"] = _should; // 添加 should 条件
if (_must.empty() == false) cond["must"] = _must; // 添加 must 条件
// 构建查询 DSL
Json::Value query;
query["bool"] = cond; // 将条件封装到 bool 查询中
Json::Value root;
root["query"] = query; // 完整的查询 DSL
// 将查询 DSL 序列化为字符串
std::string body;
bool ret = Serialize(root, body);
if (ret == false) {
LOG_ERROR("索引序列化失败!");
return Json::Value(); // 返回空 Json::Value
}
LOG_DEBUG("{}", body); // 输出请求体,便于调试
// 发起搜索请求
cpr::Response rsp;
try {
// 调用 client->search 方法,传入索引名、类型和请求体
rsp = _client->search(_name, _type, body);
// 检查响应状态码
if (rsp.status_code < 200 || rsp.status_code >= 300) {
LOG_ERROR("检索数据 {} 失败,响应状态码异常: {}", body, rsp.status_code);
return Json::Value();
}
} catch(std::exception &e) {
LOG_ERROR("检索数据 {} 失败: {}", body, e.what());
return Json::Value();
}
// 对响应正文进行反序列化
LOG_DEBUG("检索响应正文: [{}]", rsp.text);
Json::Value json_res;
ret = UnSerialize(rsp.text, json_res);
if (ret == false) {
LOG_ERROR("检索数据 {} 结果反序列化失败", rsp.text);
return Json::Value();
}
// 返回 hits.hits 数组,即匹配的文档列表
return json_res["hits"]["hits"];
}至于返回的响应结构,我们看看示例3的
javascript
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 100,
"relation": "eq"
},
"max_score": 1.2,
"hits": [
{
"_index": "products",
"_type": "_doc",
"_id": "1",
"_score": 1.2,
"_source": {
"name": "苹果手机",
"brand": "Apple",
"price": 6000,
"stock": 10
}
},
{
"_index": "products",
"_type": "_doc",
"_id": "2",
"_score": 0.9,
"_source": {
"name": "华为手机",
"brand": "Huawei",
"price": 5000,
"stock": 5
}
}
]
}
}这个 JSON 结构是解析 Elasticsearch 搜索结果的基础,你需要从中提取 hits.hits 数组来获取文档数据。
完整代码
javascript
// 类 ESSearch:用于构建复杂的布尔查询并执行搜索
class ESSearch
{
public:
// 构造函数:初始化索引名称、文档类型和客户端指针
ESSearch(std::shared_ptr<elasticlient::Client> &client,
const std::string &name,
const std::string &type = "_doc"):
_name(name), _type(type), _client(client){}
// 成员函数 append_must_not_terms:向 bool 查询的 must_not 子句中添加一个 terms 条件
// terms 用于精确匹配多个值(相当于 SQL 的 IN)
// 参数 key:字段名
// 参数 vals:要匹配的值列表
// 返回值:返回当前对象的引用,支持链式调用
ESSearch& append_must_not_terms(const std::string &key, const std::vector<std::string> &vals)
{
Json::Value fields;
for (const auto& val : vals)
{
fields[key].append(val); // 构造 { "field": [val1, val2, ...] } 形式的 JSON
}
Json::Value terms;
terms["terms"] = fields; // 包装成 { "terms": { "field": [...] } }
_must_not.append(terms); // 将该条件添加到 must_not 数组中
return *this;
}
// 成员函数 append_should_match:向 bool 查询的 should 子句中添加一个 match 条件
// match 用于全文搜索,会对查询文本进行分词
// 参数 key:字段名
// 参数 val:要匹配的文本
// 返回值:返回当前对象的引用
ESSearch& append_should_match(const std::string &key, const std::string &val) {
Json::Value field;
field[key] = val; // 构造 { "field": "value" }
Json::Value match;
match["match"] = field; // 包装成 { "match": { "field": "value" } }
_should.append(match); // 添加到 should 数组
return *this;
}
// 成员函数 append_must_term:向 bool 查询的 must 子句中添加一个 term 条件
// term 用于精确匹配单个值(不分析查询词)
// 参数 key:字段名
// 参数 val:要匹配的值
// 返回值:返回当前对象的引用
ESSearch& append_must_term(const std::string &key, const std::string &val) {
Json::Value field;
field[key] = val; // 构造 { "field": "value" }
Json::Value term;
term["term"] = field; // 包装成 { "term": { "field": "value" } }
_must.append(term); // 添加到 must 数组
return *this;
}
// 成员函数 append_must_match:向 bool 查询的 must 子句中添加一个 match 条件
// 参数 key:字段名
// 参数 val:要匹配的文本
// 返回值:返回当前对象的引用
ESSearch& append_must_match(const std::string &key, const std::string &val){
Json::Value field;
field[key] = val; // 构造 { "field": "value" }
Json::Value match;
match["match"] = field; // 包装成 { "match": { "field": "value" } }
_must.append(match); // 添加到 must 数组
return *this;
}
// 成员函数 search:执行搜索,返回命中的文档列表
// 返回值:Json::Value 类型,包含 "hits.hits" 数组,即所有匹配的文档
Json::Value search()
{
// 构建 bool 查询的条件对象
Json::Value cond;
if (_must_not.empty() == false) cond["must_not"] = _must_not; // 添加 must_not 条件
if (_should.empty() == false) cond["should"] = _should; // 添加 should 条件
if (_must.empty() == false) cond["must"] = _must; // 添加 must 条件
// 构建查询 DSL
Json::Value query;
query["bool"] = cond; // 将条件封装到 bool 查询中
Json::Value root;
root["query"] = query; // 完整的查询 DSL
// 将查询 DSL 序列化为字符串
std::string body;
bool ret = Serialize(root, body);
if (ret == false) {
LOG_ERROR("索引序列化失败!");
return Json::Value(); // 返回空 Json::Value
}
LOG_DEBUG("{}", body); // 输出请求体,便于调试
// 发起搜索请求
cpr::Response rsp;
try {
// 调用 client->search 方法,传入索引名、类型和请求体
rsp = _client->search(_name, _type, body);
// 检查响应状态码
if (rsp.status_code < 200 || rsp.status_code >= 300) {
LOG_ERROR("检索数据 {} 失败,响应状态码异常: {}", body, rsp.status_code);
return Json::Value();
}
} catch(std::exception &e) {
LOG_ERROR("检索数据 {} 失败: {}", body, e.what());
return Json::Value();
}
// 对响应正文进行反序列化
LOG_DEBUG("检索响应正文: [{}]", rsp.text);
Json::Value json_res;
ret = UnSerialize(rsp.text, json_res);
if (ret == false) {
LOG_ERROR("检索数据 {} 结果反序列化失败", rsp.text);
return Json::Value();
}
// 返回 hits.hits 数组,即匹配的文档列表
return json_res["hits"]["hits"];
}
private:
std::string _name; // 索引名称
std::string _type; // 文档类型
Json::Value _must_not; // 存储 must_not 子句的数组
Json::Value _should; // 存储 should 子句的数组
Json::Value _must; // 存储 must 子句的数组
std::shared_ptr<elasticlient::Client> _client; // 共享的客户端指针
};4.5.完整代码+测试
icsearch.hpp
cpp
#pragma once
#include <elasticlient/client.h>
#include <cpr/cpr.h>
#include <json/json.h>
#include <iostream>
#include <memory>
#include "logger.hpp"
// 定义命名空间 IMS,封装所有 Elasticsearch 相关操作
namespace IMS
{
// 函数:将 Json::Value 对象序列化为字符串
// 参数 val:要序列化的 JSON 对象
// 参数 dst:输出参数,用于存储序列化后的 JSON 字符串
// 返回值:成功返回 true,失败返回 false
bool Serialize(const Json::Value &val, std::string &dst)
{
// 创建 Json::StreamWriterBuilder 工厂类,用于配置和生成 StreamWriter
Json::StreamWriterBuilder swb;
// 设置选项:emitUTF8 为 true,确保生成的 JSON 字符串中 UTF-8 字符不被转义
swb.settings_["emitUTF8"] = true;//这个是针对JSON的设置
// 通过 StreamWriterBuilder 创建一个新的 StreamWriter 对象(使用智能指针自动管理)
std::unique_ptr<Json::StreamWriter> sw(swb.newStreamWriter());
// 创建一个字符串流,用于接收序列化输出
std::stringstream ss;
// 调用 StreamWriter 的 write 方法,将 val 写入到字符串流中
int ret = sw->write(val, &ss);
if (ret != 0) {
// 如果返回值不为 0,表示序列化失败,输出错误信息
std::cout << "Json反序列化失败!\n";
return false;
}
// 将字符串流的内容赋给输出参数 dst
dst = ss.str();
return true;
}
// 函数:将字符串反序列化为 Json::Value 对象
// 参数 src:包含 JSON 数据的字符串
// 参数 val:输出参数,用于存储解析后的 JSON 对象
// 返回值:成功返回 true,失败返回 false
bool UnSerialize(const std::string &src, Json::Value &val)
{
// 创建 Json::CharReaderBuilder 工厂类,用于配置和生成 CharReader
Json::CharReaderBuilder crb;
// 通过 CharReaderBuilder 创建一个新的 CharReader 对象(使用智能指针自动管理)
std::unique_ptr<Json::CharReader> cr(crb.newCharReader());
// 用于存储解析过程中的错误信息
std::string err;
// 调用 CharReader 的 parse 方法,从字符串 src 中解析 JSON 数据
// 参数:起始指针、结束指针、输出 Json::Value、错误信息字符串
bool ret = cr->parse(src.c_str(), src.c_str() + src.size(), &val, &err);
if (ret == false) {
// 如果解析失败,输出错误信息
std::cout << "json反序列化失败: " << err << std::endl;
return false;
}
return true;
}
// 类 ESIndex:用于定义和创建 Elasticsearch 索引的映射(mapping)和设置(settings)
class ESIndex
{
public:
// 构造函数:初始化索引名称、文档类型,并设置默认的 IK 分词器配置
// 参数 client:指向 elasticlient::Client 的共享指针,用于发送 HTTP 请求
// 参数 name:索引名称
// 参数 type:文档类型,默认为 "_doc"(Elasticsearch 7.x 后推荐)
ESIndex(std::shared_ptr<elasticlient::Client> &client,
const std::string &name,
const std::string &type = "_doc"):
_name(name), _type(type), _client(client)
{
// 构建索引设置(settings)部分,配置 IK 分词器
Json::Value analysis; // analysis 对象
Json::Value analyzer; // analyzer 对象
Json::Value ik; // ik 分词器对象
Json::Value tokenizer; // tokenizer 对象
// 设置分词器为 ik_max_word(IK 分词器的最大粒度分词模式)
tokenizer["tokenizer"] = "ik_max_word";
// 将 tokenizer 赋值给 ik 对象下的 "ik" 字段
ik["ik"] = tokenizer;
// 将 ik 对象赋值给 analyzer 对象下的 "analyzer" 字段
analyzer["analyzer"] = ik;
// 将 analyzer 对象赋值给 analysis 对象下的 "analysis" 字段
analysis["analysis"] = analyzer;
// 将 analysis 对象放入 _index 的 "settings" 字段中
_index["settings"] = analysis;
}
// 成员函数 append:向索引的 properties 中添加一个字段定义(链式调用)
// 参数 key:字段名称
// 参数 type:字段类型,默认为 "text"
// 参数 analyzer:分词器名称,默认为 "ik_max_word"
// 参数 enabled:是否启用该字段(若为 false,则该字段不会被索引和存储)
// 返回值:返回当前对象的引用,支持链式调用
ESIndex& append(const std::string &key,
const std::string &type = "text",
const std::string &analyzer = "ik_max_word",
bool enabled = true)
{
Json::Value fields;
fields["type"] = type; // 设置字段类型
fields["analyzer"] = analyzer; // 设置分词器(仅对 text 类型有效)
if (enabled == false)
{
// 如果 enabled 为 false,则添加 "enabled": false 字段,表示该字段不参与索引和存储
fields["enabled"] = enabled;
}
// 将该字段定义添加到 _properties 对象中,键为字段名
_properties[key] = fields;
// 返回当前对象引用,以便链式调用
return *this;
}
// 成员函数 create:根据已添加的字段定义,创建索引(实际发送请求到 Elasticsearch)
// 参数 index_id:可选的索引文档 ID,但这里可能用于某些特殊场景,默认为 "default_index_id"
// 注意:在 elasticlient 的 index 方法中,如果指定了 ID,会创建或更新一个文档,而不是创建索引本身。
// 但是如果索引不存在,那么就会自动触发索引的自动创建(同时设置 mapping),
bool create(const std::string &index_id = "default_index_id")
{
// 构建 mappings 部分
Json::Value mappings;
mappings["dynamic"] = true; // 允许动态添加字段(未在 mapping 中定义的字段也会被索引)
mappings["properties"] = _properties; // 将字段定义赋值给 properties
_index["mappings"] = mappings; // 将 mappings 对象放入 _index 的 "mappings" 字段
// 将整个 _index 对象序列化为字符串
std::string body;
bool ret = Serialize(_index, body);
if (ret == false) {
LOG_ERROR("索引序列化失败!");
return false;
}
LOG_DEBUG("{}", body); // 输出序列化后的请求体,便于调试
// 发起索引创建请求(实际上调用的是 index 方法,可能期望创建索引并插入一个文档)
try
{
// 调用 client->index 方法,传入索引名称、类型、文档 ID 和请求体
// 注意:这实际上是在创建或更新一个文档,而不是纯粹的创建索引。
// 如果索引不存在,Elasticsearch 会自动创建索引并使用请求体中的 mapping 作为索引的 mapping。
auto rsp = _client->index(_name, _type, index_id, body);
// 检查响应状态码是否为 2xx(成功)
if (rsp.status_code < 200 || rsp.status_code >= 300) {
LOG_ERROR("创建ES索引 {} 失败,响应状态码异常: {}", _name, rsp.status_code);
return false;
}
}
catch(std::exception &e)
{
// 捕获异常并记录错误
LOG_ERROR("创建ES索引 {} 失败: {}", _name, e.what());
return false;
}
return true;
}
private:
std::string _name; // 索引名称
std::string _type; // 文档类型(通常为 "_doc")
Json::Value _properties; // 存储字段定义的 JSON 对象(mapping 的 properties 部分)
Json::Value _index; // 完整的索引定义(包含 settings 和 mappings)
std::shared_ptr<elasticlient::Client> _client; // 共享的 elasticlient 客户端指针
};
// 类 ESInsert:用于向 Elasticsearch 索引中插入或更新文档
class ESInsert
{
public:
// 构造函数:初始化索引名称、文档类型和客户端指针
ESInsert(std::shared_ptr<elasticlient::Client> &client,
const std::string &name, //索引名称
const std::string &type = "_doc"):
_name(name),
_type(type),
_client(client){}
// 模板成员函数 append:向待插入的文档中添加字段(链式调用)
// 参数 key:字段名
// 参数 val:字段值,可以是任意类型(Json::Value 支持的类型)
// 返回值:返回当前对象的引用,支持链式调用
template<typename T>
ESInsert &append(const std::string &key, const T &val){
_item[key] = val; // 将键值对存入 _item 对象
return *this;
}
// 成员函数 insert:将构建的文档插入到 Elasticsearch 中
// 参数 id:可选,文档的 ID。如果为空字符串,Elasticsearch 会自动生成 ID。
// 返回值:成功返回 true,失败返回 false
bool insert(const std::string id = "")
{
// 将 _item 序列化为 JSON 字符串
std::string body;
bool ret = Serialize(_item, body);
if (ret == false)
{
LOG_ERROR("索引序列化失败!");
return false;
}
LOG_DEBUG("{}", body); // 输出请求体,便于调试
// 发起索引文档请求
try
{
// 调用 client->index 方法,传入索引名、类型、文档 ID 和请求体
auto rsp = _client->index(_name, _type, id, body);
// 检查响应状态码
if (rsp.status_code < 200 || rsp.status_code >= 300) {
LOG_ERROR("新增数据 {} 失败,响应状态码异常: {}", body, rsp.status_code);
return false;
}
}
catch(std::exception &e)
{
LOG_ERROR("新增数据 {} 失败: {}", body, e.what());
return false;
}
return true;
}
private:
std::string _name; // 索引名称
std::string _type; // 文档类型
Json::Value _item; // 存储待插入文档的 JSON 对象
std::shared_ptr<elasticlient::Client> _client; // 共享的客户端指针
};
// 类 ESRemove:用于从 Elasticsearch 索引中删除文档
class ESRemove
{
public:
// 构造函数:初始化索引名称、文档类型和客户端指针
ESRemove(std::shared_ptr<elasticlient::Client> &client,
const std::string &name,
const std::string &type = "_doc"):
_name(name), _type(type), _client(client){}
// 成员函数 remove:根据文档 ID 删除文档
// 参数 id:要删除的文档 ID
// 返回值:成功返回 true,失败返回 false
bool remove(const std::string &id)
{
try
{
// 调用 client->remove 方法,传入索引名、类型和文档 ID
auto rsp = _client->remove(_name, _type, id);
// 检查响应状态码
if (rsp.status_code < 200 || rsp.status_code >= 300) {
LOG_ERROR("删除数据 {} 失败,响应状态码异常: {}", id, rsp.status_code);
return false;
}
} catch(std::exception &e) {
LOG_ERROR("删除数据 {} 失败: {}", id, e.what());
return false;
}
return true;
}
private:
std::string _name; // 索引名称
std::string _type; // 文档类型
std::shared_ptr<elasticlient::Client> _client; // 共享的客户端指针
};
// 类 ESSearch:用于构建复杂的布尔查询并执行搜索
class ESSearch
{
public:
// 构造函数:初始化索引名称、文档类型和客户端指针
ESSearch(std::shared_ptr<elasticlient::Client> &client,
const std::string &name,
const std::string &type = "_doc"):
_name(name), _type(type), _client(client){}
// 成员函数 append_must_not_terms:向 bool 查询的 must_not 子句中添加一个 terms 条件
// terms 用于精确匹配多个值(相当于 SQL 的 IN)
// 参数 key:字段名
// 参数 vals:要匹配的值列表
// 返回值:返回当前对象的引用,支持链式调用
ESSearch& append_must_not_terms(const std::string &key, const std::vector<std::string> &vals)
{
Json::Value fields;
for (const auto& val : vals)
{
fields[key].append(val); // 构造 { "field": [val1, val2, ...] } 形式的 JSON
}
Json::Value terms;
terms["terms"] = fields; // 包装成 { "terms": { "field": [...] } }
_must_not.append(terms); // 将该条件添加到 must_not 数组中
return *this;
}
// 成员函数 append_should_match:向 bool 查询的 should 子句中添加一个 match 条件
// match 用于全文搜索,会对查询文本进行分词
// 参数 key:字段名
// 参数 val:要匹配的文本
// 返回值:返回当前对象的引用
ESSearch& append_should_match(const std::string &key, const std::string &val) {
Json::Value field;
field[key] = val; // 构造 { "field": "value" }
Json::Value match;
match["match"] = field; // 包装成 { "match": { "field": "value" } }
_should.append(match); // 添加到 should 数组
return *this;
}
// 成员函数 append_must_term:向 bool 查询的 must 子句中添加一个 term 条件
// term 用于精确匹配单个值(不分析查询词)
// 参数 key:字段名
// 参数 val:要匹配的值
// 返回值:返回当前对象的引用
ESSearch& append_must_term(const std::string &key, const std::string &val) {
Json::Value field;
field[key] = val; // 构造 { "field": "value" }
Json::Value term;
term["term"] = field; // 包装成 { "term": { "field": "value" } }
_must.append(term); // 添加到 must 数组
return *this;
}
// 成员函数 append_must_match:向 bool 查询的 must 子句中添加一个 match 条件
// 参数 key:字段名
// 参数 val:要匹配的文本
// 返回值:返回当前对象的引用
ESSearch& append_must_match(const std::string &key, const std::string &val){
Json::Value field;
field[key] = val; // 构造 { "field": "value" }
Json::Value match;
match["match"] = field; // 包装成 { "match": { "field": "value" } }
_must.append(match); // 添加到 must 数组
return *this;
}
// 成员函数 search:执行搜索,返回命中的文档列表
// 返回值:Json::Value 类型,包含 "hits.hits" 数组,即所有匹配的文档
Json::Value search()
{
// 构建 bool 查询的条件对象
Json::Value cond;
if (_must_not.empty() == false) cond["must_not"] = _must_not; // 添加 must_not 条件
if (_should.empty() == false) cond["should"] = _should; // 添加 should 条件
if (_must.empty() == false) cond["must"] = _must; // 添加 must 条件
// 构建查询 DSL
Json::Value query;
query["bool"] = cond; // 将条件封装到 bool 查询中
Json::Value root;
root["query"] = query; // 完整的查询 DSL
// 将查询 DSL 序列化为字符串
std::string body;
bool ret = Serialize(root, body);
if (ret == false) {
LOG_ERROR("索引序列化失败!");
return Json::Value(); // 返回空 Json::Value
}
LOG_DEBUG("{}", body); // 输出请求体,便于调试
// 发起搜索请求
cpr::Response rsp;
try {
// 调用 client->search 方法,传入索引名、类型和请求体
rsp = _client->search(_name, _type, body);
// 检查响应状态码
if (rsp.status_code < 200 || rsp.status_code >= 300) {
LOG_ERROR("检索数据 {} 失败,响应状态码异常: {}", body, rsp.status_code);
return Json::Value();
}
} catch(std::exception &e) {
LOG_ERROR("检索数据 {} 失败: {}", body, e.what());
return Json::Value();
}
// 对响应正文进行反序列化
LOG_DEBUG("检索响应正文: [{}]", rsp.text);
Json::Value json_res;
ret = UnSerialize(rsp.text, json_res);
if (ret == false) {
LOG_ERROR("检索数据 {} 结果反序列化失败", rsp.text);
return Json::Value();
}
// 返回 hits.hits 数组,即匹配的文档列表
return json_res["hits"]["hits"];
}
private:
std::string _name; // 索引名称
std::string _type; // 文档类型
Json::Value _must_not; // 存储 must_not 子句的数组
Json::Value _should; // 存储 should 子句的数组
Json::Value _must; // 存储 must 子句的数组
std::shared_ptr<elasticlient::Client> _client; // 共享的客户端指针
};
} // 命名空间 IMS 结束测试
cpp
#include "../../common/icsearch.hpp"
#include <gflags/gflags.h>
DEFINE_bool(run_mode, false, "程序的运行模式,false-调试; true-发布;");
DEFINE_string(log_file, "", "发布模式下,用于指定日志的输出文件");
DEFINE_int32(log_level, 0, "发布模式下,用于指定日志输出等级");
int main(int argc, char *argv[])
{
google::ParseCommandLineFlags(&argc, &argv, true);
IMS::init_logger(FLAGS_run_mode, FLAGS_log_file, FLAGS_log_level);
std::vector<std::string> host_list = {"http://127.0.0.1:9200/"};
auto client = std::make_shared<elasticlient::Client>(host_list);
std::cout << (uint64_t)client.get() << std::endl;
bool ret = IMS::ESIndex(client, "test_user").append("nickname")
.append("phone", "keyword", "standard", true)
.create();
if (ret == false)
{
LOG_INFO("索引创建失败!");
return -1;
}else {
LOG_INFO("索引创建成功!");
}
//数据的新增
ret = IMS::ESInsert(client, "test_user")
.append("nickname", "张三")
.append("phone", "15566667777")
.insert("00001");
if (ret == false)
{
LOG_ERROR("数据插入失败!");
return -1;
}
else
{
LOG_INFO("数据新增成功!");
}
//数据的修改
ret = IMS::ESInsert(client, "test_user")
.append("nickname", "张三")
.append("phone", "13344445555")
.insert("00001");
if (ret == false)
{
LOG_ERROR("数据更新失败!");
return -1;
}
else
{
LOG_INFO("数据更新成功!");
}
Json::Value user = IMS::ESSearch(client, "test_user")
.append_should_match("phone", "13344445555")
//.append_must_not_terms("nickname.keyword", {"张三"})
.search();
if (user.empty() || user.isArray() == false) {
LOG_ERROR("结果为空,或者结果不是数组类型");
return -1;
} else {
LOG_INFO("数据检索成功!");
}
int sz = user.size();
LOG_DEBUG("检索结果条目数量:{}", sz);
for (int i = 0; i < sz; i++) {
LOG_INFO("nickname: {}", user[i]["_source"]["nickname"].asString());
}
ret = IMS::ESRemove(client, "test_user").remove("00001");
if (ret == false) {
LOG_ERROR("删除数据失败");
return -1;
} else {
LOG_INFO("数据删除成功!");
}
return 0;
}那么这个测试做了啥呢?
以下是main函数中每个操作实际发送给Elasticsearch的Kibana Dev Tools命令(按执行顺序):
- 创建索引并插入默认文档(ID为 default_index_id)
cpp
PUT /test_user/_doc/default_index_id
{
"settings": {
"analysis": {
"analyzer": {
"ik": {
"tokenizer": "ik_max_word"
}
}
}
},
"mappings": {
"dynamic": true,
"properties": {
"nickname": {
"type": "text",
"analyzer": "ik_max_word"
},
"phone": {
"type": "keyword",
"analyzer": "standard"
}
}
}
}注:该请求会创建索引 test_user(如果不存在),并插入一个文档,其内容为索引的 settings 和 mappings。虽然文档内容本身不合理,但这是代码实际发送的请求。
- 插入文档 ID 为 00001
cpp
PUT /test_user/_doc/00001
{
"nickname": "张三",
"phone": "15566667777"
}- 更新文档 ID 为 00001(覆盖写入)
cpp
PUT /test_user/_doc/00001
{
"nickname": "张三",
"phone": "13344445555"
}- 搜索文档:phone 字段匹配 "13344445555"(使用 match 查询,放在 bool 的 should 子句中)
cpp
POST /test_user/_search
{
"query": {
"bool": {
"should": [
{ "match": { "phone": "13344445555" } }
]
}
}
}- 删除文档 ID 为 00001
cpp
DELETE /test_user/_doc/00001以上命令按顺序在Kibana Dev Tools中执行,即可完整重现C++代码的所有ES操作。
整个测试用例的执行结果如下:
cpp
ubuntu@10-13-52-255:~/cpp-chatsystem/server/example/es$ ./test
94436420871008
[default-logger][17:21:20][235123][debug ][../../common/icsearch.hpp:137] {
"mappings" :
{
"dynamic" : true,
"properties" :
{
"nickname" :
{
"analyzer" : "ik_max_word",
"type" : "text"
},
"phone" :
{
"analyzer" : "standard",
"type" : "keyword"
}
}
},
"settings" :
{
"analysis" :
{
"analyzer" :
{
"ik" :
{
"tokenizer" : "ik_max_word"
}
}
}
}
}
[default-logger][17:21:20][235123][info ][test_icsearch.cpp:26] 索引创建成功!
[default-logger][17:21:20][235123][debug ][../../common/icsearch.hpp:204] {
"nickname" : "\u5f20\u4e09",
"phone" : "15566667777"
}
[default-logger][17:21:20][235123][info ][test_icsearch.cpp:41] 数据新增成功!
[default-logger][17:21:20][235123][debug ][../../common/icsearch.hpp:204] {
"nickname" : "\u5f20\u4e09",
"phone" : "13344445555"
}
[default-logger][17:21:20][235123][info ][test_icsearch.cpp:56] 数据更新成功!
[default-logger][17:21:20][235123][debug ][../../common/icsearch.hpp:361] {
"query" :
{
"bool" :
{
"should" :
[
{
"match" :
{
"phone" : "13344445555"
}
}
]
}
}
}
[default-logger][17:21:20][235123][debug ][../../common/icsearch.hpp:379] 检索响应正文: [{"took":0,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":1,"relation":"eq"},"max_score":0.6931471,"hits":[{"_index":"test_user","_type":"_doc","_id":"00001","_score":0.6931471,"_source":{
"nickname" : "\u5f20\u4e09",
"phone" : "13344445555"
}}]}}]
[default-logger][17:21:20][235123][info ][test_icsearch.cpp:67] 数据检索成功!
[default-logger][17:21:20][235123][debug ][test_icsearch.cpp:70] 检索结果条目数量:1
[default-logger][17:21:20][235123][info ][test_icsearch.cpp:72] nickname: 张三
[default-logger][17:21:20][235123][info ][test_icsearch.cpp:80] 数据删除成功!非常的完美