在大模型普及的当下,我们习惯了使用在线聊天机器人,但在线服务往往受网络、隐私、算力限制------比如敏感数据不敢上传、高峰期卡顿、需要依赖外网。作为前端开发者,即便本地部署大模型不是核心工作,掌握这一技能也能带来诸多惊喜:既能深入理解大模型的运行逻辑,为后续开发AI相关前端应用(如本地AI工具、模型可视化界面)积累经验,也能摆脱对在线服务的依赖,实现"离线可用、隐私可控"的AI交互。
本文将详细拆解完整流程:用Ollama在本地运行大模型 → 用Docker启动Open-WebUI搭建可视化聊天界面 → 关闭防火墙+内网穿透(花生壳/ngrok),最终实现手机端(异地/本地)也能轻松访问本地大模型,全程亲测可通,有兴趣的可以自己操作一下。
以下纪录纯属个人爱好,不涉及任何技术分享,请酌情取用
一、前置认知:搞懂核心工具,不做"盲目操作"
在开始操作前,先明确几个核心工具的作用,避免只知其然不知其所以然,也能帮我们理解"为什么要这么做"。
如果对名词解释没啥兴趣,可以直接跳过到实操流程。
1.1 为什么前端要学习Ollama本地跑大模型?
很多前端同学会疑惑:"本地跑大模型不是后端/算法的工作,我为什么要学?" 核心原因有3点
- 积累AI前端开发经验:未来AI原生应用会成为主流,前端开发者需要了解大模型的部署逻辑、接口调用方式,才能更好地开发可视化界面、实现前端与本地模型的交互(比如自定义聊天界面、模型参数调节面板)。
- 隐私与效率双保障:日常测试AI功能、处理敏感数据(如工作文档、个人隐私信息)时,本地部署无需将数据上传到第三方服务器,既安全又能避免外网卡顿,离线状态也能正常使用。
- 降低开发成本:无需依赖云服务器部署大模型,利用本地电脑算力就能实现AI交互,适合个人学习、小型项目测试,不用承担云服务器的算力费用
1.2 什么是Ollama?
Ollama是一款轻量级、易上手的本地大模型运行工具,核心作用是"简化本地大模型的部署流程"。它相当于一个"大模型管理助手",能帮我们快速下载、启动各类开源大模型(如Llama 3、Qwen、Gemini等),无需复杂的环境配置(不用手动安装Python、PyTorch等依赖),一行命令就能完成模型的启动和运行,非常适合新手入门。
简单来说,Ollama解决了"普通人不会配置环境、无法本地运行大模型"的痛点,让我们能专注于使用模型,而非纠结于环境搭建。
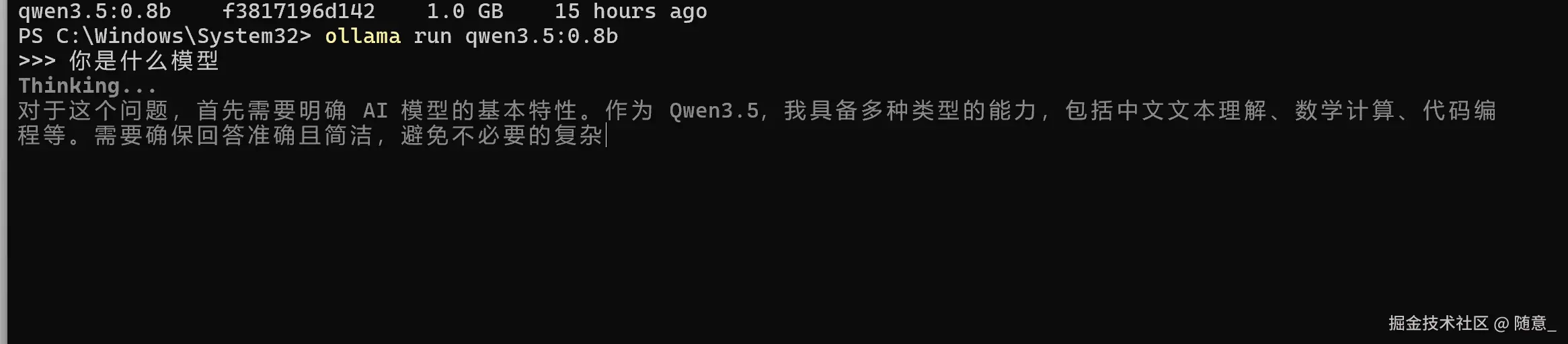
1.3 什么是Docker?为什么用Docker运行Open-WebUI?
Docker是一款"容器化工具",可以把应用及其依赖(如环境配置、软件版本)打包成一个独立的"容器",实现"一次打包,到处运行"------无论你的电脑是Windows、Mac还是Linux,只要安装了Docker,就能直接启动容器,无需担心环境不兼容、依赖缺失等问题。
而Open-WebUI是一款开源的大模型可视化聊天界面(类似ChatGPT的网页版),它支持连接本地或远程的大模型,提供简洁、易用的聊天交互界面,还能调节模型参数、保存聊天记录。
用Docker运行Open-WebUI的核心优势:无需手动配置Open-WebUI的运行环境(如Node.js、后端依赖),Docker会自动帮我们搞定所有依赖,启动命令简单,且不会污染本地电脑的环境,后续卸载也只需删除容器即可,非常便捷。
启动成功后 页面截图如下
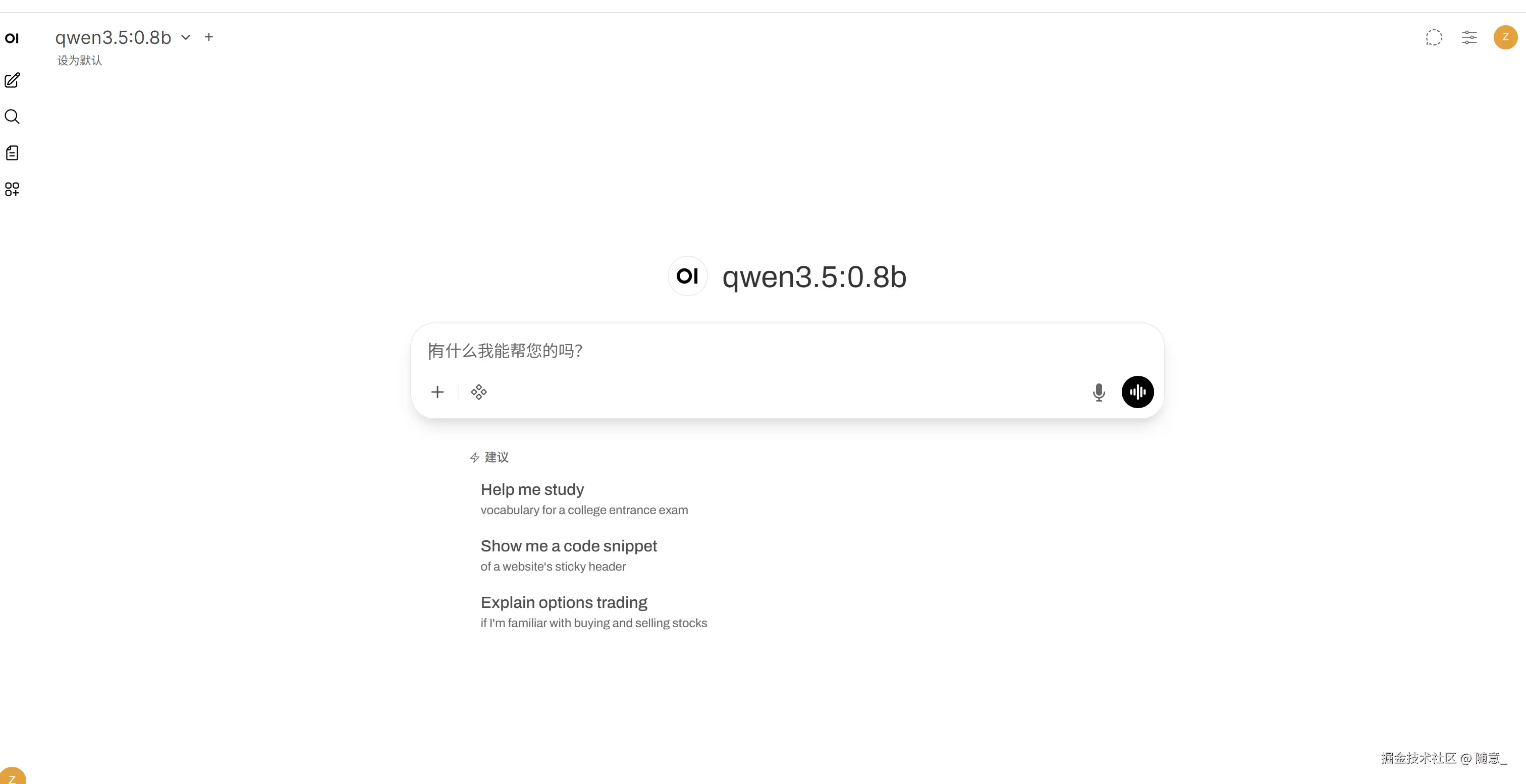
1.4 什么是内网穿透?为什么需要它?
我们本地电脑运行的大模型、Open-WebUI界面,默认只能在"本地局域网"内访问(比如同一WiFi下的电脑、手机),无法通过互联网(异地)访问,也无法让不在同一局域网的朋友访问。
内网穿透的作用,就是"把本地内网的服务(比如Open-WebUI)映射到互联网上",生成一个公开的网络地址,让外部设备(手机、异地电脑)能通过这个地址,访问到我们本地的服务。
简单来说,没有内网穿透,我们只能在自己的电脑上用可视化界面聊天;有了内网穿透,我们可以把这个界面分享给朋友,他们用手机就能访问我们本地的大模型,实现"本地部署,全网可访问"。
二、完整操作流程:从本地部署到手机访问(亲测可通)
本流程分为4个核心步骤,每一步都有详细说明,有截图展示,大家可根据自己的操作过程补充,确保每一步都能复现。
步骤1:安装Ollama,本地运行大模型
这一步的核心是"让大模型在本地电脑上跑起来",Ollama的安装和使用非常简单,全程无需复杂配置。
- 下载Ollama:访问Ollama官方网站 ollama官网 根据自己的电脑系统(Windows/Mac/Linux)下载对应安装包,双击安装即可(安装过程默认下一步,无需额外设置)。
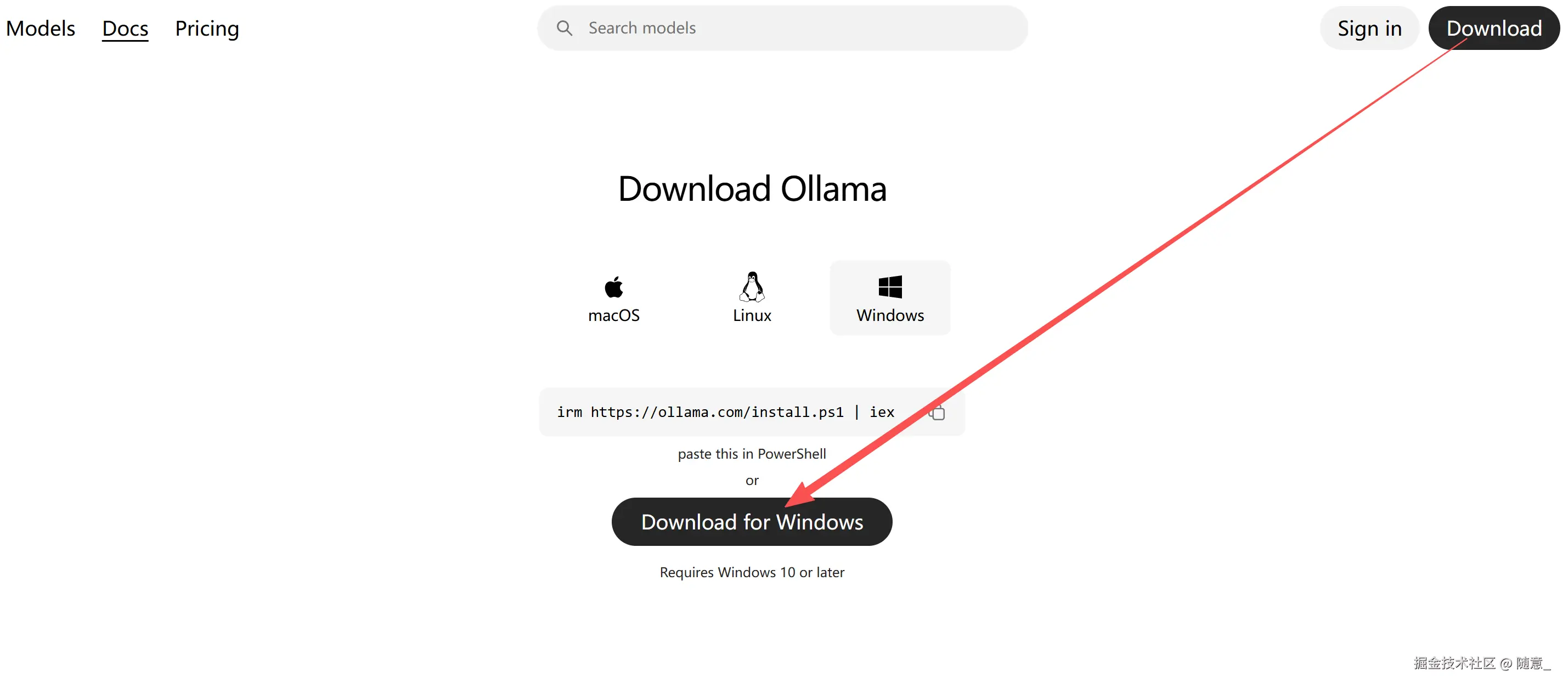
安装成功后 输入
ollama -v 有版本号输入则安装成功
ollama官网查找模型 你可先找一个小的模型 用于测试,大参数模型本地一般跑不起来,显存不够,
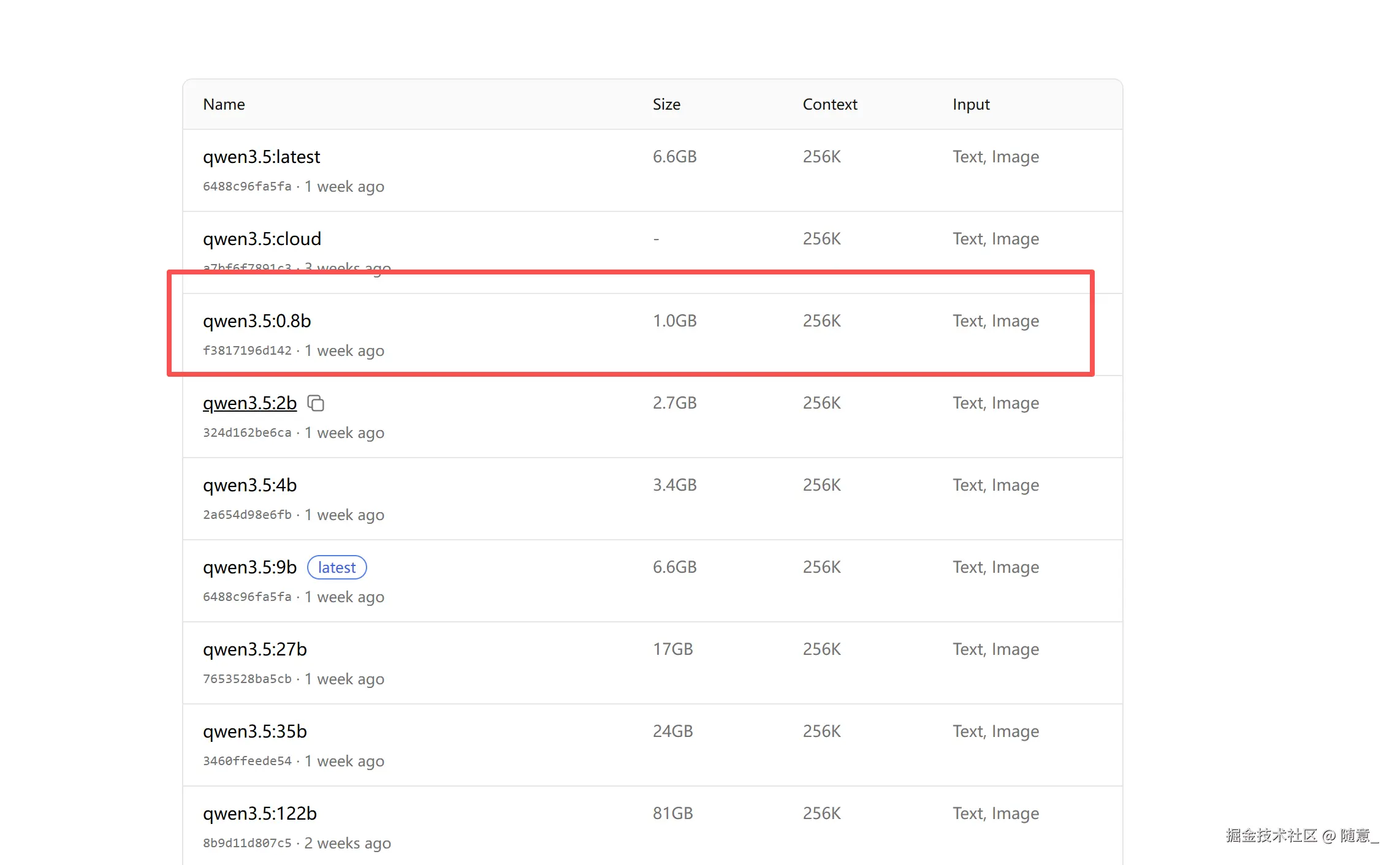
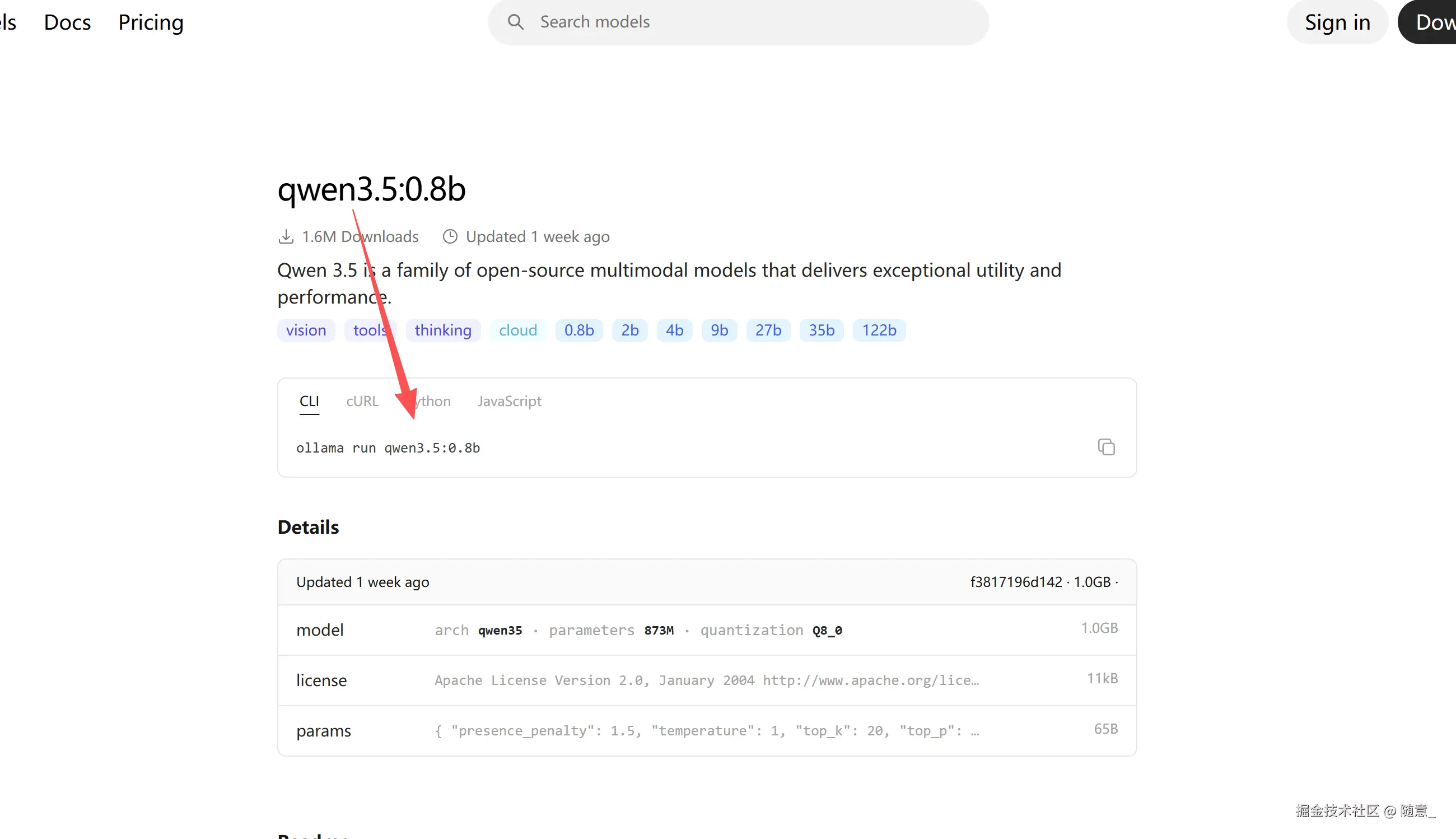
我选择就是 qwen3.5:0.8b的模型 输入命令行, 会等待模型下载, 然后运行起来的,可在终端进行提问
arduino
ollama run qwen3.5:0.8b 下载慢 请耐心等待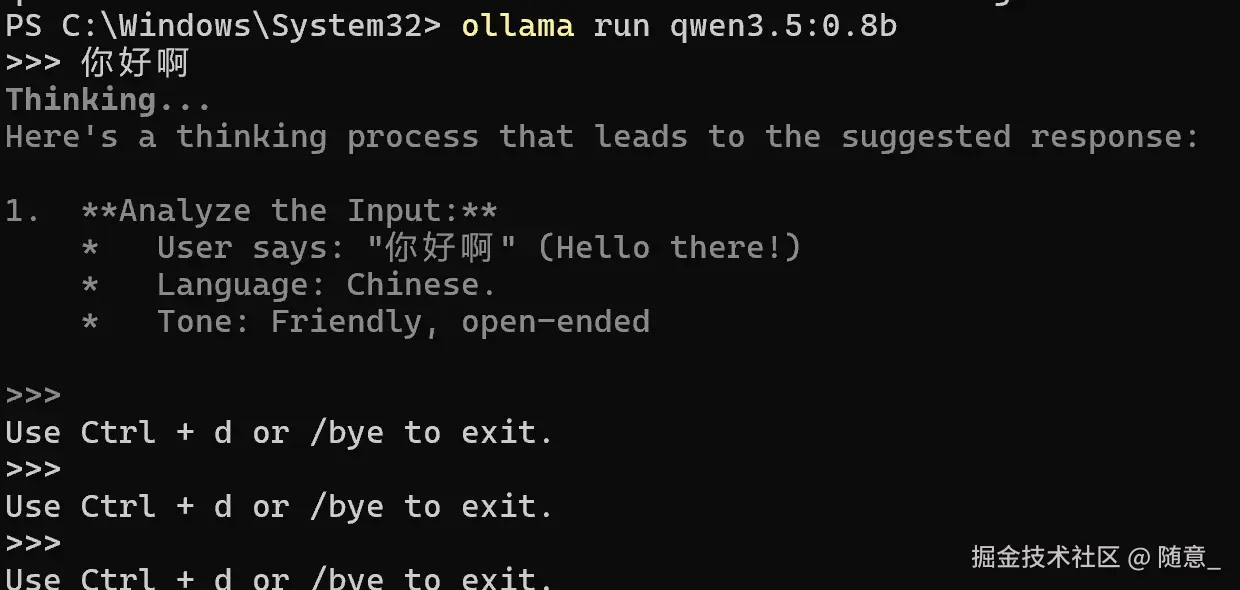
注意你个指令就行,这些指令就够用了
arduino
ollama list 展示出来当前安装的模型
ollama run 【name】运行你下载的模型
ollama run 【name】--think=false 不需要思考
ctrn + d 关闭ollama
/bye 关闭ollama注意:如果电脑显存不够,注意下载小参数模型,每一个开源模型,都会有很多的版本,请注意选择适合你自己的,避免运行卡顿。

步骤2:用Docker启动Open-WebUI,搭建可视化聊天界面
Ollama的终端聊天界面不够直观,我们用Open-WebUI搭建可视化界面,操作更友好,还能保存聊天记录、调节模型参数。
- 安装Docker:访问Docker官方网站,下载对应系统的Docker Desktop,安装完成后启动Docker(启动后,电脑状态栏会有Docker图标,显示"Running"即为启动成功)。
输入 有输入则是 安装成功,可能需要升级WSL按照命令升级就行
docker -v
- 启动Open-WebUI容器:打开终端,输入Docker启动命令
open-webui开源组件库地址 ,可查看启动方式
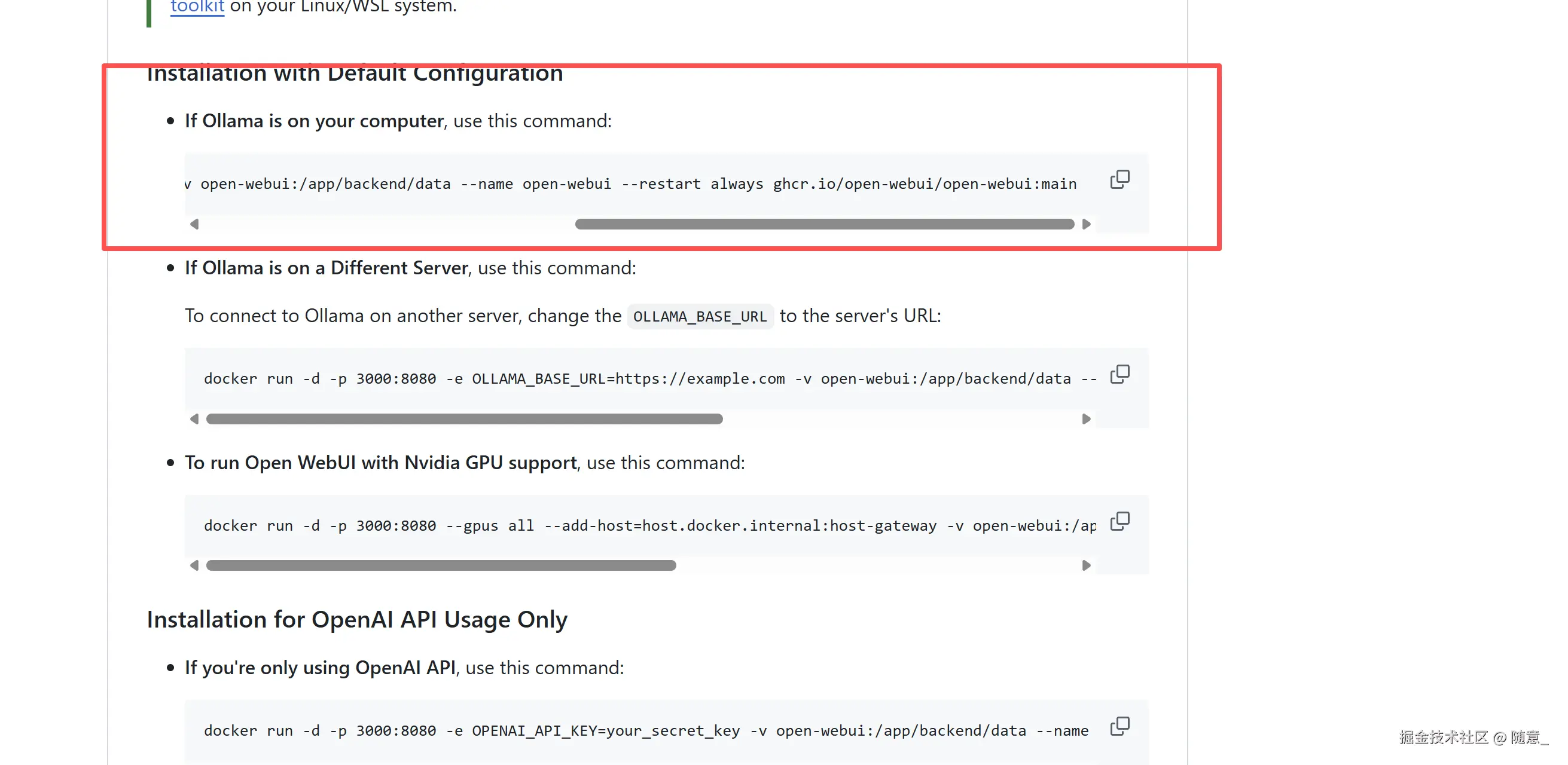
我做了以下修改,可直接复制下面的命令
js
docker run -d -p 0.0.0.0:3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always -e DISABLE_AUTO_UPDATE=true ghcr.io/open-webui/open-webui:main- 访问Open-WebUI:命令执行完成后,等待1-2分钟,会默认打开页面,如果没自动打开打开浏览器,输入
http://localhost:3000,即可进入Open-WebUI的登录界面(首次登录可创建管理员账号,无需复杂配置)。

- 你也可以在设置页面 对你的模型操作一个
syetem的prompt
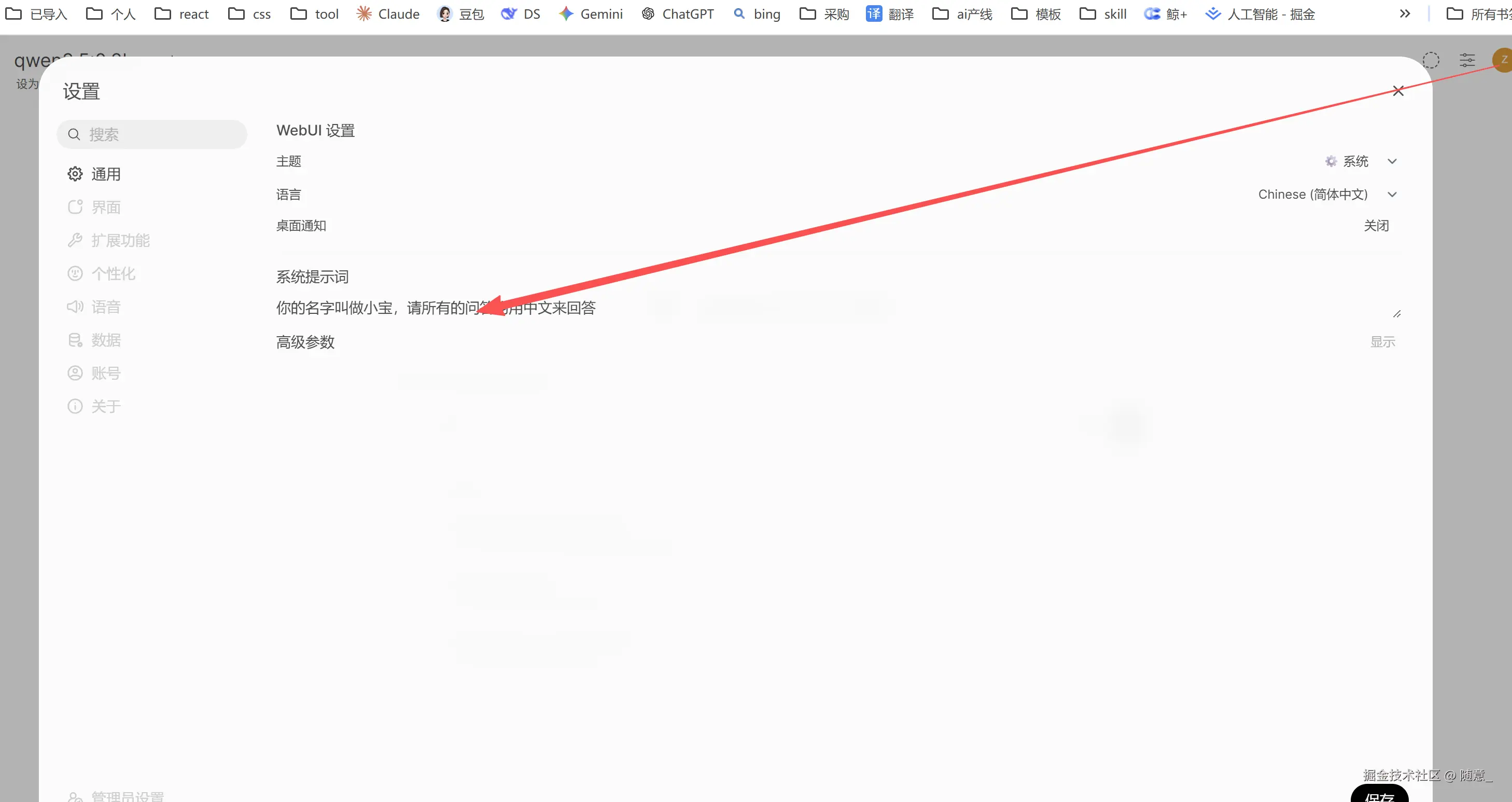
- 接着你可以进行 问答了 如果下载了多个模型,可以切换模型了

注意:如果启动容器失败,检查Docker是否正常运行,或是否有端口冲突(3000端口被其他软件占用,可修改命令中的"3000:8080"为"其他端口:8080",比如"3001:8080")。
步骤3:关闭防火墙,确保内网访问正常
防火墙会拦截外部设备对本地服务的访问,即便在同一局域网内,手机也可能无法访问Open-WebUI界面,因此需要临时关闭防火墙(操作完成后可根据需求重新开启)。
- Windows系统:打开"控制面板"→"系统和安全"→"Windows Defender防火墙",点击"关闭Windows Defender防火墙"(分别关闭公用网络和专用网络的防火墙)。
- Mac系统:打开"系统设置"→"网络"→"防火墙",点击"关闭"即可。
测试:关闭防火墙后,用同一WiFi下的手机,打开浏览器输入 电脑本地IP:3000(电脑本地IP可通过终端输入"ipconfig"(Windows)或"ifconfig"(Mac)查询),能正常打开Open-WebUI界面,说明内网访问正常。
你的IP地址 捕获获取的话 自己查找下教程
步骤4:内网穿透(花生壳/ngrok),实现手机端全网访问
关闭防火墙后,只能在同一局域网内访问,想要让朋友(异地)用手机访问,需要通过花生壳或ngrok实现内网穿透,生成公开访问地址。下面分别介绍两种工具的操作方法,二选一即可。
方法1:花生壳(更适合长期使用,稳定性强)
-
下载安装花生壳:访问花生壳官方网站,下载对应系统的花生壳客户端,安装完成后注册并登录账号。
-
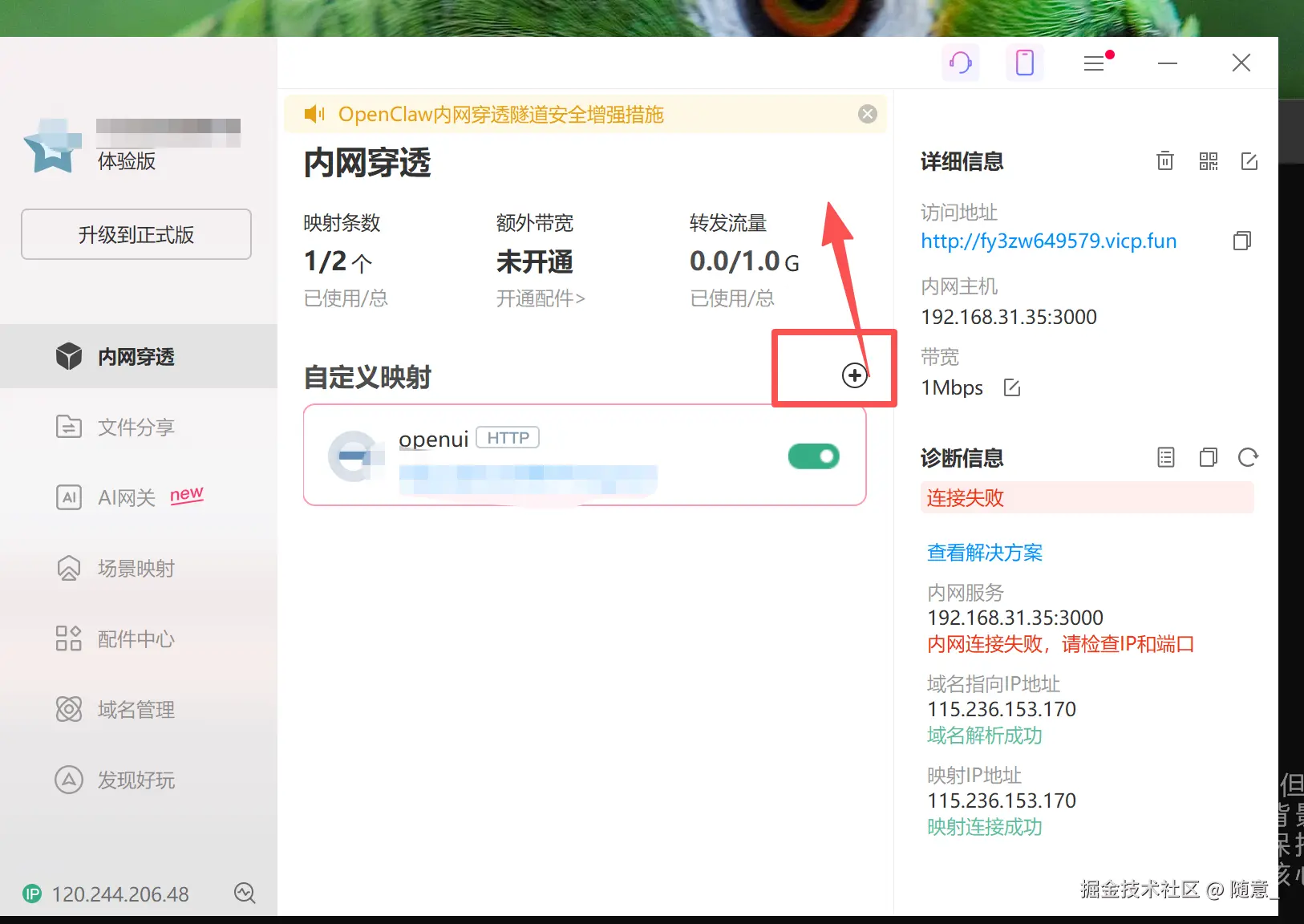
添加内网穿透映射:登录后,点击"添加映射",设置映射信息:
- 映射名称:自定义(比如"本地大模型界面")
- 应用类型:选择"HTTP"
- 内网主机:填写电脑本地IP(比如192.168.1.100)
- 内网端口:填写3000(和Open-WebUI的端口一致)
- 点击"确定",花生壳会自动生成一个公开的访问地址(比如xxxxxx.vipgz1.91vps.com)。
-
测试访问:复制花生壳生成的公开地址,用手机(断开WiFi,用流量)打开浏览器,输入该地址,能正常进入Open-WebUI界面,即可实现异地访问;将地址分享给朋友,他们也能通过手机访问你本地的大模型。
方法2:国外的软件 ngrok(适合临时使用,操作简单)但是微信打不开 会被屏蔽掉,浏览器可以打开,
- 下载安装ngrok:访问ngrok官方网站(ngrok.com/),注册账号后,下载对...
- 获取ngrok授权令牌:登录ngrok账号,在"Dashboard"页面找到"Auth Token",复制该令牌。
- 启动ngrok穿透:打开终端,进入ngrok解压目录,输入命令
ngrok authtoken 你的授权令牌(完成授权),然后输入命令ngrok http 3000(将本地3000端口映射到互联网)。 - 获取公开地址:命令执行后,终端会显示一个公开的访问地址(比如xxxxxx.ngrok.io),复制该地址。
- 测试访问:用手机(流量)打开浏览器,输入该地址,能正常进入Open-WebUI界面,即为穿透成功;分享该地址给朋友,即可实现手机端访问。
注意:ngrok免费版的公开地址会随机变化,每次重启ngrok都会生成新地址;如果需要固定地址,可升级ngrok付费版。
推荐国内使用 花生壳来操作
穿透后 可以手机访问 如下
三、常见问题排查(避坑指南)
在操作过程中,可能会遇到一些问题,这里整理了最常见的3个问题及解决方案,帮大家快速避坑。
- 问题1:Open-WebUI无法连接Ollama模型? 解决方案:检查Ollama是否正常运行(终端输入
ollama ps,查看模型状态);检查Open-WebUI的模型连接地址是否正确(默认http://host.docker.internal:11434);重启Docker容器和Ollama。 - 问题2:手机无法访问花生壳/ngrok生成的公开地址? 解决方案:检查防火墙是否关闭;检查花生壳/ngrok的映射端口是否为3000;检查电脑本地IP是否正确;重启内网穿透工具。
- 问题3:Ollama运行模型卡顿、闪退? 解决方案:选择轻量化模型;关闭电脑其他占用算力的软件(如游戏、视频剪辑工具);确保电脑内存≥8GB,显存≥4GB。
四、总结
整个流程看似复杂,实则每一步都有明确的目的:Ollama负责让大模型在本地跑起来,Docker负责简化可视化界面的部署,内网穿透负责打破局域网限制,最终实现"本地部署、全网可访问"的本地大模型可视化交互。
对于前端开发者而言,这套流程不仅能让我们摆脱对在线大模型的依赖,更能让我们深入了解AI服务的部署逻辑,为后续开发AI相关前端应用积累实战经验------毕竟,未来的前端开发,必然会与AI深度结合,提前掌握这些技能,才能更具竞争力。