概念
归并排序是一种基于分治思想的高效稳定排序算法,核心思路是将待排序序列递归拆分为若干子序列,直到每个子序列只有一个元素(天然有序),再依次将有序子序列两两合并,最终得到完整有序序列
- 核心步骤:1. 分解:递归把数组从中间分成左右两部分,直至每个子数组长度为 1;
-
- 合并:从最小有序单元开始,两两比较并按顺序合并,逐层向上归并为完整有序数组
生活中的例子
- 多人分组整理扑克牌:先把牌分给多人各自排好,再把多组有序牌依次合并成一整副有序牌
- 多队排队合并:两队已按身高排好的队伍,由工作人员逐个对比排头,按顺序合并成一队
- 书籍页码整理:先把厚书拆成多叠分别按页码排好,再把多叠有序页码逐叠合并成完整顺序
- 快递分拣:先按区域分成小堆并各自排序,再把各区域有序包裹合并成整体有序的配送清单
归并排序的思路分析
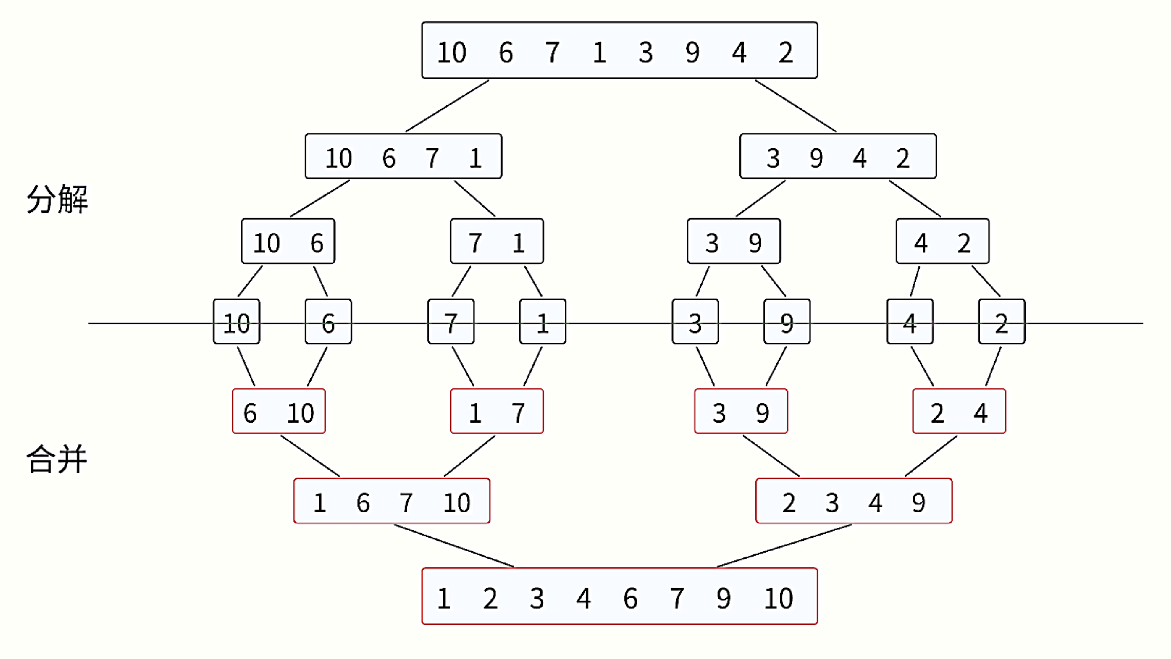
第一步:拆
想象你手里有一副乱牌:10 6 7 1 3 9 4 2,想把它从小到大理整齐,归并排序就是这么干的
先把牌堆从中间劈成两半,再把每一半继续劈成更小的堆,直到每堆只剩一张牌------ 毕竟单张牌天生就是 "排好序" 的
- 原堆:10 6 7 1
- 第一次劈:
[10 6 7 1]和[3 9 4 2] - 继续劈:
[10 6][7 1]和[3 9][4 2] - 最后劈到最小单位:
[10][6][7][1][3][9][4][2]
第二步:两两合并
现在从最小的牌堆开始,两两合并成有序小堆,就像两队排好的人,挨个比排头,把小的先拉出来:
- 先合并单张牌:
10和6→ 排成6 107和1→ 排成1 73和9→ 排成3 94和2→ 排成2 4
- 再合并这四个小堆:
6 10和1 7→ 挨个比排头,排成1 6 7 103 9和2 4→ 挨个比排头,排成2 3 4 9
- 最后合并两个大堆:
1 6 7 10和2 3 4 9→ 继续比排头,最终得到1 2 3 4 6 7 9 10
一句话总结
先把乱牌拆到 "每张都孤单",再两两凑成整齐的小堆,最后把小堆一步步拼成整副整齐的牌 ------ 这就是归并排序的核心思路
错误写法
void _MergeSort(int* arr, int* tmp, int begin, int end)
{
if (begin == end)
{
return;
}
int mid = (begin + end) / 2;
//将数组区域划分为:[begin, mid - 1] [mid, end]
_MergeSort(arr, tmp, begin, mid - 1);
_MergeSort(arr, tmp, mid, end);
////归并
int begin1 = begin;
int end1 = mid - 1;
int begin2 = mid;
int end2 = end;
int i = begin;
while (begin1 <= end1 && begin2 <= end2)
{
if (arr[begin1] < arr[begin2])
{
tmp[i++] = arr[begin1++];
}
else
{
tmp[i++] = arr[begin2++];
}
}
while (begin1 <= end1)
{
tmp[i++] = arr[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = arr[begin2++];
}
memcpy(arr + begin, tmp + begin, (end - begin + 1) * sizeof(int));
}
//归并排序
void MergeSort(int* arr, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
assert(tmp != NULL);
_MergeSort(arr, tmp, 0, n - 1);
free(tmp);
tmp = NULL;
}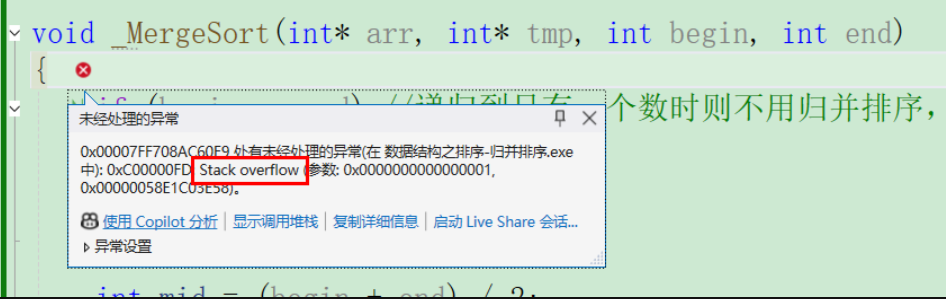
这个报错就是栈溢出,为什么会出现这样的情况呢?
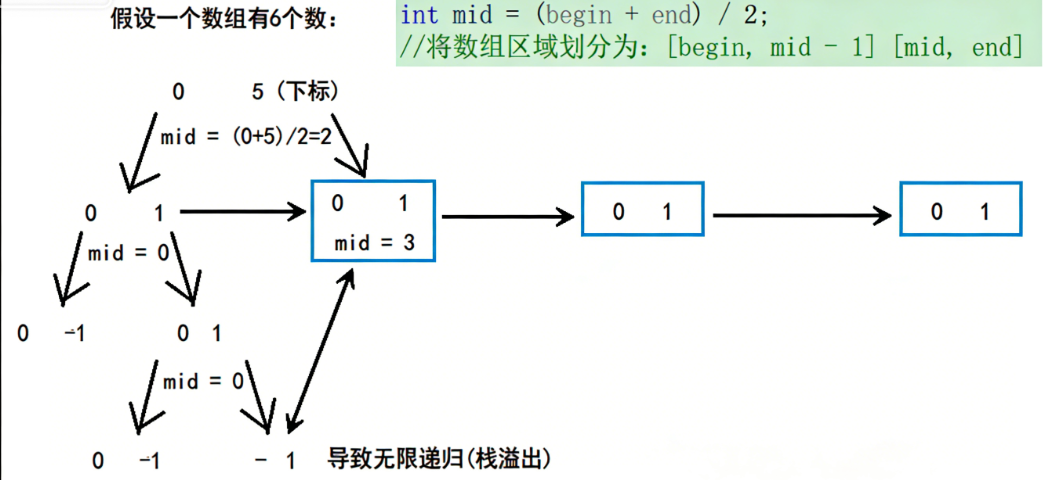
我们会发现栈溢出问题的出现就是因为中间值下标mid取的有问题 ,我们知道整型的除法是会取整的,所以奇数的取中是会有问题的;而且当递归只剩下两个数的时候,下标之和是一定为奇数的,这样就会导致如图所示 mid, end 这个区间会一直不变导致无限递归的情况,而递归一次就需要在栈区开辟新的空间,无限的递归就会导致栈溢出的问题
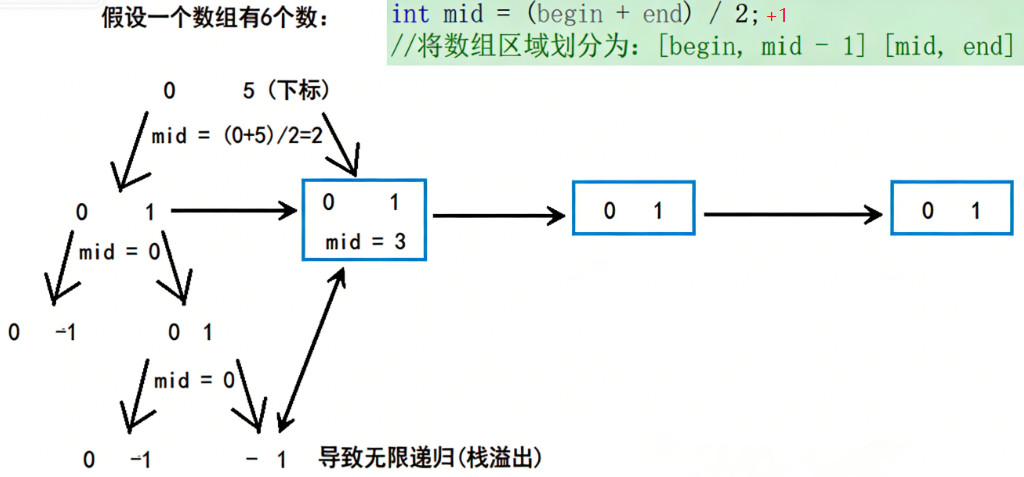
正确写法
void _MergeSort(int* arr, int* tmp, int begin, int end)
{
if (begin == end)
{
return;
}
int mid = (begin + end) / 2+1;
//将数组区域划分为:[begin, mid - 1] [mid, end]
_MergeSort(arr, tmp, begin, mid - 1);
_MergeSort(arr, tmp, mid, end);
////归并
int begin1 = begin;
int end1 = mid - 1;
int begin2 = mid;
int end2 = end;
int i = begin;
while (begin1 <= end1 && begin2 <= end2)
{
if (arr[begin1] < arr[begin2])
{
tmp[i++] = arr[begin1++];
}
else
{
tmp[i++] = arr[begin2++];
}
}
while (begin1 <= end1)
{
tmp[i++] = arr[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = arr[begin2++];
}
memcpy(arr + begin, tmp + begin, (end - begin + 1) * sizeof(int));
}
//归并排序
void MergeSort(int* arr, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
assert(tmp != NULL);
_MergeSort(arr, tmp, 0, n - 1);
free(tmp);
tmp = NULL;
}现在我们来测试一下

归并排序非递归版本
概念
归并排序非递归实现(自底向上归并排序),不使用递归调用与系统栈,直接从最小有序子序列开始,通过迭代逐层合并,最终得到完整有序序列
生活例子
假设你有8本散乱的书,要按书名首字母(A-Z)排序,用归并排序非递归的思路就是:
-
初始gap=1(单本书为一个"有序子序列"):每本书单独放,此时每一本都是"有序"的(只有1个元素,天然有序);
-
gap=2(合并相邻2本):把第1和第2本对比排序、第3和第4本对比排序、第5和第6本对比排序、第7和第8本对比排序,得到4组"2本有序的书";
-
gap=4(合并相邻4本):把前4本(两组2本有序的书)合并成1组4本有序的书,后4本同理,得到2组"4本有序的书";
-
gap=8(合并相邻8本):把两组4本有序的书合并,最终得到8本按首字母排序的完整有序书本,排序完成
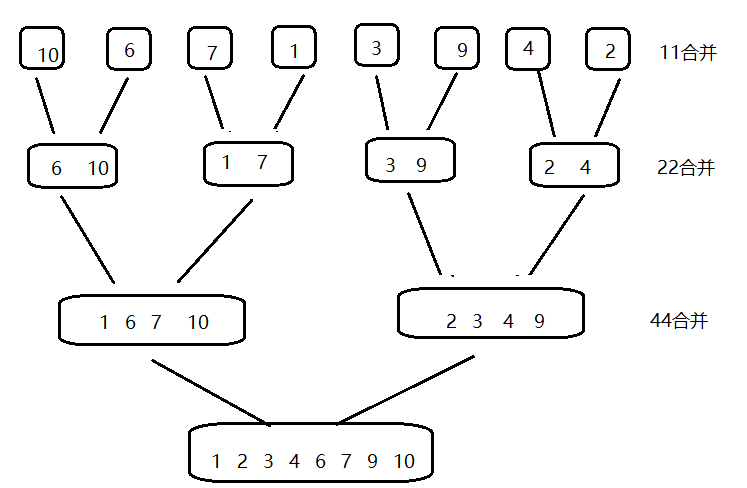
所以此时我们不再把一个数组看成一个整体,由于一次归并排序是需要两个有序数组,所以我们将第一排两两为一组进行归并排序,第一排也叫做11归并;当第一排完成归并排序后就如第二排所示,此时由于一个数组此时存放两个数,则相当于4个数为一组进行归并排序,所以第二排也叫做22归并;同理下面的逻辑也是如此,则我们就能不用递归来实现归并排序。
我们会发现每完成一排的归并后数组的数据量都进行了翻倍,但是我们知道归并排序是需要两个头指针同时进行比较排序,所以这两个头指针之间的距离是会发生变化的,也就是说我们需要一个变量来控制这个距离,我们就定义为 gap 。
gap指的就是当前一排中一个数组所存放的数据个数。当 gap = 1时相当于第一排,此时每两个数组为一组进行归并排序,全部完成后则gap = 2相当于第二排,此时再每两个数组为一组进行归并排序,以此类推。
2、数组中数据个数为2^n的代码实现
为什么我们先实现个数为2^n的数组排序呢?就由上面的图所示,我们能保证每两个数组都能成为一组进行归并排序,如果数组个数不是2^n,比如假设为10个数据,则到第二排的数组个数为5个,无法做到每两个数组为一组进行归并排序
归并排序非递归代码
void MergeSortNonR(int* a, int n)
{
int* tmp = malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc");
return;
}
int gap = 1;//gap每组归并的个数
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
//[begin1,end1][begin2,end2]
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
if (end1 >= n)
{
end1 = n - 1;
}
if (begin2 >= n)
{
break;
}
if (end2 >= n)
{
end2 = n - 1;
}
int j = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[j++] = a[begin1++];
}
else
{
tmp[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[j ++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2++];
}
memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));
}
gap *= 2;
}
free(tmp);
tmp = NULL;
}