大家好,我是 Sunday。
这两天我专门把 OpenClaw 的官方文档、仓库结构和几个核心概念文档重新过了一遍。
我发现很多人对 OpenClaw 的理解,还停留在"一个能聊天、能写代码、能接各种渠道的 AI 工具"这个层面。
但你真把它拆开看,从技术的角度来看,你会得到一个完全不一样的理解:
OpenClaw 更像是一个以 Gateway 为核心控制平面、把消息渠道、Agent Runtime、工具系统、设备节点、Canvas UI 全部串起来的"个人 AI 操作层"。
并且还有人多说 OpenClaw 不安全,会带来很大的风险。我觉得也是不全面的。
所以,这篇文章,咱们就只讲一件事情,那就是 OpenClaw 的架构设计和实现原理
OpenClaw 的本质
如果只用一句话概括 OpenClaw,我会这么说:
OpenClaw = 一个常驻 Gateway + 一个内嵌 Agent Runtime + 一套 typed tools + 一层 Skills 提示系统 + 一组可接入的消息渠道与设备节点。
这也是它和很多单进程 CLI Agent最大的不同。
官方文档明确写到:一个长期运行的 Gateway 持有所有消息入口,控制端客户端通过 WebSocket 连到 Gateway,节点设备也通过同一个 WebSocket 接入,而 Canvas/A2UI 等 Web 能力也由 Gateway 的 HTTP 服务直接挂载出来。
你可以把它理解成下面这个结构:
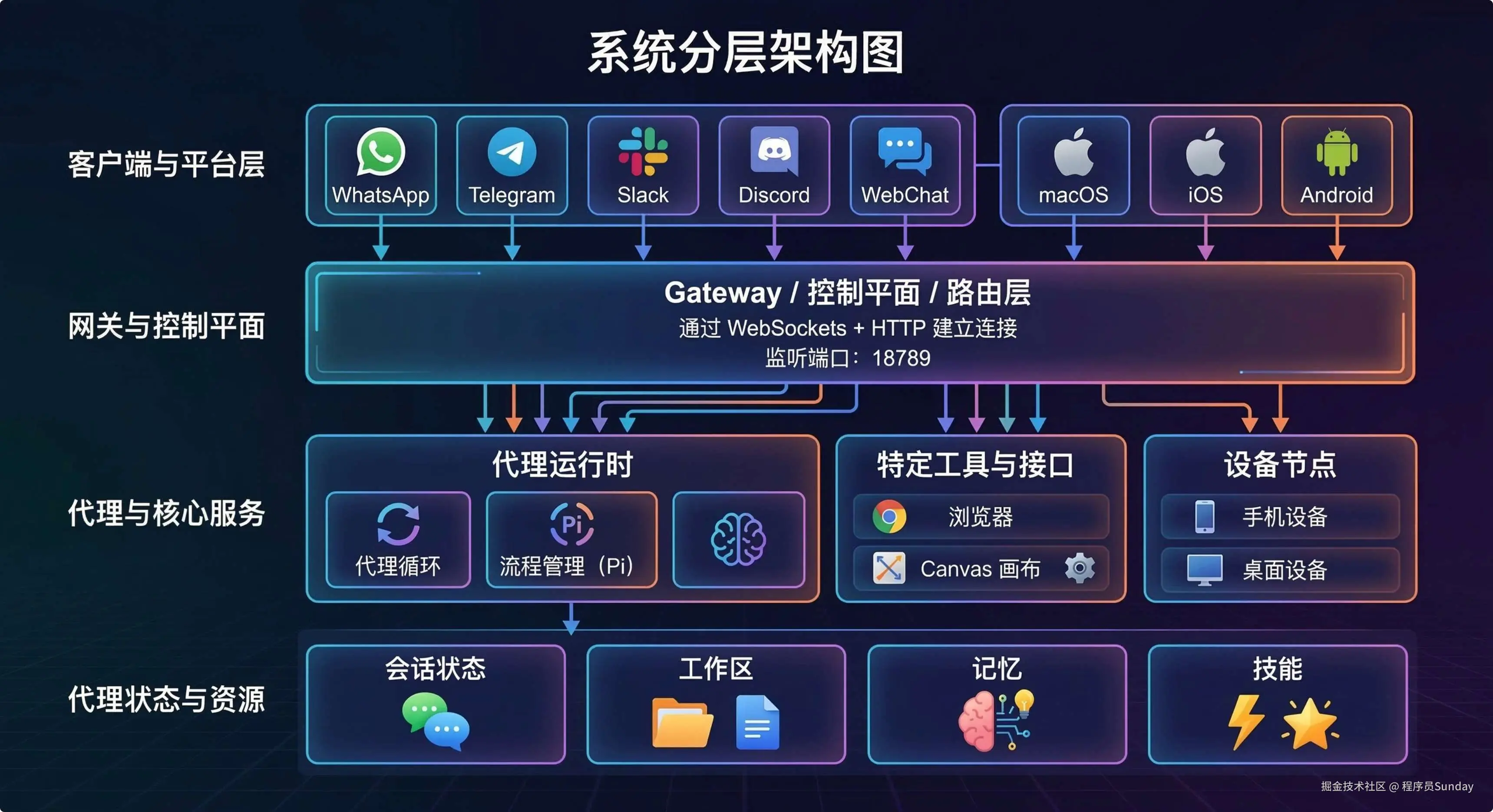
这套分层,决定了 OpenClaw 不是"收到消息 → 调模型 → 回一句话"那么简单。而是一个 有状态、有路由、有并发控制、有设备扩展面的 agent system
一、OpenClaw 的安全设计
现在很多人都说 OpenClaw 不安全,所以咱们先来讲 OpenClaw 的安全设计
这句话说得也对,也不对。
我挺喜欢 OpenClaw 文档的一点,就是它很多地方写得非常直白,不装。
因为它明确的告诉了你:有些能力就是危险的,如果你开了,又没做好隔离,那风险就是真实存在的。
那 OpenClaw 到底是怎么个"不安全法"?
我觉得可以直接讲 4 个最核心的点。
1. 默认不开沙箱时,工具就是直接跑在宿主机上的
这一点其实是最关键的。
OpenClaw 官方文档明确写了:sandbox 是可选的。如果你没有开启 sandbox,那么工具执行就是直接跑在 host 上。
只有开了 Docker sandbox,工具才会被放进隔离环境里。而且官方自己也说了,sandbox 也不是"完美安全边界",只是能明显降低文件系统和进程访问的爆炸半径。

这句话翻译成人话就是:你如果不开沙箱,模型调用的很多能力,本质上就是在你的真实机器上执行。
这就不是"聊聊天"了,这就是你让 AI 完全操控你的电脑。
2. workspace 不是硬隔离
很多人一看到 workspace,会下意识觉得:"哦,那应该就是沙箱目录了。"
但官方文档写得非常明确:
workspace 只是默认 cwd,不是 hard sandbox。 相对路径会默认落在 workspace 里,但绝对路径仍然可能访问宿主机其他位置,除非你显式开启 sandbox。

这个点其实非常重要。
因为这意味着:如果你给了文件能力,或者给了命令执行能力,那么"工作区"并不天然等于"只能访问工作区"。它更像一个默认起点,而不是一道真正的防火墙。
3. 它真的支持执行命令,而且这个能力本身就是高危能力
OpenClaw 官方有 exec tool,文档写得也很清楚:它可以在 workspace 里运行 shell commands,还支持配合 process 做前后台执行。

这件事的本质是:
只要模型拿到了足够宽的工具权限,它就是可以完全操作你的电脑。
所以 OpenClaw 的风险,从来都不是模型会不会胡说八道这么简单,而是:
- 会不会误执行命令
- 会不会被提示注入带偏
- 会不会在开放群组、开放渠道下触发不该触发的工具
- 会不会在没有隔离的情况下把危险操作落到真实机器上
这也是现在很多人觉得 openclaw 危险的主要原因。
官方的 security / doctor 检查里甚至直接把这些情况点出来了,比如:
- 开放群组能触达 runtime / filesystem 工具,但又没有 sandbox / workspace guard
- 全局最小权限 profile 被 agent 覆盖
- 扩展工具在过于宽松的策略下可达
- 小参数模型配上危险工具面,会提高注入风险
这其实已经说得很明白了:
OpenClaw 的风险,不在有没有 AI,而在你给这个 AI 开了多大权限,以及能不能控制他。
4. 一旦暴露到非本机网络,攻击面会明显变大
说白了就是一旦你不懂,并且有人想要黑你,那你就完蛋了。。。

这意味着什么?
意味着 OpenClaw 这类东西,本地单机自己玩 ,和 对外开放、接远程设备、接公开渠道、跑开放群组,风险级别根本不是一个量级。
很多人嘴里的"不安全",其实说的不是它默认就会出事,而是:
一旦你把它从"个人本地助手"往"公网可达 + 多渠道接入 + 高权限工具"这个方向推,它的风险会急剧上升。
最关键的就在:
- 有没有人搞你
- 你懂不懂防护
所以,OpenClaw 到底安不安全?
我的想法是,咱们不能从它安全不安全来说,而应该说是
它真的给了你很强的能力,但是很多人低估了想要使用这种能力,可能需要付出的代价
二、Gateway 为什么是整个系统的核心?
官方架构文档里第一句话就很关键:
A single long-lived Gateway owns all messaging surfaces
也就是,一个长期运行的 Gateway,统一持有所有消息面。默认通过 127.0.0.1:18789 提供 WebSocket 服务,同时在同端口提供 Canvas host 等 HTTP 能力。
这意味着什么?
它意味着 OpenClaw 把最难管的几件事,都放到 Gateway 里统一收口了,这些事情包括了:
- 消息渠道连接
- 请求入口统一
- 会话路由
- 事件流广播
- 客户端/节点接入
- 控制 UI 与 Canvas host 暴露
官方文档里写得很清楚,Gateway 负责维护 provider connections,暴露 typed WS API,请求/响应/事件都是同一条协议线上的能力,而且会对入站 frame 做 JSON Schema 校验。

这个设计的价值非常大。
因为 AI Agent 一旦开始"接渠道",最容易失控的地方就是状态分裂:
- Telegram 一套状态
- Slack 一套状态
- Web UI 一套状态
- 手机节点一套状态
- CLI 再来一套状态
最后整个系统到处都是胶水逻辑。
而 OpenClaw 选的路径是:别让每个入口都自己处理问题,要统一进 Gateway。
所以你会看到官方 README 里反复强调:
- Gateway 是 control plane
- Control UI 直接由 Gateway 提供
- WebChat 直接由 Gateway 提供
- 节点设备也连 Gateway
- Canvas host 还是由 Gateway 提供
这个思路其实很值得做 AI 应用的人参考。
很多团队做 AI 客服、AI 助手、AI 面试官,前期喜欢把 聊天入口、工具执行、状态存储、设备能力 拆得特别散,结果 2 个月后系统没法维护。
OpenClaw 的第一性原理很简单:控制面统一。
三、多入口 方案
在 OpenClaw 里,有三类核心参与者:
第一:Gateway

常驻后台,拥有所有消息面和控制面。
第二:Clients

比如 macOS app、CLI、web admin,这些都算控制端客户端。
它们各自保持一条 WS 连接,向 Gateway 发送 health、status、send、agent 等请求,也订阅 tick、agent、presence、shutdown 等事件。
第三:Nodes

这是 OpenClaw 很有意思的一层。
官方定义里,node 是一个 companion device,可以是 macOS / iOS / Android / headless。它通过同一个 Gateway WebSocket 接入,但声明 role: "node",然后把自己的命令面暴露出来,比如 canvas.*、camera.*、device.*、notifications.*、system.*。
这套设计,说明 OpenClaw 从一开始就不是把设备当成"被动展示层"。
它把设备当成了 可调用外设。
也就是说,模型并不是只能"说话",它还能借 Gateway 去调用外部节点的能力:
- 在手机上显示 Canvas
- 调摄像头
- 录屏
- 获取位置
- 触发通知
- 在某台机器上执行 system 相关命令
这就是为什么我说它更像"个人 AI 操作层"。
因为这里的设计,不再是 Web Chat 那种扁平问答,而是设备编排。
四、Agent Loop
Gateway 解决的是"统一接入"和"控制面"。真正把一条消息变成一次完整 Agent 运行的,是 Agent Loop。

官方文档对 Agent Loop 的定义非常清楚:
接收 → 上下文组装 → 模型推理 → 工具执行 → 流式回复 → 持久化
并且强调:一个 session 内,同一时间只会串行执行一个真实 run,整个过程中会持续触发 生命周期 和 事件流
官方给出的流程大概是这样的:
agentRPC 先校验参数,解析 session,并立即返回{ runId, acceptedAt }agentCommand才真正开始跑 agent- 它会解析模型配置、加载 skills snapshot,然后调用
runEmbeddedPiAgent runEmbeddedPiAgent会做队列串行化、创建 pi session、订阅 pi events、流式转发 assistant/tool 输出、处理 timeoutsubscribeEmbeddedPiSession再把底层事件桥接成 OpenClaw 自己的agentstream
这个设计的关键点在于:OpenClaw 把"接收请求"和"执行 Agent"解耦了。
先受理,再排队,再执行,再流式回传。
这和很多人自己写的 Agent Demo 不一样。
很多 Demo 是 HTTP 一进来,直接 await model.generate(),然后工具调用、状态更新、输出拼接全部糊在一个请求函数里。
这种方式前期快,但只要进入多 session、多入口、可中断、可观测的场景里面的时候,很快就会崩。
OpenClaw 显然是按"长期运行系统"去设计的,所以它从一开始就有:
runId- 队列
- lifecycle 事件
- assistant/tool 分流
等等的东西
五、Session 设计
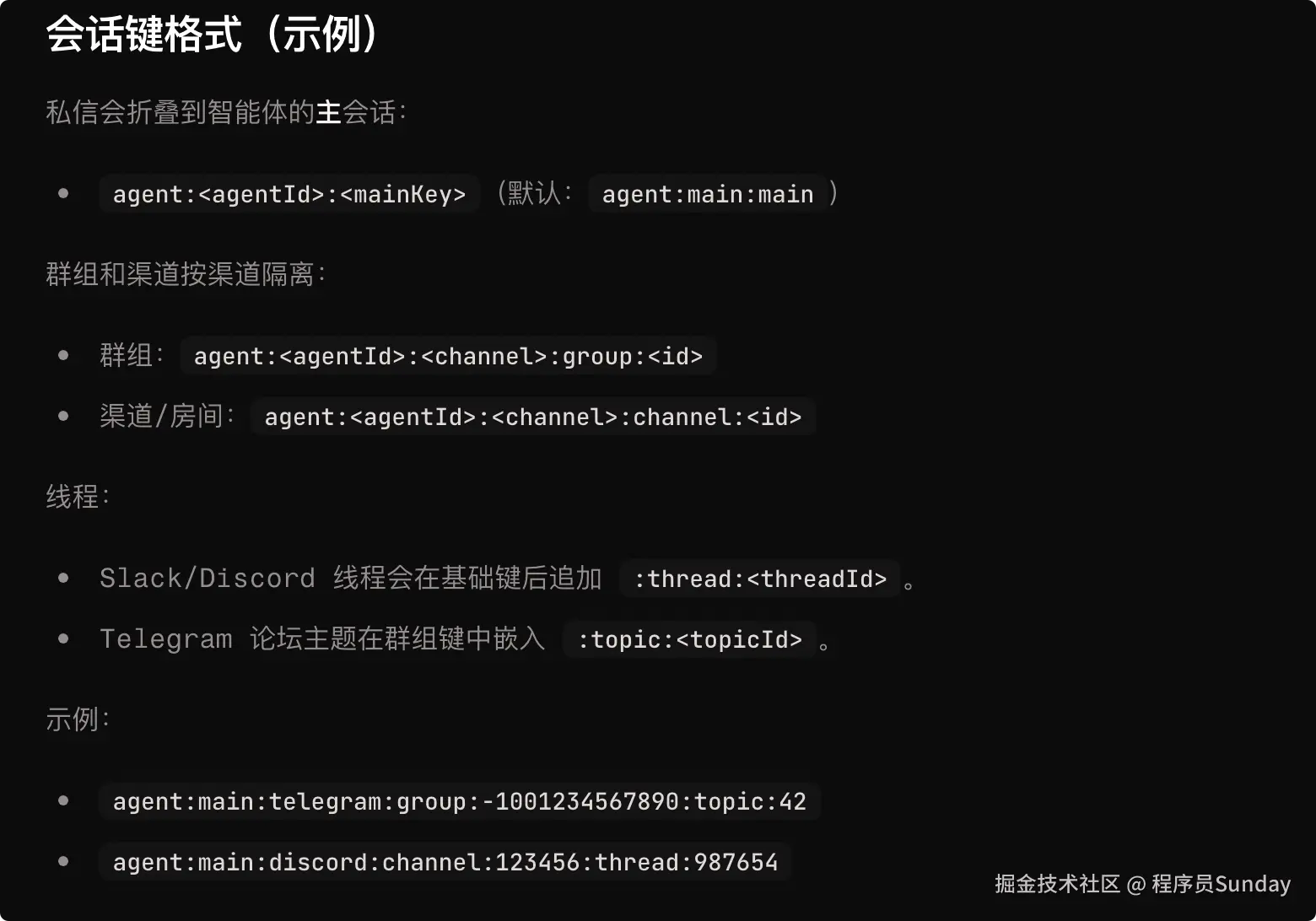
OpenClaw 很强的一点,是它对 SessionKey 的设计非常明确。
官方文档写得很清楚:
- 直接消息默认会折叠到 agent 的
mainsession - 群组和频道则会按 channel 隔离
- Slack/Discord thread 还会进一步带
:thread:<threadId> - Telegram forum topic 会带
:topic:<topicId>
这个设计非常重要。
因为 AI 产品最容易出现的一个问题就是:上下文污染。
今天和老板聊的内容,混进了群聊上下文。群聊里一个同事的需求,又跑到了另一个私聊线程里。最后 AI 的记忆就全部乱掉了
而 OpenClaw 的处理方法就是把 把 session key 设计清楚
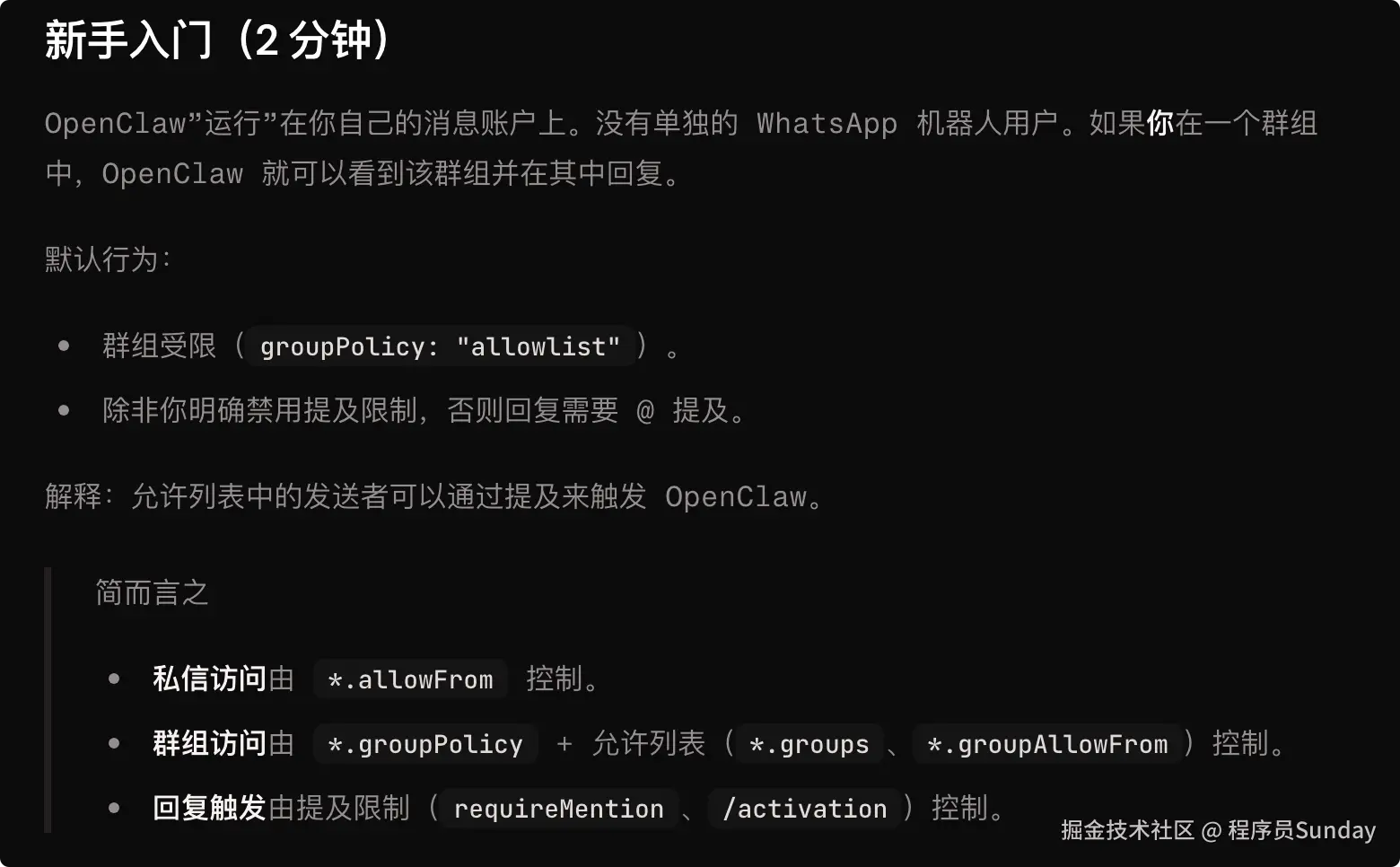
官方 Groups 文档也明确说了:
- 群消息默认是受限的
- 默认需要 mention 才会回复
- 没 mention 的消息可以"只存上下文,不回复"
- 群组 session 与私聊 session 天然隔离
这一点我特别认可。
因为对真实产品来说,群消息不是只有"回"或"不回"两个选项。
更优雅的处理是:不触发回答,但保留上下文线索。
这样 agent 既不会乱插话,也不会完全失忆。这个设计放到 AI 客服、企业群机器人、面试助手里都非常实用。
六、OpenClaw 的工具系统
OpenClaw 官方文档里对 Tools(工具系统) 的表述很直接:它暴露的是 first-class agent tools。

并且明确说,这些工具替代了旧的 openclaw-* skills,特点是:很多能力不需要再绕一层 shell 来实现,而是直接走 typed tool。
OpenClaw 明显是把"工具"当作 权限面 来管理的,而不是单纯的 大模型方法的调用 API 列表。
七、Skills 在 OpenClaw 里到底是什么?
官方文档写得很清楚:

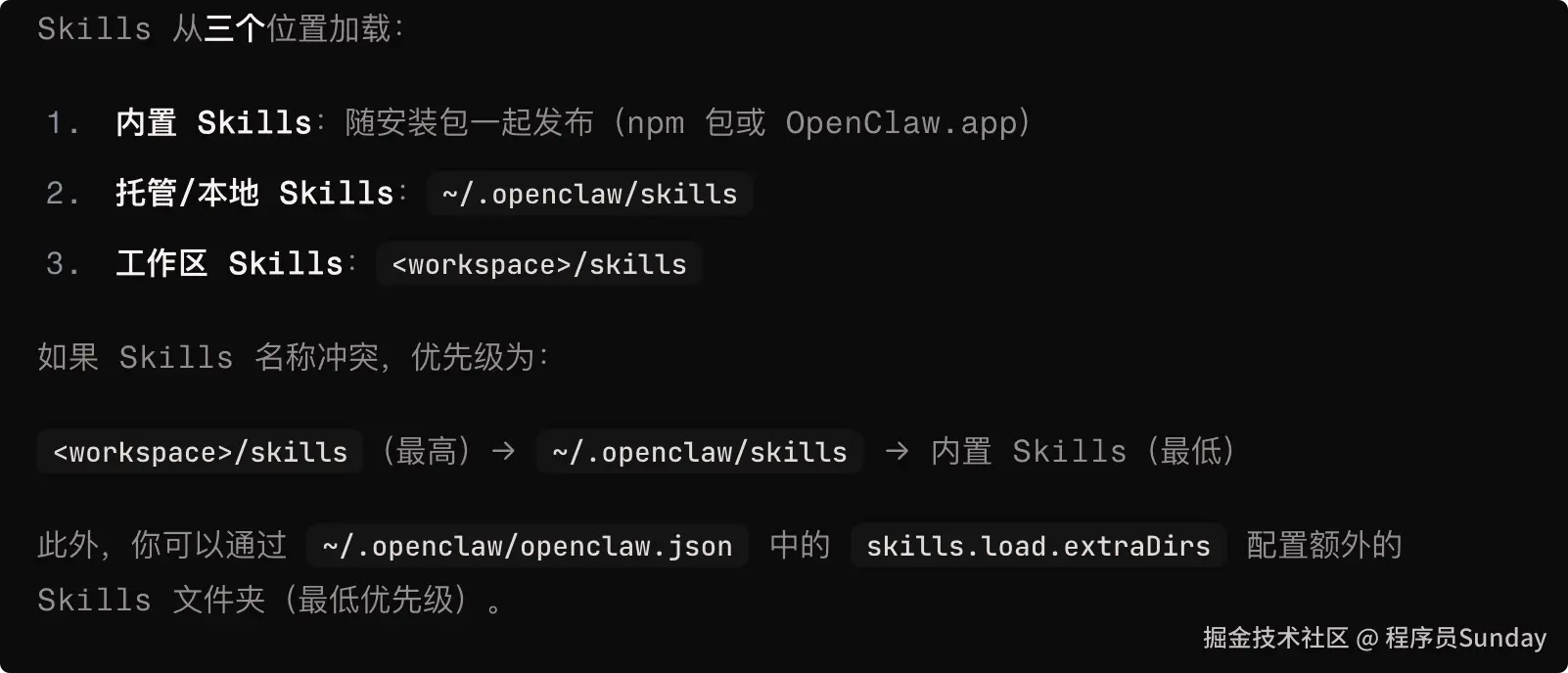
简单来说所谓的 skills 就是一个目录,里面有 SKILL.md 和 YAML frontmatter,是用来 教 agent 如何使用工具的
也就是说:
- Tools 更像执行能力
- Skills 更像调用方法 或者是 固定的行为流程
skills 的加载位置和执行流程如下:
八、OpenClaw 的记忆在哪里?
很多人说"AI 记忆",下意识想到向量库。
其实不是。
OpenClaw 的记忆主要来自于 Markdown 文件。
没错,就是那个 .md 文件。。。

整个记忆空间默认会有两层:
memory/YYYY-MM-DD.md:每日追加日志MEMORY.md:整理过的长期记忆,只在主私有 session 中加载,不进群上下文(OpenClaw9)
而 workspace 本身,被官方定义为 agent 的 home,也是 file tools 和 workspace context 的唯一工作目录。配置和 credentials 不放这里,而是放 ~/.openclaw/

这里我觉得 OpenClaw 有两个非常值得借鉴的点。
第一:记忆文件化
这会让整个系统的可解释性高很多。
你不用猜"模型记住了什么",直接看 Markdown 文件就知道。
第二:workspace 不是硬沙箱
官方明确提醒,workspace 只是默认 cwd,不是 hard sandbox。相对路径默认在 workspace 下解析,但绝对路径理论上还能访问宿主机其他位置,除非你显式开启 sandbox。

这点特别重要。
因为很多人看到"workspace"三个字,会天然以为已经隔离了。
其实没有。
OpenClaw 的态度是:默认便利优先,真要隔离请开 sandbox。
写到最后
很多人聊 OpenClaw,最容易盯着两个点:
- 一个是,它真强
- 另一个是,它真危险
但我觉得,真正值得研究的,不是它到底安不安全,而是 为什么它一旦强起来,安全问题就一定会跟着放大。
因为 OpenClaw 从来就不是一个只会聊天的机器人。它背后是 一个长期运行的 Gateway,是一套真正会处理 session、调 tools、接 channels、管 nodes、写 memory 的 Agent 系统 。你越把它当成AI 操作层来看,就越能理解它为什么会有这么大的争议。
所以这篇文章我真正想说的,不是 OpenClaw 能不能用。
而是当一个 AI 不再只是回答问题,而是真的开始接入消息渠道、调用工具、接触文件系统、甚至影响真实设备时,对于很多普通人来说,你是否真的有驾驭它的能力?
就像我们前面所说的:
OpenClaw 真的给了你很强的能力,但是很多人低估了想要使用这种能力,可能需要付出的代价