文章目录
-
- 0.引言
- 1.为什么需要日志?
- 2.核心概念
-
- [2.1 journal_t:日志全局控制结构体(核心顶层结构体)](#2.1 journal_t:日志全局控制结构体(核心顶层结构体))
- [2.2 transaction_t:事务核心结构体](#2.2 transaction_t:事务核心结构体)
- [2.3 jbd2_journal_handle_t:事务操作句柄(handle_t)](#2.3 jbd2_journal_handle_t:事务操作句柄(handle_t))
- [2.4 日志记录相关结构体(磁盘存储相关)](#2.4 日志记录相关结构体(磁盘存储相关))
- 3.核心流程
- 4.关键机制
- 5.总结
0.引言
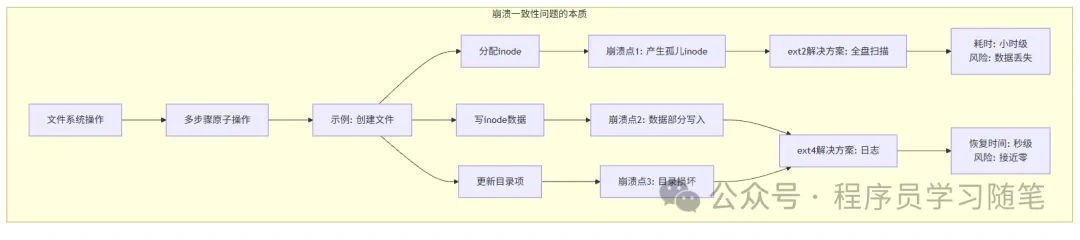
文件系统如何确保"删除一个文件"这个操作,不会因为突然断电而只完成了一半,导致空间泄露?又如何保证涉及多个数据块更新的操作,要么全部成功,要么全部失效?
这些问题的本质是数据的一致性。ext4的答案是它的日志子系统(Journal),一套在真正改动磁盘结构前,先将"意图"记录在案的机制。
在前两篇内容中,我们剖析了ext4的inode、块管理机制,了解了文件如何被存储和索引,但这些机制的正常运行,都依赖于日志子系统提供的"容错兜底"。不同于其他文件系统的日志实现,ext4的Journal子系统兼顾了性能与可靠性,通过一套严谨的"先写日志、再写数据"的核心逻辑,从根源上解决了异常场景下的数据一致性问题。
本文将从"为什么需要日志子系统"出发,深度拆解Journal的核心原理、工作流程、日志模式,以及它如何在异常中断时实现数据恢复,彻底讲清ext4是如何通过Journal保障数据一致性的。
1.为什么需要日志?
要理解为什么文件系统需要日志机制,我们可以考虑在没有日志机制的文件系统数据操作。对于数据写入如果遵循"直接写入磁盘"的逻辑:当我们执行文件创建、写入、修改操作时,系统会先修改文件的元数据(inode、目录项、超级块等),再修改实际的数据块。这个过程看似简单,却存在一个致命隐患------元数据与数据写入的"原子性"无法保证。
举个典型场景:你向磁盘写入一份100MB的文件,系统先更新了inode中的"文件大小""修改时间"等元数据(标记文件已存在),但还没来得及将实际的文件内容写入数据块,突然发生断电。此时,磁盘中存在"元数据已更新,但数据块为空"的矛盾------文件显示存在,打开后却为空,甚至可能导致整个文件系统的元数据错乱,出现"坏块""文件丢失"等更严重的问题。
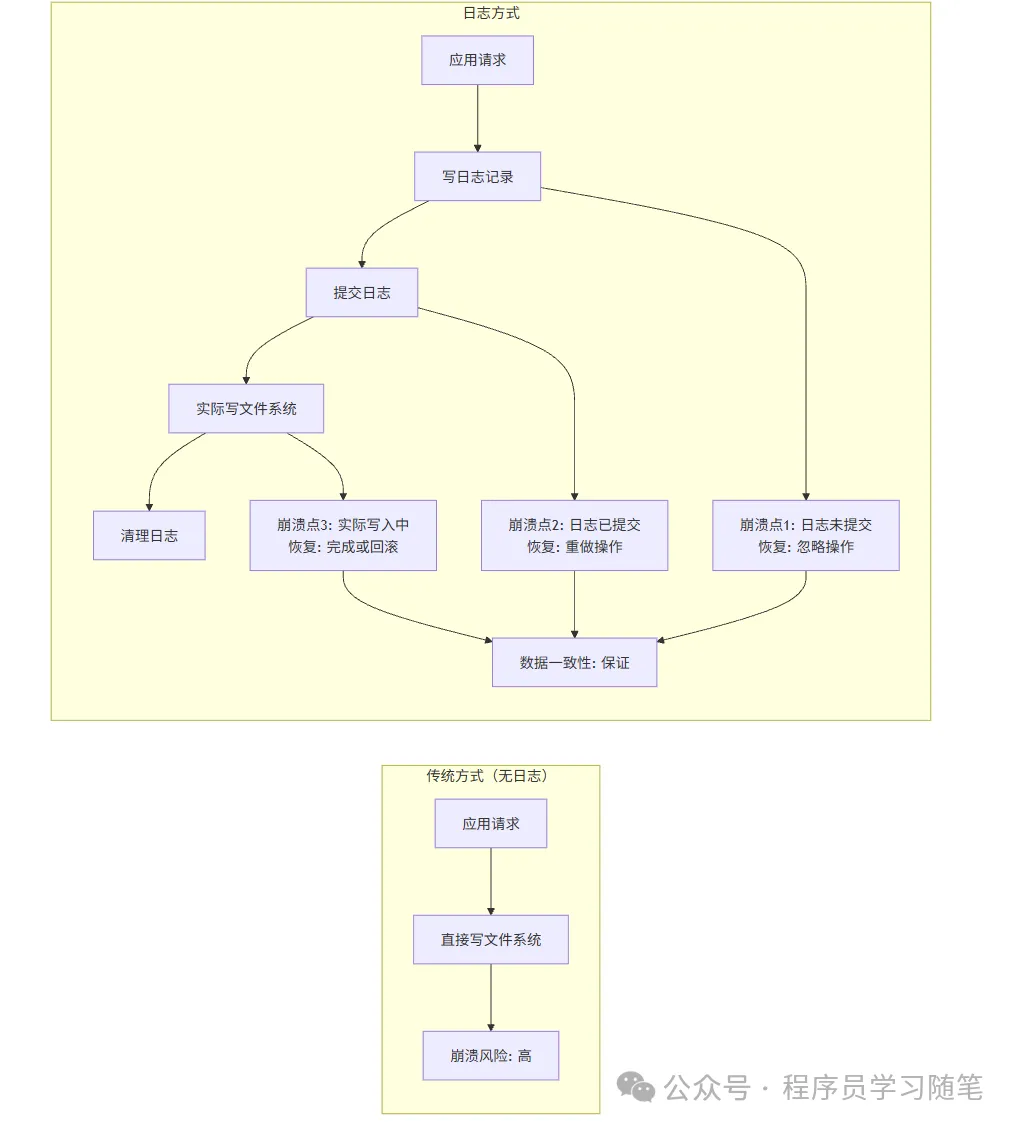
这种"部分写入"的问题,本质是"元数据与数据的写入不同步"。为了解决这个问题,ext3首次引入了Journal日志子系统,ext4在此基础上进行了大幅优化,核心目标只有一个:将"元数据+数据"的写入过程,转化为可追溯、可恢复的"原子操作",即使出现异常中断,也能通过日志还原操作,保证数据与元数据的一致性。
2.核心概念
核心概念我们从各核心结构体来看,其围绕"日志管理→事务执行→操作记录→磁盘存储"形成清晰的层级关联,核心关联链如下,结合源码定义拆解每一层的作用:
核心关联链:journal_t(日志全局管理) → transaction_t(事务) → jbd2_journal_handle_t(事务操作句柄)/ jbd2_inode_t(关联inode) → journal_entry相关结构体(日志记录,含tag、header等) → journal_superblock_t(日志超级块,磁盘存储)
2.1 journal_t:日志全局控制结构体(核心顶层结构体)
对应源码中 struct journal_s(typedef 为 journal_t),是 Journal 子系统的"总控制器",维护整个日志的全局状态、事务链表、日志分区信息等,关联到文件系统超级块。
核心作用:管理所有事务(运行中、提交中、待检查点)、日志分区的磁盘信息(设备、块大小、偏移)、日志校验相关配置,以及各类同步锁和等待队列,确保日志操作的有序性和安全性。
cpp
struct journal_s {
unsigned long j_flags; /* 日志全局状态标志
* 如JBD2_ABORT:日志已终止;JBD2_LOADED:日志超级块已加载
* 对应前文"日志损坏排查"中"Journal has been aborted"场景(此标志置位)
*/
journal_superblock_t *j_superblock; /* 指向日志超级块(journal_superblock_t)的指针
* 对应磁盘上日志分区的超级块,存储日志静态配置(如总长度)和动态状态(如当前事务序号)
*/
transaction_t *j_running_transaction;/* 指向当前运行中的事务
* 对应前文事务"活跃"状态,是事务状态管理核心指针
*/
transaction_t *j_committing_transaction;/* 指向正在提交的事务
* 对应前文事务"提交中"状态,是事务状态管理核心指针
*/
transaction_t *j_checkpoint_transactions;/* 指向待检查点清理的事务链表
* 对应前文"检查点"机制,所有已提交、可清理的事务均挂载到此链表
*/
unsigned long j_head; /* 日志环形缓冲区当前写入位置
* 与j_tail、j_free配合,实现环形日志缓冲区,避免日志溢出(对应前文核心设计)
*/
unsigned long j_tail; /* 日志环形缓冲区最旧可用位置
* 与j_head、j_free配合,实现环形日志缓冲区,避免日志溢出(对应前文核心设计)
*/
unsigned long j_free; /* 日志环形缓冲区空闲块数量
* 与j_head、j_tail配合,实现环形日志缓冲区,避免日志溢出(对应前文核心设计)
*/
struct block_device *j_dev; /* 日志所在块设备指针
* 对应前文"日志分区独立于数据分区"的设计,确保日志写入与数据写入不干扰
*/
int j_blocksize; /* 日志块大小
* 对应前文"日志分区独立于数据分区"的设计,确保日志写入与数据写入不干扰
*/
struct jbd2_revoke_table_s *j_revoke;/* 日志撤销表指针
* 对应源码"撤销机制",前文"异常恢复"中未提交事务的撤销,依赖此表记录的撤销信息
*/
// 省略冗余辅助字段(锁、等待队列、统计字段等)
};2.2 transaction_t:事务核心结构体
对应源码中 struct transaction_s(typedef 为 transaction_t),是前文"事务"概念的源码实现,封装了一个事务的所有核心信息,是"原子操作"的载体。
cpp
struct transaction_s {
journal_t *t_journal; /* 指向所属的日志对象(journal_t)
* 关联事务到具体日志分区,确保事务操作对应正确日志
*/
tid_t t_tid; /* 事务ID,全局唯一递增
* 与前文"每个事务对应唯一事务ID"完全一致,用于标记事务及关联日志记录
*/
enum {
T_RUNNING, // 事务活跃(可接收新操作)
T_LOCKED, // 事务锁定(不接收新操作,等待现有操作完成)
T_SWITCH, // 事务切换(过渡状态)
T_FLUSH, // 事务刷盘(正在将日志写入磁盘)
T_COMMIT, // 事务提交(正在写入提交标记)
T_COMMIT_DFLUSH, // 提交中(等待数据刷盘)
T_COMMIT_JFLUSH, // 提交中(等待日志刷盘)
T_COMMIT_CALLBACK, // 提交回调(过渡状态)
T_FINISHED // 事务完成(待检查点清理)
} t_state; /* 事务状态,源码定义8种,核心流转:
* T_RUNNING → T_FLUSH → T_COMMIT → T_FINISHED
* 对应前文事务"活跃、提交中、已完成"的核心状态
*/
struct journal_head *t_buffers;/* 事务关联的所有元数据缓冲区链表
* 对应前文"事务打包相关写入操作",所有修改的元数据块均挂载到此链表
*/
struct journal_head *t_reserved_list;/* 事务预留的缓冲区链表
* 对应前文"事务打包相关写入操作",用于预留日志空间,避免溢出
*/
struct list_head t_inode_list;/* 事务关联的inode链表(存储jbd2_inode结构体)
* 对应前文"顺序模式",事务提交前需同步inode数据,用于跟踪需特殊处理的inode
*/
atomic_t t_outstanding_credits;/* 事务预留的日志缓冲区配额(credits)
* 对应源码"日志空间限制",确保事务不超出日志分区容量
* 前文"性能优化"中日志分区大小调整,本质是调整此配额上限
*/
transaction_t *t_cpnext; /* 事务在检查点链表中的下一个指针
* 与t_cpprev配合,将已完成事务挂载到journal_t的j_checkpoint_transactions链表,等待清理
*/
transaction_t *t_cpprev; /* 事务在检查点链表中的上一个指针
* 与t_cpnext配合,将已完成事务挂载到journal_t的j_checkpoint_transactions链表,等待清理
*/
// 省略冗余辅助字段(时间戳、统计字段等)
};2.3 jbd2_journal_handle_t:事务操作句柄(handle_t)
对应源码中 struct jbd2_journal_handle(typedef 为 handle_t),是用户/系统操作与事务之间的"桥梁",所有文件系统的写入操作(如创建文件、修改数据),都通过此句柄关联到具体事务。
核心作用:跟踪单个原子操作的执行过程,管理事务的缓冲区配额(credits),记录操作的错误状态,确保操作被正确打包到对应的事务中。
cpp
struct jbd2_journal_handle {
union {
transaction_t *h_transaction;/* 指向当前操作所属的事务(transaction_t)
* 非预留句柄(h_reserved=0)时生效,将操作绑定到具体事务
* 确保同一操作的所有步骤(如创建文件的4个步骤)归属同一个事务
*/
journal_t *h_journal; /* 指向所属日志对象(journal_t)
* 预留句柄(h_reserved=1)时生效,关联预留句柄到具体日志
*/
};
int h_total_credits; /* 当前句柄可用的缓冲区配额
* 控制单个操作占用的日志空间,避免日志溢出
*/
int h_revoke_credits; /* 当前句柄可用的撤销记录配额
* 控制单个操作占用的撤销表空间,避免撤销表溢出
*/
int h_err; /* 操作的错误状态码
* 记录操作过程中出现的错误(如IO失败),用于后续异常处理
*/
unsigned int h_aborted:1; /* 操作终止标志(位域)
* 置位时表示操作异常终止,事务会被标记为未提交,触发撤销操作(对应前文"异常恢复")
*/
unsigned int h_jdata:1; /* 强制数据日志标记(位域)
* 置位时:当前操作的数据需写入日志(对应前文data=journal模式)
* 未置位时:对应顺序模式或写回模式(前文核心日志模式)
*/
// 省略冗余辅助字段(引用计数、类型标记等)
};2.4 日志记录相关结构体(磁盘存储相关)
此类结构体对应"日志记录(Journal Entry)",用于将事务操作记录到磁盘日志分区,是"预写日志(WAL)"机制的底层实现,核心包括日志头、日志标签、提交头、超级块等。
1)journal_header_t:所有日志块的通用头
源码定义为日志块的标准头,所有日志相关的磁盘块(描述符块、提交块、超级块)都包含此头,用于标识日志块的类型和序号。
cpp
typedef struct journal_header_s {
__be32 h_magic; /* 日志魔数,固定为0xc03b3998U
* 用于校验日志块合法性,魔数不匹配则日志块损坏(对应前文"日志校验失败"场景)
*/
__be32 h_blocktype; /* 日志块类型
* 如JBD2_DESCRIPTOR_BLOCK(描述符块)、JBD2_COMMIT_BLOCK(提交块)
* 用于区分不同类型的日志记录,便于日志解析和恢复
*/
__be32 h_sequence; /* 日志块的事务序号(网络字节序)
* 与transaction_t的t_tid对应,用于关联日志块到具体事务
* 是日志恢复时"定位未提交事务"的核心依据(对应前文恢复机制)
*/
} journal_header_t;2)journal_block_tag3_t / journal_block_tag_t:日志块标签
用于描述日志中单个缓冲区(元数据块/数据块)的信息,记录缓冲区的磁盘地址、校验和和状态,是日志记录的"核心载体",对应前文日志记录中的"操作对象"和"操作内容"。
cpp
// 新版本标签结构体(CSUM_V3特性,支持完整32位校验和)
typedef struct journal_block_tag3_s {
__be32 t_blocknr; /* 缓冲区对应的磁盘块编号(网络字节序,32位)
* 对应前文"操作对象的块编号",确保日志恢复时能定位到具体磁盘块
*/
__be32 t_flags; /* 缓冲区状态标志(网络字节序)
* 如JBD2_FLAG_DELETED:块被事务删除
* 用于日志恢复时判断操作类型(重做/撤销,对应前文恢复机制)
*/
__be32 t_blocknr_high; /* 磁盘块编号的高32位(网络字节序)
* 用于64位磁盘地址适配,确保能识别大容量磁盘的块编号
*/
__be32 t_checksum; /* 缓冲区校验和(网络字节序,CRC32C等)
* 对应前文"日志校验机制",用于校验日志记录完整性,避免恢复失败
*/
} journal_block_tag3_t;
// 旧版本标签结构体(校验和为16位,无CSUM_V3特性)
typedef struct journal_block_tag_s {
__be32 t_blocknr; /* 缓冲区对应的磁盘块编号(网络字节序,32位)
* 功能同journal_block_tag3_t的t_blocknr
*/
__be16 t_checksum; /* 缓冲区校验和(网络字节序,16位,截断版)
* 功能同journal_block_tag3_t的t_checksum,仅校验和长度不同
*/
__be16 t_flags; /* 缓冲区状态标志(网络字节序)
* 功能同journal_block_tag3_t的t_flags,仅长度不同(适配旧版本)
*/
__be32 t_blocknr_high; /* 磁盘块编号的高32位(网络字节序)
* 功能同journal_block_tag3_t的t_blocknr_high
*/
} journal_block_tag_t;3)struct commit_header:事务提交块头
对应前文"事务提交标记",当事务提交时,系统会在日志分区写入一个提交块,此结构体是提交块的核心头信息,用于标记事务已成功提交。
cpp
struct commit_header {
__be32 h_magic; /* 魔数,与journal_header_t的h_magic一致(0xc03b3998U)
* 用于校验提交块合法性,避免提交块损坏
*/
__be32 h_blocktype; /* 块类型,固定为JBD2_COMMIT_BLOCK(提交块)
* 用于区分提交块与其他日志块(如描述符块)
*/
__be32 h_sequence; /* 事务序号(网络字节序)
* 与transaction_t的t_tid对应,标记当前提交的事务ID
*/
unsigned char h_chksum_type; /* 校验和类型
* 如JBD2_CRC32C_CHKSUM(CRC32C校验),用于指定校验和算法
*/
unsigned char h_chksum_size; /* 校验和长度(字节数)
* 与h_chksum_type配合,确保校验和解析正确
*/
unsigned char h_padding[2]; /* 填充字段,用于内存对齐,无实际业务意义
*/
__be32 h_chksum[JBD2_CHECKSUM_BYTES];/* 提交块校验和(网络字节序)
* 用于校验提交块完整性,确保"事务提交"标记不被篡改
*/
__be64 h_commit_sec; /* 事务提交的秒级时间戳(网络字节序)
* 用于日志清理(检查点)时判断事务过期状态,也用于运维排查(查看提交时间)
*/
__be32 h_commit_nsec; /* 事务提交的纳秒级时间戳(网络字节序)
* 与h_commit_sec配合,精确记录事务提交时间
*/
};4)journal_superblock_t:日志超级块
存储日志分区的静态配置和动态状态,位于日志分区的起始位置,是日志子系统初始化和恢复的"入口",对应前文"日志分区独立"的设计。
cpp
typedef struct journal_superblock_s {
journal_header_t s_header; /* 日志超级块的通用头
* 包含魔数、块类型(JBD2_SUPERBLOCK_V2)、事务序号,用于校验超级块合法性
*/
__be32 s_blocksize; /* 日志块大小(网络字节序)
* 静态配置,决定日志分区的块粒度,与journal_t的j_blocksize一致
*/
__be32 s_maxlen; /* 日志总块数(网络字节序)
* 静态配置,决定日志分区的容量上限(总大小 = s_blocksize * s_maxlen)
*/
__be32 s_first; /* 日志第一个可用块编号(网络字节序)
* 静态配置,标记日志分区的有效起始位置
*/
__be32 s_sequence; /* 当前日志的起始事务序号(网络字节序)
* 动态更新,日志恢复时从该序号开始校验事务(对应前文恢复机制)
*/
__be32 s_start; /* 日志当前起始块编号(网络字节序)
* 动态更新,日志恢复时从该块开始读取日志(对应前文恢复机制)
*/
__be32 s_errno; /* 日志错误码(网络字节序)
* 日志出现异常(如损坏)时,记录对应错误码(如EFSBADCRC=校验和错误)
* 对应前文"日志损坏排查"中fsck命令检测的错误信息
*/
__be32 s_feature_compat; /* 兼容特性标志(网络字节序)
* 如JBD2_FEATURE_COMPAT_CHECKSUM(校验和兼容),用于适配旧版本系统
*/
__be32 s_feature_incompat; /* 不兼容特性标志(网络字节序)
* 如JBD2_FEATURE_INCOMPAT_CSUM_V3(校验和V3)、FAST_COMMIT(快速提交)
* 用于适配不同版本ext4文件系统的特性
*/
__be32 s_feature_ro_compat; /* 只读兼容特性标志(网络字节序)
* 用于标记只读模式下兼容的特性,避免只读挂载时出现兼容性问题
*/
__u8 s_uuid[16]; /* 日志UUID(128位)
* 用于唯一标识日志,避免日志与其他分区混淆(如多文件系统共享日志场景)
*/
// 省略冗余辅助字段(用户数、动态超级块地址、统计字段等)
} journal_superblock_t;
2.5 jbd2_inode_t:事务关联的inode结构体
对应源码中 struct jbd2_inode,用于关联事务和inode,主要在"顺序模式"下使用,跟踪需要同步数据的inode,确保数据块写入先于元数据块写入。
struct jbd2_inode {
transaction_t *i_transaction; /* inode所属的事务(transaction_t)
* 确保inode的修改操作被打包到正确的事务中
*/
transaction_t *i_next_transaction;/* 指向正在修改当前inode数据的运行中事务
* 当当前inode已有提交中事务时,用于关联后续运行中事务
*/
struct list_head i_list; /* 挂载到事务inode链表的节点
* 用于将当前jbd2_inode挂载到transaction_t的t_inode_list链表
*/
struct inode *i_vfs_inode; /* 指向VFS层的inode结构体
* 关联Journal子系统和文件系统的inode管理,打通日志与inode操作
*/
unsigned long i_flags; /* inode标志位
* 如JI_WRITE_DATA(需同步数据)、JI_WAIT_DATA(需等待数据刷盘)
* 对应前文"顺序模式",控制inode数据同步时机
*/
loff_t i_dirty_start; /* inode脏数据的起始偏移(字节)
* 用于事务提交时,精准同步inode的脏数据范围,确保数据完整性
*/
loff_t i_dirty_end; /* inode脏数据的结束偏移(字节,含)
* 与i_dirty_start配合,精准同步inode的脏数据范围,确保数据完整性
*/
};3.核心流程
实际流程根据三种日志模式会有所不同,所以我们先看日志模式:
1)日志模式(Journal Mode):最高一致性,最低性能
这种模式下,元数据块和数据块都会写入日志------所有写入操作(元数据修改、数据写入),都会先将对应的日志记录(包含元数据和数据)写入日志分区,再执行实际写入。
优势:一致性最高,即使出现异常中断,数据和元数据都能通过日志完全恢复,不会出现任何数据丢失或错乱;
劣势:性能最低,因为数据需要写入两次(日志分区+实际数据分区),IO开销较大;
适用场景:对数据一致性要求极高的场景。
2) 顺序模式(Ordered Mode):默认模式,平衡一致性与性能
这种模式下,只有元数据块写入日志,数据块不写入日志,但系统会保证"数据块的写入顺序在元数据块写入之前"。
核心逻辑:当执行写入操作时,系统会先将数据块写入实际的数据分区,再将元数据块的日志记录写入日志分区,最后执行元数据块的实际写入。这样一来,即使出现异常,元数据的日志记录中对应的"数据块已写入",不会出现"元数据已更新,但数据块为空"的情况。
优势:一致性有保障(不会出现元数据与数据不一致),性能比日志模式高(数据只需写入一次);
劣势:数据块本身没有日志备份,如果数据块写入过程中出现异常(如断电),可能会导致数据块内容损坏,但元数据仍然一致;
适用场景:大多数通用场景,如桌面端、普通服务器,是ext4的默认日志模式。
3)写回模式(Writeback Mode):最高性能,最低一致性
这种模式下,只有元数据块写入日志,数据块不写入日志,且不保证数据块与元数据块的写入顺序。
核心逻辑:系统会异步写入数据块(即先写入内存缓冲区,后续再批量同步到磁盘),同步写入元数据的日志记录和实际元数据块。此时,可能出现"元数据已更新,但数据块还未写入磁盘"的情况,异常中断后,会出现"文件存在但内容为空"的问题。
优势:性能最高,IO开销最小,适合高并发写入场景;
劣势:一致性最差,可能出现数据丢失(数据块未同步到磁盘);
适用场景:对数据一致性要求较低,追求高性能的场景,如日志服务器、临时文件存储等。
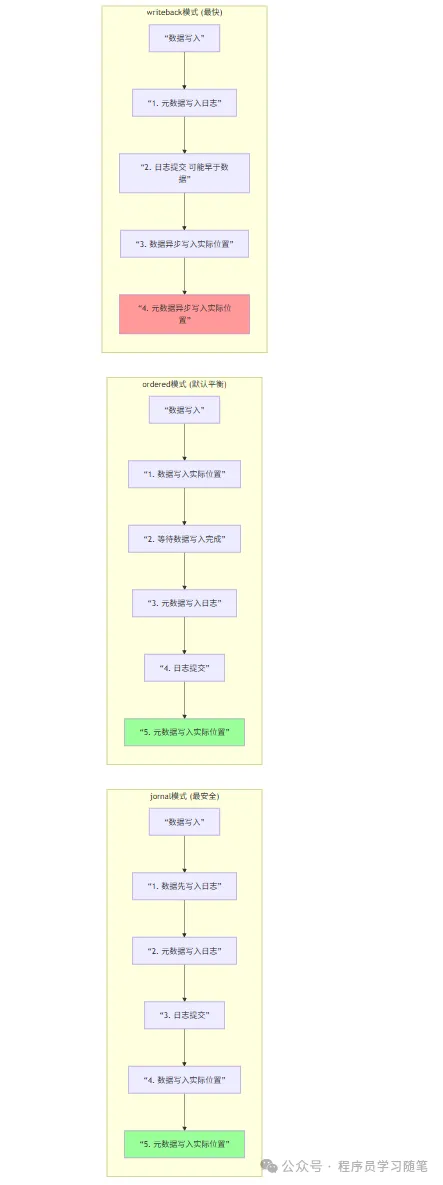
接下来来看其写入流程(如下图):
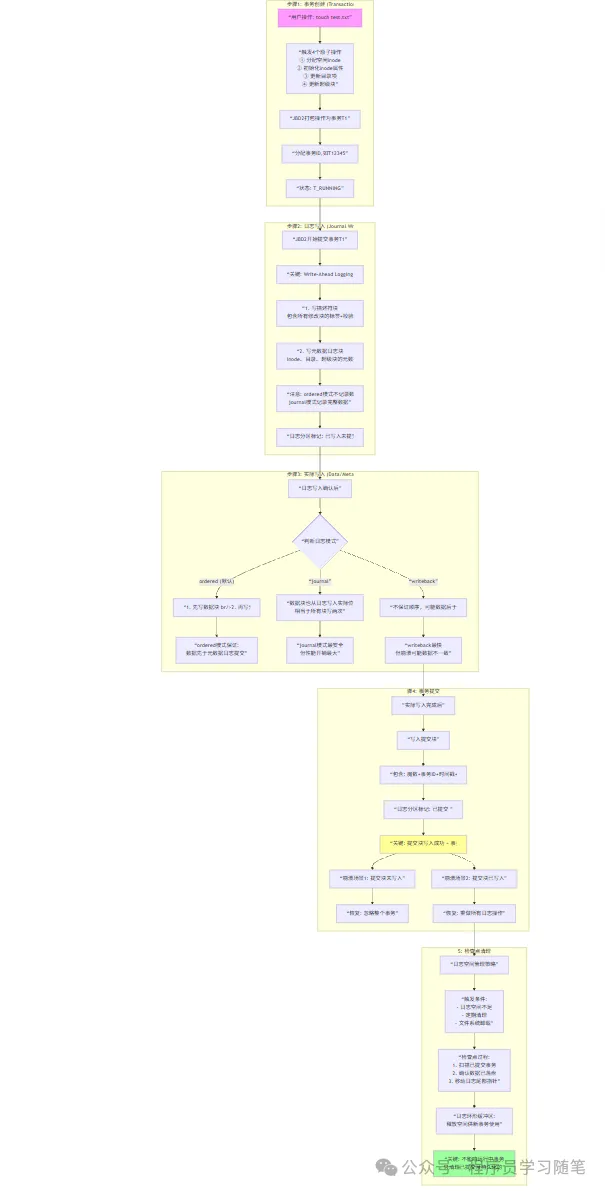
4.关键机制
通过上面的工作流程,我们已经能初步理解Journal子系统的一致性保障逻辑,其中关键机制就是WAL 预写日志机制。
WAL机制是Journal子系统的核心,其核心原则是"先写日志,再写数据"。日志记录了"操作的意图"和"操作前后的数据",相当于给所有写入操作做了一份"备份"。
当出现异常中断时,系统重启后会首先检查日志分区:
如果事务已提交(有提交标记):说明事务中的所有操作都已实际写入磁盘,日志记录可忽略,执行检查点清理即可;
如果事务未提交(无提交标记):说明事务中的实际写入操作未全部完成,系统会根据日志记录中的"操作前数据",撤销已执行的部分操作,将元数据和数据恢复到操作前的状态,避免出现"部分写入"导致的一致性问题。
5.总结
ext4的Journal子系统,本质是通过"预写日志(WAL)+ 事务原子性",解决了文件系统写入过程中的"部分写入"问题,从而保障数据与元数据的一致性。在异常场景(断电、系统崩溃)下,它能最大限度地保护数据不丢失、不错乱。
理解Journal子系统,不仅能帮助我们更好地使用ext4文件系统(如根据场景选择合适的日志模式、排查IO性能问题),更能深入理解"数据一致性"在文件系统中的实现逻辑------这也是后续学习ext4高级特性(如延迟分配、快照)的基础。
补充信息(欢迎大家了解加入):C++/Linux/ 数据库内核 | 底层开发 + AI 实战圈------12 个月系统落地,从原理到工业级实战,搭建你的核心技术壁垒