一、背景与问题
我们有个项目组在接到需求后做实时入湖开发,核心链路是采用Canal将 MySQL CDC 数据采集到Kafka,使用Flink(1.16)引擎消费同步至 Hudi 表。
项目组采用FlinkSql开发,业务表为宽表设计,单表字段数量达200多个字段。因Canal数据采集格式采用了Before/After数据模式(Flinksql创建Kafka源表对应的data字段类型指定为array<row<xx string,...>>),项目组在Sql处理逻辑中通过CASE WHEN表达式处理CDC 的 INSERT/UPDATE/DELETE三种操作类型,提取对应数据内容进行相应处理。
作业提交运行后出现以下异常:作业无法正常进入运行状态,页面一直显示作业初始化中的状态。
二、排查与分析
1.初步排查
查看Flink作业后台进程,发现JM隔一会就会自动重启,TM进程一直未启动。查看JM启动日志发现每次都是因为Java heap space堆内存溢出导致Flink容错机制自动重启,查看JM的GC日志,日志中大量出现 concurrent mode failure,表明并发 GC 已无法跟上内存分配速度。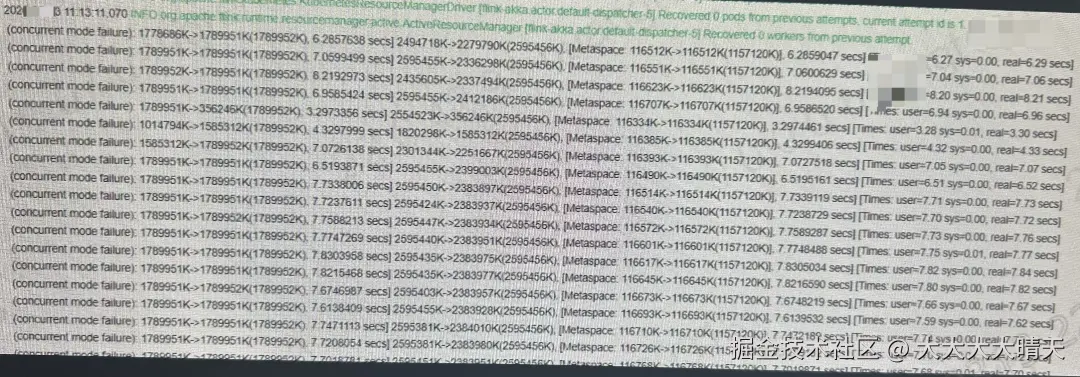 查看JM的堆内存监控,堆内存在 1 分钟内占比快速攀升接近至100%,即便配置 8G process内存,GC 也无法有效回收,几分钟内触发 OutOfMemoryError。
查看JM的堆内存监控,堆内存在 1 分钟内占比快速攀升接近至100%,即便配置 8G process内存,GC 也无法有效回收,几分钟内触发 OutOfMemoryError。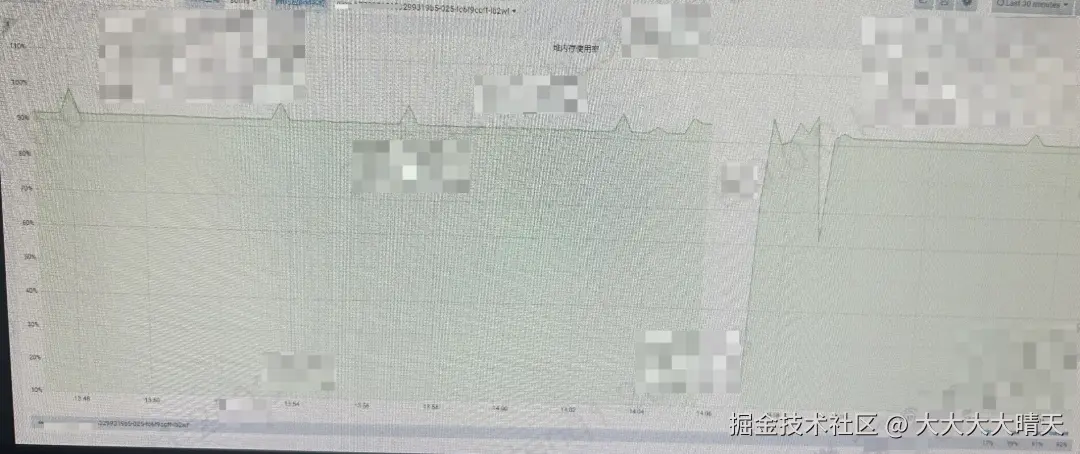 从现象看,内存暴涨发生在作业提交后、尚未开始运行数据的阶段,因此问题大概率出现在SQL解析、优化或代码生成阶段。
从现象看,内存暴涨发生在作业提交后、尚未开始运行数据的阶段,因此问题大概率出现在SQL解析、优化或代码生成阶段。
2.Heap Dump分析
使用jmap命令导出内存快照,通过VisualVM进行Heap Dump分析,发现以下类实例数量异常(数百万至千万级):
| 类名 | 实例数 |
|---|---|
| org.apache.flink.table.shaded.org.antlr.v4.runtime.CommonToken | 千万级 |
| org.apache.flink.table.shaded.org.antlr.v4.runtime.tree.TerminalNodeImpl | 千万级 |
| java.lang.Object\[\] | 百万级 |
| java.util.ArrayList | 百万级 |
| org.apache.flink.table.codesplit.JavaParser$PrimaryContext | 百万级 |
| org.apache.flink.table.shaded.org.antlr.v4.runtime.TokenStreamRewriter$ReplaceOp | 十万级 |
Heap Dump中占据绝大部分内存的是ANTLR的CommonToken和语法树节点。CommonToken是ANTLR在解析SQL时生成的Token对象,通常每个SQL语句只会生成有限数量的Token。但这里Token数量高达数千万,说明Planner内部产生了大量重复的Token,即SQL被反复解析或AST被异常放大,它们的数量爆炸直接导致了JobManager内存溢出。
3.FlinkSql逻辑分析
回头查看应用的FLinkSql逻辑,核心逻辑如下:
sql
insert into table1
select data[1].field1,
try_cast(data[1].field2 as decimal(7, 6)),
data[1].field3,
...,
data[1].fieldn,
binlog_time,
hoodie_is_deleted
from( select
case when 'opType' = 'DELETE' then 'old' else 'data' end as 'data',
FROM_UNIXTIME(try_cast(logStreamTime as bigint)/1000, 'yyyy-MM-dd HH:mm:ss') as binlog_time,
case when 'opType' = 'DELETE' then true else false end as hoodie_is_deleted
from table1_topic
where 'opType' in ('INSERT', 'UPDATE', 'DELETE') and FROM_UNIXTIME(try_cast(logStreamTime as bigint) / 1000, 'yyyy-MM-dd') >= DATE_FORMAT(timestampadd(day, -2, current_timestamp), 'yyyy-MM-dd')) t
where t.data[1].fieldk is not null;其中old、data都是Array<Row<xx string,...>>类型,经过上述FlinkSql片段分析,初步评估根因在于 CASE WHEN+ 宽表Row访问 触发了 Planner 表达式爆炸:每个字段都会生成一个条件分支表达式,用于选择 old(删除 / 更新前)或 data(插入 / 更新后)的数据;当业务表为200 + 列宽表时,总表达式数量 = 列数 × 条件分支数(3 种 opType) × Planner 规则复制次数,呈指数级增长。
在Calcite的SqlToRelConverter和RelOptUtil中,当处理CASE表达式且结果类型为结构化类型时,会调用SqlValidator进行类型推导,并展开字段访问。核心类如RexBuilder会创建大量的RexCall节点,每个节点都对应一个子表达式。一旦表达式树过大,后续的RelDecorrelator、ProjectRemoveRule等规则又会遍历并复制这些节点,进一步加剧膨胀。同时,Flink SQL Planner在代码生成阶段,会将优化后的关系表达式转换为Java代码。巨大的AST会导致生成的Java代码体积异常庞大(可达数百MB),进一步消耗内存。最终,ANTLR在解析和重写过程中需要维护大量Token和语法树节点,导致CommonToken等对象数以千万计,直接撑爆JobManager堆内存。
三、解决方案
1.核心修复
将原 CASE WHEN按 opType拆分为多个查询,用 UNION ALL合并,消除每个字段的条件分支嵌套,这样每个opType分支直接读取data或old中的具体字段,不再产生ROW类型的CASE WHEN,Planner只需处理简单的投影,AST规模线性可控。
按上述方案实施后,Flink作业正常启动稳定运行,JM堆内存保持在正常的健康水位。
2.后续优化
- 宽表拆分:将业务宽表拆分为多个窄表,只在 Flink 作业中投影必要字段,减少单作业处理的字段数量。
- 简化 SQL 表达式:将复杂计算(如 try_cast)下沉到 CDC 源端或预处理阶段,避免在 Flink SQL 中嵌套多层函数。
- 代码审查与复杂度控制:在开发阶段对复杂SQL进行review,特别关注涉及ROW、数组访问、多层CASE WHEN嵌套的场景,评估其对Planner的压力。
- 版本升级:计划升级至 Flink 1.17+,该版本对 Calcite Planner 的表达式展开做了优化,减少不必要的复制。
四、总结
本次生产故障的排查过程,是一次从现象到底层原理的典型实践:
- 现象驱动:通过JM内存飙升、GC异常锁定问题发生阶段。
- 堆外分析:利用Heap Dump发现ANTRL对象爆炸,明确问题域在SQL Planner。
- SQL分析:从具体SQL中识别出危险的CASE WHEN+ROW访问模式。
- 源码求证:结合Calcite优化规则理解表达式展开机制,最终定位根因。
在生产环境中,应保持对SQL复杂度的敏感,通过合理拆分、简化表达式来规避此类风险。同时,深入理解Flink SQL Planner的内部原理,能帮助我们更快速地诊断和解决此类疑难问题。