参考:第十三篇:Llama_index、Embedding Models、Chroma - 猿小姜 - 博客园
什么是LlamaIndex
LlamaIndex是一个专注增强LLM数据处理和查询能力的工具库,用于数据注入、数据结构化、并访问私有或特定领域数据
数据注入:将私有或特定领域数据引入到大模型的过程(使LLM能够在特定的上下文或领域中更好的理解和生成信息)
数据结构化:将非结构化的数据转变成结构化格式的过程(自由文本、图片-->表格或数据库格式)
解决数据和大模型之间的衔接问题(将需要访问的私有或特定领域的数据分散在不同的应用程序和数据存储中)
# RAG(检索增强生成):检索个人或私域数据来增强LLM的一种范式(用于解决大模型幻觉问题)
索引阶段
查询阶段
# 增强模型的方法
微调
RAG:通过数据来增强模型的技术
lamaIndex五大核心工具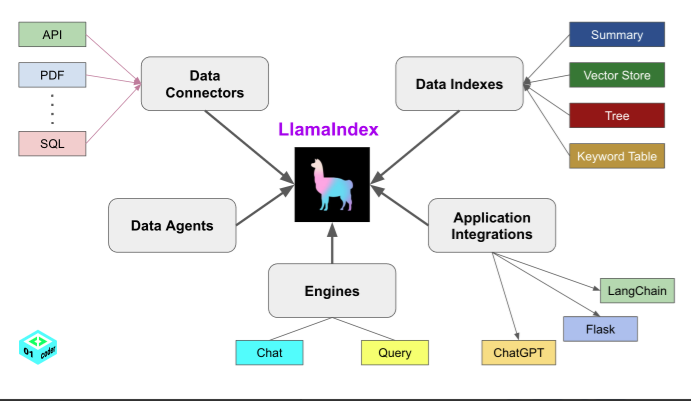
数据连接器(Data Connectors):用于从多样化源数据中提取数据并转换为结构化文档(Document对象:文本和元数据)from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader(DOC_DIR).load_data()
数据索引(Data Indexes):将原始数据构建成为高效查询的索引结构(向量索引:通过嵌入模型将文本转换为词向量)if documents:
logger.info(f"📄 已加载 {len(documents)} 个文档,正在切分...")
node_parser = SentenceSplitter(chunk_size=512, chunk_overlap=50)
nodes = node_parser.get_nodes_from_documents(documents)
logger.info(f"✂️ 生成 {len(nodes)} 个节点。")
index = VectorStoreIndex(nodes=nodes, show_progress=True)
持久化到磁盘
index.storage_context.persist(persist_dir=persist_dir)
logger.info(f"✅ 索引构建并保存完成 ({time.time()-t0:.2f}s)。路径: {persist_dir}")
#引擎(Engines):用于加载大模型(查询引擎、聊天引擎)
构建高性能查询引擎
if index:
调整 top_k 为 3,参考 rag_test_optimized.py,减少噪声
retriever = VectorIndexRetriever(index=index, similarity_top_k=3)
添加相似度后处理,过滤低质量片段 (阈值设为 0.25)
query_engine = RetrieverQueryEngine(
retriever=retriever,
node_postprocessors=SimilarityPostprocessor(similarity_cutoff=0.25)
)
logger.info("✅ RAG 引擎就绪 (TopK=3, Cutoff=0.25)")
else:
query_engine = None
logger.warning("⚠️ RAG 引擎未初始化 (无索引)")
app.state.query_engine = query_engine
app.state.index = index
logger.info("🎉 知识库初始化流程结束。")
query_engine = index.as_query_engine()
response = query_engine.query("LlamaIndex的核心功能是什么?") # 执行查询
chat_engine = index.as_chat_engine()
response = chat_engine.chat("请解释数据索引的作用。") # 多轮对话# 数据代理(Data Agents):由LLM驱动的智能代理,通过工具自动化处理数据任务
Agent = LLM(大脑) + Tools(手脚):通过自然语言理解任务,动态选择工具执行
核心价值:将静态的RAG系统升级为自主迭代的智能体
from llama_index.core.agent import ReActAgent
from llama_index.core.tools import QueryEngineTool
# 将查询引擎封装为工具供Agent调用
tool = QueryEngineTool.from_defaults(query_engine=query_engine)
agent = ReActAgent.from_tools([tool], llm=llm)
response = agent.chat("总结最近新增文档的核心观点")# 应用集成(Application Integrations):提供丰富的应用集成选项(如向量数据库集成、应用框架集成和与模型服务的对接)
from llama_index.vector_stores.chroma import ChromaVectorStore
import chromadb
# 连接Chroma数据库
chroma_client = chromadb.PersistentClient(path="./chroma_db")
vector_store=ChromaVectorStore(chroma_collection=chroma_client.create_collection("docs"))
index = VectorStoreIndex.from_documents(documents,vector_store=vector_store)