拆解 std::mutex 底层实现
在C++开发中,std::mutex 是实现线程同步的核心工具,作为悲观锁的典型代表,它看似简单的 lock()/unlock() 接口背后,藏着从用户态到内核态的多层设计巧思。
std::mutex 不是"单一锁"
很多开发者误以为 std::mutex 是一个简单的"锁结构",但实际上:
std::mutex是C++标准库对系统级同步原语的封装,本身不涉及具体锁逻辑;- 其底层依赖POSIX标准的
pthread_mutex_t,最终落地到Linux内核的futex(快速用户态互斥体); - 核心设计思想是「用户态自旋 + 内核态阻塞」的混合模式,平衡无冲突时的性能和有冲突时的资源占用。
通过架构图建立整体认知:
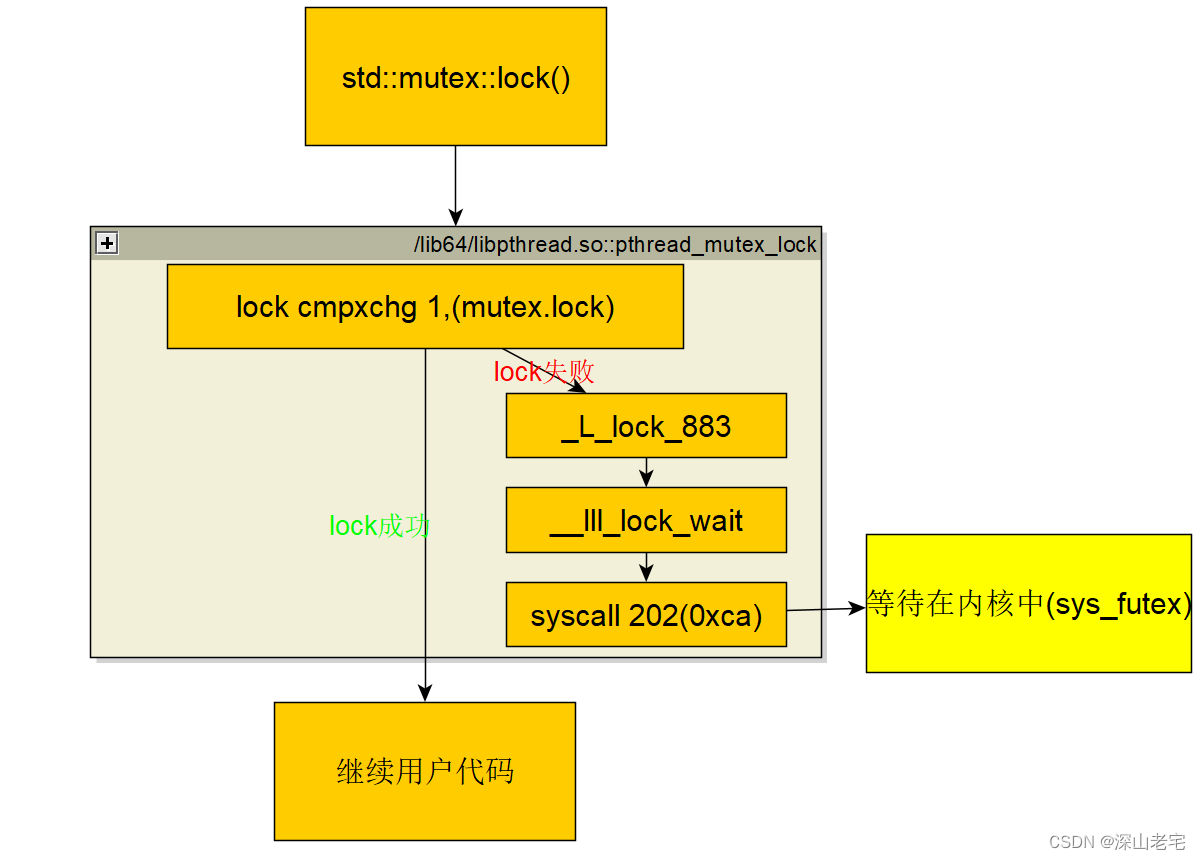
这张图清晰展示了 Linux 下 std::mutex::lock() 的完整调用链路,从 C++ 接口一路到内核态 sys_futex,让我们一步步拆解:
1. 入口:std::mutex::lock()
这是 C++ 标准库提供的上层接口,本身只是一层薄薄的封装,实际逻辑由系统库实现。
- 它会直接调用底层 POSIX 线程库的
pthread_mutex_lock函数(路径:/lib64/libpthread.so)。
2. 第一层:用户态快速路径(lock cmpxchg)
pthread_mutex_lock 首先执行 原子操作 lock cmpxchg 1,(mutex.lock):
lock前缀:在 x86 架构下,保证这条指令是总线原子的,多线程/多核下不会被打断。cmpxchg:Compare-and-Exchange 指令,尝试将mutex.lock状态从 0(未锁)改为 1(已锁)。- 两种结果 :
- lock 成功:直接跳转到「继续用户代码」,全程在用户态完成,无内核开销。
- lock 失败:说明锁已被其他线程占用,进入慢速路径。
3. 第二层:用户态慢速路径(自旋 + 等待准备)
锁失败后,进入 _L_lock_883 和 __lll_lock_wait 函数:
_L_lock_883:通常是 glibc 内部的自旋尝试函数,会在用户态循环检查锁状态,短时间内等待锁释放,避免立刻进入内核。__lll_lock_wait:低层级锁等待函数,负责准备内核等待所需的参数,为进入内核态做准备。
4. 第三层:内核态阻塞(sys_futex)
最终通过 syscall 202(0xca) 进入内核:
202是 Linux 系统中sys_futex的系统调用号(x86_64 架构),0xca是其十六进制表示。- 内核态逻辑:
- 将当前线程加入该 mutex 对应的等待队列。
- 标记线程为睡眠状态,让出 CPU 给其他线程。
- 直到持有锁的线程调用
unlock(),内核才会唤醒该线程,重新竞争锁。
5. 最终:回到用户态
被唤醒后,线程再次尝试 cmpxchg 抢锁,成功后继续执行用户代码。
从C++接口到内核实现
1. 第一层:C++标准库层(std::mutex)
std::mutex 是对底层系统锁的"轻量封装层",仅暴露标准化接口,屏蔽不同系统的实现差异。以下是GCC/libstdc++中 std::mutex 的核心简化实现:
cpp
// GCC libstdc++ 中 std::mutex 核心源码简化
#include <pthread.h>
#include <system_error>
namespace std {
class mutex {
private:
pthread_mutex_t _M_mutex; // 核心:封装POSIX互斥锁
// 禁用拷贝和移动
mutex(const mutex&) = delete;
mutex& operator=(const mutex&) = delete;
public:
// 构造函数:初始化pthread_mutex_t
mutex() noexcept {
int ret = pthread_mutex_init(&_M_mutex, nullptr);
if (ret != 0) {
throw system_error(ret, generic_category(), "mutex init failed");
}
}
// 析构函数:销毁锁
~mutex() noexcept {
pthread_mutex_destroy(&_M_mutex);
}
// 加锁:调用POSIX接口
void lock() {
int ret = pthread_mutex_lock(&_M_mutex);
if (ret != 0) {
throw system_error(ret, generic_category(), "mutex lock failed");
}
}
// 解锁:调用POSIX接口
void unlock() noexcept {
pthread_mutex_unlock(&_M_mutex);
}
// 尝试加锁:非阻塞
bool try_lock() noexcept {
return pthread_mutex_trylock(&_M_mutex) == 0;
}
};
}特点:
- 核心成员是
pthread_mutex_t,所有锁操作最终都转发给POSIX锁接口; - 禁用拷贝/移动,保证锁的唯一性;
- 封装系统调用错误,转换为C++异常(符合C++标准)。
2. 第二层:POSIX层(pthread_mutex_t)
这是 std::mutex 的核心实现层,pthread_mutex_t 基于Linux futex 实现,分为「快速路径」和「慢速路径」,目的是最小化内核态开销。
2.1 快速路径(无冲突,用户态)
当锁未被占用时,pthread_mutex_lock() 直接通过CPU原子指令(如x86的 cmpxchg)修改锁的状态标记,全程在用户态完成,无内核切换开销:
c
// pthread_mutex_t 快速路径简化逻辑
int pthread_mutex_lock(pthread_mutex_t *mutex) {
// 原子检查并设置锁状态:空闲→已占用
if (atomic_cmpxchg(&mutex->status, UNLOCKED, LOCKED) == UNLOCKED) {
return 0; // 加锁成功,用户态完成
}
// 有冲突,进入慢速路径
return __pthread_mutex_lock_slow(mutex);
}2.2 慢速路径(有冲突,自旋+内核态)
当锁已被占用时,不会直接阻塞,而是先做「有限自旋」,再陷入内核态:
- 自旋尝试:循环几次(默认10次左右)检查锁状态,若持有锁的线程快速释放,仍可在用户态获取锁,避免内核切换;
- 内核阻塞 :自旋失败后,调用
futex_wait()系统调用,让当前线程进入内核态的等待队列,释放CPU资源,避免空转。
c
// 慢速路径简化逻辑
int __pthread_mutex_lock_slow(pthread_mutex_t *mutex) {
int spin_count = 0;
// 步骤1:有限自旋(用户态)
while (spin_count++ < 10 && mutex->status == LOCKED) {
// 空转等待,短时间尝试
cpu_relax(); // 提示CPU降低功耗,不忙等
}
// 步骤2:自旋失败,进入内核态
if (mutex->status == LOCKED) {
// 调用futex_wait,线程阻塞,加入等待队列
futex_wait(&mutex->futex, LOCKED, NULL);
}
// 步骤3:被唤醒后,重新竞争锁(可能再次自旋/阻塞)
return pthread_mutex_lock(mutex);
}2.3 解锁逻辑(futex_wake 唤醒等待线程)
解锁时,pthread_mutex_unlock() 先原子修改锁状态,再调用 futex_wake() 唤醒内核等待队列中的线程:
c
int pthread_mutex_unlock(pthread_mutex_t *mutex) {
// 原子设置锁状态:已占用→空闲
atomic_store(&mutex->status, UNLOCKED);
// 唤醒等待队列中的一个线程
futex_wake(&mutex->futex, 1);
return 0;
}3. 第三层:内核层(futex)
futex(Fast Userspace Mutex)是Linux内核提供的同步原语,核心是「按需内核介入」------只有当真正存在线程竞争时,才会触发内核态操作,这也是 std::mutex 高效的关键。
3.1 futex的核心数据结构
内核中的 futex 关联两个核心结构:
- futex_hash:哈希表,映射用户态的futex地址到内核等待队列;
- wait_queue:等待队列,存放阻塞的线程,由内核调度器管理。
3.2 futex_wait() 逻辑
c
// futex_wait 内核简化逻辑
int futex_wait(int *uaddr, int expected, struct timespec *timeout) {
// 检查用户态锁状态是否与预期一致(防止虚假唤醒)
if (*uaddr != expected) {
return -1;
}
// 将当前线程加入等待队列
add_wait_queue(&futex_hash[uaddr], current);
// 标记线程为睡眠状态,释放CPU
set_current_state(TASK_INTERRUPTIBLE);
// 触发内核调度,切换到其他线程
schedule();
return 0;
}3.3 futex_wake() 逻辑
c
// futex_wake 内核简化逻辑
int futex_wake(int *uaddr, int nr_wake) {
// 从等待队列中唤醒nr_wake个线程(通常1个)
wake_up_nr(&futex_hash[uaddr], nr_wake);
return 0;
}std::mutex 完整执行流程(加锁+解锁)
结合以上,我们梳理一次完整的加锁-解锁流程:
- 线程A调用
std::mutex::lock()→ 触发pthread_mutex_lock(); pthread_mutex_lock()原子检查锁状态:空闲→直接标记为已占用(用户态,快速路径);- 线程B调用
std::mutex::lock()→ 锁已被占用,进入自旋(10次); - 自旋结束仍未获取锁 → 调用
futex_wait(),线程B陷入内核态,加入等待队列,阻塞并释放CPU; - 线程A调用
std::mutex::unlock()→ 原子标记锁为空闲,调用futex_wake(); - 内核唤醒线程B → 线程B重新竞争锁(若成功则获取,失败则再次自旋/阻塞)。
四、不同场景下的实现差异
1. 系统差异
| 环境 | 底层依赖 | 核心特征 |
|---|---|---|
| Linux + GCC | pthread_mutex_t → futex | 自旋+内核阻塞,性能均衡 |
| Windows + MSVC | CRITICAL_SECTION | 轻量级用户态锁+内核事件对象 |
| macOS | pthread_mutex_t → mach锁 | 自旋策略更保守,适配mac内核 |
2. 锁类型扩展
C++标准库基于 pthread_mutex_t 封装了不同类型的锁:
std::mutex:非递归、非超时,对应基础pthread_mutex_t;std::recursive_mutex:可重入锁,底层是PTHREAD_MUTEX_RECURSIVE类型的POSIX锁;std::timed_mutex:支持超时,底层调用pthread_mutex_timedlock()。
std::mutex 的性能瓶颈与优化
1. 性能瓶颈
- 内核态切换开销 :一旦陷入
futex_wait(),用户态→内核态切换约消耗几百纳秒,高冲突场景下频繁切换会显著降速; - 线程唤醒延迟:内核唤醒等待线程存在调度延迟,高并发下可能出现"惊群效应";
- 自旋空转:冲突率极高时,自旋会浪费CPU资源。
2. 优化建议
- 读多写少场景 :替换为
std::atomic(乐观锁,基于CAS),避免锁竞争; - 细分锁粒度:将大锁拆分为多个小锁(如按哈希分片),降低冲突概率;
- 避免长临界区:临界区代码越短,锁持有时间越短,自旋成功概率越高;