机器学习18-tensorflow3
- Tensorboard
-
- 一、核心功能与使用流程
-
- [1. 核心功能(新手常用)](#1. 核心功能(新手常用))
- [2. 基础使用流程(3步)](#2. 基础使用流程(3步))
- 二、实战示例(MNIST分类)
-
- [1. 完整代码(带TensorBoard监控)](#1. 完整代码(带TensorBoard监控))
- [2. 启动TensorBoard](#2. 启动TensorBoard)
-
- 方式1:终端启动(推荐)
- [方式2:Jupyter Notebook中启动](#方式2:Jupyter Notebook中启动)
- [3. 关键操作(网页端)](#3. 关键操作(网页端))
- 三、进阶用法(自定义监控)
-
- [1. 监控梯度(调试梯度消失/爆炸)](#1. 监控梯度(调试梯度消失/爆炸))
- [2. 超参数对比(HPARAMS)](#2. 超参数对比(HPARAMS))
- 四、常见问题与解决
-
- [1. TensorBoard无法访问/加载慢](#1. TensorBoard无法访问/加载慢)
- [2. 中文乱码](#2. 中文乱码)
- [3. 只看最新的日志](#3. 只看最新的日志)
- 总结
- 模型保存载入方式
-
- 一、核心保存方式对比(先选对方案)
- 二、方式1:保存完整模型(SavedModel格式,推荐)
-
- TensorFlow中基于ProtoBuf的模型保存与载入详解
- [1. ProtoBuf的作用](#1. ProtoBuf的作用)
- [2. SavedModel的底层结构(ProtoBuf存储)](#2. SavedModel的底层结构(ProtoBuf存储))
- 3、基于ProtoBuf(SavedModel)的保存与载入(核心方式)
-
- [3.1 完整代码示例](#3.1 完整代码示例)
- [3.2 关键说明](#3.2 关键说明)
- [4. 导出纯.pb文件(冻结图,适配旧版部署)](#4. 导出纯.pb文件(冻结图,适配旧版部署))
-
- 4.1代码示例(导出冻结.pb文件)
- [4.2 关键注意事项](#4.2 关键注意事项)
- [5. ProtoBuf方式的优势与适用场景](#5. ProtoBuf方式的优势与适用场景)
- 6、常见问题与解决
-
- [6.1 .pb文件载入后张量名找不到](#6.1 .pb文件载入后张量名找不到)
- [6.2 SavedModel载入报错(ProtoBuf解析失败)](#6.2 SavedModel载入报错(ProtoBuf解析失败))
- [6.3 冻结图时提示"找不到签名"](#6.3 冻结图时提示“找不到签名”)
- 总结
- [1. 核心特点](#1. 核心特点)
- [2. 代码示例](#2. 代码示例)
- [3. 避坑指南](#3. 避坑指南)
- 三、方式2:仅保存/载入权重(H5格式)
-
- [1. 核心特点](#1. 核心特点)
- [2. 代码示例](#2. 代码示例)
- [3. 关键注意事项](#3. 关键注意事项)
- 四、方式3:自定义Checkpoint(断点续训)
-
- [1. 核心特点](#1. 核心特点)
- [2. 代码示例(断点续训)](#2. 代码示例(断点续训))
- [3. 核心优势](#3. 核心优势)
- 五、常见问题与解决方案
-
- [1. 模型载入失败:NotFoundError](#1. 模型载入失败:NotFoundError)
- [2. 载入权重后准确率为随机值](#2. 载入权重后准确率为随机值)
- [3. Windows路径报错(FailedPreconditionError)](#3. Windows路径报错(FailedPreconditionError))
- 总结
Tensorboard
TensorFlow中的TensorBoard详解
TensorBoard是TensorFlow官方配套的可视化工具,核心作用是将模型训练过程中的指标(损失、准确率)、计算图、权重分布、嵌入向量等"可视化",帮助你直观监控训练过程、调试模型、分析性能瓶颈。
简单来说:没有TensorBoard时,你只能看到终端里枯燥的数字;有了TensorBoard,你能看到训练曲线、模型结构、参数变化等可视化图表,快速定位问题(比如过拟合、梯度消失)。
一、核心功能与使用流程
1. 核心功能(新手常用)
| 功能模块 | 作用 |
|---|---|
| Scalars | 监控标量指标(损失、准确率、学习率),看训练/验证曲线变化 |
| Graphs | 可视化模型计算图,检查网络结构是否正确 |
| Histograms | 查看权重/偏置的分布变化,分析参数更新是否正常 |
| Images | 可视化输入/输出图像(如图像分类任务的输入样本、错误预测样本) |
| Projector | 可视化高维嵌入向量(如词向量、图像特征) |
2. 基础使用流程(3步)
- 创建日志目录:指定TensorBoard保存日志的文件夹;
- 添加回调函数 :在模型训练时,用
TensorBoard回调函数记录日志; - 启动TensorBoard:在终端/Notebook中启动,访问网页查看可视化结果。
二、实战示例(MNIST分类)
1. 完整代码(带TensorBoard监控)
python
import tensorflow as tf
import numpy as np
import os
# ===================== 1. 准备数据 =====================
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = x_train / 255.0[..., tf.newaxis] # 归一化+增加通道
x_test = x_test / 255.0[..., tf.newaxis]
# ===================== 2. 配置TensorBoard日志 =====================
# (1)创建日志目录(按时间命名,避免覆盖)
log_dir = os.path.join("logs", "mnist_" + tf.datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
print(f"TensorBoard日志将保存至:{log_dir}")
# (2)定义TensorBoard回调函数
tensorboard_callback = tf.keras.callbacks.TensorBoard(
log_dir=log_dir, # 日志保存路径
histogram_freq=1, # 每1个epoch记录一次权重分布
write_graph=True, # 保存计算图
write_images=True, # 保存模型权重为图像
update_freq="epoch" # 按epoch更新日志(可选"batch"按批次)
)
# ===================== 3. 构建并训练模型 =====================
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
# 训练时加入TensorBoard回调
history = model.fit(
x_train, y_train,
epochs=5,
batch_size=64,
validation_split=0.1,
callbacks=[tensorboard_callback] # 关键:加入回调
)
# ===================== 4. (可选)手动记录自定义指标 =====================
# 除了自动记录的loss/acc,还能手动记录自定义指标(如测试集准确率)
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
# 创建SummaryWriter,手动写入日志
with tf.summary.create_file_writer(log_dir).as_default():
tf.summary.scalar('test_accuracy', test_acc, step=0) # step=0表示训练结束后记录
tf.summary.scalar('test_loss', test_loss, step=0)2. 启动TensorBoard
方式1:终端启动(推荐)
- 打开终端,进入代码所在目录;
- 执行命令:
bash
tensorboard --logdir=logs # logs是日志根目录(包含所有子日志文件夹)- 终端会输出访问地址(默认:
http://localhost:6006/),打开浏览器访问即可。
方式2:Jupyter Notebook中启动
python
# 在Notebook中运行以下代码,自动嵌入TensorBoard
%load_ext tensorboard
%tensorboard --logdir=logs3. 关键操作(网页端)
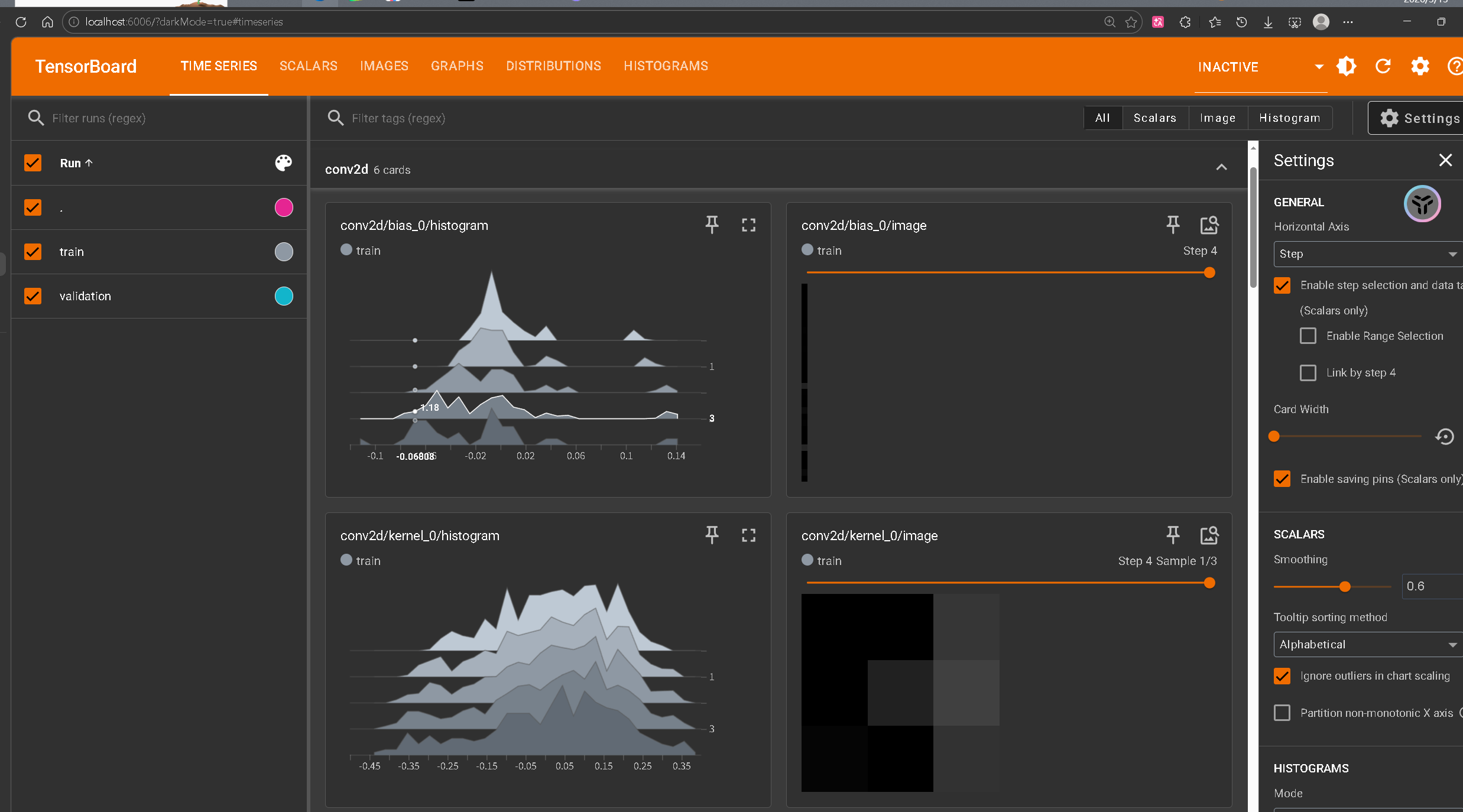
访问http://localhost:6006/后,可查看核心模块:
- Scalars:查看loss、accuracy的训练/验证曲线(重点看是否过拟合:验证集acc下降则过拟合);
- Graphs:查看模型计算图,可展开看每层的输入输出维度;
- Histograms:查看权重/偏置的分布变化(如权重是否梯度消失/爆炸);
- Images:查看输入样本、卷积核可视化结果;
- HPARAMS :(进阶)超参数调优对比(如不同学习率的效果)。
三、进阶用法(自定义监控)
1. 监控梯度(调试梯度消失/爆炸)
python
# 自定义回调函数,记录每一层的梯度
class GradientMonitor(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
with tf.summary.create_file_writer(log_dir).as_default():
for layer in self.model.layers:
if hasattr(layer, 'kernel'): # 只记录有权重的层
weights = layer.get_weights()
if len(weights) > 0:
# 记录权重的均值/标准差
tf.summary.histogram(f"{layer.name}/weights", weights[0], step=epoch)
# 记录梯度(需手动计算)
with tf.GradientTape() as tape:
y_pred = self.model(x_train[:64], training=True)
loss = tf.keras.losses.sparse_categorical_crossentropy(y_train[:64], y_pred)
grads = tape.gradient(loss, layer.kernel)
tf.summary.histogram(f"{layer.name}/gradients", grads, step=epoch)
# 训练时加入该回调
model.fit(..., callbacks=[tensorboard_callback, GradientMonitor()])2. 超参数对比(HPARAMS)
python
# 定义超参数
hparams = {
"learning_rate": 0.001,
"dropout_rate": 0.2,
"batch_size": 64
}
# 记录超参数
with tf.summary.create_file_writer(log_dir).as_default():
tf.summary.hparams(hparams, metrics=[
tf.summary.SummaryMetadata(
display_name="accuracy",
description="Validation accuracy"
)
], step=0)四、常见问题与解决
1. TensorBoard无法访问/加载慢
- 问题:端口被占用 → 解决:指定端口启动:
tensorboard --logdir=logs --port=6007; - 问题:日志为空 → 解决:检查
log_dir是否正确,确保模型训练时回调函数已加入; - 问题:网页加载卡住 → 解决:清空浏览器缓存,或重启TensorBoard(
ctrl+c终止后重新启动)。
2. 中文乱码
- 解决:在TensorBoard网页端→Settings→Font,选择支持中文的字体(如微软雅黑)。
3. 只看最新的日志
bash
# 只加载最新的日志文件夹(避免多个日志叠加)
tensorboard --logdir=logs/mnist_20260312-100000 # 替换为你的最新日志目录总结
- TensorBoard是TensorFlow的可视化工具,核心通过
TensorBoard回调函数记录日志,终端启动后在网页查看; - 新手优先关注Scalars (监控损失/准确率)和Graphs(检查模型结构);
- 关键技巧:
- 日志目录按时间命名,避免覆盖;
histogram_freq=1可监控权重分布,排查梯度问题;- 自定义回调可记录梯度、超参数等进阶指标。
使用TensorBoard能让你从"盲训模型"变为"可视化监控训练",快速发现过拟合、梯度消失等问题,是TensorFlow训练模型的必备工具。
模型保存载入方式
TensorFlow模型保存与载入(加载)全解析
TensorFlow(Keras)提供了3种核心的模型保存/载入方式,分别适配不同场景(完整模型复用、仅权重迁移、自定义模型加载),下面从原理、代码示例到避坑指南全面讲解,帮你彻底掌握模型的保存与载入。
一、核心保存方式对比(先选对方案)
| 保存方式 | 保存内容 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 完整模型(SavedModel) | 结构+权重+编译信息+优化器状态 | 直接复用模型(训练/预测)、部署 | 开箱即用,无需重构模型 | 占用空间稍大 |
| 仅保存权重(H5/Checkpoint) | 仅权重参数 | 迁移权重到新模型、微调模型 | 体积小,灵活 | 需先重构模型结构 |
| 自定义Checkpoint | 任意变量(权重、优化器、训练步数) | 断点续训、保存训练状态 | 高度灵活,支持断点恢复 | 代码稍复杂 |
二、方式1:保存完整模型(SavedModel格式,推荐)
TensorFlow中基于ProtoBuf的模型保存与载入详解
ProtoBuf(Protocol Buffers)是TensorFlow底层的序列化协议 ,也是SavedModel格式的核心存储方式(而非独立的保存方式)。简单来说:TensorFlow的SavedModel格式本质就是用ProtoBuf序列化模型结构、权重、签名等信息,最终以文件形式存储(而非单独的.pb文件)。
下面从ProtoBuf的作用、SavedModel的底层结构、保存/载入实操,到纯.pb文件的导出(适配部署),全面讲解相关内容。
1. ProtoBuf的作用
ProtoBuf是Google的轻量级序列化协议,相比JSON/XML,它:
- 体积更小、解析更快;
- 支持跨语言(Python/C++/Java等);
- TensorFlow用它定义模型结构(GraphDef)、权重(Checkpoint)、签名(SignatureDef)等核心信息。
2. SavedModel的底层结构(ProtoBuf存储)
当你用model.save()保存为SavedModel格式时,生成的文件夹结构如下(核心是ProtoBuf文件):
mnist_full_model/
├── assets/ # 静态资源(如词汇表)
├── variables/ # 权重变量(.data-00000-of-00001 + .index)
│ ├── variables.data-00000-of-00001 # 权重值(二进制)
│ └── variables.index # 权重索引(ProtoBuf格式)
└── saved_model.pb # 核心:模型结构+签名(ProtoBuf序列化的GraphDef)saved_model.pb:用ProtoBuf序列化的SavedModel协议消息,包含计算图结构、输入输出签名、设备信息等;variables/:权重参数(底层也是ProtoBuf序列化的Variable信息)。
3、基于ProtoBuf(SavedModel)的保存与载入(核心方式)
这是TensorFlow官方推荐的方式,底层完全基于ProtoBuf,兼容所有场景(训练/预测/部署)。
3.1 完整代码示例
python
import tensorflow as tf
import os
# ===================== 1. 训练基础模型 =====================
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = x_train / 255.0[..., tf.newaxis] # 归一化+通道维度
# 构建简单CNN模型
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
model.fit(x_train, y_train, epochs=1, batch_size=64, verbose=0)
# ===================== 2. 保存为ProtoBuf格式的SavedModel =====================
# 保存路径(文件夹,SavedModel是目录结构)
save_dir = os.path.join(os.getcwd(), "mnist_savedmodel_protobuf")
# 核心:保存为SavedModel(底层自动用ProtoBuf序列化)
model.save(save_dir, save_format='tf') # 'tf'即基于ProtoBuf的SavedModel格式
print(f"模型已保存为ProtoBuf格式(SavedModel):{save_dir}")
print(f"核心ProtoBuf文件:{os.path.join(save_dir, 'saved_model.pb')}")
# ===================== 3. 载入ProtoBuf格式的模型 =====================
# 方式1:Keras接口(推荐,简单)
loaded_model = tf.keras.models.load_model(save_dir)
# 验证载入效果
test_loss, test_acc = loaded_model.evaluate(x_test/255.0[..., tf.newaxis], y_test, verbose=0)
print(f"\nKeras载入模型准确率:{test_acc:.4f}")
# 方式2:TensorFlow原生接口(适配部署,纯ProtoBuf解析)
loaded_saved_model = tf.saved_model.load(save_dir)
# 获取预测签名(默认签名:serving_default)
infer = loaded_saved_model.signatures["serving_default"]
# 用原生接口预测(输入需为Tensor)
sample = tf.convert_to_tensor(x_test[0:1]/255.0[..., tf.newaxis])
pred = infer(sample)
# 解析预测结果(key为模型输出层名称,如dense_1)
pred_label = tf.argmax(pred[list(pred.keys())[0]], axis=1).numpy()[0]
print(f"\n原生ProtoBuf接口预测结果:{pred_label},真实标签:{y_test[0]}")3.2 关键说明
save_format='tf':显式指定保存为基于ProtoBuf的SavedModel格式(默认就是此格式);saved_model.pb:是唯一的核心ProtoBuf文件,包含模型的完整计算图;- 原生接口
tf.saved_model.load():直接解析ProtoBuf文件,返回SavedModel对象,适合部署场景(如TensorFlow Serving、TFLite转换)。
4. 导出纯.pb文件(冻结图,适配旧版部署)
在TensorFlow 1.x中常提到"导出.pb文件"(冻结图),本质是将计算图+权重合并为单个ProtoBuf文件(.pb),TensorFlow 2.x中可通过以下方式实现(适配旧版部署场景):
4.1代码示例(导出冻结.pb文件)
python
import tensorflow as tf
from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
# ===================== 1. 训练/加载模型 =====================
model = tf.keras.models.load_model("mnist_savedmodel_protobuf") # 加载已保存的模型
# ===================== 2. 将模型转为静态计算图(ProtoBuf) =====================
# (1)获取模型的函数式签名
input_signature = [tf.TensorSpec(model.inputs[0].shape, model.inputs[0].dtype, name='input')]
concrete_func = model.signatures['serving_default'] # 获取默认签名
# 或自定义签名:
# concrete_func = tf.function(lambda x: model(x)).get_concrete_function(input_signature)
# (2)冻结图(将变量转为常量,合并到计算图中)
frozen_func = convert_variables_to_constants_v2(concrete_func)
frozen_graph = frozen_func.graph.as_graph_def()
# ===================== 3. 保存为纯.pb文件 =====================
pb_file_path = os.path.join(os.getcwd(), "mnist_frozen_model.pb")
with tf.io.gfile.GFile(pb_file_path, "wb") as f:
f.write(frozen_graph.SerializeToString()) # 序列化ProtoBuf并保存
print(f"纯ProtoBuf格式.pb文件已保存至:{pb_file_path}")
# ===================== 4. 载入.pb文件并使用 =====================
def load_frozen_pb(pb_path):
# 读取.pb文件
with tf.io.gfile.GFile(pb_path, "rb") as f:
graph_def = tf.compat.v1.GraphDef()
graph_def.ParseFromString(f.read()) # 解析ProtoBuf
# 导入计算图
with tf.Graph().as_default() as graph:
tf.import_graph_def(graph_def, name="")
# 获取输入/输出张量
input_tensor = graph.get_tensor_by_name("input:0") # 输入张量名
output_tensor = graph.get_tensor_by_name(f"{model.outputs[0].name}:0") # 输出张量名
# 创建会话执行预测(TensorFlow 2.x兼容模式)
with tf.compat.v1.Session(graph=graph) as sess:
def predict(x):
return sess.run(output_tensor, feed_dict={input_tensor: x})
return predict
# 载入.pb文件并预测
predict_fn = load_frozen_pb(pb_file_path)
sample = x_test[0:1]/255.0[..., tf.newaxis]
pred = predict_fn(sample)
pred_label = tf.argmax(pred, axis=1).numpy()[0]
print(f"\n冻结.pb文件预测结果:{pred_label},真实标签:{y_test[0]}")4.2 关键注意事项
-
冻结图的适用场景:仅用于部署(如嵌入式设备、旧版TensorFlow服务),不支持继续训练;
-
张量名获取 :载入.pb文件前需知道输入/输出张量的名称,可通过以下方式查看:
python# 打印.pb文件中的所有张量名 for node in frozen_graph.node: print(f"张量名:{node.name},操作:{node.op}") -
TensorFlow 2.x兼容 :冻结图依赖
tf.compat.v1接口,是为了兼容旧版部署,新场景优先用SavedModel格式。
5. ProtoBuf方式的优势与适用场景
| 方式 | 优势 | 适用场景 |
|---|---|---|
| SavedModel(ProtoBuf) | 完整保存模型、支持继续训练、跨语言部署 | 绝大多数场景(训练后复用、TensorFlow Serving/TFLite) |
| 冻结.pb文件 | 单文件、体积小、适配旧版部署 | 嵌入式设备、旧版TensorFlow环境、轻量部署 |
6、常见问题与解决
6.1 .pb文件载入后张量名找不到
- 原因:输入/输出张量名错误;
- 解决:打印
frozen_graph.node查看所有张量名,确认输入张量名(如conv2d_input:0)和输出张量名(如dense_1/Softmax:0)。
6.2 SavedModel载入报错(ProtoBuf解析失败)
- 原因:模型保存时版本不兼容、文件损坏、自定义层未指定;
- 解决:
-
确保保存和载入的TensorFlow版本一致;
-
含自定义层/损失时,载入需指定
custom_objects:pythonloaded_model = tf.keras.models.load_model(save_dir, custom_objects={"CustomLayer": CustomLayer}) -
重新保存模型(排除文件损坏)。
-
6.3 冻结图时提示"找不到签名"
- 原因:模型未生成默认签名;
- 解决:先调用
model.save()保存为SavedModel,再加载后冻结,或手动定义tf.function签名。
总结
- ProtoBuf是TensorFlow模型保存的底层序列化协议 ,SavedModel格式的核心文件(
saved_model.pb)就是ProtoBuf序列化结果; - 日常使用优先选
model.save()保存为SavedModel(ProtoBuf格式),开箱即用且支持所有场景; - 纯.pb冻结文件仅用于旧版部署,TensorFlow 2.x中不推荐日常使用;
- 核心技巧:
- SavedModel载入用
tf.keras.models.load_model()(Keras接口)或tf.saved_model.load()(原生部署接口); - 冻结.pb文件需先转为静态图,再序列化保存,载入时需指定输入/输出张量名。
- SavedModel载入用
1. 核心特点
- 保存模型结构、权重、编译信息(优化器、损失函数)、甚至训练状态;
- 载入后可直接
predict()/fit(),无需重新编译; - TensorFlow默认格式,支持部署(TensorFlow Serving/TFLite)。
2. 代码示例
python
import tensorflow as tf
import os
# ===================== 1. 训练简单模型 =====================
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = (x_train / 255.0)[..., tf.newaxis]
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
model.fit(x_train, y_train, epochs=1, batch_size=64, verbose=0)
# ===================== 2. 保存完整模型 =====================
# 定义保存路径(文件夹形式,SavedModel是目录结构)
save_dir = "E:/models/mnist_full_model"
# 方案A:基础保存
model.save(save_dir) # 默认保存为SavedModel格式
print(f"完整模型已保存至:{save_dir}")
# 方案B:指定格式(兼容旧版本)
# model.save(save_dir, save_format='tf') # 显式指定TF格式
# model.save("mnist_full_model.h5", save_format='h5') # 保存为H5单文件
# ===================== 3. 载入完整模型 =====================
# 直接载入,无需重构模型
loaded_model = tf.keras.models.load_model(save_dir)
# 载入后可直接使用(预测/评估/继续训练)
test_loss, test_acc = loaded_model.evaluate((x_test/255.0)[..., tf.newaxis], y_test, verbose=0)
print(f"载入后模型测试准确率:{test_acc:.4f}")
# 继续训练(无需重新编译)
loaded_model.fit(x_train, y_train, epochs=1, batch_size=64, verbose=0)
# 继续训练后可直接使用(预测/评估/继续训练)
test_loss2, test_acc2 = loaded_model.evaluate((x_test/255.0)[..., tf.newaxis], y_test, verbose=0)
print(f"继续训练后模型测试准确率:{test_acc2:.4f}")3. 避坑指南
-
路径问题 :Windows路径避免含中文/特殊字符(如冒号、空格),推荐用
os.getcwd()/os.path.expanduser("~"); -
自定义层/损失函数 :若模型含自定义层/损失,载入时需指定
custom_objects:python# 示例:载入含自定义损失的模型 def custom_loss(y_true, y_pred): return tf.keras.losses.sparse_categorical_crossentropy(y_true, y_pred) loaded_model = tf.keras.models.load_model( save_dir, custom_objects={"custom_loss": custom_loss} # 指定自定义对象 )
三、方式2:仅保存/载入权重(H5格式)
1. 核心特点
- 只保存权重参数(
.h5文件),不保存模型结构/编译信息; - 需先重构和原模型完全一致的结构,再载入权重;
- 适合:迁移学习、微调模型、节省存储空间。
2. 代码示例
python
import tensorflow as tf
# ===================== 1. 训练简单模型 =====================
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = (x_train / 255.0)[..., tf.newaxis]
# ===================== 1. 训练模型并保存权重 =====================
# (1)训练基础模型
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=1, batch_size=64, verbose=0)
# (2)保存权重(H5格式)
weight_path = "E:/models/mnist_weights.h5"
model.save_weights(weight_path)
print(f"权重已保存至:{weight_path}")
# ===================== 2. 载入权重(关键:重构相同结构) =====================
# (1)重构和原模型完全一致的结构(层数量、参数、输入形状必须一致)
new_model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28,28)), # 和原模型一致
tf.keras.layers.Dense(128, activation='relu'), # 和原模型一致
tf.keras.layers.Dense(10, activation='softmax')# 和原模型一致
])
# (2)编译模型(载入权重前/后编译均可)
new_model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# (3)载入权重
new_model.load_weights(weight_path)
# (4)验证效果
test_loss, test_acc = new_model.evaluate(x_test/255.0, y_test, verbose=0)
print(f"载入权重后模型准确率:{test_acc:.4f}")3. 关键注意事项
-
模型结构必须完全匹配:层的数量、类型、输入输出形状、神经元数量必须和保存权重时一致,否则载入失败;
-
编译时机 :载入权重前无需编译,但使用
fit()/evaluate()前必须编译; -
迁移学习场景 :可载入部分权重(冻结底层,训练顶层):
python# 示例:迁移学习(载入权重后冻结前几层) new_model.load_weights(weight_path) # 冻结前1层 for layer in new_model.layers[:1]: layer.trainable = False # 重新编译(必须重新编译,否则冻结不生效) new_model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
四、方式3:自定义Checkpoint(断点续训)
1. 核心特点
- 基于
tf.train.Checkpoint,可保存任意变量(权重、优化器、训练步数、甚至自定义参数); - 适合:长时间训练的模型(断点续训)、保存训练状态;
- 最灵活,是TensorFlow原生的保存方式。
2. 代码示例(断点续训)
python
import tensorflow as tf
import os
# ===================== 1. 训练简单模型 =====================
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = (x_train / 255.0)[..., tf.newaxis]
# ===================== 1. 定义模型和优化器 =====================
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
optimizer = tf.keras.optimizers.Adam()
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy()
# ===================== 新增:编译模型 =====================
model.compile(
optimizer=optimizer,
loss=loss_fn,
metrics=['accuracy']
)
# ===================== 2. 定义Checkpoint =====================
# 保存模型、优化器、训练步数
checkpoint_dir = "E:/models/mnist_checkpoints"
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(
step=tf.Variable(0), # 训练步数
optimizer=optimizer, # 优化器(保存学习率等状态)
model=model # 模型权重
)
# 定义Checkpoint管理器(自动保存最新N个检查点)
manager = tf.train.CheckpointManager(
checkpoint, checkpoint_dir, max_to_keep=3 # 最多保存3个检查点
)
# ===================== 3. 自定义训练循环(支持断点续训) =====================
# (1)恢复最新检查点(如果有)
if manager.latest_checkpoint:
checkpoint.restore(manager.latest_checkpoint)
print(f"已恢复检查点:{manager.latest_checkpoint},当前步数:{checkpoint.step.numpy()}")
# (2)训练循环
epochs = 2
batch_size = 64
train_dataset = tf.data.Dataset.from_tensor_slices((x_train / 255.0, y_train)).batch(batch_size)
for epoch in range(epochs):
for x_batch, y_batch in train_dataset:
with tf.GradientTape() as tape:
y_pred = model(x_batch, training=True)
loss = loss_fn(y_batch, y_pred)
# 计算梯度并更新
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# 更新步数
checkpoint.step.assign_add(1)
# 每个epoch保存一次检查点
save_path = manager.save()
print(f"Epoch {epoch + 1},保存检查点至:{save_path}")
# ===================== 4. 验证恢复后的模型 =====================
test_loss, test_acc = model.evaluate(x_test / 255.0, y_test, verbose=0)
print(f"断点续训后模型准确率:{test_acc:.4f}")3. 核心优势
- 断点续训:即使训练中断,恢复后可从上次的步数、优化器状态继续训练(学习率衰减等状态不丢失);
- 灵活保存:可自定义保存的变量(如训练步数、验证集最好准确率);
- 版本管理 :
CheckpointManager可自动保留最新N个检查点,避免磁盘占满。
五、常见问题与解决方案
1. 模型载入失败:NotFoundError
- 原因:路径错误/模型文件损坏/自定义对象未指定;
- 解决:
- 检查路径是否正确(用
os.path.exists(save_dir)验证); - 自定义层/损失需在
load_model中指定custom_objects; - 重新训练并保存模型(排除文件损坏)。
- 检查路径是否正确(用
2. 载入权重后准确率为随机值
- 原因:模型结构和保存权重时不一致;
- 解决:逐行核对模型结构(输入形状、层类型、神经元数量),确保完全匹配。
3. Windows路径报错(FailedPreconditionError)
- 原因:路径含中文/特殊字符/过长;
- 解决:改用纯英文短路径(如
os.path.expanduser("~") + "/mnist_model")。
总结
- 优先选SavedModel格式:完整保存模型,开箱即用,适合直接复用/部署;
- 仅权重保存:适合迁移学习、微调模型,需先重构相同结构的模型;
- Checkpoint :适合断点续训,可保存训练状态(权重+优化器+步数);
4. 核心避坑点:- 路径避免中文/特殊字符;
- 载入权重需保证模型结构一致;
- 自定义层/损失需指定
custom_objects。
根据你的场景选择对应方式:快速复用选SavedModel,迁移学习选权重保存,长时间训练选Checkpoint。