****论文题目:****Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering(基于快速局域谱滤波的卷积神经网络)
会议:NIPS2016
****摘要:****在这项工作中,我们感兴趣的是将卷积神经网络(cnn)从表示图像、视频和语音的低维规则网格推广到高维不规则域,如社交网络、大脑连接体或单词嵌入,由图表示。本文提出了一种基于谱图理论的卷积神经网络公式,为在图上设计快速局部卷积滤波器提供了必要的数学背景和有效的数值方案。重要的是,该技术提供了与经典cnn相同的线性计算复杂度和恒定的学习复杂度,同时对任何图结构都是通用的。在MNIST和20NEWS上的实验证明了这种新颖的深度学习系统在图上学习局部、静止和组合特征的能力。
论图上的快速局部化谱滤波------从傅里叶到切比雪夫的优雅转变
引言:CNN能处理非规则数据吗?
卷积神经网络(CNN)在图像、视频、语音识别上取得了巨大成功。但这些数据都有一个共同特点:它们定义在规则网格上。然而现实中大量数据是非规则的:
- 社交网络的用户关系
- 分子结构
- 3D点云
- 文本的词共现图
能否将CNN的强大能力扩展到这些非规则图结构数据上?这正是这篇NIPS 2016论文要解决的核心问题。
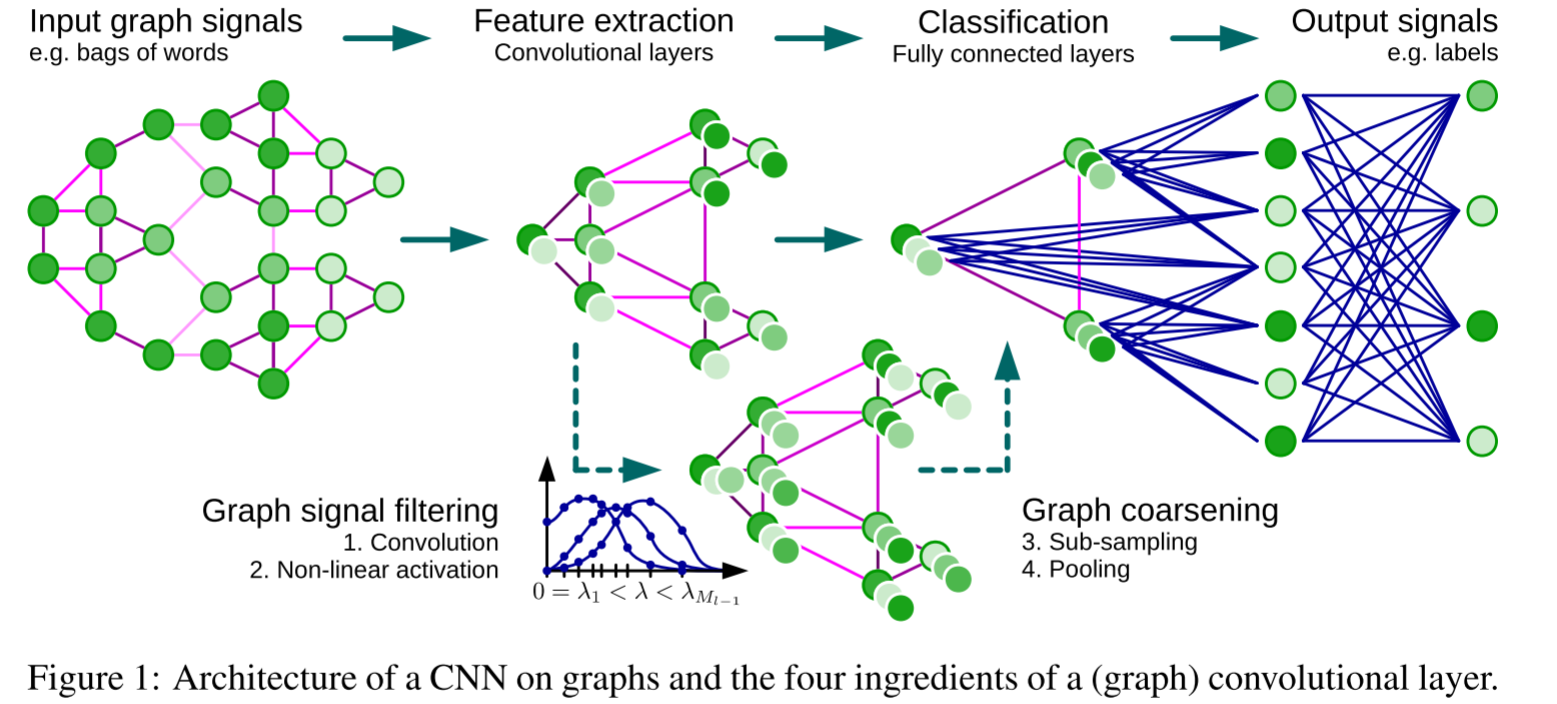
为什么图上的卷积很难?
空间视角的困境
在图像上,卷积很直观:一个5×5的卷积核在图像上滑动,局部性和平移不变性天然满足。但在图上:
- 节点的邻居数量不固定(度不一致)
- 没有明确的"上下左右"方向
- 如何定义"平移"?
虽然可以定义spatial graph convolution,但邻域匹配是个挑战。
谱方法的代价
图信号处理(GSP)提供了优雅的谱方法:通过图拉普拉斯的特征分解定义图傅里叶变换:
x̂ = U^T x (正变换)
x = U x̂ (逆变换)卷积在谱域变成简单的乘法:
y = g_θ(L)x = U g_θ(Λ) U^T x但这有三大问题:
- 计算昂贵:与U相乘需要O(n²)操作
- 存储昂贵:U是n×n的稠密矩阵
- EVD昂贵:计算U需要特征值分解
对于百万节点的图,这些都是不可接受的。
核心创新:切比雪夫多项式的妙用
为什么需要多项式参数化?
非参数滤波器g_θ(Λ) = diag(θ)有两个问题:
- 不局部化:频域滤波器不保证空间局部性
- 参数太多:需要O(n)个参数
多项式参数化g_θ(Λ) = Σ θ_k Λ^k 解决了这两个问题:
- 局部性:K阶多项式严格K-局部化(by Lemma 5.2 from Hammond et al.)
- 参数少:只需K个参数
但还有计算问题:即使是多项式,y = U g_θ(Λ) U^T x 仍需要与U相乘!
切比雪夫递归:避开傅里叶基
切比雪夫多项式T_k(x)有美妙的递归性质:
T_k(x) = 2x T_{k-1}(x) - T_{k-2}(x)
T_0(x) = 1, T_1(x) = x利用这个性质,我们可以递归计算:
x̄_k = T_k(L̃)x = 2L̃ x̄_{k-1} - x̄_{k-2}其中L̃ = 2L/λ_max - I是归一化拉普拉斯(特征值在-1,1)。
最终滤波输出:
y = Σ θ_k x̄_k关键点:
- 只需与稀疏矩阵L̃相乘K次
- 复杂度O(K|E|),对于稀疏图|E| = O(n),是线性的!
- 完全避开了傅里叶基U
- 不需要特征值分解
局部性的严格证明
引理(Hammond et al. 2012 Lemma 5.2): 如果d_G(i,j) > K(i到j的最短路径>K),则(L^K)_{i,j} = 0
推论:K阶切比雪夫滤波器的感受野恰好是K跳邻域!
这种严格的局部性保证是切比雪夫参数化的巨大优势。
图粗化:构建图的"金字塔"
CNN的成功离开不了池化,它降低分辨率同时增加感受野。图上的池化需要图粗化(coarsening)。
Graclus算法
论文选用Graclus------一个多层图聚类算法:
- 贪心匹配:在每层,选择未标记节点i,找邻居j使normalized cut W_{ij}(1/d_i + 1/d_j)最大
- 节点合并:匹配的(i,j)合并为粗化图的一个节点
- 递归粗化:重复直到达到目标尺寸
优点:
- 每层规模约减半
- 最小化normalized cut,保留图结构
- 计算高效
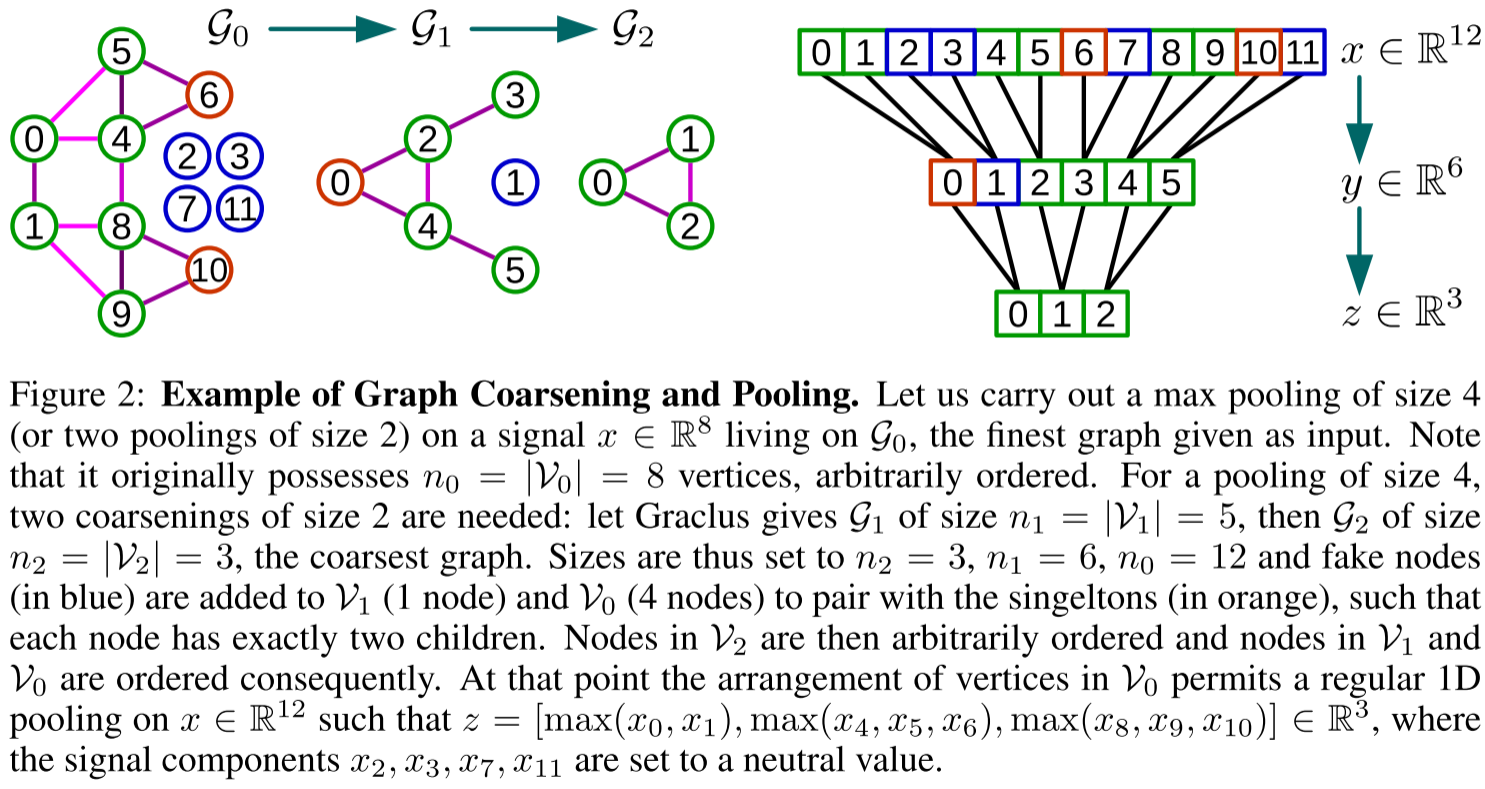
快速池化:从无序到有序
粗化后的节点排列是无序的,直接池化需要查找表,效率低且难以并行。论文提出了巧妙的解决方案:
二叉树重排
-
构建平衡二叉树:
- Graclus可能产生singleton(未匹配的节点)
- 添加fake nodes使每个节点恰好有两个子节点
- fake nodes的信号值设为中性值(如0)
-
层次编号:
- 在最粗层任意排序节点
- 传播到细层:节点k的子节点编号为2k和2k+1
-
结果:最细层的节点排列变得"规则"------相邻节点在层次上相关
现在池化就像1D信号池化一样简单:
z = [max(x[0], x[1]), max(x[2], x[3]), ...]此处配Figure 2的详细解释
完整架构
一个图卷积层包含:
y_{s,j} = Σ g_{θ_{i,j}}(L) x_{s,i}- F_in个输入特征图
- F_out个输出特征图
- 每对(i,j)有K个切比雪夫系数θ_{i,j}
然后接ReLU激活和池化。
超参数:
- K=25(MNIST)
- K=5(20NEWS)
- 对于k-NN图,k不敏感(实验中k=8)
实验结果与分析
MNIST:逼近经典CNN

- 差距仅0.19%!
这是重要的sanity check:证明图CNN在规则网格(也是图的特例)上能恢复经典CNN的性能。
性能微小差距可能源于:
- 图滤波器是各向同性的(没有方向性)
- 架构设计经验较少
- 可能需要更好的初始化策略
图构建:MNIST构建8-NN图,权重:
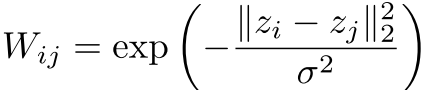
其中zi是像素i的2D坐标。
20NEWS:文本分类
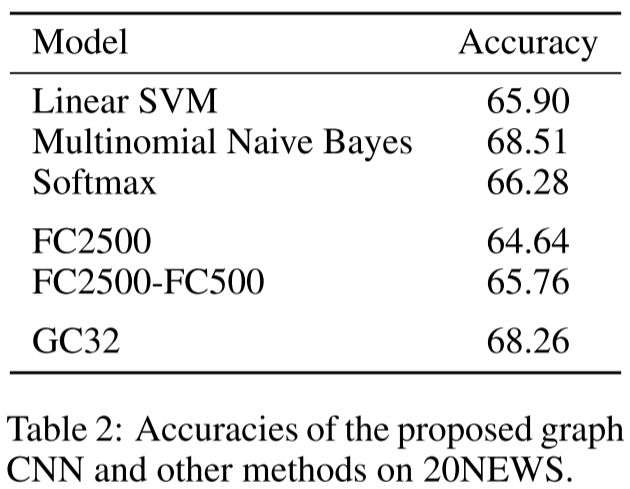
- DGI方法: 68.26%
- Multinomial Naive Bayes: 68.51%
- Linear SVM: 65.90%
- FC2500: 64.64%
图CNN表现不错,虽未超过朴素贝叶斯,但优于全连接网络(需要更多参数)。
图构建:
- 10,000个最常见单词
- 16-NN图,基于word2vec嵌入
这展示了图CNN在非结构化数据(文本)上的潜力。
滤波器对比
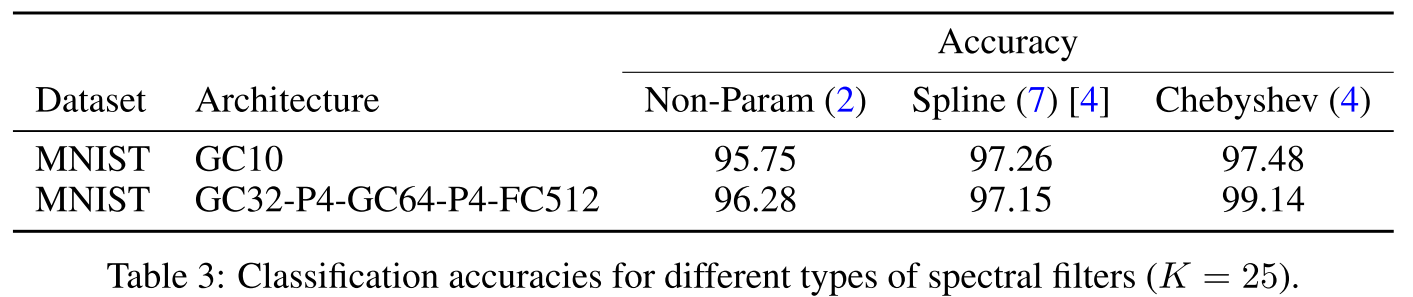
切比雪夫明显最优!原因:
- 严格K-局部化
- 参数数量适中(K个)
- 计算高效
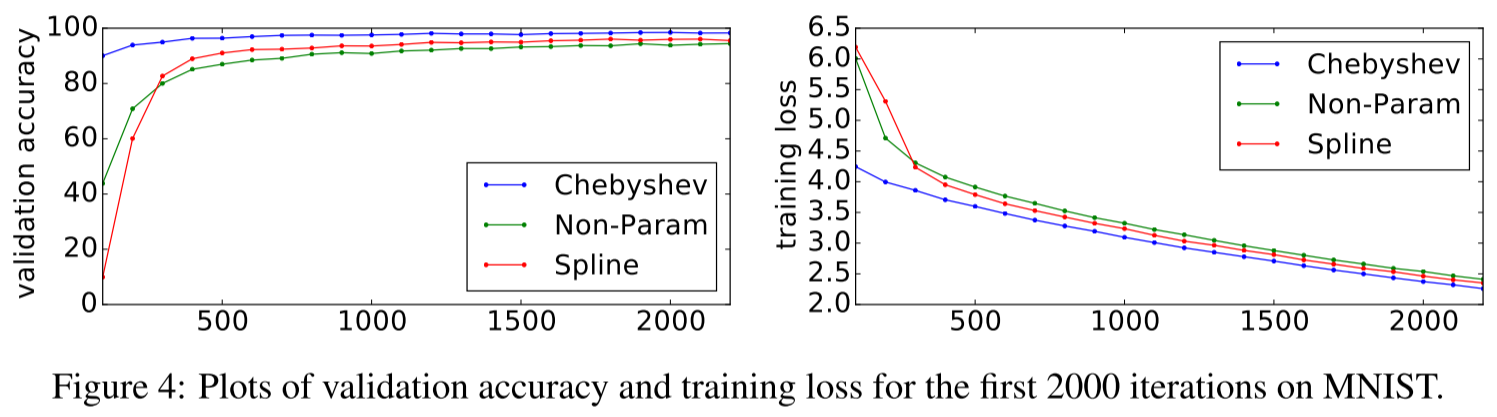
从收敛曲线看,Chebyshev不仅最终准确率高,收敛也更快更稳定。
计算效率
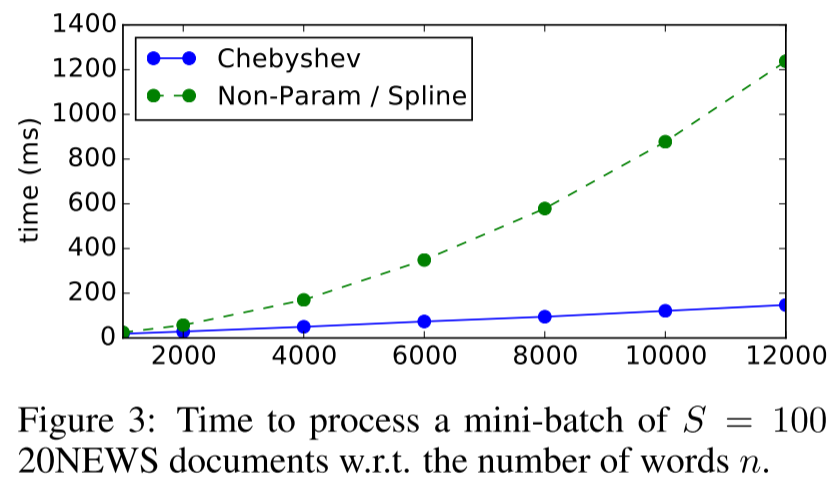
处理100个20NEWS文档的时间(ms):
- n=2000: Chebyshev ~100ms, Spline ~400ms
- n=12000: Chebyshev ~200ms, Spline ~1300ms
复杂度分析:
- Chebyshev: O(K|E|F_in F_out S) ≈ O(Kn) for sparse graphs
- Spline: O(n² F_in F_out S)
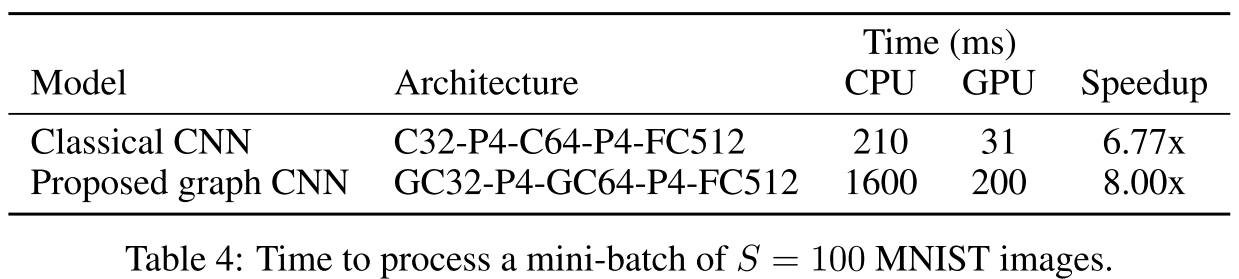
- 经典CNN: 6.77x加速
- 图CNN: 8.00x加速
两者相当,说明图CNN的矩阵运算同样适合GPU并行化。
图质量的影响
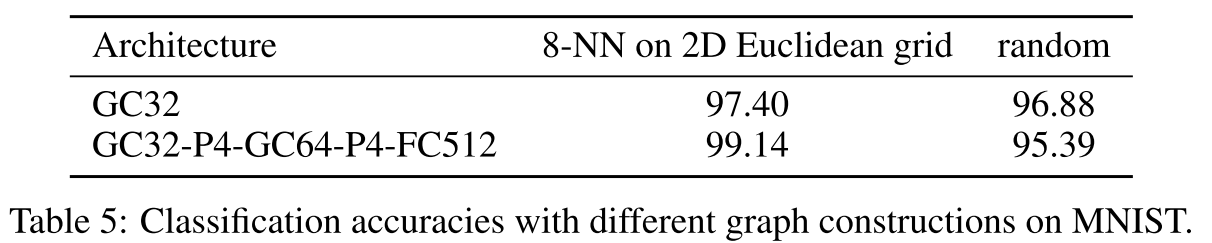

MNIST上:
- 8-NN on 2D grid: 99.14%
- Random graph: 95.39% ⬇3.75%
20NEWS上:
- word2vec learned: 68.26%
- bag-of-words: 67.50%
- random: 67.75%
结论:图的质量至关重要!好的图应该满足:
- 局部性:相似节点相连
- 平稳性:局部结构相似
- 组合性:支持层次化特征
与相关工作的对比
| 方法 | 空间/谱 | 复杂度 | 局部性 | 参数量 |
|---|---|---|---|---|
| Bruna et al. 2013 | 谱 | O(n²) | 非严格 | K |
| 本文 Chebyshev | 谱 | O(Kn) | 严格K跳 | K |
| Spatial GCN | 空间 | O(Kn) | K跳 | 不共享 |
| GraphSAGE | 空间 | O(Kn) | K跳 | 共享 |
本文首次实现了"谱方法+线性复杂度+严格局部化"三者结合。
实现细节
优化器:
- MNIST: SGD, lr=0.03, decay=0.95, momentum=0.9
- 20NEWS: Adam, lr=0.001
正则化:
- Dropout: 0.5
- L2 weight: 5e-4
Early stopping: patience=20 epochs
初始化: Glorot initialization
局限与未来方向
当前局限
- 各向同性:谱方法无法学习方向性特征(如水平vs垂直边缘)
- 图构造依赖:需要预先定义好的图,对图质量敏感
- 大图内存:虽然计算线性,但Laplacian矩阵仍需存储
- 动态图:当前仅处理静态图
未来方向
- 自适应图学习:联合学习图结构和CNN参数(Henaff et al. 2015开始探索)
- 动态图扩展:处理时变图
- 更高效pooling:探索DiffPool等可学习pooling
- 理论分析:图CNN的表示能力、泛化界等
核心贡献总结
✅ 理论优雅 :谱图理论+切比雪夫多项式的完美结合 ✅ 严格局部化 :K阶滤波器→K跳感受野,可证明 ✅ 计算高效 :O(K|E|)线性复杂度,避开EVD和傅里叶基 ✅ 实现简洁 :递归计算,GPU友好 ✅ 实验验证 :MNIST和20NEWS上的竞争性能 ✅ 通用框架:为后续spatial和spectral方法奠定基础
对后续工作的影响
这篇论文开创性地解决了图CNN的计算效率问题,直接影响了:
- GCN (Kipf & Welling 2017): 简化为K=1的特例
- GraphSAGE: 借鉴了采样和聚合思想
- GAT: 在类似框架下引入注意力
- ChebNet的工业应用: 被Pinterest等公司用于推荐系统
它证明了谱方法不仅理论优雅,也能实现工程高效,为图深度学习的发展铺平了道路。