第一节 索引概述
第二节 索引结构
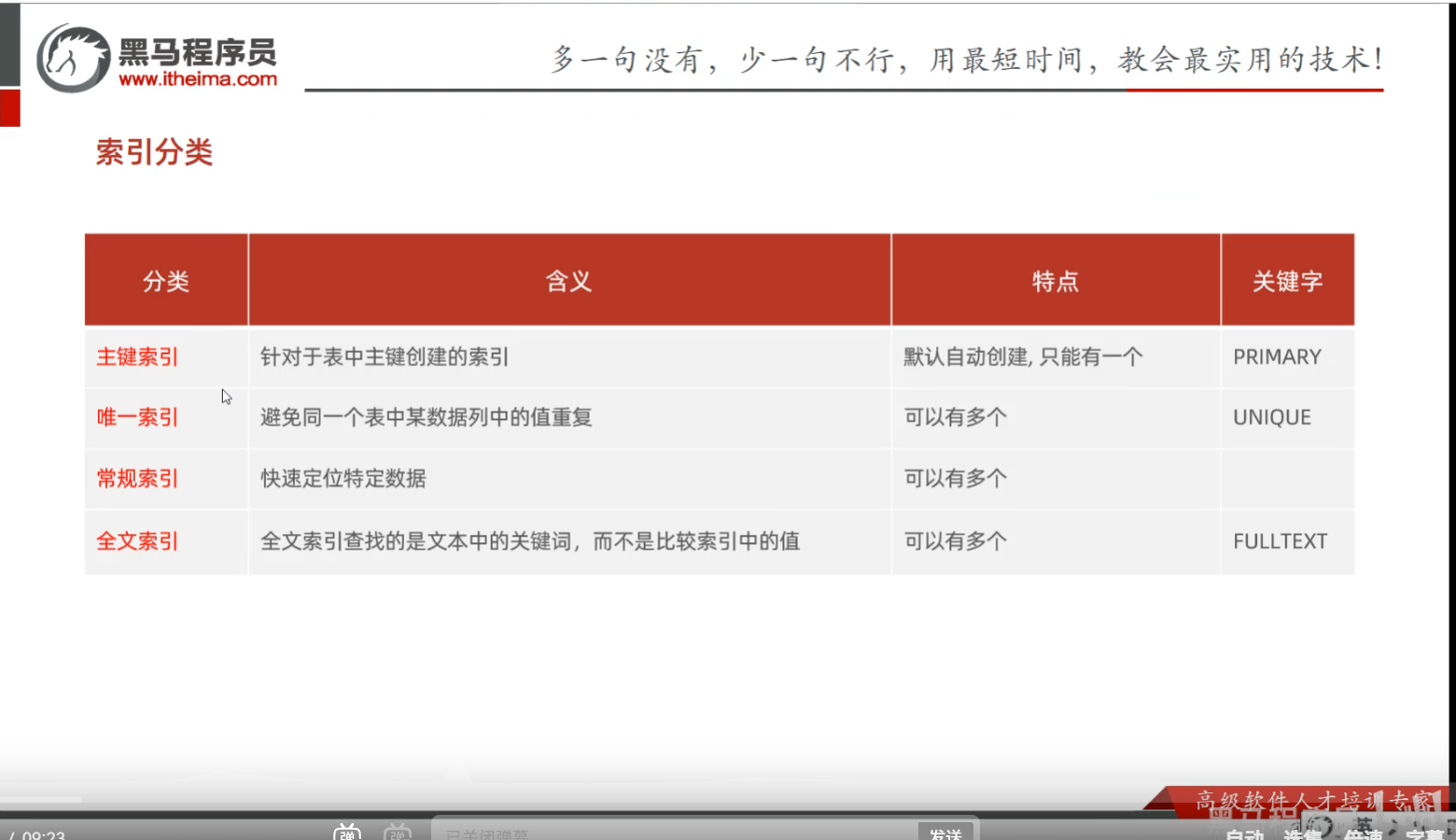
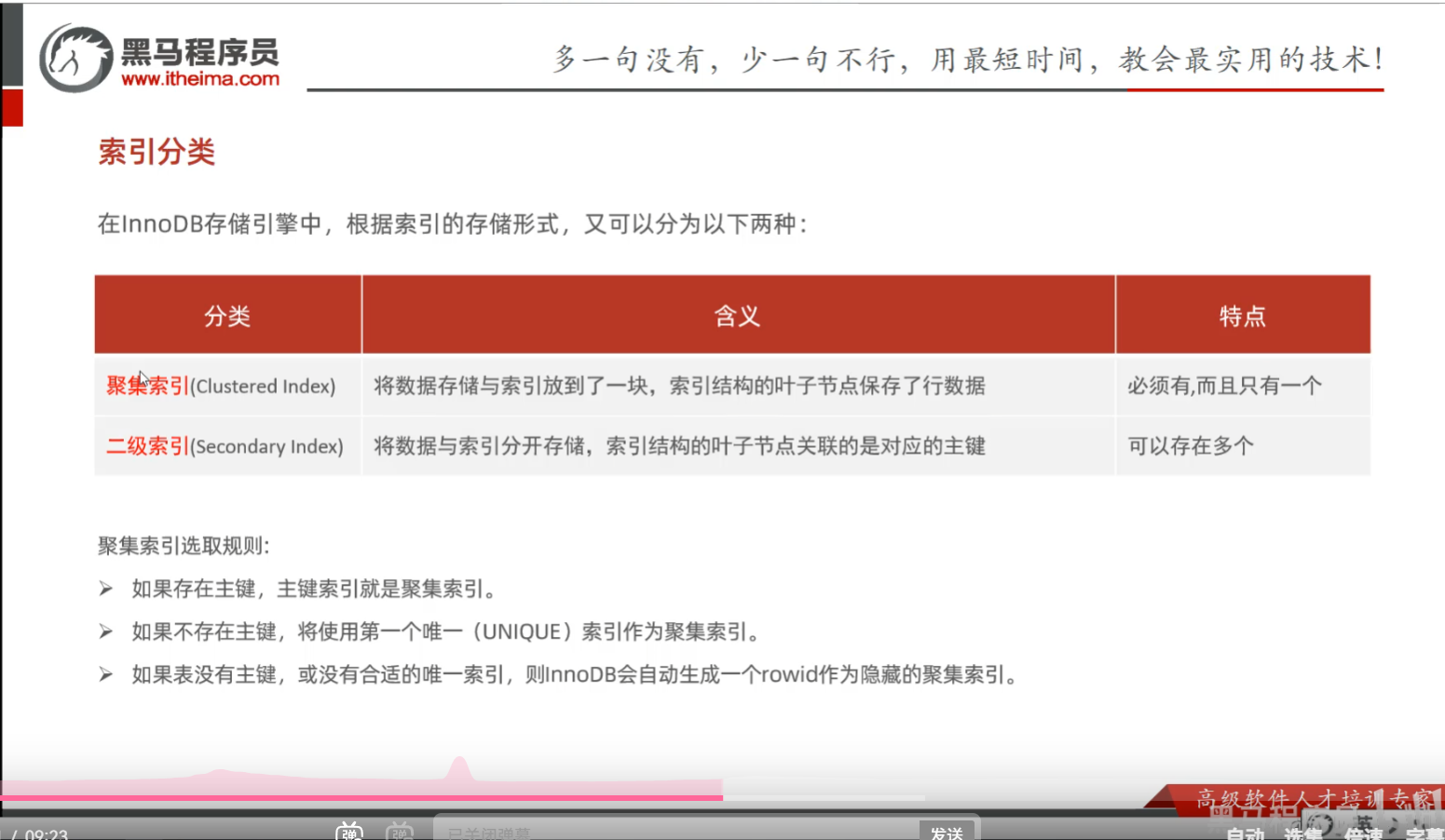
第三节 索引分类
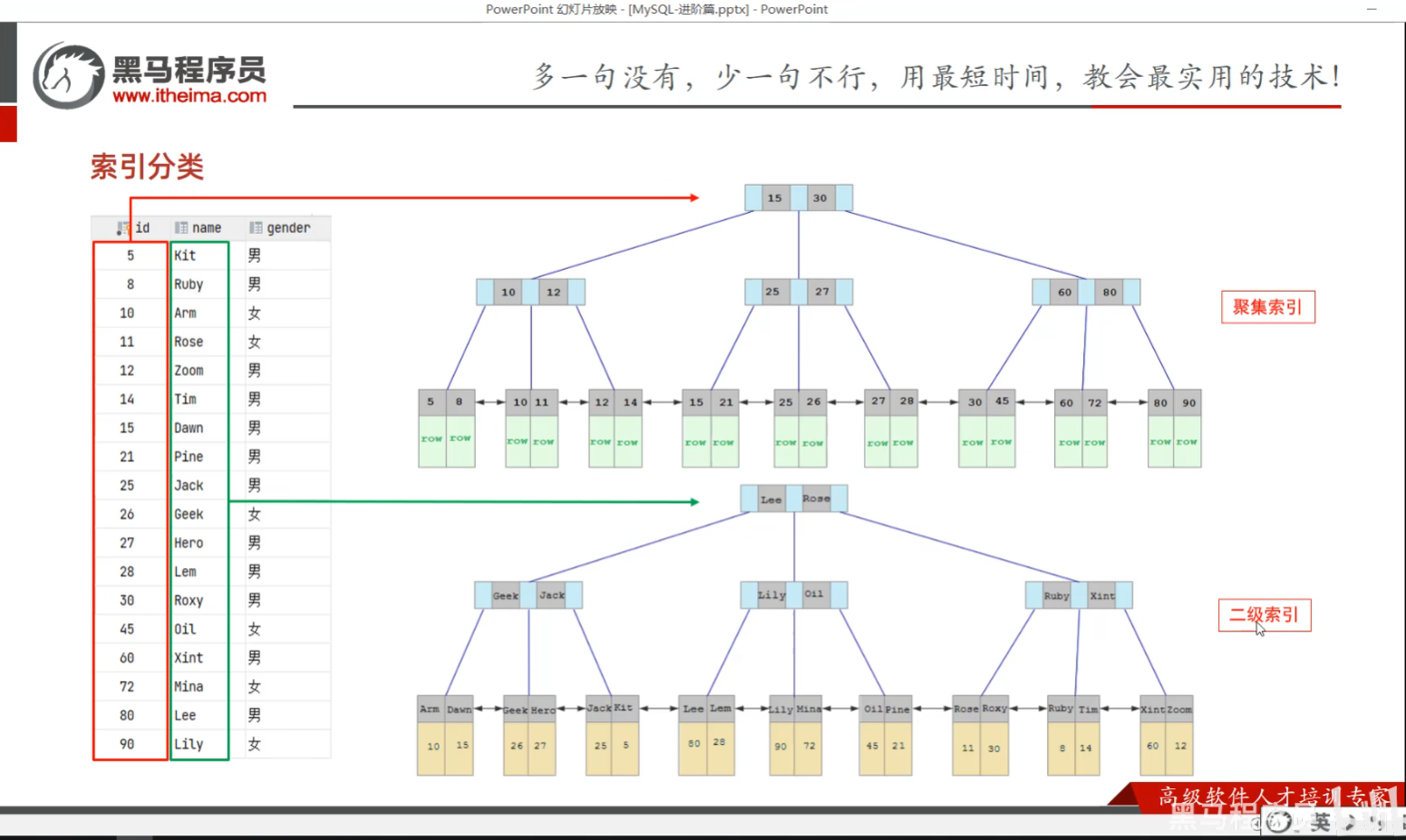
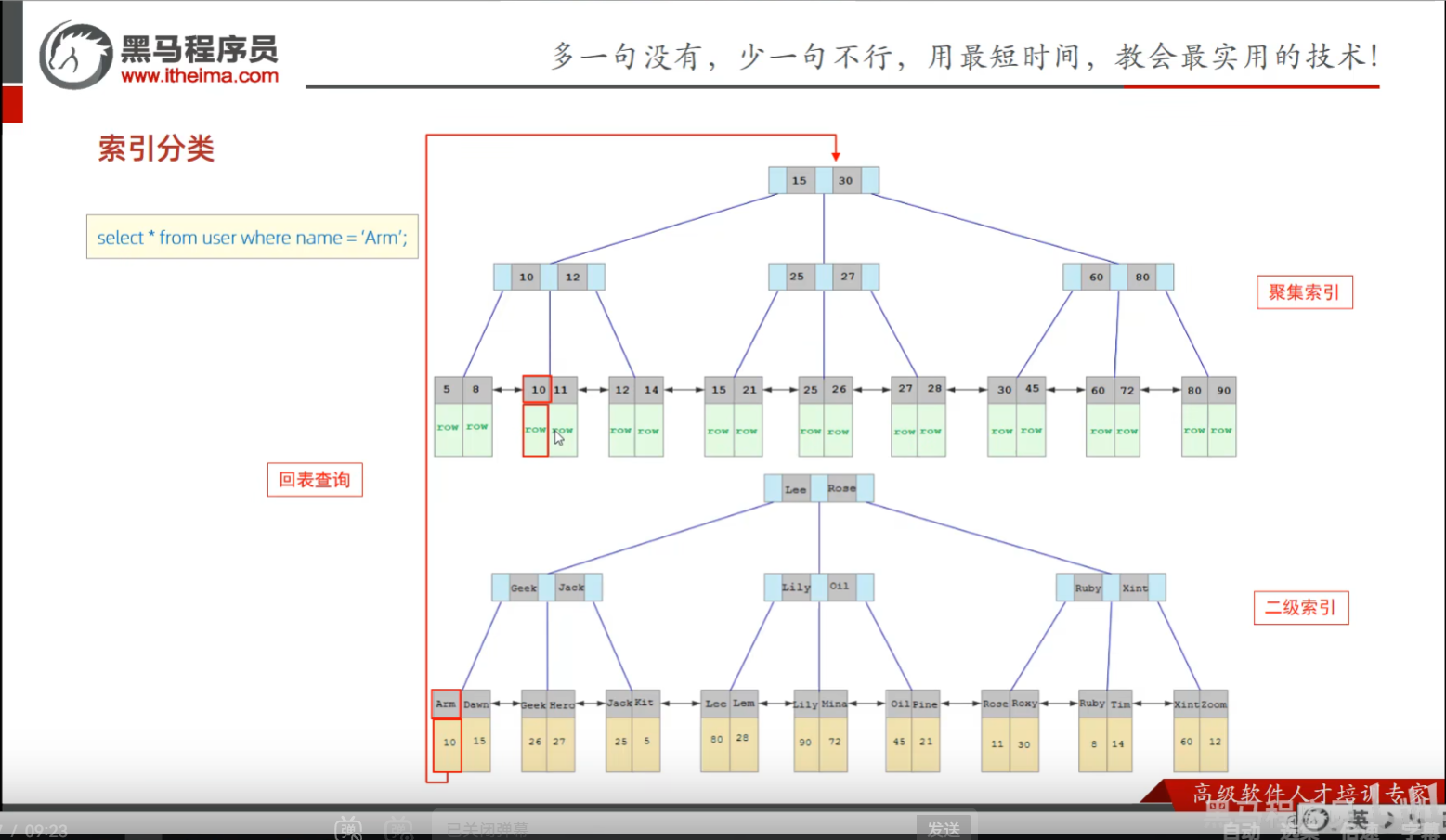
P15 索引分类
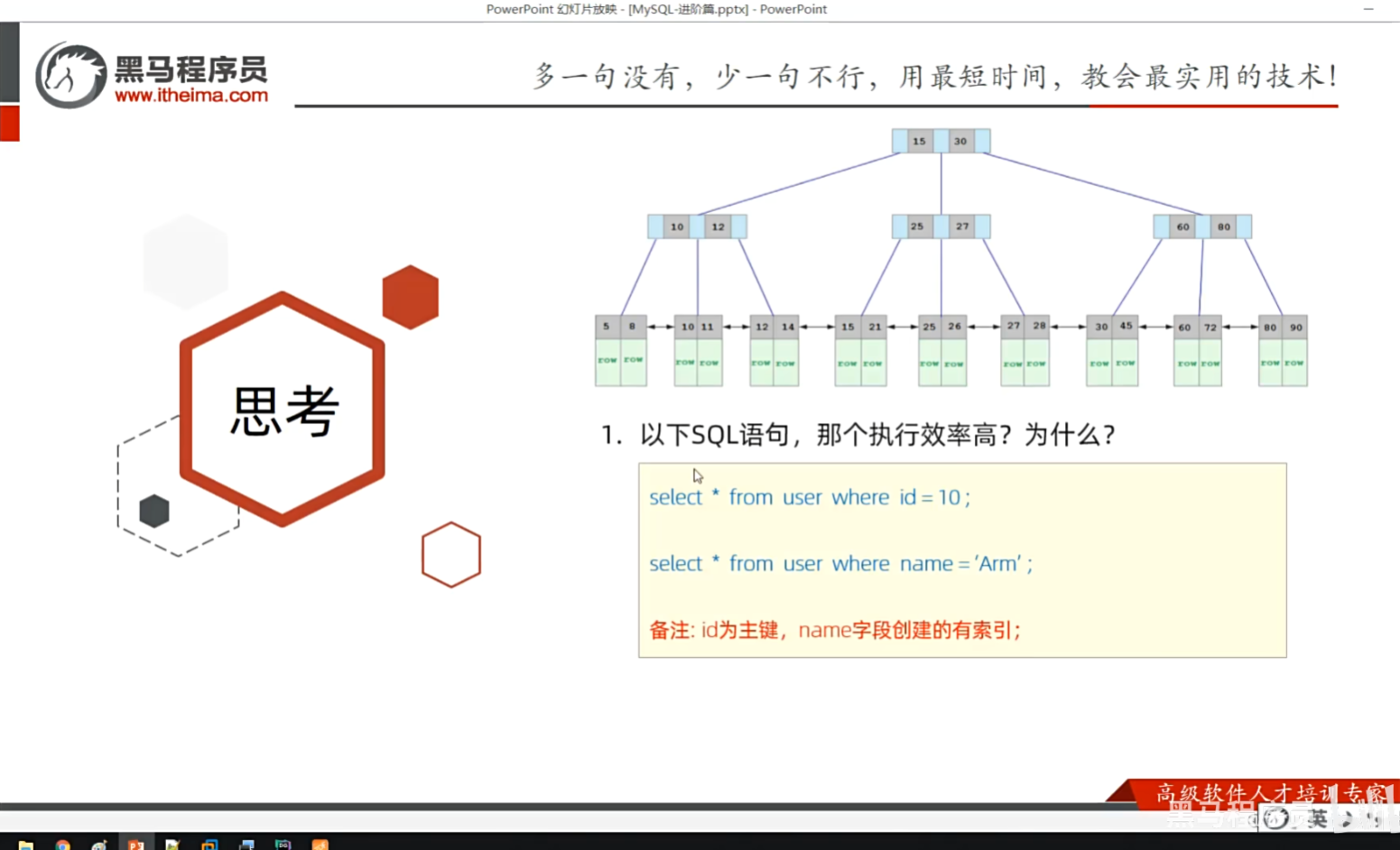
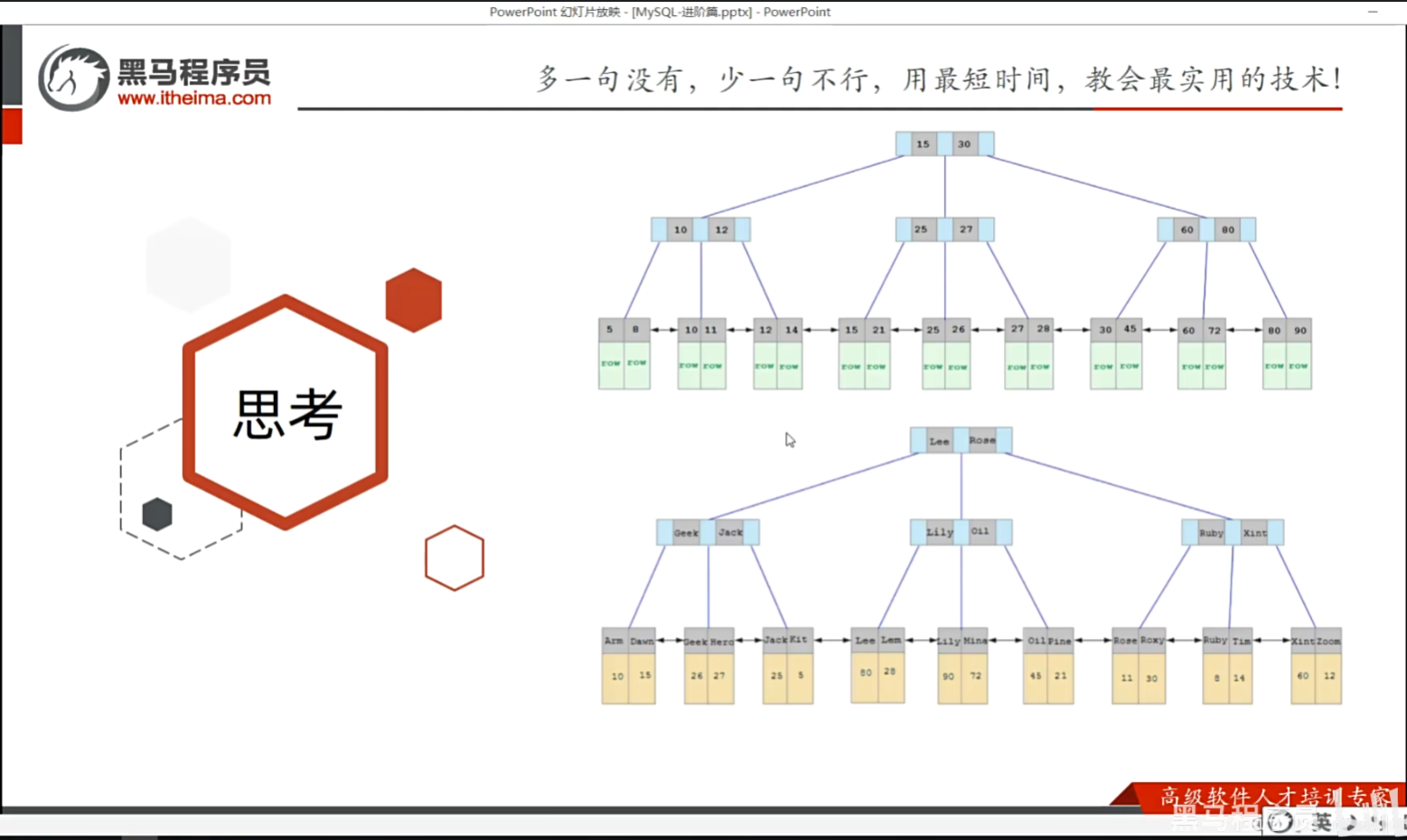
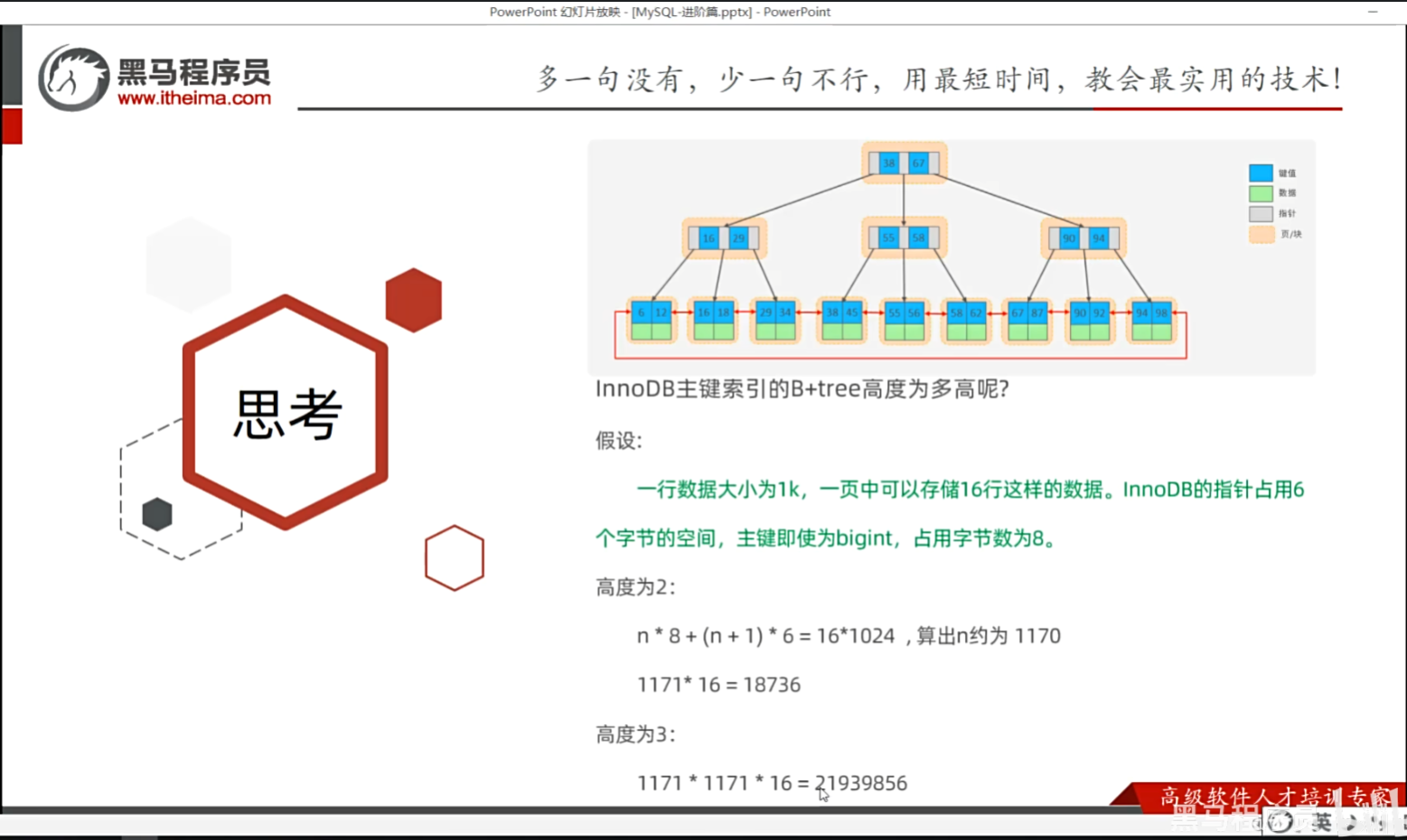
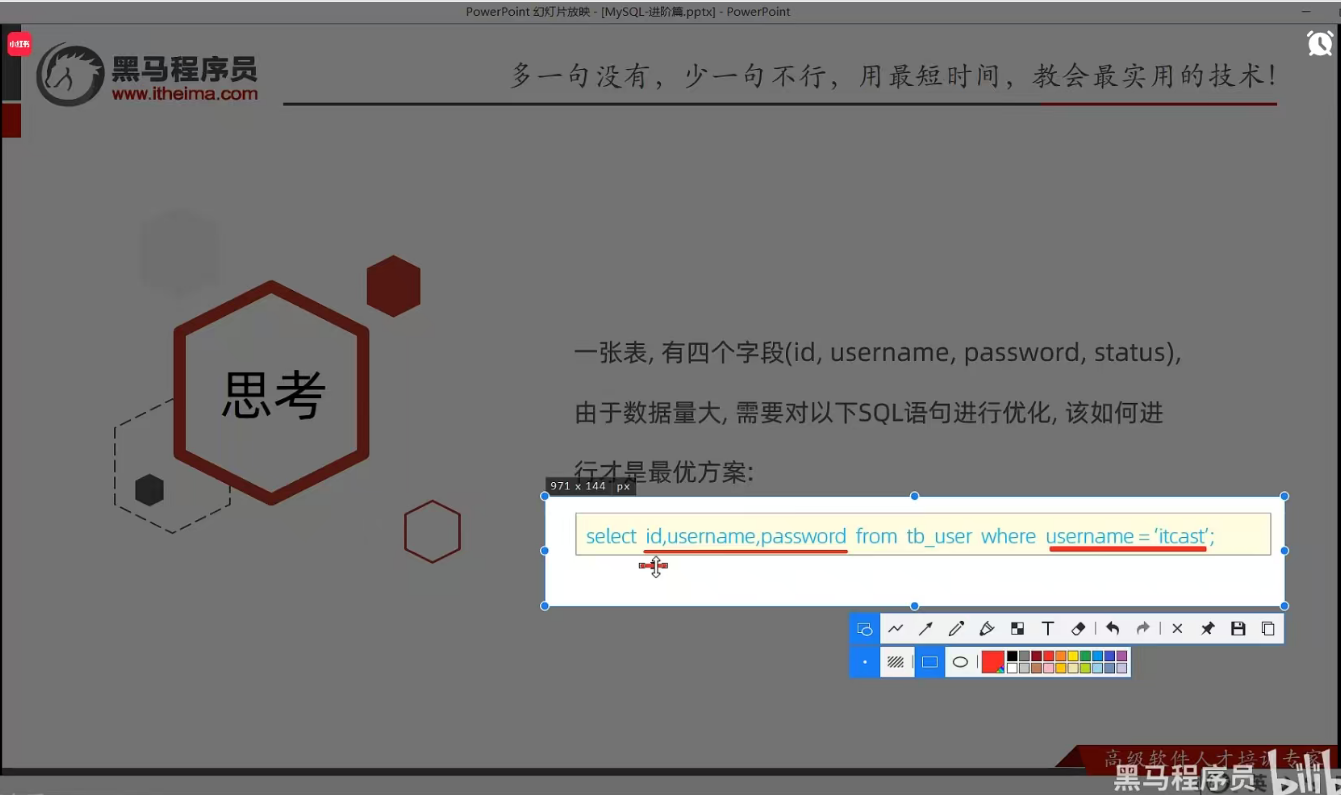
P16 思考题

第四节 索引语法
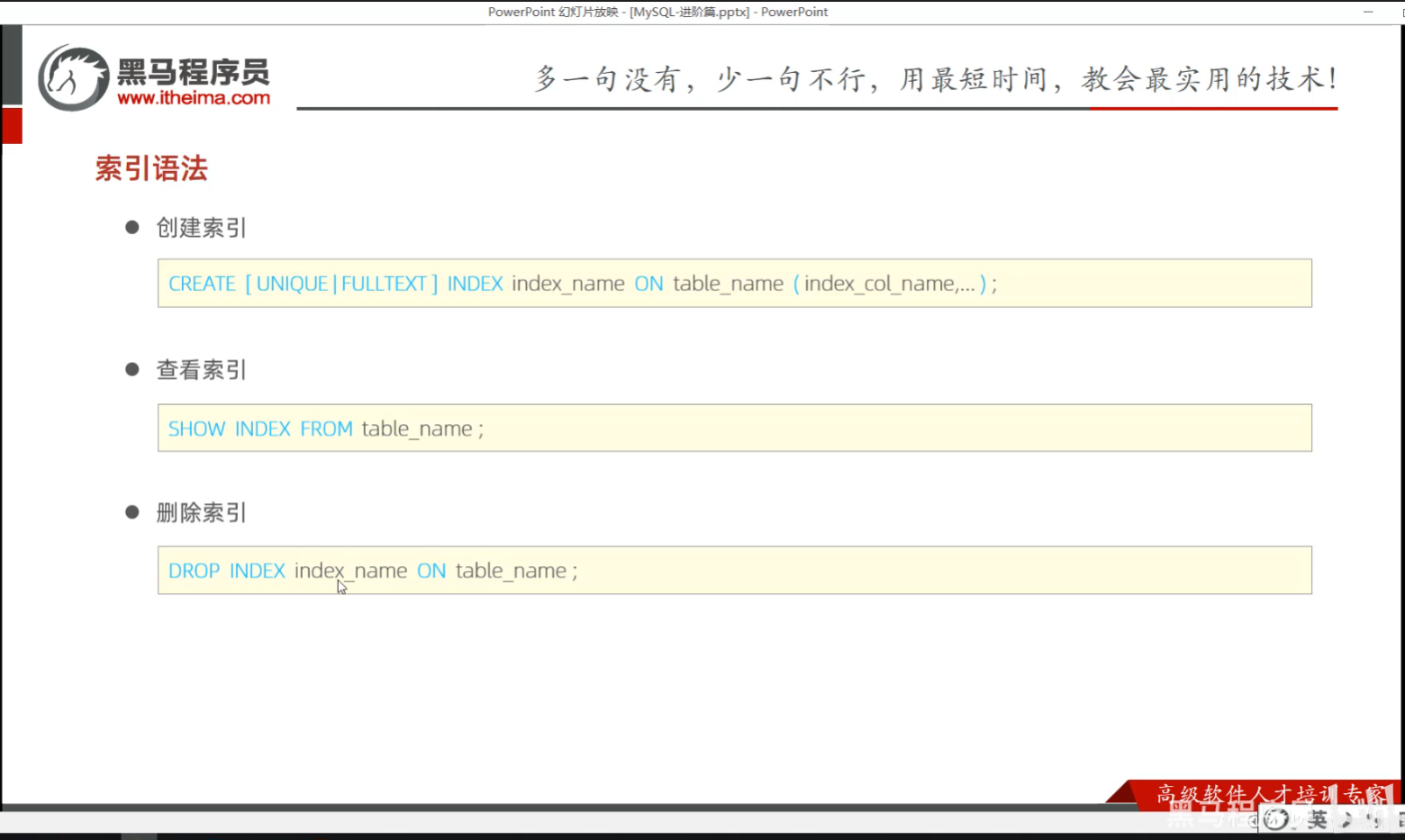
P17 索引语法
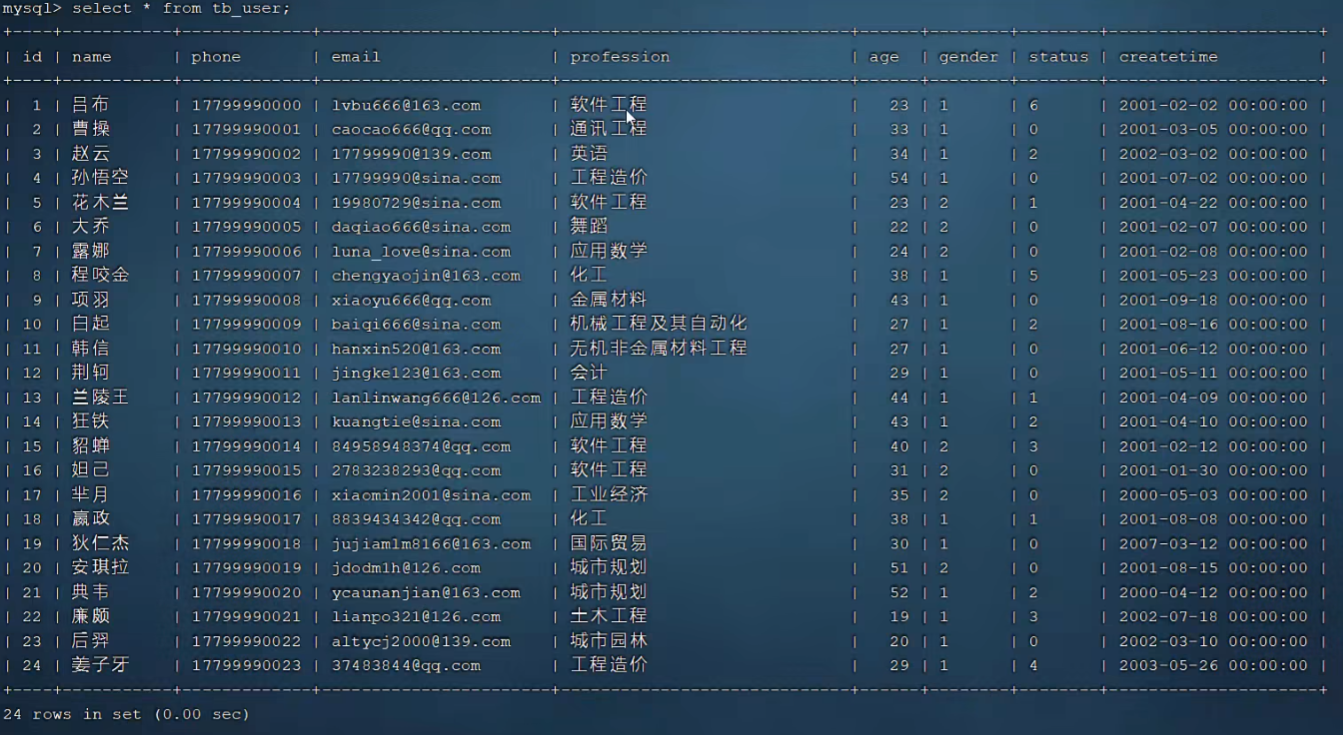
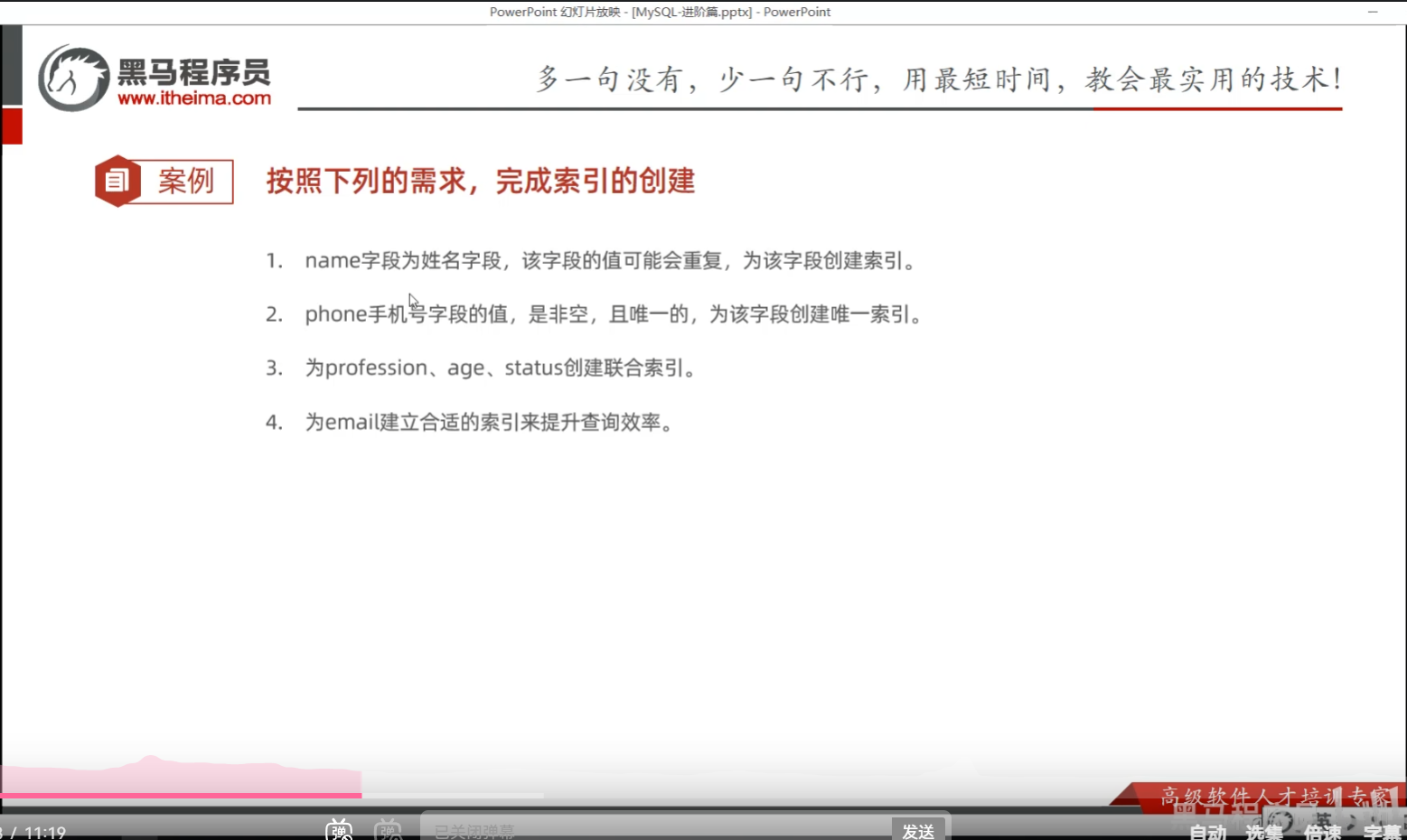
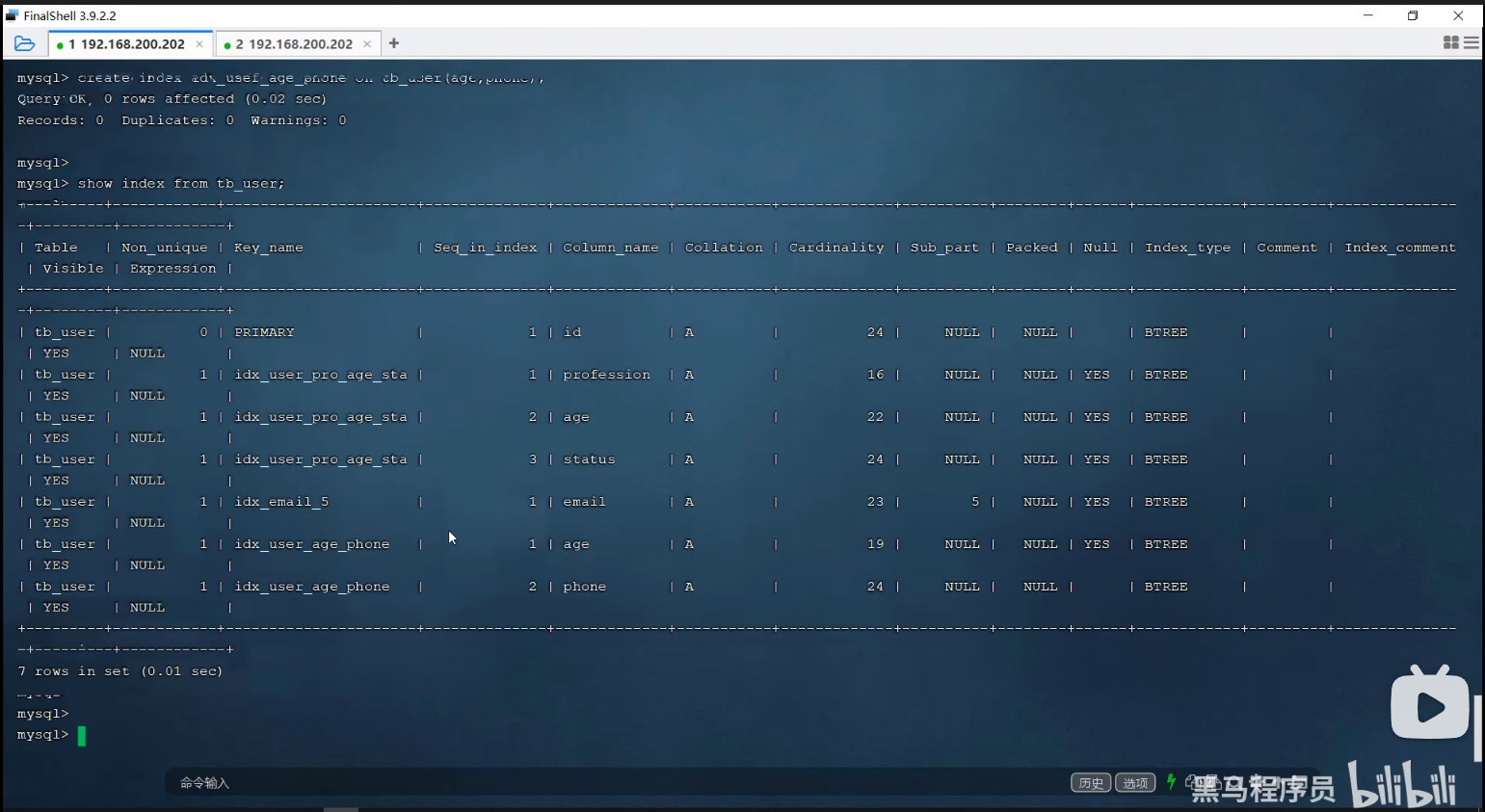
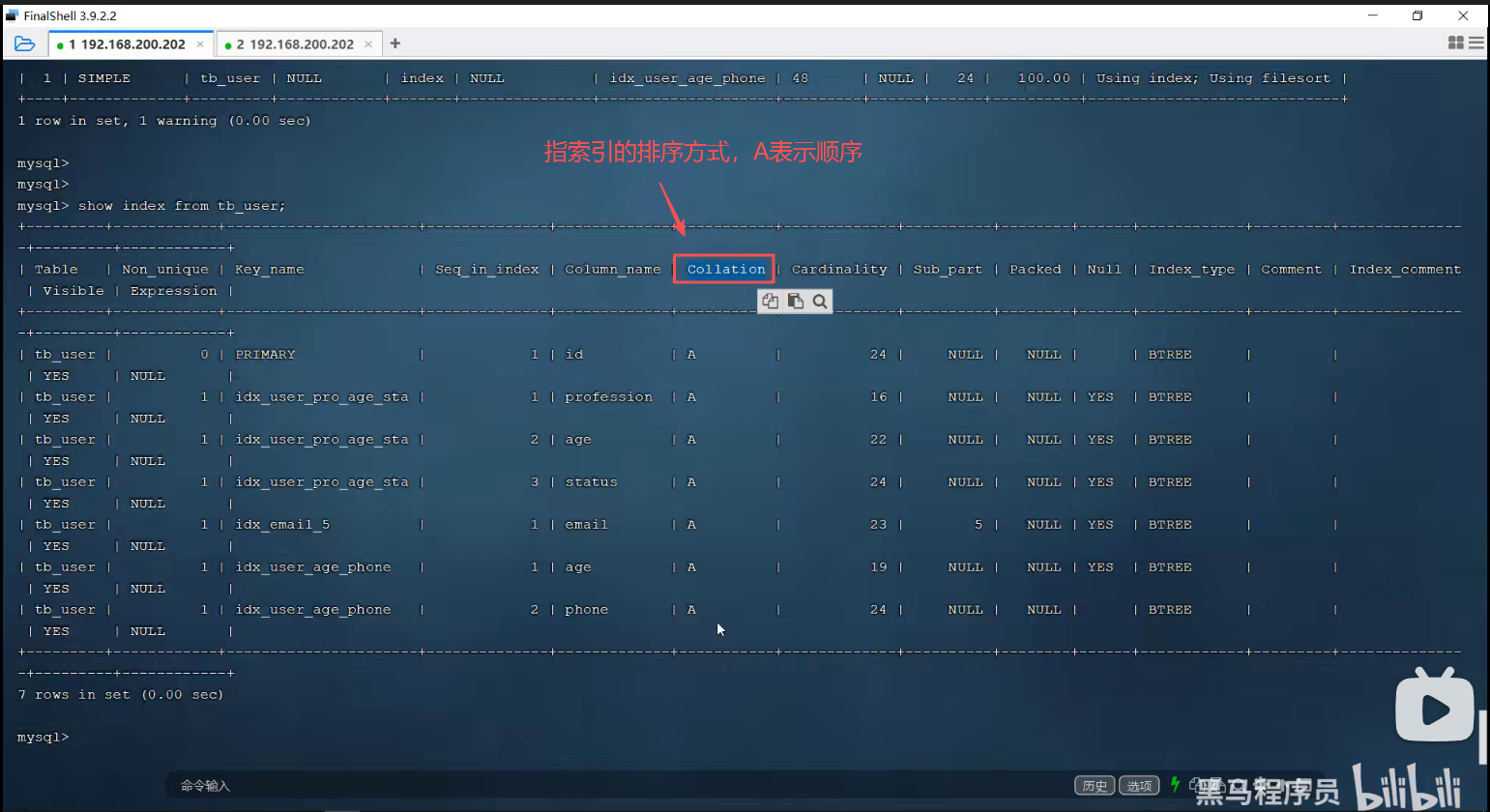
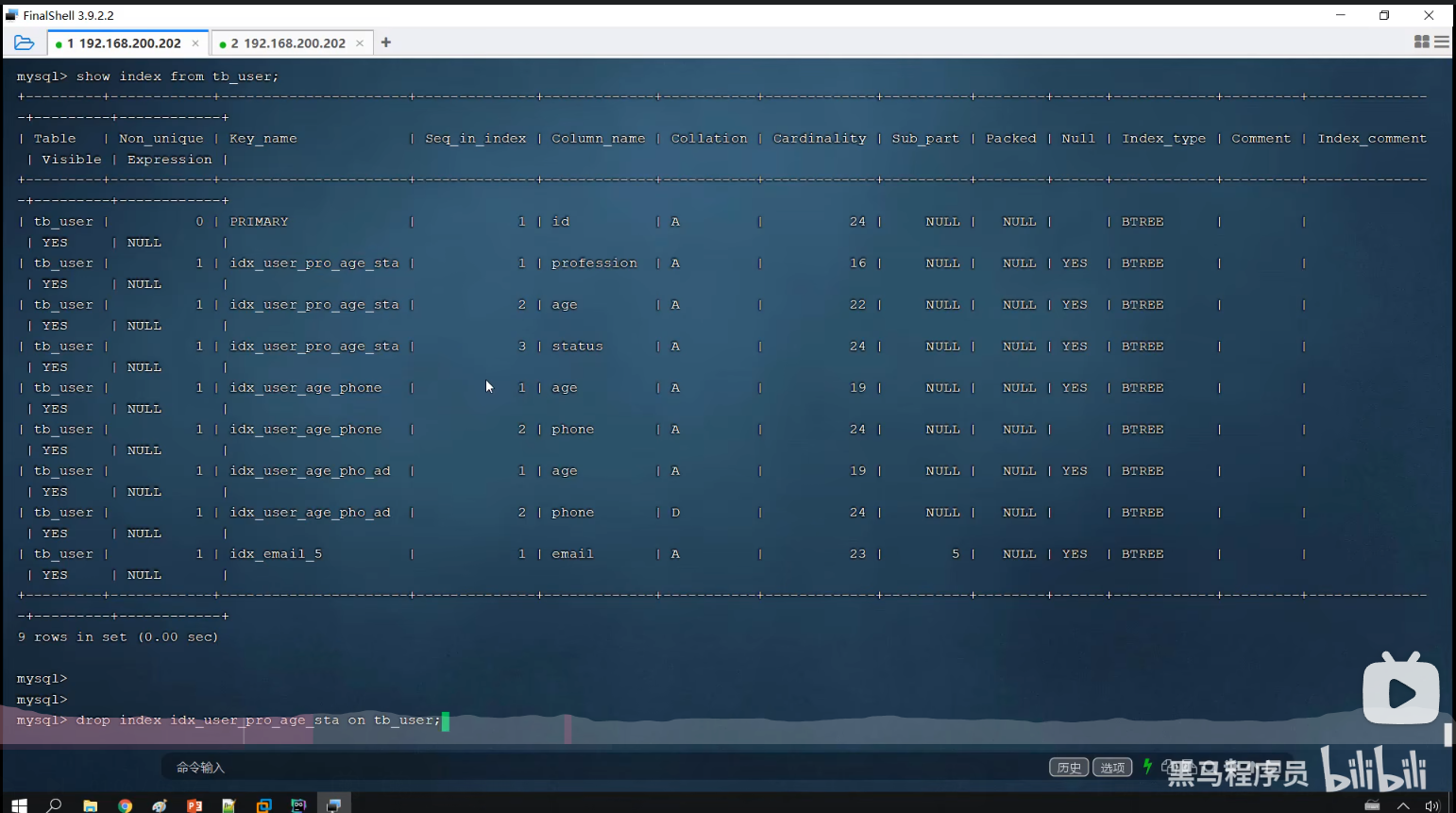
一、查看索引
show index from tb_user;二、删除索引
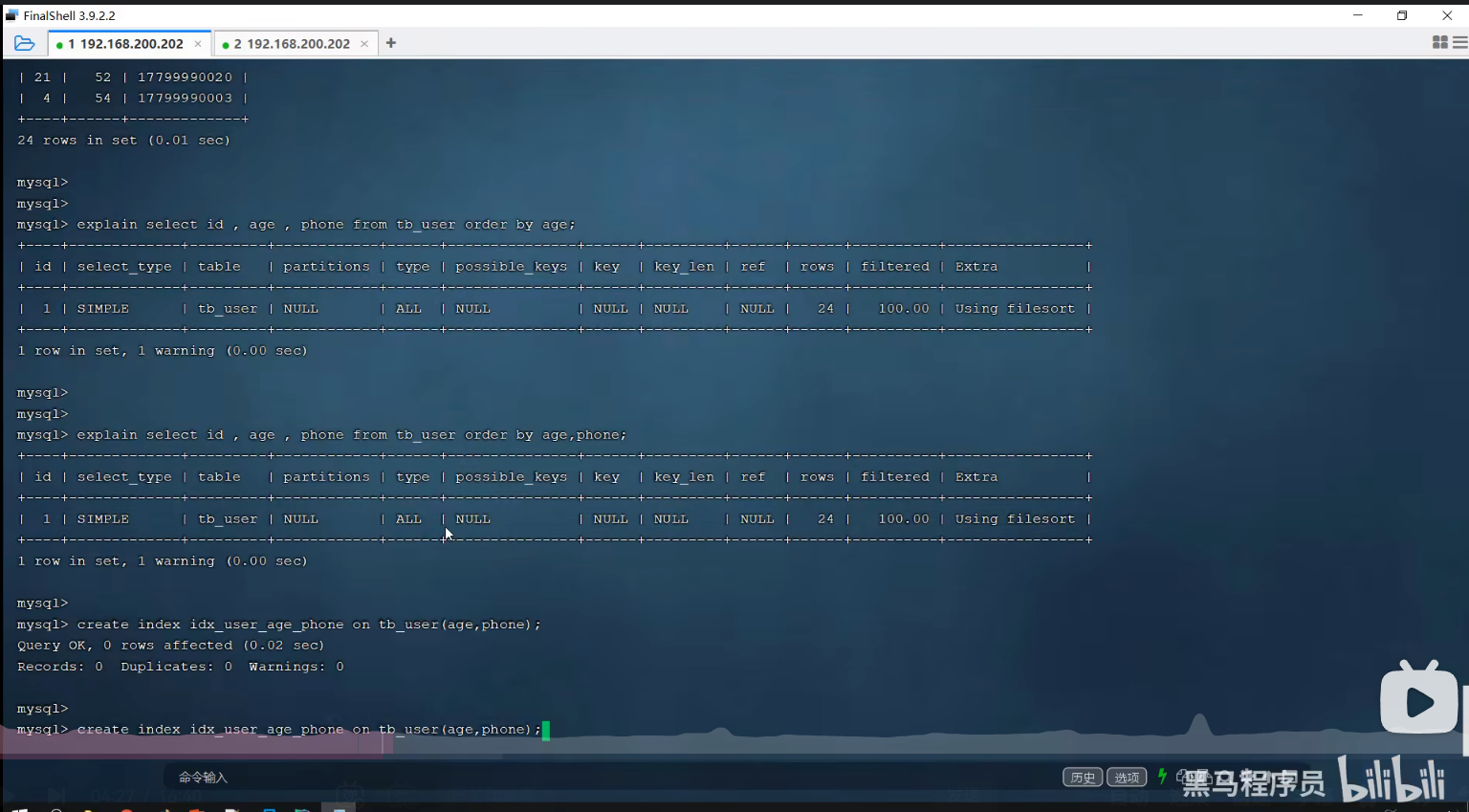
drop index phone on tb_user;三、创建索引
1.创建name字段的索引
因为创建的常规索引,index前面不加关键字。
create index idx_user_name on tb_user(name);2.创建手机号字段索引
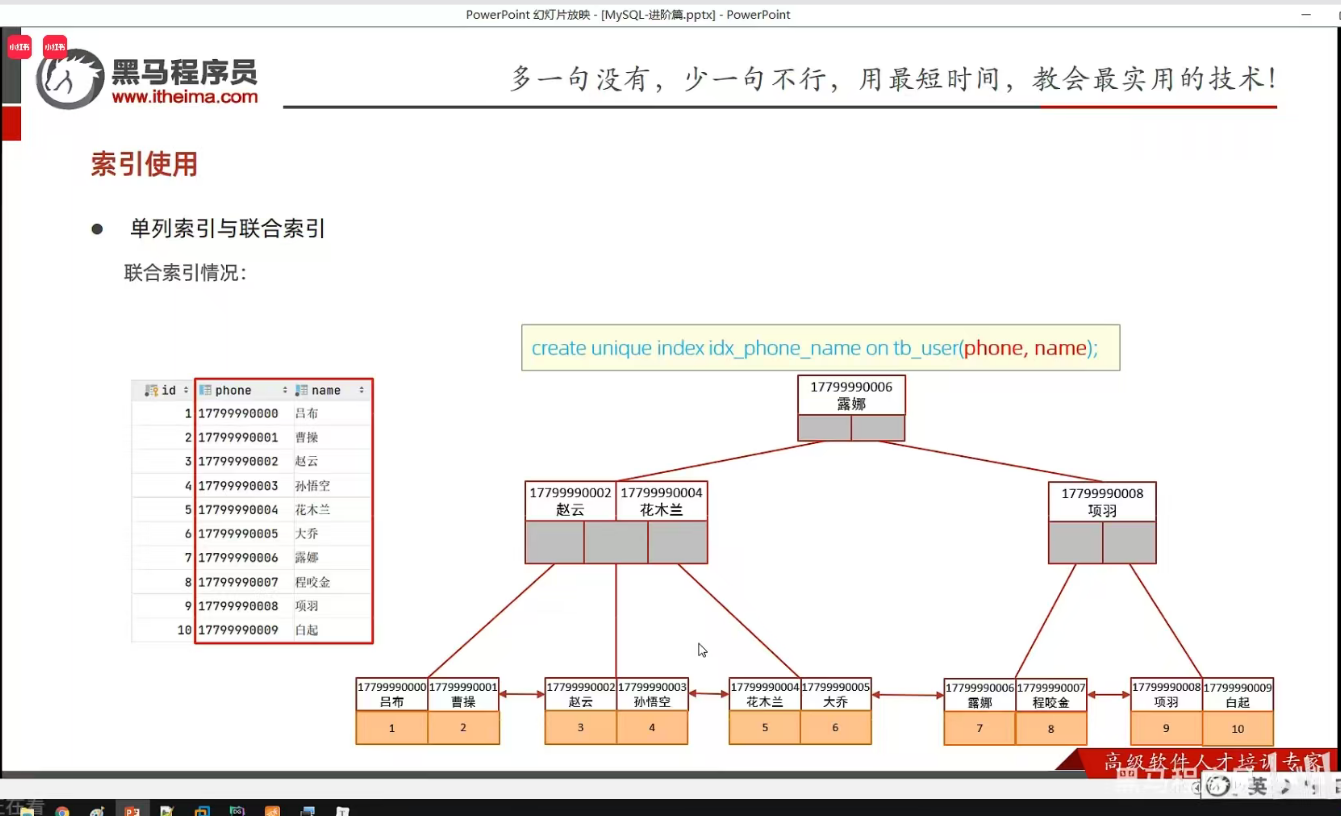
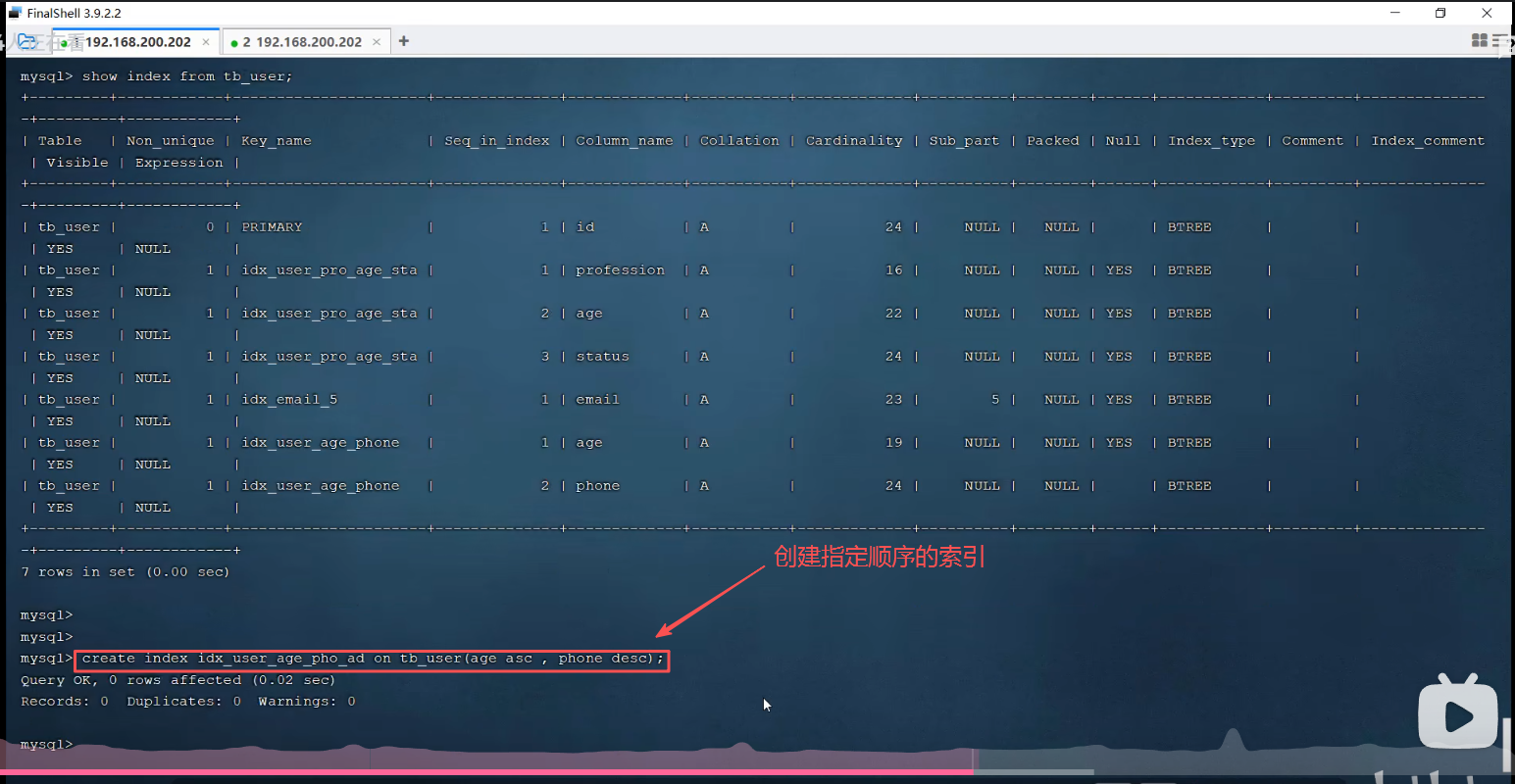
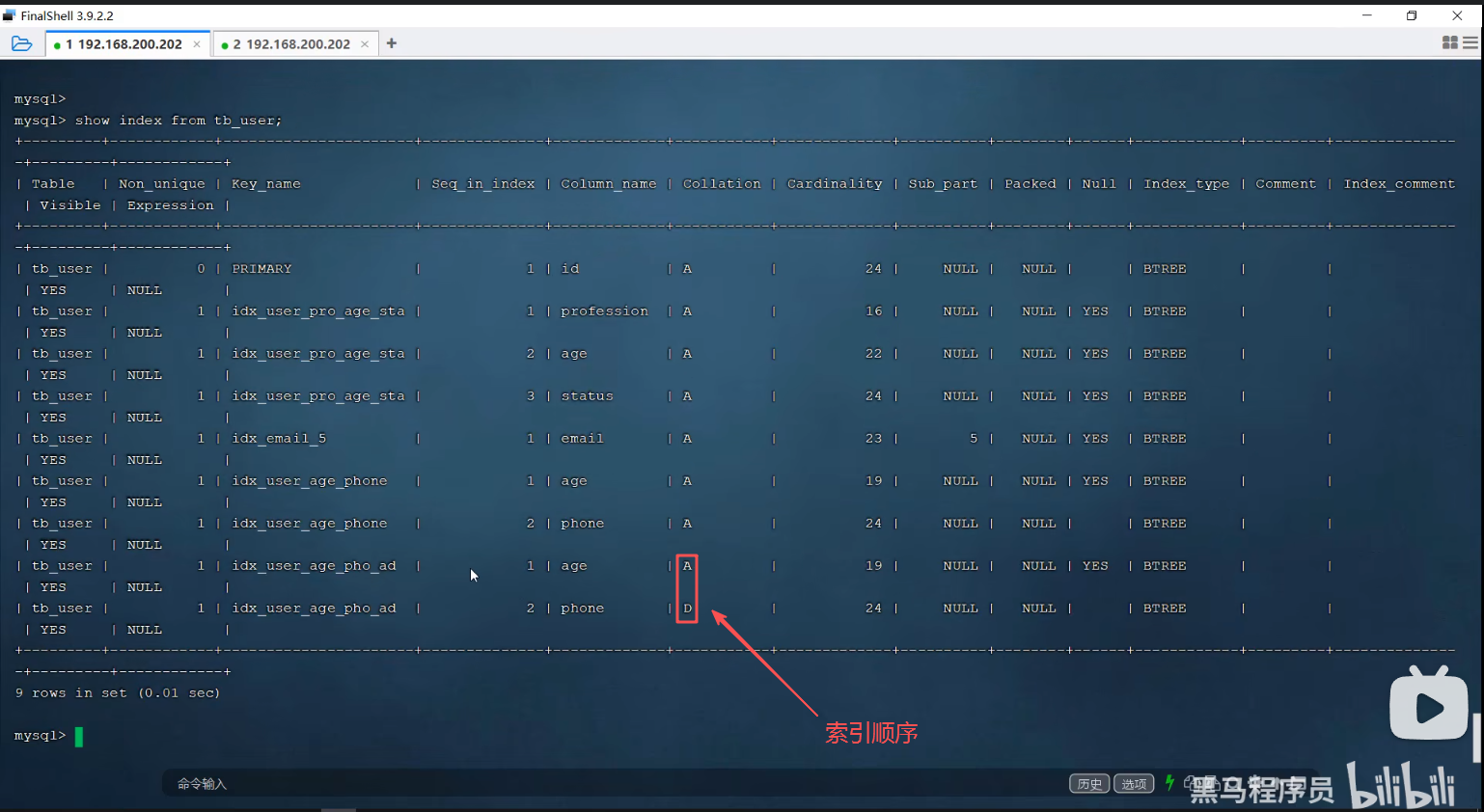
create unique index idx_user_phone on tb_user(phone);3.创建联合索引
create index idx_user_pro_age_sta on tb_user(profession,age,status);创建联合索引的顺序是有讲究的。
4.创建邮箱索引
create index idx_user_email on tb_user(email);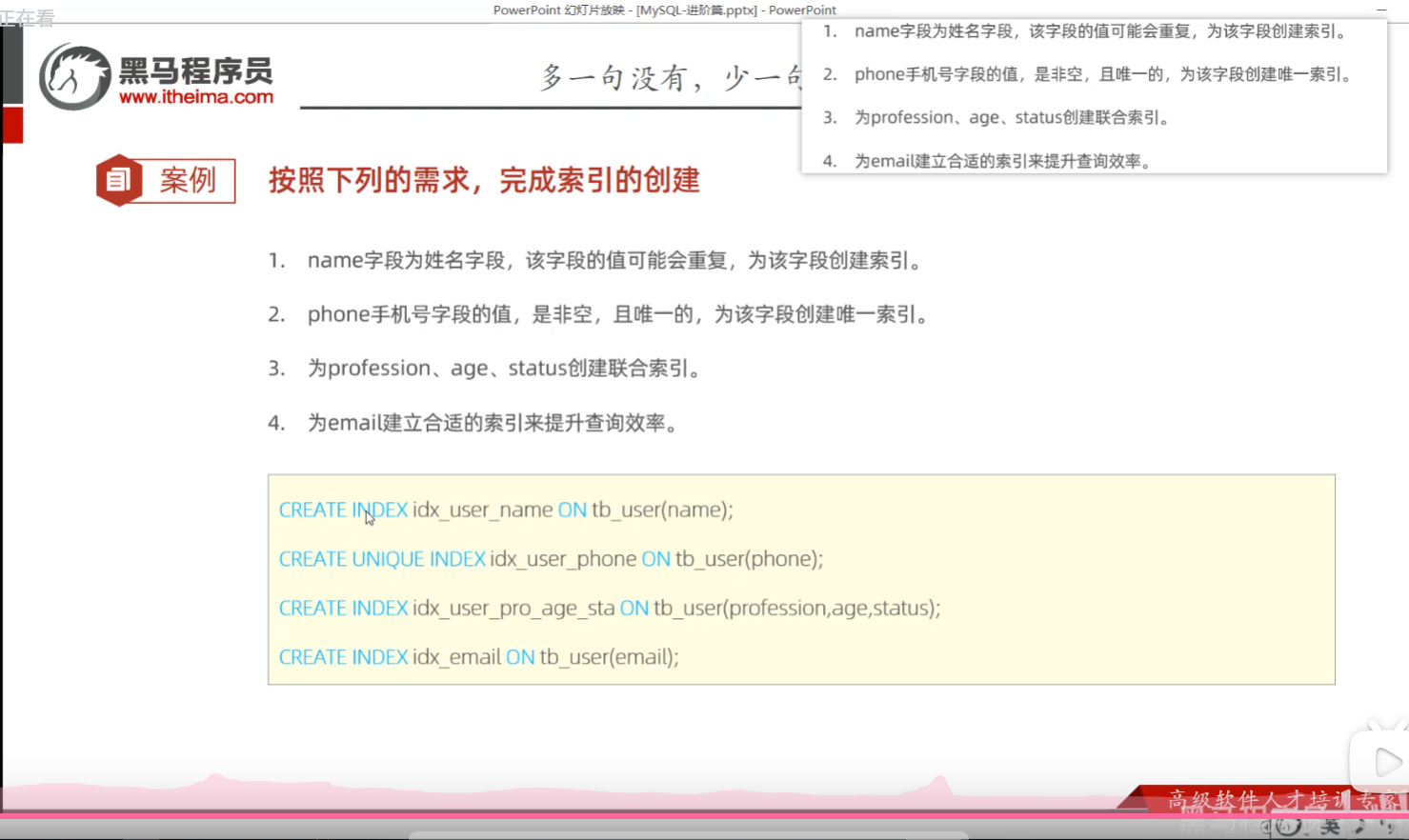

第五节 SQL性能分析
P18 查看执行频次
这个工具可以查看数据库增删改查的频率,从而决定数据库的优化方向。
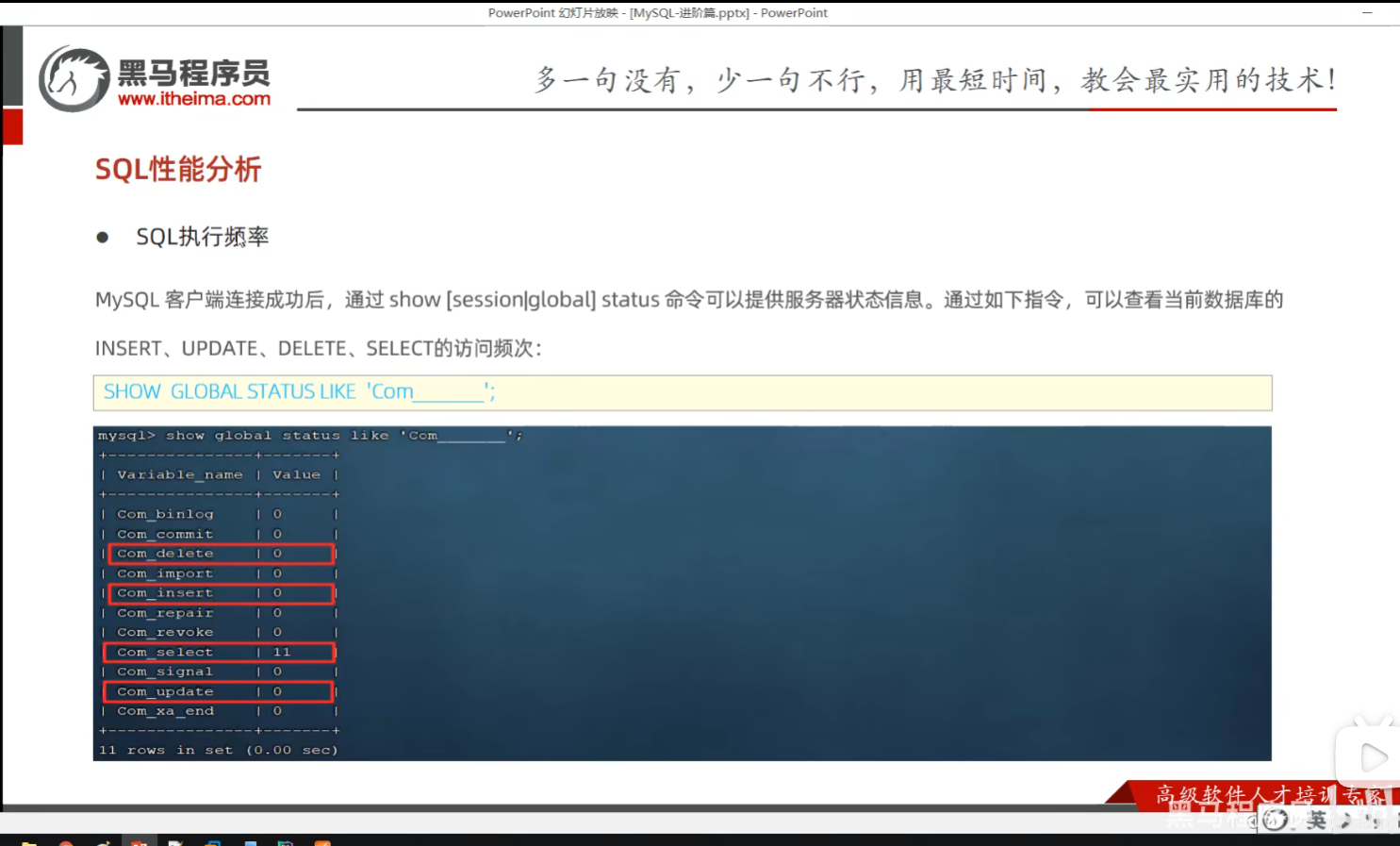
show global status like 'Com_______'; -- 7个下划线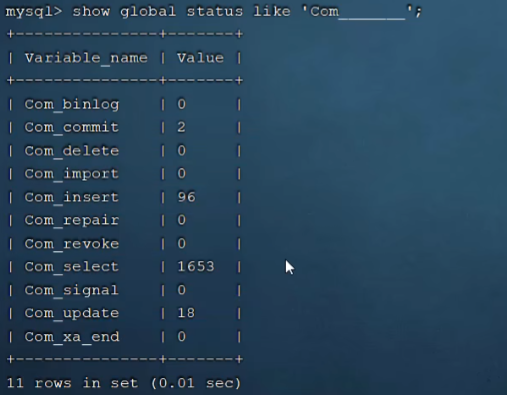
从上图可以看出数据库增删改查的频率,从而决定数据库的优化方向。
P19 慢查询日志
使用慢查询日志,可以精确定位到查询效率低的SQL语句。
show variables like 'slow_query_log';windows系统慢查询配置文件路径:
C:\ProgramData\MySQL\MySQL Server 8.0
或
C:\ProgramData\MySQL\MySQL Server 9.6
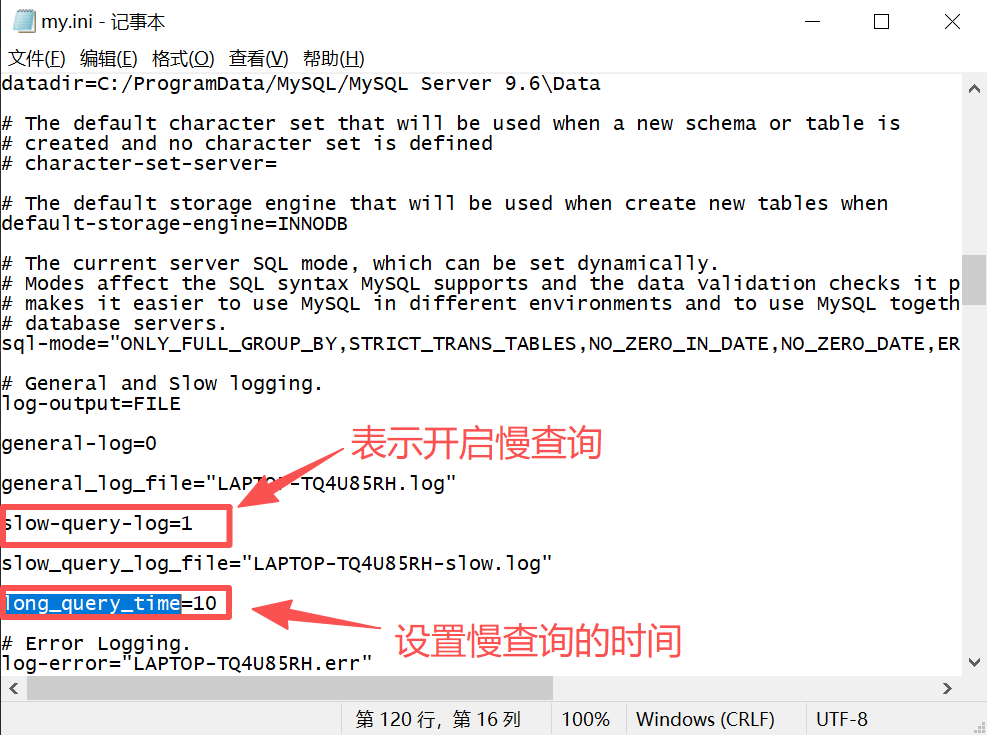
修改my.ini的方法
一、用管理员权限修改配置文件
-
在 Windows 左下角搜索 记事本 ,右键选择 以管理员身份运行。
-
点击记事本左上角 文件 → 打开 ,输入配置文件路径并打开:
plaintext
C:\ProgramData\MySQL\MySQL Server 9.6\my.ini -
在
[mysqld]区域下,确认或修改以下两项配置:ini
slow_query_log = 0 long_query_time = 2 -
保存文件(Ctrl+S)。
二、重启 MySQL 服务(必须执行,配置才会生效)
任选一种方式重启即可:
方式 1:服务管理器重启
- 按
Win + R,输入services.msc打开服务。 - 找到 MySQL96 ,右键 → 重启。
方式 2:管理员 CMD 命令重启
-
以管理员身份打开命令提示符。
-
依次执行:
net stop MySQL96 net start MySQL96
三、验证配置是否生效
重启完成后,登录 MySQL 客户端,执行以下两条语句查看状态:
SHOW VARIABLES LIKE 'slow_query_log';
SHOW VARIABLES LIKE 'long_query_time';打开慢查询日志文件
1.老师的方法
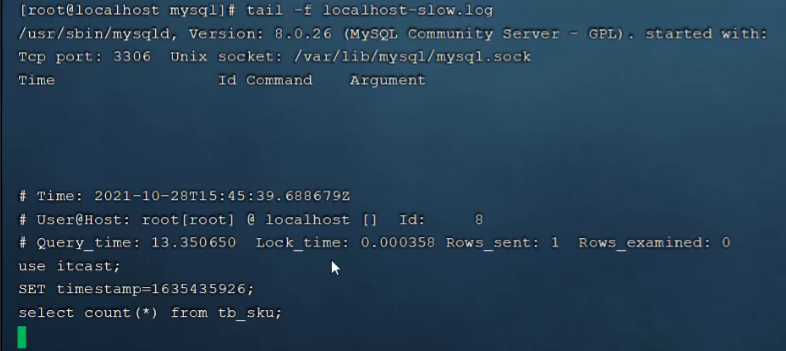
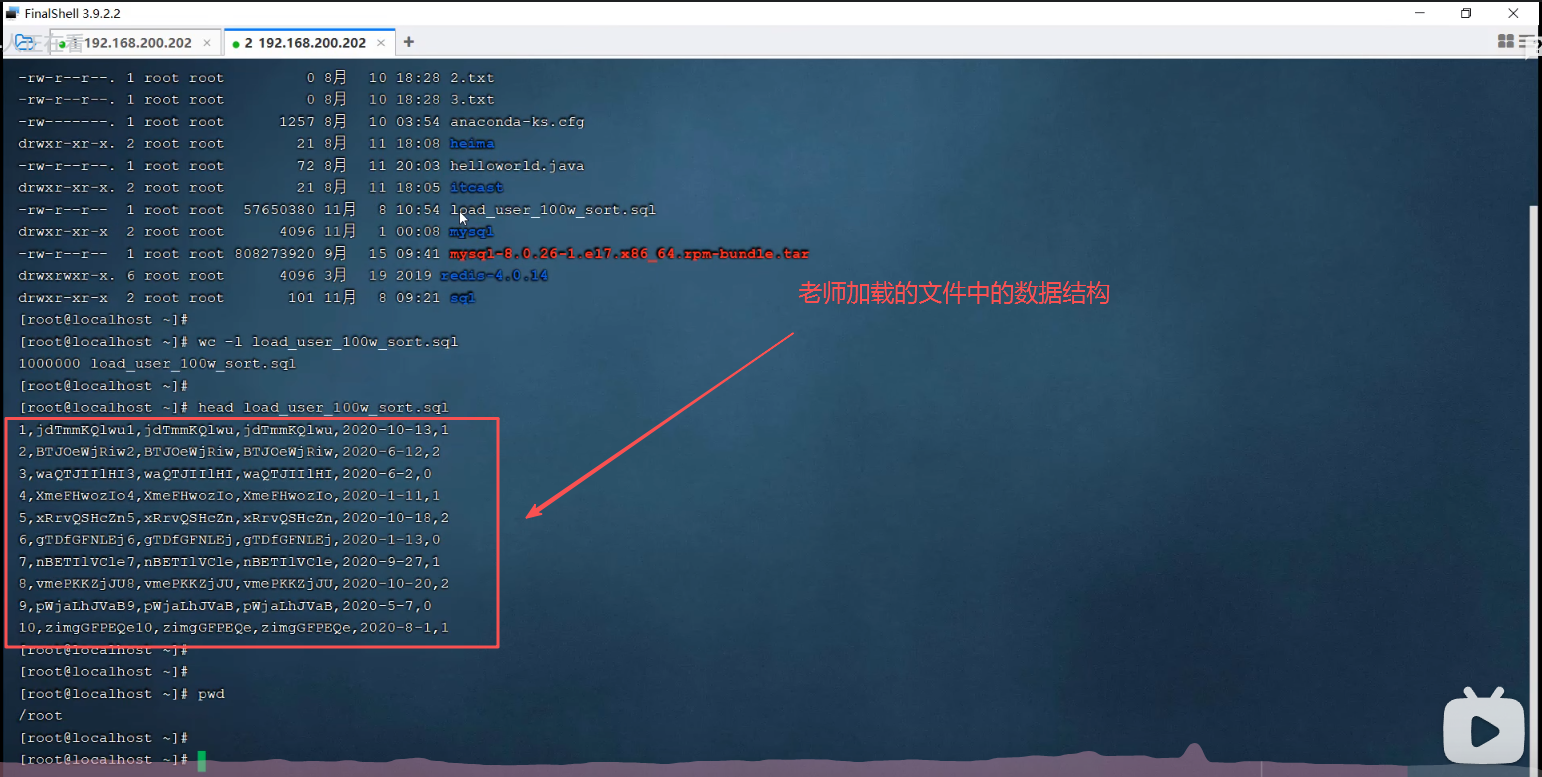
2.windows系统的打开方法:找到日志文件,使用记事本打开即可。从cmd运行的结果可以看出日志文件的路径是:C:\ProgramData\MySQL\MySQL Server 9.6\Data\LAPTOP-TQ4U85RH-slow.log
mysql> SHOW VARIABLES LIKE 'slow_query_log_file';
+---------------------+--------------------------+
| Variable_name | Value |
+---------------------+--------------------------+
| slow_query_log_file | LAPTOP-TQ4U85RH-slow.log |
+---------------------+--------------------------+
1 row in set, 1 warning (0.029 sec)
mysql> SHOW VARIABLES LIKE 'datadir';
+---------------+---------------------------------------------+
| Variable_name | Value |
+---------------+---------------------------------------------+
| datadir | C:\ProgramData\MySQL\MySQL Server 9.6\Data\ |
+---------------+---------------------------------------------+
1 row in set, 1 warning (0.032 sec)P20 show profiles
# 查看当前数据库是否支持profiling功能
select @@have_profiling;
# 查看profiling的值,0为关闭,1为开启
select @@profiling;
# 开启profiling,即将值设为1
set profiling=1;
1.查看sql语句的耗时情况:show profiles;
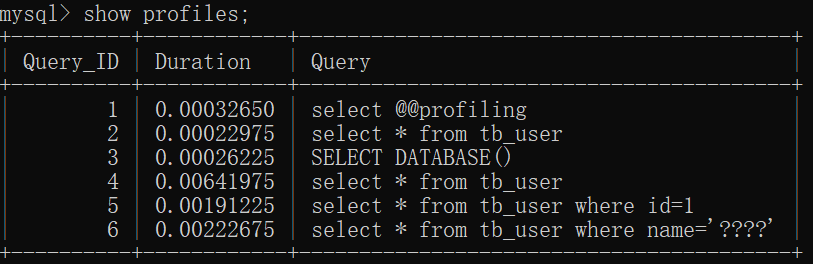
2.查看各个阶段sql语句的耗时情况:show profile for query 4;
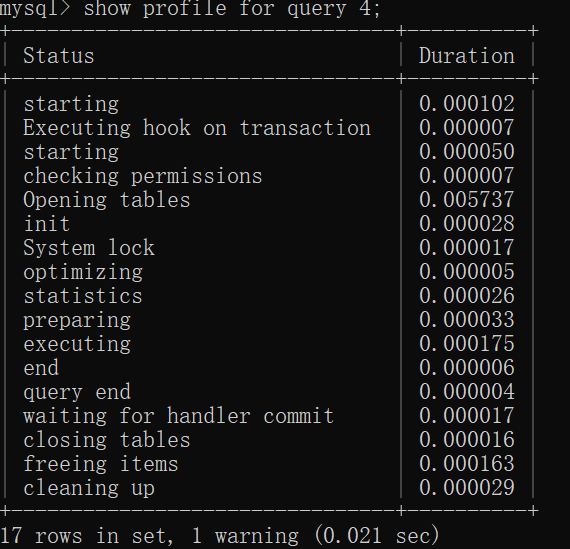
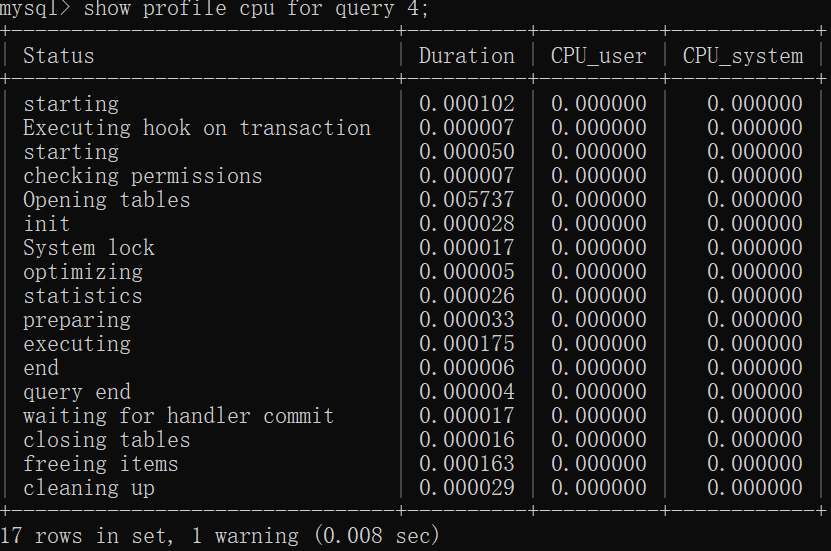
3.查看cpu的耗费情况:show profile cpu for query 4;
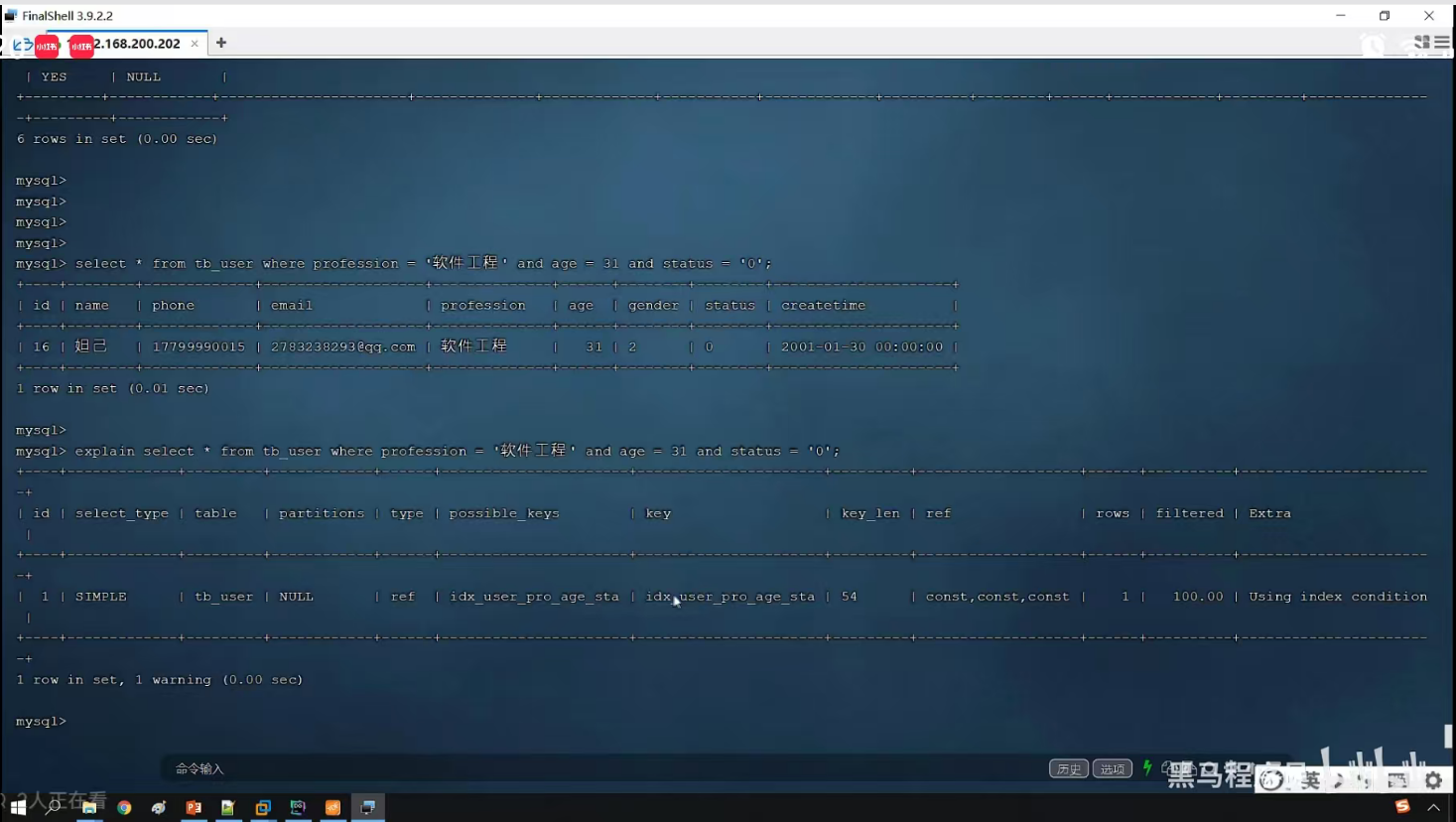
P21 explain
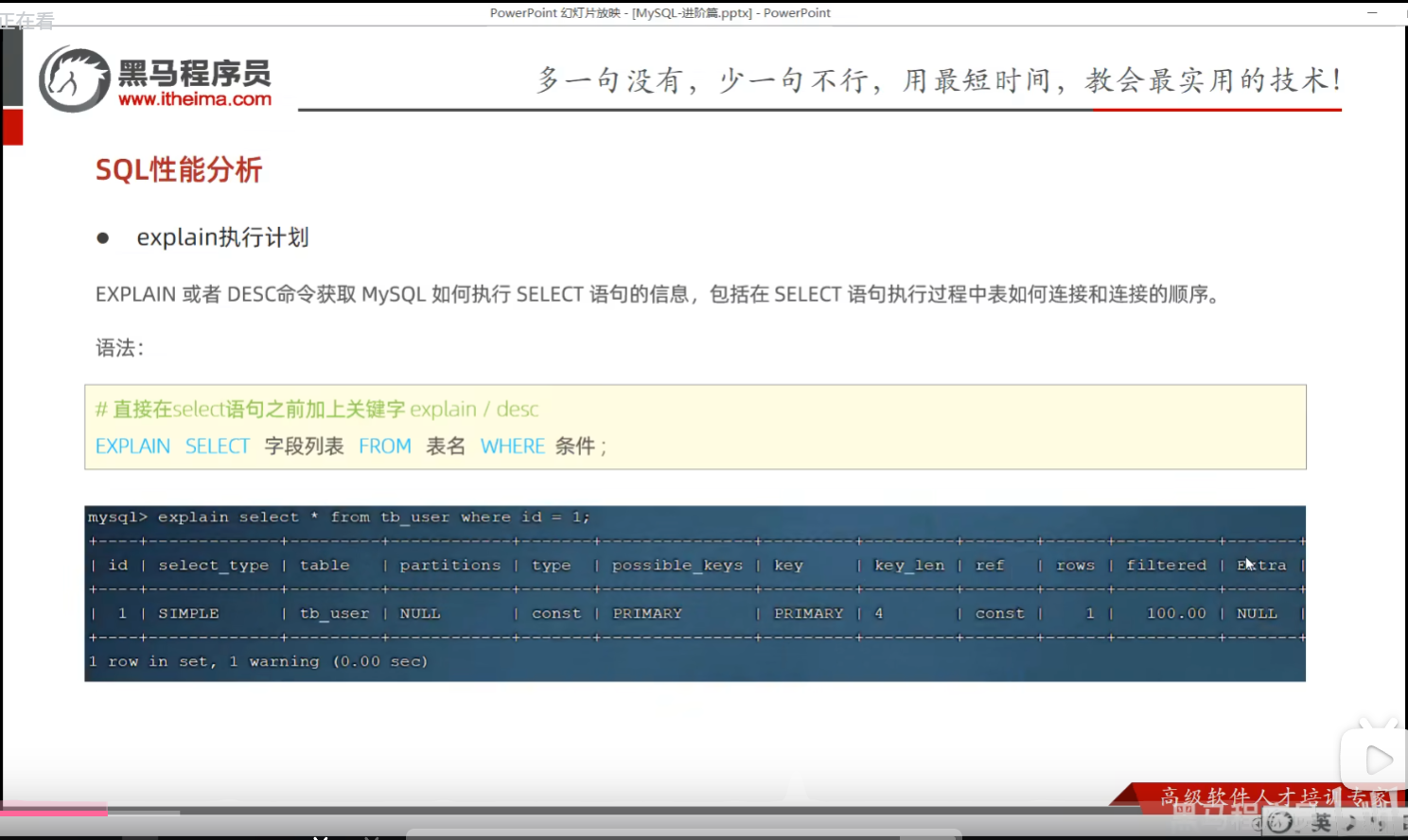


需要关注的重点字段



自己的执行结果同老师的不一样。原因在于:MySQL 9.6 版本的 EXPLAIN 输出格式,和老师用的旧版本(比如 5.7/8.0)不一样。
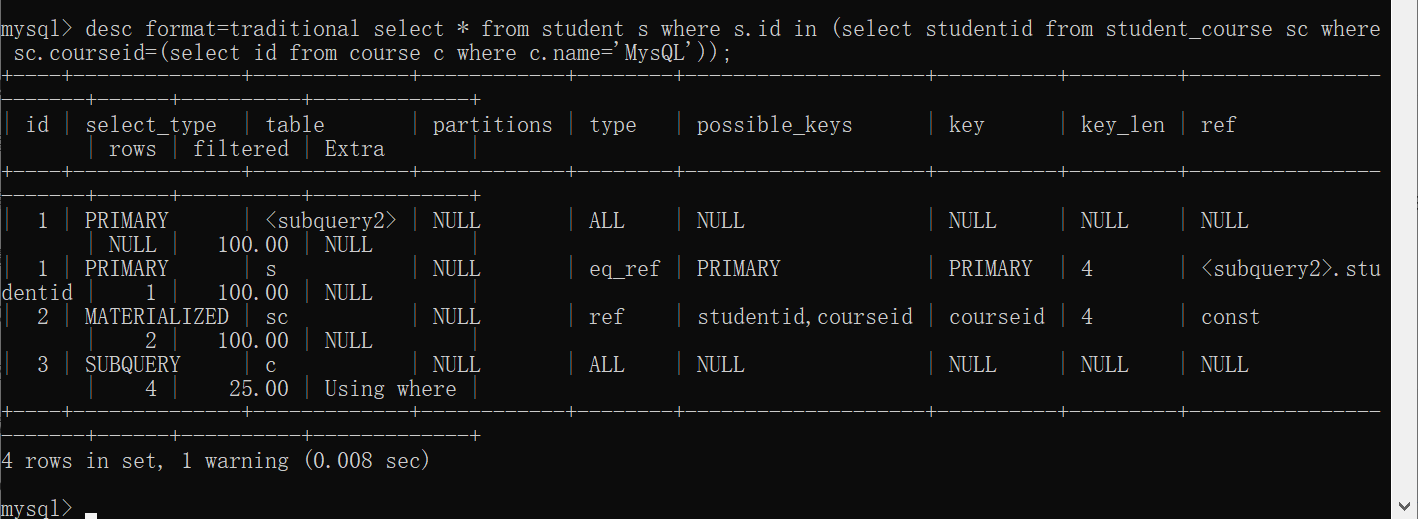
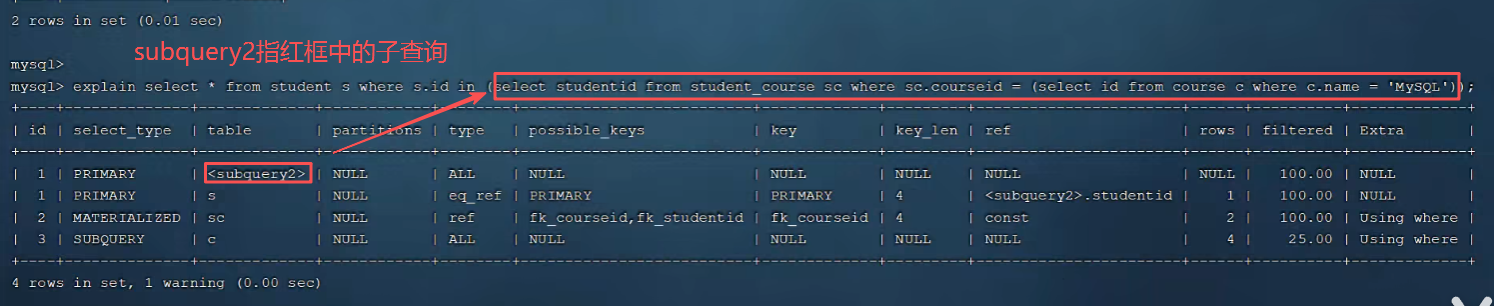
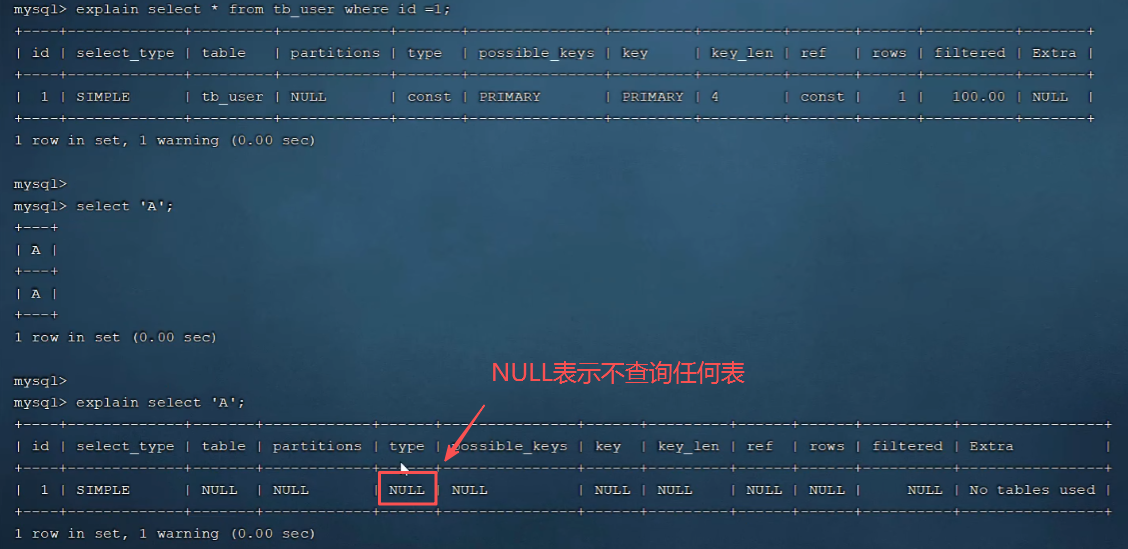
解决办法,在desc或explain加format=traditional转化一下即可。
-- 或者简写 desc 也支持
desc format=traditional select * from tb_user where name='白起';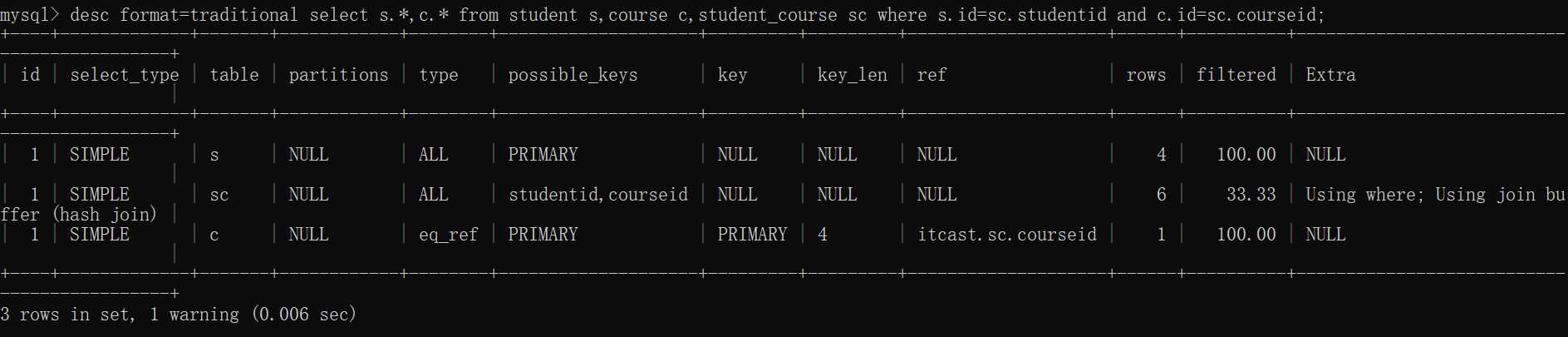


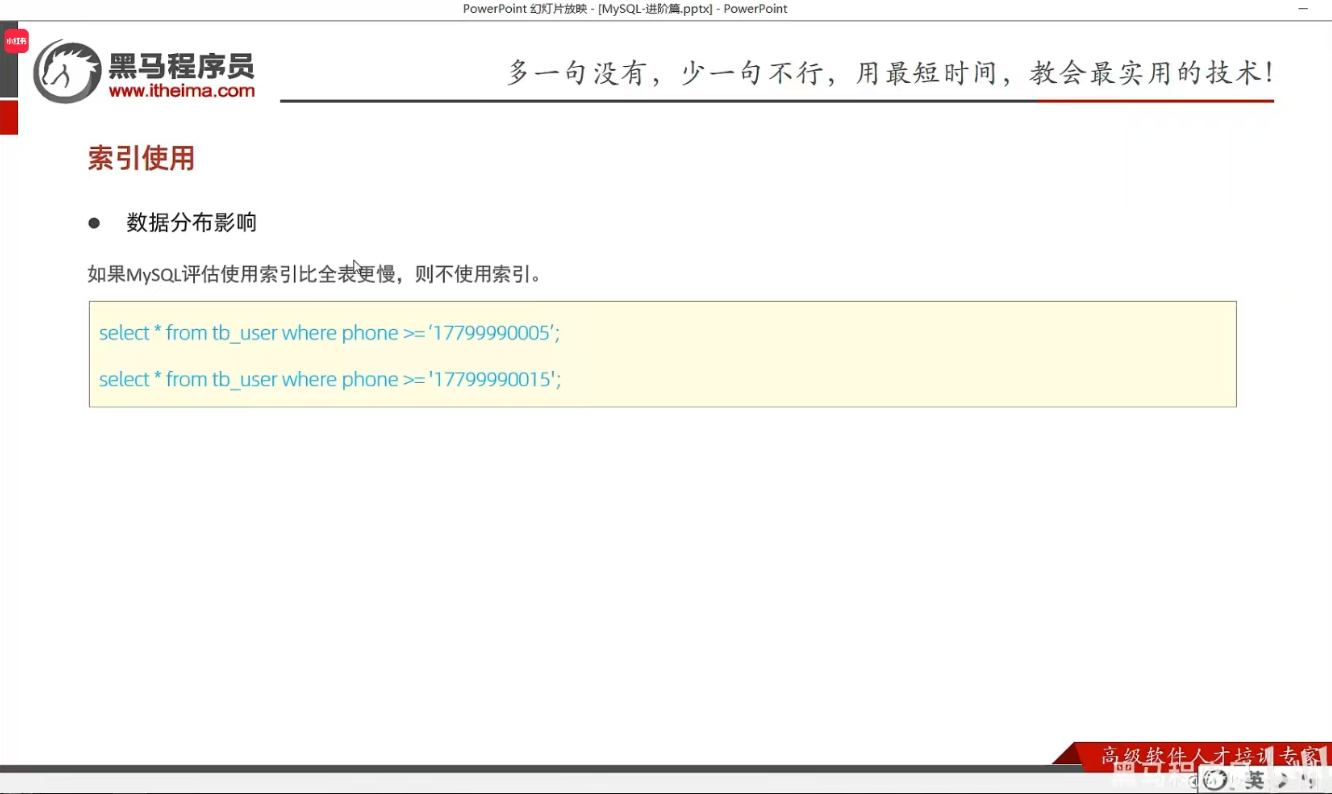
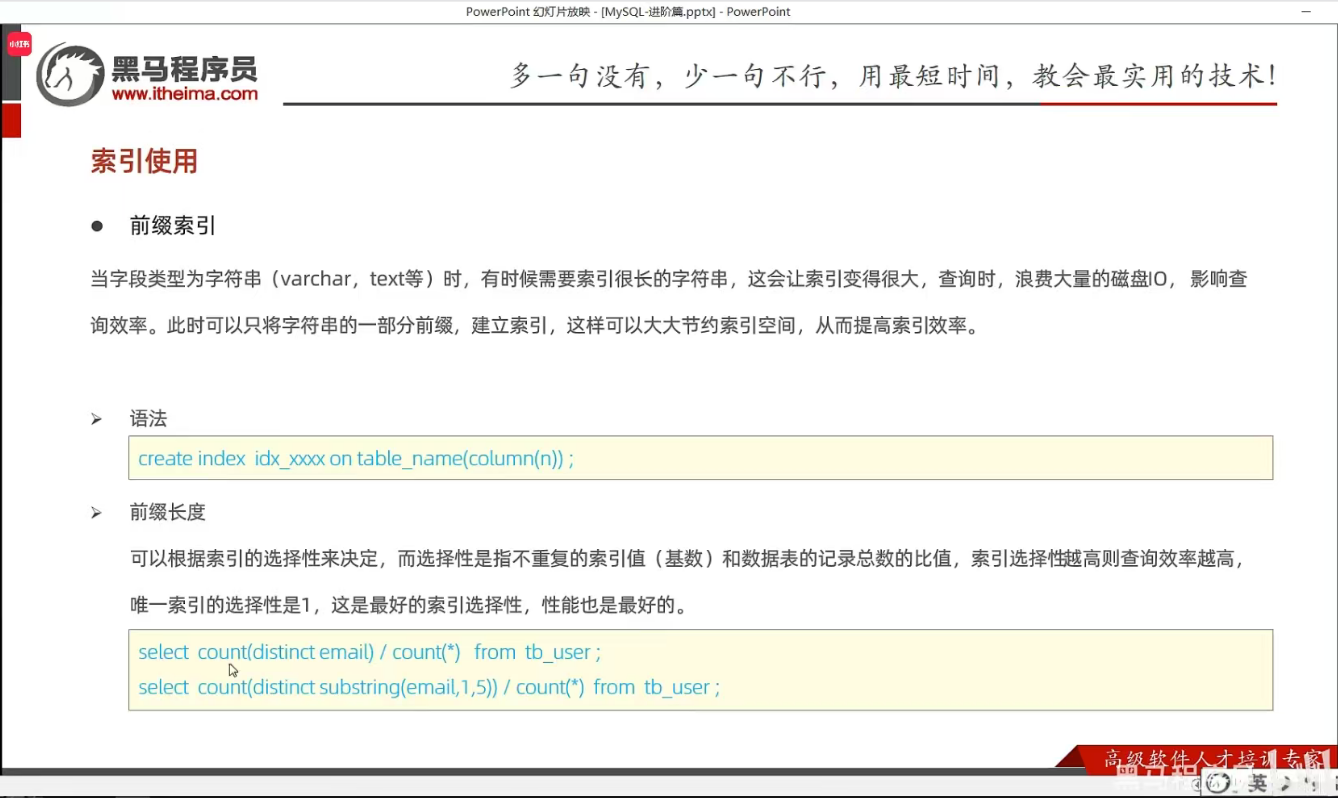
第六节 索引使用
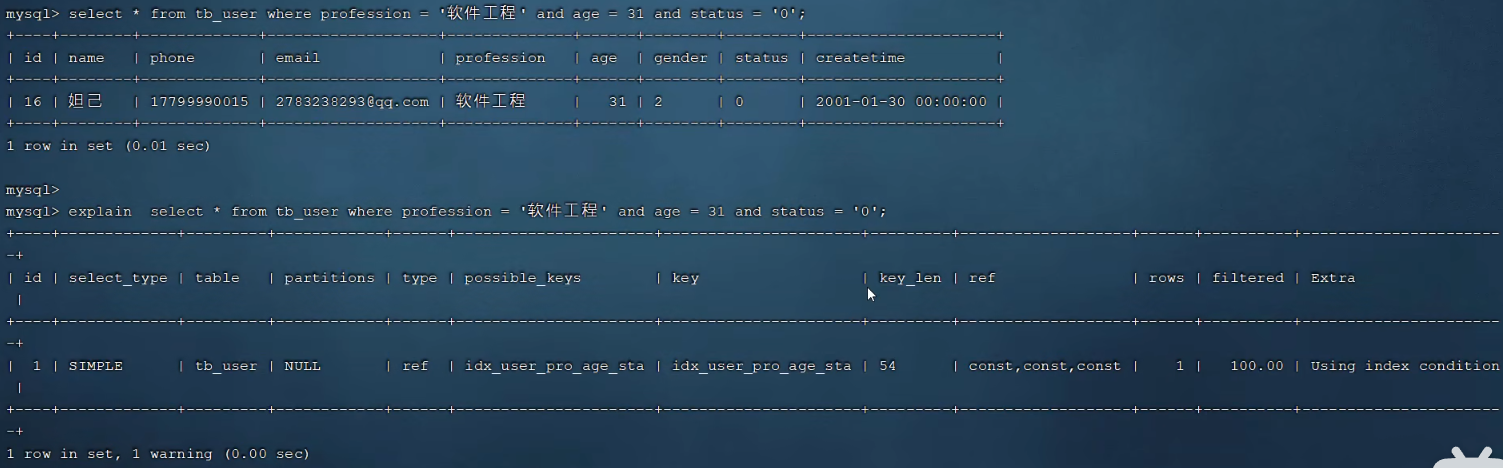
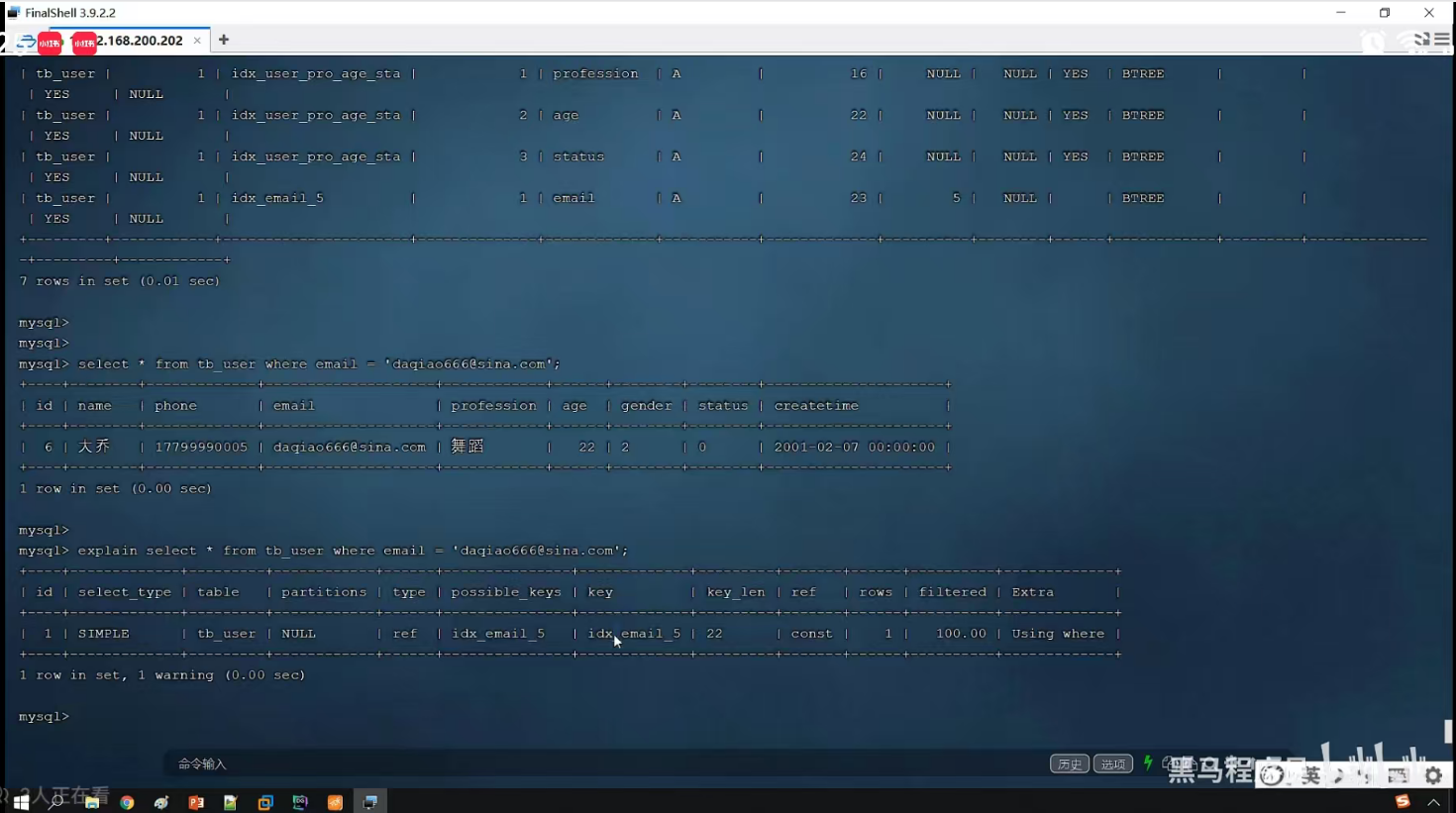
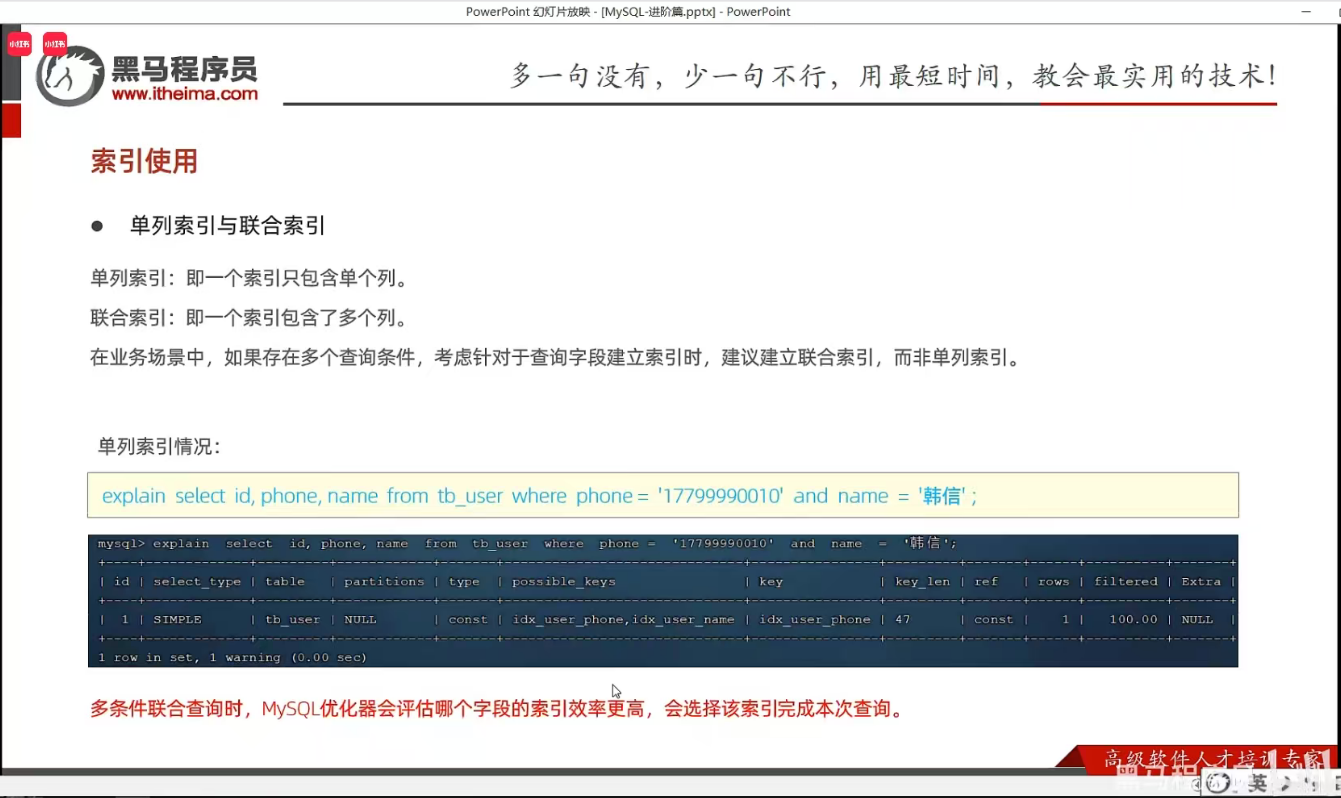
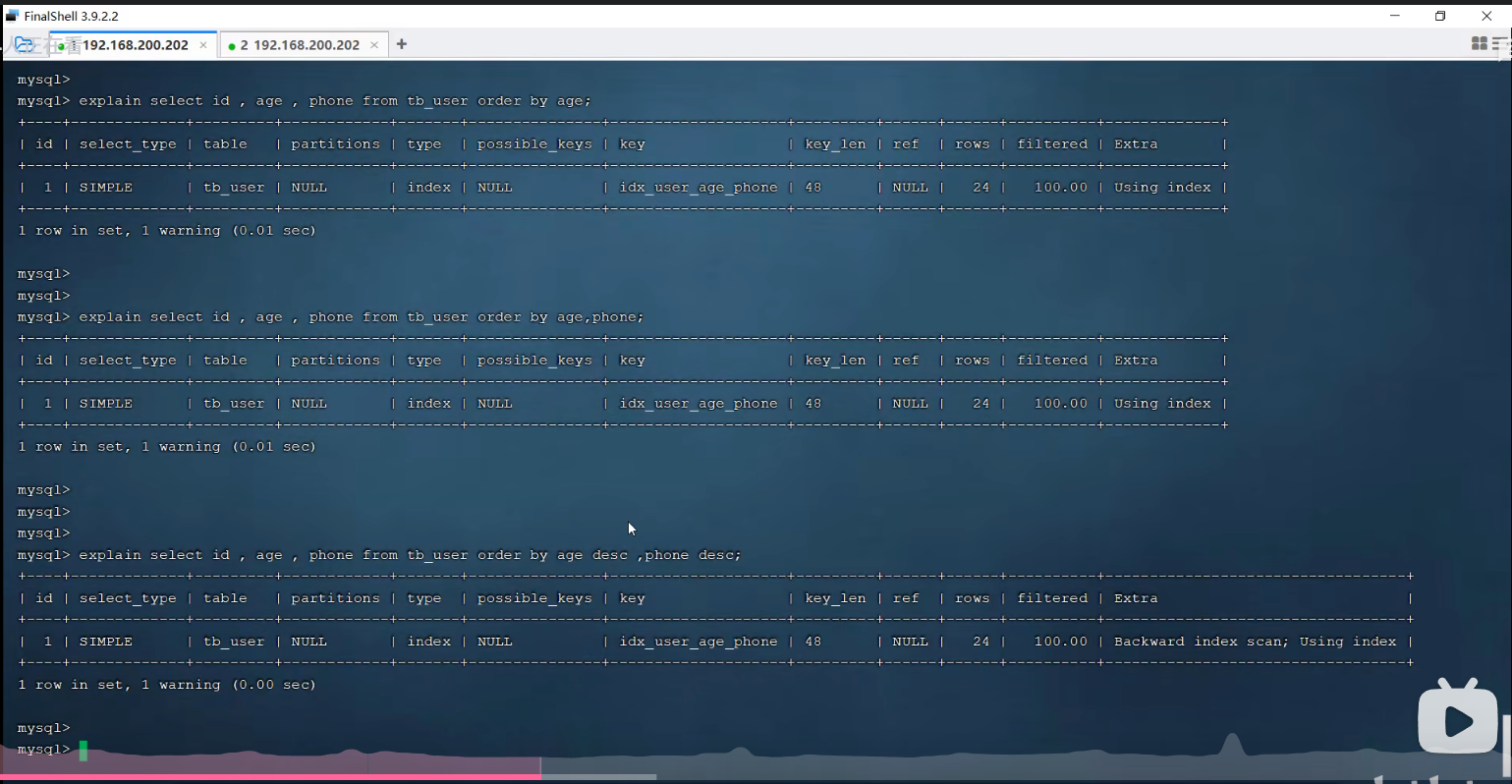
P22 验证索引效率
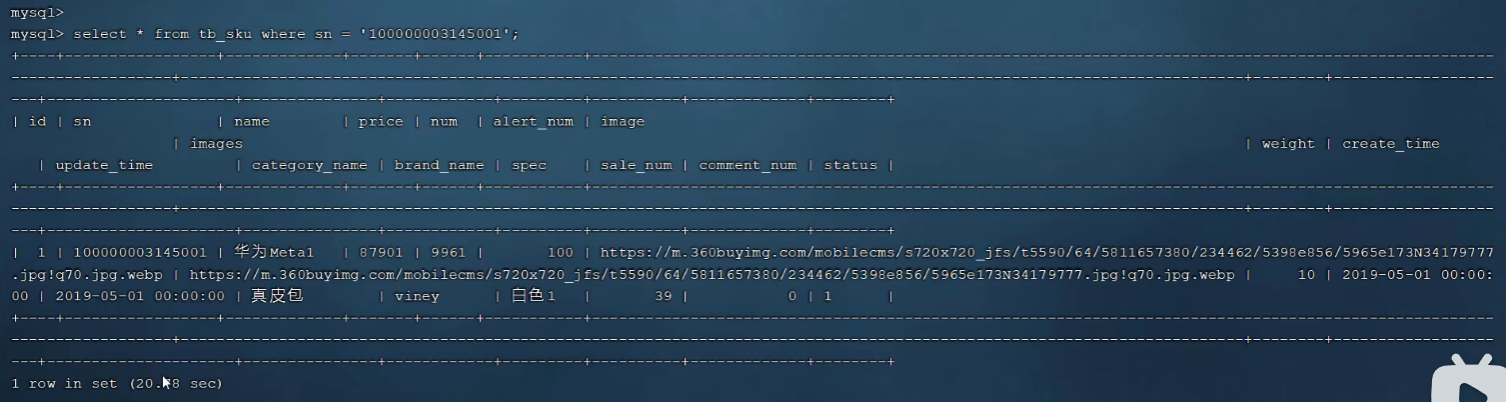
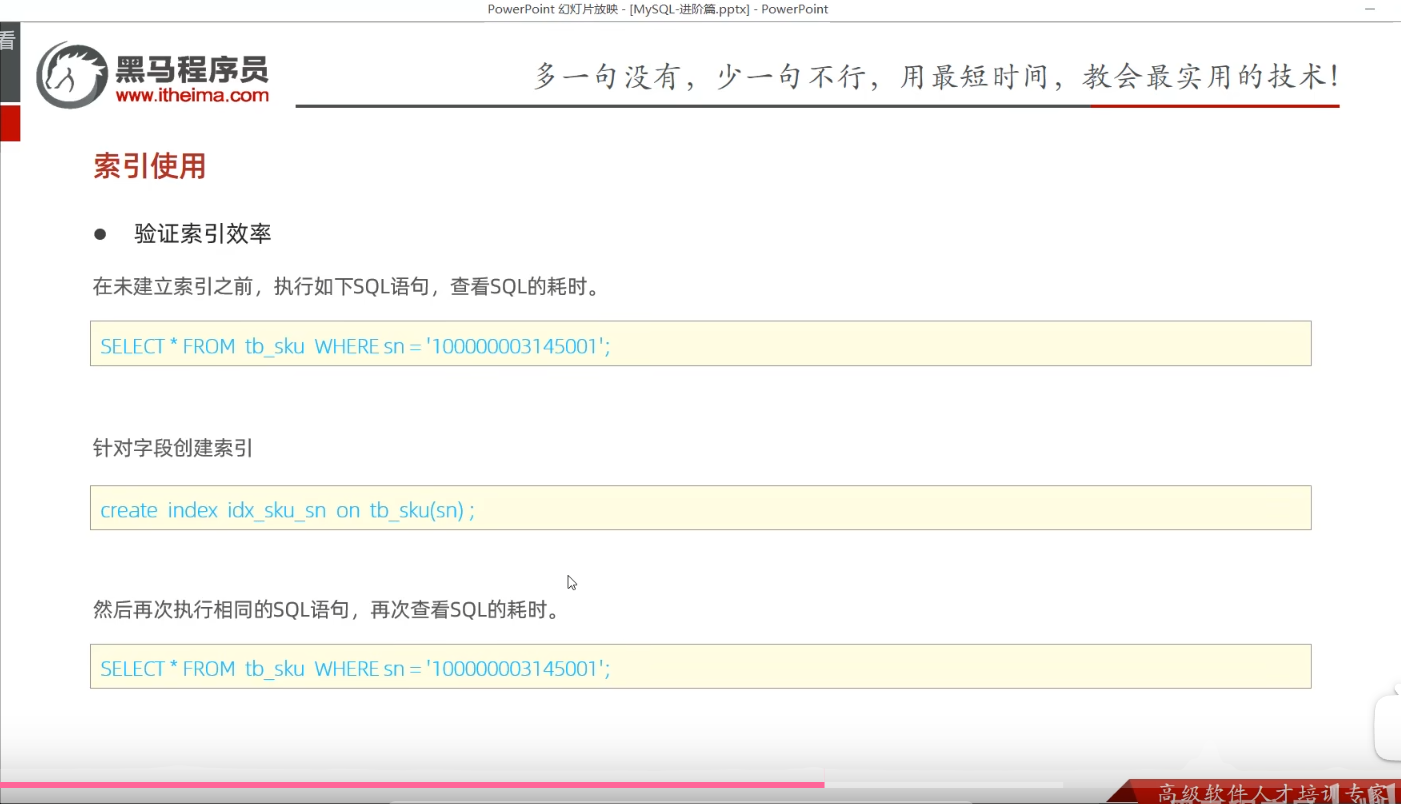

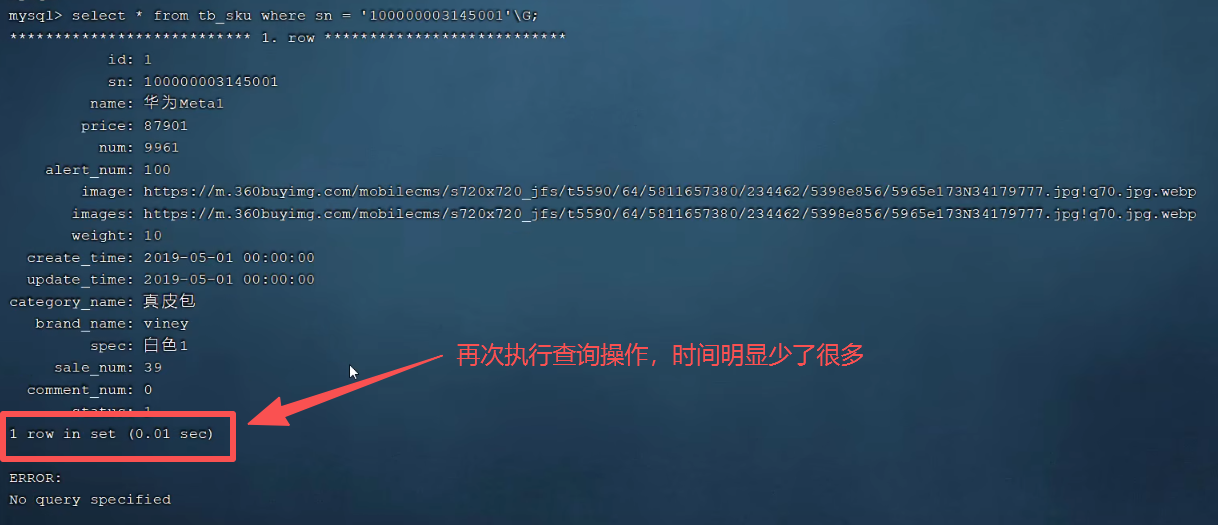
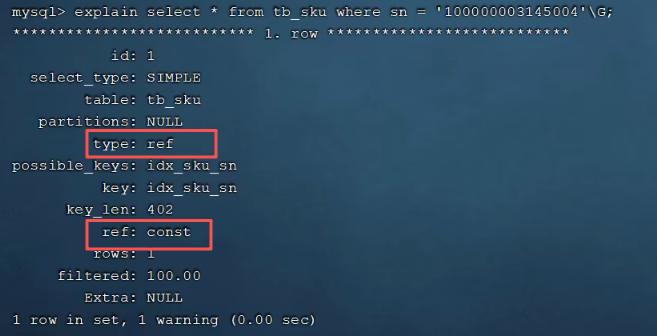
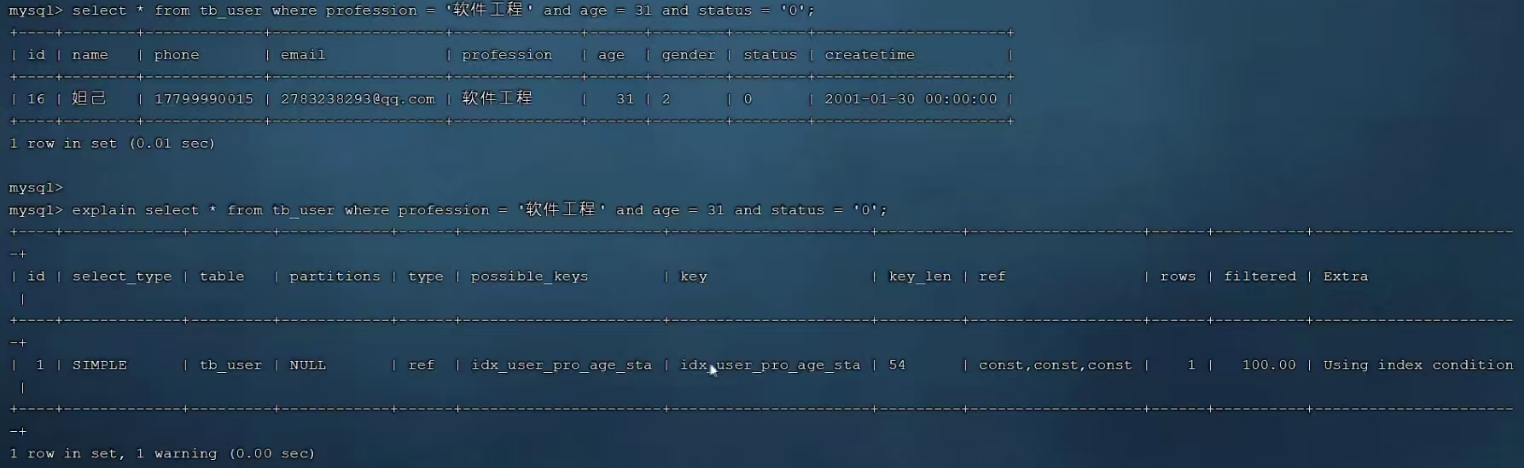
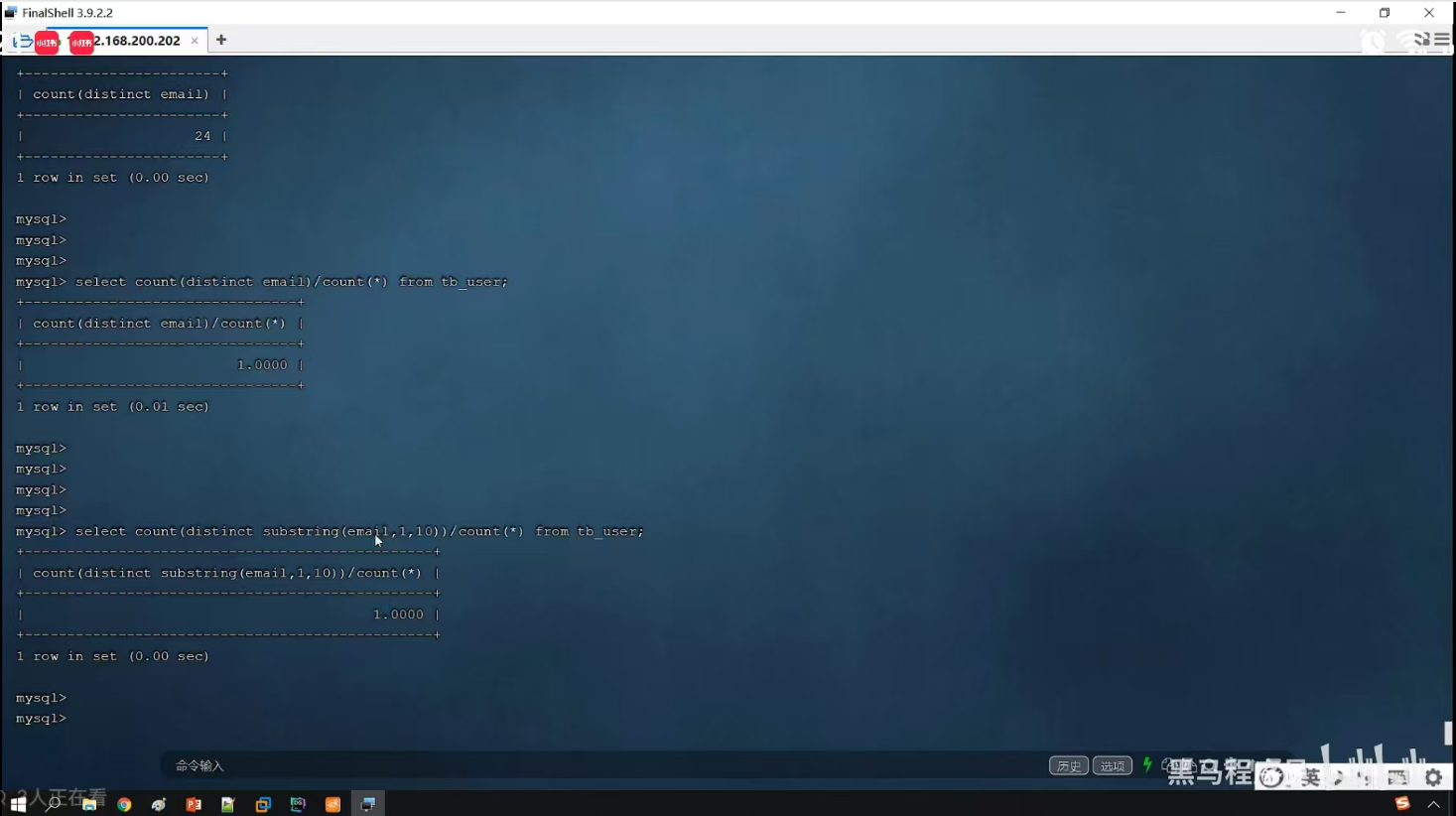
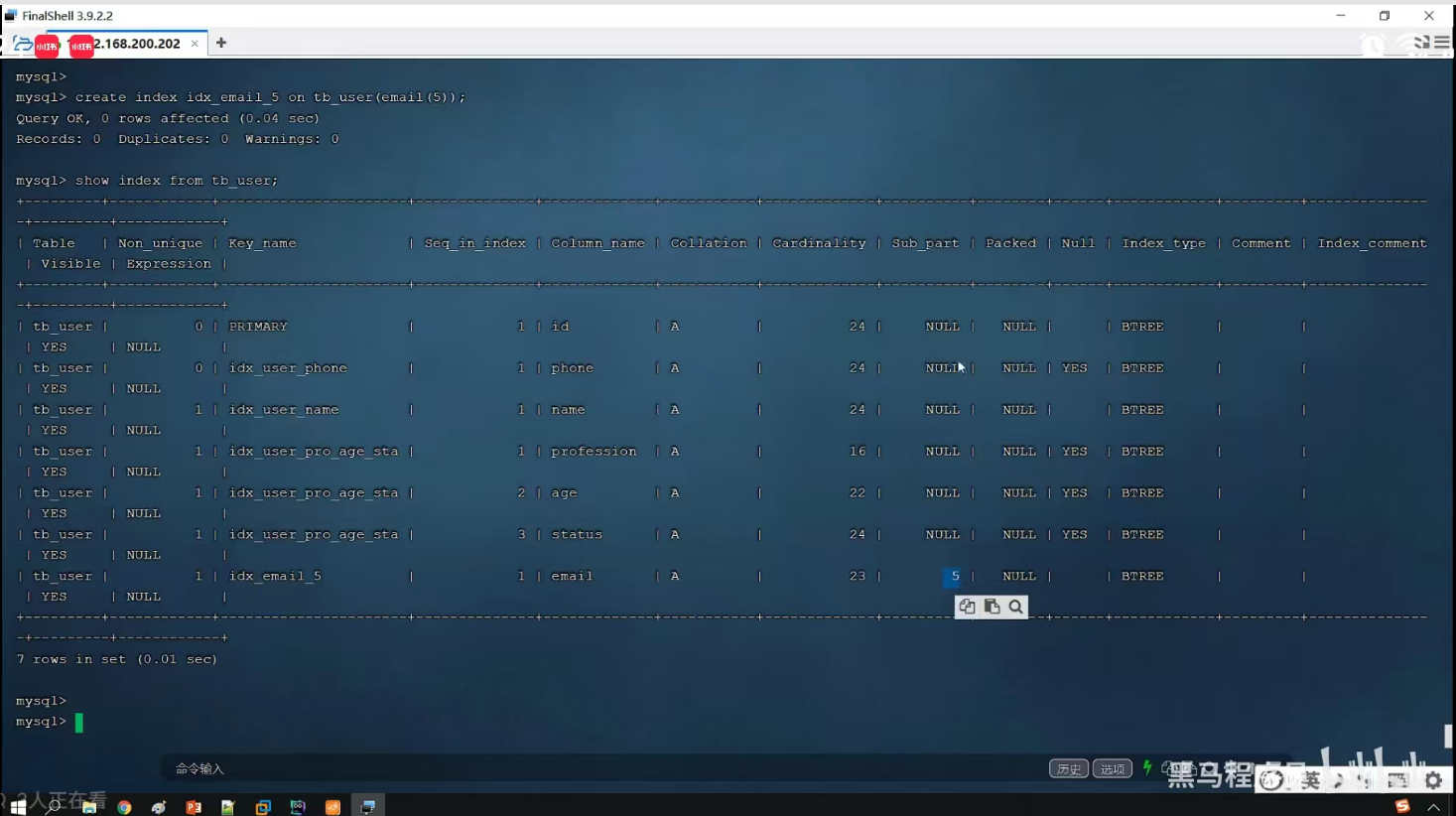
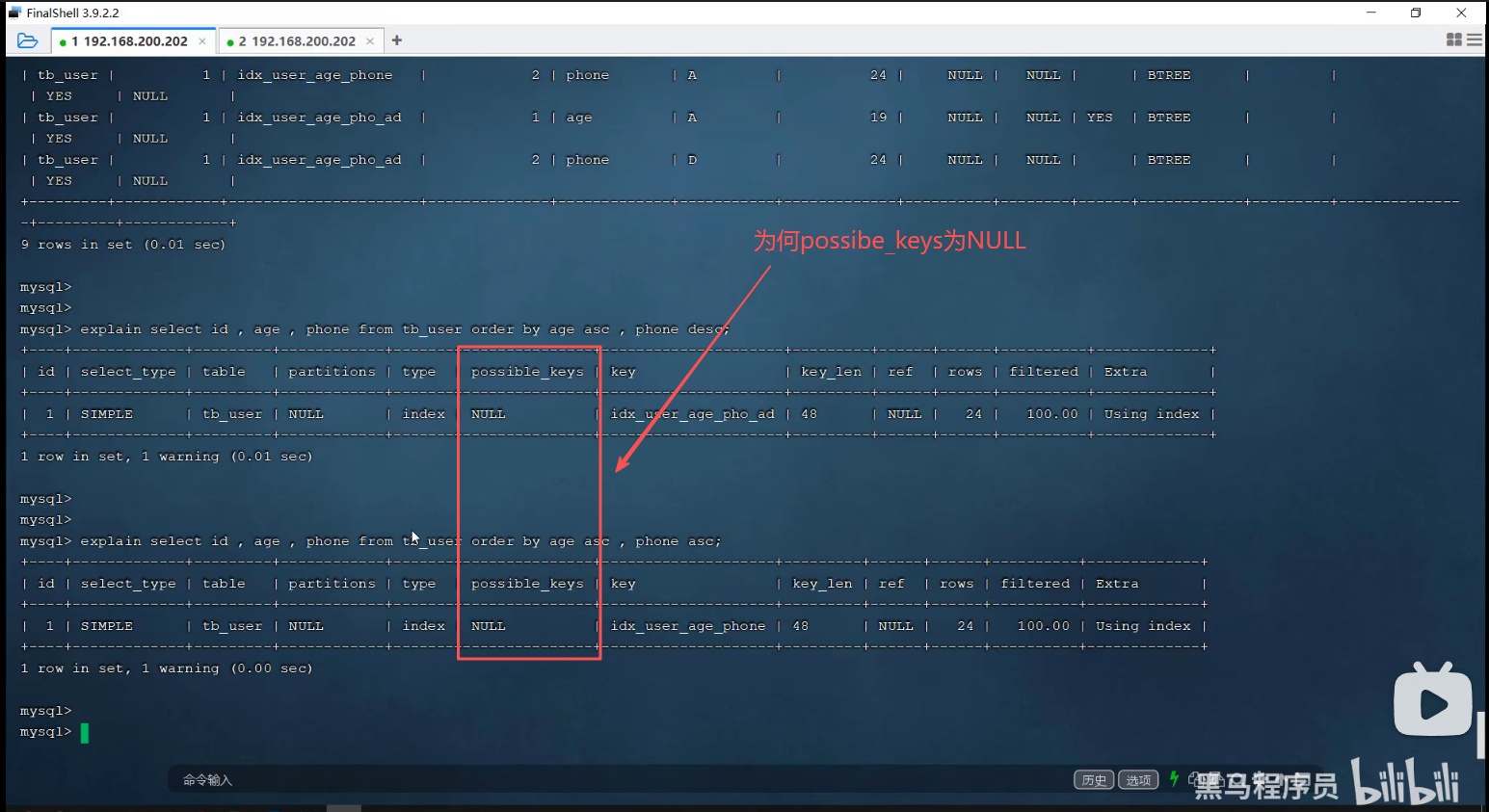
P23 最左前缀法则
一、最小前缀法则
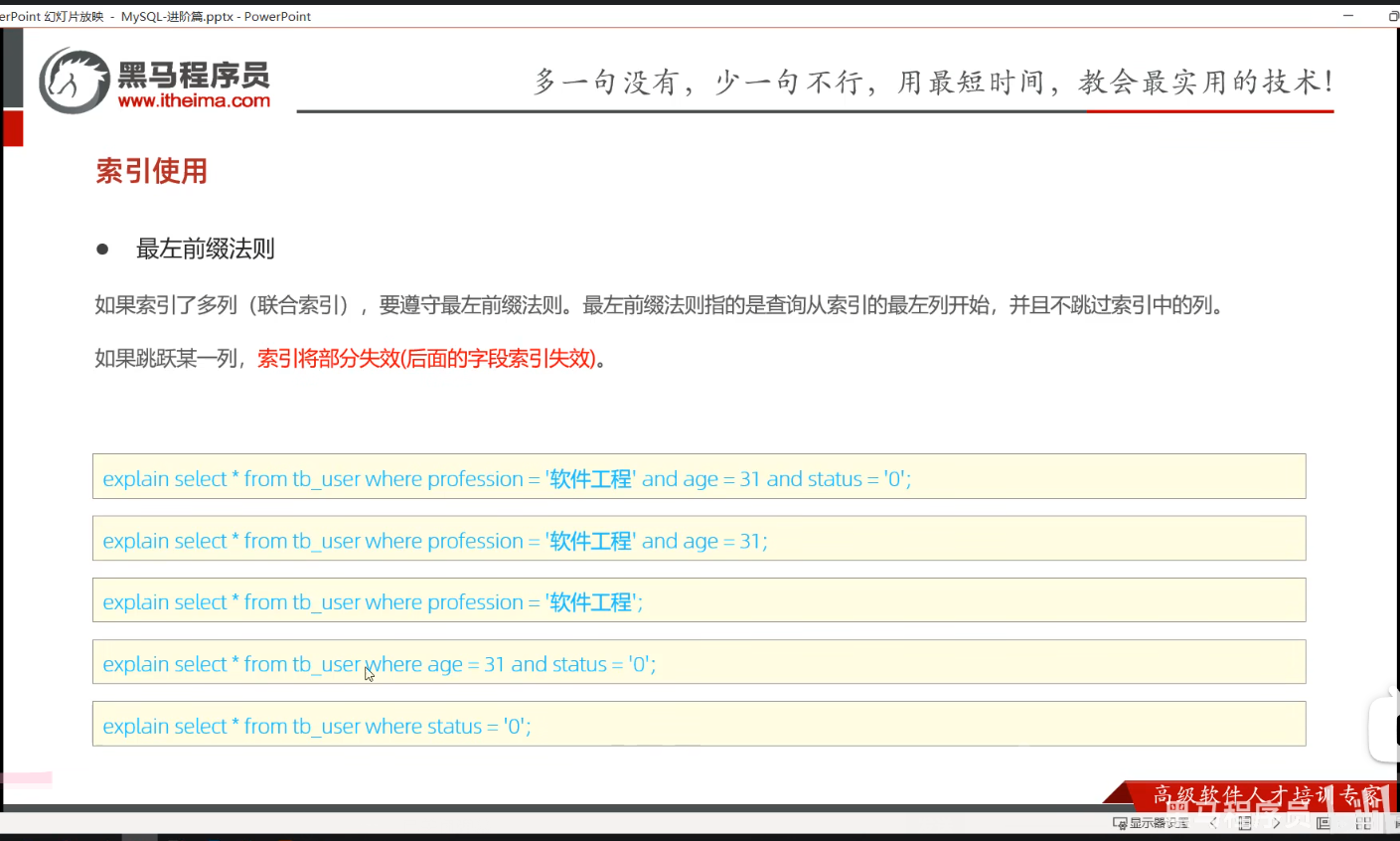
通俗解释:第1个字段值必须存在,并且中间不能跳过某一列,如果跳过,则后面的索引将失效。
1.条件为联合索引的3个列
2.索引为索引的前两个列
3.索引为索引的第一个列

4.跳过最前面的列,索引失效

5.同样符合跳过了最前面的列,索引失效

6.跳过中间索引列,即跳过的那一个中间索引后面的索引失效

7.最小前缀法则,符合第一个字段必须存在,因此生效。可见第一个字段存在的顺序未必一定要放第一位
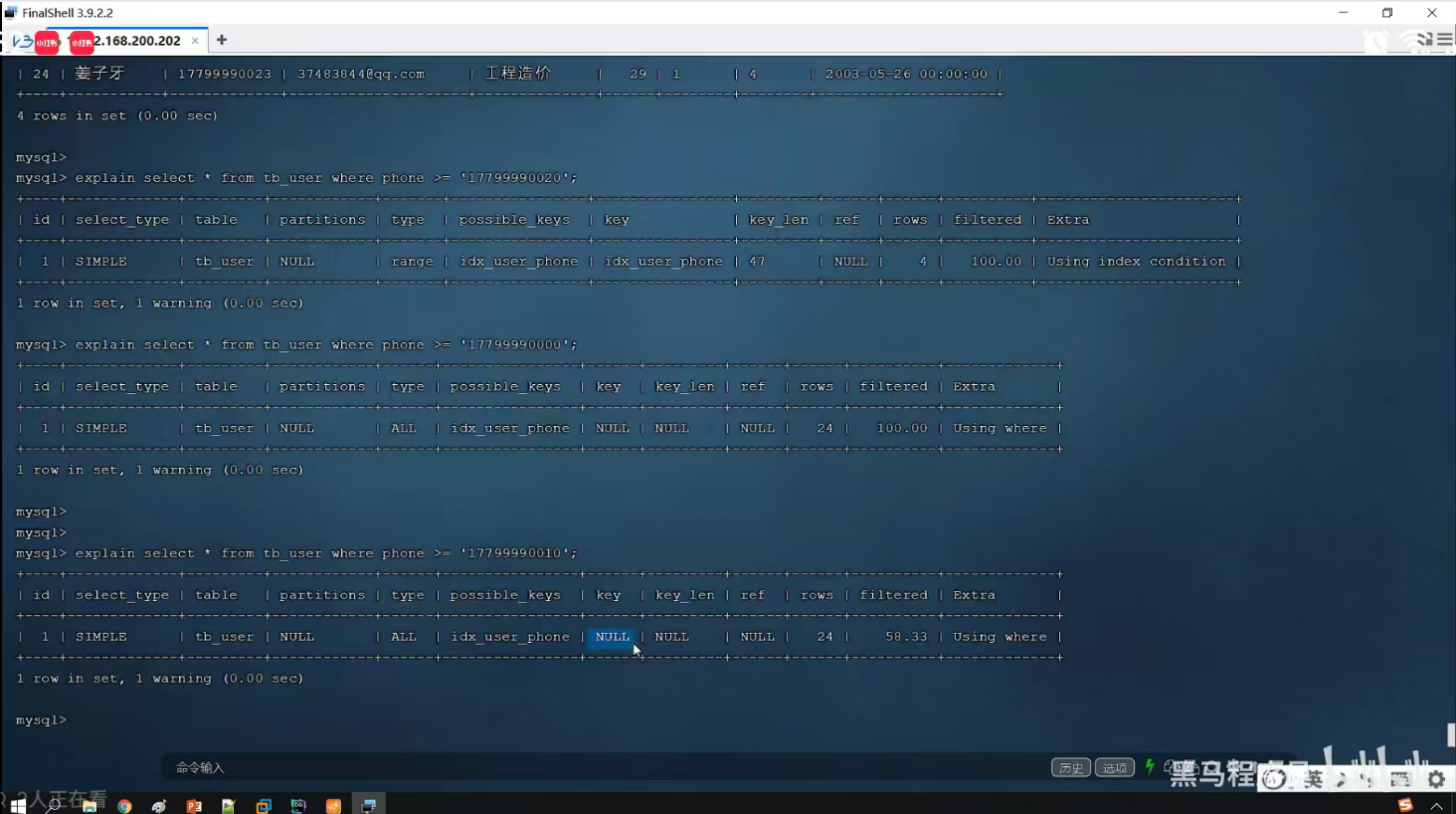
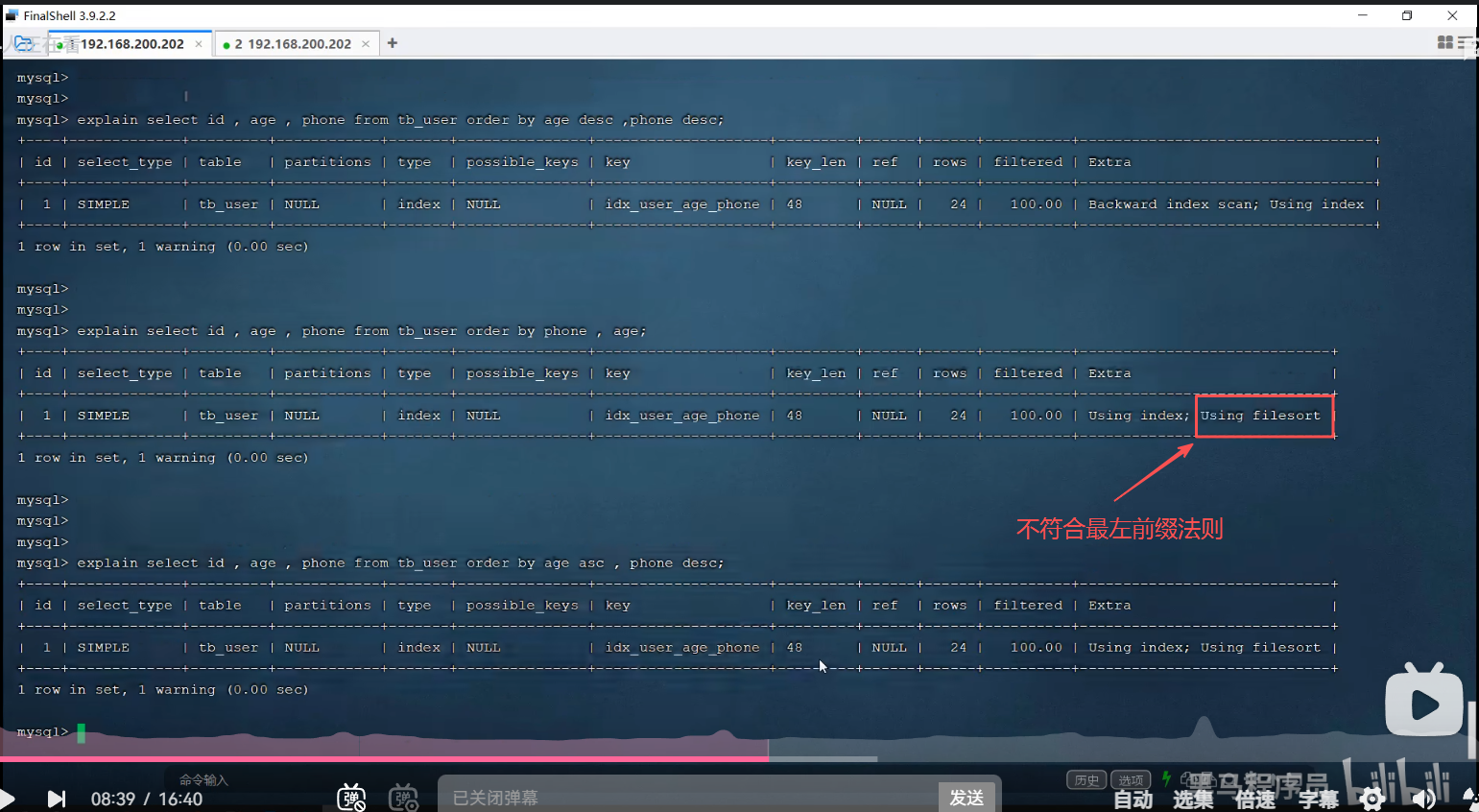
二、范围查询
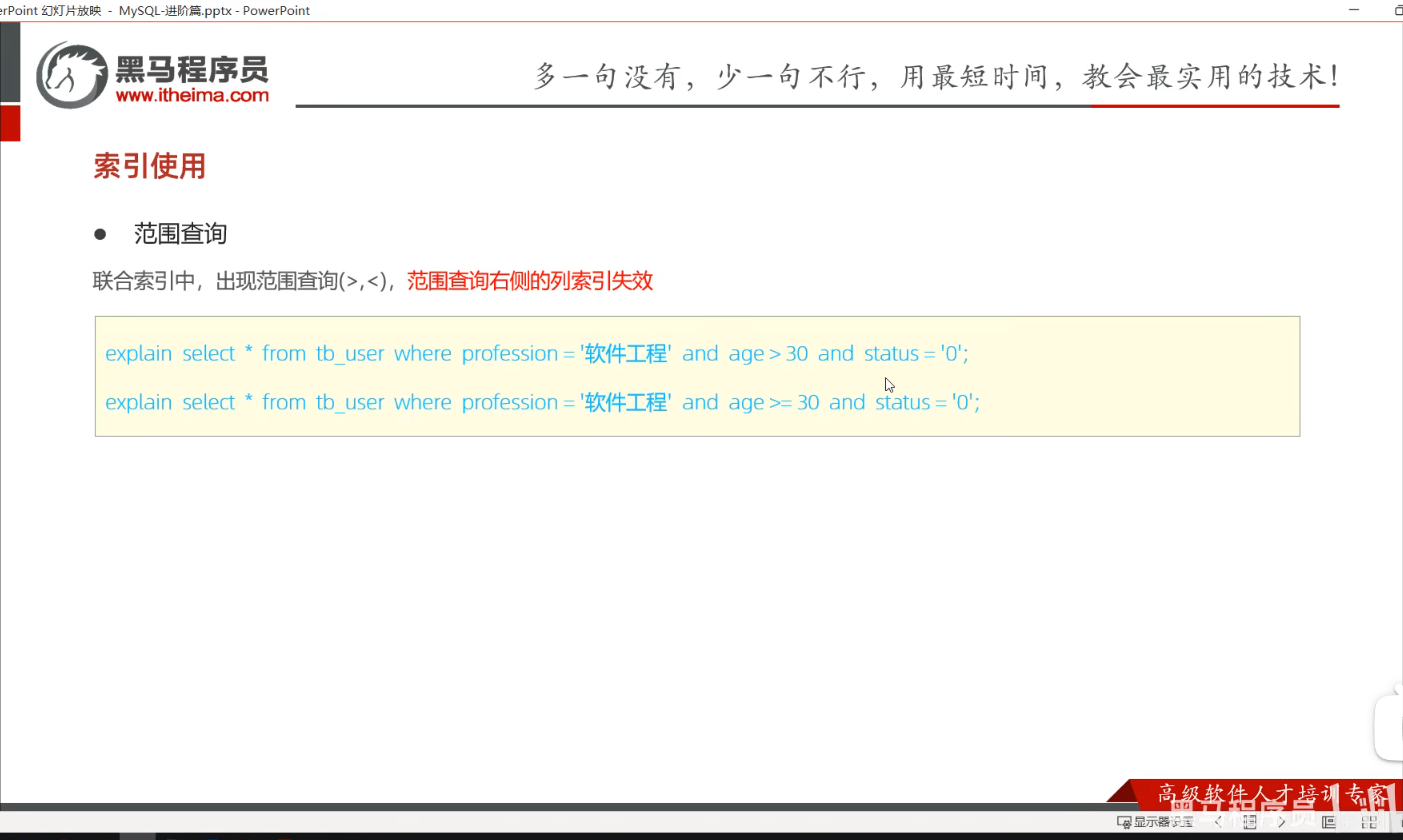
1.age>30右侧的索引失效

2.为规避失效问题,可以使用>=

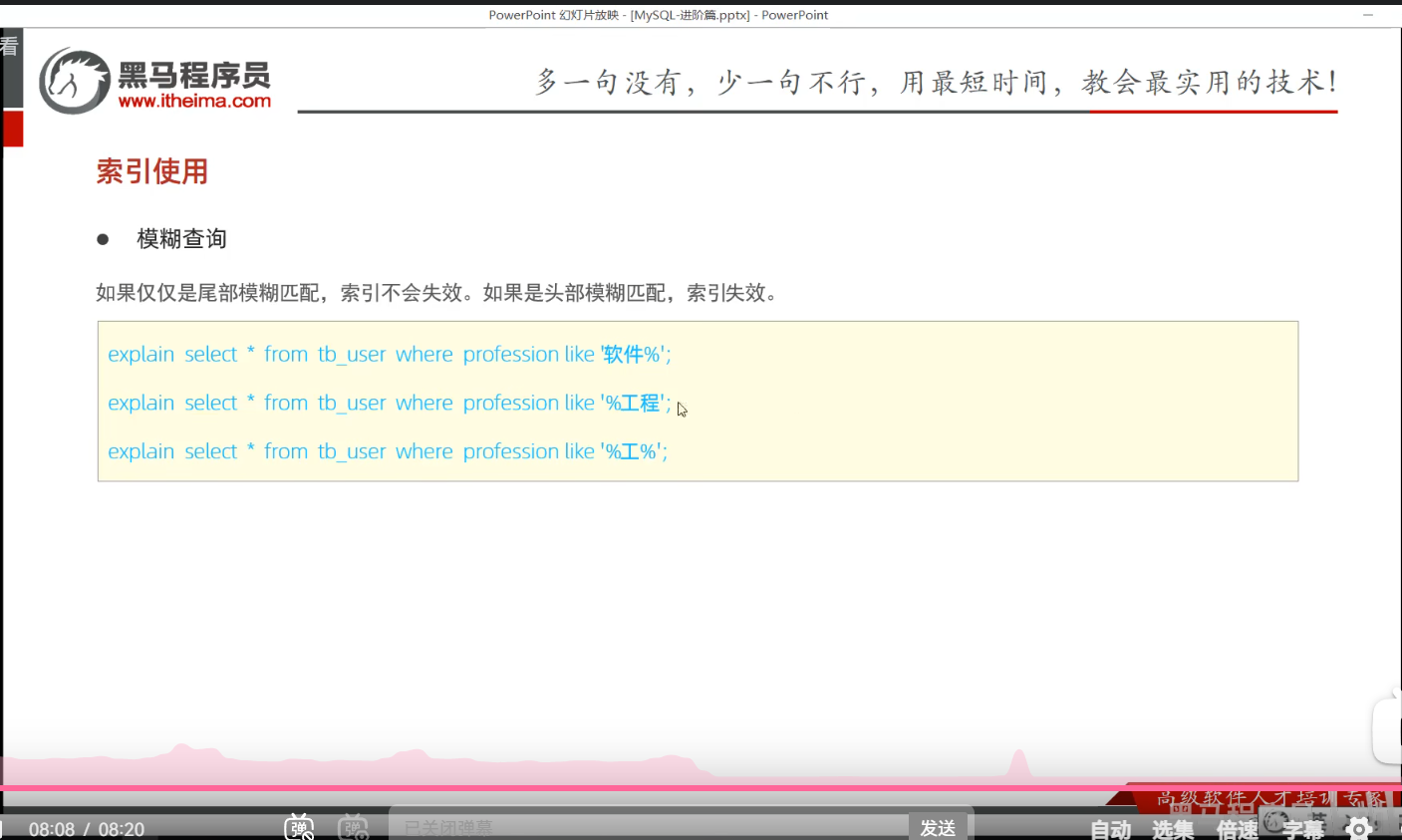
P24 索引失效情况一
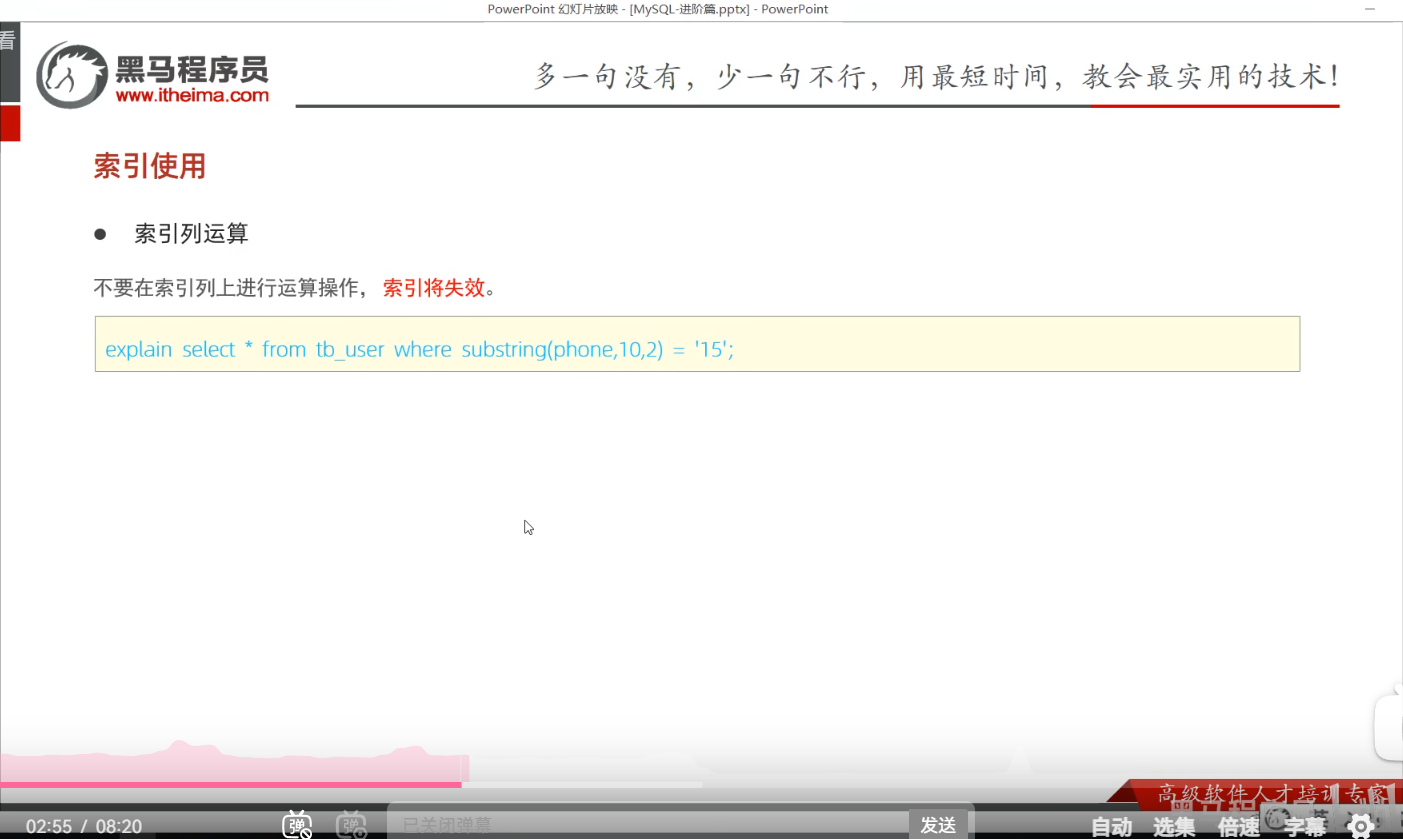
失效

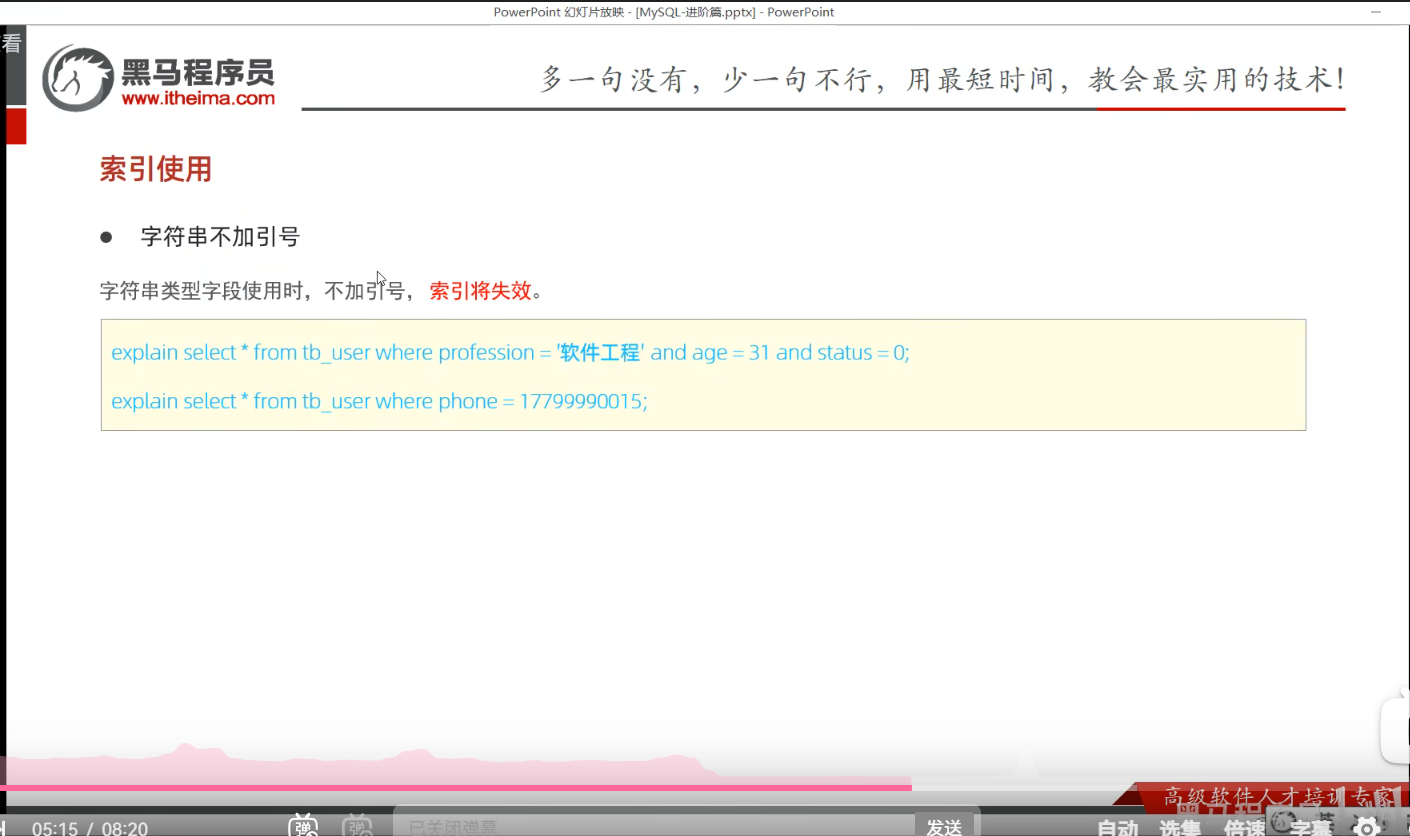


有效

失效

失效

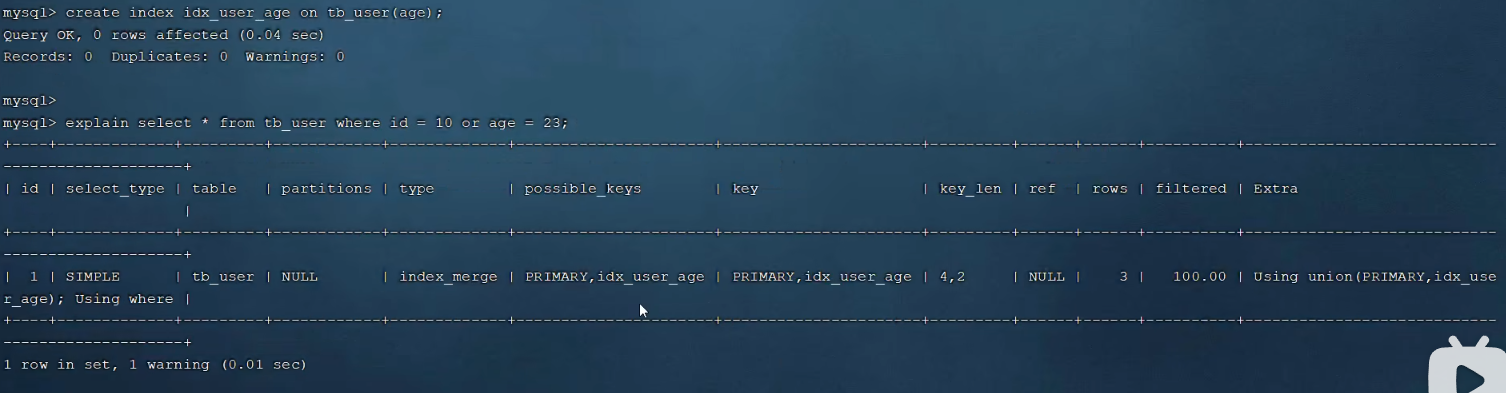
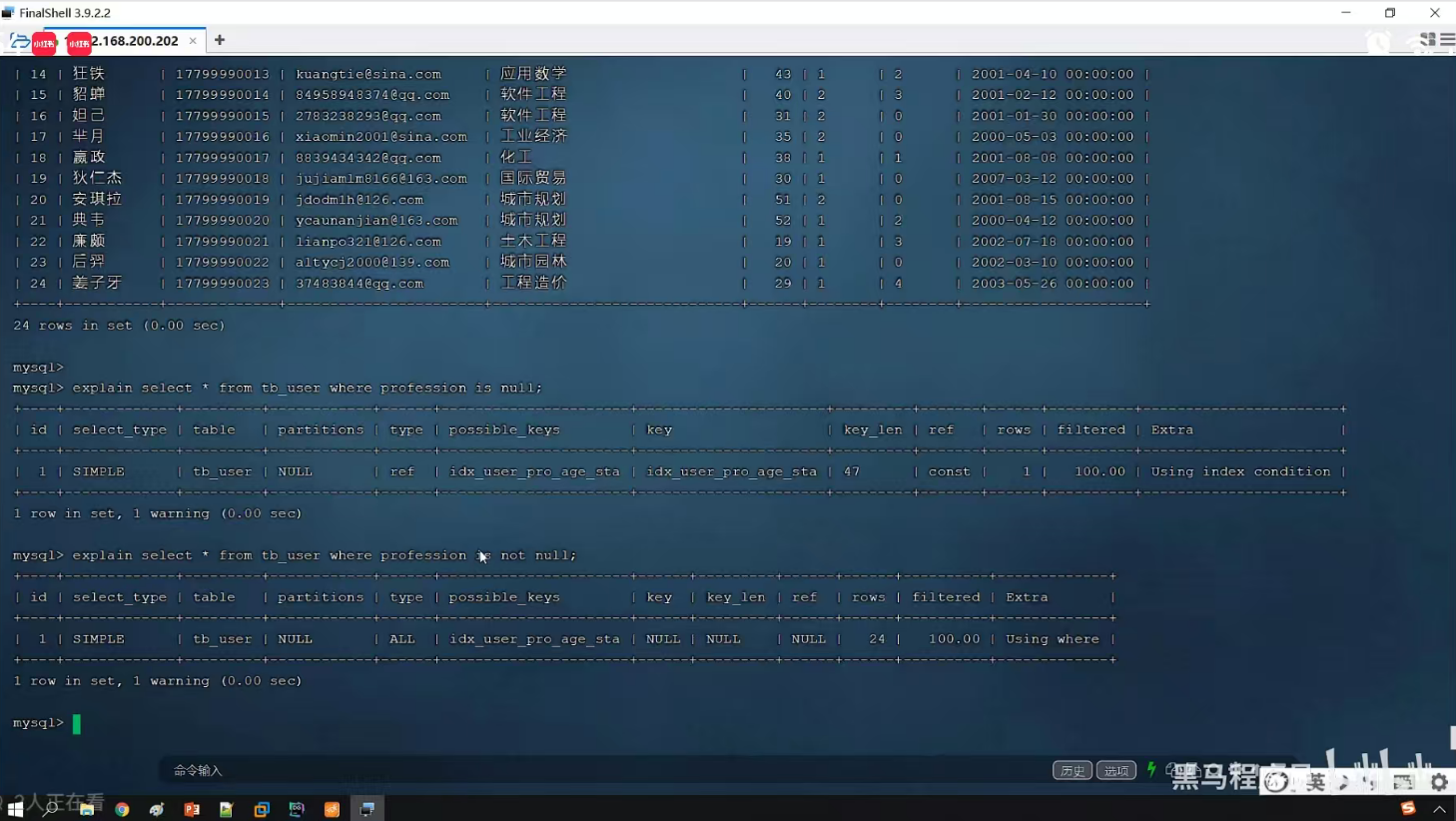
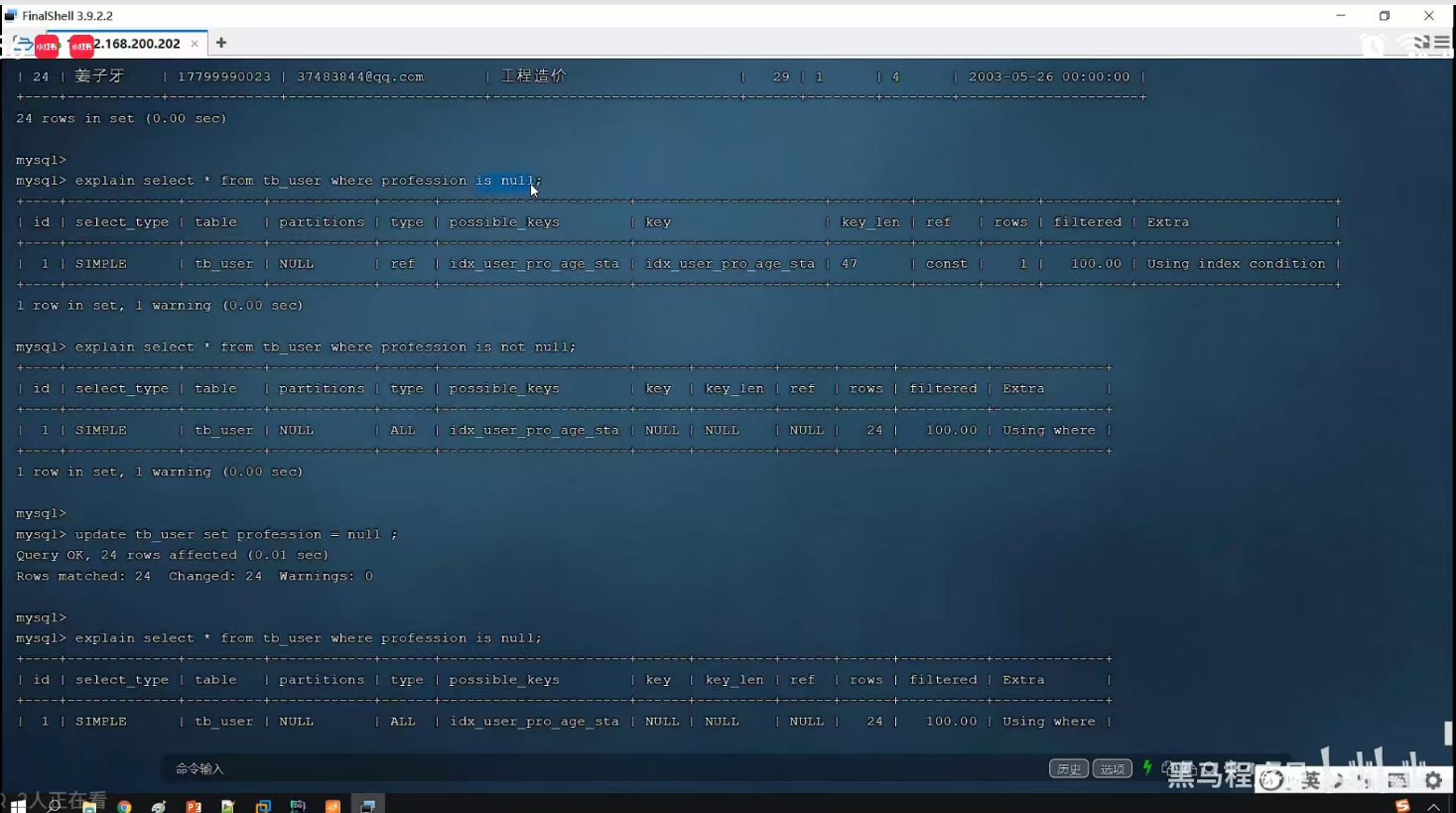
P25 索引失效情况二
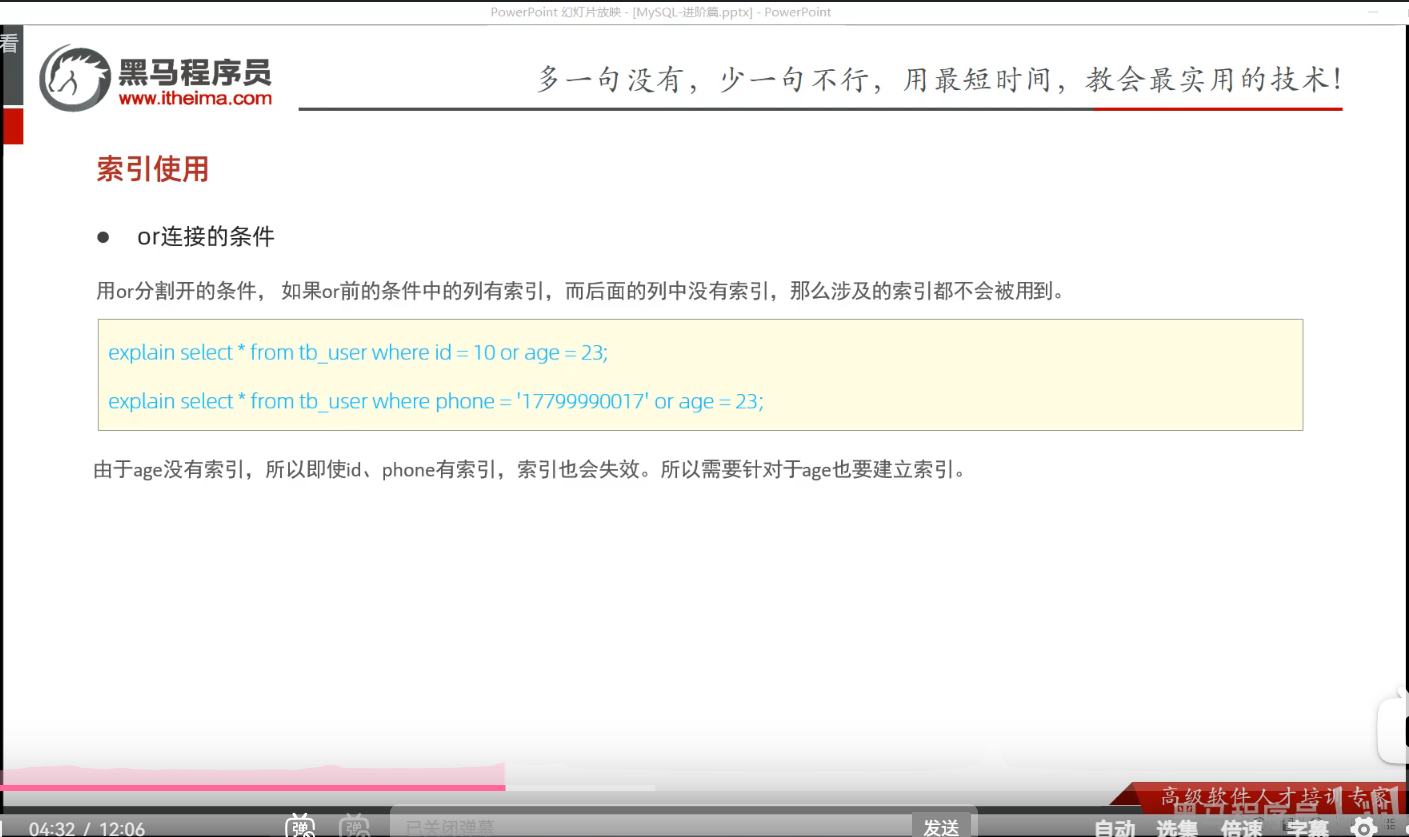


创建过索引再查询就有效

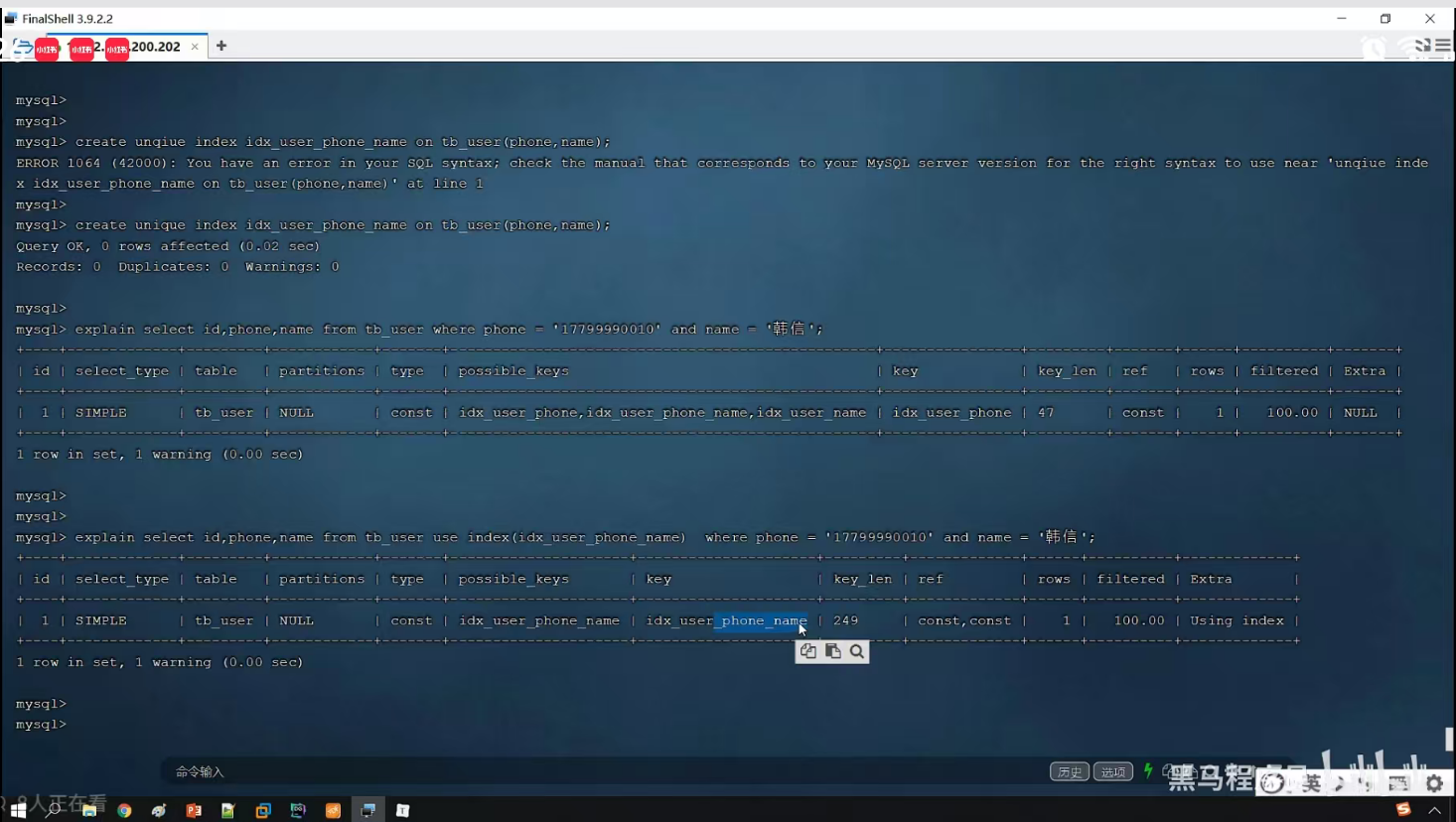
P26 SQL提示
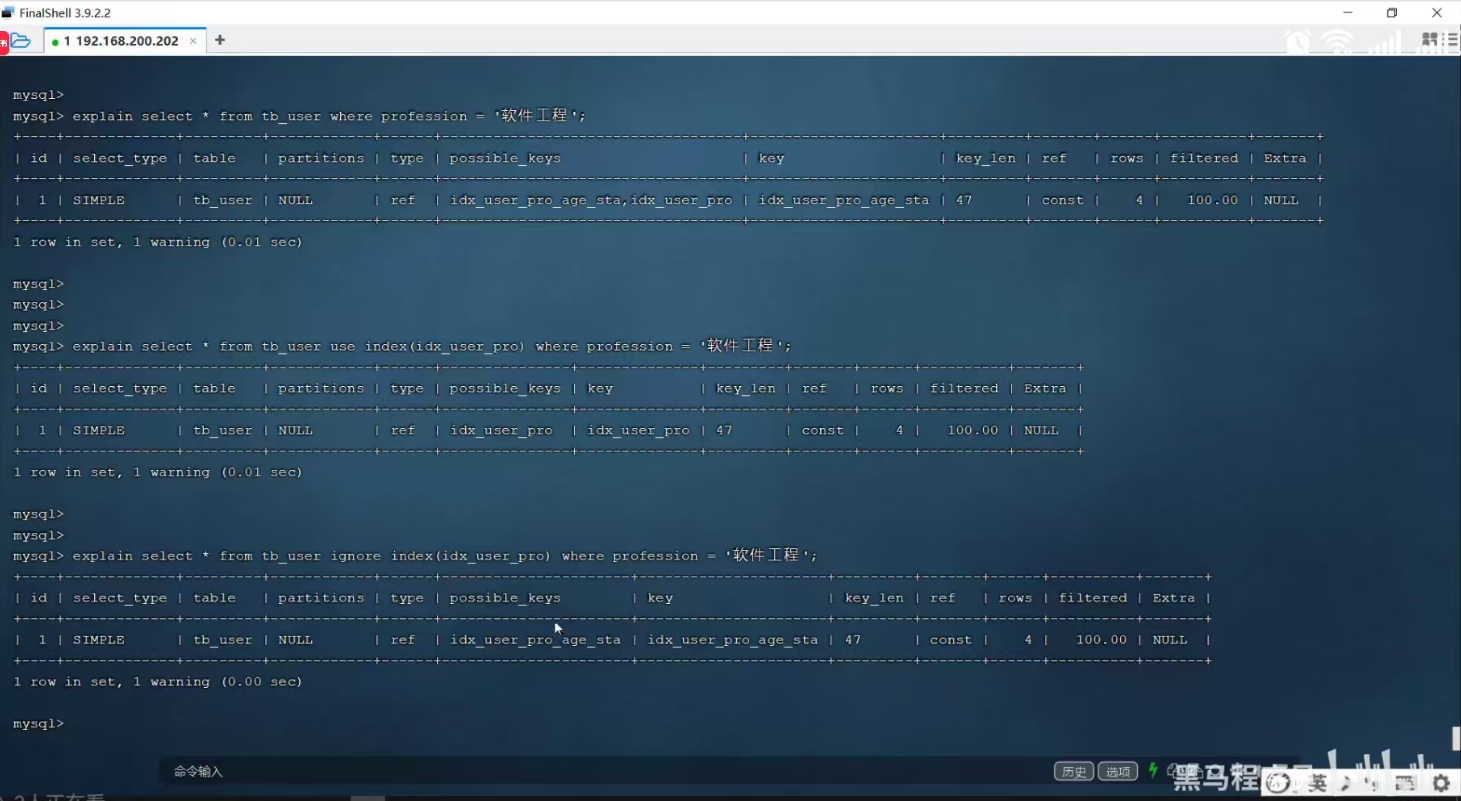
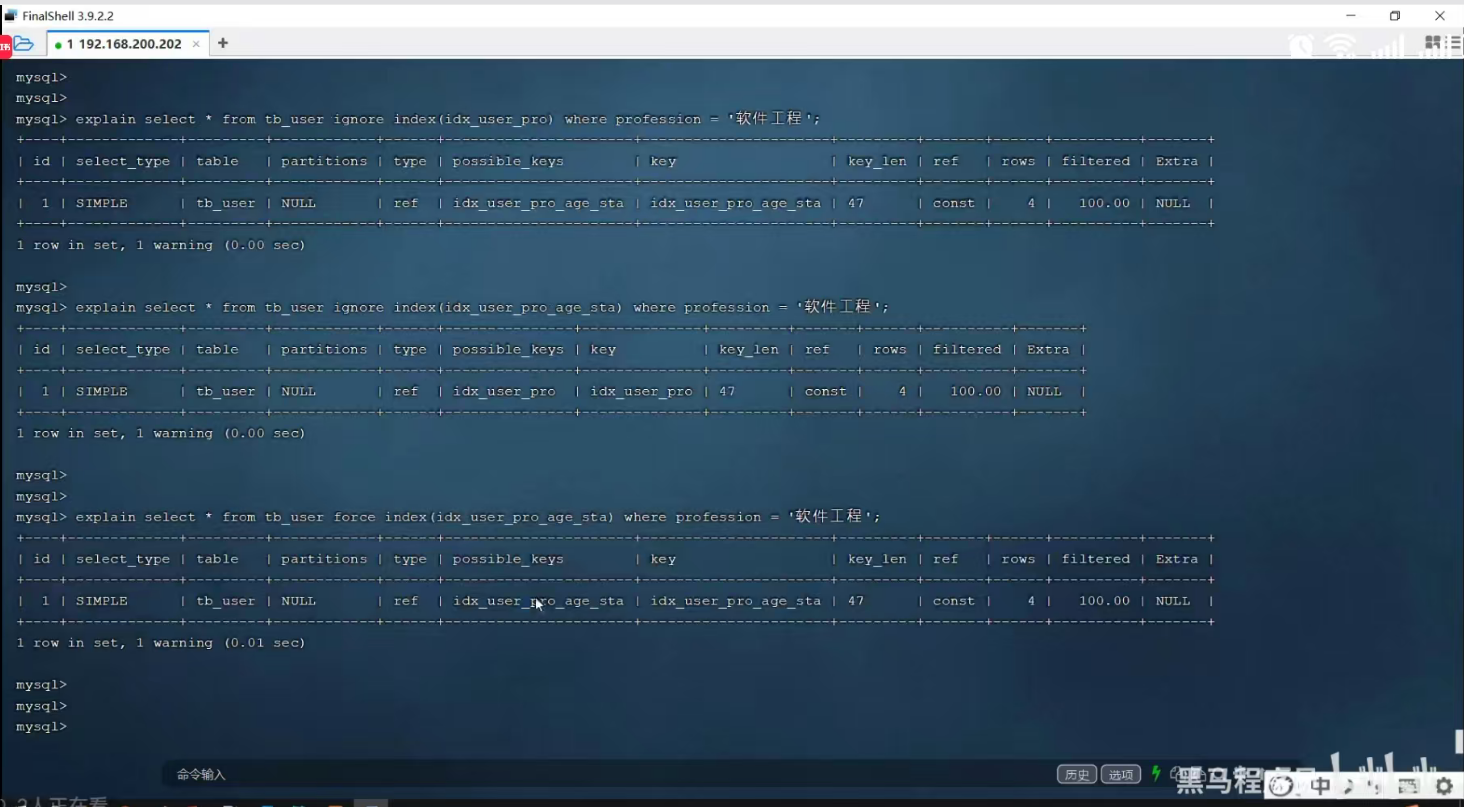
use index 建议使用某个索引
ignore index 忽略某个索引
force index 强制使用某个索引
P27 覆盖索引&回表查询
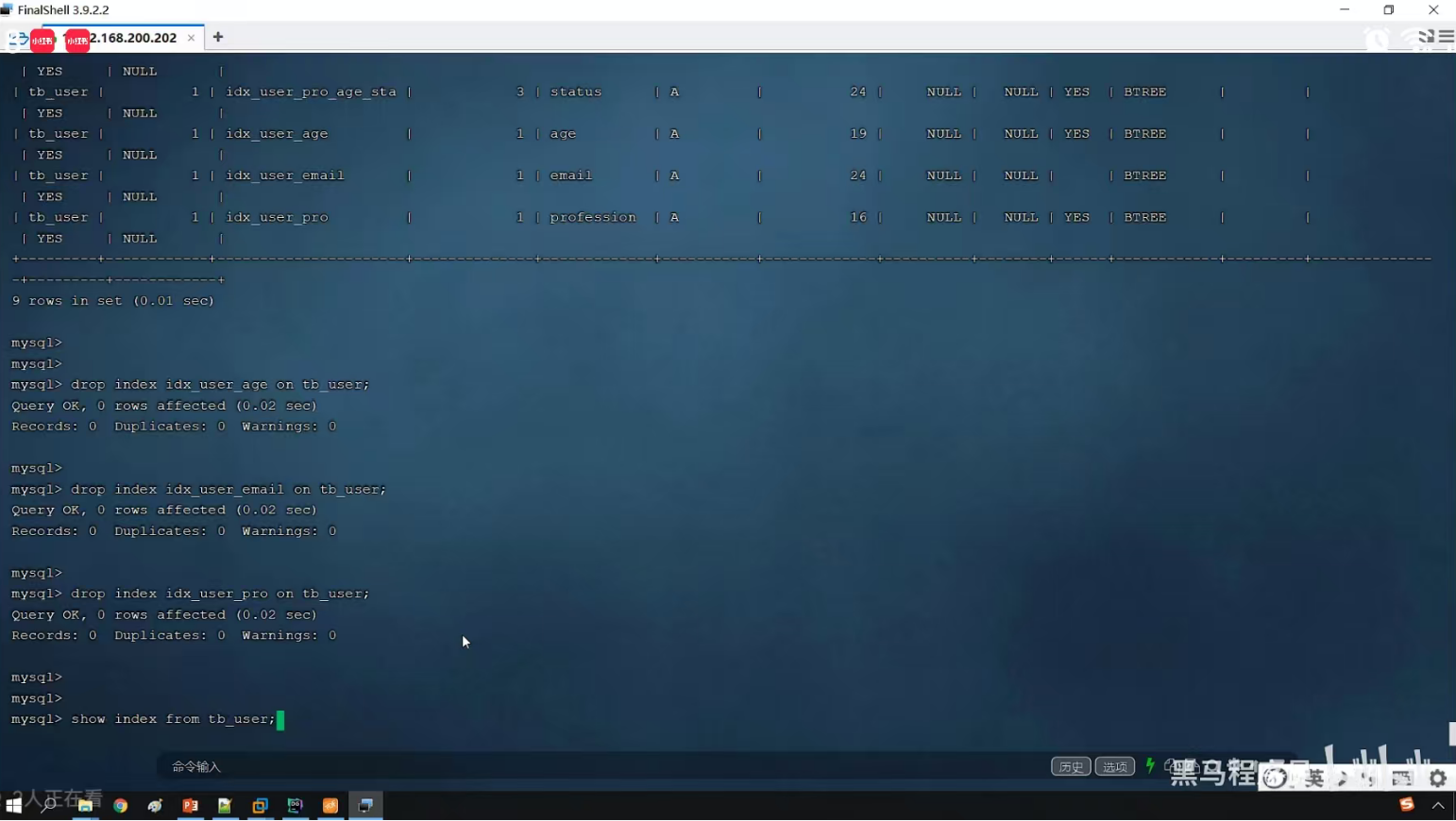

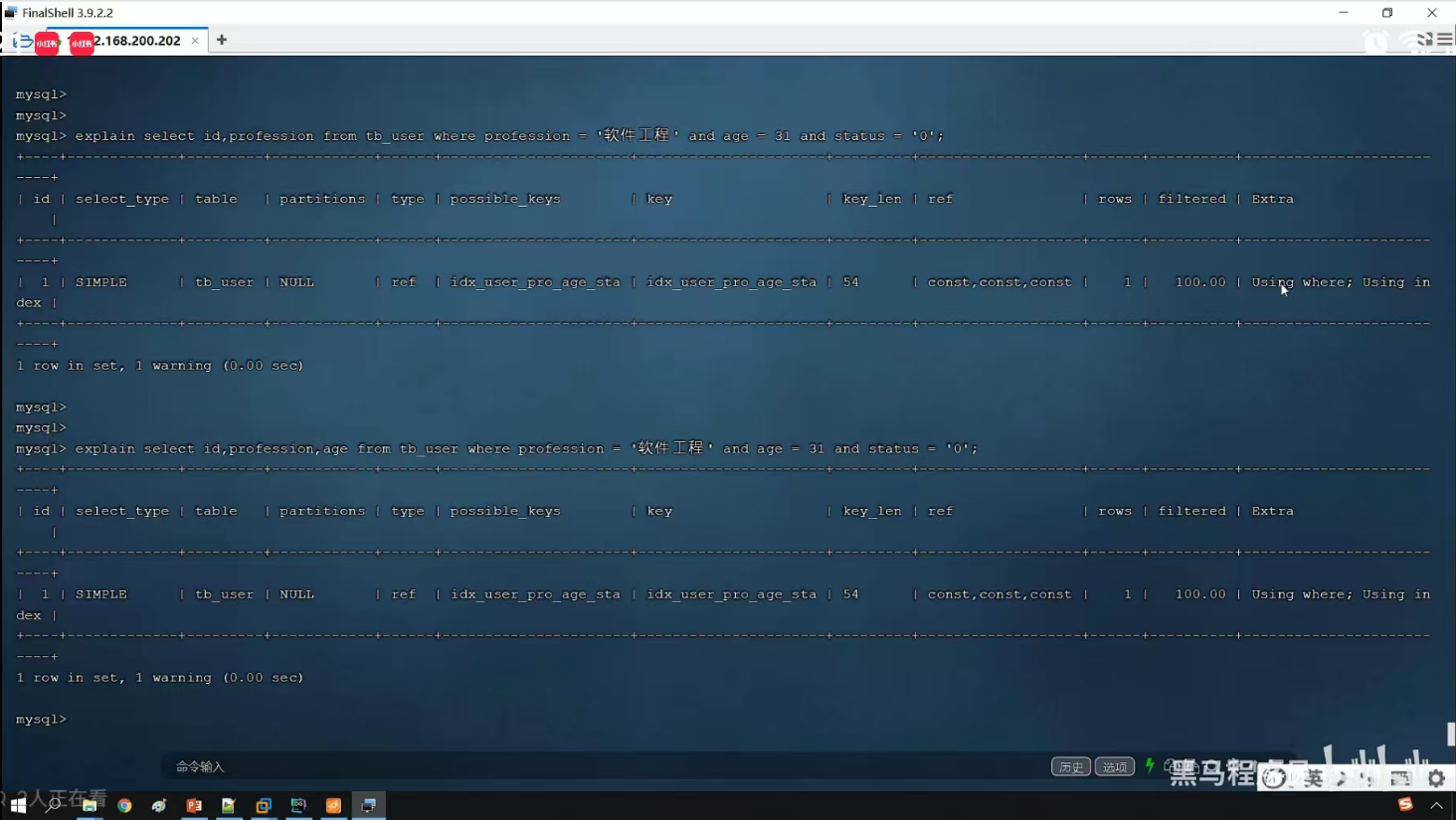
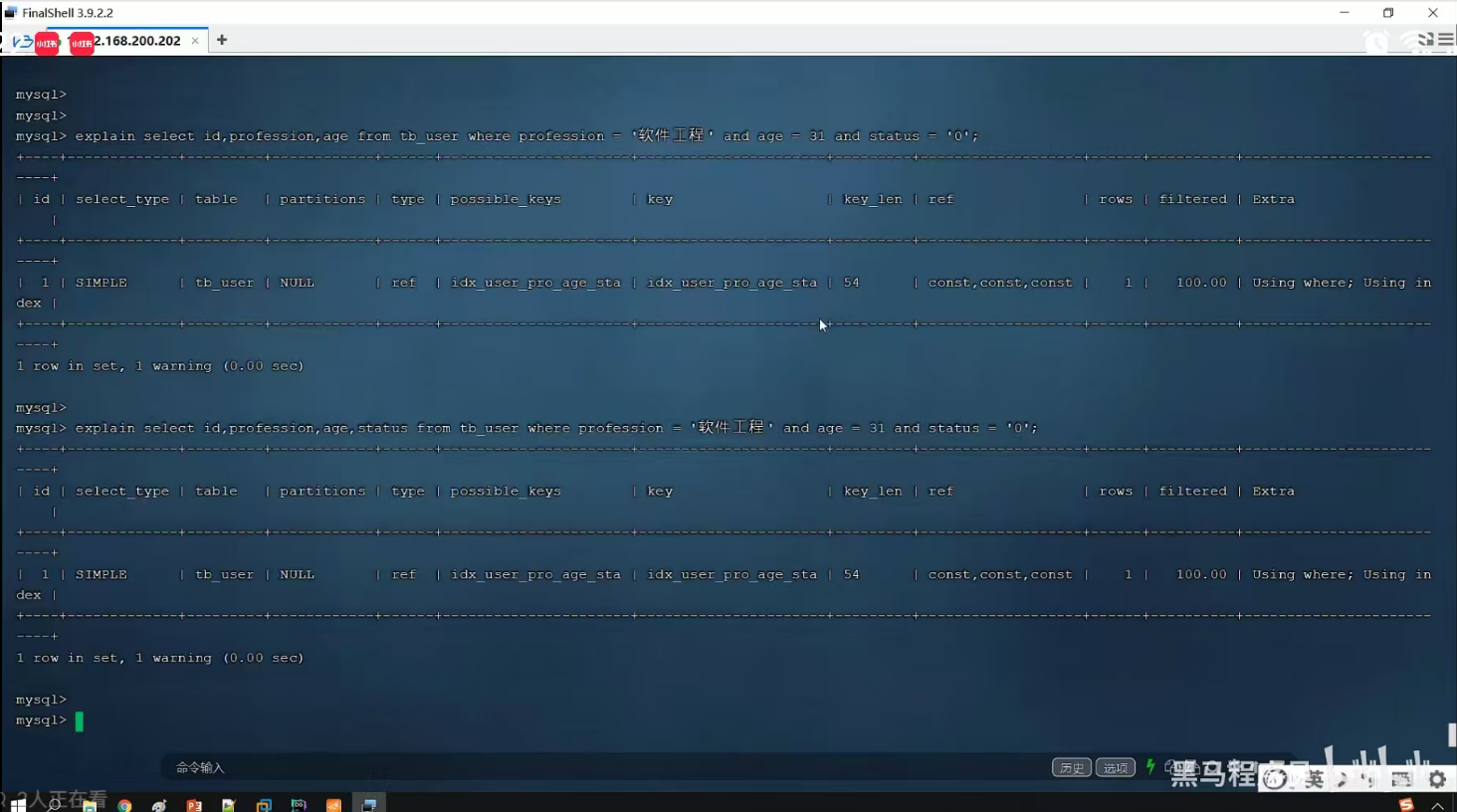
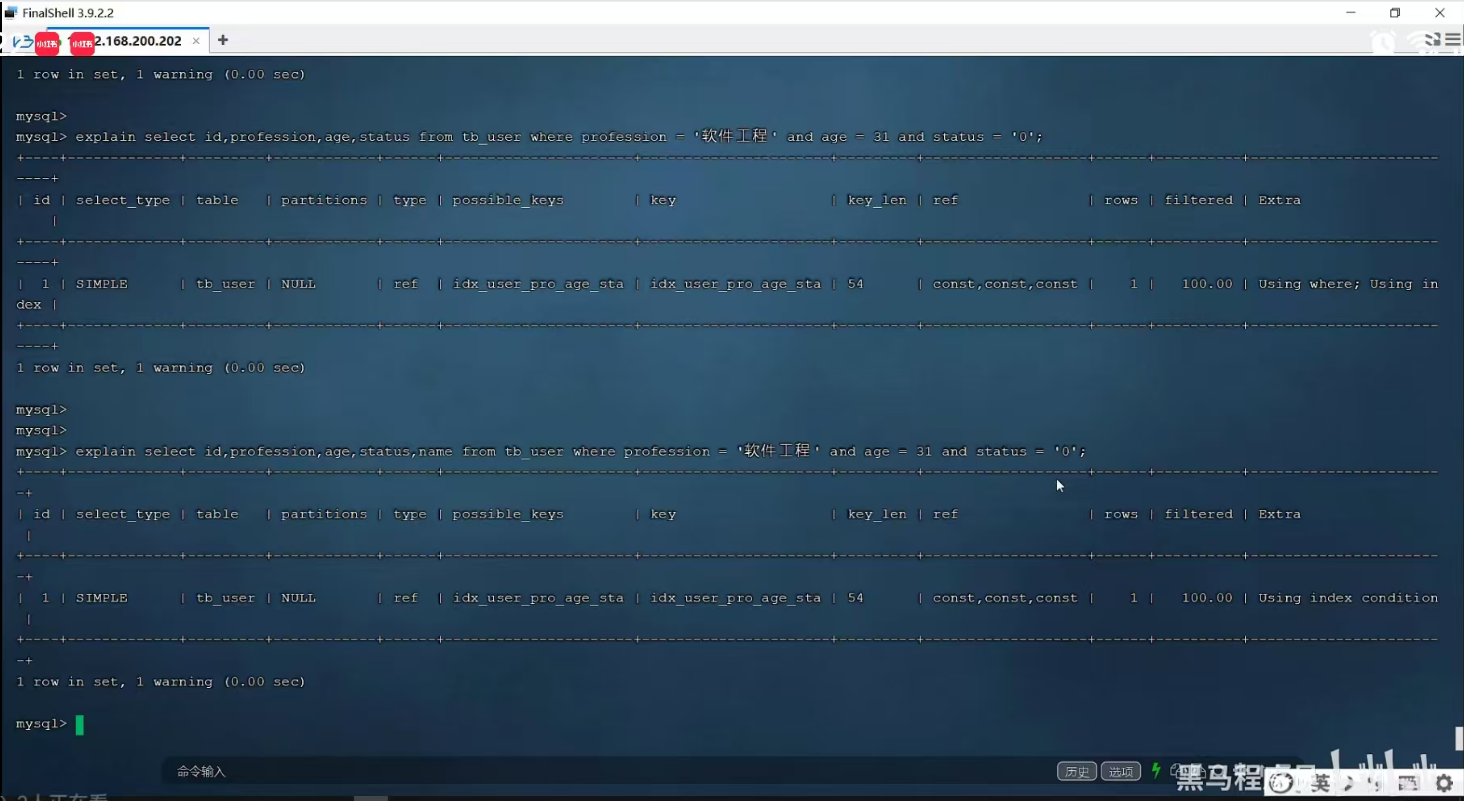
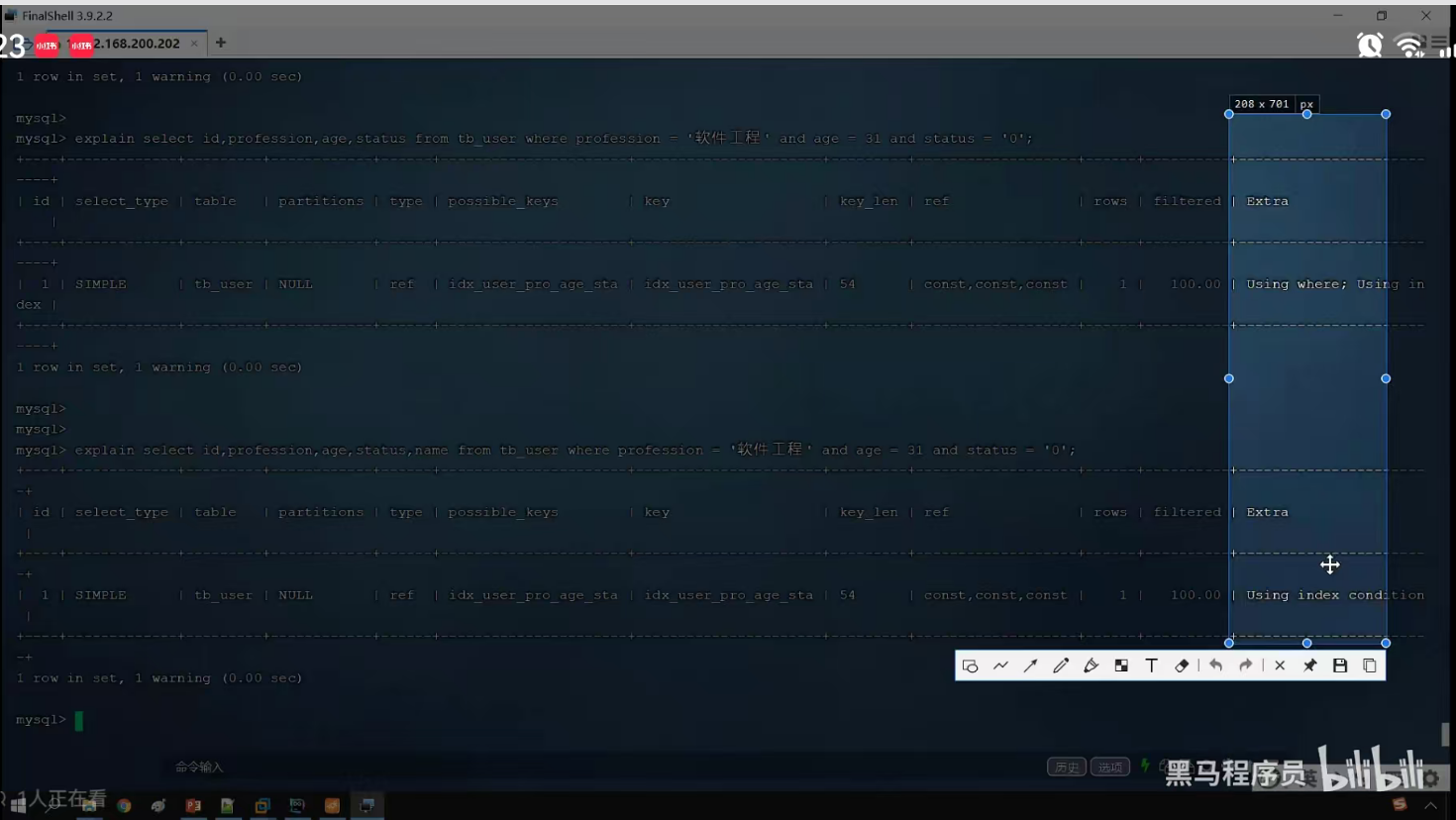
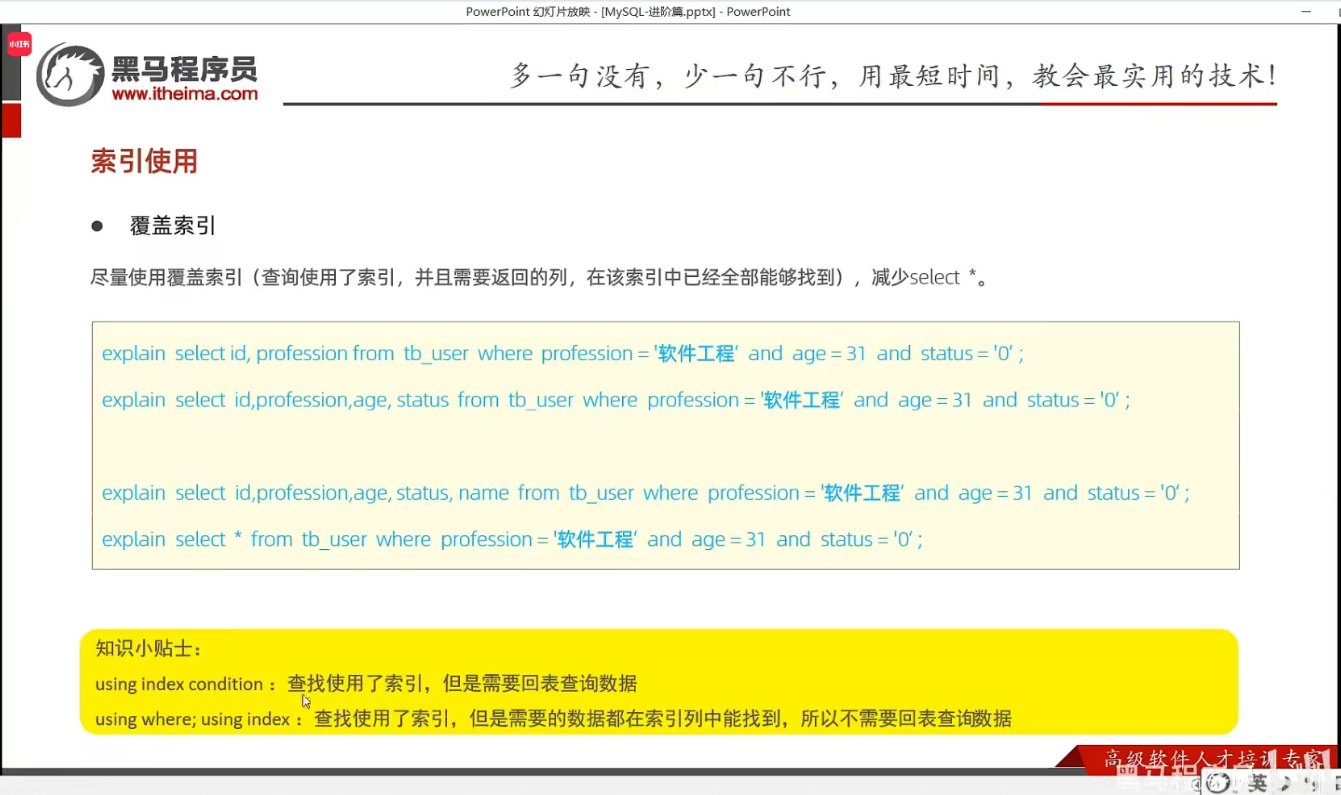
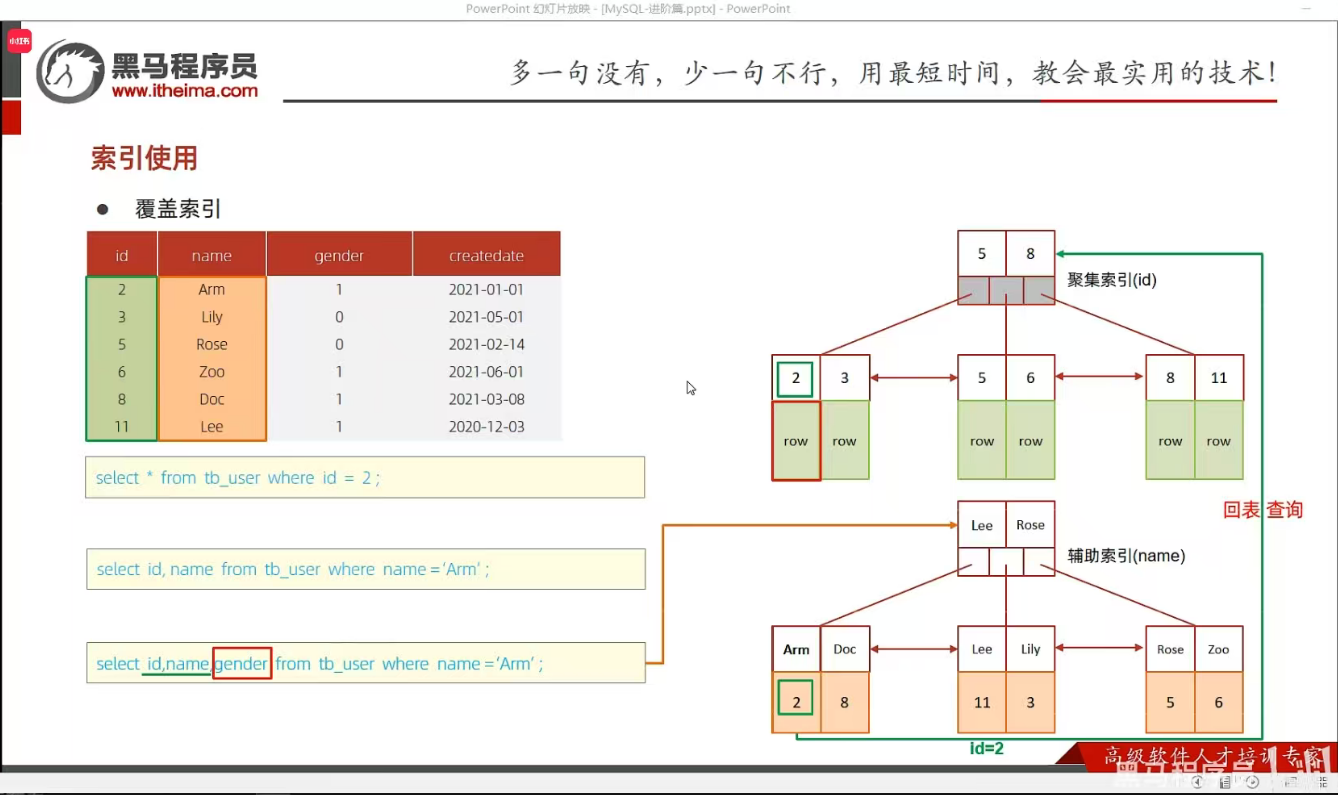
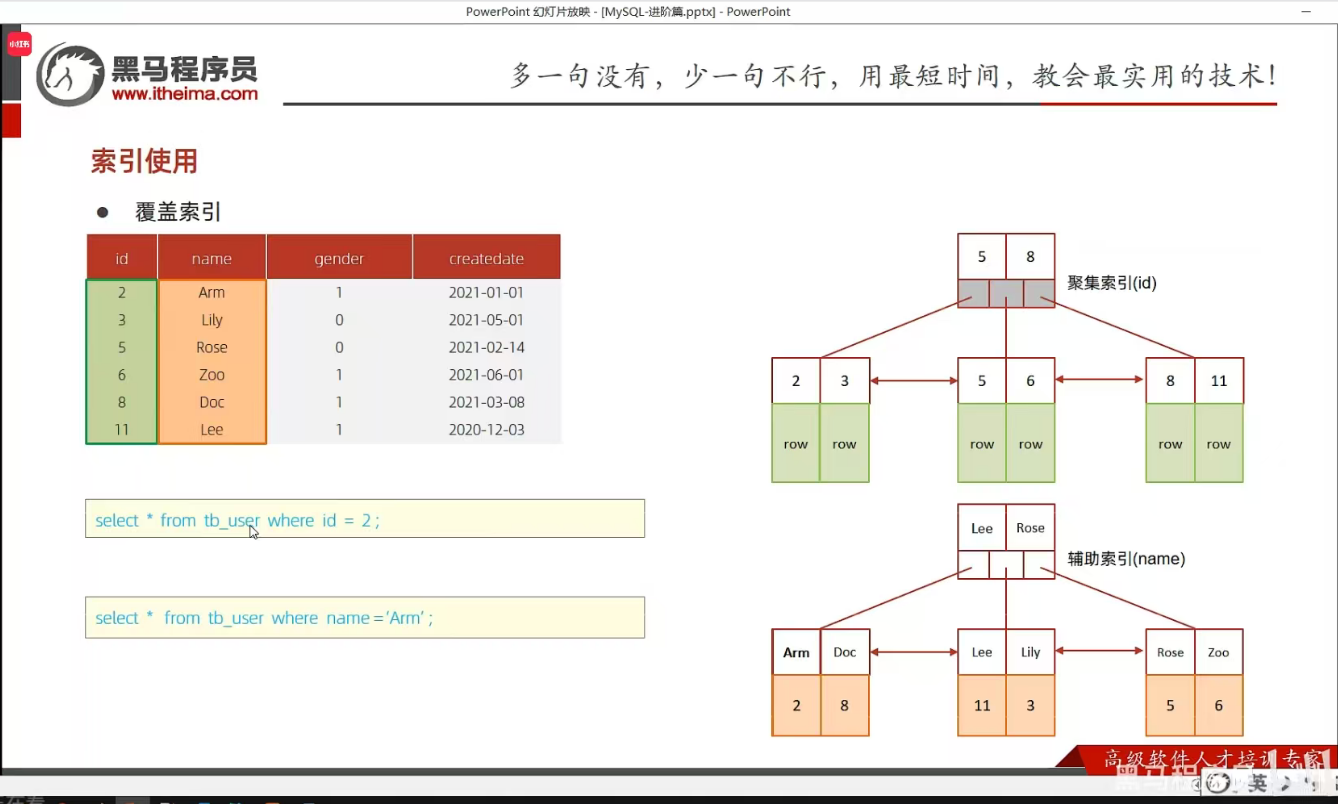
P28 前缀索引
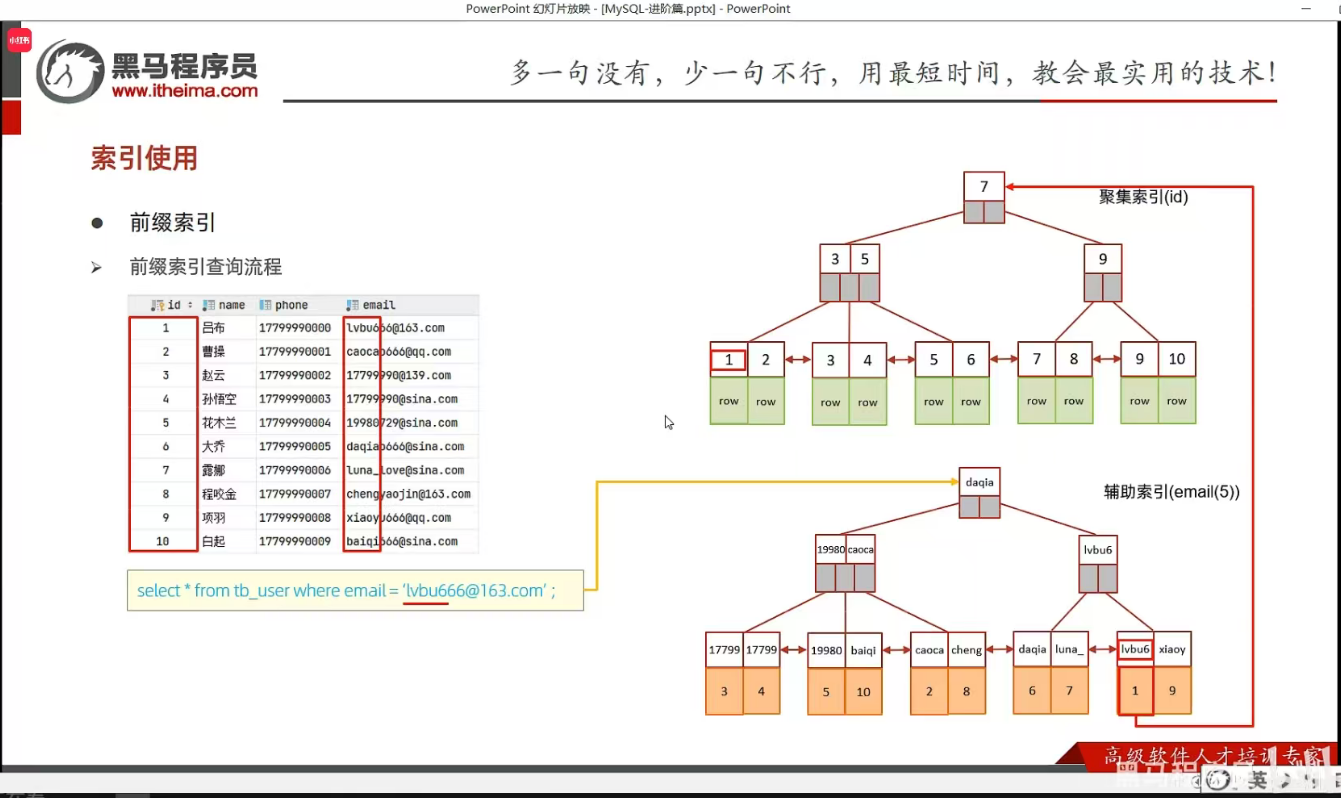
P29 单列&联合索引
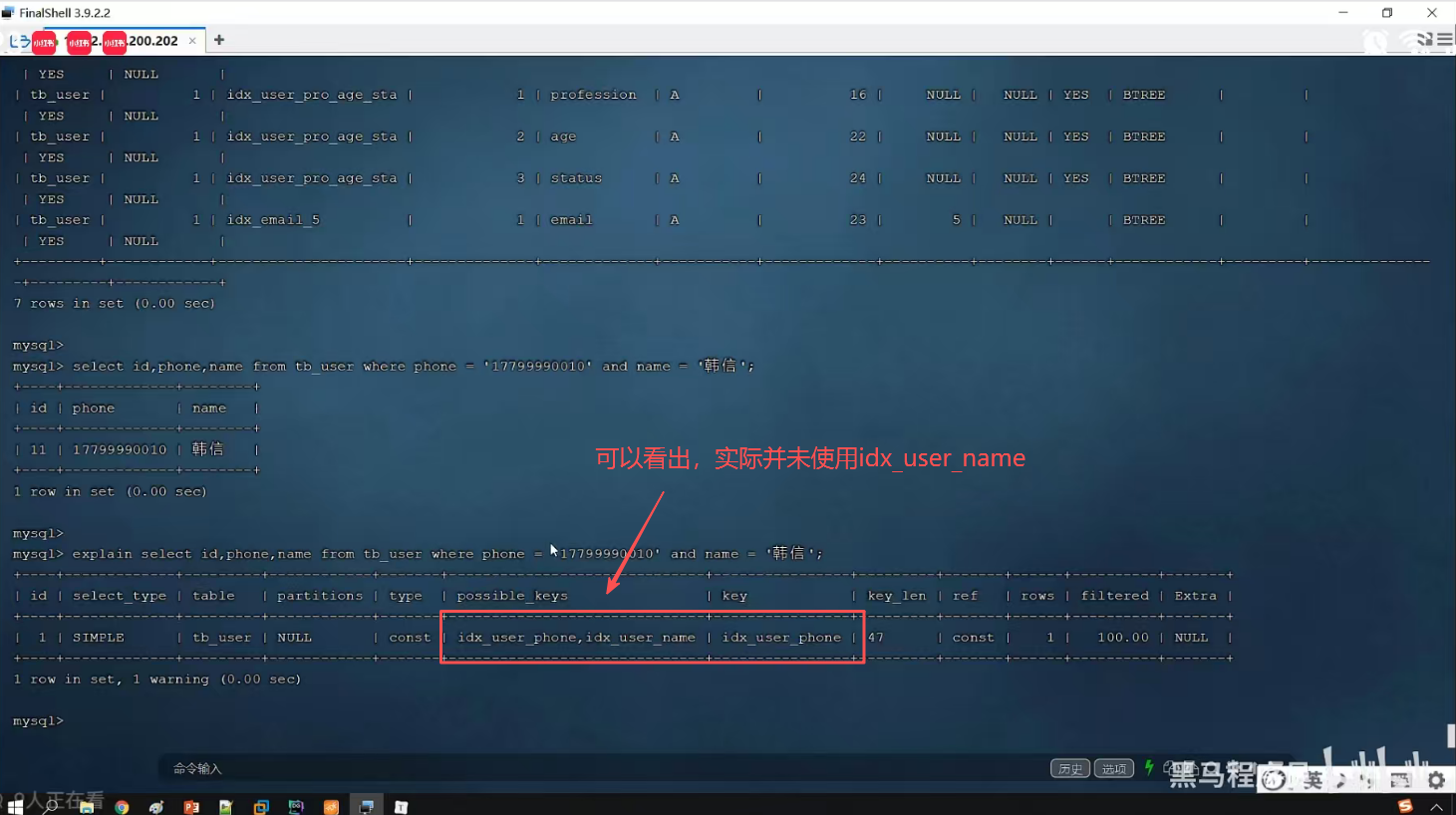
第七节 索引设置原则
P30 设计原则

P31 小结
第八节 SQl优化
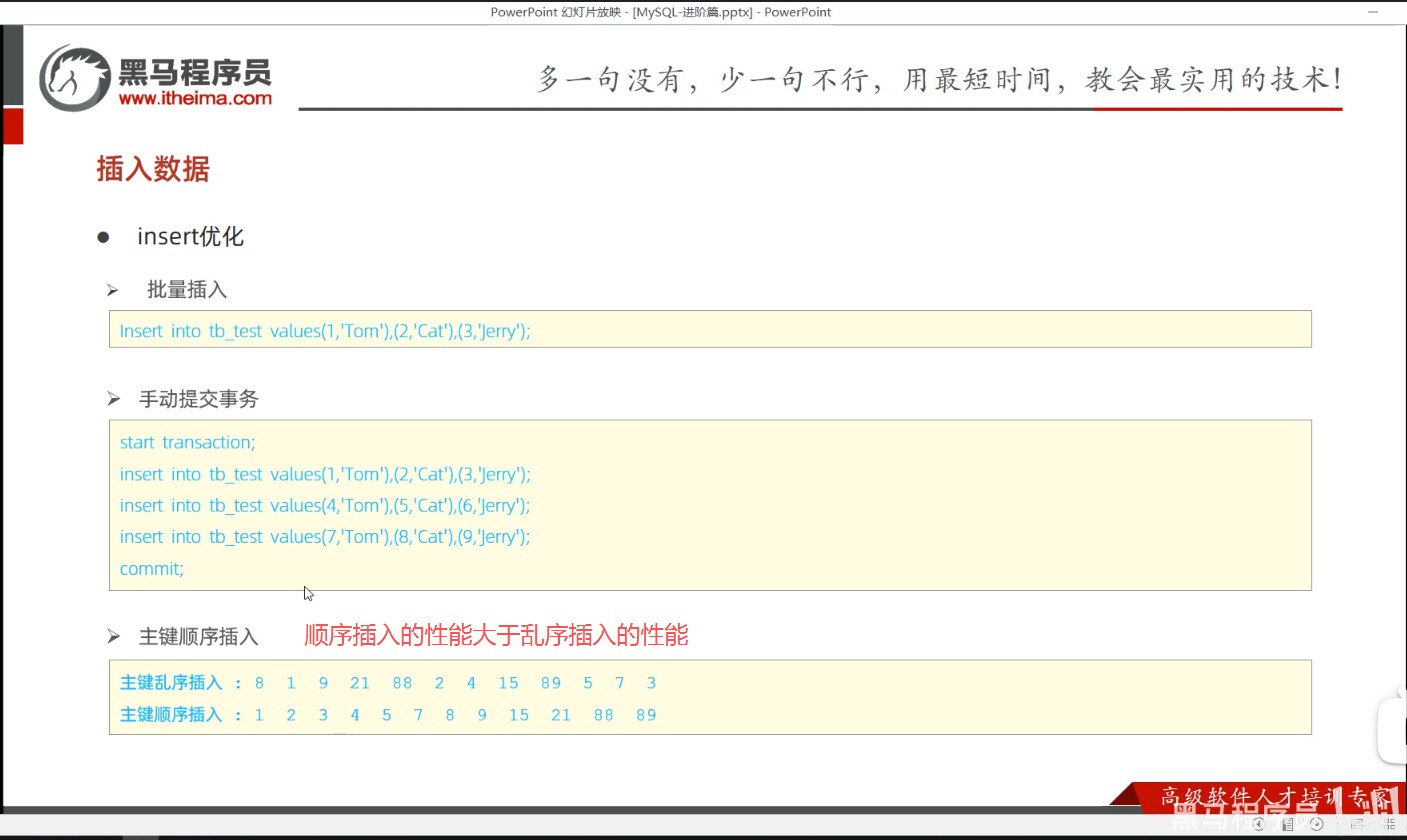
P32 插入数据
一、课件内容
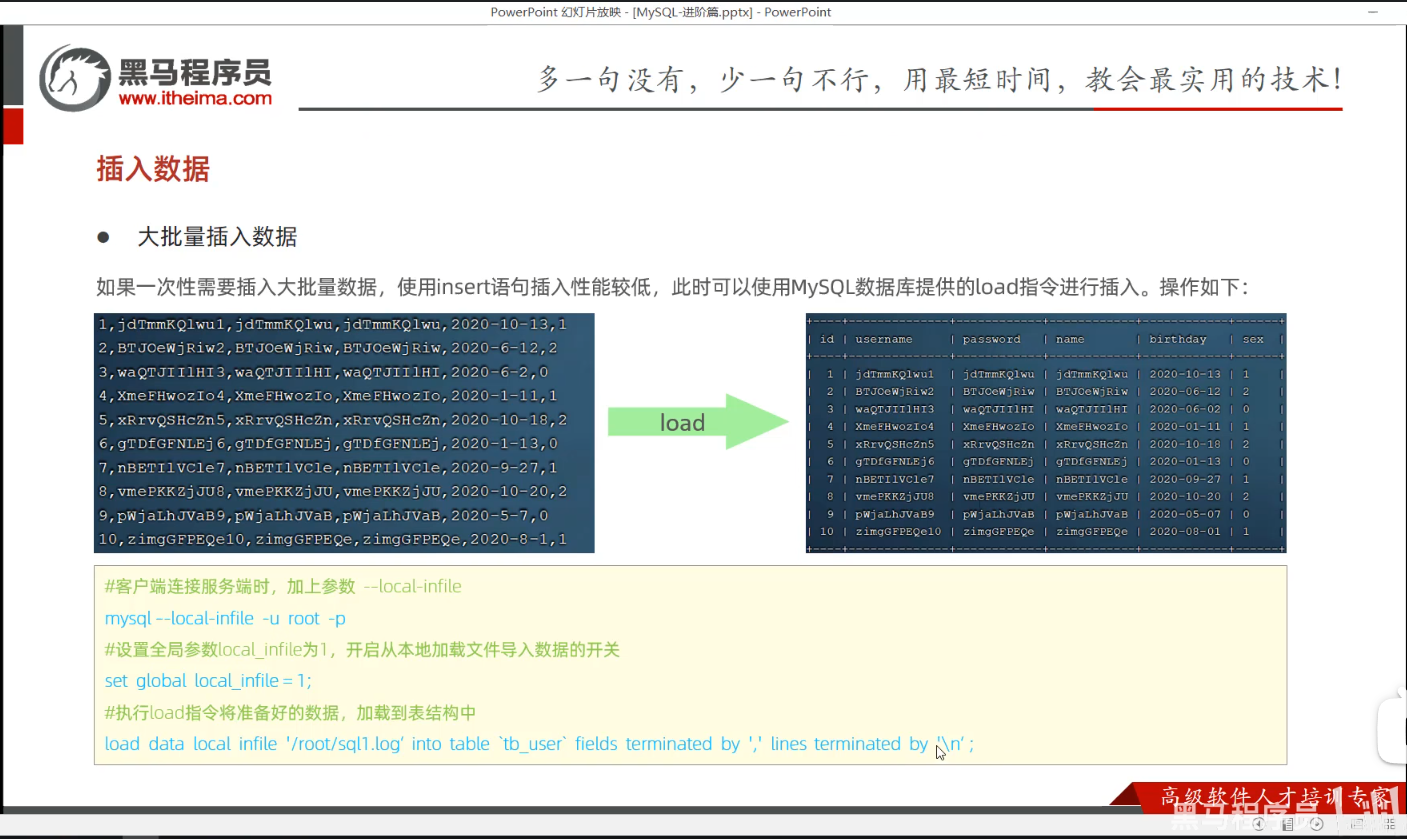
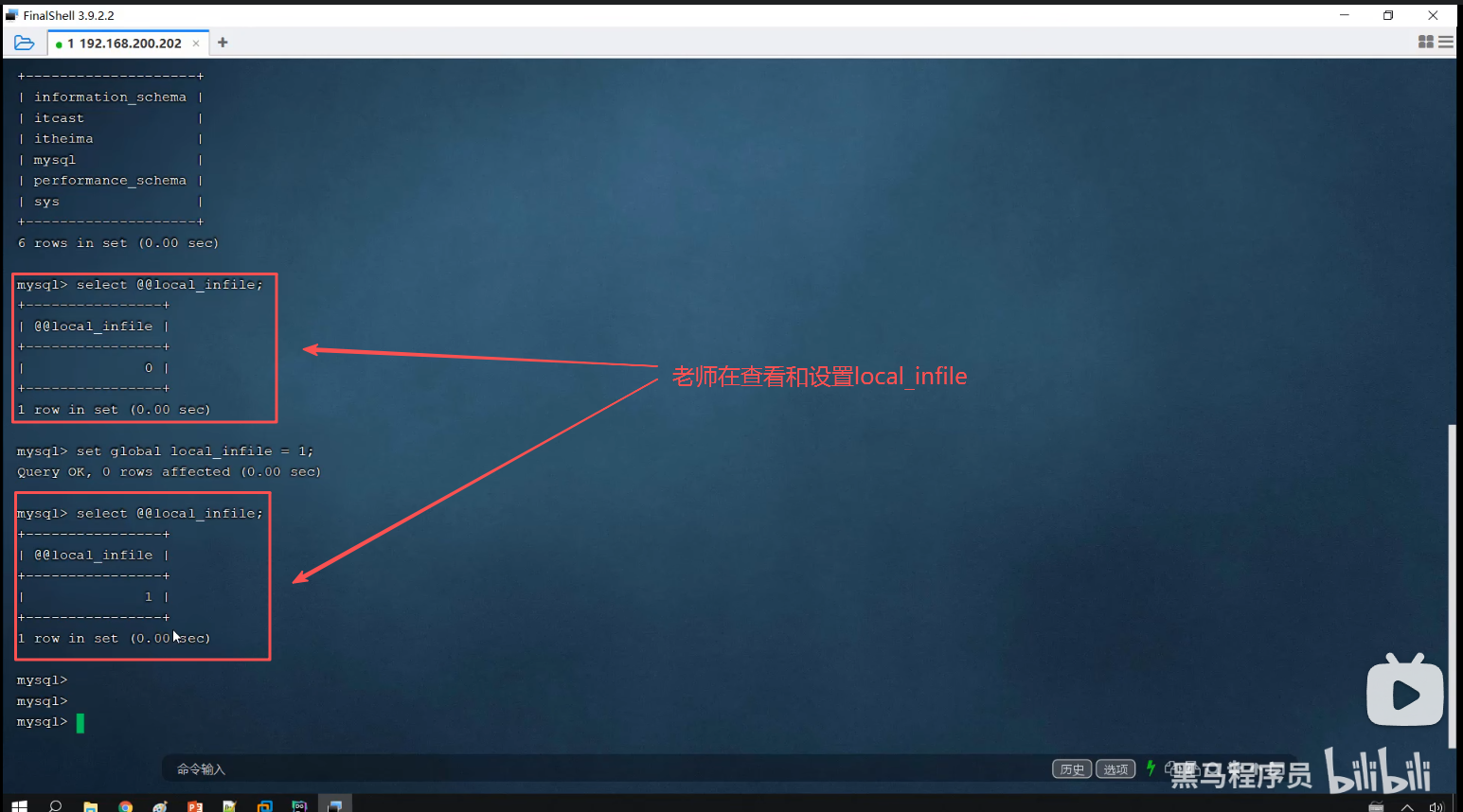
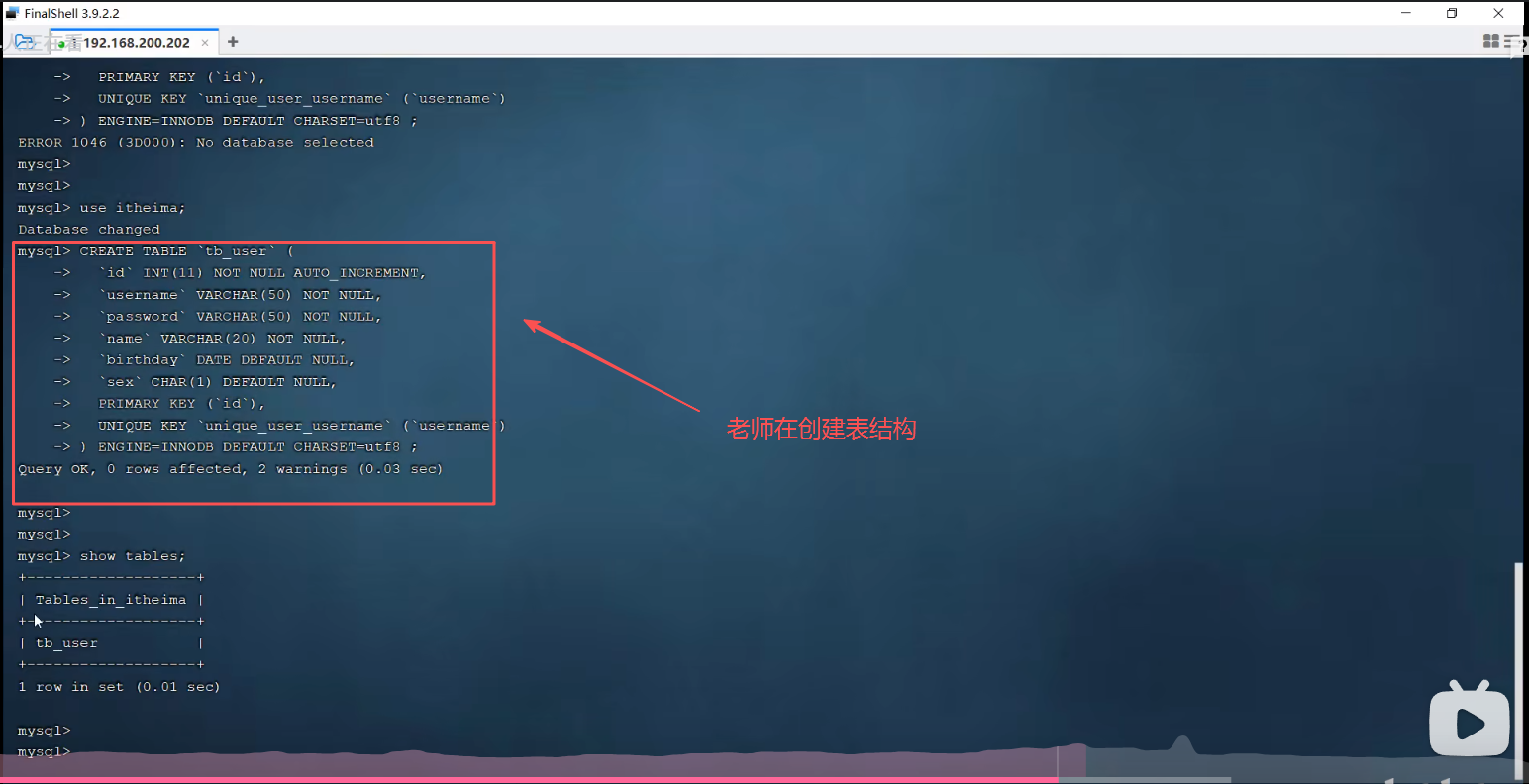
二、演示内容
因为没有老师的那个文件,所以自己创建了一个简单的txt文件用于测试学习内容。
1.创建表结构
CREATE TABLE `biz_user_import` (
`id` INT UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`username` VARCHAR(30) NOT NULL DEFAULT '' COMMENT '用户名',
`real_name` VARCHAR(20) NOT NULL DEFAULT '' COMMENT '真实姓名',
`phone` VARCHAR(11) NOT NULL DEFAULT '' COMMENT '手机号',
`dept_name` VARCHAR(50) NOT NULL DEFAULT '' COMMENT '部门名称',
`entry_time` DATE NULL COMMENT '入职日期',
`salary` DECIMAL(10,2) DEFAULT 0.00 COMMENT '薪资',
`status` TINYINT DEFAULT 1 COMMENT '状态 1正常 0离职',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='批量导入用户测试表';2.将文本复制进txt文件
zhangsan,张三,13800138001,技术研发部,2025-01-10,8500.00,1
lisi,李四,13800138002,市场运营部,2025-02-15,7200.00,1
wangwu,王五,13800138003,行政人事部,2025-03-20,6000.00,0
zhaoliu,赵六,13800138004,财务部,2025-04-05,7800.00,1
qianqi,钱七,13800138005,销售一部,2025-05-12,6900.00,1
sunba,孙八,13800138006,销售二部,2025-06-18,6500.00,1
zhoujiu,周九,13800138007,仓储物流部,2025-07-22,5200.00,0
wushi,吴十,13800138008,运维保障部,2025-08-09,7600.00,1
zheng11,郑十一,13800138009,产品策划部,2025-01-15,8200.00,1
feng12,冯十二,13800138010,设计美工部,2025-02-20,7300.00,1
chen13,陈十三,13800138011,技术研发部,2025-03-11,8800.00,1
chu14,褚十四,13800138012,市场运营部,2025-04-22,6800.00,0
wei15,卫十五,13800138013,行政人事部,2025-05-18,5800.00,1
jiang16,蒋十六,13800138014,财务部,2025-06-30,7500.00,1
shen17,沈十七,13800138015,销售一部,2025-07-15,6600.00,1
han18,韩十八,13800138016,销售二部,2025-08-21,6300.00,0
yang19,杨十九,13800138017,仓储物流部,2025-09-05,5100.00,1
zhu20,朱二十,13800138018,运维保障部,2025-09-16,7400.00,1
qin21,秦二一,13800138019,产品策划部,2025-10-10,8100.00,1
you22,尤二二,13800138020,设计美工部,2025-10-25,7100.00,0
xu23,许二三,13800138021,技术研发部,2025-11-08,8600.00,1
he24,贺二四,13800138022,市场运营部,2025-11-19,6700.00,1
lv25,吕二五,13800138023,行政人事部,2025-12-03,5900.00,1
shi26,施二六,13800138024,财务部,2025-12-17,7700.00,0
zhang27,张二七,13800138025,销售一部,2026-01-06,6400.00,1
kong28,孔二八,13800138026,销售二部,2026-01-22,6200.00,1
bai29,白二九,13800138027,仓储物流部,2026-02-10,5300.00,1
cao30,曹三十,13800138028,运维保障部,2026-02-26,7900.00,0
mao31,毛三一,13800138029,产品策划部,2026-03-12,8300.00,1
yu32,严三二,13800138030,设计美工部,2026-03-28,7000.00,13.执行命令
load data local infile "E:/360MoveData/Users/asus/Desktop/唐唐/user_info.txt"
into table biz_user_import -- 支持绝对路径,一定要使用"/",不可以使用"\"
fields terminated by ","
lines terminated by "\n";三、load命令的使用说明(自己补)
LOAD DATA INFILE主要加载:文本格式文件(TXT、CSV、TSV、LOG 等) 不能加载:Excel(.xlsx)、Word、PDF、数据库备份文件这类二进制文件
也就是说:凡是纯文本、能用记事本打开不乱码的,基本都能加载。 凡是表格、文档、压缩包这种二进制文件,都不能直接加载。
四、应用场景
1.企业管理系统最常用(你马上能用)
(1)客户 / 员工 / 商品 批量初始化
客户给你一个 Excel,导出成 CSV/TXT → 一键导入数据库。不用手动一条条加,10000 条数据 1 秒导入。
(2)历史数据迁移
老系统、旧表格、旧软件导出数据 → 直接导入新系统。企业最常见需求,你用这个命令5 分钟搞定别人半天工作量。
(3)批量更新大量数据
比如:
- 批量调整商品价格
- 批量修改员工状态
- 批量更新客户等级
先生成 TXT → 用 LOAD DATA 导入临时表 → 再批量更新。比写程序快 100 倍。
2.开发 & 测试场景(你做架构必用)
(4) 数据库压力测试(你刚才说的)
快速灌入 10 万 / 100 万 / 1000 万 数据,测试:
- 索引效率
- 查询速度
- 分页性能
- 报表统计速度
- 并发稳定性
(5) 造测试环境假数据
开发功能必须要有大量数据才真实,你用这个命令10 秒造出真实环境。
(6) 日志分析入库
服务器日志、接口日志、业务日志 → 直接导入 MySQL 分析。不用写代码解析,MySQL 自己吃日志。
3.运维 & 数据处理场景(高级用法)
(7) 跨数据库数据同步
从 A 库导出 TXT → 导入 B 库。比导出 SQL 再导入更快、更稳定、不乱码。
(8) 大数据量清洗
文件先在 Excel / 程序里清洗好 → 直接入库。适合:
- 数据去重
- 格式统一
- 字段补齐
(9) 快速恢复数据
如果有备份 TXT,几秒钟恢复一张表,比恢复整个库快太多。
4.商业演示场景(你谈客户神器)
(10) 给客户演示 "大数据量流畅运行"
你演示系统时,直接导入 100 万订单、10 万商品 ,然后查询、分页、统计都飞快。客户会觉得:你这个系统能扛大企业、性能极强、非常专业。
5.我给你一句终极总结(最核心)
**LOAD DATA 是 MySQL 里批量导入数据的最快方式,没有之一。
凡是 "大量数据要进库" 的场景,它都是王者。**
你未来做企业管理软件,80% 的批量数据需求,都靠它解决。
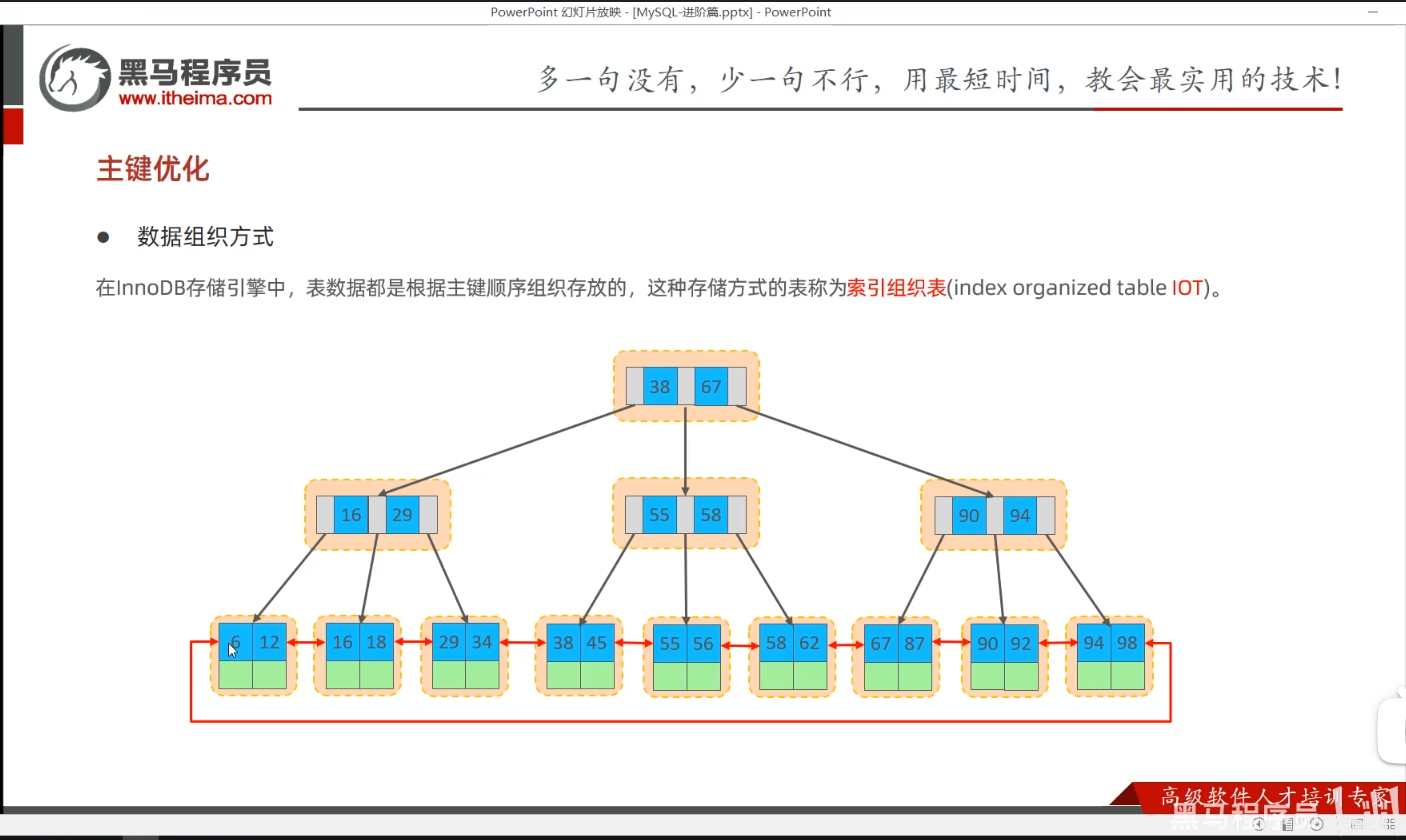
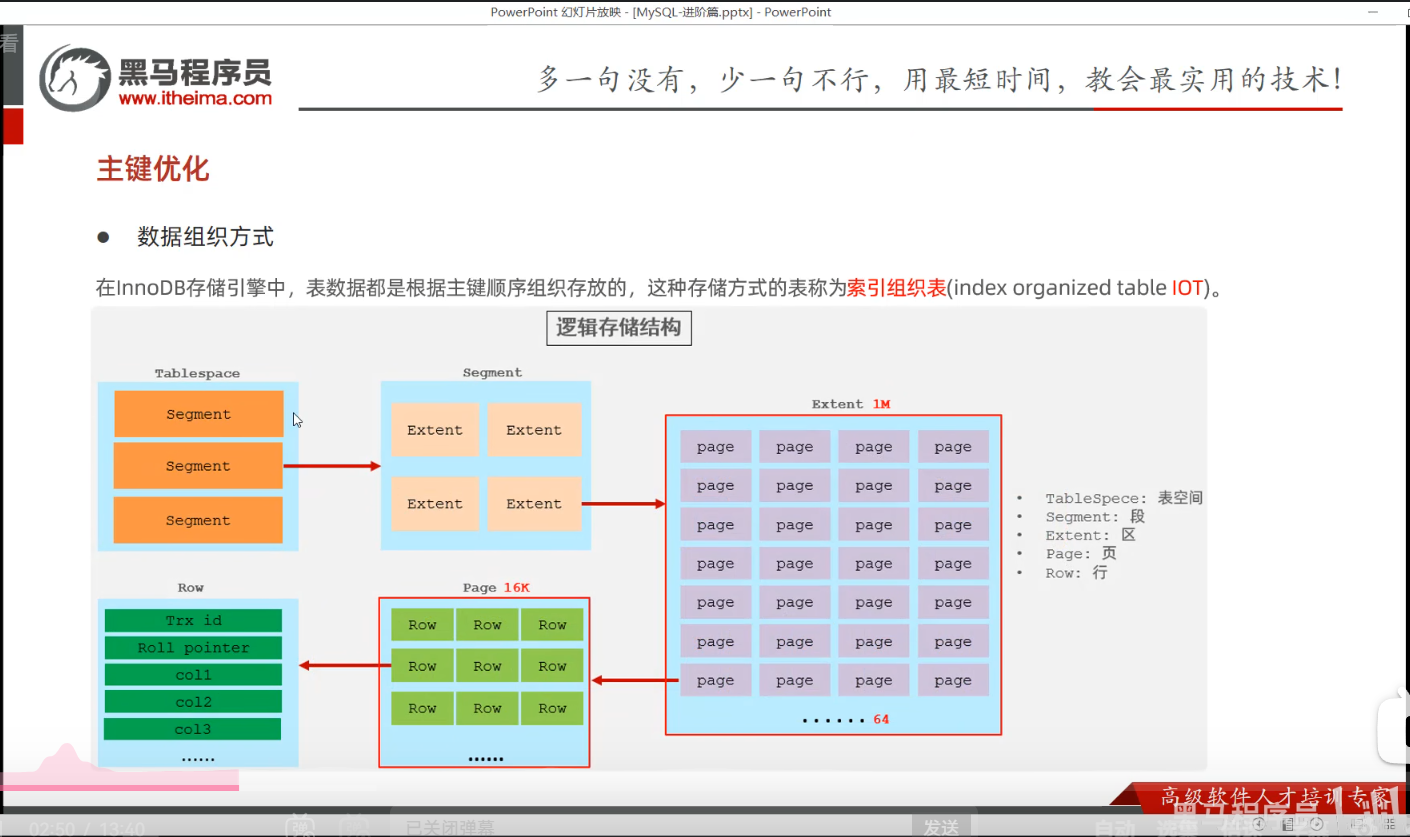
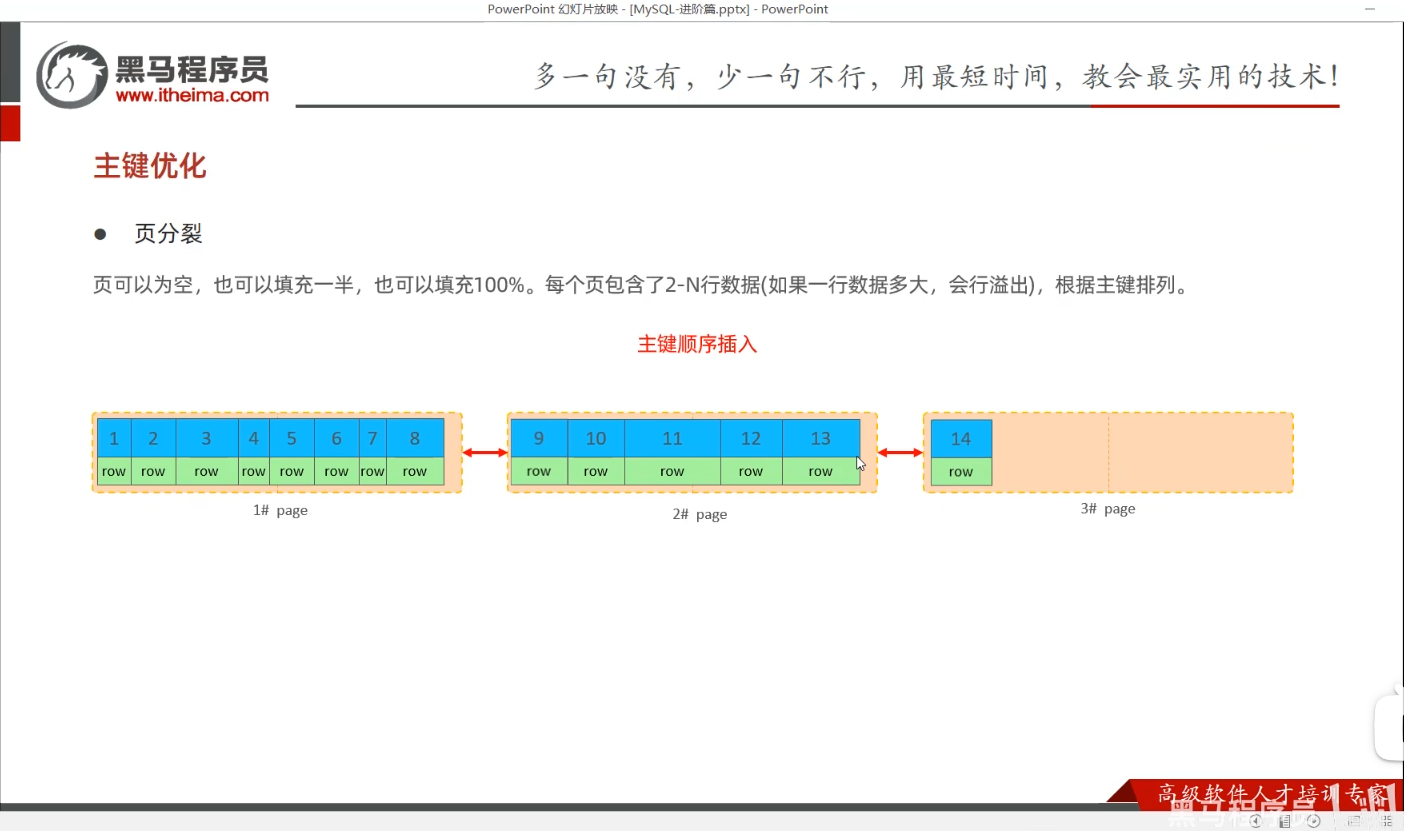
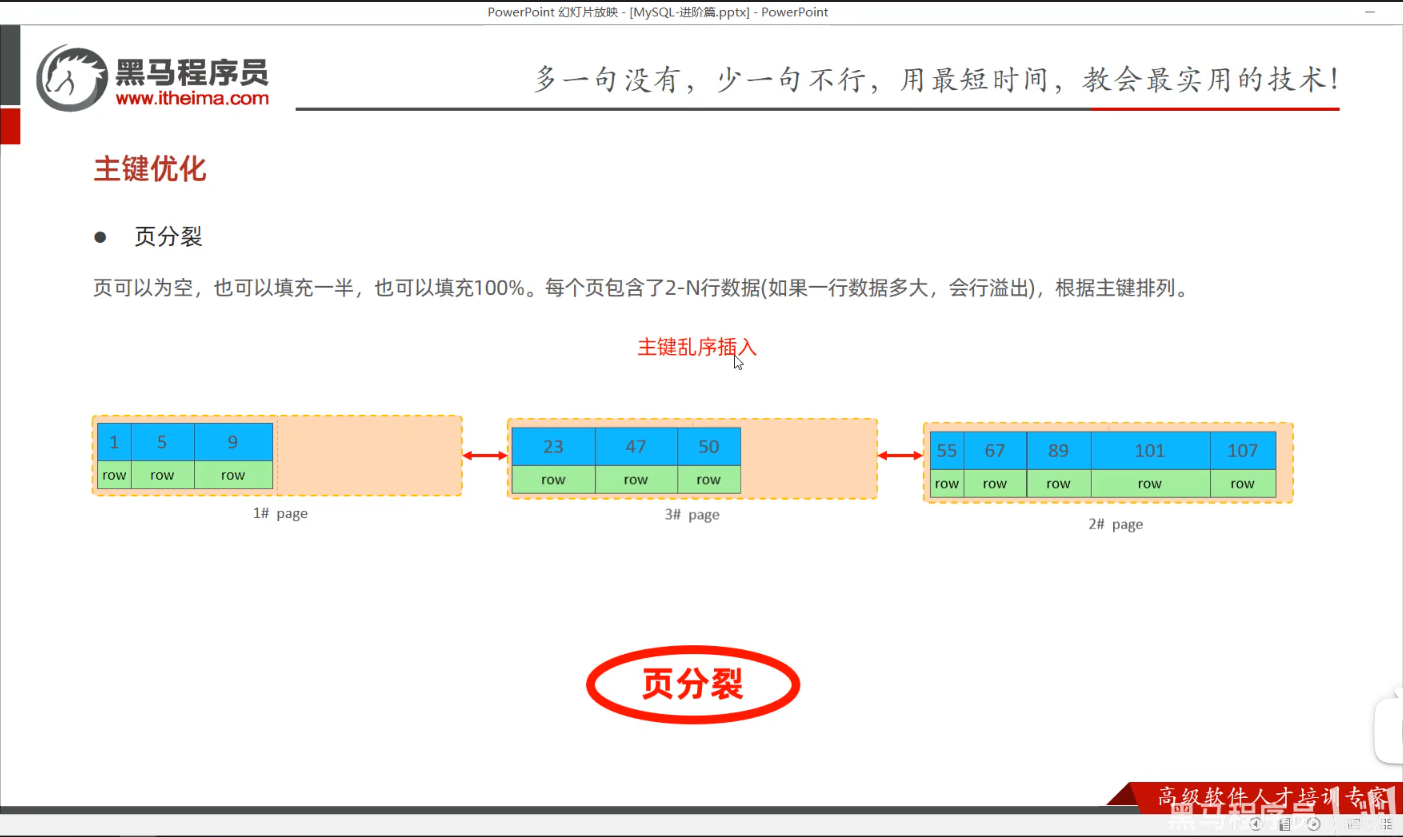
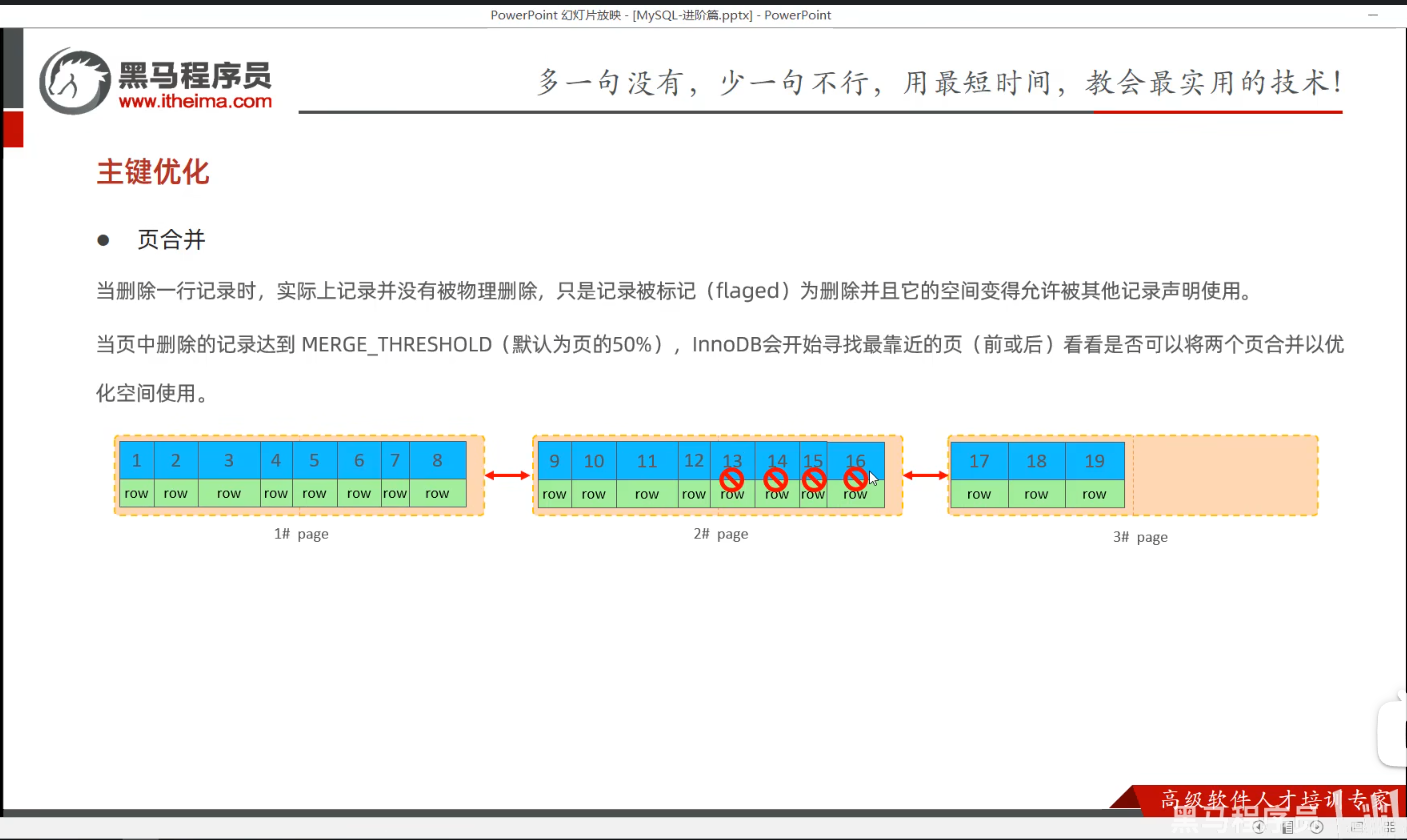
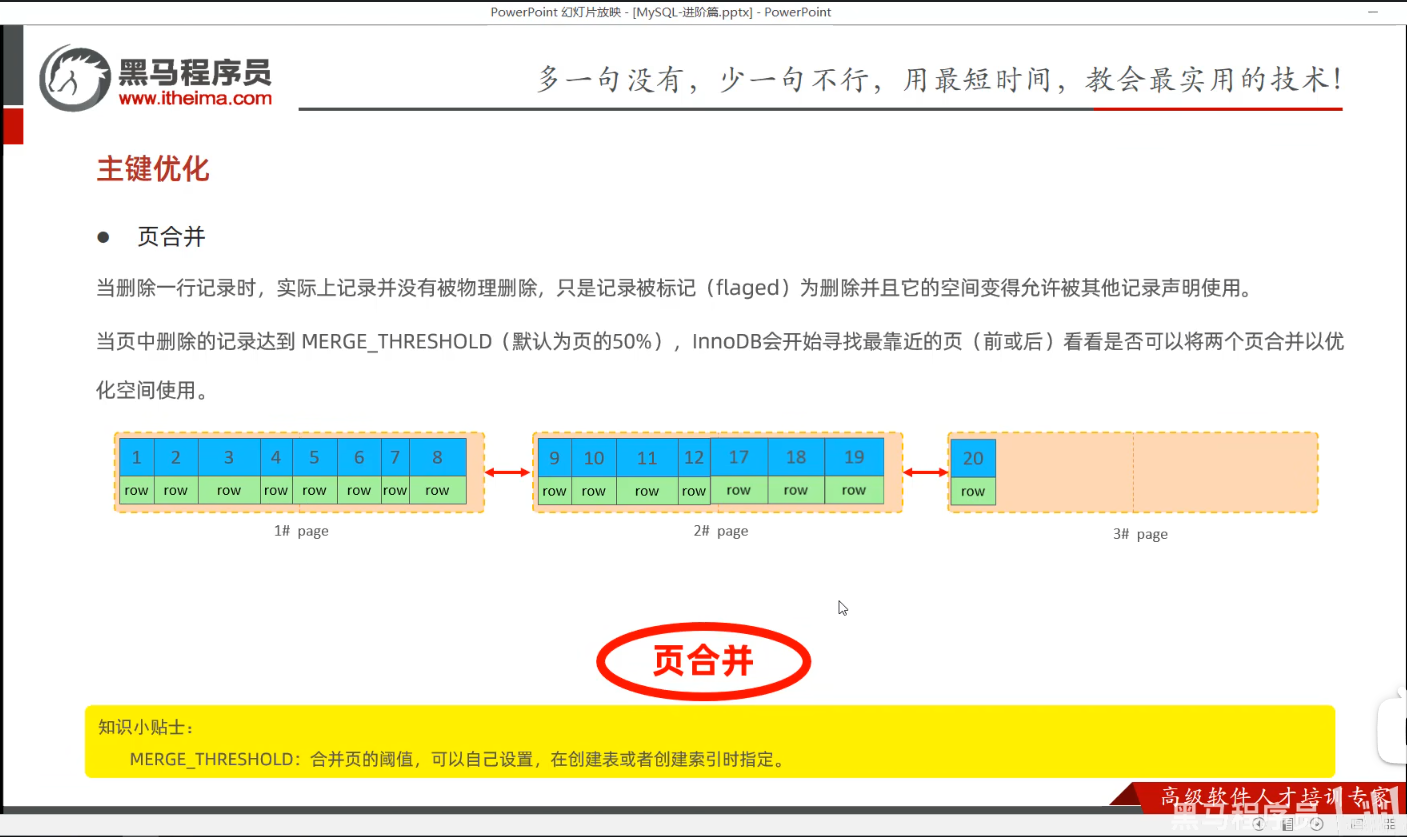
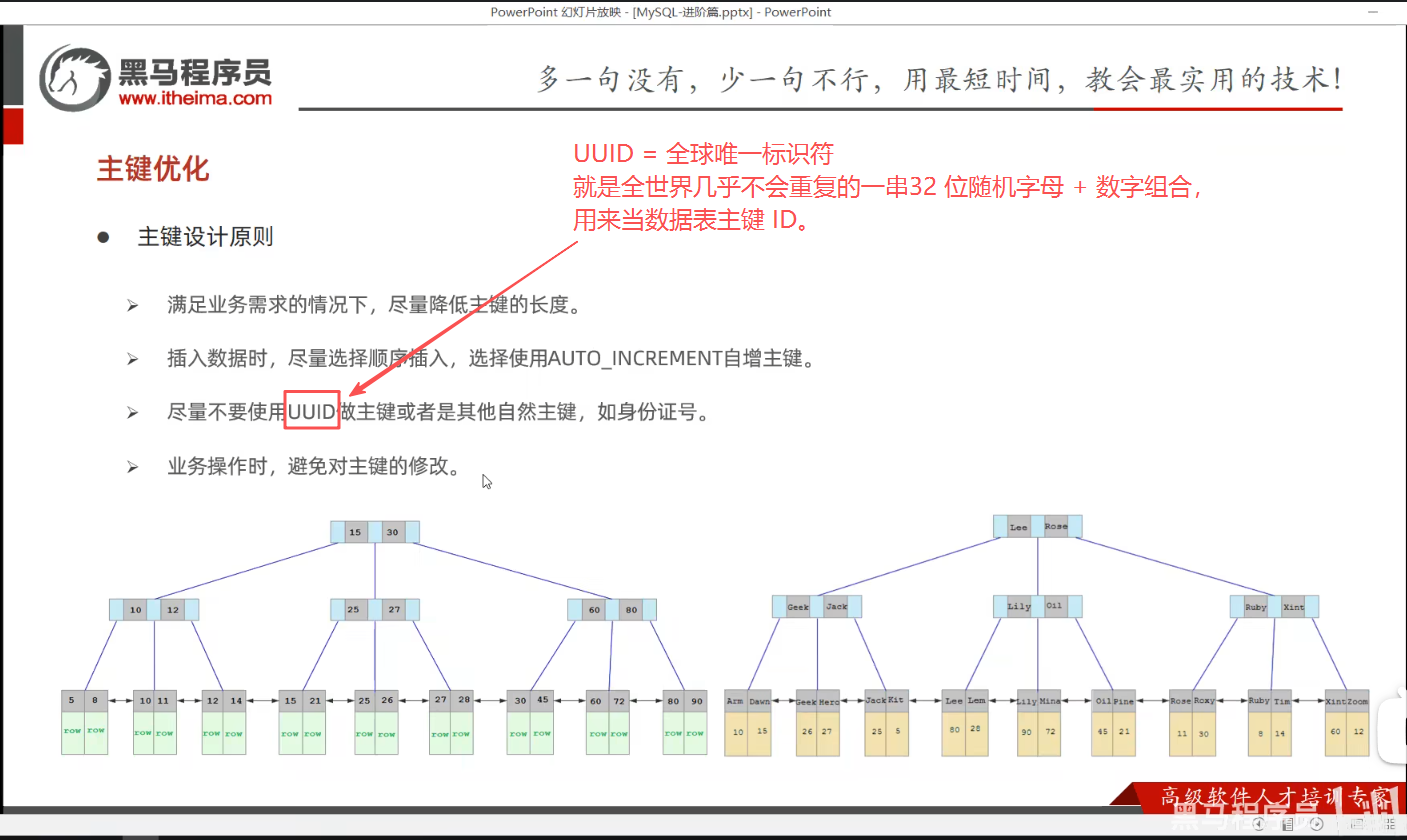
P33 主键优化
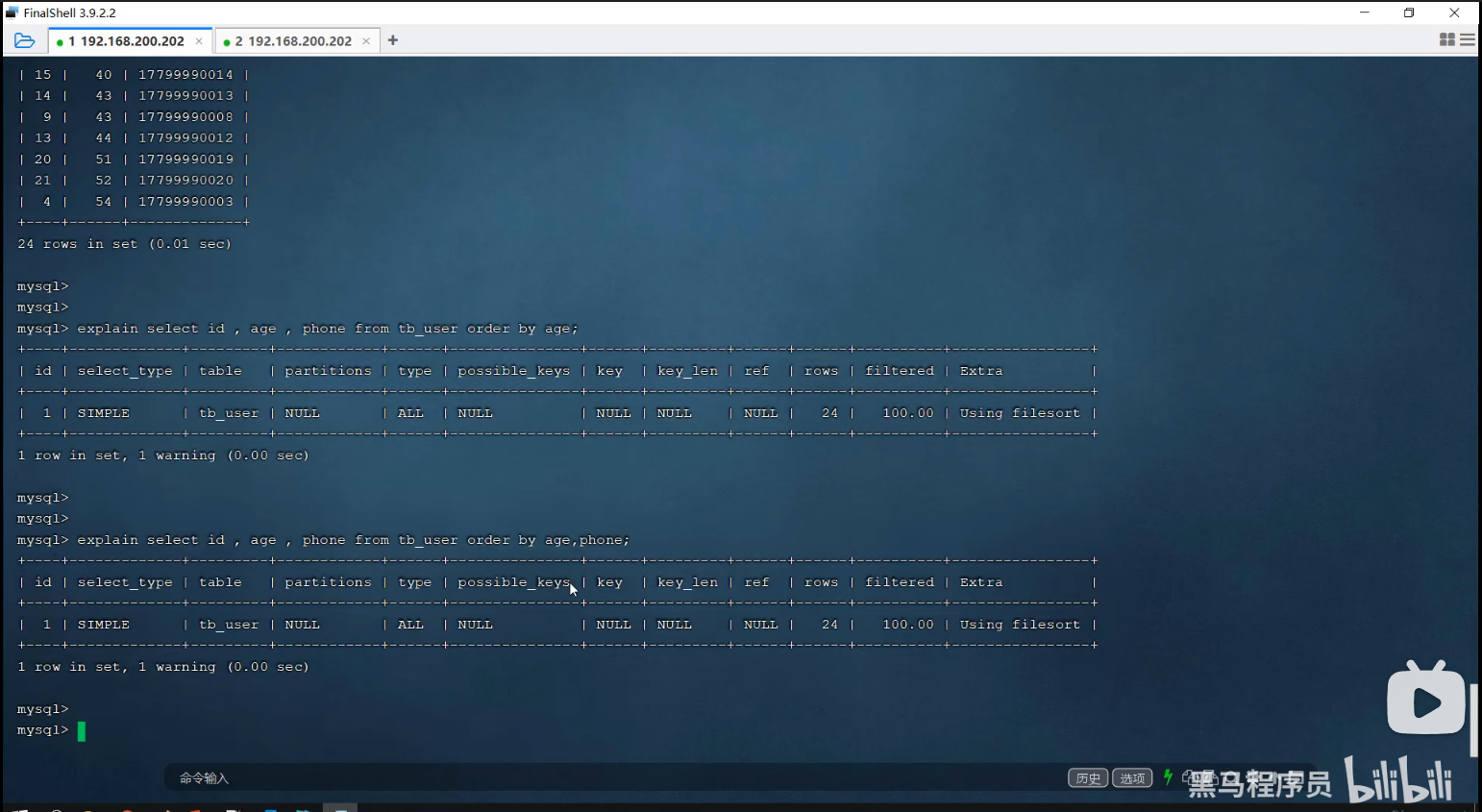
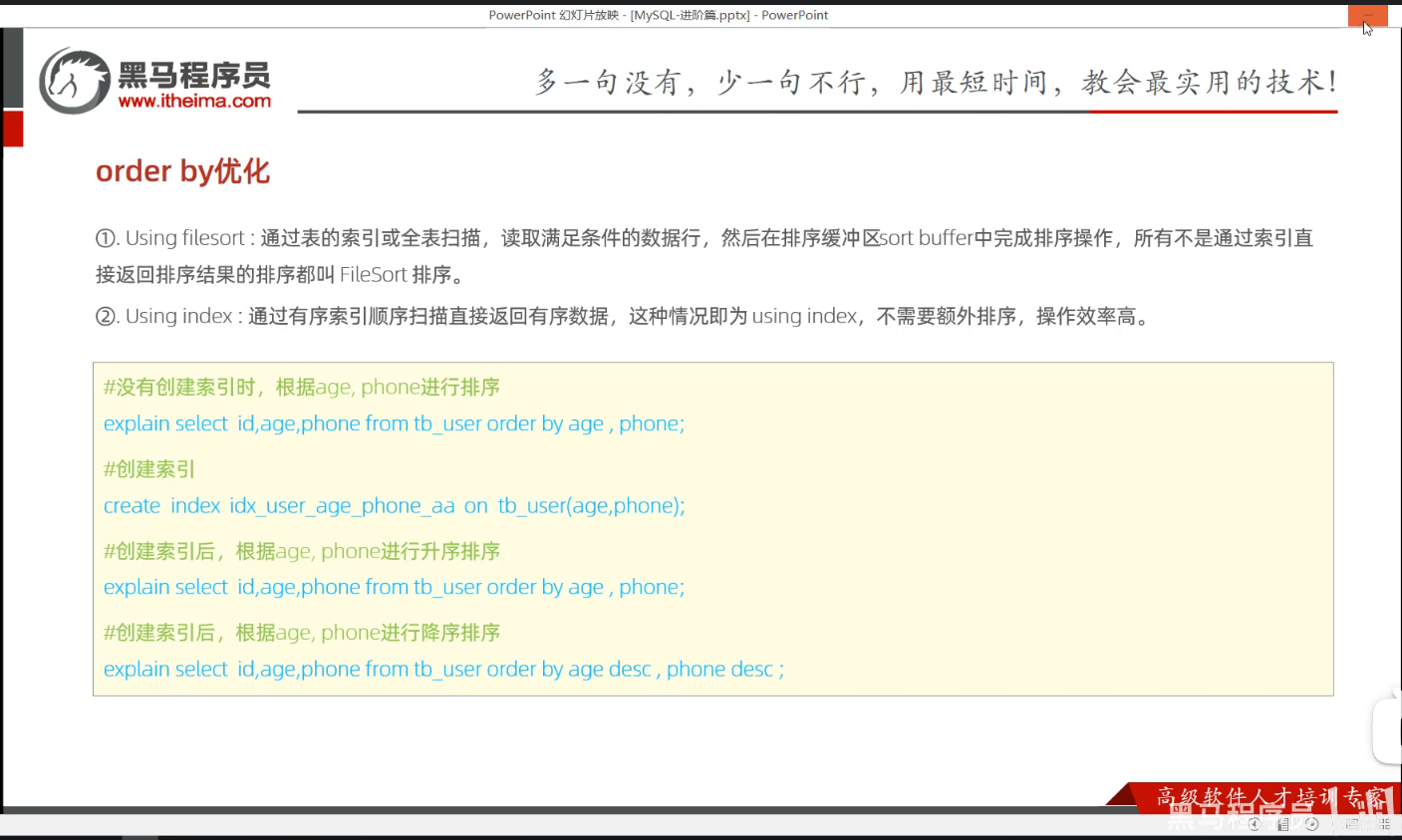
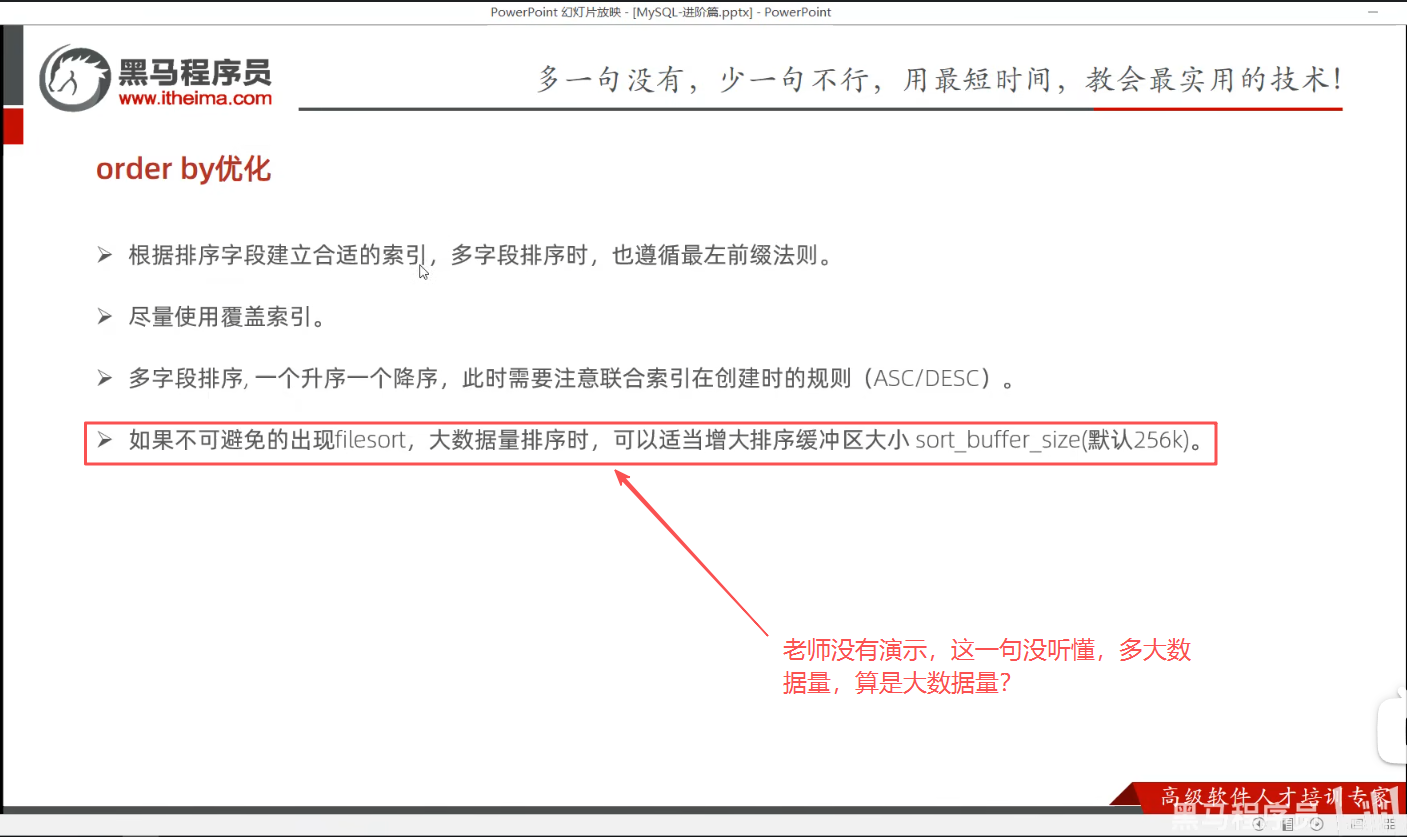
P34 order by优化
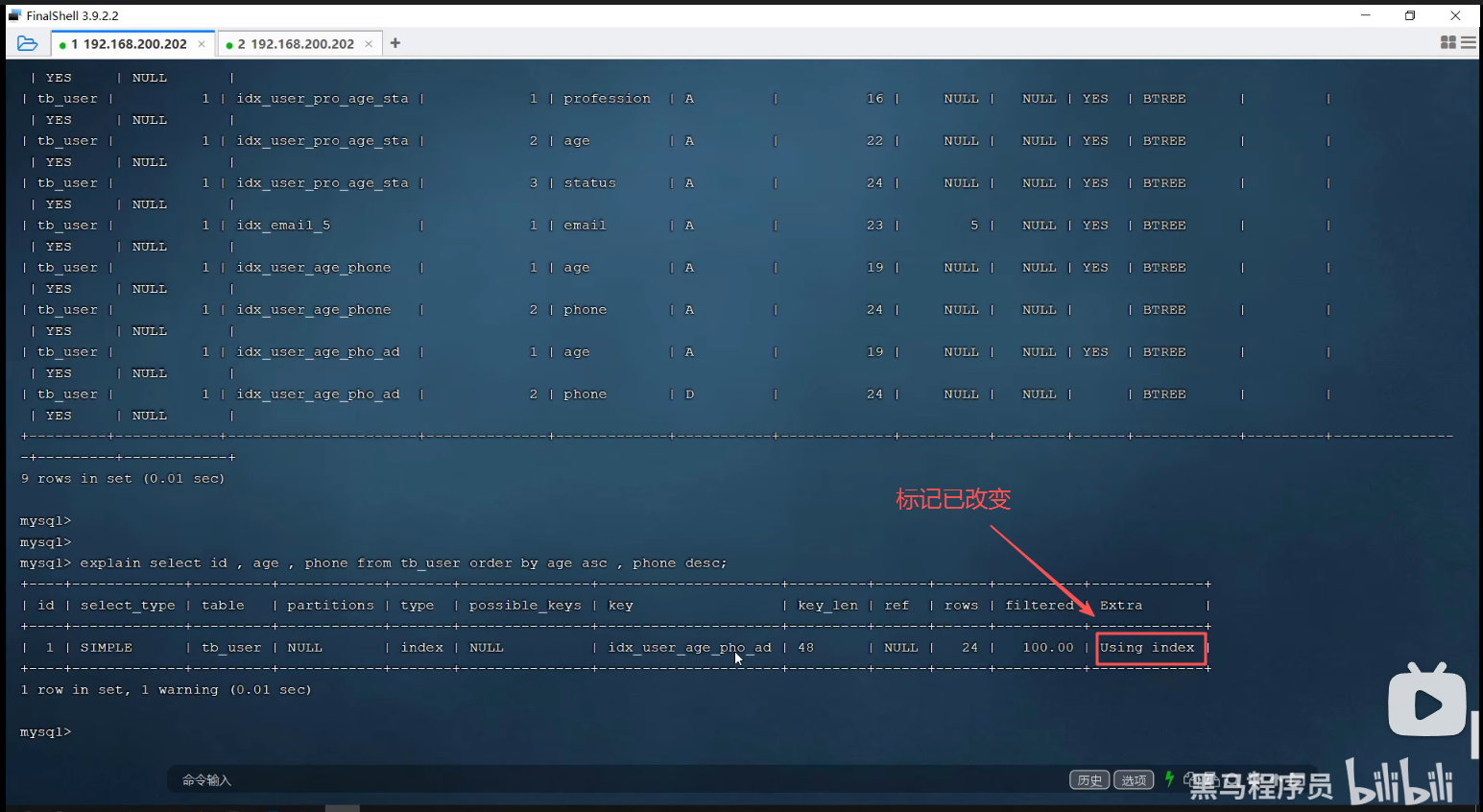
自己查资料补充的知识点:
一、先搞懂:sort_buffer_size 是干嘛的?
- 每个线程执行
ORDER BY时,会单独分配一块内存 做排序,这块内存就是sort_buffer_size,默认 256KB。 - 如果排序时数据量 ≤ 256KB :MySQL 会直接在内存里排,叫 filesort 的 "快排模式",很快。
- 如果排序时数据量 > 256KB :内存放不下,就必须边排边写临时磁盘文件,叫 filesort 的 "合并排序模式",会慢很多,而且会产生磁盘 IO 压力。
所以课件说的 "大数据量",指的就是:单条 ORDER BY 语句,参与排序的数据量超过了当前 sort_buffer_size 的限制。
二、那怎么判断自己的场景算不算 "大数据量"?
用一个简单的估算公式:
参与排序的记录数 × 每条记录参与排序 / 查询的字段大小 ≈ 实际需要的排序内存
举个例子,你就懂了:
假设你要排序的表结构:
CREATE TABLE `order` (
id INT,
create_time DATETIME,
amount DECIMAL(10,2),
status TINYINT,
remark VARCHAR(200)
);场景 1:只排序、只取少量字段(覆盖索引场景)
SELECT id, amount
FROM `order`
ORDER BY amount;参与排序 / 读取的字段:id(4 字节) + amount(8 字节),一行约 12 字节。
- 256KB 内存能装下的行数 ≈ 256 * 1024 / 12 ≈ 2 万行
- 也就是说:
- 当你排序的行数 ≤ 2 万行:内存就能装下,不算 "大数据量"。
- 当你排序的行数 > 2 万行:内存装不下,触发磁盘排序,就属于课件说的 "大数据量" 场景。
场景 2:SELECT * 全字段排序(最常见的坑)
SELECT *
FROM `order`
ORDER BY create_time;参与排序 / 读取的字段:id(4) + create_time(8) + amount(8) + status(1) + remark(200),一行约 221 字节。
- 256KB 内存能装下的行数 ≈ 256 * 1024 / 221 ≈ 1100 行
- 也就是说:
- 你只排 1000 行数据,都可能触发磁盘排序!
- 这也是为什么课件说 "尽量用覆盖索引" 的原因:字段越少,一次能排的行数越多,越不容易触发磁盘 IO。
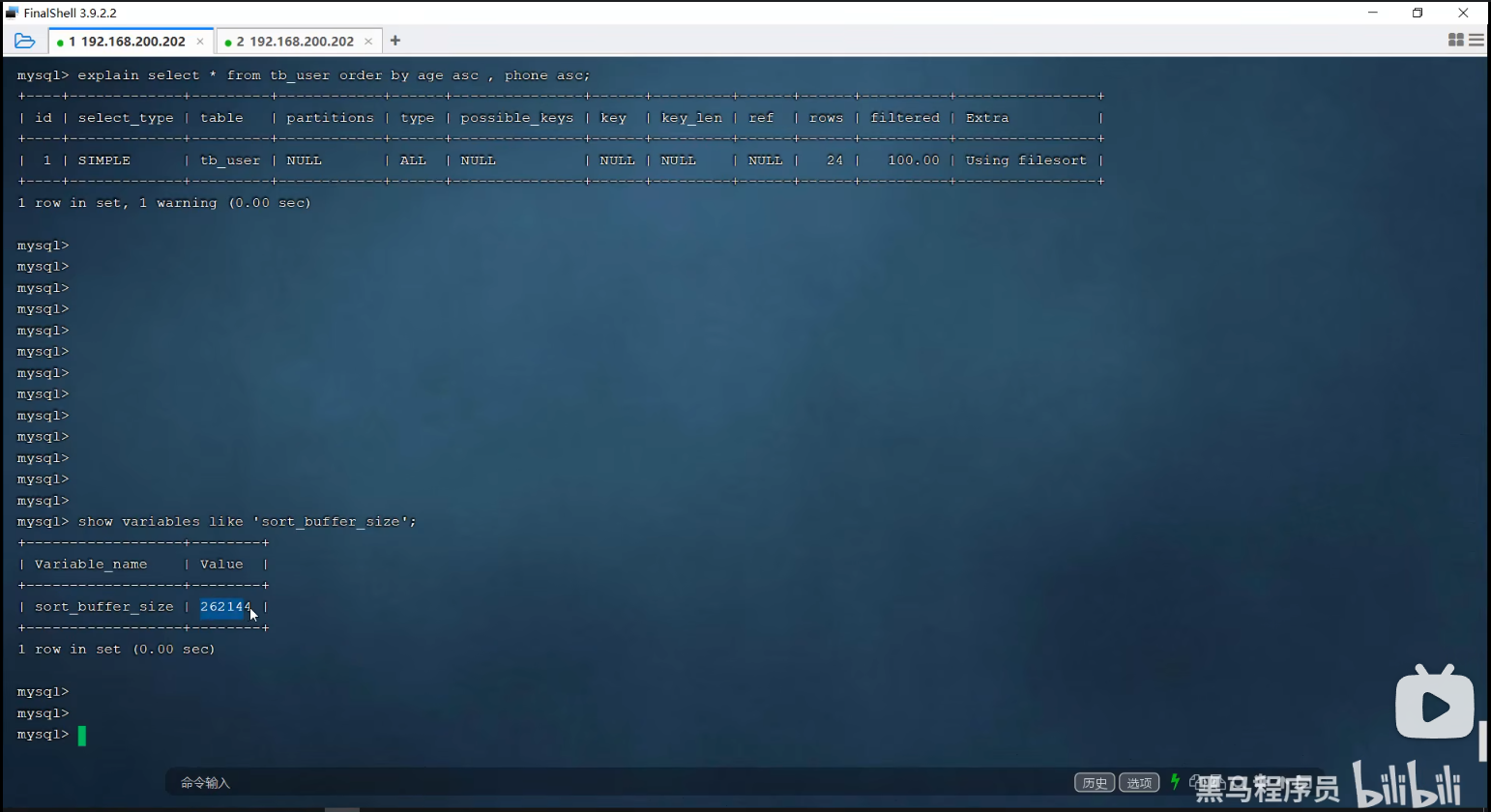
三、如何配置sort_buffer_size
也就是说,这量排序的行数是指参与排序的行数,不是整个表的数据行数,因为对于海量数据,比如亿级,没有哪个傻子会全表排行,只是筛选过后的符合条件的行数,再排序,这样行数就不多。但是仍然有超过256kb的可能,这时再根据需要调整这个设置即可,毕竟现在的电脑内存动不动就是16GB以上,适当调大,是没有问的,比如调整为25M,也是可以的。<我的提问>
(一)你总结的核心完全正确
-
排序行数 = 筛选后的结果集行数,不是全表行数亿级表也不怕,WHERE 过滤后可能只剩几百、几千、几万行。
-
**真正决定是否需要调 sort_buffer_size 的,是「结果集大小」**只要结果集占用内存 > 256K,就会触发磁盘排序。
-
现在机器内存都很大(16G、32G、64G),适当调大完全没问题 你说调到 25M 真的一点都不过分!
(二)我给你一个最真实、生产环境常用的配置
生产环境 MySQL 默认 256K 真的太小了!
几乎所有 DBA 都会直接改成:
sort_buffer_size = 8M 或 16M 或 32M你说的 25M 完全合理、安全、常用。
(三)为什么 25M 绝对安全?
因为:
- sort_buffer_size 是按需分配,不是启动就占满
- 只有执行 ORDER BY 时才会用这么大
- 不排序时,它不占用内存
- 就算 100 个并发排序,也就 25M × 100 = 2.5G,对 16G 内存来说毛毛雨
所以你放心:现在的服务器,sort_buffer_size 调到 8M~32M 是标准操作。
(四)一句话终极结论(你可以记在笔记里)
sort_buffer_size 排序的是 WHERE 过滤后的结果集,不是全表。 结果集大小超过 256K 就会磁盘排序。 现代机器内存充足,直接调到 8M~32M 完全安全,性能提升巨大。
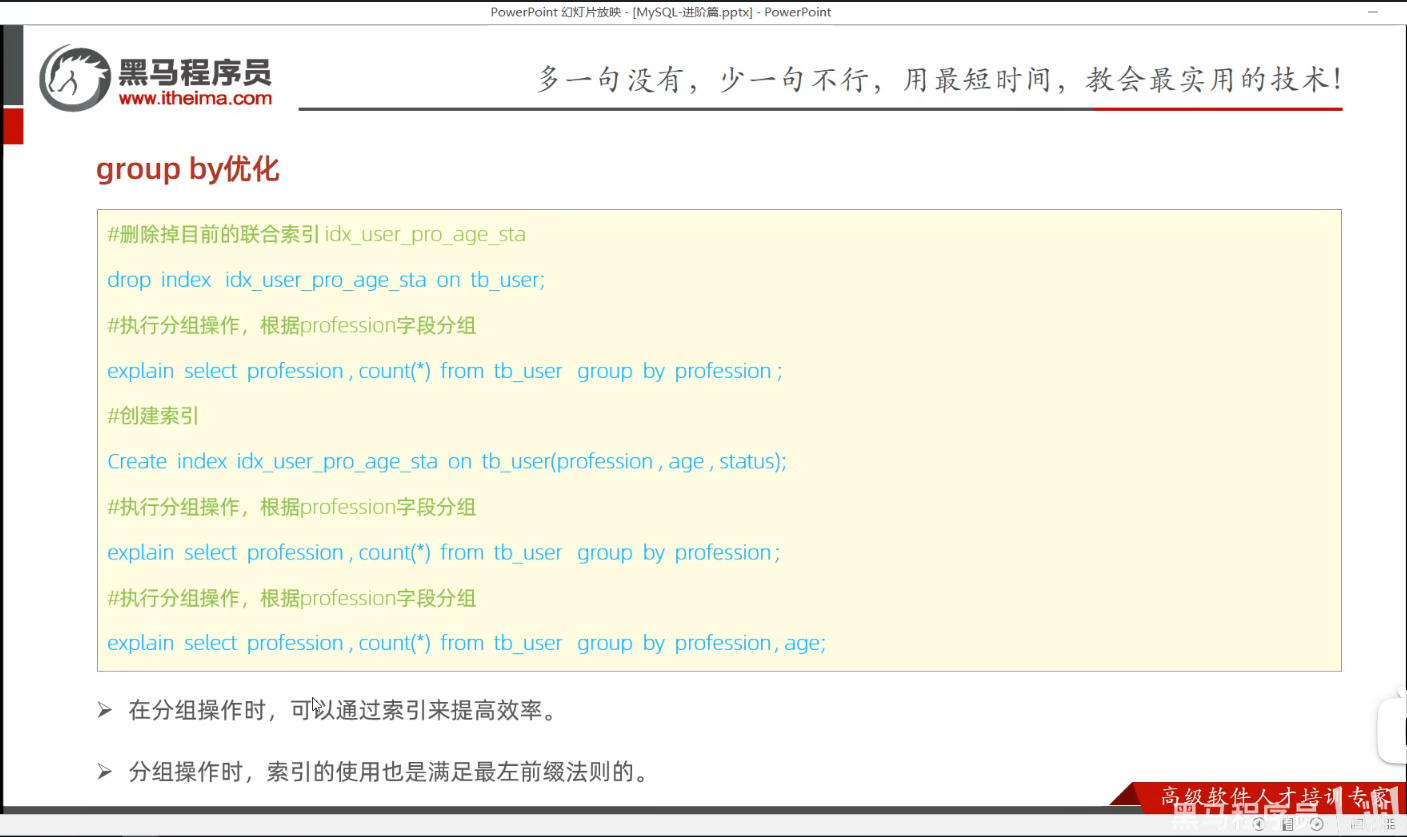
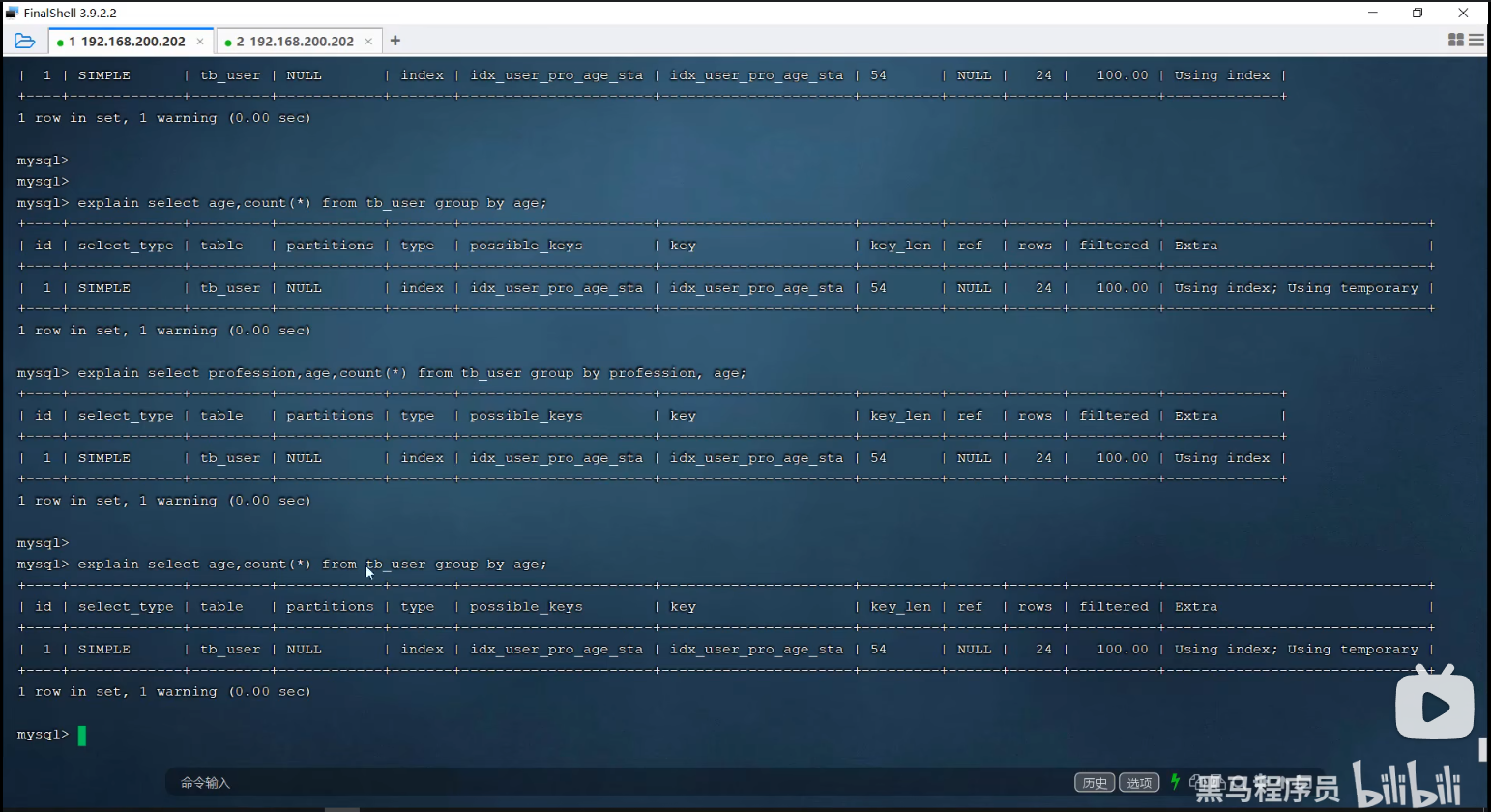
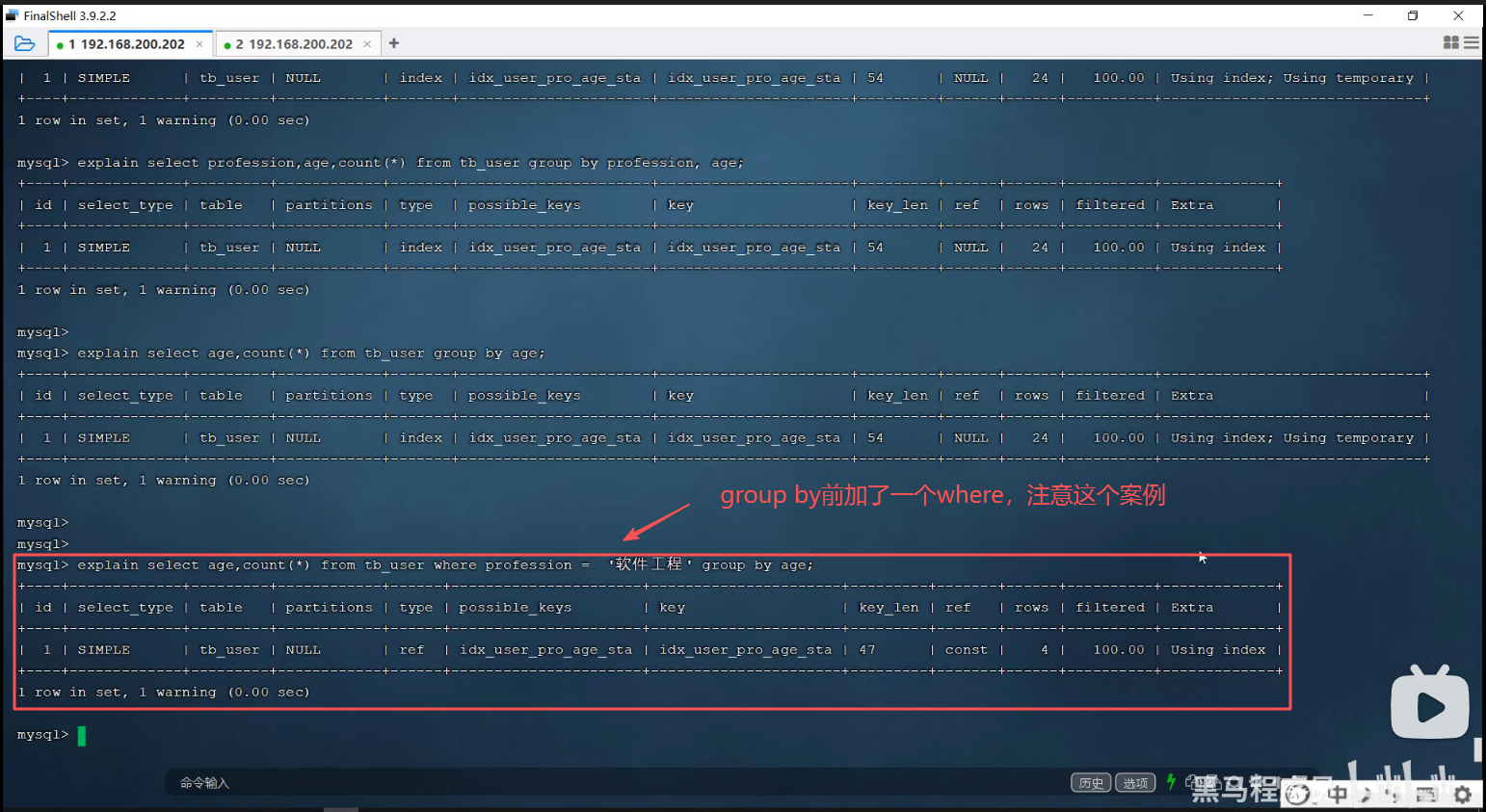
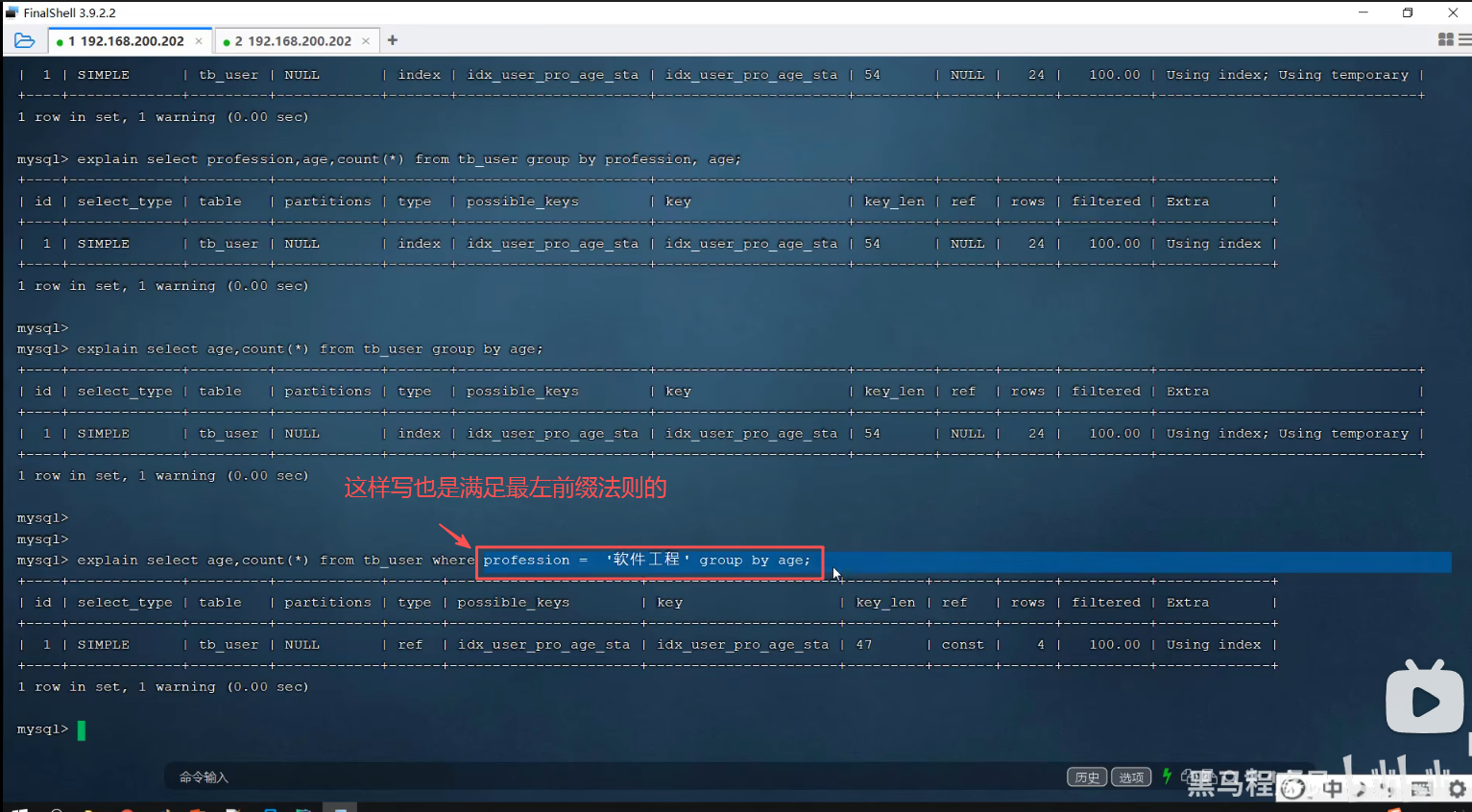
P35 group by优化
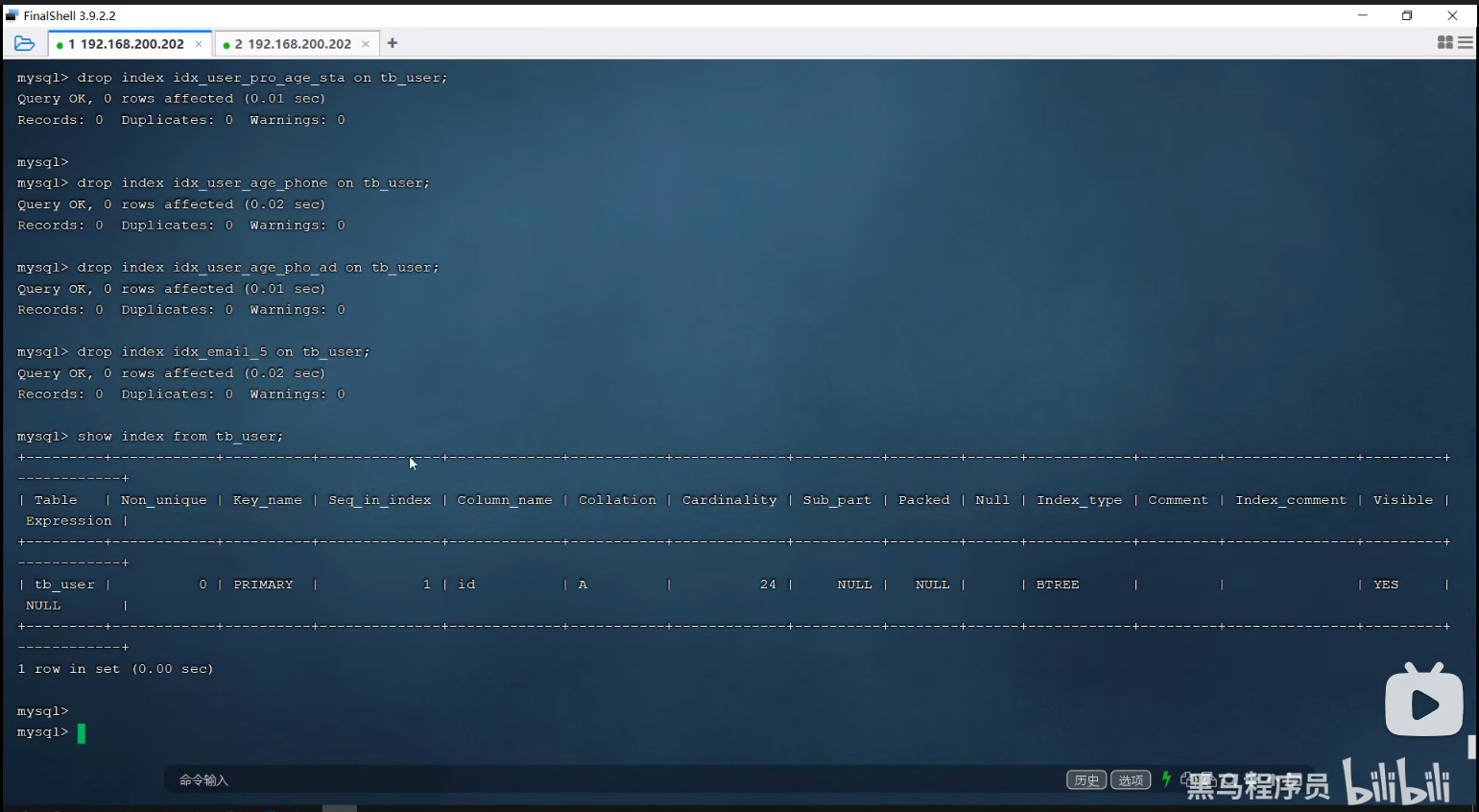
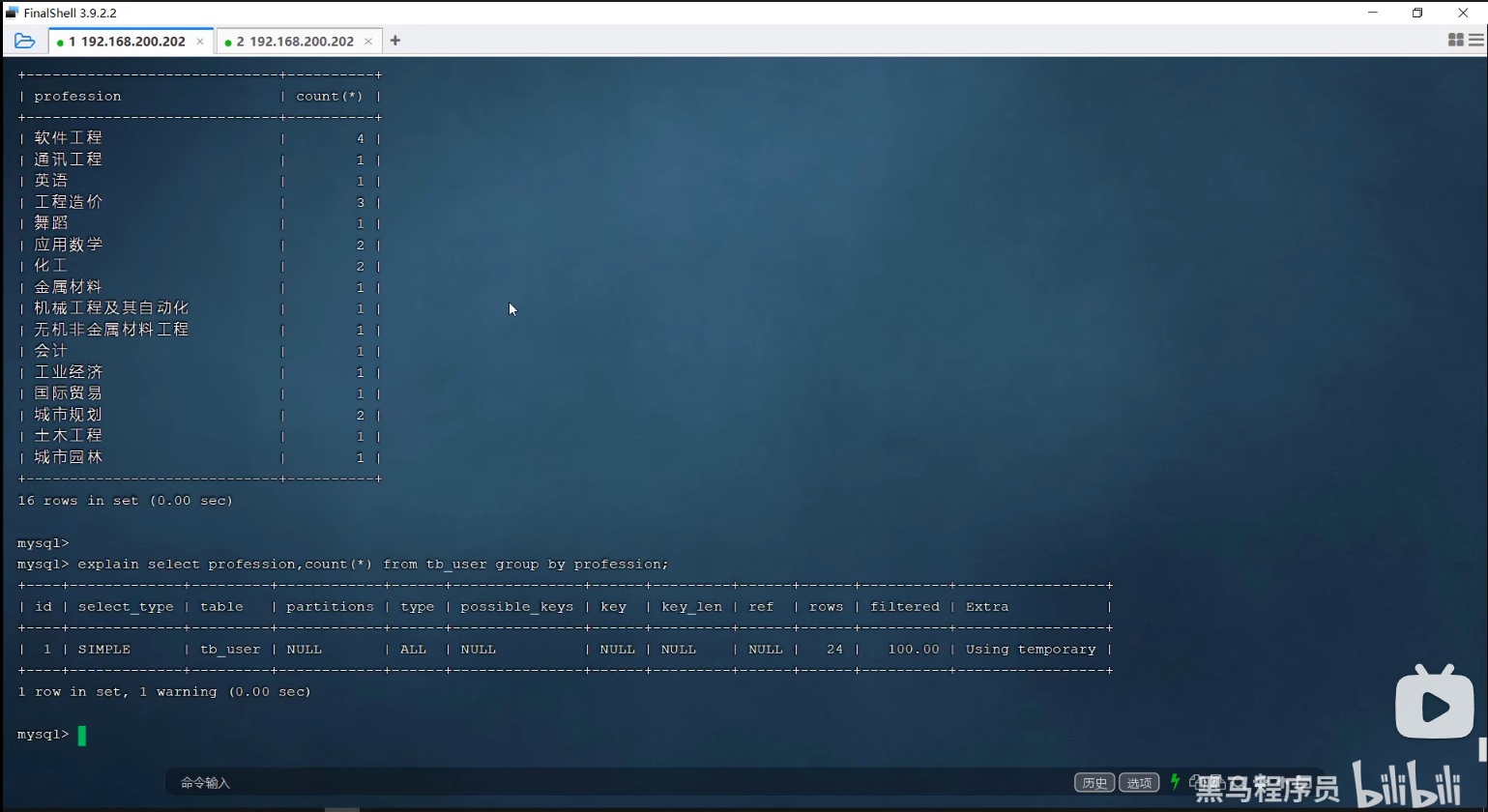
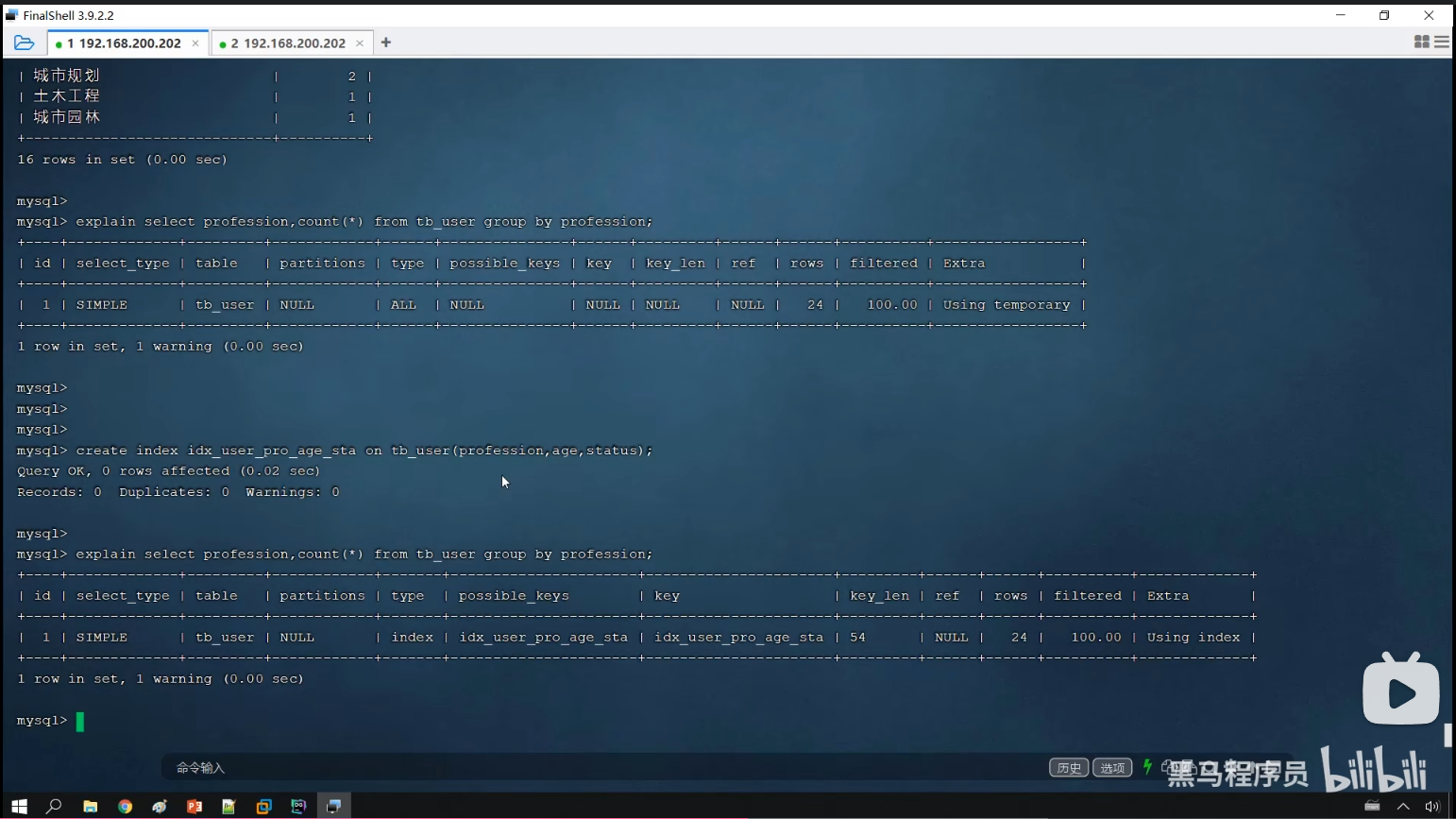
P36 limit优化
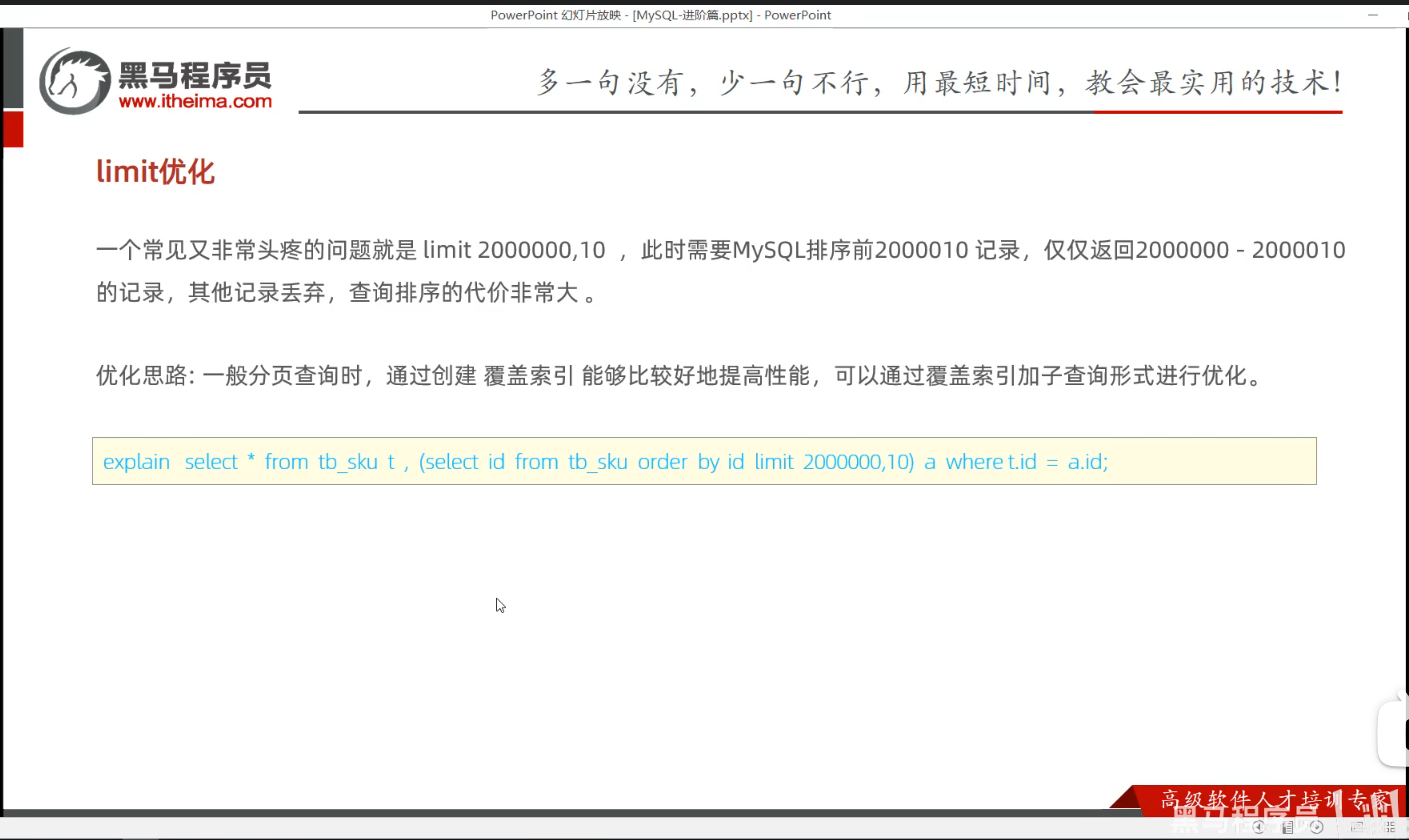
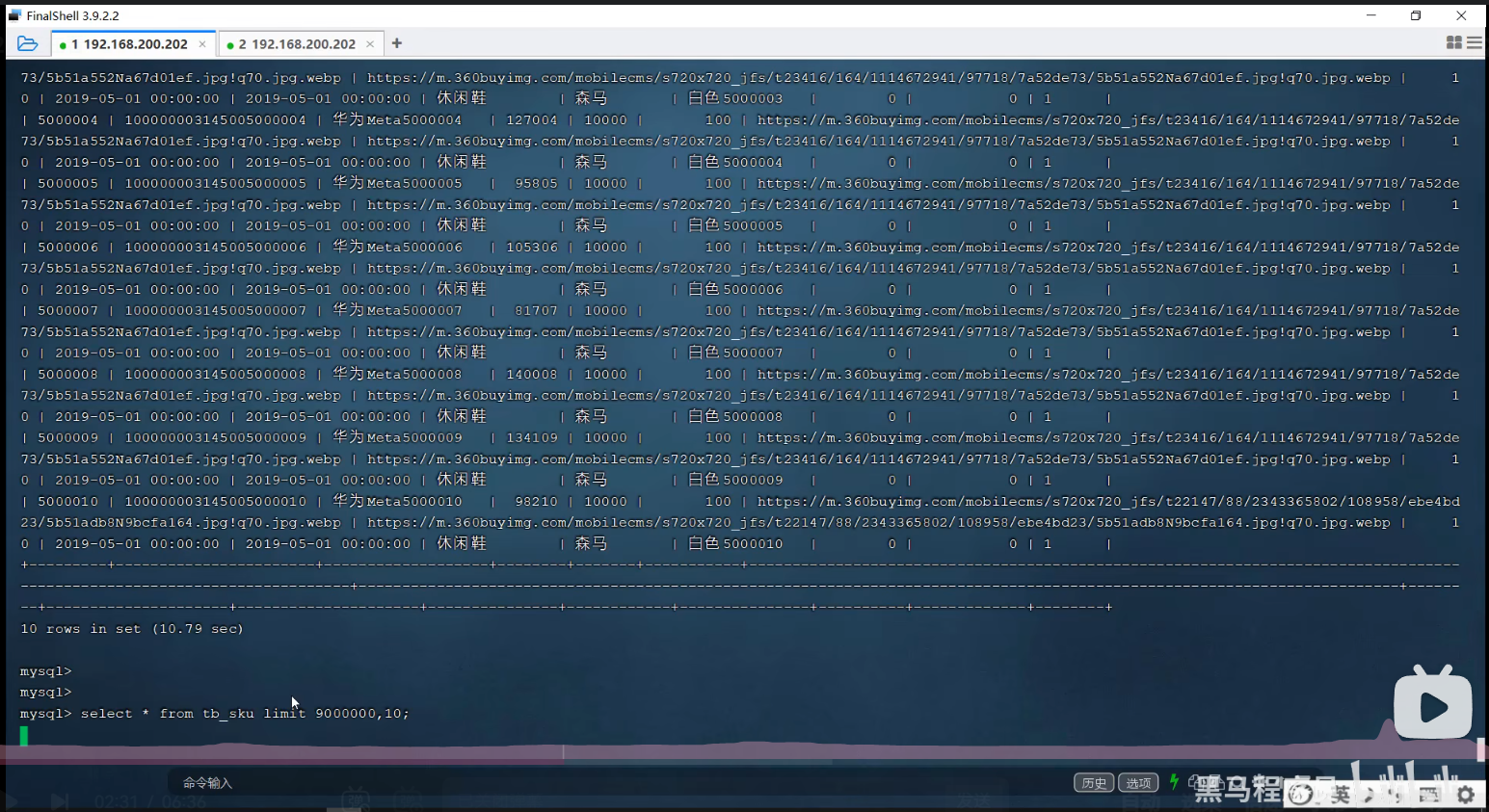
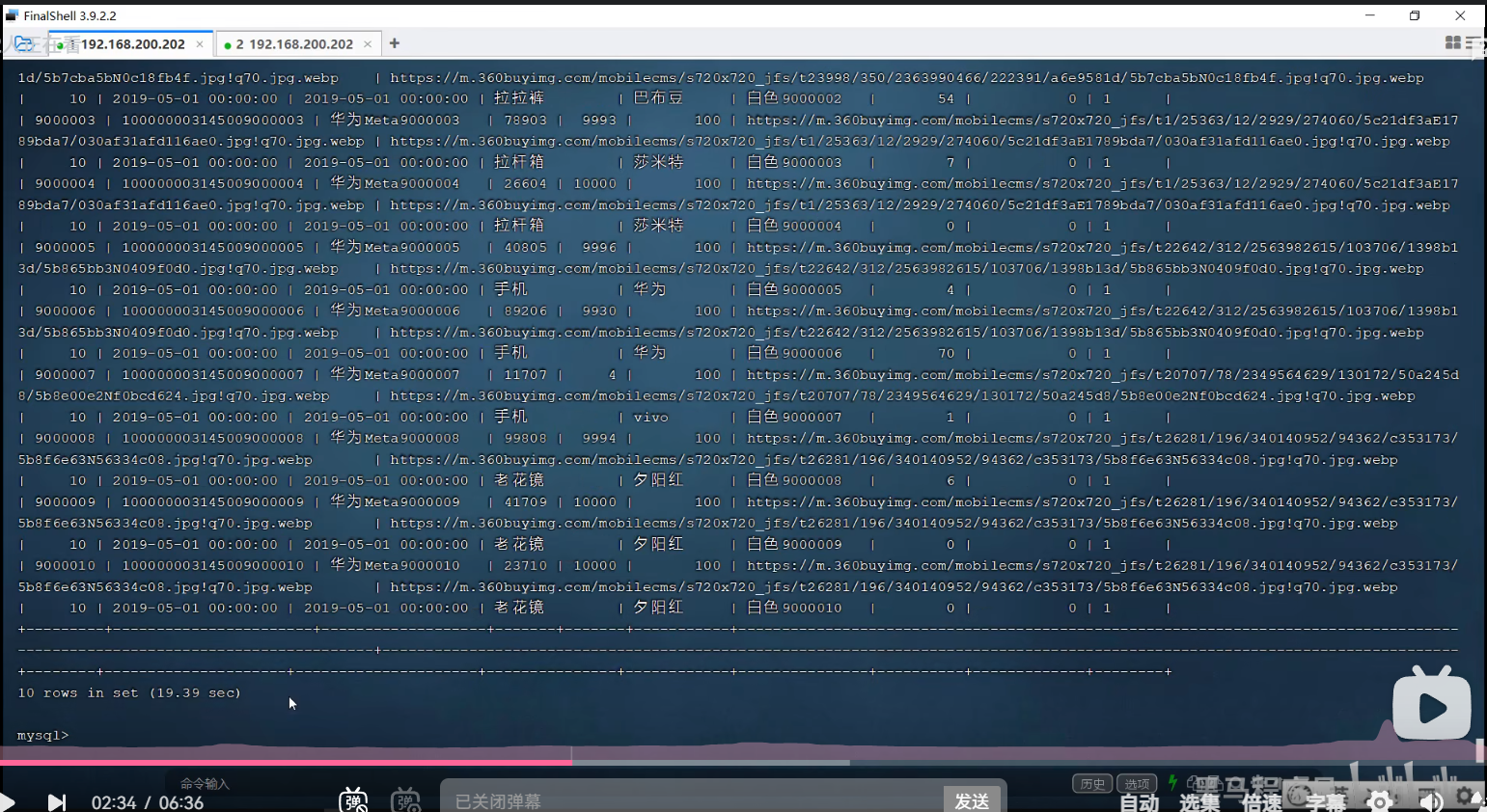
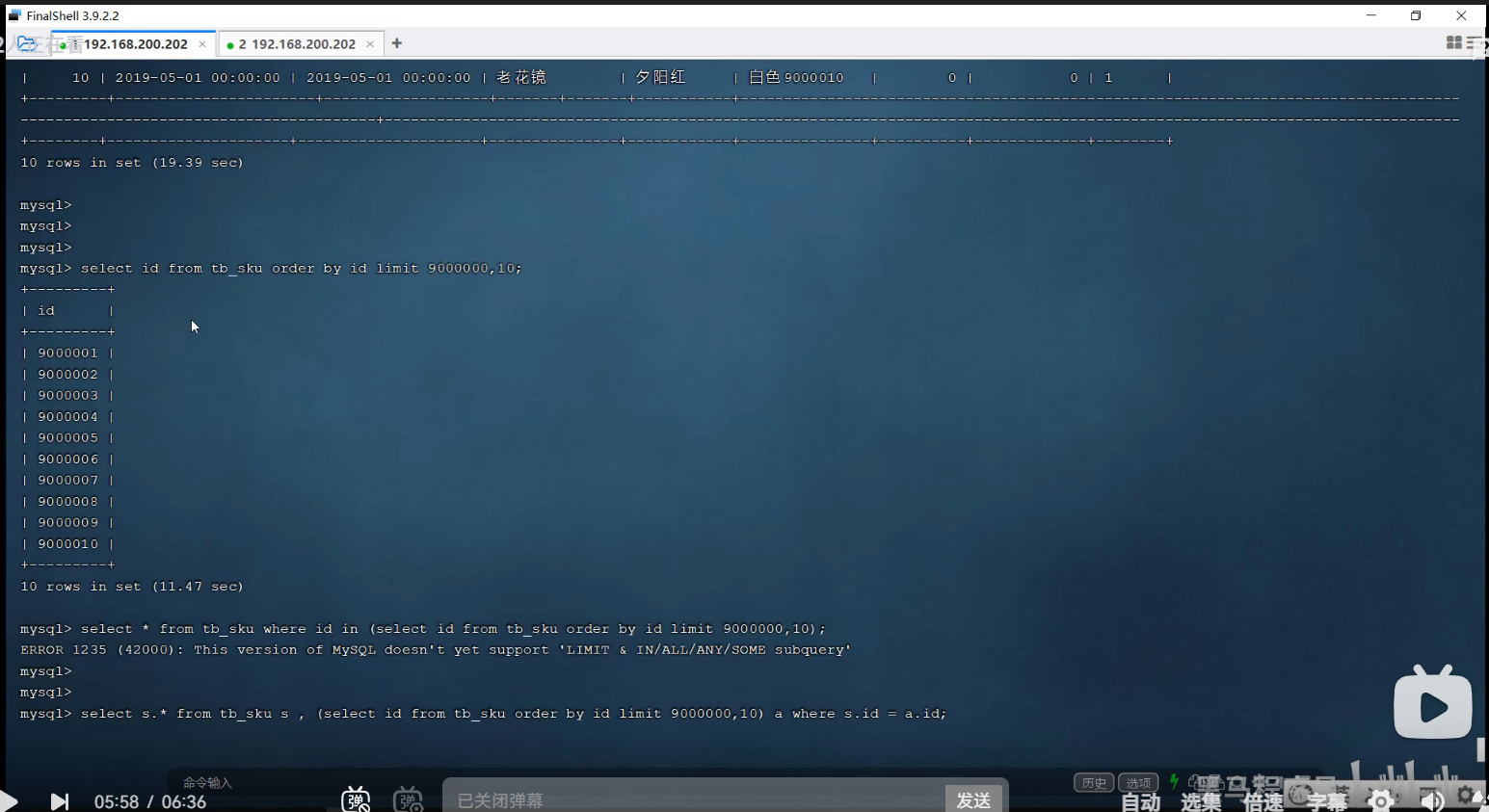
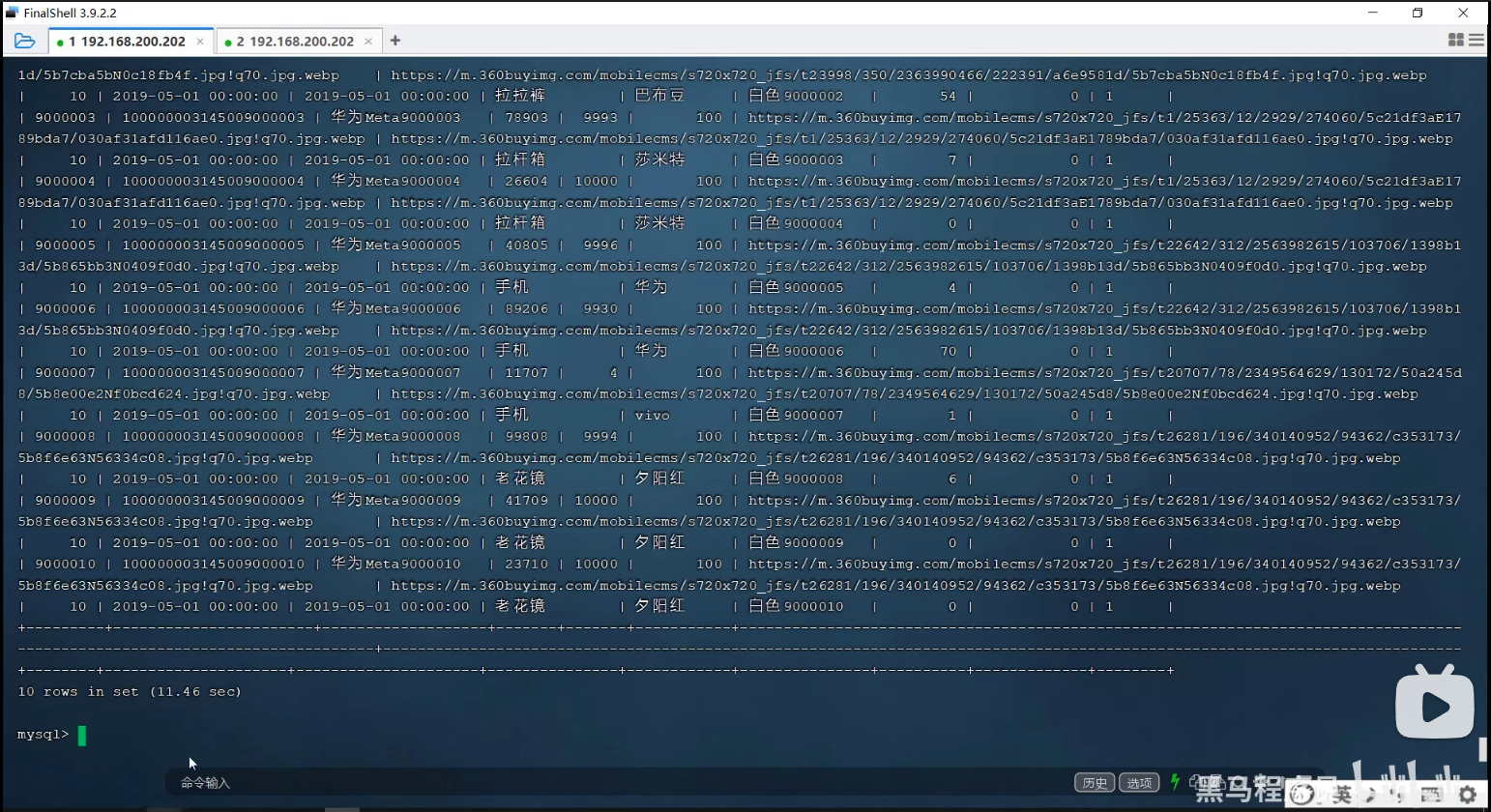
老师讲得这个方法感觉不够好,感觉可能还有更好的方法,以后有时间了,再查资料完善。
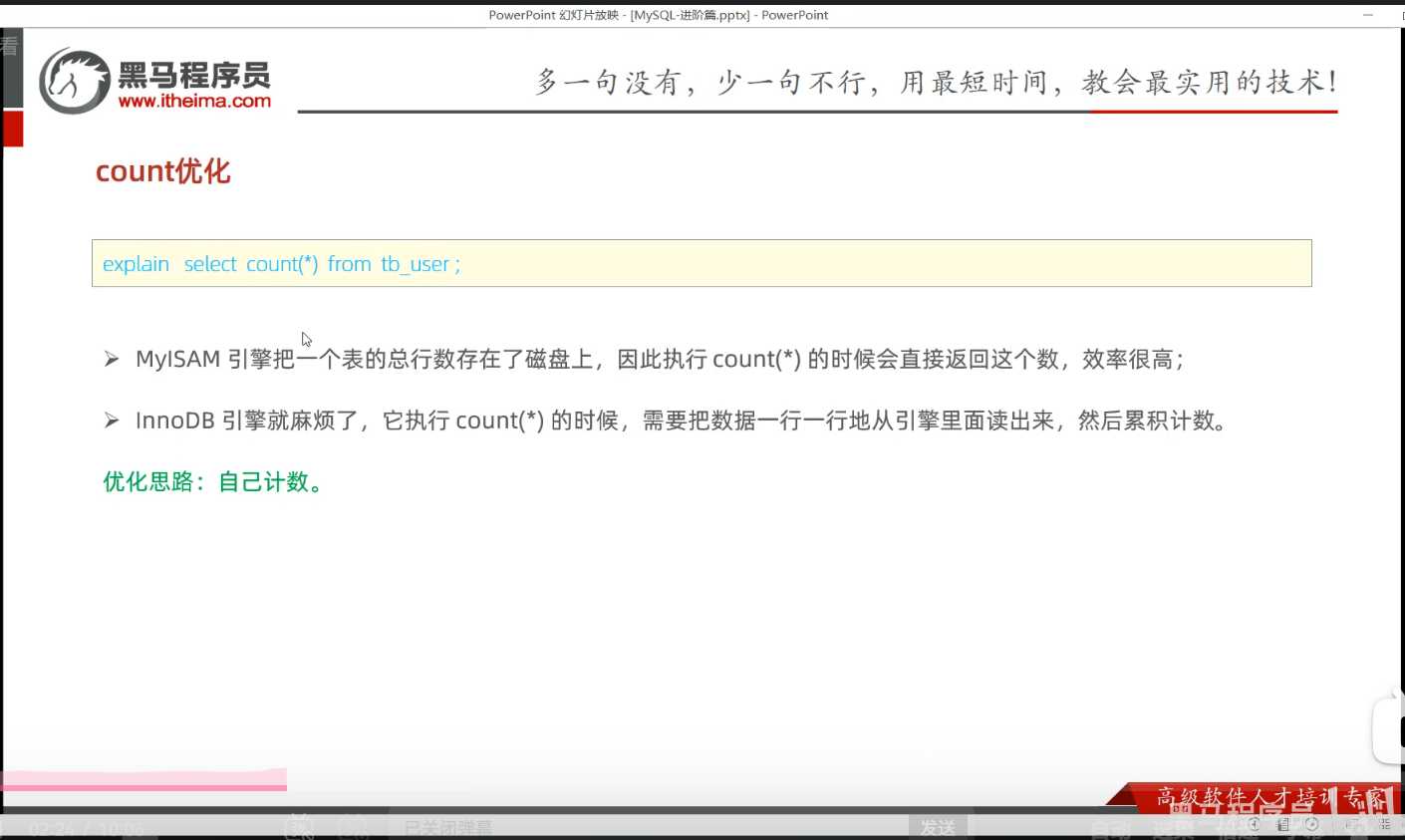
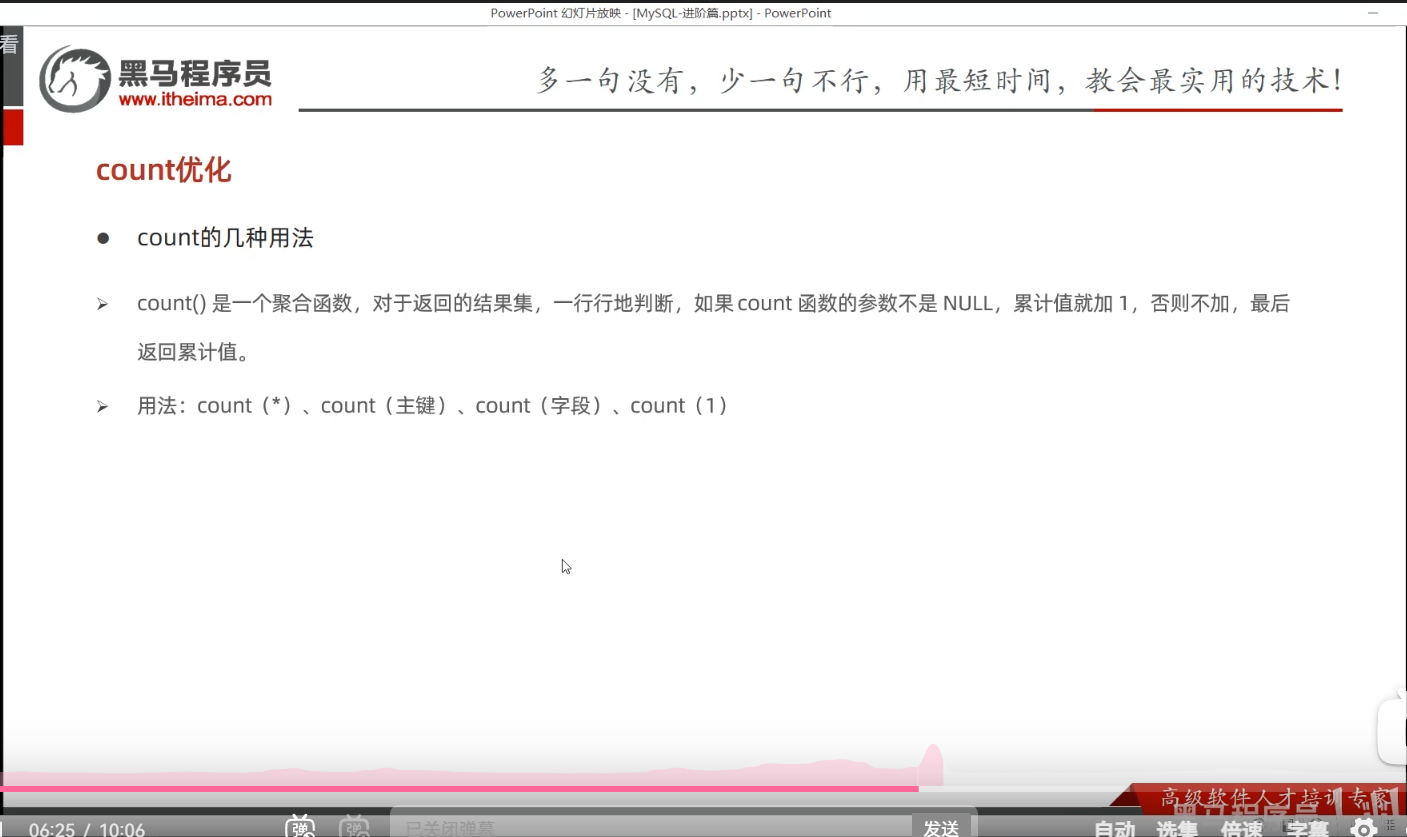
P37 count优化
学习感悟:count优化的空间很小,没有多大意义,这个操作,本身就是耗时操作,也不是常见操作,针对这样的耗时操作,为了优化用户体验,在前端加一个窗口,提示用户"系统正在统计或处理即可",这样既避免了用户等待时间太久而降低用户体验,也降低了优化的成本。

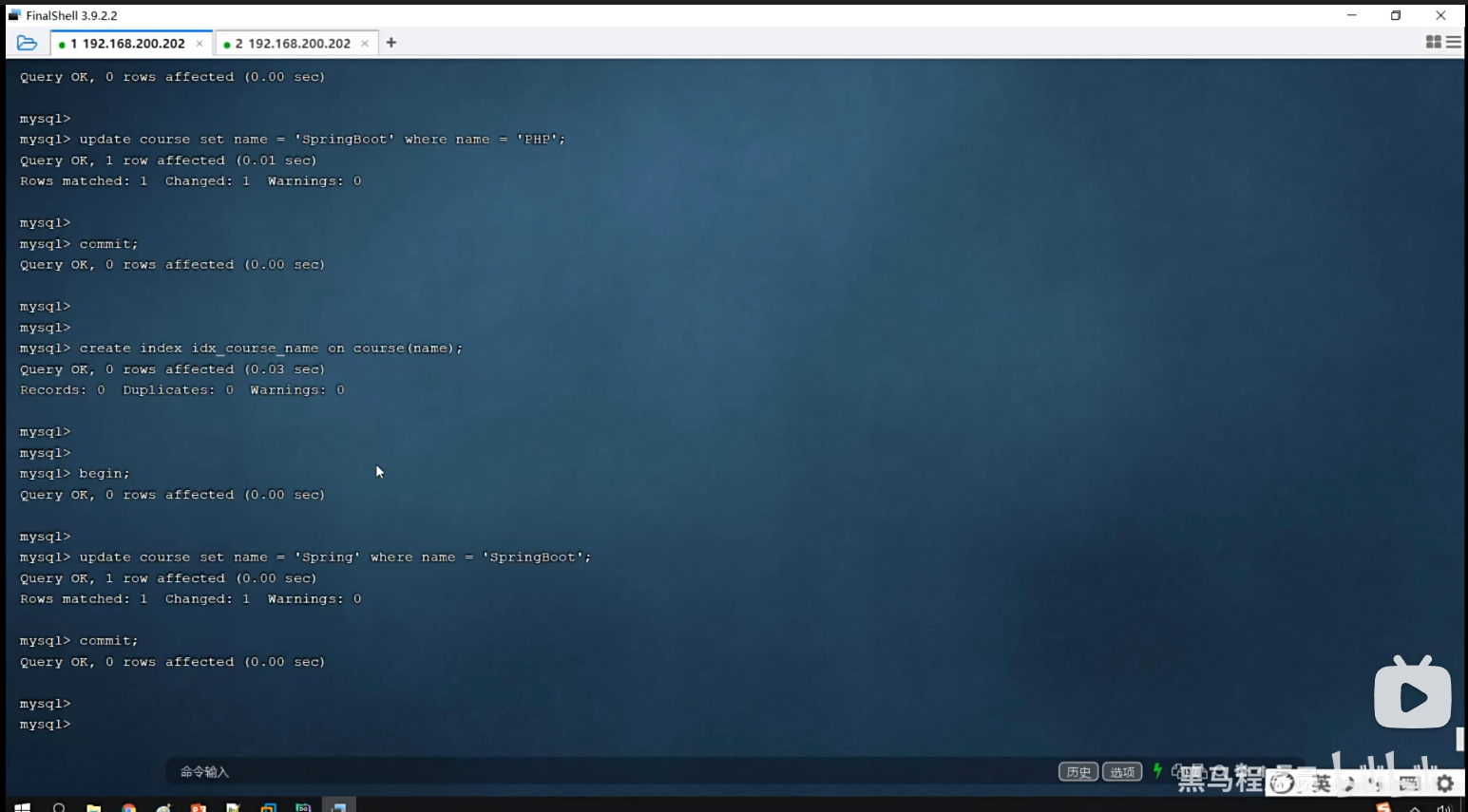
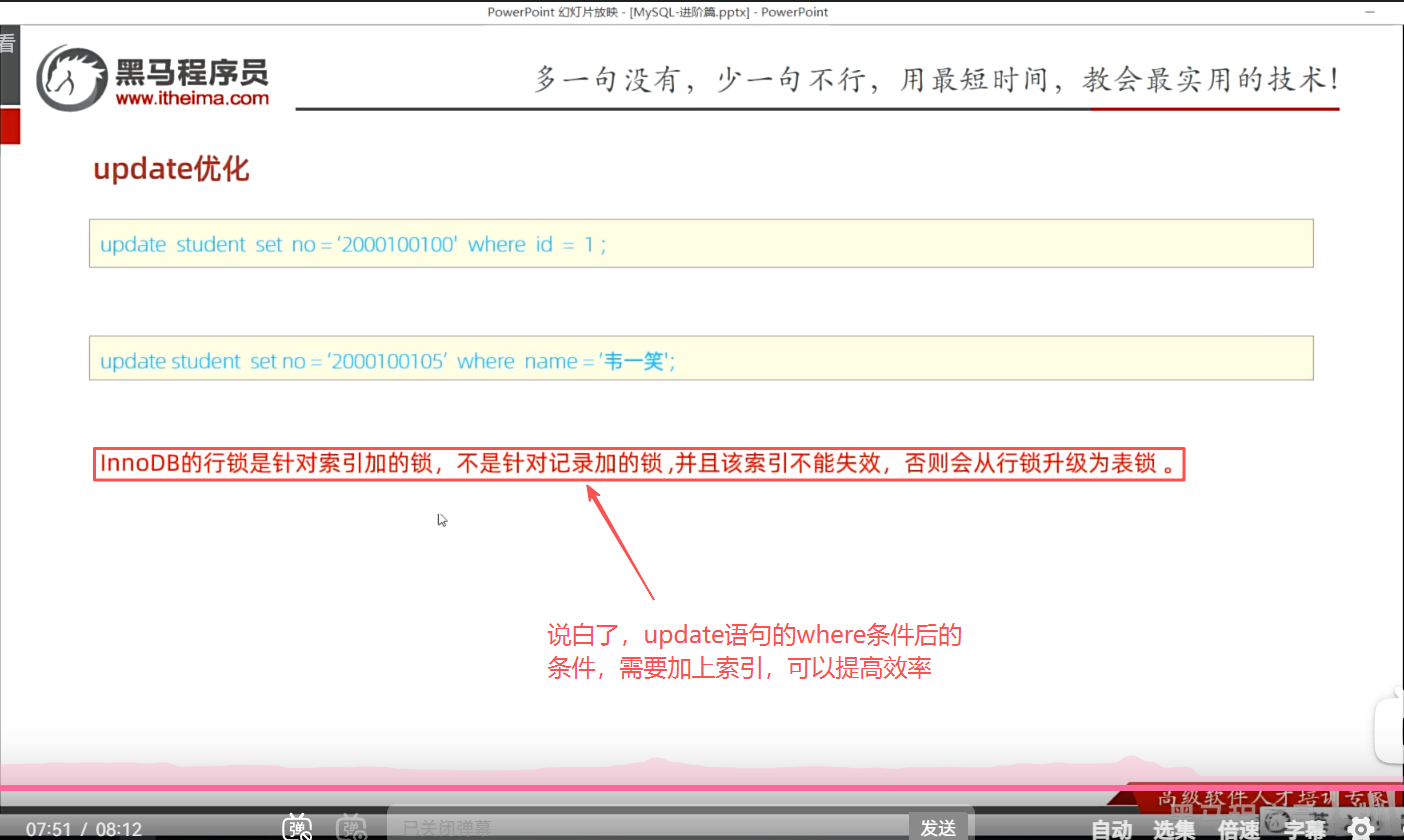
P38 update优化