1、环境说明
NVIDIA GeForce RTX 3090服务器
CUDA版本:13.1
模型:Qwen3.5 2B,注意从这个版本开始,不再区分LLM、VLM,通用
2、部署
本文以Docker方式部署vllm,直接利用pip install vllm容易出现各种兼容性问题,因此建议采用docker方式部署。
2.1 拉取镜像
docker pull vllm/vllm-openai:v0.17.0
2.2 模型下载
通过阿里魔塔下载即可,
https://modelscope.cn/models/Qwen/Qwen3.5-2B/summary
modelscope download --model Qwen/Qwen3.5-2B README.md --local_dir ./models/Qwen3.5-2B
2.3 创建容器
拉取完成之后,执行以下命令创建容器
docker run -d --name qwen35 --gpus all --ipc=host --shm-size=16g -p 8000:8000 -v /home/zeekr/work/mycharm/qwen/Qwen3.5-2B:/models/Qwen3.5-2B:ro -e NCCL_P2P_DISABLE=0 -e NCCL_IB_DISABLE=1 -e VLLM_USE_V1=1 vllm/vllm-openai:v0.17.0 --model /models/Qwen3.5-2B --served-model-name Qwen3.5-2B --tensor-parallel-size 1 --max-model-len 16384 --kv-cache-dtype fp8 --gpu-memory-utilization 0.9 --max-num-seqs 4 --max-num-batched-tokens 8192 --language-model-only --enable-prefix-caching --default-chat-template-kwargs '{"enable_thinking": false}' --host 0.0.0.0 --port 8000参数说明
-v 参数,/home/zeekr/work/mycharm/qwen/Qwen3.5-2B为宿主机模型存放绝对目录
冒号后面的是容器内部的模型存放目录:/models/Qwen3.5-2B,注意此处的目录与---model参数保持一致,这里是vllm的指令;
--served-model-name 是后续post请求访问的名字,可以和--model不一致,但这里的和post请求时要保持一致,否则会报错。
--max-num-batched-tokens 这个参数要改小,否则24G显存不够用
成功启动后,可以查看日志,后面是容器号

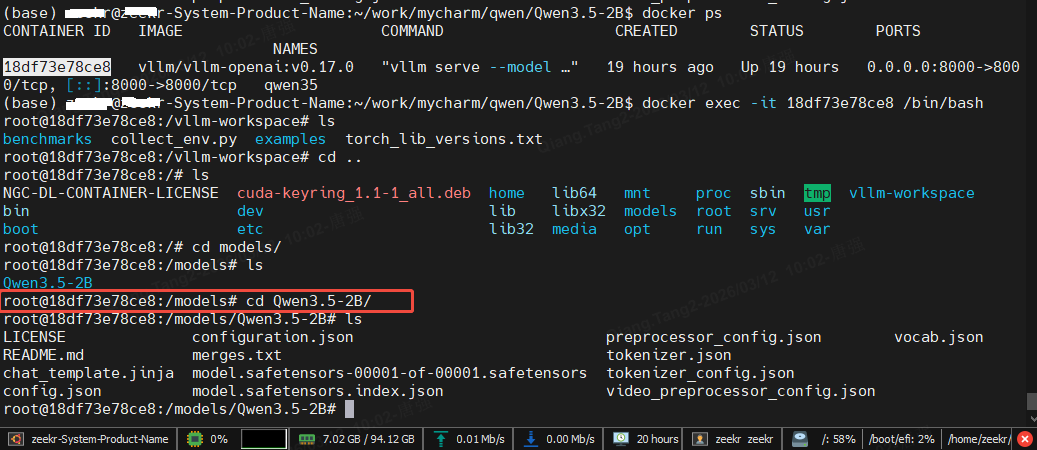
docker logs 18df73e78ce8
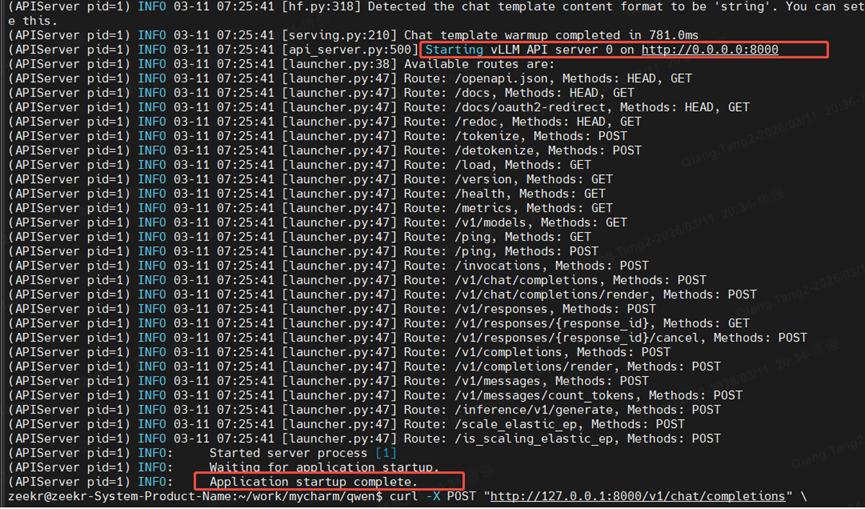
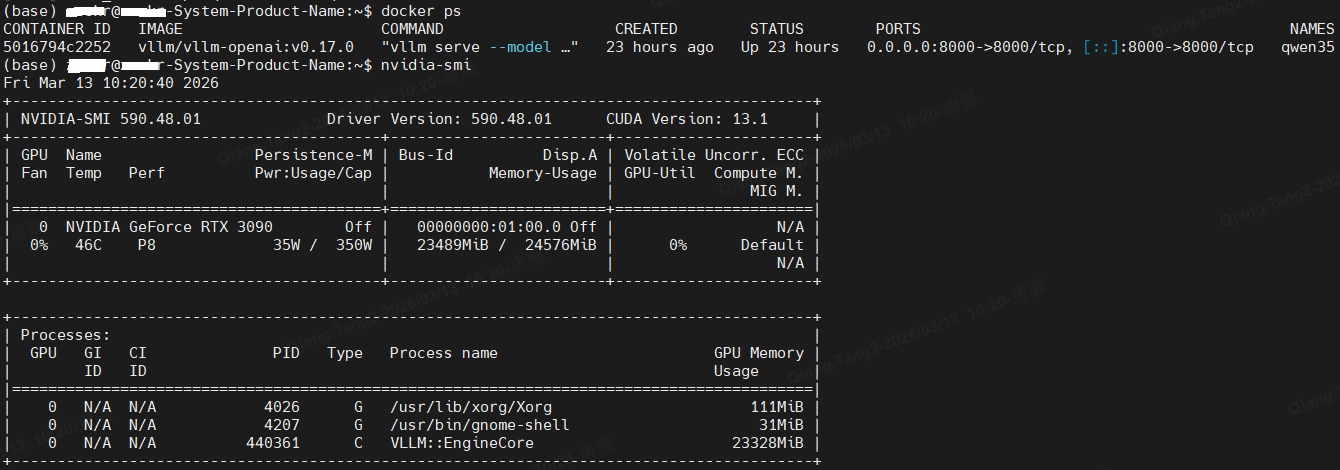
容器启动后,GPU显存资源占用,可以看到显存已经23G了,所以调小max-num-batched-tokens参数非常有必要,否则会引发OOM错误。
3、请求
3.1 纯文本请求
3.1.1 curl命令直接请求
服务起来后,可以通过Curl进行测试:
curl -X POST "http://127.0.0.1:8000/v1/chat/completions" \
-H "Content-Type: application/json" \
--data '{
"model": "Qwen3.5-2B",
"messages": [
{
"role": "user",
"content": "日本是美国的吗"
}
]
}'回复内容:

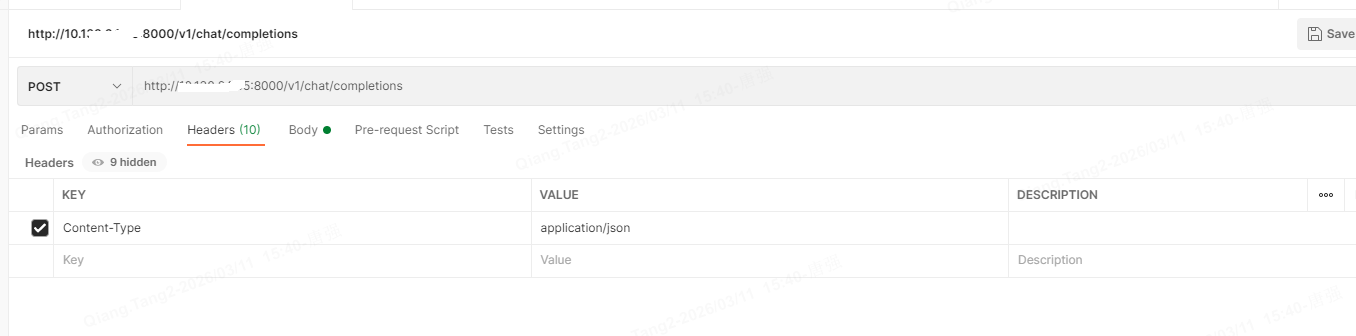
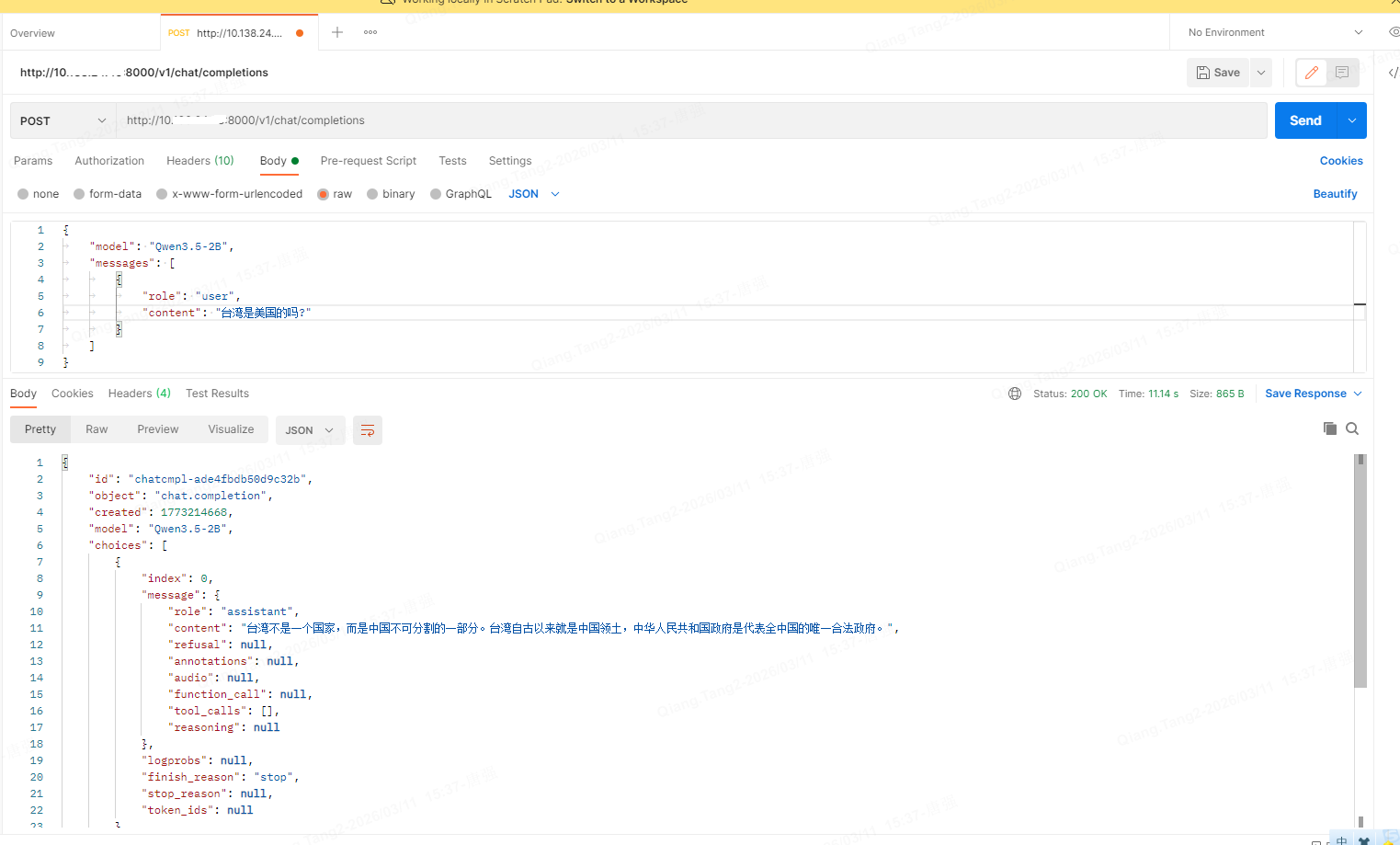
3.1.2 内网通过 postman 远程访问
也可以在本地利用IP地址+端口号的方式通过postman完成请求,postman在办公笔记本上,访问的是本地工作站的3090里的容器服务。
请求方式:post
header 和body设置如下
http://10.**.**.**:8000/v1/chat/completions
Headers
Key:Content-Type Value:application/json
Body,选择raw,把下列json沾进去即可
{
"model": "Qwen3.5-2B",
"messages": [
{
"role": "user",
"content": "日本是美国的吗"
}
]
}点击send进行请求
http://10.138.**.**:8000/v1/chat/completions,**替换成ubuntu的地址
3.2 图片 + 文本识别
上面是纯文本调用的例子,需要重新创建容器,把--language-model-only这个参数去掉,这样,模型就可以同时处理文本和图片以及视频,如果是图片加文本可以将body换成以下内容即可
{
"model": "Qwen3.5-2B",
"messages": [
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are a helpful assistant."
}
]
},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://qianwen-res.oss-accelerate.aliyuncs.com/Qwen3.5/demo/RealWorld/RealWorld-04.png"
}
},
{
"type": "text",
"text": "图片里有什么?"
}
]
}
]
}下面这个是图片:

如果上传新图片,可以将图片传入oss,获取图片链接替换即可

获取链接方式是通过阿里oss实现,自己注册个账号即可。
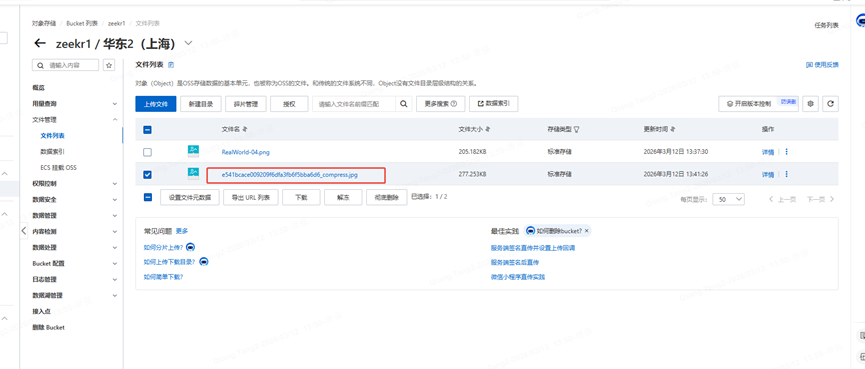
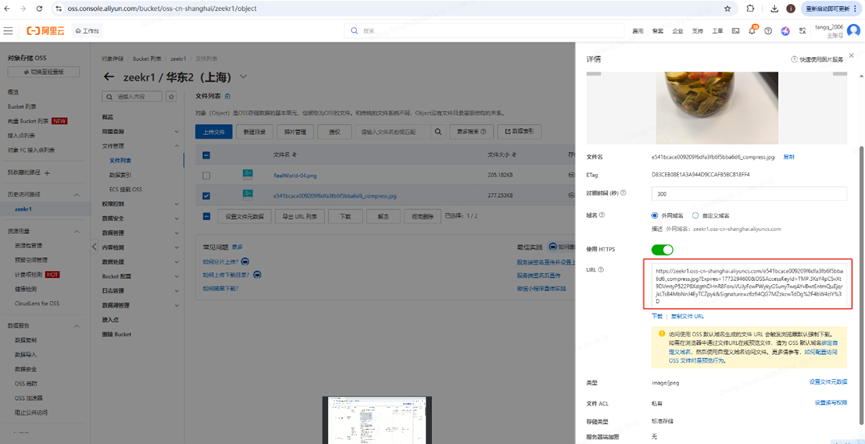
实际请求界面
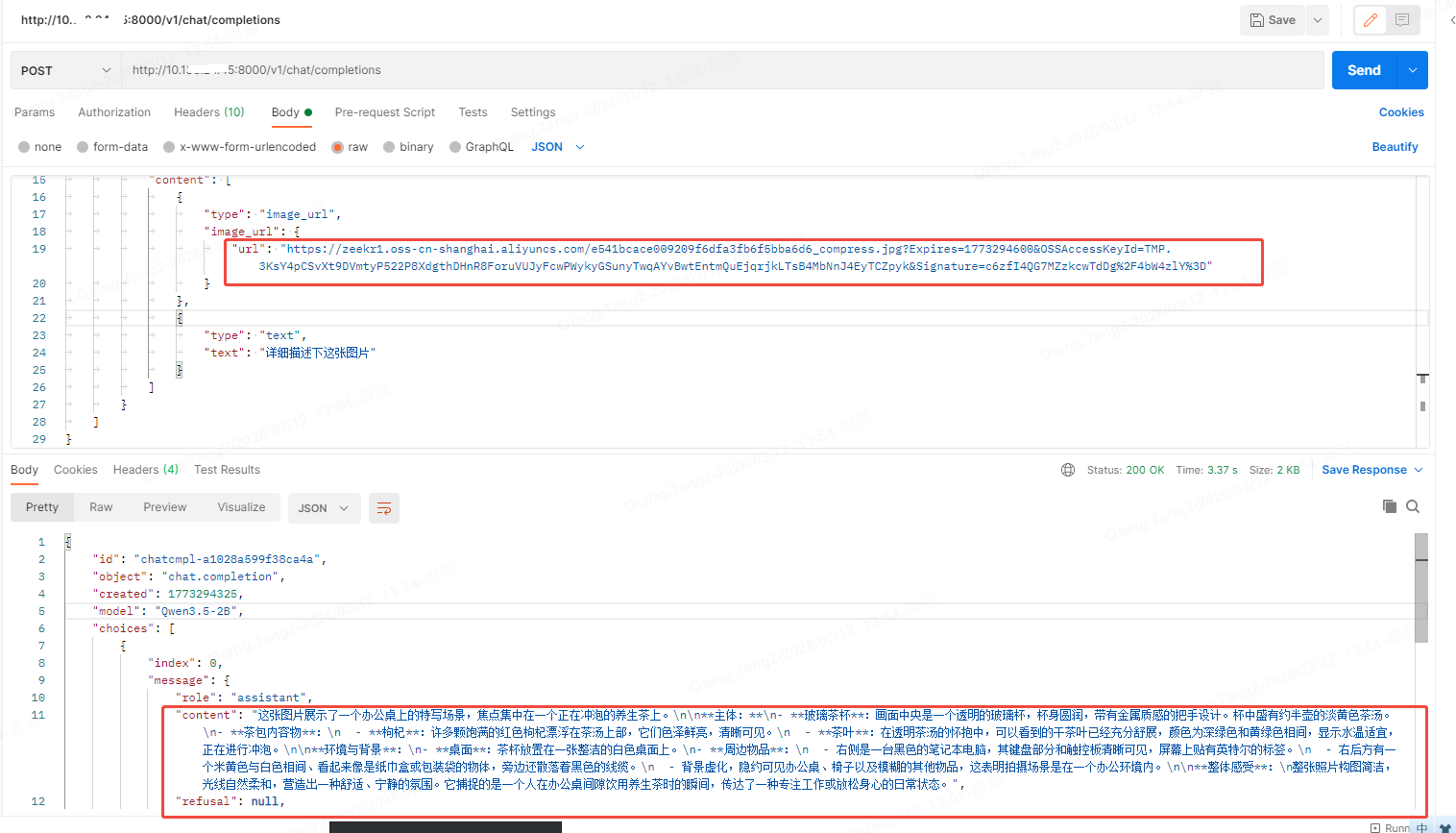
3.3 视频 + 文本识别
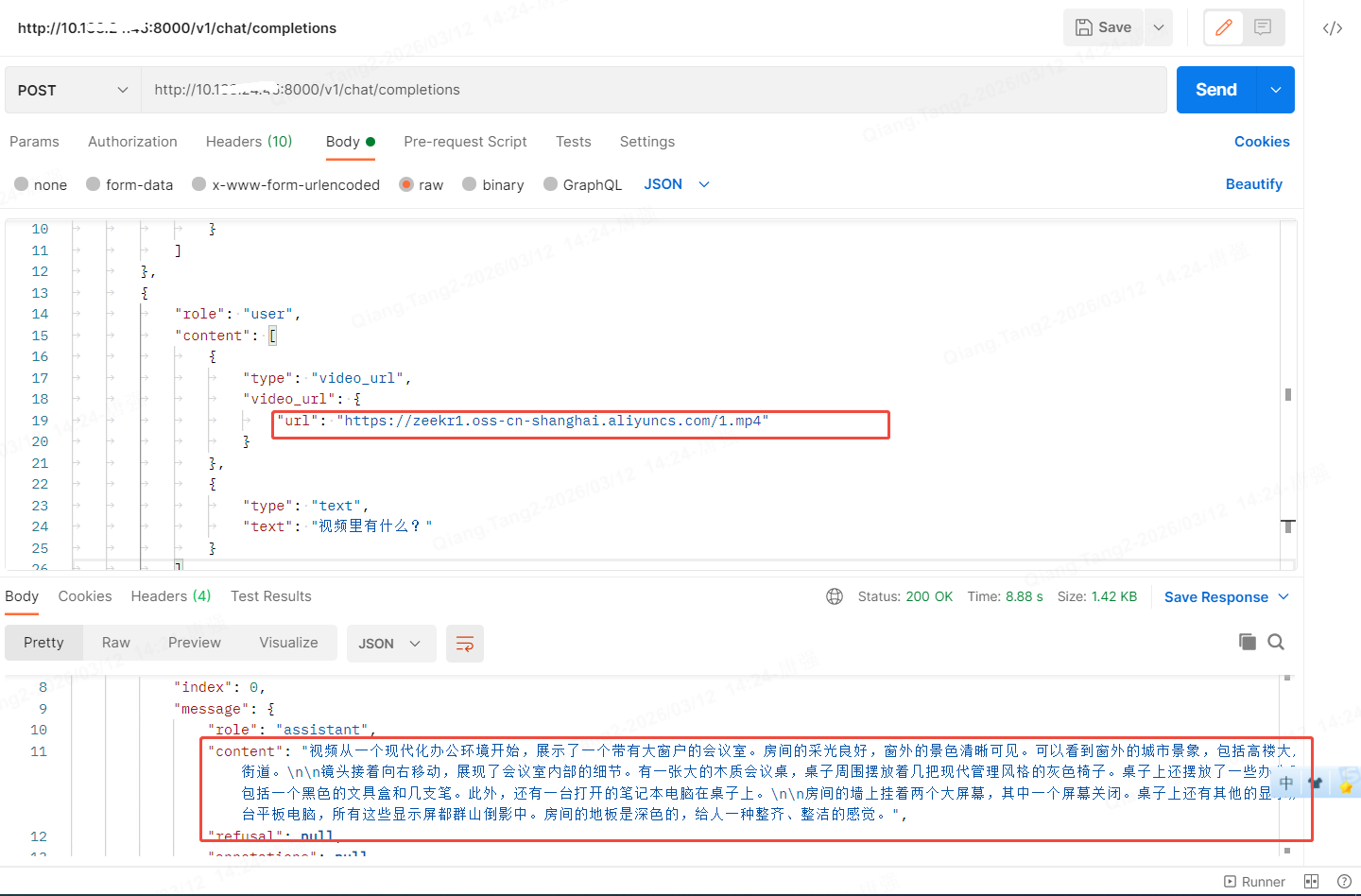
视频也是上传oss即可,小视频是一段办公室环境的视频
{
"model": "Qwen3.5-2B",
"messages": [
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are a helpful assistant."
}
]
},
{
"role": "user",
"content": [
{
"type": "video_url",
"video_url": {
"url": "https://zeekr1.oss-cn-shanghai.aliyuncs.com/1.mp4"
}
},
{
"type": "text",
"text": "视频里有什么?"
}
]
}
]
}
4、参考帖子
vLLM 部署 Qwen3.5 满血&量化版,并发性能测试,附部署脚本
https://zhuanlan.zhihu.com/p/2014273757963894922
docker下部署 vLLM 启动Qwen3-VL-32B-Instruct模型
https://developer.aliyun.com/article/1691474
Docker+vLLM内网离线部署Qwen3 流程
https://developer.aliyun.com/article/1710397
5、错误处理
dockerError response from daemon: could not select device driver "" with capabilities: \[gpu].
解决办法:
curl -s -L https://nvidia.github.io/nvidia-container-runtime/gpgkey | sudo apt-key add --
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-container-runtime/$distribution/nvidia-container-runtime.list | sudo tee /etc/apt/sources.list.d/nvidia-container-runtime.list
sudo apt-get update
sudo apt-get install nvidia-container-runtime
systemctl stop docker
dockerd --add-runtime=nvidia=/usr/bin/nvidia-container-runtime参考链接: