1、介绍
本次开发完全基于AI进行:所有代码、测试案例以及XML Schema均由AI生成,绝大部分代码来自DeepSeek和Kimi。这类似于"氛围编程"(vibe coding),但不同之处在于:提示词完全由手工编写,全程主控,并根据反馈情况实时调整提问方式、整理上下文,最终将多轮交互汇聚成完整的代码库。我在想,要实现真正的AI编程,必须躬身入局,学会在128k的上下文中编写有效的提示词,保存多轮交流中的关键信息,构造长期有效的"记忆体",并时刻驱动测试代码来验证所输出的代码的正确性,并确定后续的处理。只有这样,才能让AI的产出真正融入项目,而非杂乱无章的代码堆砌。
使用大模型生成代码的时候,发现不同的大模型生成的代码质量有细微差别,目测差别不大,但这细微的差别也会导致多轮重构和反复debug,我选用LLM的路径是 deepseek 3.1 kimi2 think kimi 2.5。不过deepseek 推出1M上下文之际,debug变得尤为方便,可以一次性加载大量代码和历史对话,避免循环往复地整理和重写提示词,提升了效率。
这次AI编程不再是单向的指令输出,而是一场人机协作的深度对话。把自己当作创作者,各个大模型当作牛马,思想当作画布,在浩瀚的思绪中有效操控受限的上下文空间,提炼思想的精髓,以测试案例为栅栏,并由AI反复淬炼成最终的成果,让AI成为创造力的无限延伸。
代码发布在
https://github.com/lxx-com-cn/hsite-workflow,如果方便,欢迎点一个star,我想在儿子面前起到示范作用,鼓励他未来也能在开源社区做一些有意义的事情。如果你们在项目中使用,也建议也采用纯AI编程的方式来完善和改进,念想和愿望需要实践来承载:我们拭目以待,未来会有更多项目由纯 AI 开发完成,而你我都是见证者和实践者。
1.1、背景概述
这些体验源自于在私域平台中工作流设计的亲身实践,为了更好的说明这一设计的初衷和功能,这里稍微介绍下私域平台的内容,有助于理解workflow的设计初衷和功能。私域平台不是传统区域医疗平台和医疗系统的叠加,而是构建一个区域级、私有化部署的健康大平台,以"聊天系统 + AI Chatbot + AI agent + 业务工作流 + 医疗区域数仓"为核心,向下聚合全域医疗健康数据,向上承载医保、医疗、医药、健康管理服务,构建多方共赢的"医疗健康超级入口"和"数字新基建"。在这套体系从上往下包括了业务表单处理,业务API调用,数据流的处理,以及AI业务处理,可以归纳有4层能用到工作流:
- 表单层:基于业务表单的多人流转业务流程(传统BPM范畴);
- API层:基于REST及Spring Bean的API编排业务流程(本文重点研究的范畴);
- 数据层:围绕数据处理的业务流程,传统是ETL的范畴;
- 智体层:基于AI Agent的动态工作流,由其他系统支撑;
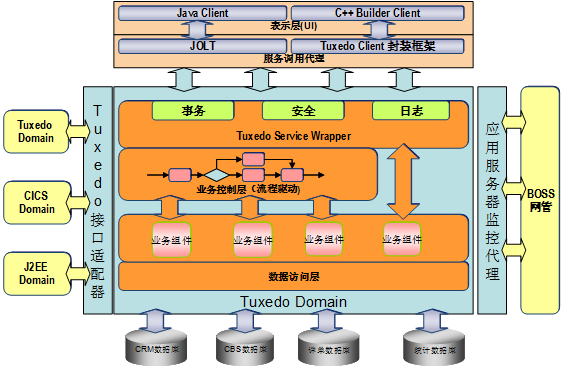
之所以将API编排和数据流处理作为工作流的重点,源于20年前在移动BOSS 1.5时代的开发体验。当时就采用API编排技术,将不同API连接成整体解决方案,每个API对应一段SQL或简单业务功能,通过MAP做数据扁平化传输,借助Eclipse RCP建模器实现图形化拖拽设计,编译部署后发布为一个功能号,前端应用只需调用该功能号即可完成业务。这种模式极大提高了开发效率,能在2-3个月内完成一个省级BOSS系统。
这段历史让我深刻体会到,API编排能最大化复用已有业务沉淀,快速响应新需求,这正是当前workflow设计的核心理念。
1.2、思路分析
API编排的概念是微服务架构落地伴生而来,原本一次请求即可处理完成的业务,现在可能需要多次请求才能完成,为了降低前端逻辑的复杂性并提高前后端交互效率,BFF层应运而生。BFF作为前后端的代理层,提供了一个业务接口聚合层,其核心职责是为前端(PC、小程序、H5等)适配不同的业务场景,降低客户端与业务端的耦合,前期通过硬编码的方式来实现BFF层的需求,是最简单最直接的方式。但随着BFF层承接业务需求的增多,采取硬编码方式容易产生编码效率低、编码细节难以规范、调试测试效率低等问题。
服务编排在统一规范的基础上提供了业务逻辑的柔性设计,通过可视化设计快速的API的编排、调试、测试和上线。看上去服务编排和工作流引擎在形式上趋同,但两者不一样。在脚手架/低代码平台会提供类似Flowable、Activiti、Camunda实现的OA审批工作流系统。这种工作流基于表单模式,通过扩展表或者表单表上添加辅组字段满足业务的审批流转,最终形成留痕记录。
前面所述属于典型的人-机交互模式,而服务编排,更多的是机-机交互模式,强调的是服务(API)的有序调用。工作流引擎通常用于长周期、多人参与的业务流程(如审批),而服务编排专注于短周期、服务间的自动调用。
1.2.1、BFF的作用
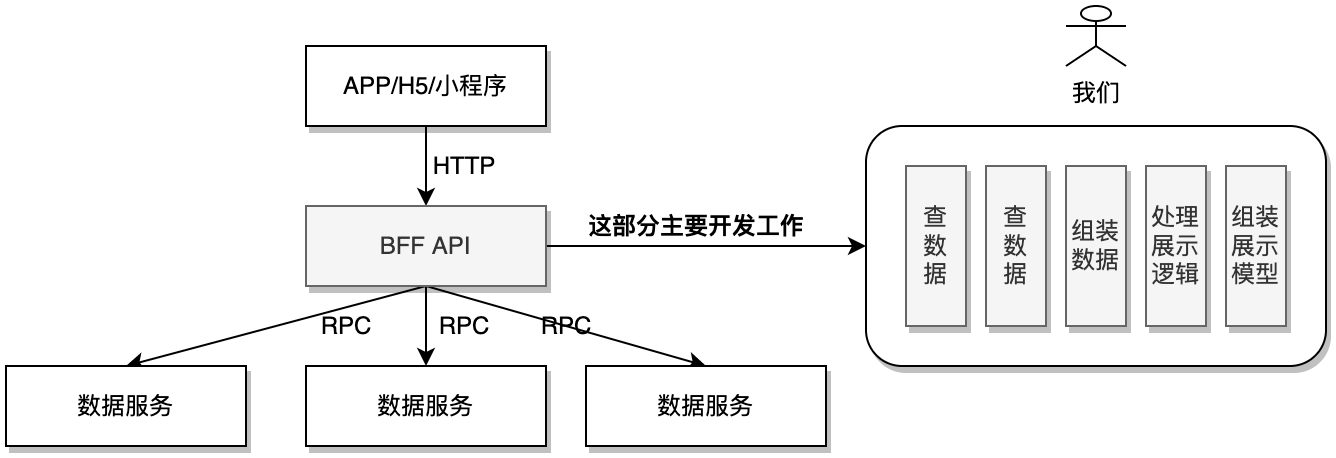
微服务体系架构是一种前后端架构,在前后端之间添加中间层 (BFF:Backend For Frontend),以解决服务的汇聚和调用,把BFF加入在前后端架构之后,前端服务不再直接访问后端微服务,而是通过 BFF 层进行访问。从微服务的角度来看,由于有关 UI 逻辑的数据在 BFF 层进行了处理,减少前后端细颗粒微服务之间的相互调用。
BFF层的主要职责是组合使用后台数据,并处理部分前端展示逻辑,如数据裁剪、格式转换等。采用BFF之后的开发逻辑:通过后台工具查到原始数据,然后按照业务要求,把查到的原始数据封装成API,再通过加工->组装->适配成可以展示给前端的信息,最后发送给客户端使用。这部分各个服务(API)的聚合工作主要由中间层的BFF API负责。
BFF API的处理也是有一定的业务逻辑,可以抽象为串行,并行,分支,汇聚等,包括多种服务接口的适配,可视化业务逻辑的设计,持久化保存需求,接口返回数据的裁剪、排序、格式化等操作,这些功能又可以映射为编排能力,提升微服务的复用度,降低编码及编译打包的等待时间,提高业务逻辑的快速交付能力。
如果是需要临时的数据批处理,也可以利用BFF的功能,提供了ForkJoin能力,把业务逻辑的快速编排和数据层面的高效处理有效结合起来。当然复杂的ETL任务可能会耗尽线程池或内存,面对数仓级别的数据处理,还需要使用专门的ETL工具。
从Tuxedo时代的API编排,到当前基于BFF的服务编排,技术形态在变,但复用与效率的追求始终如一。
1.2.2、BFF的功能
1.2.2.1、后端服务适配层
作为前后端的代理层,为前端调用提供一个业务接口聚合层,主要实现接口聚合和响应数据裁剪,屏蔽复杂的服务调用关系,让前端应用聚焦在所需要的数据上。其核心职责是为前端适配不同的业务场景,降低前后端的耦合。通过硬编码的方式也能实现功能聚合,但其弊端在于编码效率低、编码细节难以规范、调试测试效率低和服务治理能力弱等。
1.2.2.2、服务编排
通过流程设计,以XML/JSON描述接口调用顺序、条件分支、并行聚合等逻辑,由编排引擎解析执行,通过简单的脚本完成不同业务需求的定制,以及对接口返回数据的裁剪、排序、格式化等操作。编排后可通过在线测试的功能,直接对编排的服务进行测试,快速验证功能,降低编码及编译打包的等待时间,提升业务整体的交付效率。
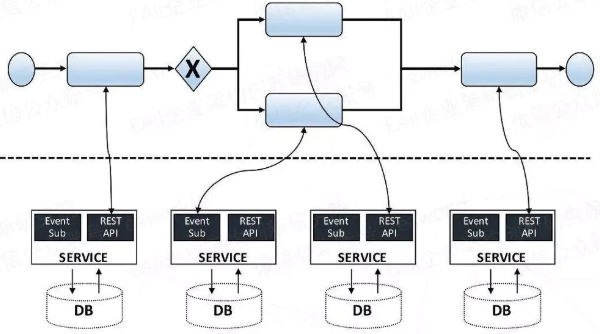
在实际的业务场景中,业务模块提供各种形态的接口,通过流程编排这些接口实现一个新的流程模型,活动模型进行赋值、invoke(调用)等,执行流程可分为顺序、分支、循环、异常抛出、异常捕获、并行等,然后给参与编排的服务提供正确的出参和入参,适配的过程就是从上下文中给入参赋值以及将出参的结果写入到上下文中。
1.2.2.3、可视化建模
通过图形建模器拖拽活动元素和连线,快速定义业务过程,生成XML/JSON描述文档。该文档既是业务流程的蓝图,也是引擎执行的依据。设计时需兼顾业务表达的包容性和未来扩展能力。
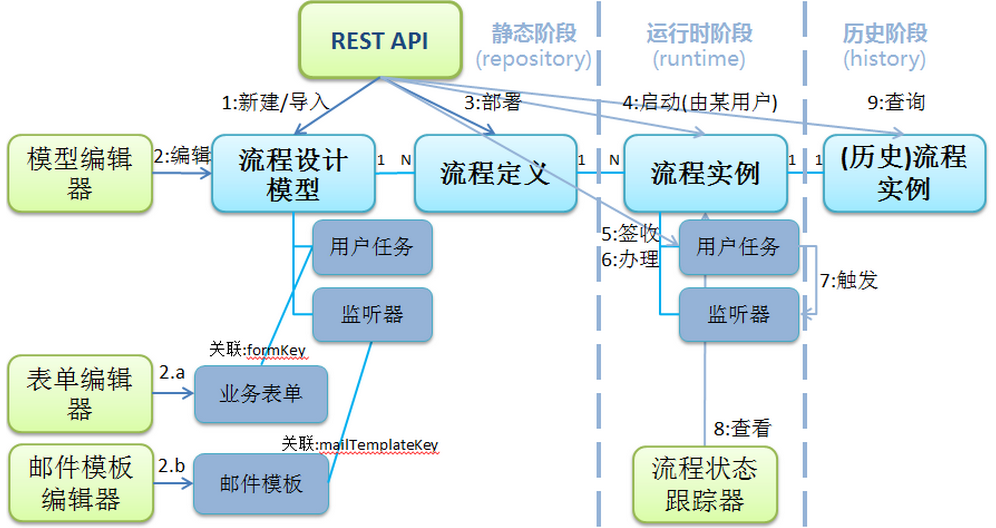
业务过程可分为三大阶段:
- 建模阶段:通过图形建模器设计流程,产物为XML/JSON文件,可保存至文件系统或数据库,并可细分为"设计"和"发布"两个子阶段。
- 运行阶段:流程调度引擎解析描述文档,按顺序、分支、并行、循环等逻辑自动调用各服务,完成业务处理。
- 完成阶段:包括正常完成、异常终止、取消等,所有状态持久化至数据库,便于审计和追溯。
自此整个项目背景,工作流历史渊源,服务编排的业务诉求便阐述完毕。
2、成果
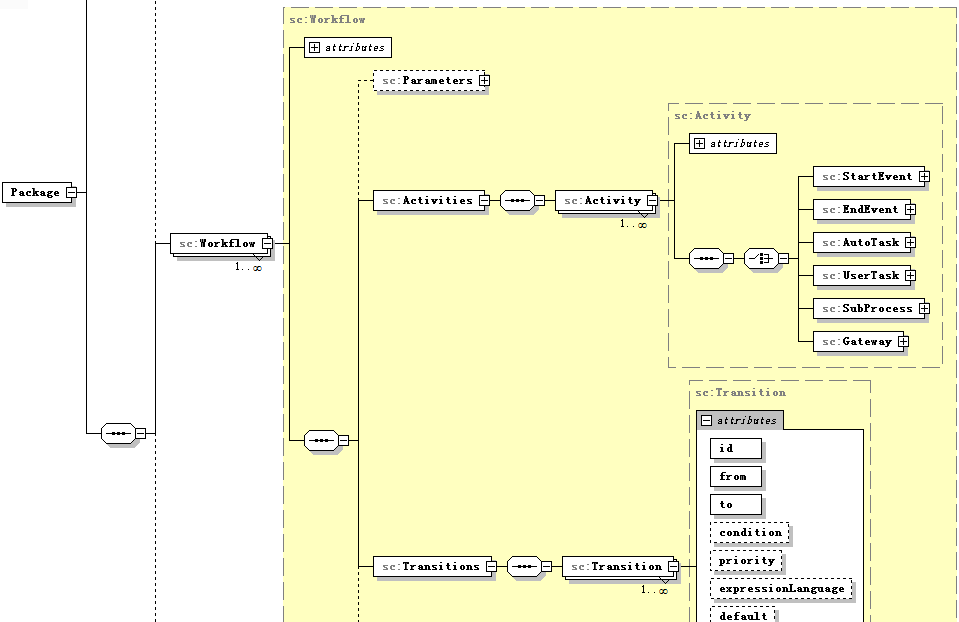
BFM引擎是一个基于Spring Boot 2.7 + JDK8 + MyBatis-Flex + MySQL 5.7构建的服务编排框架,专为BFF层API聚合设计(当前只有后台,springboot形态,还未设计web界面)。它借鉴了XPDL1.0的思想,参考了BPMN 2.0理念,通过XML定义业务流程,支持丰富的活动类型(自动任务、人工任务、子流程、网关)和灵活的数据映射,以状态机驱动执行,实现了从简单同步调用到复杂异步编排的全覆盖。
- 三层状态机联动:确保流程执行正确性,状态转换可追溯。
- 四种网关:提供排他、并行、包容、复杂分支汇聚能力,实现流程灵活控制。
- 五种子流程模式:覆盖同步、异步、事务、DAG编排、批量处理,满足多样化需求。
- 异步持久化:Redis缓冲+批量刷盘,提升写性能,降低数据库压力。
- 细粒度锁:保障高并发下的状态安全。
- 表达式与数据映射:灵活处理变量,支持复杂数据转换。
2.1、系统介绍
2.1.1、系统架构

基于业务流程管理(BFM)的引擎,支持通过 XML 定义流程包(包含多个工作流),运行时创建流程实例,驱动活动(开始/结束事件、自动任务、人工任务、子流程、各类网关)按照转移线规则执行;网关包括排他,并行,条件和复杂类型,满足各种条件判断需求;并内置了强大的表达式引擎(SpEL)、灵活的数据映射(输入/输出)、多种子流程执行模式(
SYNC/ASYNC/TX/FUTURE/FORKJOIN)、人工任务会签/或签/退转办等业务功能;同时通过 Redis 缓冲队列实现高吞吐异步持久化,并提供完善的运维监控接口。
2.1.2、模块划分
com.hbs.site.module.bfm
├── config # 配置类(持久化、线程池、RestTemplate)
├── controller # REST API接口(运维、监控)
├── dal # 数据访问层(实体、Mapper、Service)
│ ├── entity # 数据库实体(MyBatis-Flex注解)
│ ├── mapper # MyBatis-Flex Mapper接口
│ └── service # 业务服务接口与实现
├── data # 数据定义与运行时
│ ├── define # XML Schema对应的POJO定义
│ └── runtime # 运行时实例(流程、活动、工作项)
├── engine # 核心引擎
│ ├── expression # SpEL表达式求值
│ ├── gateway # 网关执行器(排他/并行/包容/复杂)
│ ├── invoker # 服务调用分发器(REST/Bean/JavaBean/Message)
│ ├── mapping # 数据映射处理器(输入/输出)
│ ├── persist # 持久化服务(Redis缓冲+批量写入)
│ ├── state # 状态机管理(活动/流程/工作项状态)
│ ├── subprocess # 子流程执行器(SYNC/ASYNC/TX/FUTURE/FORKJOIN)
│ ├── transition # 转移线评估器
│ └── usertask # 人工任务执行器
├── listener # 事件监听器
├── parser # XML解析器
└── utils # 工具类(ID生成、对象转换)2.1.2.1、config模块:配置管理
功能:提供引擎运行所需的各种配置 Bean。
业务逻辑:
- BfmPersistenceProperties:持久化相关配置(是否启用Redis缓冲、队列前缀、批量大小、间隔、线程数等)。
- RestTemplateConfig:创建 RestTemplate 和 ObjectMapper(注册 JavaTimeModule,支持 Java8 时间类型)。
- SubProcessThreadPoolConfig:为子流程异步执行提供两个线程池(普通异步线程池和 ForkJoin 工作窃取线程池)。
2.1.2.2、controller模块:对外接口
功能:提供 REST API 用于监控流程状态和执行运维操作。
业务逻辑:
- BfmPerformanceMonitorController:查看队列积压情况、消费统计、强制刷新队列、健康检查。
- ProcessOpsController:查询可恢复流程、恢复流程执行、获取历史、强制终止流程(部分方法为示例骨架)。
2.1.2.3、dal模块:数据访问层
功能:定义数据库实体、MyBatis-Flex Mapper 和业务 Service。
- 实体(Entity):
- BaseEntity:抽象基类,包含通用字段(创建时间、更新时间、逻辑删除)。
- BfmProcessInstance:流程实例表(雪花ID主键,存储流程变量、上下文快照等)。
- BfmActivityInstance:活动实例表(存储活动运行时数据,输入/输出/本地变量)。
- BfmExecutionHistory:执行历史表(记录流程执行过程中的事件)。
- BfmWorkItem:工作项表(人工任务实例,包含表单数据、处理人、状态、会签信息等)。
- BfmPackage:流程包定义表(存储 XML 内容,版本管理)。
- BfmProcessPausePoint:流程暂停点表(用于恢复执行)。
- Mapper:为每个实体提供基础 CRUD 和自定义查询方法(如根据流程实例ID查询活动、查询可恢复流程等)。
- Service:
- IBfmPackageService / BfmPackageServiceImpl:流程包部署、获取、禁用。
- IProcessInstancePersistenceService / HighPerformanceProcessInstancePersistenceService:核心持久化服务,实现了 Redis 缓冲队列的高性能写入,所有写操作先入队,由 BatchPersistenceConsumerService 批量刷库;同时提供同步降级方法。
2.1.2.4、data模块:数据模型(定义与运行时)
功能:承载流程定义解析后的对象和流程运行时的内存对象。
- 子包 define:与 XML Schema 对应的 Java 类(使用 Jackson XML 注解)。
- Package:根元素,包含 Messages、Workflow 列表、Dependencies、GlobalConfig。
- Workflow:工作流定义,包含 Parameters、Activities(活动列表)、Transitions(转移线)、调试监控配置。
- 活动抽象类 Activity,及其具体子类:StartEvent、EndEvent、AutoTask、UserTask、SubProcess、Gateway。
- 其他辅助类:DataMapping(输入/输出映射)、Assignment(任务分配)、CompletionRule(完成规则)、ExtendedOperation(扩展操作)、FaultHandler(异常处理)等。
- 子包 runtime:流程运行时的内存对象。
- ProcessInstance:流程实例(内存ID + 数据库雪花ID),包含状态、变量、活动实例映射、工作项映射、退回栈、执行历史等。提供 start()、onActivityCompleted()、terminate() 等方法。
- ActivityInstance:活动实例,包含活动定义引用、状态、输入/输出数据、本地变量、关联的工作项列表。提供 execute()、checkWorkItemsCompletion() 等方法。
- WorkItemInstance:工作项实例,包含处理人、状态、表单数据、操作历史等。提供 start()、complete()、transfer()、delegate()、back() 等方法。
- ExecutionContext:执行上下文,封装变量作用域(LOCAL/WORKFLOW/PACKAGE)和调用栈。
- RuntimePackage:运行时包(不可变),包含所有 RuntimeWorkflow 和包级变量。
- RuntimeWorkflow:运行时工作流,缓存活动定义、转移矩阵、参数定义等。
- VariableScope:变量作用域管理器。
2.1.2.5、engine模块:核心引擎
这是系统的中枢,按职责分为多个子包:
- engine.expression:表达式求值
ExpressionEvaluator:核心类,使用 Spring SpEL 求值,支持 ${...} 和 #{...} 包裹,处理赋值表达式、集合字面量、类实例化、嵌套属性等。将所有流程变量注册到 SpEL 上下文中,支持复杂表达式。
- engine.gateway:网关执行器
GatewayExecutor 接口:定义 execute(gatewayDef, gatewayInstance)。
具体实现:
- ExclusiveGatewayExecutor:排他网关,SPLIT 时选择唯一满足条件的分支(优先 default),JOIN 时直接透传。
- ParallelGatewayExecutor:并行网关,SPLIT 时启动所有分支,JOIN 时等待所有分支到达(计数器)。
- InclusiveGatewayExecutor:包容网关,SPLIT 时启动所有满足条件的分支(若无则走 default),JOIN 时等待所有实际激活的分支。
- ComplexGatewayExecutor:复杂网关(目前降级为排他网关处理)。
- GatewayExecutorFactory:根据网关类型返回对应执行器。
- engine.invoker:调用分发器
InvokerDispatcher:负责调用 Spring Bean、REST、WebService、JavaBean、消息等外部服务。核心方法 invokeSpringBean 通过反射查找最佳匹配方法,并处理参数类型转换(支持 varargs、VO 对象直接传递等)。
- engine.mapping:数据映射处理器
- DataMappingInputProcessor:处理输入映射,根据 DataMapping.InputMapping 从上下文获取值,支持嵌套目标(自动创建父 Map),处理类型转换(Set/List/Bean)。
- DataMappingOutputProcessor:处理输出映射,将求值结果写入指定作用域,支持嵌套 target。
- engine.persist:异步持久化
- RedisPersistenceQueueService:封装 Redis 列表作为队列,提供入队(LPUSH)和批量出队(使用 Redis 事务实现原子性)方法。
- BatchPersistenceConsumerService:定时批量消费四个队列(流程实例、活动实例、执行历史、工作项),将消息反序列化为实体,执行插入/更新(幂等处理主键冲突)。
- PersistenceEventListener:监听状态变更事件,异步调用持久化服务(实际调用 HighPerformanceProcessInstancePersistenceService 的对应方法)。
- engine.state:状态管理
状态枚举:
- ProcStatus:流程状态(CREATED, RUNNING, SUSPENDED, COMPLETED, TERMINATED, CANCELED)。ActStatus:活动状态(CREATED, RUNNING, SUSPENDED, COMPLETED, SKIPPED, TERMINATED, CANCELED)。WorkStatus:工作项状态(CREATED, RUNNING, COMPLETED, TERMINATED, CANCELED)。
- 状态转换规则:每个枚举类内定义了 TRANSITION_RULES 静态映射,通过 canTransitionTo() 校验。
- 事件类:ProcessStatusChangedEvent、ActivityStatusChangedEvent、WorkItemStatusChangedEvent,继承自 Spring ApplicationEvent。
- StatusTransitionManager:核心状态管理器,使用细粒度锁(ConcurrentHashMap + ReentrantLock)保证每个实例的状态转换线程安全。提供 transition() 和 forceTransition() 方法,转换成功后会发布事件,并触发下游驱动(通过 ProcessInstanceExecutor)、级联终止等逻辑。同时实现了 SmartLifecycle,支持优雅关闭。
- engine.subprocess:子流程执行器
SubProcessExecutor 接口:定义 execute(subProcess, activityInstance)。
五种执行模式:
- SyncSubProcessExecutor:同步阻塞,等待子流程完成。
- AsyncSubProcessExecutor:异步执行,使用 CompletableFuture,主线程不阻塞,但等待结果时使用 future.get(timeout)(同步等待异步结果),实现了"异步执行 + 同步等待结果"的模式。
- TxSubProcessExecutor:在 @Transactional(propagation = REQUIRES_NEW) 中执行子流程,确保事务独立。
- FutureSubProcessExecutor:DAG 并行执行,根据子流程定义构建 DAG,使用 CompletableFuture 实现并行,支持嵌套 Future(同步)。
- ForkJoinSubProcessExecutor:使用 ForkJoinPool 对批量输入数据进行分治并行处理,每个分片启动一个子流程。
- SubProcessExecutorFactory:根据 ExecutionStrategy 的 mode 返回对应执行器。
- SubProcessStarter 接口:由 ServiceOrchestrationEngine 实现,用于启动子流程实例,解耦循环依赖。
- TxModeHolder:ThreadLocal 标记当前是否处于 TX 模式,用于禁用重试等。
- engine.transition:转移线评估
TransitionEvaluator:根据当前活动 ID 从工作流定义获取出栈转移线,逐一评估条件表达式,按优先级排序,返回可执行的转移线列表(排他网关只取最高优先级,包容网关取所有满足条件的)。
- engine.usertask:人工任务执行
- UserTaskExecutor:根据 UserTask 配置推断任务类型(SINGLE/OR_SIGN/COUNTERSIGN),解析分配人,创建 WorkItemInstance,设置权限、到期时间,并注册到 WorkItemService。
- WorkItemService:提供工作项的完整业务操作:认领、完成、转办、委托、退回、催办、加签等,并维护内存索引(生产环境应替换为数据库)。核心方法 findWorkItem 先查内存,再遍历流程实例兜底。
- engine 顶层类
- ServiceOrchestrationEngine:引擎入口,负责部署流程包、启动流程实例、执行活动。内部持有上述所有组件,通过 executeActivity 根据活动类型分发给对应执行器(开始/结束事件、自动任务、人工任务、子流程、网关)。同时实现 SubProcessStarter 接口。
- ProcessInstanceExecutor:流程实例执行驱动器,核心方法是 onActivityCompleted,当活动完成时由状态管理器回调。它使用 TransitionEvaluator 获取下游活动,并通过引擎的 executeActivity启动它们,内部维护活动锁和完成记录防止重复执行。
2.1.2.6、listener 模块:事件监听器
StatusChangeListener:异步监听状态变更事件,用于日志、监控、级联等。使用 @Async,并捕获 Spring 关闭时的 TaskRejectedException 避免异常。
2.1.2.7、parser 模块:XML 解析器
WorkflowParser:使用 Jackson XML 将 XML 流解析为 Package 对象,并进行基本校验(非空、开始/结束事件等)。支持从 Resource 或路径批量解析。
2.1.2.8、utils 模块:工具类
IdGenerator:雪花 ID 生成器(单例),基于 MAC 地址生成 workerId。
ObjectConverter:Map 到 Bean 的转换工具,依次尝试 Jackson、BeanUtils、反射。
2.1.3、核心逻辑
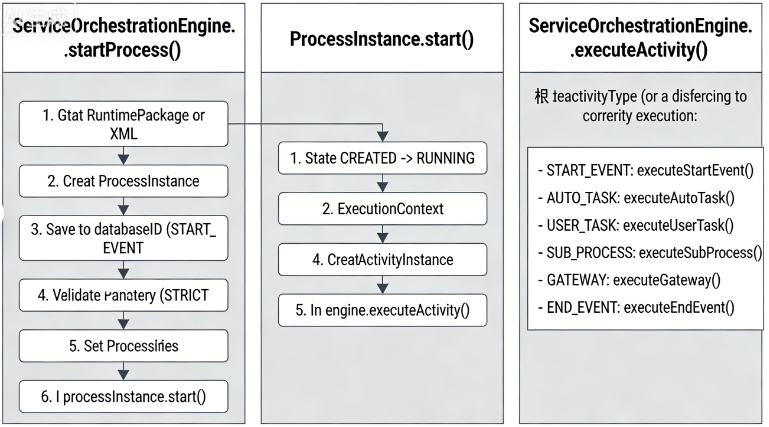
流程启动是 BFM 引擎的核心入口,从外部调用到第一个活动执行,涉及多个组件的协同工作,以调用
ServiceOrchestrationEngine.startProcess() 为起点。关键设计要点:
- 状态驱动:整个流程的推进由状态管理器 + 活动完成回调驱动,实现了核心逻辑与持久化的分离。
- 细粒度锁:每个活动实例有独立的锁,确保并发安全的同时提高吞吐量。
- 去重机制:活动完成事件通过 processedCompletions 去重,防止重复驱动下游。
- 可扩展性:通过TransitionEvaluator和GatewayExecutor等策略组件支持不同路由逻辑。
- 异步持久化:通过事件监听器和 Redis 队列,将写操作异步化,提升响应速度。
2.1.3.1、启动入口
调用者(如 REST API)调用
ServiceOrchestrationEngine.startProcess(packageId, workflowId, version, businessKey, inputVariables)。
该方法是流程启动的公共入口,负责解析包、创建工作流实例并触发执行。
2.1.3.2、获取运行时定义
引擎根据 packageId 和 version 从缓存 packageCache 中获取已部署的 RuntimePackage。
从 RuntimePackage 中根据 workflowId 获取对应的 RuntimeWorkflow,包含活动的详细定义和转移矩阵。
2.1.3.3、创建流程实例
- 调用 ProcessInstance 构造函数,生成雪花ID(IdGenerator.nextId()),并初始化内部状态为 CREATED。
- 构造函数中还会设置 businessKey、traceId(从 MDC 或输入变量中提取)、runtimeWorkflow 引用等。
2.1.3.4、持久化流程实例(可选)
- 调用 IProcessInstancePersistenceService.saveProcessInstance(processInstance) 将流程实例写入数据库。
- 如果启用了 Redis 缓冲,该操作会异步入队,否则同步写入。这里为简化,视为同步/异步皆可。
2.1.3.5、输入参数校验与设置
- 如果工作流定义为 STRICT 模式,调用 processInstance.validateRequiredParameters() 校验输入变量是否满足参数定义。
- 将外部传入的 inputVariables 通过 processInstance.setVariable() 设置到流程实例的变量映射中。
2.1.3.6、调用 processInstance.start() 启动流程
- 状态转换:通过 StatusTransitionManager.transition(processInstance, ProcStatus.RUNNING) 将流程状态从 CREATED 转为 RUNNING。
- 记录开始时间 startTime。
- 创建执行上下文 ExecutionContext(包含变量作用域、调用栈等)。
- 获取开始活动 ID:runtimeWorkflow.getStartActivityId(),通常是一个 START_EVENT 类型的活动。
- 创建开始活动实例:new ActivityInstance(startActivityId, processInstance, statusManager),此时活动状态为 null。
- 活动状态初始化:通过 statusManager.transition(startActivity, ActStatus.CREATED) 将活动状态设为 CREATED。
- 将活动实例放入流程实例的 activityInstMap 中(键为活动 ID)。
- 调用引擎的 executeActivity(startActivity) 开始执行开始活动。
2.1.3.7、引擎执行活动(以开始事件为例)
ServiceOrchestrationEngine.executeActivity(activityInstance) 根据活动类型(activityType)进行分发。
对于 START_EVENT:
- 获取活动定义中的 DataMapping 配置(如果存在)。
- 调用 DataMappingInputProcessor.processInputs() 处理输入映射,从上下文中提取值,构建输入数据 Map。
- 将处理后的输入数据通过 processInstance.setVariable() 设置到流程变量中(开始事件常用于初始化流程变量)。
- 状态转换:statusManager.transition(activityInstance, ActStatus.RUNNING):将活动置为运行中;statusManager.transition(activityInstance, ActStatus.COMPLETED):立即完成开始事件(开始事件没有实际业务逻辑,通常直接完成)。
- 活动完成时,StatusTransitionManager 内部会调用 triggerDownstreamActivities(activityInstance) 触发下游驱动。
2.1.3.8、活动完成触发下游驱动
- triggerDownstreamActivities 方法会获取流程实例的 ProcessInstanceExecutor,并调用 onActivityCompleted(activityInstance)。
- 这一步是流程向前推进的核心:每个活动完成后,都会通过 ProcessInstanceExecutor 评估转移线,启动后续活动。
2.1.3.9、下游活动驱动
ProcessInstanceExecutor.onActivityCompleted(completedActivity) 执行以下操作:
- 去重检查:通过 processedCompletions 缓存防止同一活动多次触发。
- 保存上下文快照:调用持久化服务保存当前变量和活动状态快照,便于后续恢复。
- 获取可执行转移线:调用 TransitionEvaluator.evaluateTransitions(completedActivityId, processInstance),根据条件表达式和网关类型,返回可执行的下游目标活动列表。
- 对每个目标活动:
- 从 activityInstMap 中获取或创建活动实例。如果实例不存在,创建新实例并设置状态为 CREATED。如果实例已存在且未终态(例如并行分支),则直接使用。通过活动锁(activityExecutionLocks)防止同一活动被并发启动。调用 engine.executeActivity(targetActivity) 执行目标活动。
- 检查流程是否完成:最后调用 processInstance.checkIfProcessCompleted(),遍历所有活动实例,若全部终态且无失败,则将流程状态转为 COMPLETED。
2.1.3.10、流程持续执行
- 后续活动(如自动任务、子流程、网关等)会按照上述模式继续执行,直到遇到结束事件或流程被终止。
- 所有状态变更都会通过 StatusTransitionManager 发布事件,由监听器异步处理持久化、日志等副作用。
通过核心逻辑章节的描述,可以看到 BFM 引擎如何将一个静态的流程定义转化为动态运行的流程实例,并确保每一步的可靠执行
2.2、模块说明
2.2.1、三层状态机(FSM)
在 BFM 引擎中,状态管理是核心机制之一,涉及三个层次:流程实例(ProcessInstance)、活动实例(ActivityInstance)和工作项实例(WorkItemInstance)。这三层通过状态管理器(StatusTransitionManager)协同工作,形成两种典型的模式:
- 机-机模式:流程 + 自动活动(非人工任务,如开始/结束事件、自动任务、子流程、网关)。两层状态机,活动状态变化直接影响流程状态。
- 人-机模式:流程 + 人工活动 + 工作项。三层状态机,工作项状态变化通过活动汇聚后间接影响流程。
下面详细阐述各层状态定义、转换规则及相互影响。
2.2.1.1、状态枚举定义
- 流程实例状态(ProcStatus)
|------------|----------------------|--------|
| 状态 | 含义 | 终态 |
| CREATED | 流程实例已创建,尚未开始执行 | 否 |
| RUNNING | 流程正在执行中,至少有一个活动处于非终态 | 否 |
| SUSPENDED | 流程被挂起,暂停执行 | 否 |
| COMPLETED | 流程正常结束,所有活动均已终态且无失败 | 是 |
| TERMINATED | 流程因异常或强制操作而终止 | 是 |
| CANCELED | 流程被取消(通常由外部操作触发) | 是 |
- 活动实例状态(ActStatus)
|------------|--------------------------|--------|
| 状态 | 含义 | 终态 |
| CREATED | 活动实例已创建,尚未开始执行 | 否 |
| RUNNING | 活动正在执行中(人工任务表示已创建/分配工作项) | 否 |
| SUSPENDED | 活动被挂起(暂未使用) | 否 |
| COMPLETED | 活动正常完成 | 是 |
| SKIPPED | 活动因条件不满足而被跳过(如网关分支未选中) | 是 |
| TERMINATED | 活动因异常或流程终止而强制结束 | 是 |
| CANCELED | 活动被取消 | 是 |
- 工作项实例状态(WorkStatus)
|------------|------------------|----|
| 状态 | 含义 | 终态 |
| CREATED | 工作项已创建,待处理人认领 | 否 |
| RUNNING | 工作项已被认领,正在处理中 | 否 |
| COMPLETED | 工作项正常完成(提交表单/审批) | 是 |
| TERMINATED | 工作项因异常或活动终止而强制结束 | 是 |
| CANCELED | 工作项被取消 | 是 |
2.2.1.2、机-机模式:流程 + 自动活动
在机-机模式中,活动(如 AUTO_TASK、SUB_PROCESS、网关等)由引擎自动执行,无需用户参与。状态变迁及相互影响如下:
正常执行流程
- 流程启动后,首先创建开始事件活动实例,状态从 null 转为 CREATED(通过 StatusTransitionManager.transition)。
- 引擎执行活动,活动状态依次转为 RUNNING → COMPLETED。对于 START_EVENT,允许直接从 CREATED 到 COMPLETED。对于 AUTO_TASK,执行过程中可能经历 RUNNING,完成后变为 COMPLETED。
- 活动完成后,StatusTransitionManager 发布 ActivityStatusChangedEvent,并调用 ProcessInstanceExecutor.onActivityCompleted 驱动下游。
- 下游活动被创建并执行,重复上述过程,直到遇到结束事件。
- 结束事件完成后,ProcessInstanceExecutor.onActivityCompleted 会触发流程完成检查(processInstance.checkIfProcessCompleted)。当所有活动均为终态且无失败时,流程状态由 RUNNING 转为 COMPLETED。
异常与终止
- 如果某个自动活动执行抛出异常,该活动状态转为 TERMINATED,并记录错误信息。
- StatusTransitionManager 会级联将流程状态转为 TERMINATED(通过 cascadeTerminationToProcess)。
- 流程终止后,会遍历所有活动,将未终态的活动强制转为 TERMINATED 或 CANCELED。
跳过机制
- 在排他网关或包容网关中,未被选中的分支活动会被标记为 SKIPPED。
- SKIPPED 是终态,不会触发下游驱动,也不影响流程完成检查(流程只需所有活动终态即可)。
状态影响关系
- 活动 → 流程:活动状态变为 COMPLETED 可能触发流程完成检查;活动变为 TERMINATED 会立即导致流程终止。
- 流程 → 活动:流程终止时,会强制级联所有未终态活动变为 TERMINATED。
- 活动之间无直接状态影响,通过转移线驱动下游活动创建。
2.2.1.3、人-机模式:流程 + 人工活动 + 工作项
在人-机模式中,人工活动(USER_TASK)会创建多个工作项,工作项状态独立变化,通过活动汇聚后影响流程。
正常执行流程
- 人工活动实例被创建,状态从 CREATED 转为 RUNNING(由 UserTaskExecutor.execute 触发)。
- 根据任务类型(SINGLE/OR_SIGN/COUNTERSIGN),创建若干工作项,每个工作项初始状态为 CREATED。
- 工作项被用户认领后,状态转为 RUNNING。
- 用户完成任务提交(WorkItemService.completeWorkItem),工作项状态转为 COMPLETED,同时记录表单数据、操作历史。
- 每个工作项完成后,会触发其所属活动实例的 checkWorkItemsCompletion(),根据会签规则判断活动是否完成。规则包括:ANY(任一完成)、ALL(全部完成)、N(指定数量)、PERCENTAGE(比例),若活动完成条件满足,则调用 statusManager.transition(activityInstance, ActStatus.COMPLETED)。
- 活动完成后,与机-机模式相同,驱动下游并最终可能完成流程。
退回操作
- 工作项支持退回(back 操作),用户可选择退回到指定活动。
- 退回时,工作项状态转为 COMPLETED(但动作标记为 BACK),并携带退回目标。
- 活动实例的 checkWorkItemsCompletion 检测到退回操作后,会调用 handleBackOperation,将退回信息记录并通知流程实例。
- 流程实例 onActivityBack 会清理下游活动,重置目标活动状态,并重新执行目标活动。
异常与终止
- 若某个工作项执行失败(如抛出异常),其状态转为 TERMINATED。
- 活动实例的 checkWorkItemsCompletion 根据会签规则判断是否应终止活动(例如 ALL 模式下任一失败则整体失败)。
- 活动终止后,会级联终止流程(同机-机模式)。
- 流程终止时,会级联终止所有未终态的活动及其所有工作项。
状态影响关系
- 工作项 → 活动:每个工作项状态变为 COMPLETED 或 TERMINATED 后,活动实例会进行汇聚检查,可能触发活动状态转换。
- 活动 → 工作项:活动状态变为 TERMINATED 时,会级联所有未终态的工作项变为 TERMINATED。
- 活动 → 流程:活动状态变为 COMPLETED 或 TERMINATED 后,同样驱动流程完成或终止。
- 流程 → 活动/工作项:流程终止时,级联影响所有活动和其工作项。
2.2.1.4、状态机联动机制
BFM 引擎通过 StatusTransitionManager 实现三层状态机的统一管理,这种分层状态机设计既保证了流程引擎的健壮性,又提供了灵活的扩展点(如自定义会签规则、退回逻辑),是 BFM 引擎可靠运行的基础。核心机制如下:
- 细粒度锁:每个实例(流程/活动/工作项)有独立的 ReentrantLock,确保并发下状态转换安全。
- 事件驱动:状态转换后发布相应事件(ProcessStatusChangedEvent、ActivityStatusChangedEvent、WorkItemStatusChangedEvent),由监听器异步处理持久化、日志等副作用,避免阻塞状态转换线程。
- 级联规则:活动失败 → 流程终止:当活动变为 TERMINATED 时,自动调用 cascadeTerminationToProcess 将流程置为 TERMINATED;流程终止 → 活动/工作项终止:流程变为终态时,遍历所有活动,对未终态活动执行 forceTransition 到 TERMINATED 或 CANCELED,活动再级联其工作项;工作项完成 → 活动完成:工作项状态变为 COMPLETED 后,通过活动实例的 checkWorkItemsCompletion 检查是否可完成活动。
- 生命周期集成:StatusTransitionManager 实现了 SmartLifecycle,在 Spring 容器关闭时优雅停止接受新事件,防止资源泄漏。
2.2.2、四种网关
在 BFM 流程定义中,网关(Gateway)用于控制流程的分支与汇聚,类似于工作流中的决策节点。根据 XML 中 type 属性的不同,分为四种类型:EXCLUSIVE_GATEWAY(排他网关)、PARALLEL_GATEWAY(并行网关)、INCLUSIVE_GATEWAY(包容网关)和 COMPLEX_GATEWAY(复杂网关)。每种网关在引擎内部由对应的执行器类实现,它们都实现了 GatewayExecutor 接口。
网关的核心作用是 路由(SPLIT)和 汇聚(JOIN),通过 mode 属性区分(默认为 SPLIT)。
|------|--------------------------|-------------------|-------------|------|----------------------|
| 网关类型 | 实现类 | SPLIT 行为 | JOIN 行为 | 条件评估 | 适用场景 |
| 排他网关 | ExclusiveGatewayExecutor | 选择第一个满足条件的分支(或默认) | 直接透传 | 是 | 互斥分支决策,如 if-else |
| 并行网关 | ParallelGatewayExecutor | 无条件启动所有分支 | 计数器等待所有分支到达 | 否 | 并行执行多个独立任务,AND 汇聚 |
| 包容网关 | InclusiveGatewayExecutor | 启动所有满足条件的分支(或默认) | 等待实际激活的分支 | 是 | 多条件并行,且汇聚需等待所有执行过的分支 |
| 复杂网关 | ComplexGatewayExecutor | 降级为排他网关 | 降级为排他网关 | - | 预留扩展,目前不建议使用 |
2.2.2.1、ExclusiveGatewayExecutor:排他网关
实现方式
public void execute(Gateway gatewayDef, ActivityInstance gatewayInstance) {
String gatewayId = gatewayInstance.getActivityId();
String mode = gatewayDef.getConfig() != null ? gatewayDef.getConfig().getMode() : "SPLIT";
if ("JOIN".equals(mode)) {
executeJoin(gatewayDef, gatewayInstance);
} else {
executeSplit(gatewayDef, gatewayInstance);
}
}
private void executeSplit(Gateway gatewayDef, ActivityInstance gatewayInstance) {
ProcessInstance processInstance = gatewayInstance.getProcessInst();
statusManager.transition(gatewayInstance, ActStatus.RUNNING);
// 获取所有出栈转移线
List<Transition> outgoingTransitions = getOutgoingTransitions(processInstance, gatewayId);
// 评估条件
List<EvaluatedTransition> evaluatedList = outgoingTransitions.stream()
.map(t -> new EvaluatedTransition(t, evaluateCondition(t, processInstance)))
.collect(Collectors.toList());
// 找第一个满足条件的非默认转移线
Optional<EvaluatedTransition> selected = evaluatedList.stream()
.filter(EvaluatedTransition::isSatisfied)
.findFirst();
// 若没有,找默认分支
if (!selected.isPresent()) {
selected = evaluatedList.stream()
.filter(EvaluatedTransition::isDefault)
.findFirst();
}
if (!selected.isPresent()) {
throw new IllegalStateException("排他网关无满足条件的分支且无默认分支");
}
// 记录选中的分支起点,用于 JOIN 透传(如果有对应 JOIN 网关)
String joinGatewayId = findCorrespondingJoinGateway(processInstance, gatewayId);
if (joinGatewayId != null) {
expectedBranches.put(buildKey(processInstance, joinGatewayId), selected.get().getTransition().getTo());
}
// 只创建并执行选中的分支
ActivityInstance targetInst = createActivityInstance(selected.get().getTransition().getTo(), processInstance);
startActivity(targetInst, processInstance);
statusManager.transition(gatewayInstance, ActStatus.COMPLETED);
}
private void executeJoin(Gateway gatewayDef, ActivityInstance gatewayInstance) {
log.info("排他网关JOIN执行透传: gatewayId={}", gatewayId);
passThrough(gatewayInstance, processInstance); // 直接启动所有下游活动
}核心机制:
- SPLIT:评估所有出栈转移线的条件,按顺序选择第一个满足条件的转移线(如果条件为真),如果没有,则选择带有 default="true" 的默认转移线;若两者都不存在,抛出异常。选中的分支被启动,其他分支被忽略。
- JOIN:由于排他网关的特性(只有一个分支会被执行),JOIN 时无需等待多个分支,直接透传(启动所有下游活动)。
- 通过 expectedBranches 缓存选中的分支起点,供对应的 JOIN 网关透传时使用(但实际上排他网关 JOIN 中未使用该缓存,因为透传逻辑简单)。
特点
- 单选路由:SPLIT 时只选择一个分支执行,相当于 if-else if-else 结构。
- 默认分支:支持定义默认转移线,当所有条件都不满足时走默认路径。
- 简单汇聚:JOIN 时不进行任何等待,直接透传,因为只有一个分支会到达。
- 条件评估:使用 ExpressionEvaluator 评估 SpEL 表达式,表达式返回 true 的分支被选中。
适用场景
- 基于数据的决策:例如根据订单金额决定走不同的审批路径(金额<1000 走自动审批,>=1000 走人工审批)。
- 多条件分支但只需执行其一:如异常处理中根据错误类型选择不同的补偿措施。
- 简单的互斥路由:任何只需一条路径执行的场景。
2.2.2.2、ParallelGatewayExecutor:并行网关
实现方式
public void execute(Gateway gatewayDef, ActivityInstance gatewayInstance) {
// ... 类似,区分 mode
}
private void executeSplit(Gateway gatewayDef, ActivityInstance gatewayInstance) {
ProcessInstance processInstance = gatewayInstance.getProcessInst();
statusManager.transition(gatewayInstance, ActStatus.RUNNING);
List<Transition> outgoingTransitions = getOutgoingTransitions(processInstance, gatewayId);
if (outgoingTransitions.isEmpty()) {
statusManager.transition(gatewayInstance, ActStatus.COMPLETED);
return;
}
// 查找对应的 JOIN 网关
String joinGatewayId = findJoinGatewayId(processInstance, gatewayId);
if (joinGatewayId != null) {
String counterKey = buildCounterKey(processInstance, joinGatewayId);
// 初始化计数器:分支数
joinCounters.put(counterKey, new AtomicInteger(outgoingTransitions.size()));
}
// 启动所有分支
for (Transition transition : outgoingTransitions) {
ActivityInstance targetInst = createActivityInstance(transition.getTo(), processInstance);
startActivity(targetInst, processInstance);
}
statusManager.transition(gatewayInstance, ActStatus.COMPLETED);
}
private void executeJoin(Gateway gatewayDef, ActivityInstance gatewayInstance) {
ProcessInstance processInstance = gatewayInstance.getProcessInst();
String counterKey = buildCounterKey(processInstance, gatewayId);
AtomicInteger counter = joinCounters.get(counterKey);
if (counter == null) {
log.warn("并行网关JOIN未找到计数器,降级为透传");
passThrough(gatewayInstance, processInstance);
return;
}
int remaining = counter.decrementAndGet();
log.info("并行网关JOIN汇聚: gatewayId={}, remaining={}", gatewayId, remaining);
if (gatewayInstance.getStatus() == ActStatus.CREATED) {
statusManager.transition(gatewayInstance, ActStatus.RUNNING);
}
if (remaining <= 0) {
joinCounters.remove(counterKey);
passThrough(gatewayInstance, processInstance);
} else {
gatewayInstance.setWaiting(true); // 等待其他分支
}
}核心机制:
- SPLIT:获取所有出栈转移线,无条件启动所有分支。同时查找对应的 JOIN 网关(通常命名匹配,如 parallelSplit 对应 parallelJoin),并初始化一个计数器(值为分支数量)。
- JOIN:每个分支到达 JOIN 网关时,递减计数器;当计数器归零时,表示所有分支都已到达,网关透传启动下游活动。如果计数器不存在(例如分支通过其他路径到达),则降级为直接透传。
- 等待标记:当计数器未归零时,将当前 JOIN 网关实例的 waiting 标记为 true,表示处于等待状态(不会继续执行下游)。
特点
- 全部分支并行:SPLIT 时启动所有分支,无任何条件判断。
- 计数器汇聚:JOIN 时依靠计数器确保所有分支到达后才继续。
- 一对一对应:通常要求每个 SPLIT 有一个对应的 JOIN,命名上有规律(如通过正则替换 split 为 join)。
- 无条件跳过:即使分支内活动被跳过(如 SKIPPED),分支仍然会到达 JOIN(因为活动本身完成了),计数器正常递减。
- 等待状态:JOIN 网关在等待过程中处于 RUNNING 且 waiting=true 状态,不会继续执行下游。
适用场景
- 需要同时执行多个独立任务:例如订单支付成功后,同时发送短信、发送邮件、记录积分,三者完成后才进行下一步。
- 并行处理后再汇聚:如并行审核多个环节,全部通过后才进入最终审批。
- 任何"与"汇聚(AND):必须等所有分支都完成才能继续。
2.2.2.3、InclusiveGatewayExecutor:包容网关
实现方式
public void execute(Gateway gatewayDef, ActivityInstance gatewayInstance) {
// 类似
}
private void executeSplit(Gateway gatewayDef, ActivityInstance gatewayInstance) {
ProcessInstance processInstance = gatewayInstance.getProcessInst();
statusManager.transition(gatewayInstance, ActStatus.RUNNING);
List<Transition> outgoingTransitions = getOutgoingTransitions(processInstance, gatewayId);
List<EvaluatedTransition> evaluatedList = ... // 评估条件
// 收集所有满足条件的非默认分支
List<Transition> activeTransitions = evaluatedList.stream()
.filter(e -> e.isSatisfied() && !e.isDefault())
.map(EvaluatedTransition::getTransition)
.collect(Collectors.toList());
// 如果没有满足条件的非默认分支,则使用默认分支
if (activeTransitions.isEmpty()) {
Optional<Transition> defaultBranch = evaluatedList.stream()
.filter(EvaluatedTransition::isDefault)
.map(EvaluatedTransition::getTransition)
.findFirst();
defaultBranch.ifPresent(activeTransitions::add);
}
if (activeTransitions.isEmpty()) {
throw new IllegalStateException("包容网关无满足条件的分支且无默认分支");
}
// 记录激活的分支用于 JOIN 汇聚
String joinGatewayId = findJoinGatewayId(processInstance, gatewayId);
if (joinGatewayId != null) {
String branchesKey = buildKey(processInstance, joinGatewayId);
Set<String> activeBranchIds = activeTransitions.stream()
.map(Transition::getTo)
.collect(Collectors.toSet());
activeBranches.put(branchesKey, activeBranchIds);
joinCounters.put(branchesKey, new AtomicInteger(activeTransitions.size()));
}
Set<String> activeIds = activeTransitions.stream().map(Transition::getTo).collect(Collectors.toSet());
// 启动所有激活的分支,并标记其他分支为 SKIPPED
for (EvaluatedTransition eval : evaluatedList) {
String targetId = eval.getTransition().getTo();
ActivityInstance targetInst = createActivityInstance(targetId, processInstance);
if (activeIds.contains(targetId)) {
startActivity(targetInst, processInstance);
} else {
statusManager.transition(targetInst, ActStatus.SKIPPED); // 标记跳过
}
}
statusManager.transition(gatewayInstance, ActStatus.COMPLETED);
}
private void executeJoin(Gateway gatewayDef, ActivityInstance gatewayInstance) {
ProcessInstance processInstance = gatewayInstance.getProcessInst();
String branchesKey = buildKey(processInstance, gatewayId);
AtomicInteger counter = joinCounters.get(branchesKey);
Set<String> expectedBranches = activeBranches.get(branchesKey);
if (counter == null || expectedBranches == null) {
log.warn("包容网关JOIN未找到状态记录,降级为透传");
passThrough(gatewayInstance, processInstance);
return;
}
int remaining = counter.decrementAndGet();
log.info("包容网关JOIN汇聚: gatewayId={}, activeBranches={}, remaining={}",
gatewayId, expectedBranches, remaining);
if (gatewayInstance.getStatus() == ActStatus.CREATED) {
statusManager.transition(gatewayInstance, ActStatus.RUNNING);
}
if (remaining <= 0) {
joinCounters.remove(branchesKey);
activeBranches.remove(branchesKey);
passThrough(gatewayInstance, processInstance);
} else {
gatewayInstance.setWaiting(true);
}
}核心机制:
- SPLIT:评估所有出栈转移线的条件,收集所有满足条件的非默认分支;如果没有任何满足条件的非默认分支,则选择默认分支(如果有)。记录被激活的分支集合和对应的计数器(值为激活分支数)。
- 分支启动:所有被激活的分支正常启动;未被激活的分支对应的活动实例被标记为 SKIPPED(跳过),这样它们不会真正执行,但后续仍会到达 JOIN 网关吗?实际上,SKIPPED 的活动也算作完成,所以它们也会走到 JOIN,但需要区分:包容网关的 JOIN 只等待实际被激活的分支,而不是所有分支。
- JOIN:到达 JOIN 时,检查该网关对应的激活分支集合和计数器,递减计数器。当计数器归零时,表示所有激活的分支都已到达,JOIN 透传;否则等待。非激活分支到达 JOIN 时,计数器不会递减?源码中 executeJoin 仅检查当前到达的网关实例,它并不知道到达的是哪个分支,计数器是在每次有活动到达 JOIN 时无条件递减的?让我们仔细看:executeJoin 被调用时,网关实例已经存在,但分支到达时实际上会创建一个新的网关实例还是复用同一个?在流程执行中,每个活动实例是独立的,所以当第一个分支到达 JOIN 时,会创建 JOIN 网关的活动实例,状态变为 RUNNING,并等待。后续分支到达时,它们会尝试获取同一个 JOIN 网关实例(因为活动 ID 相同,流程实例中活动实例映射已存在),所以会进入同一个实例的 executeJoin 方法,此时计数器递减。因此,无论分支是否被激活,只要它们到达 JOIN,计数器都会递减,这会导致问题:如果非激活分支也到达 JOIN(因为活动被 SKIPPED,也算完成),那么计数器会错误地递减。但源码中 executeSplit 对于非激活分支创建了活动实例并标记为 SKIPPED,这些实例最终也会完成并尝试进入 JOIN,导致计数器多减。
总之,包容网关的汇聚机制是基于实际激活的分支数,通过 activeBranches 记录哪些分支被激活,然后每个到达 JOIN 的分支(应该是激活分支)递减计数器,直到归零。
特点
- 条件分支任意组合:SPLIT 时根据条件可能激活零个、一个或多个分支。
- 动态汇聚:JOIN 只等待实际被激活的那些分支,而不是所有分支。
- 默认分支兜底:如果没有分支满足条件,可走默认分支(仅当有默认分支时)。
- 跳过未激活分支:未被选中的分支对应的活动实例被标记为 SKIPPED,不会实际执行,但理论上它们不应该影响汇聚。
- 复杂度较高:需要维护激活分支集合,处理并发到达 JOIN 时的计数器递减。
适用场景
- 多条件路径可能同时多条:例如审批流程中,根据申请金额和用户等级,可能同时需要财务审批和法务审批(两者都满足条件),也可能只需其中一个。
- 汇聚时需等待所有实际执行的分支:类似于"或"汇聚,但具体分支数动态变化。
- 业务规则复杂,可能触发多个后续路径:如风控规则可能同时命中多条,需要并行处理。
2.2.2.4、ComplexGatewayExecutor:复杂网关
实现方式
@Slf4j
@Component
public class ComplexGatewayExecutor implements GatewayExecutor {
private final ExclusiveGatewayExecutor exclusiveGatewayExecutor;
public ComplexGatewayExecutor(ExclusiveGatewayExecutor exclusiveGatewayExecutor) {
this.exclusiveGatewayExecutor = exclusiveGatewayExecutor;
log.info("ComplexGatewayExecutor初始化完成(当前降级为排他网关)");
}
@Override
public void execute(Gateway gatewayDef, ActivityInstance gatewayInstance) {
String gatewayId = gatewayInstance.getActivityId();
log.warn("复杂网关执行: gatewayId={},当前降级为排他网关处理", gatewayId);
exclusiveGatewayExecutor.execute(gatewayDef, gatewayInstance);
}
}核心机制:
- 当前版本中,ComplexGatewayExecutor 并没有实现真正的复杂网关逻辑,而是直接委托给 ExclusiveGatewayExecutor 处理。
- 日志记录降级信息,并预留扩展点(未来可支持动态路由、循环、基于规则的分支选择等高级特性)。
特点
- 占位实现:目前仅作为排他网关的代理,行为与排他网关相同。
- 可扩展性:设计上预留了接口,后续可以添加更复杂的路由策略,例如基于规则引擎、决策表等。
- 日志警示:执行时会打印 warn 日志,提醒当前为降级处理。
适用场景
- 当前不建议使用,除非明确知道降级为排他网关能满足需求。
- 未来扩展:当需要实现复杂的动态路由、循环执行、基于外部条件的变化分支时,可以在该类中完善逻辑。
2.2.3、五种子流程
子流程通过ExecutionStrategy配置执行模式,由SubProcessExecutorFactory创建对应的执行器,每个模式均可独立配置线程池、超时、事务属性等,实现了逻辑统一与物理隔离。
|----------|--------|----------------|--------------------|--------------|--------------------------|
| 执行器 | 并发粒度 | 主线程行为 | 事务特性 | 是否使用多线程 | 典型场景 |
| Sync | 子流程整体 | 阻塞等待 | 继承父事务 | 否 | 耗时极短、需强一致性的子流程 |
| Async | 子流程整体 | 阻塞等待(但执行在独立线程) | 独立线程,事务取决于子流程自身配置 | 是(一个子流程一个线程) | 子流程耗时较长,希望隔离线程,但仍需同步等待结果 |
| Tx | 子流程整体 | 阻塞等待 | 独立事务(REQUIRES_NEW) | 否 | 需要事务隔离的子流程(如外部调用、独立工作单元) |
| Future | 活动级别 | 阻塞等待整个 DAG | 子流程内部活动事务共享(同子流程) | 是(活动级并行) | 子流程内部存在复杂 DAG,需要活动级并发执行 |
| ForkJoin | 数据分片级别 | 阻塞等待所有分片 | 每个分片子流程独立事务 | 是(分治并行) | 批量数据处理,每个数据项执行一个完整子流程 |
子流程执行器的业务适用性:
- 需要简单、快速、强一致 → 选 Sync
- 需要事务隔离 → 选 Tx
- 子流程耗时,希望释放父线程 → 选 Async(注意父线程仍会阻塞,但不会占用业务线程池)
- 子流程内部活动可并行 → 选 Future
- 批量数据需并行处理 → 选 ForkJoin
2.2.3.1、SyncSubProcessExecutor :同步阻塞模式
实现方式
public void execute(SubProcess subProcess, ActivityInstance activityInstance) {
// 1. 状态转换 CREATED -> RUNNING
statusManager.transition(activityInstance, ActStatus.RUNNING);
// 2. 准备输入参数(通过 DataMapping)
Map<String, Object> subInputVariables = prepareSubProcessInput(...);
// 3. 启动子流程(通过 SubProcessStarter)
ProcessInstance subProcessInstance = subProcessStarter.startSubProcess(...);
// 4. **轮询等待子流程完成**(while循环 + sleep)
waitForSubProcessCompletion(subProcessInstance);
// 5. 收集输出并存储到父活动本地变量
collectAndStoreSubProcessOutputs(...);
// 6. 父活动状态转换为 COMPLETED
statusManager.transition(activityInstance, ActStatus.COMPLETED);
}核心机制:
- 父活动所在线程完全阻塞,通过 while (!subProcessInstance.getStatus().isFinal()) { Thread.sleep(100); } 轮询子流程状态,直到其变为终态。
- 不使用任何异步线程,所有操作都在调用线程中顺序执行。
- 子流程内部的活动仍可能异步(如子流程中又包含 Async 子流程),但从父活动的角度看,整个 execute 方法返回时子流程必定已完成。
特点
- 简单可靠:代码逻辑线性,易于理解和调试。
- 线程资源占用:父线程被占用直到子流程结束,若子流程耗时较长,可能导致父线程池耗尽(若父流程也使用线程池)。
- 事务传播:默认继承父流程的事务(如果存在),子流程的数据库操作在同一个事务中。
适用场景
- 子流程执行时间很短(毫秒级),不值得引入异步开销。
- 需要强一致性:要求子流程的数据库操作与父流程的其他操作在同一个事务中,要么全部成功,要么全部回滚。
- 父流程本身已经在一个专用线程中执行(例如父流程是同步调用的),无需考虑线程池阻塞问题。
示例:一个简单的数据校验子流程,内部只包含几个自动任务,总耗时<50ms,父流程可以直接等待。
2.2.3.2、TxSubProcessExecutor:独立事务模式
实现方式
public void execute(SubProcess subProcess, ActivityInstance activityInstance) {
// 1. 状态转换
statusManager.transition(activityInstance, ActStatus.RUNNING);
// 2. 准备输入参数
Map<String, Object> subInputVariables = prepareSubProcessInput(...);
// 3. **在新事务中启动并等待子流程**
ProcessInstance subProcessInstance = executeInNewTransaction(workflowRef, subInputVariables, activityInstance);
// 4. 强制同步输出到父流程变量空间(关键修复点)
forceSyncOutputsToParentProcess(...);
// 5. 父活动完成
statusManager.transition(activityInstance, ActStatus.COMPLETED);
}
@Transactional(propagation = Propagation.REQUIRES_NEW, rollbackFor = Throwable.class)
public ProcessInstance executeInNewTransaction(...) {
// 标记当前为 TX 模式(禁用重试等)
TxModeHolder.setTxMode(true);
try {
ProcessInstance subInstance = subProcessStarter.startSubProcess(...);
waitForSubProcessCompletionWithErrorDetail(subInstance);
return subInstance;
} finally {
TxModeHolder.clear();
}
}核心机制:
- 使用 Spring @Transactional(propagation = REQUIRES_NEW) 将子流程的执行包裹在一个独立的新事务中。
- 父线程仍然同步阻塞等待子流程完成(因为 executeInNewTransaction 是同步调用的)。
- 子流程的事务与父流程的事务完全隔离,子流程的提交/回滚不影响父流程的事务(反之亦然)。
- 通过 TxModeHolder 在线程上下文中标记"TX模式",通知其他组件(如 InvokerDispatcher)禁用重试等干扰事务的行为。
特点
- 事务隔离:子流程的数据库操作在独立事务中执行,即使父流程后续回滚,子流程的变更依然持久化(或者子流程失败回滚,父流程不受影响)。
- 同步阻塞:与 Sync 模式一样,父线程会被阻塞直到子流程完成。
- 异常传播:子流程中的业务异常会包装后抛给父流程,父流程可以捕获并决定如何处理(例如记录错误后继续)。
适用场景
- 需要将子流程作为独立的工作单元提交,即使父流程整体失败,子流程的结果也应保留(或子流程的失败不应导致父流程自动回滚)。
- 与外部系统交互且要求事务独立:例如子流程包含调用外部 REST 接口的操作,我们不希望外部调用因父流程的事务回滚而被撤销(无法回滚)。
- 批量操作中需要部分成功部分失败:父流程可以启动多个 Tx 子流程,每个独立成功或失败,父流程根据每个子流程的结果做决策。
示例:
在一个主流程中,需要向多个第三方系统发送通知(每个通知作为一个子流程),我们希望每个通知独立事务,即使某个通知失败(抛异常),主流程可以继续尝试发送其他通知,而不是整体回滚。
2.2.3.3、AsyncSubProcessExecutor:异步线程执行
实现方式
public void execute(SubProcess subProcess, ActivityInstance activityInstance) {
// 立即将父活动状态转为 RUNNING
statusManager.transition(activityInstance, ActStatus.RUNNING);
// 提交异步任务到独立线程池
CompletableFuture<ProcessInstance> future = CompletableFuture.supplyAsync(() -> {
// 在异步线程中启动并等待子流程
return executeSubProcessInternal(subProcess, activityInstance, ...);
}, asyncWorkerPool);
try {
// 主线程阻塞等待,直到子流程完成或超时
ProcessInstance subInstance = future.get(timeoutMs, TimeUnit.MILLISECONDS);
handleSubProcessSuccess(subInstance, ...);
} catch (TimeoutException e) {
future.cancel(false);
handleTimeout(...);
} catch (ExecutionException e) {
handleError(...);
}
// 父活动最终会转为 COMPLETED 或 TERMINATED
}
private ProcessInstance executeSubProcessInternal(...) {
// 1. 准备输入参数
Map<String, Object> inputs = prepareSubProcessInput(...);
// 2. 启动子流程实例(调用 SubProcessStarter)
ProcessInstance subInstance = subProcessStarter.startSubProcess(...);
// 3. **轮询等待子流程完成**(while循环)
waitForSubProcessCompletion(subInstance, timeoutMs, startTime);
return subInstance;
}核心机制:
- 将整个子流程的"启动+等待"操作封装成一个 Callable,通过 CompletableFuture.supplyAsync 提交到独立的线程池(asyncWorkerPool)。
- 主线程立即调用 future.get(timeout, unit) 阻塞等待,直到异步任务完成或超时。
- 异步任务内部通过 waitForSubProcessCompletion 轮询子流程实例的状态,直到终态。
- 超时发生后,会主动取消 Future(cancel(false)),并执行超时处理逻辑(将父活动置为终止)。
特点
- 线程隔离:子流程的执行线程与父流程的当前线程分离,父线程(可能是业务线程池中的线程)不会因子流程耗时而被长期占用,可以继续处理其他请求。
- 主线程仍阻塞:尽管子流程在另一个线程中运行,但调用 execute 的方法(如流程引擎的主线程)仍然会被阻塞,直到 future.get() 返回。因此,从调用者角度看,这是一个同步阻塞 API。
- 超时控制:对子流程整体设置超时,超时后强制取消并终止父活动。
- 事务:子流程运行在独立的线程中,默认不继承父流程的事务(如果父流程有事务,子流程在新线程中会开启新事务,取决于子流程自身的 @Transactional 配置)。
- 资源开销:每个 Async 子流程会占用一个线程池线程(asyncWorkerPool)直到子流程结束,线程池大小需根据并发量合理配置
适用场景
- 子流程执行时间较长(秒级到分钟级),但父流程又必须等待其结果才能继续(例如后续活动依赖子流程的输出)。
- 希望释放父线程资源:父流程可能由有限的线程池执行(如 HTTP 请求线程),不希望线程被长时间阻塞,通过将子流程 offload 到后台线程,可以快速释放父线程去处理其他请求。
- 需要统一的超时管理:对子流程整体设置超时,避免子流程卡死导致资源泄漏。
示例:
一个订单处理主流程中,需要调用外部风控服务(封装为子流程),该服务响应时间不稳定(可能几秒到几十秒),使用 Async 模式可以将风控调用放到后台线程,主线程设置 30 秒超时等待,避免占用 Tomcat 线程。
2.2.3.4、FutureSubProcessExecutor:DAG 并行执行模式
实现方式
public void execute(SubProcess subProcess, ActivityInstance activityInstance) {
// 1. 构建子流程的 DAG 图
DagGraph dag = new DagGraph(subProcess.getRuntimeWorkflow());
List<Set<String>> layers = dag.topologicalSort(); // 获取层级
Map<String, CompletableFuture<ActivityResult>> futures = new ConcurrentHashMap<>();
CountDownLatch completionLatch = new CountDownLatch(1);
AtomicReference<ActivityResult> endResultRef = new AtomicReference<>();
// 2. 按拓扑层级逐层构建 Future
for (Set<String> layer : layers) {
List<CompletableFuture<Void>> layerFutures = new ArrayList<>();
for (String actId : layer) {
CompletableFuture<ActivityResult> future = buildActivityFuture(
actId, dag, futures, subInstance, completionLatch, endResultRef, ...);
futures.put(actId, future);
layerFutures.add(future.thenAccept(r -> {}));
}
// 等待当前层所有活动完成
CompletableFuture.allOf(layerFutures.toArray(new CompletableFuture[0]))
.get(timeout, TimeUnit.MILLISECONDS);
}
// 3. 等待 EndEvent 完成信号
boolean completed = completionLatch.await(timeout, TimeUnit.MILLISECONDS);
// 4. 根据结果处理成功/失败
}
private CompletableFuture<ActivityResult> buildActivityFuture(...) {
// 获取该活动的所有依赖活动(前驱)
Set<String> deps = dag.getDependencies(actId);
List<CompletableFuture<ActivityResult>> depFutures = ...;
// 依赖全部完成后,执行本活动
return CompletableFuture.allOf(depFutures.toArray(new CompletableFuture[0]))
.thenCompose(v -> {
// 检查依赖活动的结果
for (CompletableFuture<ActivityResult> df : depFutures) {
ActivityResult dr = df.getNow(null);
if (dr == null || dr.getStatus() != ActStatus.COMPLETED) {
return CompletableFuture.completedFuture(skippedResult);
}
}
// 执行本活动(通过引擎的 executeActivity)
return supplyAsyncWithSingleCheck(actId, activity, subInstance, ...);
});
}
// 保证每个活动只执行一次
private CompletableFuture<ActivityResult> supplyAsyncWithSingleCheck(...) {
String flagKey = subInstance.getId() + ":" + actId;
AtomicBoolean flag = activityExecutionFlags.computeIfAbsent(flagKey, k -> new AtomicBoolean(false));
if (!flag.compareAndSet(false, true)) {
return CompletableFuture.completedFuture(skippedResult); // 重复调度跳过
}
return CompletableFuture.supplyAsync(() -> executeActivity(...), ACTIVITY_EXECUTOR);
}核心机制:
- 解析子流程定义,构建 DAG(有向无环图),并通过拓扑排序得到活动的执行层级。
- 为每个活动创建一个 CompletableFuture,并建立依赖关系:一个活动的 Future 需要等待其所有前驱活动的 Future 完成后才能开始执行。
- 通过 activityExecutionFlags(ConcurrentHashMap<String, AtomicBoolean>)保证每个活动只被启动一次,防止汇聚活动被多个上游重复触发。
- 整个 DAG 的执行通过 CompletableFuture.allOf 组合各层,主线程阻塞等待所有活动完成(或 EndEvent 触发)。
- 最终通过 CountDownLatch 等待 EndEvent 完成,收集结果。
特点
- 活动级并发:子流程内部多个无依赖的活动可以并行执行,充分利用多核 CPU,缩短子流程整体耗时。
- 精确依赖管理:严格按照 DAG 的拓扑顺序执行,保证前驱活动完成后才启动后继活动。
- 防重复执行:通过执行标志(AtomicBoolean)确保汇聚网关后的活动只被触发一次,避免逻辑错误。
- 主线程阻塞:虽然内部大量使用 CompletableFuture 实现并行,但主线程(调用 execute 的线程)会阻塞直到整个 DAG 完成。
- 活动级线程池:使用共享的 ACTIVITY_EXECUTOR(固定大小线程池)执行各个活动,避免线程无限增长。
- 整体超时:对整个 DAG 设置超时,超时后取消所有未完成的活动 Future。
适用场景
- 子流程内部包含大量可并行的活动:例如多个独立的自动任务、多个并行的审批分支(用户任务)等。
- 活动间有复杂依赖:需要使用排他网关、并行网关、汇聚网关等构建的 DAG 结构。
- 需要精确控制每个活动的执行:例如某些活动必须在其他活动完成后才能开始,且结果需要被后续活动使用。
示例:
一个"产品发布"子流程,需要同时进行代码构建、自动化测试、安全扫描(并行),全部完成后才进入人工审批节点。使用 Future 模式可以并行执行构建、测试、扫描,大幅缩短总时间。
2.2.3.5、ForkJoinSubProcessExecutor:数据分治并行模式
实现方式
public void execute(SubProcess subProcess, ActivityInstance activityInstance) {
// 1. 准备批量输入数据(从 DataMapping 获取 List)
List<Object> batchData = prepareBatchInput(dataMapping, activityInstance);
// 2. 如果数据为空,初始化空输出并返回
if (batchData.isEmpty()) {
initializeEmptyOutputs(dataMapping, context);
statusManager.transition(activityInstance, ActStatus.COMPLETED);
return;
}
// 3. 创建 ForkJoin 任务,提交到 ForkJoinPool
int threshold = (strategy != null) ? strategy.getForkJoinConfig().getThreshold() : 100;
SubProcessBatchTask task = new SubProcessBatchTask(
batchData, workflowRef, subProcessStarter, statusManager, objectMapper,
threshold, 0, batchData.size() - 1);
List<ProcessInstance> subInstances = forkJoinPool.invoke(task);
// 4. 处理批量输出(聚合各子流程的结果)
handleBatchOutput(subInstances, dataMapping, context);
statusManager.transition(activityInstance, ActStatus.COMPLETED);
}
// 内部 ForkJoinTask 实现
static class SubProcessBatchTask extends RecursiveTask<List<ProcessInstance>> {
@Override
protected List<ProcessInstance> compute() {
int size = end - start + 1;
if (size <= threshold) {
// 顺序处理当前分片
return processSequentially();
} else {
// 拆分成两个子任务
int mid = start + size / 2;
SubProcessBatchTask left = new SubProcessBatchTask(..., start, mid);
SubProcessBatchTask right = new SubProcessBatchTask(..., mid + 1, end);
left.fork();
List<ProcessInstance> rightResult = right.compute();
List<ProcessInstance> leftResult = left.join();
// 合并结果
List<ProcessInstance> results = new ArrayList<>(leftResult);
results.addAll(rightResult);
return results;
}
}
private List<ProcessInstance> processSequentially() {
List<ProcessInstance> results = new ArrayList<>();
for (int i = start; i <= end; i++) {
Object data = batchData.get(i);
// 为每个数据项启动一个完整的子流程实例
ProcessInstance subInstance = startSubProcessForData(data, i);
waitForSubProcessCompletion(subInstance);
results.add(subInstance);
}
return results;
}
}核心机制:
- 从输入映射中获取一个 List 类型的批量数据(例如订单列表)。
- 使用 ForkJoinPool 和自定义 RecursiveTask 将数据分片,每个分片在独立的线程中顺序处理该分片内的数据项。
- 每个数据项启动一个独立的子流程实例,子流程内部可以执行任意复杂的逻辑。
- 所有分片处理完成后,主线程得到所有子流程实例的列表,然后通过输出映射(DataMapping)聚合各子流程的结果(例如收集所有子流程的某个输出字段为一个集合)。
- 结果聚合时支持去重,若发现重复的子流程 ID 会抛出异常(防止逻辑错误)。
特点
- 数据分治并行:将大任务拆分为小任务,并行执行,最终合并结果,典型的 Map-Reduce 模式。
- 每个数据项独立子流程:每个输入元素对应一个完整的子流程实例,拥有独立的变量空间、活动实例等。
- 主线程阻塞:forkJoinPool.invoke(task) 是同步调用,主线程会阻塞直到所有分片任务完成。
- 事务隔离:每个子流程实例运行在各自的事务中(取决于子流程本身的配置),彼此隔离,一个子流程失败不影响其他。
- 结果聚合:支持将各子流程的输出按指定表达式提取并合并为集合(List 或 Set),便于父流程后续使用。
- 去重保护:在聚合阶段会检查子流程实例 ID 是否重复,防止因分片错误导致同一数据被处理多次。
适用场景
- 需要对大量独立业务数据进行相同流程处理:例如批量审批订单、批量发送通知、批量数据清洗等。
- 数据量较大,且每个数据项的处理相对独立:可以利用并行显著提升吞吐量。
- 需要聚合所有处理结果:例如收集所有订单的审批意见、所有发送通知的状态等。
示例:
一个"批量催缴"子流程,输入是 10000 个欠费用户列表,每个用户需要执行一个催缴子流程(包含生成催缴单、发送短信、记录日志)。使用 ForkJoin 模式可以将用户列表分片并行处理,最终聚合所有用户的催缴结果(成功/失败列表)。
2.2.4、异步持久化
BFM 引擎采用 Redis 缓冲 + 批量刷库 的异步持久化策略,将流程运行时产生的大量写操作(流程实例、活动实例、执行历史、工作项)先快速写入 Redis 队列,再由后台线程批量、异步地写入 MySQL,从而显著提升引擎吞吐量,降低数据库压力。同时,系统保留了同步降级路径,支持动态开关。
BFM 引擎的异步持久化设计体现了 高性能、高可用 和 可观测性 的追求,适合对响应时间敏感、写并发高的业务流程,例如大规模服务编排、高频状态变更记录等场景。通过合理配置缓冲参数,可以在数据一致性与性能之间取得平衡
- 高性能:通过 Redis 缓冲将写操作延迟从数据库的几十毫秒降低到毫秒级,同时批量刷库提升吞吐。
- 高可用:同步降级、幂等处理、多队列隔离保证了系统的鲁棒性。
- 可观测:丰富的监控指标和健康检查接口便于运维。
2.2.4.1、整体架构
[流程引擎]
↓ (写请求)
[高性能持久化服务]
├─ (若启用缓冲) → [Redis队列] → [批量消费服务] → [MySQL]
└─ (若不启用) → [直接写入 MySQL]
[事件监听器] ← (状态变更事件) 异步触发持久化- 写操作入口:HighPerformanceProcessInstancePersistenceService 实现了 IProcessInstancePersistenceService 接口,所有持久化请求都经过该类。
- 缓冲开关:通过 BfmPersistenceProperties.redisBufferEnabled 控制是否启用 Redis 缓冲(默认 true)。
- 队列服务:RedisPersistenceQueueService 封装 Redis List 操作,提供入队和原子性批量出队。
- 消费服务:BatchPersistenceConsumerService 定时从各队列拉取消息,批量写入 MySQL(幂等处理)。
- 事件驱动:PersistenceEventListener 监听状态变更事件,异步调用持久化服务,实现最终一致性。
2.2.4.2、核心组件
RedisPersistenceQueueService:Redis 队列服务
实现方式:
- 使用 Redis 的 List 数据结构,每个队列对应一个 Key(如 bfm:queue:process_instance)。
- 入队:opsForList().leftPush(key, json)(LPUSH),保证 FIFO 顺序。
- 出队:通过 Redis 事务(MULTI/EXEC)实现原子性的 批量取走并删除:
- 消息序列化:Jackson 将消息对象转为 JSON 字符串。
特点:
- 高性能:纯内存操作,单次入队毫秒级响应。
- 原子性:事务保证批量取出和删除的原子性,避免重复消费或数据丢失。
- 隔离性:不同类型的持久化数据(流程实例、活动实例等)分队列存储,互不干扰。
- 容错:消费失败的消息不会从队列中移除(事务回滚),保证至少一次处理。
适用场景:
- 所有需要异步写入数据库的写操作,作为缓冲层削峰填谷。
- 需要保证数据最终一致性的场景,允许短暂延迟(秒级)。
BatchPersistenceConsumerService:批量消费服务
实现方式:
- 启动时创建 独立线程池(consumerExecutor)和 定时调度线程池(scheduledExecutor)。
- 为每个队列(流程实例、活动实例、执行历史、工作项)启动一个 定时任务,以固定间隔(flushIntervalMs)执行批量消费。
- 统计消费总量、批次数量、错误次数,并定时打印日志。
消费逻辑:
- 调用 queueService.batchDequeue 获取一批消息(最多 batchSize 条)。
- 将 JSON 反序列化为对应的消息对象。
- 根据消息中的 operation 字段(INSERT/UPDATE)分别处理:INSERT:尝试插入数据库,若主键冲突(DuplicateKeyException),则转为更新(幂等);UPDATE:直接执行更新。
- 使用 MyBatis-Flex 的 insert 和 update 方法,批量操作时循环单条处理(当前实现未使用批量 API,但可接受)。
特点:
- 批量处理:减少数据库连接开销,提高写入吞吐。
- 幂等设计:通过主键冲突检测实现"插入或更新"语义,确保消息重复消费时数据最终一致。
- 多线程隔离:每个队列独立线程消费,互不影响;可配置消费者线程数(consumerThreads)。
- 优雅关闭:实现 @PreDestroy,在应用关闭前尝试刷新所有队列,并等待线程池终止。
- 监控指标:提供队列长度、消费速率、错误数等统计,可通过 REST 接口获取。
适用场景:
- 高并发写入场景,需要将数据库写压力从实时路径转移到后台。
- 对数据一致性要求为最终一致,允许秒级延迟的业务。
- 需要监控队列积压情况,及时告警。
PersistenceEventListener:持久化事件监听器
实现方式:
- 使用 Spring 的 @EventListener 注解监听三个状态变更事件:ProcessStatusChangedEvent、ActivityStatusChangedEvent、WorkItemStatusChangedEvent。
- 监听器方法标注 @Async,由 Spring 异步线程池执行,不阻塞状态转换主流程。
- 方法内部调用 HighPerformanceProcessInstancePersistenceService 的对应持久化方法(例如 updateProcessStatus、saveActivityInstance),这些方法会根据缓冲配置决定是入队还是直接写库。
特点:
- 解耦:状态转换与持久化分离,状态管理器只负责状态变更和事件发布,不关心持久化。
- 异步:持久化操作在独立线程中执行,避免影响引擎核心性能。
- 容错:捕获异常并记录日志,防止单个持久化失败影响整个流程。
适用场景:
- 所有需要持久化状态变更的地方,通过事件机制统一处理。
- 希望减少状态管理器代码侵入性,保持核心逻辑简洁。
HighPerformanceProcessInstancePersistenceService:高性能持久化服务
实现方式:
- 实现 IProcessInstancePersistenceService 接口,提供流程实例、活动实例、工作项等的增删改方法。
- 每个写方法内部判断是否启用 Redis 缓冲(properties.isRedisBufferEnabled()):启用:构建对应的消息对象(如 PersistenceMessage.ProcessInstanceMsg),调用 queueService.enqueueXxx 入队,立即返回(毫秒级);未启用:直接调用同步降级方法(如 doSyncSaveProcessInstance),操作 Mapper 写库。
- 同步降级方法完整实现了数据库写操作,与未启用缓冲时的行为一致。
- 对于查询操作(如 getByProcessId),直接查询数据库,不受缓冲影响。
特点:
- 透明切换:上层调用方无需感知缓冲是否存在,接口保持一致。
- 降级机制:当 Redis 不可用或配置关闭时,自动降级为同步写库,保证功能可用。
- 数据完整性:同步降级方法包含完整的数据转换逻辑(如清理 NullValue、转换操作历史等),与异步路径等价。
- 轻量消息:消息对象只包含必要字段,避免序列化大对象。
适用场景:
- 作为流程引擎与持久化介质之间的适配层,统一所有持久化入口。
- 需要灵活切换高性能模式与兼容模式的部署环境。
2.2.4.3、高级特性
幂等处理(Idempotent Insert/Update)
- 在批量消费时,对于 INSERT 操作,若抛出 DuplicateKeyException(主键冲突),则捕获异常并执行更新操作。
- 判断逻辑:isDuplicateKeyException(e) 检测异常类型或 SQL 错误码,确保幂等性。
- 这允许消息被重复消费(如消费失败重试)而不产生重复数据。
多队列隔离
- 四种数据(流程实例、活动实例、执行历史、工作项)使用不同的 Redis Key 前缀,独立消费。
- 避免某一类数据积压影响其他数据;可根据业务优先级调整消费线程数和间隔。
动态配置
- 缓冲开关、批量大小、刷新间隔、消费者线程数等均通过 BfmPersistenceProperties 配置,支持运行时动态调整(需配合配置中心)。
- 可通过 REST 接口(BfmPerformanceMonitorController)实时查看队列状态,辅助调优。
监控指标
- 消费服务定期打印统计日志:队列积压、已消费条数、批次数量、平均批次大小、错误次数。
- 提供 /api/bfm/monitor/queue/status 和 /api/bfm/monitor/consumer/stats 接口,便于集成到监控系统。
- 健康检查接口 /api/bfm/monitor/health 根据队列积压量判断系统健康状态。
优雅关闭
- BatchPersistenceConsumerService 和 RedisPersistenceQueueService 均实现销毁前回调,在应用停止时尽可能刷新所有队列,减少数据丢失风险。
- StatusTransitionManager 实现 SmartLifecycle,在 Spring 容器关闭时停止接受新事件,确保正在进行的状态转换能完成持久化。
2.2.5、表达式求值器
实现方式
-
ExpressionEvaluator 类基于 Spring SpEL 进行了大量增强,支持:
-
自动解包:#{...} 或 ${...} 包裹的表达式自动去除包裹。
-
赋值表达式:支持 #bean.property = value 语法,递归设置嵌套属性(自动创建中间 Map 或对象)。
-
集合字面量:{#var}、{1,2,3} 解析为 LinkedHashSet。
-
类实例化:全限定类名(如 com.example.User)自动实例化,并初始化字段默认值。
-
复杂 SpEL:T(System).currentTimeMillis()、'prefix_' + #var、#list.?#this\>0 等标准 SpEL 特性。
-
属性访问增强:通过自定义 PropertyAccessor 支持 Map 和普通 Bean 的嵌套属性读取/写入。
// 赋值表达式示例
expression = "#userRequest.postIds = {#postId}";
// 求值后,将 #postId 的值放入 Set,并赋值给 userRequest 对象的 postIds 属性
// 嵌套变量访问
expression = "#postResult.postId"; // 从流程变量中获取 postResult 对象,再取其 postId 属性
特点
- 语法丰富:覆盖了日常 90% 的动态逻辑需求,无需编写 Java 代码。
- 类型转换:自动将求值结果转换为目标类型(如 String 转 Long)。
- 安全访问:对 null 值进行保护,避免 NPE。
- 高性能:SpEL 表达式编译后缓存,重复使用。
适用场景
- 流程定义中的条件分支(转移线条件)。
- 数据映射中的源表达式(从上下文提取值)。
- 动态赋值和变量计算。
2.2.6、数据映射处理
实现方式
DataMappingInputProcessor 和
DataMappingOutputProcessor 共同实现输入/输出映射,支持:
-
扁平映射:直接将表达式结果赋给简单变量。
-
嵌套映射:通过 #target.nested 语法,自动创建中间 Map 或 Bean 对象。
-
类型转换:根据 dataType(set/list/bean)和 beanClass 自动转换集合类型或实例化 Bean。
-
必填校验:required=true 时若值为 null 则抛出异常。
-
作用域控制:通过 scope 属性决定变量存入 WORKFLOW/LOCAL/PACKAGE 作用域。
特点
- 声明式数据转换:通过 XML 配置完成复杂的数据准备和回写,减少 Java 代码。
- 自动构建对象:对于嵌套目标,自动创建 HashMap 或指定类型的 Bean,并填充属性。
- 类型安全:支持强类型 Bean 转换(基于 Jackson)。
- 灵活的作用域:变量可存储在流程、活动或包级别,满足不同生命周期需求。
适用场景
- 活动输入参数的准备(如从流程变量提取并构造调用参数)。
- 活动输出结果的回写(将执行结果存入流程变量供后续使用)。
- 子流程与父流程之间的数据传递。
2.2.7、DAG 并行执行与防重复机制
实现方式
在 FutureSubProcessExecutor 中,通过以下技术实现高效的 DAG 并行执行:
-
DAG 构建与拓扑排序:解析工作流定义,构建活动依赖图(DagGraph),计算拓扑层级。
-
CompletableFuture 链式驱动:每个活动对应一个 Future,依赖关系通过 thenCompose、allOf 组合。
-
执行标志防重复:使用 ConcurrentHashMap<String, AtomicBoolean> 记录每个活动是否已被调度执行。汇聚网关后的活动可被多个上游同时触发,通过 CAS 确保只执行一次。
-
超时控制:对整个 DAG 设置超时,超时后取消所有未完成 Future。
// 活动级防重复执行
String flagKey = processId + ":" + actId;
AtomicBoolean flag = activityExecutionFlags.computeIfAbsent(flagKey, k -> new AtomicBoolean(false));
if (!flag.compareAndSet(false, true)) {
// 已有线程在执行或已执行过,直接返回跳过结果
return CompletableFuture.completedFuture(skippedResult);
}
特点
- 细粒度并行:活动级别并发,最大化利用 CPU。
- 精确依赖:严格按照 DAG 拓扑执行,保证正确性。
- 防重复触发:关键机制确保汇聚节点不被多次执行。
- 可观测性:执行过程中记录每个活动的耗时和状态。
适用场景
- 子流程内部存在复杂依赖且可并行的场景(如并行网关、包容网关)。
- 需要精确控制活动执行顺序的业务流程。
- 对执行时间敏感,希望最大化并发的场景。
2.2.8、细粒度并发控制与锁机制
实现方式
StatusTransitionManager 摒弃了传统的全局同步锁,采用 Per-Instance 细粒度锁:
-
为每个流程实例、活动实例、工作项实例创建独立的 ReentrantLock,存储在 ConcurrentHashMap 中。
-
转换状态时,通过实例 ID 获取对应的锁,仅锁定该实例,不影响其他实例。
-
锁的创建和清理通过 computeIfAbsent 惰性创建,实例进入终态后可考虑移除(但当前未自动清理,可优化)。
private ReentrantLock getLock(ActivityInstance actInst) {
String lockKey = "ACT:" + actInst.getId();
return instanceLocks.computeIfAbsent(lockKey, k -> new ReentrantLock());
}
public void transition(ActivityInstance actInst, ActStatus newStatus) {
ReentrantLock lock = getLock(actInst);
lock.lock();
try {
doTransition(actInst, newStatus);
} finally {
lock.unlock();
}
}
此外,ProcessInstanceExecutor 中通过 ConcurrentHashMap 维护活动执行锁,防止同一个活动被重复执行。
特点
- 高并发:不同实例的状态转换可并行执行,无锁竞争。
- 死锁预防:每个实例只锁自己,不会出现交叉锁等待。
- 细粒度控制:锁范围最小化,提升系统吞吐量。
- 锁复用:同一个实例多次状态转换使用同一把锁,保证顺序性。
适用场景
- 高并发流程引擎,需要支持大量流程实例同时运行。
- 对状态转换顺序有严格要求(如不能跳过中间状态)的场景。
- 避免全局锁导致性能瓶颈。
2.2.9、事务模式与重试禁用
实现方式
TxSubProcessExecutor 通过 @Transactional(propagation = REQUIRES_NEW) 将子流程执行包裹在独立事务中。同时引入 TxModeHolder(ThreadLocal)标记当前线程处于事务模式,用于通知其他组件(如 InvokerDispatcher)禁用重试等干扰事务的行为。
@Transactional(propagation = Propagation.REQUIRES_NEW, rollbackFor = Throwable.class)
public ProcessInstance executeInNewTransaction(...) {
TxModeHolder.setTxMode(true); // 标记事务模式
try {
// 启动并等待子流程
ProcessInstance subInstance = subProcessStarter.startSubProcess(...);
waitForSubProcessCompletionWithErrorDetail(subInstance);
return subInstance;
} finally {
TxModeHolder.clear(); // 清理标记
}
}
// InvokerDispatcher 中检查 TxMode
int maxAttempts = TxModeHolder.isTxMode() ? 1 : 3; // 事务模式下不重试特点
- 事务隔离:子流程在独立事务中运行,提交/回滚不影响父事务。
- 重试禁用:避免事务内重试导致数据不一致或资源浪费。
- 异常传播:子流程中的业务异常完整抛出,父流程可根据需要处理。
- 组合使用:可与 Sync、Async 等模式叠加,实现"独立事务 + 同步等待"。
适用场景
- 需要将子流程作为独立工作单元提交的场景(如记录日志、发送消息)。
- 子流程包含不可回滚的操作(如调用外部系统)。
- 希望避免子流程失败导致父事务回滚的场景。
3、开发
虽然代码是AI写的,但整个架构和设计由本人控制,并没有交给AI去天马行空。因为我很清楚,AI本质上是在根据上下文匹配知识库,预测并输出最可能的下一个单词,这个过程天然带有偶然性和随机性。在现阶段,没有程序员的干预,AI提供的代码只是各种组织堆砌的没有灵魂的肉体,只有经过程序员的指引和约束,才能赋予其真正的业务逻辑与"灵魂"。
这种与AI海量的信息交互中,需要随时做好上下文的保存和修改,虽然现在openclaw已经提供了skills和永久记忆的方式,但我们的初衷是设计一款具备通用逻辑的抽象设计,追求在可控范围内实现精确的代码,而不是由AI随意发挥。实践中,AI的实现时常无法满足预期,甚至表现出"偷懒"倾向,这时就需要反复鞭策,必要时借助多个AI模型进行交叉验证对比,以及提供一些示例,AI才能最终完成所需的实现。
这些心得与体验,不敢独享,在此抛砖引玉,希望能为同路人提供些许参考。
3.1、上下文构建
下面是我写的第一个需求,千里之行始于足下,所以在这里记录下来,这是本工程的起点,这也是贯穿整个BFF开发的总纲。
3.1.1、构建总体需求
我需要实现服务编排的功能,类似工作流和bpm功能,基于spirngboot 2.7,jdk8,lombok标注,mybatis-flex,mysql5.7的技术栈。具体服务编排的功能描述如下
- 服务编排的概念是微服务架构落地伴生而来,原本一次请求即可处理完成的业务,现在可能需要多次请求才能完成,为了降低前端逻辑的复杂性并提高前后端交互效率,BFF层应运而生。BFF作为前后端的代理层,提供了一个业务接口聚合层,其核心职责是为前端适配不同的业务场景,降低客户端与业务端的耦合,前期通过硬编码的方式来实现BFF层的需求,是最简单最直接的方式。但随着BFF层承接业务需求的增多,采取硬编码方式容易产生编码效率低、编码细节难以规范、调试测试效率低等问题。
- 服务编排在统一规范的基础上提供了业务逻辑的柔性设计,通过可视化设计快速的API的编排、调试、测试和上线。看上去服务编排和工作流引擎在形式上趋同,但两者不一样。在脚手架/低代码平台会提供类似Flowable 、Activiti、Camunda实现的OA审批工作流系统。这种工作流基于表单模式,通过扩展表或者表单表上添加辅组字段满足业务的审批流转,最终形成留痕记录。这种模式都是人-机交互模式,而服务编排,更多的是机-机交互模式,强调的是服务(API)的有序调用。
- 微服务体系架构是一种前后端架构,在前后端之间添加中间层 (BFF:Backend For Frontend),以解决服务的汇聚和调用,把BFF加入在前后端架构之后,前端服务不再直接访问后端微服务,而是通过 BFF 层进行访问。从微服务的角度来看,由于有关 UI 逻辑的数据在 BFF 层进行了处理,减少前后端细颗粒微服务之间的相互调用。
- 采用BFF之后的开发逻辑:通过后台工具查到原始数据,然后按照业务要求,把查到的原始数据封装成API,再通过加工->组装->适配成可以展示给前端的信息,最后发送给客户端使用。这部分各个服务(API)的聚合工作主要由中间层的BFF API负责。
- BFF API的处理也是有一定的业务逻辑,可以抽象为串行,并行,分支,汇聚等,包括多种服务接口的适配,可视化业务逻辑的设计,持久化保存需求,接口返回数据的裁剪、排序、格式化等操作,这些功能又可以映射为BPM的能力。所以最终支持BFF层运行的底层组件是BPM系统,提高提升微服务的复用度,降低编码及编译打包的等待时间,提高业务逻辑的快速交付能力。
可视化服务编排系统的核心功能都是对BFF日常需求及研发流程的抽象,从接口的调用方式、出入参的处理、接口异常情况的处理、服务的调试测试、服务的上线流程等几个维度完成系统整体功能的设计。
A、实现思路
- BFF 层中包括了类似BPM的系统,可以用于定义和管理API的聚合逻辑,包括不同微服务之间的调用顺序、条件和数据处理流程。
- BPM 系统可以充当一个中心化的控制器,负责协调和管理各种微服务之间的交互,从而简化前端与后端微服务之间的通信。
- 通过 BPM 系统,可以实现复杂的业务流程和逻辑,将这些逻辑从前端和后端微服务中解耦出来,提高系统的灵活性和可维护性。
B、具体方案
- 在 BFF 层引入一个BPM 系统,用于定义和管理API 的聚合逻辑。
- BPM 系统提供可视化流程配置界面,方便业务人员定义和修改流程规则。流程设计器,交互的产品可以是符合schema的xml,或者等价转换的json
- BPM 系统需要与微服务架构无缝集成,可以通过Rest/WebService/local SpringBean 或消息队列等方式与后端服务进行通信。
- BPM包括与人交互的部分,为将来人工介入提供入口。
C、核心功能
- 接口调用:接口间调用关系可以抽象为:串行调用、并行调用、排他调用
- 参数处理:包括入参/出差,静态/动态参数,动态参数的值来自外部接口的返回值
- 异常处理:在异常场景下,流程能执行一个预期的分支,并把异常信息能捕获
- 调试测试:需要输出编排执行的输出日志,以及异常信息的捕获
- 服务部署:引擎可以分为单节点部署和多节点部署,不同的节点执行不同的业务流程,同时因为不是硬编码,所以业务逻辑的部署实现了类似定义即部署的方式。
3.1.2、人肉永久记忆
这里用sublime承载了需要长期记忆的内容,使用editplus来组织每次需要交流的语言,并且每次当前会话的token告罄之后,重新组织新的上下文,关键内容和需要长期记忆的内容需要转移记录在sublime保存。
3.1.3、开发思路
前期LLM上下文只有128k,在提交提示词的时候非常考验所提交的内容,并且要估算他的关键字和注意力是在什么地方。所以思考后定下整体流程和步骤
- 首先做模型定义,这是基础,模型定义清楚了,整个bfm的功能就界定。
- 引擎开发顺序是先做xml解析,其次是普通流程执行(自动活动),顺理成章的扩展到其他子流程模式;接着是处理4个网关;然后是人工活动处理,状态机从2层扩展到3层;最后才做持久化和缓存以及批处理。这样能让开发工作有序扩展,代码量不会在早期膨胀过快,难度大的放在前面处理,确保LLM有足够的token来反复交流和确认。
- 测试驱动,每次修改代码完毕后都要完整的回归测试,验证代码的效果
- 交替使用deepspeed,kimi,qwen,向他们提相同的问题,在差异化的回答中寻求端倪和答案,并交叉验证。交叉验证后,大模型往往会比上一次回答要更精准,这应该是在提示词中出现了关键字或者反复出现的内容,让大模型的注意力有了变化。
3.2、模型定义
最难的其实在xml schema定义阶段,反复沟通反复拉扯,xml schema前后修改了几十个版本,在进入开发阶段后,xml shema 还做过修改,整个代码都要重构,不过在LLM的加持下,所有的修改只是一个时间的问题。在清晨和节假日的时间里,大模型的效率和速率会高一些,这是我和LLM独处的黄金时刻,此时此刻与LLM人机合一。
在交流的过程中,首先自己要有立场,LLM提供的信息要不是佐证,要不就是证伪,是对是错彼此都要说服,另外deepspeed比较黏人的,语气友好,比较顺从提问者的思路,有时候会陪你一路走到黑,所以需要多方资源交叉验证,确保路线和方向不能走偏。在反复拉扯中,还把kimi2问得有些抑郁了,说要休息下,明天再聊。
考虑到xml schema的重要性和前置性,在BFM项目开始的时候,首先要完成的是xml schema的定义,所以一上来我就旗帜鲜明的亮出了自己的观点,编写如下提示词:
3.2.1、早期提示词
1、要满足xml spy 2012的兼容性
2、1个package可以包括多个工作流,可以是主流程也可以是子流程,原则是package内工作流定义相互共享,但也可以引用外部package的工作流
3、工作流启动可以接受外部的传参,也支持结果的返回。返回数据包括流程执行信息,返回的流程结果,以及执行的过程步骤和执行时间,如果有异常支持异常栈信息
4、流程可以给子流程传递数据,子流程结束后可以返回数据给主流程
5、子流程可以是同步执行,也可以是异步执行,但需要控制好异步子流程的时候,如果主流程正常结束,异步执行子流程出现异常的情况
6、活动包括开始,结束,自动活动,人工活动,路由活动
7、开始活动(支持消息,信号来激活),
8、结束活动(支持结束后可以发送消息或者信号),
9、自动活动(支持rest,webservice,spirngbean,javaben调用,支持参数传递和返回),
10、人工活动(支持web表单的调用,以及传参),人工活动,有多种与外部人员交互的动作,每个人工活动代表一个web表单的业务处理,但与该web表单可能会涉及多人
a、这个表单单独指定给某一个去做
b、这个表单分配给某个角色/部门/小组,这里涉及到多人,允许先登录系统先分配,或者主动领取任务的方式,或者由系统指派任务
c、这个表单分配给某个角色/部门/小组,1人执行表单处理后,该工作完成;也可以是大多数人处理后才算完成;也可以是全部处理后才算完成
11、路由活动(支持单一条件分支,条件多分支,全部分支等)
在EXCLUSIVE_GATEWAY,COMPLEX_GATEWAY,INCLUSIVE_GATEWAY这里允许执行某个条件,或者某个条件表达式,
然后与transition的条件匹配,满足条件的,就走这个分支
12、如果子流程除了开始活动和结束活动之外,都是自动活动组成,可以设定,对于条件分支后满足多个自动活动执行的情况下可以允许用多线程并行执行,
用来加快处理速度,然后在聚合节点,进行线程同步,再进行后续处理
那表达分支、合并的transition则定义了线程的并行和同步关系,在分支的情况下,后续自动活动可以多线程执行,
而到达了合并的节点,则需要等待前面线程都同步了,再执行后续的线程(api)。
如何表达这个关系,是继续沿用之前的sub,还是单独设定一个类型?在这里用什么方式表达多线程运行和合并的方式?
13、变迁代表活动之间的转移,支持根据条件的转移方式
仔细比较workflow-v4.xsd和workflow-v5.xsd的差异性,并一一指出
1、把workflow-v4.xsd合理的功能补充到workflow-v5.xsd中
2、另外需要在workflow-v5.xsd补充如下功能
a、package 应该有id和name,version作为package内各个workflow的统一版本
b、自动活动改为autoTask,简洁一些
c、自动活动少了个springbean的调用,这个是在spring容器内调用的,javabean是通过反射调用的
d、自动活动的参数,包括了入参和出参,应该有参数类型的定义把,以及参数传递过程中可能有的参数数据类型转换
根据以上几点,完善workflow-v5.xsd,并完整输出,不要省略3.2.2、改进提示词
在后来迭代的时候,考虑到LLM需要知道你所做的功能和边界,所以我把流程模型的定义也补充在这里,明确告知功能列表,修改的提示词如下:
根据这个工作流xml-schema,生成测试xml流程,这里的开始活动和结束活动都是普通活动,不添加消息和信号。如有需要,会明确提出
1、在1个pckage中设计1个workflow,有1个开始,1个结束,中间是5个自动活动,api从前面给定的示例中获取,要求能从流程开始处接受参数,流程结束后,返回数据;并且每个自动活动有能接受数据传参,后续活动能获取到前面一个活动的返回结果,并参与后续活动的处理
......
14、在1个pckage中设计2个workflow,1主流程,1子流程。主流程有1个开始,1个结束,3个自动活动,1个路由活动,1个子过程活动,子流程同步调用。api从前面给定的示例中获取,要求能从流程开始处接受参数,1个路由活动,INCLUSIVE类型,根据条件找到符合的条件的后续,并在某个汇合点同步等到,等待前驱活动全部完成,再完成后续流程结束后,返回数据。并且各个自动活动,有必要的数据传参,后续活动能获取到前面一个活动的返回结果,并参与后续活动的处理
......
20、在1个pckage中设计2个workflow,1个main流程,1个子流程,主流程有1个开始,1个结束,3个人工活动,1个自动活动,1个子过程活动,要求能从流程开始处接受参数, 每个人工活动包括多种分配方式:FIXED,CLAIM,ROUND_ROBIN,涉及的人员有角色,部门,指定人等,完成方式有any,all,MAJORITY,
需要设计一个自定义的工作流定义的xml schema,要求如下
1、要求xml schema的定义能支持前面20个流程业务要求,每个工作流定义需要和xml schema能对应上,需要一一对应并展示出来
2、人工活动的处理,需求参考但不限于如下,根据这些下面的信息进行完善和改进,需要能灵活处理各种业务场景,每个人工活动包括多种分配方式:FIXED,CLAIM, ROUND_ROBIN,涉及的人员有角色,部门,指定人等,完成方式有any,all,MAJORITY,
另外有几个地方需要完善
工作流有main和sub类型的区分,这个在哪里体现
package是管理workflow的容器,可包含1到多个workflow的定义,其工作流定义可以引用其他package的工作流,这里还有版本的控制,有体现吗
对于sub流程,如果定义了多线程模式,其内部的自动活动,在条件判断后续有多个自动活动可同时处理的时候,启用多线程方式,并在汇聚的地方启动线程同步等待
活动参考如下事件,但不限于如下的信息,进行完善和改进,事件数据处理规则:
空启动
消息启动事件,外部→流程,$messageBody,将原始消息转换为结构化流程参数
消息结束事件,流程→外部,$messageBody,将流程结果封装为输出消息
信号捕获事件,外部→流程,$signalData,解析信号携带的有效载荷
信号抛出事件,流程→外部,$signalData 附加业务数据到发出的信号
定时器事件,内部生成,无,通过扩展字段传递时间参数
基于消息启动/抛出,应对应具体的参数和类型,才能在流程推进过程中被各个活动共享
消息完整性:当消息/信号包含DataMapping时,必须至少有一个Input或Output映射
变量作用域:$messageBody仅在消息事件中有效,$signalData仅在信号事件中有效
转换器兼容:信号数据支持二进制转换(如Base64编解码),需在转换器实现层处理
可以参考如下,根据这些下面的信息进行完善和改进
多线程子流程,设置ExecutionMode.mode="CONCURRENT"并指定maxThreads
跨包引用,使用WorkflowRefType指定packageId+workflowId+version三元组
分支同步,网关设置syncPoint="true",completionSize定义需要完成的分支数
版本控制,Package.version遵循语义化版本,WorkflowRef.version精确匹配目标版本
xml schema做适当调整,以便基于该xml schema生成的xml不必套用命名空间,设计符合以上功能的xml schema,给出完整的xml schema定义,不要省略,兼容XML Spy 2012。此处生成的xml schema是workflow-v8.xsd
期间还有过条件放置位置的争论,是主要参考xpdl规范还是参考bpm规范的讨论,LLM知识极其渊博和全面,和LLM对话,需要自身也要具备相应的知识体系,避免被带到沟里去。现在xml schema已经是v10版本了,这是大版本的更新,期间还有小版本的改进。
3.3、完善基座
在实际做xml schema之前,还花了一点时间优化一个开发脚手架,之前公司的版本有些老,也是希望在私域平台中全面升级整个技术体系,所以这次对开发脚手架进行了新的遴选和摸排,选择了若依作为开发基座。不过考虑到原始版本用的是mybatis-plus,而bfm平台用于后端且有大量数据处理的需求,把plus切换成flex,这也是全面使用AI来编写代码的第一次尝试。
第一次其实是不成功,可能有些贪多,想保留framewokr所有的starter,结果在租户和数字权限这里折腾了一些时间,可能一些数据过滤用到了plus的特殊功能和sqlpaser的底层代码,测试用例总是无法通过。后来也想清楚了,既然是后端框架,注重数据处理的高效性,其实有些功能就不必要,做了部分starter的裁剪,才把plus迁移到了flex。这也是BFM工程的预演,通过小规模的验证,证明了LLM能做一些大型的软件,前提是设定合适的目标,规划好实施的路径,写好测试用例,剩下的就交给LLM。
3.4、引擎设计
3.4.1、早期提示词
首先,用户提供的XML Schema定义了工作流的结构,包括包(Package)、工作流(Workflow)、活动(Activity)、网关(Gateway)、事件(StartEvent、EndEvent)、任务(AutoTask、UserTask、SubProcess)等元素。
测试XML文件展示了各种工作流配置,如顺序执行、子流程同步/异步调用、不同类型的网关、人工任务分配等。
解析代码使用XStream来处理XML到Java对象的映射,其中包含了各种模型类和转换器。
接下来,我需要分析这些内容,确定工作流引擎需要支持的功能:
1. 流程定义解析:能够解析用户提供的XML格式,转换为内部的模型对象。
2. 流程执行控制:支持顺序执行、分支、并行、子流程同步/异步调用。
3. 活动类型处理:自动任务(REST、WebService、JavaBean、SpringBean)、人工任务(分配策略、表单、完成规则)、子流程、事件(开始、结束)和网关(排他、并行、包含、复杂)。
4. 数据映射:输入输出参数的类型转换和映射。
5. 依赖管理:处理不同包之间的依赖关系。
6. 版本控制:支持工作流版本管理。
7. 异常处理与日志:执行过程中的错误处理和日志记录。
8. 事件驱动:消息和信号事件的处理。
我需要设计模块和类结构。可能分为以下几个模块:
核心引擎模块:负责流程的解析、执行、状态管理。
活动处理器模块:处理不同类型的活动(自动任务、人工任务等)。
网关处理器模块:处理各种网关的逻辑。
数据映射模块:处理参数的类型转换和映射。
持久化模块:虽然用户暂时不需要数据库,但未来可能需要,暂时用内存存储。
事件处理模块:处理消息和信号事件。
需要确定各个模块所需的Java类,例如:
WorkflowEngine:核心引擎,启动和管理流程实例。
WorkflowParse*:解析XML到模型对象。
ActivityExecutor:活动执行接口,不同活动类型的具体实现(如AutoTaskExecutor、UserTaskExecutor)。
GatewayEvaluator:网关条件评估器。
DataMapper:处理数据映射和转换。
ProcessInstance:代表一个流程实例,保存当前状态。
TaskService:管理人工任务的分配和完成。
工作流引擎核心功能设计,核心功能模块如下
流程定义管理:支持XML配置解析、版本控制、依赖管理、参数校验
流程执行引擎:驱动流程实例运行,处理分支/并行逻辑,维护执行上下文
活动处理器:处理自动任务(REST/WebService/Java/Spring)、人工任务、子流程、网关等不同类型活动
数据转换系统:支持类型转换(日期/JSON/base64)、自定义转换器、Bean映射
事件管理:处理消息/信号事件、支持跨流程通信
任务调度:人工任务分配策略(固定/抢单/轮询)、审批规则(全票/多数票/任意)
异常处理:流程中断/重试/补偿机制、错误日志记录
监控统计:流程实例状态跟踪、执行耗时统计、节点轨迹记录3.4.2、改进提示词
实现自定义轻量级工作流,包括如下功能
XML Schema定义工作流的结构,包括包(Package)、工作流(Workflow)、活动(Activity)、
网关(Gateway)、事件(StartEvent、EndEvent)、任务(AutoTask、UserTask、SubProcess)等元素。
测试XML文件展示了各种工作流配置,如顺序执行、子流程同步/异步调用、不同类型的网关、人工任务分配等。
解析代码使用XStream来处理XML到Java对象的映射,包含各种模型类和转换器。
一、功能总结分析与补充
确定工作流引擎需要支持的功能:
1. 流程定义解析:能够解析用户提供的XML格式,转换为内部的模型对象。
Schema校验:需增加XML Schema严格校验(使用JAXP的SchemaFactory),防止非法流程定义
高性能解析:考虑使用StAX解析器替代DOM,处理大文件时内存更高效
扩展性设计:预留自定义元素扩展点(如<xs:any>处理)
错误定位:需记录详细解析错误日志(行号、元素路径)
2. 流程执行控制:支持顺序执行、分支、并行、子流程同步/异步调用。
执行模式:同步/异步执行模式,支持多级嵌套,跨流程数据映射
同步子流程:需实现调用栈管理(Stack<ExecutionContext>)
异步子流程:需集成线程池(配置最大并发数、拒绝策略)
网关增强:排他/并行/包含/复杂网关逻辑,支持条件表达式与智能合并函数(如coalesce)
并行网关:实现syncPoint机制(等待所有分支到达)
复杂网关:支持动态条件优先级(非默认顺序评估)
中断处理:需支持流程实例的暂停(SUSPEND)、恢复(RESUME)状态
跨流程通信机制
消息驱动(messageRef)与信号广播(signalRef)双模式
事件总线实现发布-订阅模型,支持负载传递和系统变量注入(如$system.currentUser)
3. 活动类型处理:自动任务(REST、WebService、JavaBean、SpringBean)、人工任务(分配策略、表单、完成规则)、子流程、事件(开始、结束)和网关(排他、并行、包含、复杂)。
自动任务增强:
自动任务 REST/WebService/JavaBean/SpringBean调用配置,支持HTTP方法、WSDL绑定等
协议支持:
REST:连接池管理、重试机制(可配置次数/间隔)
WebService:WSDL缓存、SOAP头处理
Bean调用:类加载隔离(防止不同流程的类冲突)
服务调用适配器
协议类型 关键配置项 特殊处理
REST endpoint, method, headers 连接池管理、重试策略
WebService wsdl, operation, port 端口缓存、SOAP报文压缩
JavaBean class, method 反射调用、异常堆栈捕获
SpringBean beanName, method 上下文感知的Bean查找
消息中间件集成
异步任务队列(RabbitMQ/Kafka)
信号多播:单个信号触发多个子流程实例
人工任务增强:动态表单加载、多维度分配策略(FIXED/CLAIM/ROUND_ROBIN)、完成规则配置
分配策略:
动态表单:需设计表单渲染引擎(根据URL加载JSON Schema)
任务抢占:实现CLAIM策略的分布式锁机制
4. 数据映射:输入输出参数的类型转换和映射。
表达式引擎:集成轻量级表达式引擎(如SpEL)处理复杂映射
嵌套结构:支持Map/List的深层路径解析(如user.address.city)
类型安全:增加运行时类型检查(如将String强制转为Long时的异常捕获)
数据转换体系
转换类型 示例 实现方式
内置转换器 stringToInt, dateFormat 预置通用转换逻辑
自定义转换器 EmployeeToUserIdConverter 实现统一接口并注册到上下文
动态格式处理 base64Encode(敏感字段加密) 通过format属性指定参数
5. 依赖管理:处理不同包之间的依赖关系。
版本解析:实现语义化版本控制(SemVer)的依赖解析算法 ,class VersionResolver
隔离加载:采用类加载器隔离不同包的依赖(避免Jar冲突)
依赖缓存:缓存已解析的依赖包,提升加载速度
6. 版本控制:支持工作流版本管理。通过package的版本,对包内所有workflow进行统一版本控制
版本回滚:提供API回滚到历史版本
流程快照:执行中的实例应关联定义版本(即使定义更新,正在运行的实例不受影响)
灰度发布:支持多版本并存,按条件路由(如header指定版本)
7. 异常处理与日志:执行过程中的错误处理和日志记录。
错误边界:定义每个活动的异常捕获范围(类似try-catch作用域)
重试策略:可配置的指数退避重试(适用于网络调用)
事务补偿:实现SAGA模式(对已完成操作提交补偿任务)
日志分级:区分引擎日志(DEBUG)与业务日志(INFO)
8. 事件驱动:消息和信号事件的处理。
事件总线:实现基于主题(Topic)的发布-订阅机制,class EventBus
信号广播:支持跨流程实例的信号传播
事件持久化:关键事件需持久化存储(用于审计)3.5、三层状态机
3.5.1、设计与考量
在领域驱动设计中,贫血模型和充血模型是两种常见的领域对象设计风格。贫血模型指领域对象仅包含属性(getter/setter)和极少的行为,业务逻辑集中在 Service 层,本质上是面向过程的编程,丢失了业务语义;充血模型则强调领域对象既包含属性也包含业务行为,符合面向对象的封装原则,更能体现业务的完整性。基于spring的开发有其内在的特点,spring推崇基于贫血模式的开发模式,所以在设计BFM 引擎状态机的时候,考虑到了贫血模型与充血模型的平衡。
Spring 框架自诞生以来,其核心设计理念与贫血模型高度契合:
- 依赖注入的便利性:Spring 的核心是管理无状态的 Bean,通过依赖注入将它们组装起来。充血模型中的领域对象如果包含行为,这些行为往往需要依赖其他服务(如 Repository、外部接口),导致领域对象本身也需要被 Spring 管理,从而可能引发循环依赖、构造器复杂等问题。贫血模型则将行为剥离到 Service 层,Service 作为无状态 Bean 被注入,领域对象仅作为数据载体,契合了 Spring 的依赖注入机制。
- 事务边界的清晰性:在 Spring 中,事务通常声明在 Service 层的方法上,保证了事务的开启和提交在明确的边界内。如果领域对象自身包含持久化行为(如 order.save()),事务控制会变得分散且难以管理。贫血模型将数据库操作集中在 Service 或 Repository 层,事务边界一目了然。
- 分层架构的惯例:传统三层架构(Controller-Service-Dao)已深入人心,开发者习惯将业务逻辑写在 Service 中,领域对象仅作为数据传输对象。这种分层方式简单直观,便于团队协作和测试(Service 可轻松 Mock 领域对象)。
在状态机中有一些开源的实现,Spring StateMachine 是 Spring 官方提供的有穷状态机实现,它严格遵循 UML 状态机规范,支持层次状态、正交区域、伪状态(choice、fork、join、history 等)等高级特性。但评估后觉得Spring StateMachine不合适:
- 有状态且重量级:每个状态机实例内部维护复杂的状态结构,无法在分布式环境中直接共享,且内存开销大。
- 学习曲线陡峭:开发者需要理解 UML 状态机的全套概念,增加了使用成本。
- 与业务耦合不足:BFM 需要管理流程、活动、工作项三层状态的联动,以及数据库持久化,Spring StateMachine 的通用设计难以直接贴合这些特定需求。
BFM 的场景是服务编排,而不是通用状态机,我们需要的是一种轻量、高效、与数据库深度集成的解决方案。最后系统采用的是自研状态机:贫血实体 + 集中式状态管理的混合模式。在实现方面做出了一次巧妙的平衡,既没有完全采用贫血模型导致 Service 臃肿,也没有陷入充血模型的复杂陷阱,而是设计了一种"贫血实体 + 集中式状态管理 + 活动执行器"的混合模式:
- 实体仅承载数据(贫血):ProcessInstance、ActivityInstance、WorkItemInstance 等实体类只包含属性(如状态、变量、时间戳),没有任何业务行为。它们纯粹作为状态数据的容器,便于持久化和传输。
- 状态转换逻辑集中化(富血管理器):所有状态转换的合法性校验、转换执行、事件发布都集中在 StatusTransitionManager 中。该类通过细粒度锁(Per-Instance ReentrantLock)保证并发安全,并通过 Spring 事件机制将状态变更通知到监听器(如持久化、日志)。状态转换规则在枚举类中显式定义(TRANSITION_RULES),一目了然。
- 活动执行逻辑分散到各个 Executor(关注点分离):针对不同的活动类型(自动任务、人工任务、子流程、网关),设计了独立的执行器(如 AutoTaskExecutor、UserTaskExecutor、GatewayExecutor)。这些执行器负责具体的业务逻辑,但它们不直接修改实体状态,而是通过调用 StatusTransitionManager 来触发状态变更。
可以说,BFM 的状态管理是"贫血的实体 + 富血的管理器",既保留了贫血模型的清晰分层,又通过集中式管理器实现了业务逻辑的内聚。这样的优势在于:
- 职责清晰:流程、活动、工作项各司其职,状态转换规则显式定义,活动执行逻辑按类型分散,每一部分的职责单一且明确,易于理解和维护。
- 扩展灵活:新增活动类型只需扩展对应的 Executor,新增状态处理逻辑只需修改 StatusTransitionManager 或添加新的事件监听器,无需大范围改动。
- 性能可控:细粒度锁避免了全局竞争,高并发下不同实例的状态转换可并行执行;异步持久化(Redis 缓冲 + 批量刷库)进一步提升了系统吞吐量。
- 可观测性强:状态变更事件贯穿整个生命周期,通过监听器可以轻松实现日志、监控、审计等功能,便于问题追溯和系统运维。
BFM 最终没有选择引入 Spring StateMachine 等外部框架,而是自研了一套轻量级状态机,正是因为它紧密贴合了服务编排的业务场景:不需要 UML 的复杂特性,只需要可靠、高效地协调流程、活动和任务项的三层状态。这种"贫血实体 + 集中式管理器"的混合模式,既符合 Spring 开发的惯例,又通过合理的抽象避免了贫血模型的缺陷,是轻量级引擎设计中一次成功的平衡实践。
3.5.2、状态跃迁
下面的设计图来自早期的思路,在设计提示词的时候清洗完整的传达给了LLM,也是我们设计状态机的基石。在实际的实现中,LLM说服了我,对各个层级的状态做了一些微调,但整体思路没有变化,具体的内容可以参看前面的内容。
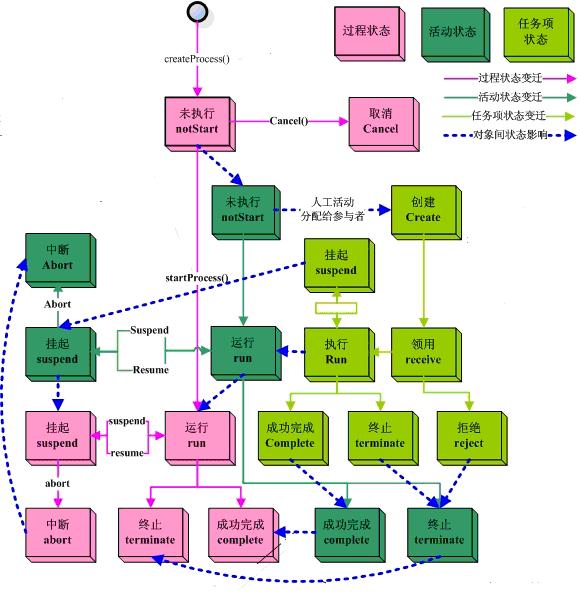
3.5.2.1、三层跃迁关系
这里是三层状态机的状态跃迁变化图,面对对于多层状态机,每层状态机拥有自己的状态变化,同时状态变化可能会对其他状态机产生影响。这里区分2种情况:
- 人-机场景(流程-活动-任务项):对于人工活动,它不直接面向参与者,需要item与参与者交互,同时拥有自身的状态和控制字段,并和活动作状态交互。所以对于人工活动来说,有三层状态:过程活动任务项。
- 机-机场景(流程-活动):自动活动主要处理业务逻辑,没有人-机界面,不需要额外的控制,因此对于自动活动来说,它就只有两层状态,过程活动。
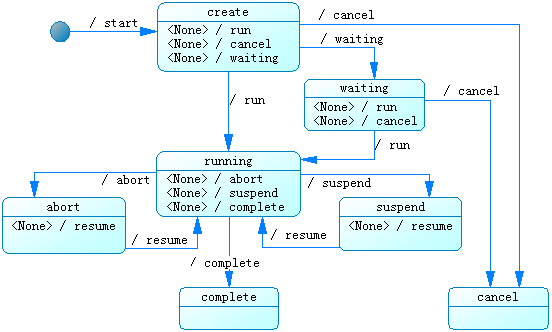
3.5.2.2、单层状态跃迁
单层状态变化以及操作的关系(这里是process status为例)
3.5.2.3、状态联动
这里是早期设计的思路草图,仅供参考,从另外一个角度分析状态机的相互关联
1、自动流程模式
这是最简单的业务场景,只会包括流程和活动。2层状态机。活动是begin,end和auto,这里不包括human活动。
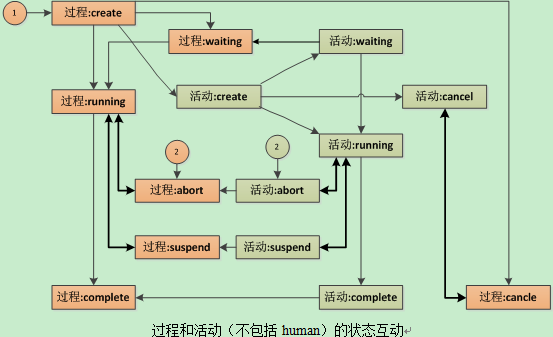
说明
- abort态表示活动出现了excption,被cache抛出;
- suspend是用于human活动中,对工作项的挂起处理;
- waiting是外部条件不满足,导致对象等待,比如等待某个时间点才触发;
- 圆圈1,表示触发过程的启动
- 圆圈2,表示流程在异常情况下,经过运维处理,由员工在过程或活动处重起
2、人工活动模式
带人工活动的业务场景,人工活动的处理包括了任务项(workitem),涉及到单人,多人,抢单还是分配等模式,workitem自身也有状态,形成了3层状态机
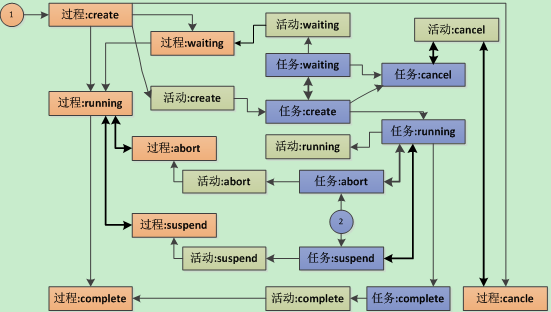
3、子流程模式
流程中定义了子流程的场景。设计时,子流程在父流程定义中用"子流程活动"来表达,子流程活动状态和子流程各个活动状态有相互影响,形成3层状态机。状态变迁和上图类似。
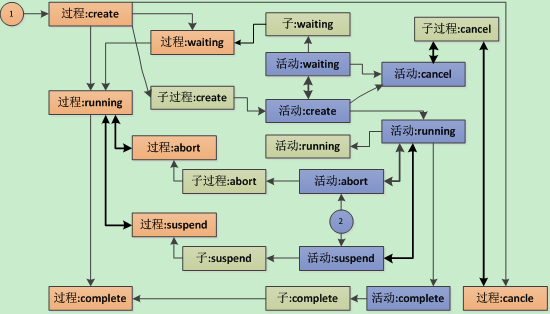
3.6、总结
本章节只是展示了人机交流的冰山一角,在开发过程中有很多琐碎的对话和交流,我在设想后续的开发是否可用vibe编程,尤其是openclaw出来后,从此收集信息,构造提示词,修改代码,测试验证,提交代码就可以自动完成。
4、收工
代码最后能在mvn package中尽数通过,心里还是蛮开心的,释放了一点久违的内啡肽。曾经就写过类似的代码,借鉴了ofbiz,shark,obe,带领了一个团队加班加点来实现。平心而论,我在多线程异步协同+锁方面有些偏弱,但LLM能在很短的时间内给出了最合适的答案,功能更完善、性能更强劲的版本只需要1名架构师和1个不知疲倦的LLM。
这些代码都是在deepseekv3.1,v3.2以及kimi2-think,kimi2.5上完成的。其实类似的工作在更早期的时候就开展了,包括项目工程代码往高版本迁移以及功能性能完善方面。但早期的LLM给出的代码,略显简略,质量不算完美,合并后的代码需要反复验证和调试,而且当时算力紧张,只有在下半夜到凌晨才能较好的交互。但当时就已经埋下一颗种子,觉得AI编程是可行而且势在必行。时至今日,该想法得到了真实的确认,只要架构把控得当,模块拆分合理,代码持续迭代,进度小步快跑,功能测试验证的方式下,任何人类可以想象到的复杂代码都可以实现。如果今天某个功能没有跑出来,没关系,休息会儿,也许明天LLM就会给你新的思路和尝试;如果当前LLM无法体现你的宏大设定,我觉得也没关系,给自己放个假,放松一下,下一步版本的LLM就可以实现。
在与 LLM 的深度交互中,我发现它的能力远不止写代码。通过提供精心标注的信息,AI 能在海量数据中寻找内在关联并预测趋势。例如去年在一建考试中,160分大约命中20分左右(算知识点),这种从代码生成到知识预测的延展,令人惊叹,对考题预测感兴趣的考友可以参考《一建备考的岁月征程》。
Workflow完成后将转向agent的开发,像OpenClaw这样的LLM+skills的应用,要在私域平台落地,还需要进一步打磨,以"LLM + agent-flow+工具箱+skills"的架构让把概率性生成模型与确定性流程编排相结合,构建可工程化、可信任的AI智能体。前路虽长,但规划已明,我坚信,即将到来的 DeepSeek V4 必将助力我实现所有的开发愿景。