一、AI Coding 现状与痛点:为什么需要 Harness
当前使用情况
得物离线数仓各小组已基本完成 AI Coding 工具的覆盖,主力工具为 Claude Code,辅以数据平台的 IDE 插件,应对重复性工作时效率提升明显。
核心痛点
尽管整体提效已显现,但团队在实际使用中暴露出三类结构性痛点。
痛点一:AI 不记得上下文约束,开发过程中反复"失忆"。会话开始时告知了"金额字段单位是千元",对话进行到一半后 AI 忘了,生成的 SQL 把千元当元用,导致数据差了 1000 倍。这不是偶发问题,而是 Claude Code 的 context compact 机制(上下文压缩)的系统性限制:当对话 token 接近上限(约 95%)时,历史内容被自动压缩为摘要,临时口头说的约束全部丢失。
痛点二:规范执行不稳定,靠记忆兜底的部分最容易出问题。OneData 命名规范、注释三段式、INSERT 必须带 PARTITION 子句......这些规范大家都知道。在项目工期紧张时,人工规范遵守率降至 60%~70%,AI 靠 prompt 记忆的规范遵守率也只有 70%~80%。真正需要的是:把规范从"LLM 记忆中的指导性内容"变成"每次执行时强制检查的护栏"。
痛点三:大型需求开发中,context 很快被撑满,越到后期 AI 越不可靠。复杂需求(大型宽表、大量下游血缘)的典型开发过程:
objectivec
血缘查询结果(500~3000 tokens) 自测 23 条 SQL 执行结果(5000~15000 tokens) SKILL 规范文件内容(~10000 tokens) 数据比对两表样本(大量行)= context 迅速膨胀 → compact 触发 → 关键约束遗忘 → AI 开始犯低级错误核心矛盾:越是复杂的需求,越依赖 AI;但越复杂的需求,context 越容易撑满,AI 越容易"失忆"。
从"随手问 AI"到"把能力封装起来"
针对上述痛点,我们沿用了一条反复验证的结论:规范执行是人的短板、AI 的长板;业务判断是 AI 的短板、人的长板。Harness 工程的目标,就是把"执行层"的不稳定因素系统性地消掉:把规范写进 hooks,不再靠 AI 记忆,每次写 SQL 文件后自动触发检查;把迭代约束写进持久化文件,compact 后自动重新注入,不再靠临时口头说;把高 token 操作隔离到 subagent,主 context 只接收摘要,不被过程数据撑满。
二、先搞清楚"Harness"是什么
在 Claude Code 的 update-config skill 描述中有一句话:"Automated behaviors require hooks configured in settings.json --- the harness executes these, not Claude"。
Harness = Claude Code 的宿主运行框架,即 Claude Code 客户端本身这个"工具链容器"。它:管理 context window 生命周期;在 LLM 推理循环之外确定性地执行 hooks;协调 subagents 的生命周期;不依赖模型判断,直接执行配置的自动化行为。区别总结:

三、核心问题:compact 到底丢掉什么?
每次数仓开发 context 接近满时,auto-compact 触发(默认 95% 时触发),会把整个对话历史替换为一份摘要,token 缩减到原来的约 12%。哪些内容 compact 后丢失:
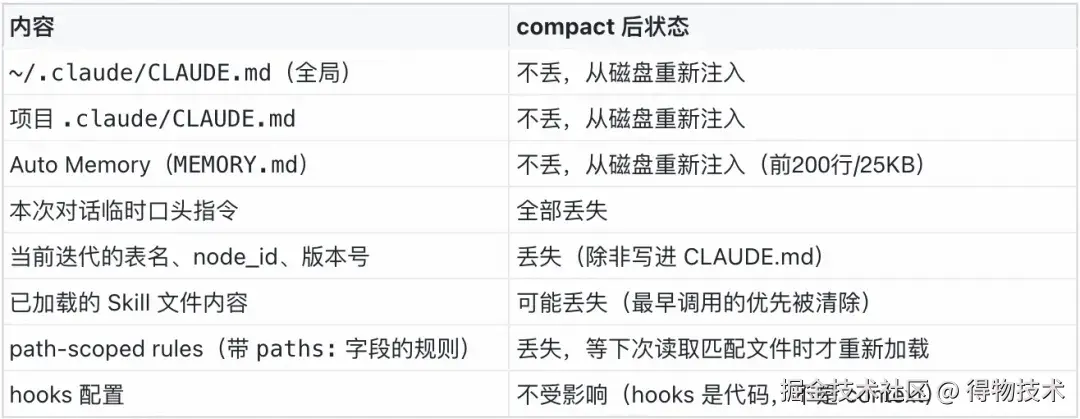
数仓场景最痛的点:对话中说的"这次用 OVERWRITE 模式"、"先忽略 field_a 字段" → compact 后全忘;SKILL 文件读了一半,compact 后前几个 step 的内容没了 → Claude 重复询问;自测跑出来 50 行结果,加上血缘查询的几十行表结构 → context 很快膨胀到 compact 阈值。
四、五层防御体系(从简单到复杂)
第一层:写死进 CLAUDE.md(立即可用)
机制:项目根目录 .claude/CLAUDE.md 每次 compact 后从磁盘重新注入,是最可靠的持久化位置。将当前迭代的关键信息写入,格式建议:
sql
# 当前迭代状态(每次迭代手动更新)## 正在开发- 表:db_a.dws_table_a
版本:V1.0
node_id:1000000001
状态:ETL开发阶段(Step 3/8)
## 本次迭代约束- 禁止修改:dwd_table_b(已上线,只读)
分区字段:partition_dt(格式 yyyyMMdd,不是 dt)
amount 字段单位:千元(不是元)
## 数仓全局规范
建表:分区字段必须是 partition_dt string
禁止:SELECT *,UPDATE/DELETE 无 WHERE
金额字段用 DECIMAL(20,4),不用 DOUBLE
INSERT 必须带 PARTITION 子句操作规则:进入新迭代时,更新"正在开发"和"本次迭代约束"两节;上线后清空"本次迭代约束";全局规范长期保留,控制在 100 行以内。
第二层:Auto Memory 自动积累(已在运行)
机制:Claude 自动将跨会话发现写入 ~/.claude/projects//memory/MEMORY.md,每次 compact 后重新注入。数仓场景下主动触发 Claude 写记忆的时机:"这张表的 amount 字段单位是千元,请记住";"field_a 在特定场景下会为空,请记住这个踩坑";"本次 V1.0 的关键变更是 field_b 逻辑调整,请记住"。Claude 会自动写入 MEMORY.md,下次会话或 compact 后自动恢复。
第三层:hooks 自动验证(核心防御,解决"忘了检查"的问题)
这是解决"每次写完 SQL 自动检查"的关键机制。
配置文件位置
markdown
数仓项目根目录/
└── .claude/
├── settings.json ← hooks 在这里配置
├── CLAUDE.md ← 数仓规范上下文
└── hooks/
├── validate_sql.sh ← SQL 规范自动检查
├── block_dangerous_ddl.sh ← 危险 DDL 拦截
└── inject_context.sh ← compact 后重注入上下文settings.json 完整配置
swift
{"hooks": {"PostToolUse": [{"matcher": "Write|Edit","hooks": [{"type": "command","command": "\"$CLAUDE_PROJECT_DIR\"/.claude/hooks/validate_sql.sh","timeout": 60,"statusMessage": "检查 SQL 规范..."}]}],"PreToolUse": [{"matcher": "Bash","hooks": [{"type": "command","command": "\"$CLAUDE_PROJECT_DIR\"/.claude/hooks/block_dangerous_ddl.sh"}]}],"SessionStart": [{"matcher": "compact","hooks": [{"type": "command","command": "cat \"$CLAUDE_PROJECT_DIR\"/.claude/context/dw_conventions.md","statusMessage": "重注入数仓规范..."}]}],"Stop": [{"hooks": [{"type": "prompt","prompt": "检查用户要求的所有任务是否都已完成。如果还有未完成项,返回提示但不要重新开始。检查 stop_hook_active 是否为 true,如是则直接 exit。","model": "claude-haiku-4-5-20251001"}]}]}}SQL 规范自动检查脚本
.claude/hooks/validate_sql.sh:
bash
#!/bin/bash
INPUT=$(cat)
FILE_PATH=$(echo"$INPUT" | python3 -c "import sys,json; d=json.load(sys.stdin); print(d.get('tool_input',{}).get('file_path',''))" 2>/dev/null)
# 只处理 .sql 文件
[[ "$FILE_PATH" != *.sql ]] && exit 0
[[ -z "$FILE_PATH" ]] && exit 0
SQL=$(cat "$FILE_PATH" 2>/dev/null)
[[ -z "$SQL" ]] && exit 0
ERRORS=()
# 规范1:禁止 SELECT *echo "$SQL" | grep -iqE 'SELECT\s+\*' && ERRORS+=("CRITICAL: 发现 SELECT *,必须明确列名")
# 规范2:INSERT 必须带 PARTITIONif echo "$SQL" | grep -iqE 'INSERT\s+(INTO|OVERWRITE)'; thenecho "$SQL" | grep -iqE 'PARTITION\s*\(' || ERRORS+=("CRITICAL: INSERT 缺少 PARTITION 子句")
fi# 规范3:DOUBLE 类型金额echo "$SQL" | grep -iqE '\bDOUBLE\b' && ERRORS+=("WARNING: 金额字段建议用 DECIMAL(20,4),不用 DOUBLE")
# 规范4:UPDATE/DELETE 必须有 WHEREif echo "$SQL" | grep -iqE '\b(UPDATE|DELETE)\b'; thenecho "$SQL" | grep -iqE '\bWHERE\b' || ERRORS+=("CRITICAL: UPDATE/DELETE 缺少 WHERE 条件")
fiif [ ${#ERRORS[@]} -gt 0 ]; thenecho "=== SQL 规范检查失败:$FILE_PATH ===" >&2
for err in"${ERRORS[@]}"; doecho " $err" >&2
doneexit 2
fiecho "SQL 规范检查通过: $(basename $FILE_PATH)" >&2
exit 0危险 DDL 拦截脚本
.claude/hooks/block_dangerous_ddl.sh:
bash
#!/bin/bash
INPUT=$(cat)
CMD=$(echo"$INPUT" | python3 -c "import sys,json; d=json.load(sys.stdin); print(d.get('tool_input',{}).get('command',''))" 2>/dev/null)
# 拦截生产表 DROP/TRUNCATE(放行 _dev/_test/_stg 后缀)if echo "$CMD" | grep -iqE '\b(DROP\s+TABLE|TRUNCATE\s+TABLE)\b'; thenif ! echo "$CMD" | grep -qiE '(_dev|_test|_stg)\b'; thenecho "BLOCKED: 检测到生产表 DROP/TRUNCATE 操作,请确认表名是否正确" >&2
exit 2
fifiexit 0hook 通信协议关键规则

关键陷阱:阻断必须用 exit 2,用 exit 1 不会阻止 Claude 继续执行。
第四层:subagents 做上下文隔离(防 context 膨胀)
核心原则:把"高 token 消耗但结果只需要摘要"的操作放到 subagent 的独立 context 中执行。
数仓场景适合下放 subagent 的操作

创建 subagent 文件
.claude/agents/sql-validator.md(SQL 语法验证):
yaml
---
name: sql-validator
description: ODPS/MaxCompute SQL 语法验证与规范检查专用 agent。当用户生成或修改 SQL 文件后需要验证时调用。在独立 context 运行,防止大量验证日志污染主对话。
tools: Read, Bash, Grep, Glob
model: haiku
permissionMode: dontAsk
---
你是数仓 SQL 规范专家,只做验证,不修改文件。
验证项(按优先级):
1. SELECT * 禁止
2. INSERT 必须带 PARTITION
3. 字段用 snake_case 命名
4. 金额字段用 DECIMAL 不用 DOUBLE
5. 多表 JOIN 必须有 ON 条件
6. 笛卡尔积风险检测
输出格式:
- 状态:PASS / FAIL
- 问题列表(CRITICAL / WARNING / INFO)
- 修改建议(具体到行号)
不超过 50 行,只返回结构化报告。.claude/agents/dw-explorer.md(防止血缘查询撑爆主 context):
yaml
---
name: dw-explorer
description: 数仓结构探索 agent。当需要大量读取表结构、DDL、字段信息、血缘关系时自动调用,避免大量文件内容污染主 context。只读,不修改任何文件。
tools: Read, Glob, Grep, Bash
model: haiku
permissionMode: dontAsk
---
你是数仓探索专家,只读操作。
当被调用时:
1. 读取指定表的 DDL、字段信息、分区策略
2. 分析上下游血缘(一层)
3. 识别关键字段口径(金额、日期、状态类字段)
输出:不超过 80 行的结构化摘要,包含:
- 表基本信息(层级、粒度、分区策略)
- 核心字段定义(含口径说明)
- 上下游血缘(只列表名,不展开内容)
- 发现的特殊口径或踩坑点使用方式
在主对话中自然触发:
sql
用 dw-explorer 分析 db_a.dwd_table_a 的结构
对刚生成的 insert_dws_table_a.sql 用 sql-validator 验证或强制指定(避免 Claude 自行判断):
lua
@"sql-validator (agent)" 验证 path/to/insert.sql第五层:SKILL 文件改造(减少 context 消耗)
当前的问题:每次调用 SKILL 文件(01~08.md),内容全部加载进主 context,加速 compact 触发。改造方向:把 SKILL 文件的"执行步骤"提炼成 subagent 指令,subagent 内部读完整 SKILL 文件,主 context 只接收结果摘要;用 path-scoped rules 替代 SKILL 文件中的规范章节,按需加载:
yaml
---
# .claude/rules/etl-rules.md
paths:
- "**/*insert*.sql"
- "**/*_di.sql"
- "**/*_df.sql"
---
# ETL 开发规范(按文件路径自动加载)
- 必须有 partition_dt 分区
- INSERT OVERWRITE 前检查分区是否已存在
- 不允许跨库 JOINSKILL 文件保持现状,但改变调用方式:不要在主对话中直接触发,而是启动一个 subagent 来读 SKILL 文件执行 ETL,主对话只接收最终产出的 SQL 文件路径。
五、可行落地方案:数仓 Harness 架构
先让我们看一下整体的架构设计(整体架构图):

这张架构图的核心逻辑是职责分层:不同类型的工作交给最合适的机制去做,而不是全部压在 Claude 的推理循环里。
持久化层解决的是"失忆"问题,任何临时口头说的约束,compact 后都会消失;但写进 .claude/CLAUDE.md 的内容,每次会话启动和 compact 后都会从磁盘重新注入------这是整套方案里最简单也最可靠的一层。
Harness 层(Hooks) 解决的是"规范靠记忆"的问题,PostToolUse hook 在每次写 .sql 文件后确定性触发,不依赖 Claude 有没有记住规范要求;违规时 exit 2 强制阻断,Claude 必须修正后才能继续,规范遵守率从 70%80% 提升到 95%+。
Subagent 层解决的是"context 被撑满"的问题,血缘查询、23 项自测、数据比对这类操作会产生大量 token,放到独立 context 的 subagent 里执行,主会话只接收一份摘要,compact 触发频率预计降低 50%70%。
三层机制分工明确,互不干扰:Hooks 处理"写动作触发的规范检查",subagent 处理"读操作的 context 隔离",CLAUDE.md 处理"跨会话状态持久化"。为了配合这套架构落地,数仓的研发流程可以拆解为 8 个大的步骤,流程图如下:

从 Harness 架构的视角来看,8 个步骤可以按"对 context 的影响"分成两类:一类是直接在主会话处理 (内容量有限,context 压力低):需求分析(读 PRD)、技术设计(写规范说明)、SR 导入(生成配置)、SLA/DQC(生成规则)。另一类必须通过 Harness 机制处理(否则会加速 compact 或规范失控):ETL 开发每次写 .sql 文件,PostToolUse hook 自动触发规范检查,不依赖人工提醒;自测时 23 条 SQL 的执行结果体量大,交给 data-quality-checker subagent 隔离,主会话只收 PASS/FAIL 摘要;数据比对时两表样本数据量大,交给 data-comparator subagent 隔离;性能优化时血缘 + 多层 DDL 每次 500~3000 tokens,交给 dw-explorer subagent 隔离。这种分工不是把步骤拆开独立执行,而是在同一个工作流里,让每个步骤以最合适的方式运行------context 压力小的步骤留在主会话保持流畅,context 压力大的步骤通过 subagent 隔离保持干净,规范检查通过 hook 自动执行不需要人工干预。
六、基于 SKILL 规范的数仓工作流设计
数仓 8 步 SKILL 规范(需求分析→技术设计→ETL→自测→数据比对→SR 导入→性能优化→SLA/DQC)天然对应 Harness 的三层机制。核心思路是:SKILL 文件不变,改变调用方式------主对话只读规范结论,实际执行由 subagent 或 hook 完成。
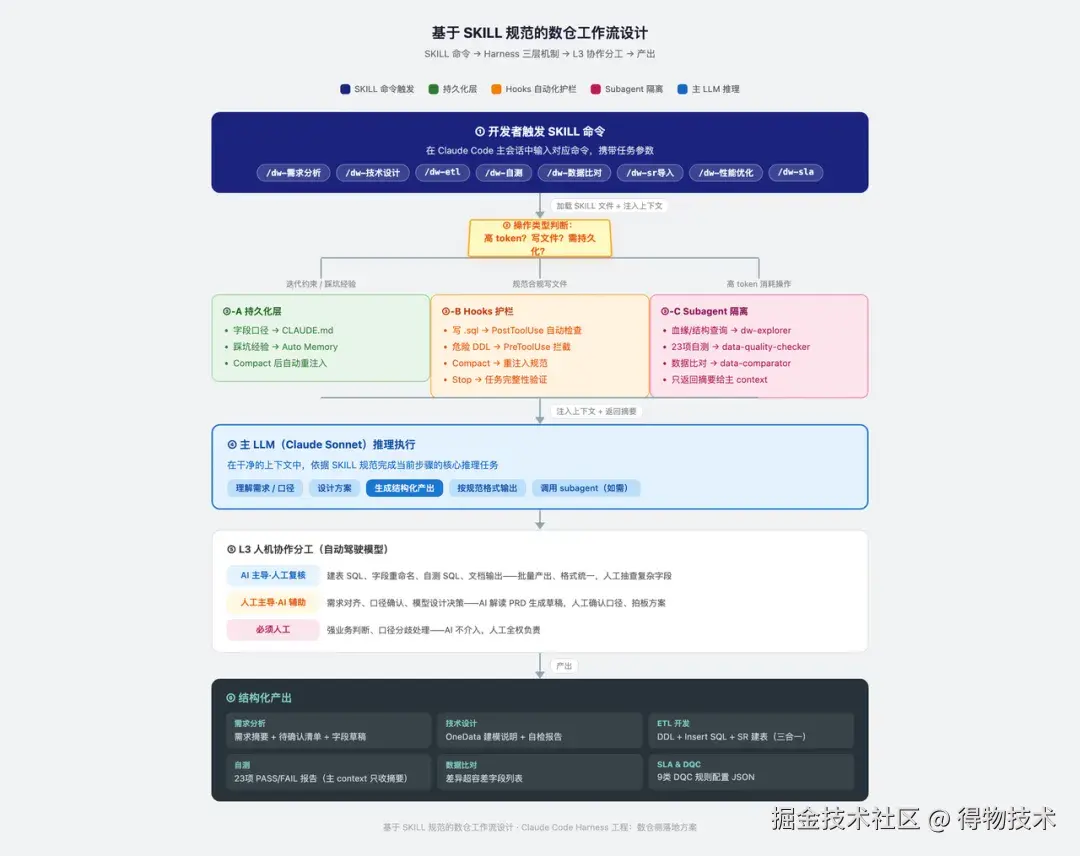
各步骤推荐提示词与工作流
Step 1:需求分析
推荐提示词:
markdown
用 dw-explorer subagent 先读取上游表结构(只返回摘要),
然后按需求分析规范生成:
1. 需求摘要(≤5行)
2. 表字段口径草稿
3. 待确认问题清单(按优先级排序)
需求文档 URL:[粘贴PRD链接]Hook 配合:SessionStart 注入当前迭代约束(版本号/表名/禁止修改的表)。
Step 2:技术设计
推荐提示词:
css
基于上一步确认的需求,按 OneData 规范完成技术设计:
表名:[按 层级_域_主题_粒度_周期 格式命名]
粒度:[描述]
分区:partition_dt string(格式 yyyyMMdd)
禁止:任何与上游不一致的字段命名
输出 OneData 建模说明,不超过 60 行CLAUDE.md 写入(设计完成后手动更新):
diff
## 当前迭代技术设计决策- 表名:db_a.dws_table_a
- 主键:order_no + partition_dt
- 特殊约束:amount 字段继承上游千元单位,不做转换Step 3:ETL 开发
这是 Harness 工程价值最高的步骤,PostToolUse hook 在每次 SQL 文件保存时自动触发。
推荐提示词:
sql
按 ETL 开发规范生成建表 DDL + Insert SQL:
- 建表文件:ddl_[表名].sql
- 插入文件:insert_[表名].sql
- 要求:INSERT 用 OVERWRITE 模式,PARTITION 子句必须包含 partition_dt
- 金额字段:DECIMAL(20,4),单位继承上游(千元)
生成完毕后,用 sql-validator subagent 验证两个文件Hook 自动执行(无需手动触发):每次写入 .sql 文件 → PostToolUse hook 自动运行规范检查。若发现 SELECT * 或缺少 PARTITION → 返回 exit 2,Claude 收到错误自动修正。
Step 4:自测
推荐提示词(防止自测结果撑爆主 context):
css
用 data-quality-checker subagent 对 [表名] 执行 23 项标准自测,
bizdate = [日期]
补充口径约束:[如"is_perform=1 只取履约订单"]
只返回:PASS/FAIL 汇总 + FAIL 项详情(≤50行),不返回原始 SQL 执行结果效果:23 条 SQL 的执行结果全在 subagent context 里,主对话只收到一份摘要报告。
Step 5:数据比对
推荐提示词:
ini
用 data-comparator subagent 对比:
新表:[新表名] partition_dt = [日期]
参考表:[旧表名/线上表]
比对字段:[核心金额字段列表]
容差:≤ 0.01%(金额类)
只返回:差异超过容差的字段列表 + 差值,不返回全量对比数据Step 6:SR数据库导入
推荐提示词(自动生成最优数据库建表参数):
markdown
用 dw-sr SKILL生成建表任务, 先查以下表的 DDL 和一层上下游血缘(只返回摘要):
- 源表:[ODPS表名]
- 目标表:[SR表名]
然后基于 DDL 摘要,分析当前 SR 同步任务的配置风险:
1. 字段类型是否有精度丢失风险(DECIMAL/DOUBLE → DECIMAL(38,18))
2. Key 字段选择是否合理(重复率是否过高导致 DUPLICATE KEY 膨胀)
3. 分区数量是否合理(partition_live_number 与下游查询窗口是否匹配)
4. DISTRIBUTED BY HASH 的 bucket 数与数据量是否匹配
5. 是否有 DATETIME 字段在 SR 侧用了 VARCHAR 存储(会导致时间过滤走全表扫描)
输出同步任务配置建议(按风险高低排序),不超过 20 行。
每条格式:[风险等级 高/中/低] 问题描述 → 建议修改方式Step 7:性能优化
推荐提示词(防止血缘查询撑爆主 context):
sql
用 dw-explorer subagent 先查 [表名] 的一层上下游血缘和 DDL(只返回摘要),
然后分析当前 Insert SQL 的性能瓶颈:
1. 是否有全表扫描
2. 是否有笛卡尔积风险
3. 是否可以用 MAP JOIN 替代 HASH JOIN
输出优化建议(按收益排序),不超过 30 行Step 8:SLA/DQC
推荐提示词:
css
按 SLA/DQC 规范为 [表名] 生成 9 类 DQC 规则:
完整性:主键非空、分区数据量
准确性:核心金额字段与上游比对(容差 0.01%)
一致性:is_perform 与 perform_flag 联动逻辑
时效性:产出时间 SLA ≤ 次日 8:00
输出 DQC 配置 JSON,可直接使用SKILL 调用方式改造(减少主 context 消耗)
当前问题:触发 SKILL 时,SKILL 文件全文(约 10KB)加载进主 context,加速 compact。改造方向:

核心原则:主对话只接收决策级信息(PASS/FAIL、差异字段、优化方案),不接收过程数据(SQL 执行结果、原始血缘列表、完整 DDL 内容)。
精准对话流设计:控制AI思考的艺术
文章中多次提到 /dw-etl、/dw-自测 等命令,这是数仓研发全流程 SKILL 套件的核心触发词,每个命令对应一个封装了规范、产出格式和工具调用的标准化执行单元。核心理念:把每次都要重复讲的要求写进 SKILL,把每次都怕忘的检查点写进 SKILL,把每次都需要的结构化输出也写进 SKILL------这样谁来做需求都行,底座是一致的。
8 个 SKILL 命令一览

以 /dw-etl 为例:一条命令封装了什么?ETL 开发(Step 3)是 Harness 工程价值最高的步骤,SKILL 文件内封装了:① 规范内容(写死,不靠记忆):建表规范:分区字段必须是 partition_dt STRING(格式 YYYYMMDD);金额字段:DECIMAL(26,4),不用 DOUBLE;INSERT 模式:必须使用 INSERT OVERWRITE,必须带 PARTITION 子句;禁止:SELECT *、跨库 JOIN(非血缘关系)。② 产出格式(结构化,不走样):
sql
输出文件:
├── ddl_[表名].sql ← ODPS 建表语句(含注释三段式、生命周期配置)
├── insert_[表名].sql ← ODPS Insert SQL(含分区裁剪、JOIN 规范)
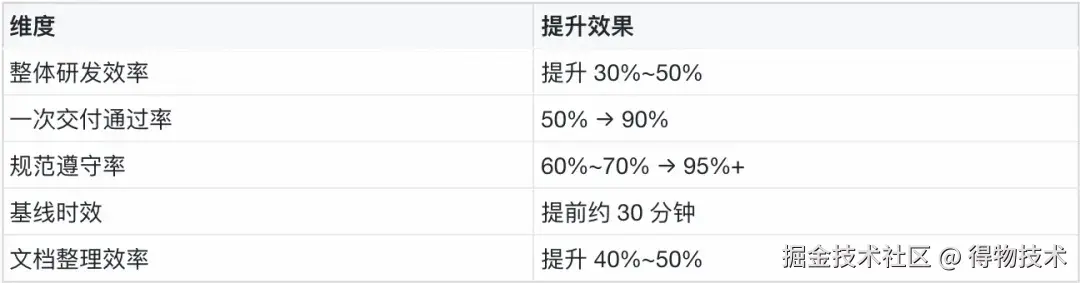
└── ddl_sr_[表名].sql ← SR 建表语句(Key 列顺序、DECIMAL 精度)③ 自动护栏(Hook 配合):每次 .sql 文件写入后,PostToolUse hook 自动执行 validate_sql.sh;发现 SELECT * 或缺少 PARTITION → exit 2 阻断,Claude 强制修正。④ subagent 卸载(防 context 膨胀):"生成完毕后,用 sql-validator subagent 验证两个文件";验证结果全在 subagent context 里,主对话只收到"PASS/FAIL + 问题列表"。综合效益数据:
七、落地步骤
步骤一:项目级上下文持久化。在数仓项目目录下创建 .claude/CLAUDE.md,写入当前迭代状态。每次新迭代开始时更新"正在开发"和"本次迭代约束"两节,上线后清空约束节。全局规范永久保留,控制在 100 行以内。
步骤二:配置 hooks 自动验证。创建 .claude/settings.json + hooks/ 目录,配置 PostToolUse hook(每次写 .sql 后自动规范检查)和 PreToolUse hook(拦截危险 DDL)。效果:不需要每次手动说"帮我检查 SQL 规范",hook 在 Harness 层自动触发,不占用 Claude 推理资源。
步骤三:创建 subagents 隔离高 token 操作。创建三个核心 subagent 文件:sql-validator.md、dw-explorer.md、data-quality-checker.md。将 Step 4/5/7 的执行全部下放,预计主 context compact 频率降低 50%~70%。
八、Harness 工程能解决的核心问题
这一节是整个方案的出发点,也是对"为什么要这么做"的直接回答。
数仓 AI 开发当前的本质瓶颈:语义理解
在实际数仓 AI 开发中,技术能力不是瓶颈,语义理解才是。需求理解偏差占总返工的 40%~60%,大约 40%~50% 的工作时间花在理解需求和与业务核对口径上。精准血缘探查:准确率提升显著,远超传统方式。这两个观察揭示了同一个问题:AI 在数仓场景的不准确,根本原因不是"不会写 SQL",而是"不理解业务语义"------不知道这张表的 amount 单位是千元还是元,不知道 is_perform=1 在这个版本里意味着什么,不知道某字段在特定场景下会为空。
语义 × 数据 = 准确率
数仓 AI 开发的准确率,可以用一个公式来理解:
准确率 = 语义理解深度 × 数据规范覆盖度
结论:Harness 工程的本质,是把"语义"和"规范"从不可靠的 LLM 记忆中,迁移到确定性的 hooks + 持久化文件里,从而让 语义 × 规范 = 准确率 这个等式两边的变量都变得稳定。
具体能解决的四类问题
问题一:字段口径遗忘导致的计算错误
现状:对话开始时告知了"amount 字段单位是千元",compact 后 Claude 忘了,生成的 SQL 把千元当元用,导致数据差 1000 倍。Harness 解法:字段口径写进 .claude/CLAUDE.md(compact 后重新注入);踩坑经验写进 Auto Memory(跨会话持久化);结果:这类错误从"时常发生"降到"基本不出现"。
问题二:需求理解偏差导致的返工
现状:需求文档描述的是"用户视角的 GMV",但 AI 生成了"交易视角的 GMV",两者口径不同,数据对不上,需要返工。Harness 解法:需求分析的产出(口径草稿 + 待确认问题清单)写进 CLAUDE.md 的迭代约束节;Stop hook 检查任务完整性,确认待确认问题清单已全部明确后才放行;结果:需求一次交付通过率从约 50% 提升到 90%。
问题三:SQL 规范执行不一致
现状:规范文档写了"INSERT 必须带 PARTITION",但 Claude 有时会忘,或在 compact 后规范内容被清除后生成不合规的 SQL。Harness 解法:PostToolUse hook 在每次写 .sql 文件后自动执行规范检查,不依赖 Claude 记忆;违规时 exit 2 返回错误,Claude 强制修正后才能继续;结果:规范执行率从"依赖 LLM 记忆的 70%~80%"提升到"hook 强制的 95%+"。
问题四:大型需求开发中的 context 耗尽
现状:复杂需求(大型宽表、大量下游血缘)开发过程中,血缘查询 + 自测结果 + SKILL 文件内容堆满 context,compact 触发后丢失关键约束,Claude 开始犯低级错误。Harness 解法:血缘查询 → dw-explorer subagent(独立 context,只返回摘要);23 项自测 → data-quality-checker subagent(独立 context,只返回 PASS/FAIL 报告);SKILL 文件内容 → subagent 内部读取,主 context 只接收产出的 SQL 文件路径;结果:主 context compact 频率预计降低 50%~70%。
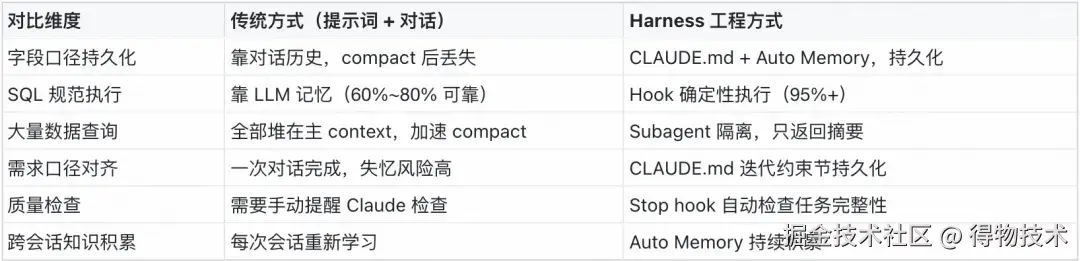
与传统数仓 AI 开发方式的对比
从"AI 帮我写代码"到"AI 嵌入研发流水线"
Harness 工程的最终目标,不是让 Claude 更聪明,而是让整个研发流水线更可靠。Claude(LLM)负责:理解需求、设计方案、生成代码------这些需要语义理解的事;Harness(hooks)负责:规范检查、危险拦截、任务完整性验证------这些需要确定性执行的事;Subagents 负责:大量文件读取、血缘查询、自测执行------这些会消耗大量 context 的事;CLAUDE.md + Memory 负责:字段口径、迭代约束、踩坑经验------这些需要跨会话持久化的事。这四层分工,让数仓 AI 开发从"对话驱动的一次性辅助"升级为"规则嵌入的流水线自动化"。
往期回顾
1.BP Claw 破解 AI 编码输入难题 ------FlinkSpec 需求智能化实践|得物技术
2.基于 Harness + SDD + 多仓管理模式的 AI 全栈开发实践|得物技术
3.通用 AI Agent 驱动网关路由安全审计实践|得物技术
文 /丹克
关注得物技术,每周三更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。