Spark sql
资源调优
spark的资源分配粒度最小是container,就是一个executor带的cpu和内存资源。资源的申请和移除都是通过executor进程的增加和减少达成。
Executor
executor的参数影响了cpu的内存资源的分配,通过设置executor的参数,可以调节实际处理的并行度。资源最高并行度=executor num*executor core*vcore ratio
task数量 = partition 数量
|-------------------------|---------------------|
| 参数 | 描述 |
| spark.executor.cross | 每个executor的cpu核数 |
| spark.vcore.boost.ratio | vcore,虚拟核数。提高cpu利用率 |
静态分配
|--------------------------|-----------------|
| 参数 | 描述 |
| spark.executor.instances | 静态资源下的executor数 |
动态分配
当任务资源最高并发<Task数量时,会根据参数配置向yarn申请新的executor;
当任务资源最高并发 > Task 数量时,会根据参数配置释放的executor;
|-------------------------------------------------|-----------------------------|
| 参数 | 描述 |
| spark.dynamicAllocation.enabled | 动态资源开关 |
| spark.dynamicAllocation.initialExecutor | 初始化时启用的executor的个数 |
| spark.dynamicAllocation.minExecutors | 最少分配的executor的个数 |
| spark.dynamicAllocation.maxExecutors | 最大可分配的executor的个数 |
| spark.dynamicAllocation.executorIdleTimeout | executor的空闲回收时间 |
| spark.dynamicAllocation.schedulerBacklogTimeout | 启动新executor,未分配的task等待分配的时间 |
Task数量
不可切割文件,partition数量为文件数
|-----------------------------------|----------------------------------|
| 参数 | 描述 |
| spark.sql.files.maxPartitionBytes | 读取可切分文件时,每个Partition / Split的最大值 |
| spark.sql.shuffle.partitions | Reduce 后partition 数量 |
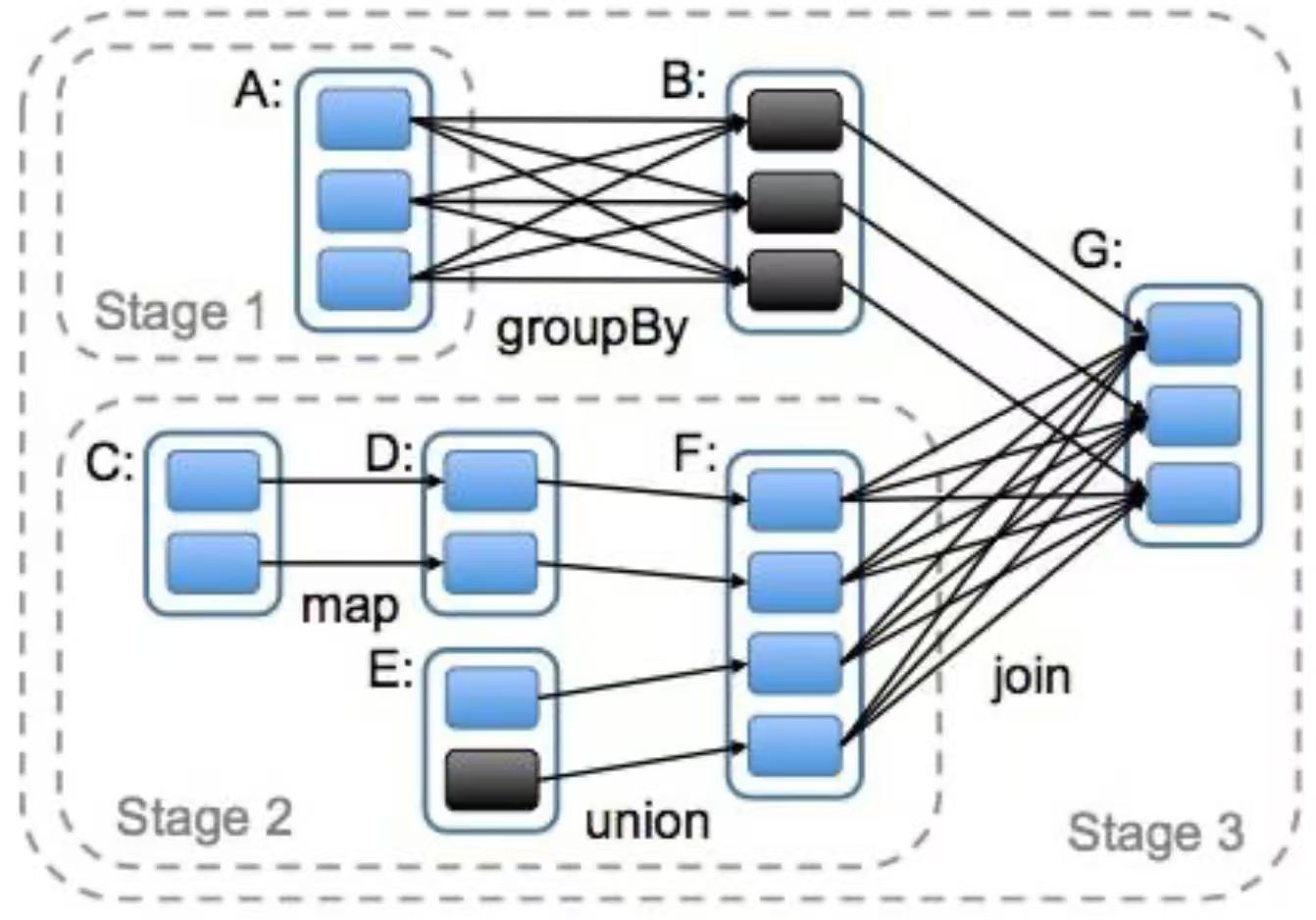
区分:application, job,stage, task
-
Application:初始化一个 SparkContext 即生成一个 Application
-
Job:一个 Action 算子就会生成一个 Job
-
Stage: 遇到一个宽依赖划分一个 Stage。
-
Task: Stage 是一个 TaskSet,将 Stage 划分的结果发送到不同的 Executor 执行即为一个
Task。
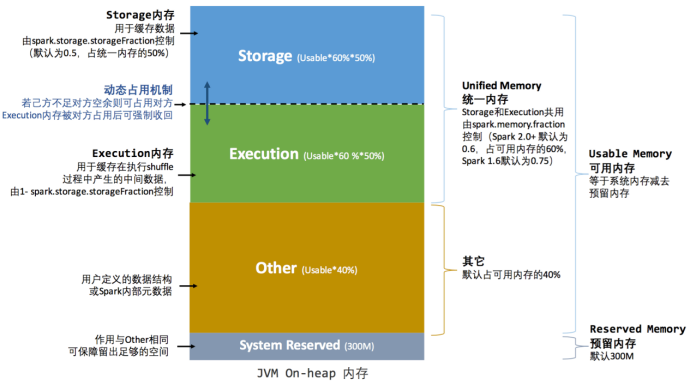
堆内内存
- 存储内存:缓存 RDD 和 Broadcast变量
- 执行内存:Shuffle 数据
- other:用户定义的数据结构
- System Reserved: 保留内存防止OOM,(非序列化对象周期采样估算,JVM回收延迟)
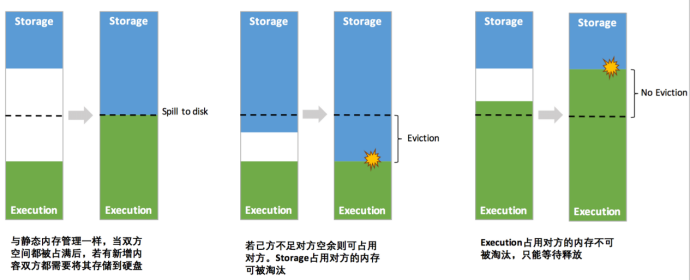
动态内存管理
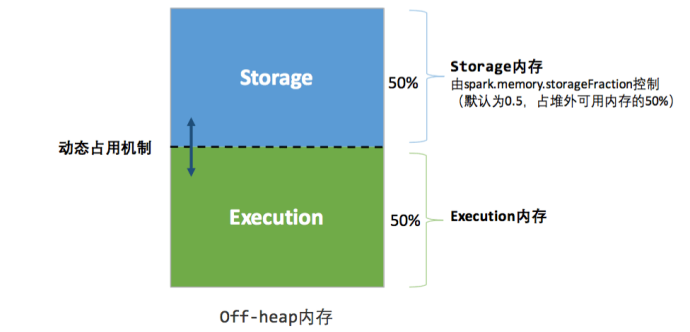
堆外内存
提高 Shuffle 时排序的效率,优化内存使用,减少垃圾回收对应用的影响。
堆外内存可以被精确地申请和释放,所以相比堆内内存来说降低了管理的难度,也降低了误差
Adaptive Query Execution
Spark 3.0 接入了 AQE,可以根据执行过程中的中间数据优化后续执行,从而提高整体执行效率。核心在于两点
- 执行计划可动态调整
- 调整的依据是中间结果的精确统计信息
|----------------------------|----------------------|
| 参数 | 描述 |
| spark.sql.adaptive.enabled | Adaptive execution开关 |
Reduce task 数量控制
未开启AQE,由spark.sql.shuffle.partition 参数控制,控制所有阶段的reduce个数,
开启后 reduce partition的数量初始切分为maxNumPostShufflePartitions,根据配置的targetPostShuffleInputSize大小,对于小文件map端的partition进行合并。并限制分区个数不少于minNumPostShufflePartitions
|-------------------------------------------------------|-------------------------------------------------------|
| 参数 | 描述 |
| spark.sql.adaptive.minNumPostShufflePartitions | reduce个数区间最小值,为了防止分区数过小 |
| spark.sql.adaptive.maxNumPostShufflePartitions | reduce个数区间最大值,同时也是shuffle分区数的初始值 |
| spark.sql.adaptive.shuffle.targetPostShuffleInputSize | 动态合并reducer的partition。map端多个partition 合并后数据阈值,小于阈值会合并 |
Map join 触发限制
未开启AQE 由spark.sql.autoBroadcastJoinThreshold 参数限制,缺点是从application执行一开始就确定,由于数据统计信息的缺失或不准确,或者是过滤条件的影响会导致最开始的估算不准确,导致执行的计划不是最优计划。
开启AQE之后,在join前会根据准确的上游数据来指定执行计划。
|------------------------------------------|-------------------------------------|
| 参数 | 描述 |
| spark.sql.adaptive.join.enabled | 自动转换sortMergeJoin到broadcast join 开关 |
| spark.sql.adaptiveBroadcastJoinThreshold | 将sortMergeJoin转换成broadcast join 阈值 |
Hash join 触发限制
|-------------------------------------|---------------------------------------|
| 参数 | 描述 |
| spark.sql.adaptive.hashJoin.enabled | 自动转换sortMergeJoin到ShuffledHashJoin 开关 |
| spark.sql.adaptiveHashJoinThreshold | 将sortMergeJoin转换成ShuffledHashJoin 阈值 |
数据倾斜优化
可解决 Join 时数据倾斜问题,根据预先的配置在作业运行过程中自动检测是否出现倾斜,并对倾斜的partition进行拆分由多个task来进行处理,最后通过union进行结果合并。
满足倍数限制且满足(大小限制 或者 条数限制 )才会被当做倾斜的partition处理
|-----------------------------------------------------|---------------------------------|
| 参数 | 描述 |
| spark.sql.adaptive.skewedJoin.enabled | 倾斜处理开关 |
| spark.sql.adaptive.skewedPartitionFactor | 倾斜的partition/同一stage的中位数 不能小于该值 |
| spark.sql.adaptive.skewedPartitionSizeThreshold | 倾斜的partition大小不能小于该值 |
| spark.sql.adaptive.skewedPartitionRowCountThreshold | 倾斜的partition条数不能小于该值 |
| spark.sql.adaptive.skewedPartitionMaxSplits | 被判定为数据倾斜后最多会被拆分成的份数 |
Join调优
多种join的差别
Broadcast Join
适用:大表join极小表
限制:
- 对广播的表大小有比较大的限制。见 Map join 触发限制
- 对driver和executor的内存、带宽等资源增加压力
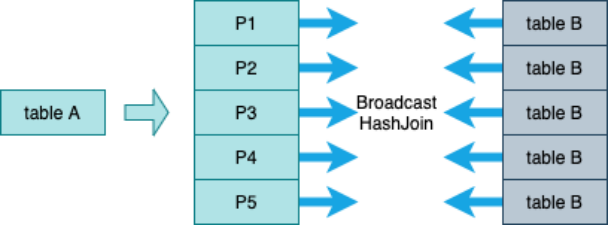
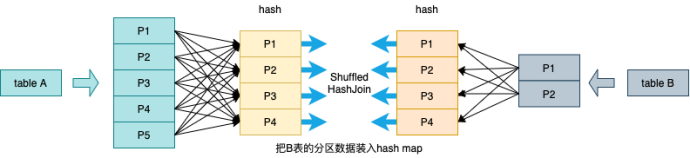
Shuffle Hash Join
适用:大表join小表
限制:
- spark.sql.join.preferSortMergeJoin = false(默认是true)
- 每个分区的平均大小不超过BroadcastJoinThreshold限制
- 大表大小 > 3*小表大小
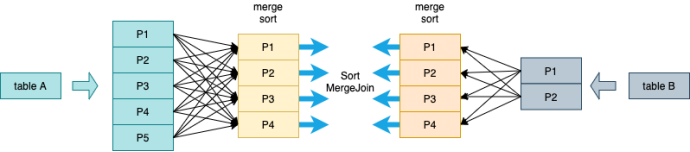
Sort Merge Join
适用:大表join大表
Bucket join

优点:
- 根据bucket key(或超集)进行 join、group by, 不会进行shuffle操作
- 可兼容历史数据,根据修改时间的后一天作为bucket起始分区,之前的分区还是被视为非bucket
- 可修改分桶数量
- 提升压缩比
- 提升过滤速度
限制:
- 两张表必须分bucket
- 两张表的bucket是倍数关系
- Bucket key要与join\group key相等或者是子集
- 不支持full join 写消除
- 在写入bucket表的执行计划的最后一个节点按照分桶key join/group by 才能消除shuffle操作
|------------------------------------------|--------------------------------|
| 参数 | 描述 |
| spark.sql.sources.bucketing.enabled | 是否开启bucket |
| spark.sql.bucket.multiple.enable | 是否开启一对多bucket join |
| spark.sql.bucket.supportSuperSetEnabled | 是否支持join key set是bucket key的超集 |
| spark.sql.bucket.writingExchangeOptimize | 优化写bucket表带来的额外shuffle |
场景
大表join小表
采用map join。可以适当增加broadcast的存储限制,加大executor和driver内存
采用hash join。
大表join大表
提前过滤
如果A表left join B表。主表A只有少量的key在B表中,可以提前把A表的key聚合,广播到B表。预先过滤B表无用数据。
采用Bucket join
数据倾斜调优
表现
部分task执行非常慢,或者报OOM错误
解决方案
- spark 3.0 可以开启AE的数据倾斜优化判断这些key是不是可以提前过滤掉
- 小表改成map join去除shuffle
- 增加reduce并行度,减少shuffle后每个task的数据量,适用于有较多 key 对应的数据量都比较大的情况,一定情况下可以缓解数据倾斜,但是浪费资源
- 将聚合分为两步,a. 将key加前缀打散后分散到多个task上做聚合,b. 再去除随机值聚合
- 将数据拆成两份,找到倾斜的key,对这些key单独加盐按照5处理之后,在union其他非倾斜数据的聚合结果
其他调优
本地化调优
本地化级别
|---------------|----------------------------------------------------------------|
| 名称 | 解析 |
| PROCESS_LOCAL | 进程本地化,task 和数据在同一个Executor 中 |
| NODE_LOCAL | 节点本地化,task 和数据在同一个节点中,但是 task 和数据不在同一个 Executor中,数据需要在进程间进行传输。 |
| RACK_LOCAL | 机架本地化,task 和数据在同一个机架的两个节点上,数据需要通过网络在节点之间进行传输。 |
| NO_PREF | 对于 task 来说,从哪里获取都一样,没有好坏之分。 |
| ANY | task 和数据可以在集群的任何地方,而且不在一个机架中,性能最差。 |
|---------------------|---------|
| 参数 | 描述 |
| spark.locality.wait | 本地化等待时长 |
Driver 会对每一个 stage 的 task 进行分配,从最优节点开始分配,超过等待阈值,会自动降级到下个本地化级别。对于shuffle大的任务,为减少网络传输,可适当调节等待时长。
Shuffle调优
|--------------------------------|-------------------|
| 参数 | 描述 |
| spark.shuffle.io.maxRetries | reduce 端拉取数据重试次数 |
| spark.shuffle.io.retryWait | reduce 端拉取数据时间间隔 |
| spark.shuffle.hdfs.enabled | map 端开启双写 |
| spark.shuffle.hdfs.replication | 写hdfs的副本数 |
| spark.shuffle.file.buffer | map 端拉取数据缓冲区大小 |
| spark.reducer.maxSizeInFlight | reduce 端拉取数据缓冲区大小 |
GC导致shuffle 文件拉取失败
执行 GC 会导致 Executor 内所有的工作,可以适当调节大maxRetries和retryWait
长任务,shuffle量大的任务,FetchFailedException 报错
建议开启spark.shuffle.hdfs.enabled,默认shuffle中map端只存储数据到本地磁盘上,当IO和CPU满载时,会导致reducer从map端拉取数据失败。
将mapper存储到本地shuffle数据多存储一份到HDFS上,当reducer获取不到shuffle数据时,会从HDFS拉取
可适当调大 spark.shuffle.hdfs.replication
Map 端处理大量数据
调节shuffle.file.buffer,来调大map端缓冲区大小,避免频繁的磁盘IO操作。
Reduce 端处理大量数据
如果内存资源较为充足,适当增加reducer.maxSizeInFlight,来增加拉取数据缓冲区的大小,可以减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能
实际优化案例
边缘日志大文件优化案例
限定统一的cpu和内存资源的情况下,优化大文件的处理速度并减小存储压力
Spark 3.0
spark.dynamicAllocation.enabled = false;
spark.executor.instances = 1;
spark.executor.cores = 3;
实验结果
|----|----------|-------|-----|-------------------------|---------|-----------------------|----------|------------|----------|-----------|----------|--------|
| 编号 | 压缩格式 | 文件大小 | 可切割 | spark.vcore.boost.ratio | Task 数量 | spark.executor.memory | 资源的最高并行度 | Task 耗时中位数 | GC耗时 中位数 | 读入文件大小中位数 | 读取耗时 中位数 | 总耗时 |
| 1 | gz | 6.2 G | no | 1 | 1 | 10g | 3 | 5.8min | 7s | 6.2 G | 2.8min | 5.8min |
| 2 | txt | 18.4G | yes | 1 | 37 | 10g | 3 | 7s | 0.1s | 512M | 2s | 2min |
| 3 | zstd | 5.2 G | no | 1 | 1 | 10g | 3 | 3.4min | 5s | 5.2 G | 1.4min | 3.4min |
| 4 | 4mz | 5.4 G | yes | 1 | 11 | 10g | 3 | 31s | 1s | 513 MB | 19s | 2.2min |
| 5 | 4mz | 5.4 G | yes | 4 | 11 | 10g | 12 | 34s | 2s | 513MB | 19s | 37s |
| 6 | 4mz | 5.4 G | yes | 4 | 11 | 4g | 12 | 2.5min | 1.6min | 513MB | 1.4min | 2.5min |
同样的资源,从耗时上来看测试5相较于1,性能有10倍的提升,并且存储也降低了12%
总结:
- 采取合适的文件压缩格式,采用可切割文件格式,可提高任务执行效率同时减少存储压力。
- 在内存充足的情况下可以适当调节vcore
- 调节vcore如果内存资源不够,会导致GC压力过大,反而执行效率会退化
Bucket join 优化案例
A表5.6T,B表635M,两表根据多个字段join,ABjoin的压力在于A表的shuffle耗时.
set spark.sql.adaptive.maxNumPostShufflePartitions=10000;
set spark.executor.memory=10g;
set spark.dynamicAllocation.maxExecutors=1000;
|----|-----------------|-----------------|------------|--------|------------------|------------|--------------------------------|----------------|-----------------|
| ID | #左表bucket\size | #右表bucket\size | 左表是否先group | 总耗时 | 总stage数量 | #Join task | Join Median input/Shuffle Read | Join Median GC | Median Duration |
| 1 | 无\5.6T | 无\635M | 有 | 1h4min | 4 (1r+1r+1gj+1i) | 10000 | 0/1.3 GiB | 1.1min | 17min |
| 2 | 5000\2.8T | 1000\635M | 有 | 1h6min | 3 (1r+1rgj+1i) | 5000 | 541M/208K | 3min | 28 min |
| 3 | 5000\2.8T | 5000\693M | 有 | 1h7min | 2 (1rrgj+1i) | 5000 | 541M/0 | 2.7min | 28min |
| 4 | 20000\2.9T | 20000\711M | 有 | 40min | 2 (1rrgj+1i) | 20000 | 136M/0 | 43 s | 6min |
| 5 | 20000\2.9T | 20000\711M | 无 | 18min | 2 (1rrgj+1i) | 20000 | 136M/0 | 10 s | 2.6min |
对比1和4,从普通join转为bucket join,耗时优化了37%,大表存储优化了48%
对比4和5,如果减少了大表的一次group操作,耗时优化了50%
总结:
- 对大表分bucket可以进一步提高压缩率,但是对小表分bucket由于会增加大量小文件,未最大化压缩收益,反而可能会减低压缩率
- 要设置合理的bucket数量,提高任务运行的并行度
- 在开始调优之前,先分析sql是否可以优化。优化sql带来的性能提升效率可能大于调参优化
通过增加资源提高运行效率案例
set spark.sql.adaptive.maxNumPostShufflePartitions=3000;
set spark.dynamicAllocation.maxExecutors=250;

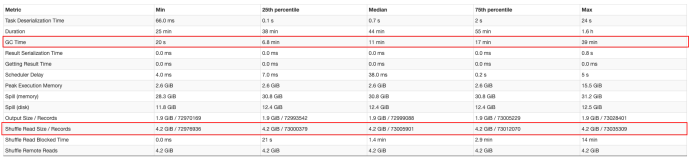
set spark.sql.adaptive.maxNumPostShufflePartitions=10000;
set spark.dynamicAllocation.maxExecutors=1000;

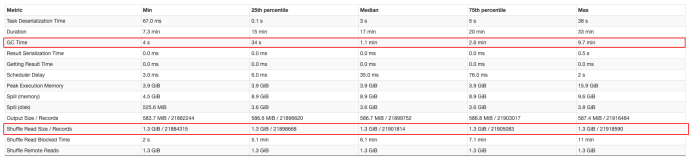
运行耗时减少了近65%
总结:
- 合理的调节Reduce 的partition数量可以提升运行效率
- 在资源满足要求以及任务数多的情况下可以增加cpu资源来提升运行并行度
减少资源浪费率案例
任务资源初始使用图如下,可见输入表为大表,但是reduce操作之后数据量有非常显著下降
set spark.shuffle.hdfs.enabled=true;
set spark.sql.adaptive.maxNumPostShufflePartitions=3000;
set spark.executor.memory=10g
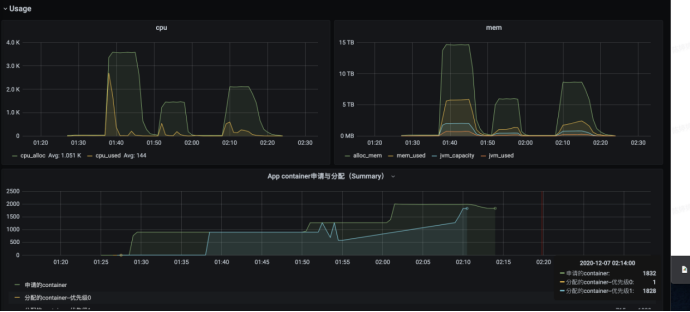
优化后参数
set spark.shuffle.hdfs.enabled=true;
set spark.executor.memory=8g;
set spark.dynamicAllocation.executorIdleTimeout=30;
set spark.dynamicAllocation.maxExecutors=250;
set spark.sql.adaptive.maxNumPostShufflePartitions=500;
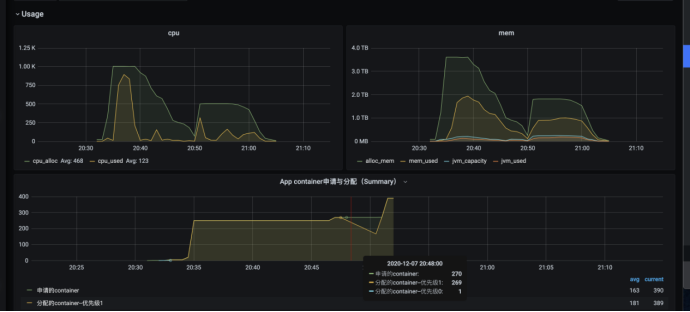
优化后总cpu浪费下降3倍
总结:
- Partition 的数据不是越多越好,太多的小文件也会影响运行效率并且浪费资源
- 可以适当减少executor空闲回收时间,加快资源释放
- 可以通过限制maxExecutors数量来控制最高并行度,减少无效的executor申请,提高资源使用率
异常排查
- Error log 写磁盘超过6G失败
日志目录占用磁盘空间过大杀死,检查stderr是哪个function在写错误日志

2.内存使用超出限制
可加大堆外内存,和增加partition数量
ExecutorLostFailure (executor 185 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding physical memory limits. 10.0 GB of 10 GB physical memory used. Consider boosting spark.executor.memoryOverhead.
3.不同队列或者平台跑相同任务,运行情况不一样
不同队列或者平台的默认参数会有些不同导致任务运行情况不一样。