自然语言处理概要
The Chief Introduction to Natural Language Processing (NLP)
By Jackson@ML
0 序言
翻遍身边的图书,无论是图书馆馆藏著作,还是新华书店售卖的书籍,都会发现关于自然语言处理的书籍不少,但是,能够让人眼前一亮的书籍,则寥寥无几。
很多优秀图书,要么侧重于算法和公式,让人一看便望而却步;要么,一大堆代码,使人感觉形同鸡肋,不知道该如何入手。
本文抛砖引玉,从人们平常最多接触的语言开始,以自然语言的角度,来一步步揭开神秘面纱,使得自然语言处理看起来不那么深奥、不再那么难懂,也不再那么遥远。系列文章陆续推出,希望对您有所帮助。
自然语言处理(NLP)概要:从理论到智能体实践
目录
- 语言及其基本模块
- 真实世界的自然语言处理
- 自然语言处理的任务
- 自然语言处理的困难和挑战
- 自然语言处理的方法
- 自然语言处理的工具
- 自然语言处理的演练:利用智能体
1. 语言及其基本模块
自然语言处理(Natural Language Processing, 简称NLP) 是计算机科学、人工智能和语言学的交叉领域,致力于使计算机能够理解、解释和生成人类语言。要理解NLP,首先需要理解语言本身的层次结构。
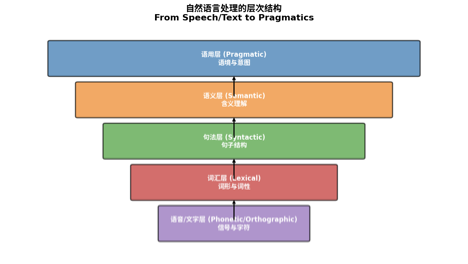
如上图所示,语言的五个基本模块构成金字塔结构,主要有以下层次:
1.1 语音/文字层(Phonetic/Orthographic)
• 定义:语言的最底层物理表现形式,包括语音信号或文字符号。
• 处理任务:包括语音识别(Speech-to-Text)、光学字符识别(OCR)、拼写检查。
• 示例:将声波信号转换为文字"Hello",或识别手写体汉字。
1.2 词汇层(Lexical)
• 定义:词汇的基本单元及其形态特征。
• 处理任务:包括分词(Tokenization)、词性标注(POS Tagging)、词形还原(Lemmatization)。
• 示例:"Running" → 词干"run" + 词性"动词现在分词"。
1.3 句法层(Syntactic)
• 定义:词汇如何组合成合法句子的结构规则。
• 处理任务:句法分析(Parsing)、依存关系分析(Dependency Parsing)。
• 示例:分析"猫捉老鼠"的主谓宾结构(猫主语 捉谓语 老鼠宾语)。
1.4 语义层(Semantic)
• 定义:语言表达的实际含义,超越字面理解。
• 处理任务:语义角色标注、词义消歧(WSD)、语义相似度计算。
• 示例:理解"银行"在"河边" vs "金融"语境下的不同含义。
1.5 语用层(Pragmatic)
• 定义:语言在特定语境中的使用效果和言外之意。
• 处理任务:对话管理、意图识别、情感分析、指代消解。
• 示例:理解"这房间真冷"可能是要求关窗或调高空调,而非单纯陈述温度。
理论基础:NLP的发展深受乔姆斯基生成语法和系统功能语言学影响。现代NLP系统通常采用"由下至上"(Bottom-up)和"由上至下"(Top-down)相结合的处理策略。
2. 真实世界的自然语言处理
自然语言处理(NLP)技术已渗透到各行各业。根据最新的行业调研信息,以下是近年来最具代表性的一些应用案例:
2.1 通用应用领域
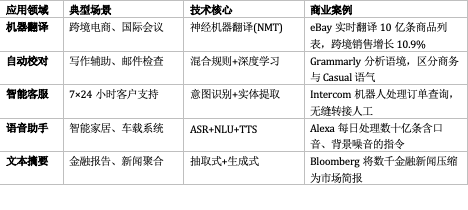
2.2 垂直行业深度应用
自然语言处理在多个行业领域存在不同的深度应用。
医疗健康
• 临床文档处理:Dragon Medical One实现99%医学术语识别准确率,55万医生使用。
• 临床试验匹配:Mayo Clinic利用NLP分析非结构化病历,识别适合临床试验的患者。
• 计算表型:Vanderbilt大学分析280万份临床笔记,发现新的疾病表型关联。
金融服务
• 风险评估:通过分析财报电话会议、分析师报告提取文本风险信号。
• 合规审查:HSBC使用NLP每日审查1亿笔交易,假阳性降低20%。
• 欺诈检测:识别通信中的异常语言模式和可疑交易描述。
法律科技
• 合同审查:Allen & Overy律所使用NLP审查1万份合同,节省250万美元律师费,耗时减少70%。
• 判例检索:自动匹配相关法条和先例,加速法律研究。
人力资源
• 简历筛选:强生公司年处理150万份简历,匹配率从62%提升至85%,招聘时间节省70%。
• 员工情绪分析:通过内部沟通文本监测员工满意度和离职风险。
2.3 新兴应用场景
• 跨语言知识迁移:将英语医疗资源知识迁移至低资源语言(如斯瓦希里语、冰岛语)。
• 紧急事件检测:YouCOMM应用通过NLP连接病患与护士,实时识别紧急医疗需求。
• 内容推荐:《纽约时报》"Project Feels"项目通过情感分析提升31%订阅留存率。
3. 自然语言处理的任务
NLP任务按照处理维度可分为四个层次,形成完整的处理流水线:
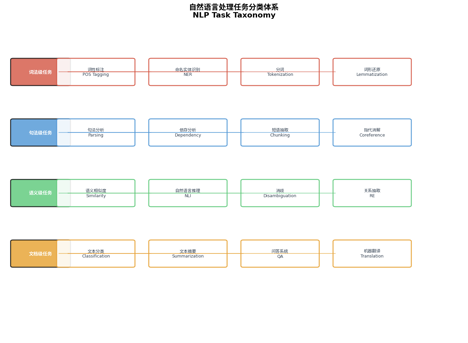
3.1 词法级任务(Word Level)
目标:处理词汇边界与形态特征
• 分词(Tokenization) :将连续字符切分为有意义单元
o 英文:"Hello world" → "Hello", "world"
o 中文:"自然语言处理" → "自然", "语言", "处理"(需处理歧义切分如"研究生命")
• 词性标注(POS Tagging) :为每个词分配语法类别
o 示例:"Run"可以是动词(跑)或名词(一次跑步)
• 命名实体识别(NER):识别专有名词(人名、地名、机构名、时间等)
o 示例:"马云于1999年在杭州创立阿里巴巴" →
• 词形还原(Lemmatization)与词干提取(Stemming) :归一化词汇形态
o 示例:"running", "ran", "runs" → 原型 "run"
3.2 句法级任务(Sentence Level)
目标:分析句子内部结构关系
• 句法分析(Constituency Parsing):构建短语结构树
o 识别名词短语(NP)、动词短语(VP)等成分
• 依存句法分析(Dependency Parsing):识别词与词之间的支配关系
o 示例:确定"吃"的主语是"我",宾语是"苹果"
• 指代消解(Coreference Resolution):确定代词指向哪个实体
o 示例:"小明把书给他"中的"他"指代谁?
3.3 语义级任务(Semantic Level)
目标:理解语言深层含义
• 词义消歧(WSD):确定多义词在具体语境中的含义
o 示例:"Bank"在金融机构 vs 河岸之间的选择
• 语义角色标注(SRL):识别谓词-论元结构
o 示例:"张三昨天在商场买了苹果" → 施事(张三)、时间(昨天)、地点(商场)、受事(苹果)
• 自然语言推理(NLI):判断文本间的逻辑关系(蕴含、矛盾、中立)
o 前提:"所有人都会死",假设:"苏格拉底会死" → 蕴含关系
• 语义相似度:计算两段文本的语义接近程度(用于搜索、去重)
3.4 文档级任务(Document Level)
目标:处理长篇文本的整体理解与生成
• 文本分类(Text Classification):情感分析、主题分类、垃圾邮件检测
• 机器翻译(MT):跨语言自动翻译(目前已达专业译员水平)
• 文本摘要(Summarization):
o 抽取式:从原文选取关键句子
o 生成式:用新语言表达核心内容(如GPT系列)
• 问答系统(QA):阅读理解、开放域问答(如ChatGPT、Kimi)
• 对话系统(Dialogue):多轮对话管理、上下文跟踪
4. 自然语言处理的困难和挑战
尽管大语言模型(LLM)取得突破性进展,NLP仍面临根本性挑战

4.1 歧义性(Ambiguity)------核心难题
词法歧义(Lexical Ambiguity)
• 同形异义词:"Bank"(银行/河岸)、"Date"(日期/枣子)
• 词性歧义:"I need a light"(形容词轻的/名词灯)
句法歧义(Syntactic Ambiguity)
• 附着歧义:"I saw the man with the telescope"
o 解释A:我用望远镜看到了那个男人(介词短语修饰动词)
o 解释B:我看到了那个带望远镜的男人(介词短语修饰名词)
语义歧义(Semantic Ambiguity)
• 角色歧义:"鸡不吃了" → 鸡不吃食了?还是人不吃鸡了?
• 预设歧义:"他停止吸烟" → 暗示他以前吸烟
4.2 常识与背景知识依赖
人类交流依赖大量未言明的常识:
• "我把水倒在盆栽里,因为它渴了" → 需要植物生理学常识(植物通过土壤吸水,而非"口渴")
• "他提着公文包走进了办公室" → 隐含"公文包通常装文件"、"办公室是工作场所"等知识
当前局限:大模型虽能记忆统计关联,但缺乏因果推理和物理世界建模能力。
4.3 语言多样性与低资源问题
• 语言数量:世界现存7,000+语言,NLP资源主要集中在英语、中文等20种高资源语言
• 方言与变体:中文的普通话、粤语、闽南语;英语的英式、美式、印度式
• 领域差异:医学、法律、工程等专业领域的术语鸿沟
4.4 数据与评估挑战
• 标注数据稀缺:高质量标注语料库(如CoNLL NER数据集)构建成本极高
• 领域迁移困难:在新闻文本上训练的模型在社交媒体文本上表现骤降
• 评估指标局限:
o BLEU、ROUGE等自动指标与人类感知存在差距
o F1分数无法区分精确率与召回率的业务重要性(如医疗诊断必须优先保证召回率)
4.5 大模型特有的挑战
• 幻觉(Hallucination):模型生成看似合理但虚假的内容
• 可解释性缺失:难以解释模型为何做出特定决策(黑盒问题)
• 计算资源:GPT-4级别模型训练成本数千万美元,推理延迟高
• 伦理偏见:训练数据中的社会偏见被模型放大(性别、种族刻板印象)
5. 自然语言处理的方法
NLP方法经历了五个阶段的演进,每次范式转移都带来性能飞跃:
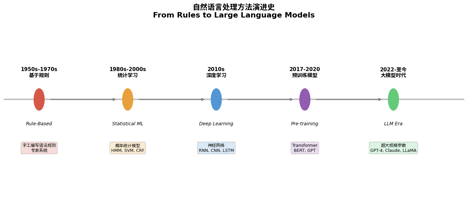
5.1 基于规则的方法(1950s-1970s)
特征:依赖语言学家手工编写语法规则与词典
• 示例系统:ELIZA(1966)、SHRDLU(1970)
• 技术:正则表达式、上下文无关语法(CFG)、有限状态自动机
• 局限:
o 规则无法覆盖所有语言现象(长尾问题)
o 维护成本高,难以跨领域迁移
o 对歧义处理能力弱
5.2 统计学习方法(1980s-2000s)
特征:从大规模语料库中学习概率模型
核心算法:
• N-Gram模型:通过相邻词共现概率预测下一个词
二元语法示例
P("吃" | "喜欢") = Count("喜欢吃") / Count("喜欢")
• 隐马尔可夫模型(HMM):用于词性标注、命名实体识别
• 条件随机场(CRF):序列标注的经典方法
• 支持向量机(SVM):文本分类任务
代表成果:IBM统计机器翻译(将语音识别率从70%提升至90%)
5.3 深度学习方法(2010s)
特征:神经网络自动学习特征表示,端到端训练
关键架构:
• RNN/LSTM/GRU:处理序列数据,捕捉长距离依赖,解决梯度消失问题
• CNN:捕捉局部n-gram特征,用于文本分类
• Seq2Seq + Attention:编码器-解码器架构革新机器翻译
• Word2Vec/GloVe:分布式词向量("King - Man + Woman ≈ Queen")
5.4 预训练语言模型(2017-2020)
特征:"预训练+微调"范式,迁移学习主导
里程碑模型:
• Transformer(2017):自注意力机制(Self-Attention)取代RNN,并行计算效率大幅提升
• BERT(2018):双向编码器,通过MLM(掩码语言模型)预训练,在11项NLP任务上刷新记录
• GPT系列(2018-2020):自回归语言模型,展现强大的文本生成能力
• ERNIE/StructBERT:针对中文优化的预训练模型
5.5 大语言模型时代(2022-至今)
特征:超大规模参数(数十亿至数千亿)、涌现能力(Emergent Abilities)、指令遵循
技术特点:
• Scaling Laws:模型性能随参数规模、数据量、计算量幂律增长
• 提示工程(Prompt Engineering):通过自然语言指令激活模型能力
• RLHF(人类反馈强化学习):对齐人类价值观,提升指令遵循度
• RAG(检索增强生成):结合外部知识库,缓解幻觉问题
• 多模态融合:GPT-4V、Gemini等模型融合文本、图像、语音处理能力
当前趋势:
• Agent化:LLM作为核心控制器,调用工具(计算器、搜索引擎、代码解释器)完成复杂任务
• 高效微调:LoRA、QLoRA等技术降低领域适配成本
• 模型压缩:知识蒸馏、量化技术推动端侧部署
6. 自然语言处理的工具
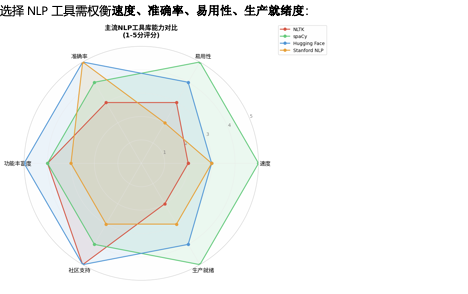
6.1 工具库详解

6.2 代码示例对比
spaCy工业级流水线(推荐用于生产环境):
python
import spacy
# 加载预训练模型(支持70+语言)
nlp = spacy.load("zh_core_web_sm")
# 一次性完成分词、词性标注、命名实体识别、依存分析
doc = nlp("苹果公司正在开发大语言模型。")
# 提取命名实体
for ent in doc.ents:
print(f"{ent.text}: {ent.label_}") # 苹果公司: ORG
# 高效批量处理(关键优化)
texts = ["文本1", "文本2", ...] # 10万条文本
for doc in nlp.pipe(texts, batch_size=1000, disable=["parser"]):
# 仅启用NER,禁用句法分析以提速
print([ent.text for ent in doc.ents])
NLTK(教学与语言学研究):
import nltk
from nltk.tokenize import word_tokenize
from nltk import pos_tag, ne_chunk
# 分词与词性标注
tokens = word_tokenize("Natural language processing is fascinating.")
tagged = pos_tag(tokens) # [('Natural', 'JJ'), ('language', 'NN'), ...]
# 命名实体识别(基于规则,准确率较低)
tree = ne_chunk(tagged)6.3 深度学习框架
• PyTorch:研究首选,动态图机制便于调试,Hugging Face主要后端
• TensorFlow/Keras:工业部署成熟,TFX支持大规模生产流水线
• JAX/Flax:Google新一代框架,适合超大规模模型训练
• ONNX:跨框架模型交换标准,优化推理性能
7. 自然语言处理的演练:利用智能体
现代NLP应用已从单一模型演进到智能体(Agent)架构,结合大模型推理能力与工具使用能力。
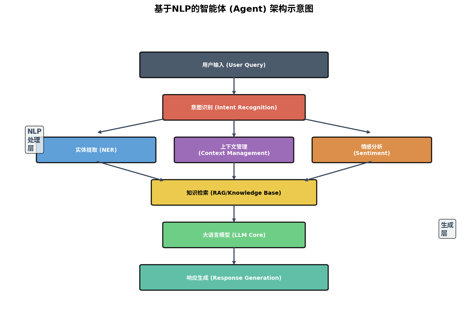
7.1 智能体核心组件
感知层(Perception)
• 意图识别(Intent Recognition):分类用户请求类型(查询、预订、投诉)
• 实体抽取(NER):提取关键参数(时间、地点、专有名词)
• 情感分析(Sentiment Analysis):检测用户情绪状态,调整响应策略
认知层(Cognition)
• 上下文管理(Context Management):维护对话状态,处理指代消解
• 知识检索(RAG):从向量数据库检索相关文档,增强回答准确性
• 大语言模型(LLM Core):推理决策中枢,生成响应草稿
执行层(Action)
• 响应生成(Response Generation):结构化输出,包含文本、语音或多模态内容
• 工具调用(Tool Use):调用计算器、API、数据库等外部工具
7.2 实战:构建客服智能体
以下是一个NLP智能体实现的代码,整合多模块用来处理客户咨询。
python
"""
NLP Agent Demo: 电商客服智能体
整合意图识别、实体抽取、情感分析、RAG检索
"""
import spacy
from transformers import pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
import numpy as np
class CustomerServiceAgent:
def __init__(self):
# 1. 加载spaCy进行基础NLP处理
print("加载spaCy模型...")
self.nlp = spacy.load("zh_core_web_sm", disable=["parser"])
# 2. 加载Hugging Face情感分析
print("加载情感分析模型...")
self.sentiment = pipeline(
"sentiment-analysis",
model="uer/roberta-base-finetuned-jd-binary-chinese"
)
# 3. 简单的意图分类器(基于TF-IDF + 朴素贝叶斯)
self.intent_classifier = self._train_intent_classifier()
# 4. 模拟知识库(RAG检索源)
self.knowledge_base = {
"物流": "标准快递3-5个工作日,顺丰次日达。",
"退款": "支持7天无理由退货,需保持商品完好。",
"优惠": "新用户注册领满100减20优惠券。",
"账户": "可在'我的-设置'中修改密码或绑定手机。"
}
def _train_intent_classifier(self):
"""训练简单的意图分类器"""
# 训练数据(实际应用需大规模标注数据)
texts = [
"我的快递到哪里了", "什么时候到货", "查物流",
"我要退货", "怎么退款", "商品有问题",
"有没有优惠券", "打折吗", "活动",
"忘记密码了", "怎么改手机号", "账户问题"
]
labels = ["物流查询", "退款申请", "优惠活动", "账户问题"]
# 重复标签以匹配文本数量
y = ["物流查询"]*3 + ["退款申请"]*3 + ["优惠活动"]*3 + ["账户问题"]*3
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(texts)
clf = MultinomialNB()
clf.fit(X, y)
return (vectorizer, clf)
def perceive(self, user_input):
"""感知层:处理原始输入"""
# spaCy处理:分词、实体识别
doc = self.nlp(user_input)
entities = [(ent.text, ent.label_) for ent in doc.ents]
tokens = [token.text for token in doc]
# 情感分析
sentiment_result = self.sentiment(user_input[:512])[0]
# 意图识别
vectorizer, clf = self.intent_classifier
X = vectorizer.transform([user_input])
intent = clf.predict(X)[0]
intent_prob = np.max(clf.predict_proba(X))
return {
"tokens": tokens,
"entities": entities,
"sentiment": sentiment_result,
"intent": intent,
"confidence": intent_prob,
"raw": user_input
}
def retrieve_knowledge(self, intent):
"""检索知识库(简化版RAG)"""
# 意图到知识库的映射
intent_to_kb = {
"物流查询": "物流",
"退款申请": "退款",
"优惠活动": "优惠",
"账户问题": "账户"
}
key = intent_to_kb.get(intent, None)
return self.knowledge_base.get(key, "抱歉,暂未找到相关信息。")
def generate_response(self, perception, knowledge):
"""生成层:组装最终回复"""
intent = perception["intent"]
sentiment = perception["sentiment"]
entities = perception["entities"]
# 根据情感调整语气
tone = ""
if sentiment["label"] == "negative" and sentiment["score"] > 0.8:
tone = "非常抱歉给您带来不好的体验,"
# 构建响应
response = f"{tone}关于您的{intent},{knowledge}"
# 如果识别到具体实体(如订单号、日期),可进一步个性化
if entities:
response += f"\\n(检测到实体:{entities})"
return response
def process(self, user_input):
"""完整处理流程"""
print(f"\\n用户输入: {user_input}")
# Step 1: 感知
perception = self.perceive(user_input)
print(f"意图识别: {perception['intent']} (置信度: {perception['confidence']:.2f})")
print(f"情感分析: {perception['sentiment']}")
print(f"命名实体: {perception['entities']}")
# Step 2: 知识检索
knowledge = self.retrieve_knowledge(perception["intent"])
# Step 3: 生成响应
response = self.generate_response(perception, knowledge)
print(f"系统回复: {response}")
return response
# 运行示例
if __name__ == "__main__":
agent = CustomerServiceAgent()
# 测试案例
test_queries = [
"我的包裹三天了还没到,怎么回事?",
"这个商品能退吗?质量太差了",
"有没有新人优惠券可以领?",
"我忘记密码了怎么找回?"
]
for query in test_queries:
agent.process(query)7.3 代码解析与优化建议
性能优化技巧(基于spaCy官方最佳实践):
1. 禁用无用组件: 若只需NER,禁用parser和tagger可提速40%+
nlp = spacy.load("zh_core_web_sm", disable="tagger", "parser")
2. 批量处理: 使用nlp.pipe()替代循环调用,速度提升5-8倍
docs = nlp.pipe(texts, batch_size=100, n_process=4) # 多进程
3. 模型选择:
• 轻量模型(_sm):速度快,适合分词/NER。
• 大模型(_trf):基于Transformer,准确率高但慢。
进阶架构建议:

总结与展望
自然语言处理正经历从工具型AI向伙伴型AI的范式转变:
- 技术融合:NLP与计算机视觉(VLP)、语音处理(ASR/TTS)界限日益模糊,多模态成为标配。
- 效率革命:模型压缩(INT8/INT4量化)、蒸馏技术使大模型可在边缘设备运行。
- 可信AI:解决幻觉、偏见、可解释性问题,建立人机协作的信任机制。
- 低资源语言:通过跨语言迁移学习(XLM-R、mBERT) democratize NLP技术。
以下是几方面可能的学习路径,仅供各位参考。 - NLP基础:掌握Python + 正则表达式 + 基础统计学。
- 传统NLP:学习NLTK/spaCy,理解分词、标注、解析原理。
- 深度学习:PyTorch/TensorFlow → RNN/CNN/Transformer架构。
- 现代NLP:Hugging Face生态 → 预训练 → 微调 → 提示工程。
- 系统构建:LangChain/LlamaIndex → RAG → Agent架构
参考书目:
• Jurafsky, D., & Martin, J. H. (2024). Speech and Language Processing (3rd ed.). Stanford University.
• 索米亚-瓦贾拉等.(2022).自然语言处理实战-从入门到项目实战(Practical Natural Language Processing). 人民邮电出版社.
• 霍布森-莱恩等.(2020).自然语言处理实战-利用Python理解、分析和生成文本(Natural Language Processing In Action). 人民邮电出版社.
• Goldberg, Y. (2017). Neural Network Methods for Natural Language Processing. Morgan & Claypool Publishers.
• 宗成庆. (2013). 《统计自然语言处理》(第2版). 清华大学出版社.
技术好文陆续推出,敬请关注、收藏和点赞👍!
您的认可,我的动力! 😃