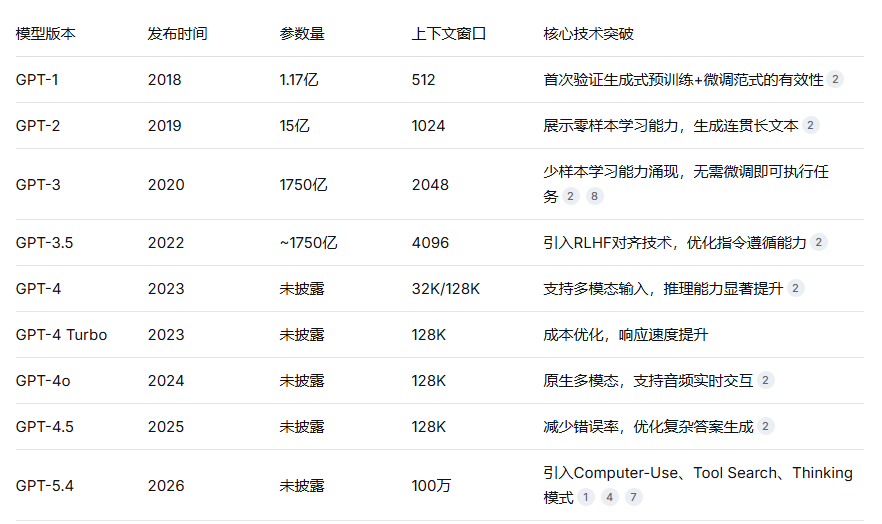
自2018年OpenAI发布第一代GPT模型以来,生成式预训练Transformer架构经历了七年的快速迭代,从1.17亿参数扩展到万亿级混合专家模型,从单纯的文本生成演进为具备计算机操作能力的AI代理。本文深度拆解GPT系列模型的核心技术架构,包括Transformer底层原理、自回归训练机制、RLHF对齐技术、以及最新GPT-5.4引入的百万Token上下文与Computer-Use能力,为开发者提供从理论到工程实践的全景式技术解读。 文章还包含关键代码示例和技术参数对比,帮助读者理解大模型的技术演进逻辑。
本文首发于RskAi(ai.rsk.cn),访问RskAi可体验Gemini 3 Pro,grok,Claude,gpt等大模型
一、GPT技术基石:Transformer架构深度解析
1.1 从RNN到Transformer的范式革命
在Transformer出现之前,自然语言处理领域主要依赖循环神经网络(RNN)及其变体(LSTM、GRU)。RNN的核心问题是串行计算------每个时间步的输出依赖于前一个时间步的隐藏状态,这不仅导致训练效率低下,还难以捕捉长距离的语义依赖关系。
2017年,Google团队在论文《Attention Is All You Need》中提出的Transformer架构彻底改变了这一局面。其核心创新在于:
并行计算能力:摒弃RNN的时序依赖,所有位置同时参与计算
自注意力机制:每个词可以直接与序列中任意位置的词建立关联
可扩展性:通过堆叠多层构建深度网络,支持大规模参数扩展
1.2 多头注意力机制的数学原理
自注意力机制的核心公式为:
Attention(Q,K,V) = softmax(QK^T/√d_k)V
其中Q(Query)、K(Key)、V(Value)通过输入与三个权重矩阵相乘得到。缩放因子√d_k的作用是防止点积结果过大导致softmax梯度消失。
多头注意力(Multi-Head Attention)将输入投影到多个子空间并行计算注意力:
MultiHead(Q,K,V) = Concat(head₁,...,head_h)W^O
每个头关注不同的语义特征------有的头关注语法关系,有的头关注指代关系,有的头关注长距离依赖。以GPT-3为例,其使用了96个注意力头,在1750亿参数的规模下实现了丰富的特征表达。
1.3 位置编码的工程实现
由于Transformer缺乏对序列顺序的感知能力,必须通过位置编码注入位置信息。原始Transformer采用正弦函数生成固定位置编码:
PE(pos,2i) = sin(pos/10000^(2i/d_model))
PE(pos,2i+1) = cos(pos/10000^(2i/d_model))
而GPT系列从GPT-2开始采用可训练的位置嵌入(Learnable Positional Embeddings),将位置索引映射为可学习的向量。这种方法让模型能够根据训练数据自适应地调整位置表征,在工程实践中表现更优。
二、GPT模型的训练范式演进
2.1 自回归语言模型:下一个词预测
GPT系列采用自回归(Autoregressive)训练范式,目标是根据前文预测下一个词。训练目标为最大化对数似然:
L = Σ_{t=1}^T log P(x_t | x_{<t})
这种设计天然适配文本生成任务------模型在推理时逐个词元(token)生成,每一步都基于已生成的内容预测下一个词。
生成过程的数学描述:
接收初始文本序列(prompt)作为输入
计算词汇表中所有词元的概率分布
根据采样策略选择下一个词元(贪心、Top-k、Top-p等)
将选定词元加入序列,重复上述步骤
温度参数(temperature)控制生成的随机性:τ→0时趋近于贪心选择,τ较高时增加多样性。
2.2 预训练的数据工程
GPT-3的训练数据规模达到45TB,涵盖Common Crawl(570GB)、WebText2、Books1/2、Wikipedia等多个来源。数据清洗流程包括:
去重:使用MinHash算法去除近似重复文档
质量过滤:基于N-gram语言模型过滤低质量文本
安全过滤:移除成人内容、暴力等有害信息
GPT-3的参数量达1750亿,训练所需算力约为3.14E23 FLOPs,在数千块A100 GPU上训练数十天。
2.3 从GPT-1到GPT-4的关键技术突破