【问题】为什么Redis不使用C语言原生字符串?
第一点 :由于C语言原生字符串是不支持在字符串内部存储"\0"这种特殊字符,因为C语言原生字符串在扫描到\0后会自动表示当前字符串终止,但是实际上,当前字符串并没有结束。所以,Redis sds针对以上问题进行优化。
第二点 :Redis sds针对buf存储区数据结尾不是使用\0进行区别结束与否,而是采用记录当前buf存储区中数据大小进行。这样就省去每次都需要读到\0才结束,同时由于Redis sds也支持存储\0,这样以来还可以避免Redis sds内存储数据被误解,而是可以自行判断是否后续还有没有数据。
第三点 :字符串扩容与缩容问题,C语言字符串在创建时候就需要确定下来对应的存储字符串长度,如果后续需要追加字符串情况下,是需要重新申请空间,并且将当前字符串拷贝进新空间再追加,过程比较繁琐。但是Redis sds则是会预先进行申请一部分空间预留,然后如果需要追加新字符串进入,则很方便的加入到对应buf存储区内部。
而在缩容方面也是类似,一个原生的C语言字符串变短的话,是需要立刻进行内存拷贝的,而Redis sds只需要修改结构体内部的len字段存储的长度与buf存储区的字符串数据即可,不需要任何内存拷贝。
Redis sds结构体:
struct sds {
int len; // 记录char数组实际使用了多少个字节
int alloc; // 记录char数组的实际长度
unsigned char flags //低3位用于表示字符串的类型是sds5、sds8还是其他类型
char buf[]; // 存储字符串
}; Redis内部sds.h源码文件针对sdshdr结构体的定义:
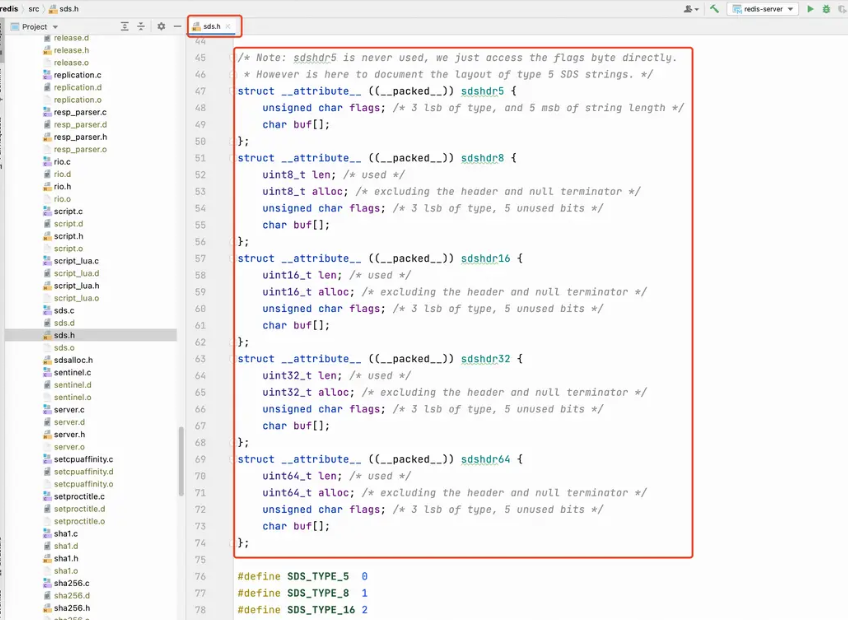
其中我们注意到sdshdr5其实就是当前sdshdr结构buf存储区只能存储2^5 - 1长度范围内部的字符串。
而Redis内部为了节省空间,不同的sdshdr结构体其所占用的存储空间也不同,仅仅看sdshdr8和sdshdr16,我们就可以发现,他们在len(实际buf存储数据长度)和alloc(整体buf被分配到空间大小)这两个字段上,就有着2个字节的节省:
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; // 下面的buf数组已经使用了多少字节
uint8_t alloc; // 下面的buf数组实际分片
unsigned char flags; // 低三位用来表示字符串的类型【注意】
char buf[]; // 用来存储字符串数据
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};【深入问题】__attribute__ ((__packed__))是什么?
在了解__attribute__ ((__packed__))之前,我们需要知道,在使用编译器时候自带的内存对齐机制:
首先,内存对齐是为了避免因为内存拥挤导致当前数据在进行一次读取后是无法被读取完成,这样如果在寻访一个数据时候,我们需要跨空间查询,读取两次,性能会低:
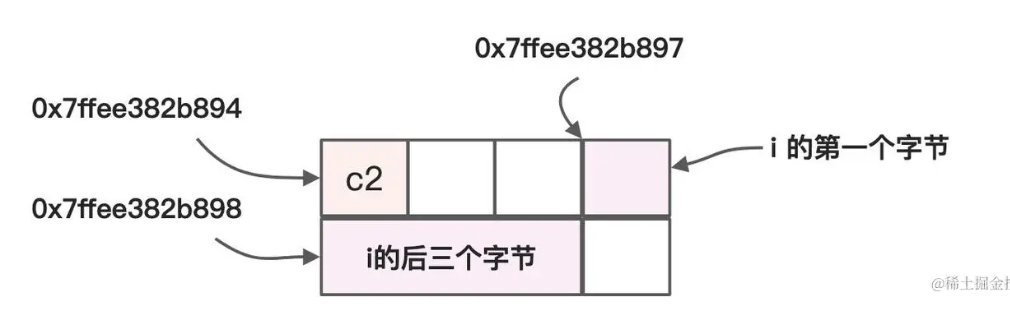
在机器中,内存对齐即依据当前结构体内部的字段进行填充对应字节,其类型决定其起始地址与对齐区间的大小:
typedef struct {
char c1; // 1字节
short s; // 2字节
char c2; // 1字节
int i; // 4字节
} sdemo;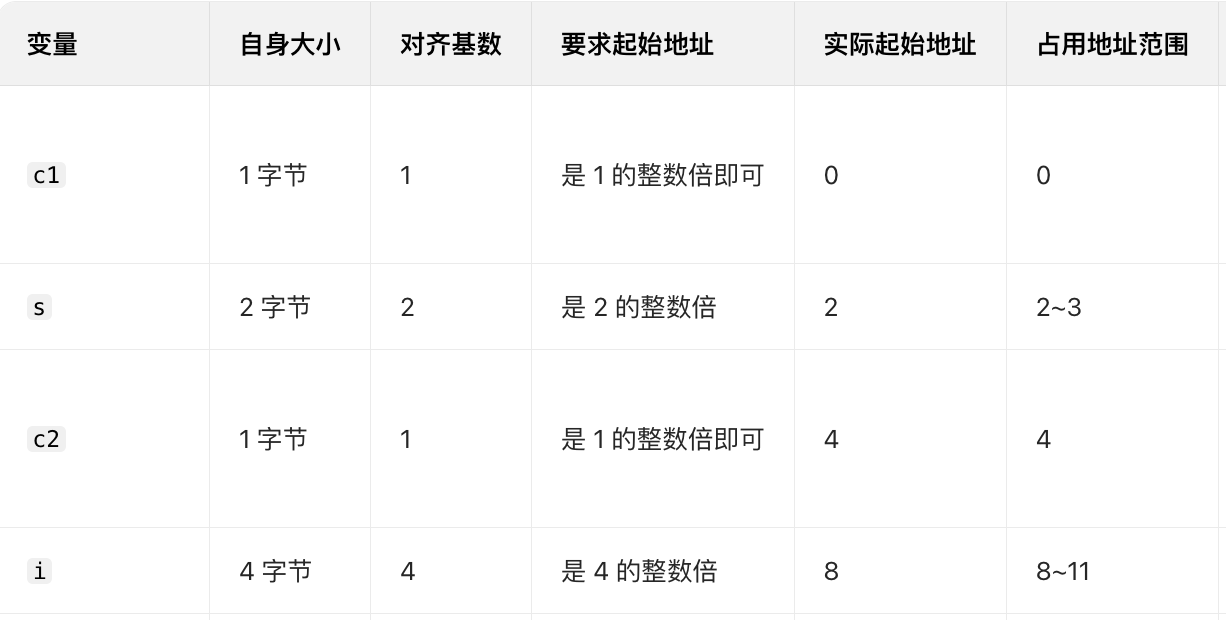
- 如果我们在日常内存对齐情况下,我们的内存存储结构是这样的:
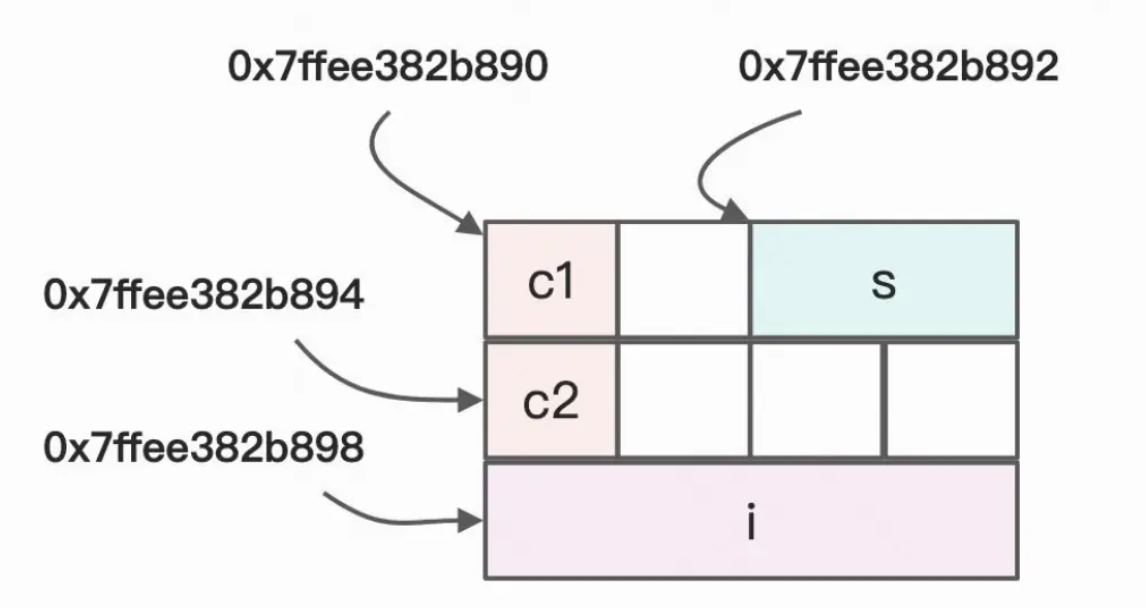
- 如果我们在使用
__attribute__ ((__packed__))进行消除内存填充,优化内存占用情况下,其结构会是这样:
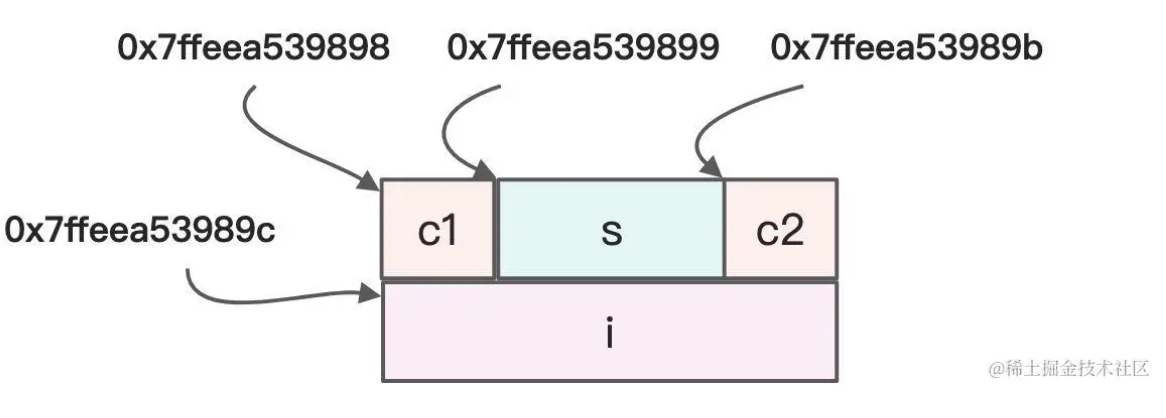
【注意】
-
在内存中,结构体整体对齐是依据结构体内部最大类型字段进行对齐,而具体内部偏移与填充则是看对应存储数据类型进行,例如:
type struct{
int a
char b
char c
char d
short e
}
那么其结构体存储内存会是:
内存地址偏移: 0 1 2 3 4 5 6 7 8 9 10 11
存储内容: [a] [a] [a] [a] [b] [c] [d] [×] [e] [e] [×] [×]
←----a占用----→ ←3个char→ ←填充→ ←e占用→ ←填充→整体占用12字节,即为4字节倍数,并且short e需要填充后进行存储,因为short类型占用2字节,则需要在2为倍数的存储位置中存储。
【补充】sds 不是独立结构体,而是一个 char* 指针,直接指向 sdshdr 内部的 buf存储区起始位置,Redis 用它来读写字符串。