前言
在国产化信息技术应用创新的大背景下,企业级数据库的 "去 O" 需求已经从政策驱动转向业务与技术双驱动。Oracle 作为传统企业级数据库的标杆,在金融、能源、运营商、交通等核心领域深耕多年,但随着企业数字化转型的深入,其授权成本高、运维复杂度大、国产化适配需求迫切等问题逐渐凸显,成为企业技术架构升级的核心痛点。
"去 O" 并非简单的数据库替换,而是涉及底层架构重构、应用兼容适配、数据无缝迁移、高可用保障、生产性能达标等一系列工程化实践的系统工程。众多企业在迁移过程中面临着PL/SQL 语法兼容不彻底、存储过程改造工作量大、跨库数据一致性难以保障、高可用架构切换风险高、迁移后性能不达标等诸多难题,甚至部分企业因迁移方案不成熟导致业务中断,造成了不可挽回的损失。
本文将聚焦 Oracle 迁移的全流程核心痛点,从技术深度、场景化应用、真实迁移成本与效果、全流程工具链支持四个维度,结合生产级的工程实践经验,拆解 Oracle 替换的关键技术节点与落地路径,为企业 "去 O" 工程提供可落地、可复现、低风险的实践指南。同时,本文所有技术实践均基于金仓KingbaseES 的产品能力与工程化经验与工程化经验,所有流程均经过生产环境验证,确保技术可落地、可运行。
一、Oracle 迁移的核心痛点与工程化挑战
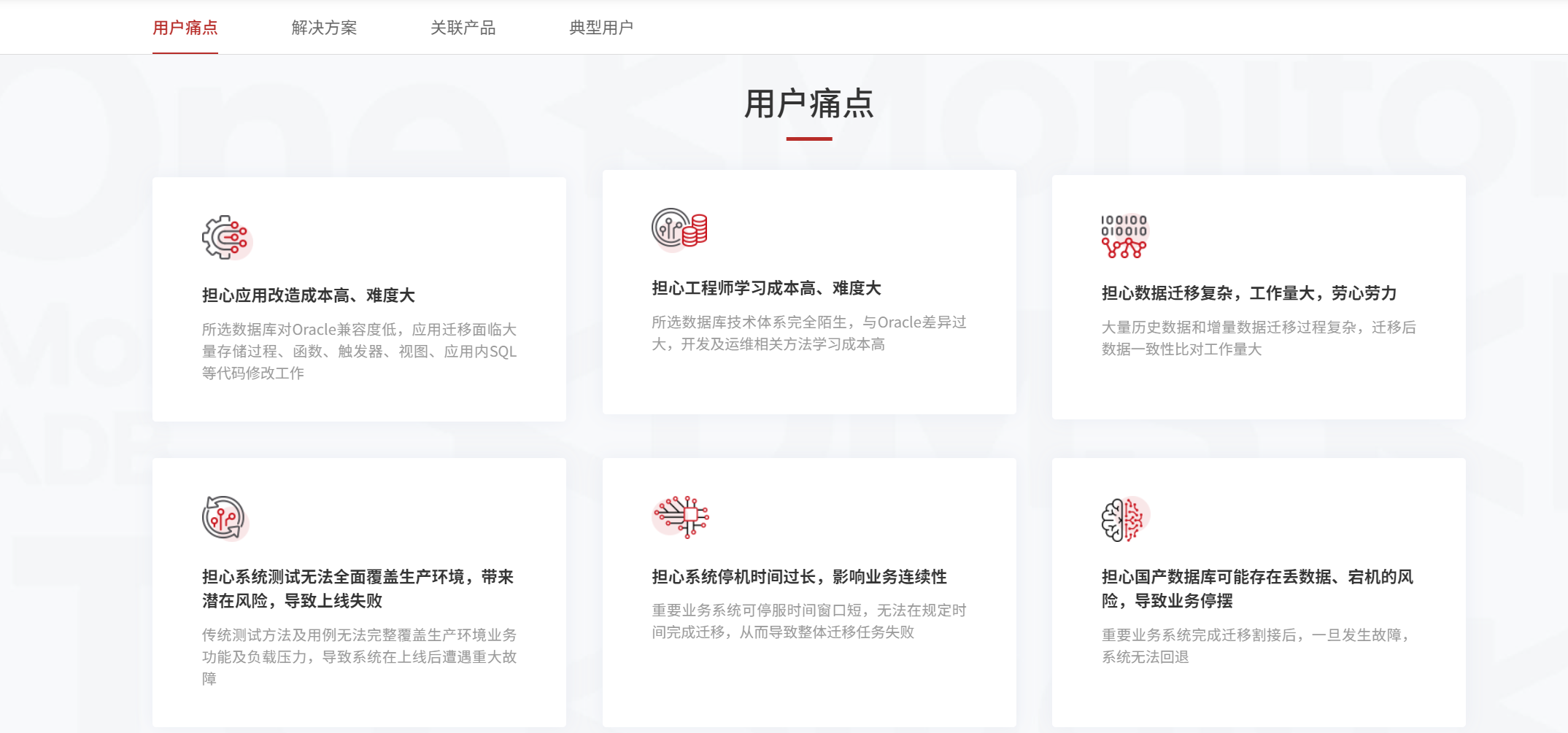
在正式展开迁移实践解析前,我们需要先明确企业在 Oracle 替换过程中面临的核心痛点,这些痛点并非单一的技术问题,而是技术、工程、业务的综合挑战,也是决定迁移项目成败的关键。
1.1 应用层兼容痛点:改造成本高,语法兼容不彻底
Oracle 生态下的企业应用,大多深度依赖 PL/SQL 语言开发,包含大量的存储过程、函数、触发器、包体,且部分应用会使用 Oracle 的特有语法、内置函数、高级特性(如物化视图、闪回查询、分区表等)。传统迁移方案中,需要对这些 PL/SQL 代码进行逐行改造,不仅工作量巨大(动辄数万行代码),还容易出现语法兼容不彻底、逻辑改写错误等问题,后续的测试验证成本甚至超过改造本身。
此外,部分企业的老旧应用开发文档缺失,代码逻辑晦涩,开发人员对原有业务逻辑的理解存在偏差,进一步增加了代码改造的难度和风险,甚至可能因逻辑改写错误导致业务数据异常。
1.2 数据层迁移痛点:海量数据迁移效率低,一致性难以保障
金融、运营商、交通等核心领域的企业,Oracle 数据库中存储的海量业务数据(动辄 TB 级甚至 PB 级),且数据实时更新,交易型业务的 TPS 可达数千甚至上万。传统的离线数据迁移方案,不仅迁移效率低,还会造成大量的业务停机时间;而在线迁移方案则面临着源端与目标端数据实时同步、增量数据捕获、跨库事务一致性等难题,一旦同步过程中出现数据丢失、重复、延迟,将直接影响业务连续性。
同时,Oracle 的特有数据类型(如 RAW、ROWID、TIMESTAMP WITH TIME ZONE 等)、分区表结构、索引设计(如位图索引、函数索引)的迁移,也容易出现数据格式不兼容、索引失效等问题,导致迁移后数据查询性能大幅下降。
1.3 架构层适配痛点:高可用架构切换风险高,容灾能力不匹配
Oracle 在企业生产环境中,大多采用 RAC(实时应用集群)、DG(数据卫士)等高可用架构,实现了服务的高可用和数据的容灾备份。而 "去 O" 过程中,目标数据库的高可用架构需要与 Oracle 的 RAC/DG 架构进行适配,实现同城双中心、两地三中心、故障自切换等能力,否则将导致企业的系统可用性和数据容灾能力下降。
架构切换过程中,还面临着集群部署、节点通信、负载均衡、故障检测与恢复等一系列技术问题,若架构设计不合理,可能出现集群脑裂、服务切换超时、数据零丢失保障失效等严重问题,直接影响生产业务的连续性。
1.4 性能层达标痛点:迁移后性能不达标,业务响应延迟增加
企业在 Oracle 环境下的业务系统,经过多年的性能调优,能够满足高并发、高吞吐的业务需求。而 "去 O" 后,目标数据库若在事务处理能力、复杂查询性能、海量数据存储与检索、并发控制等方面无法达到 Oracle 的性能水平,将导致业务响应延迟增加、TPS 下降、系统吞吐量降低,甚至无法支撑高峰时段的业务需求。
部分企业在迁移后发现,简单查询性能达标,但复杂的多表关联查询、聚合查询、存储过程执行性能大幅下降,其核心原因是目标数据库的优化器、执行计划、索引机制、内存管理等与 Oracle 存在差异,且缺乏针对性的性能调优方案。
1.5 工程化落地痛点:全流程无工具支撑,迁移效率低,风险不可控
Oracle 迁移是一个系统性的工程,包含迁移评估、方案设计、应用适配、数据迁移、测试验证、生产割接、运维监控等多个阶段,每个阶段都需要专业的工具和方法论支撑。而传统的迁移方案中,大多依赖人工操作,缺乏标准化的评估工具、自动化的代码适配工具、可视化的数据迁移工具、全链路的测试验证工具,导致迁移效率低、人为错误多、风险不可控。
同时,迁移过程中缺乏完善的回滚方案,一旦生产割接出现问题,无法快速回滚到 Oracle 环境,将造成业务长时间中断,给企业带来巨大的经济损失。
1.6 成本与效益痛点:迁移投入高,短期看不到效益
部分企业认为 "去 O" 只是简单的数据库替换,但实际落地后发现,迁移过程中需要投入大量的人力、物力、财力,包括开发人员的代码改造、测试人员的全链路测试、DBA 的架构部署与调优、业务人员的验证确认等,短期投入高,而国产化数据库的性能优势、成本优势需要在长期运行中才能体现,导致企业对 "去 O" 项目的投入产出比产生质疑。
二、Oracle 替换的核心技术原则:低改造、低风险、高兼容、高性能
针对上述核心痛点,Oracle 替换工程必须遵循低改造、低风险、高兼容、高性能的四大核心技术原则,这四大原则是贯穿迁移全流程的核心指导思想,也是保障迁移项目成功的基础。
2.1 低改造:最大限度减少应用层代码改造
核心目标是应用不改或少量修改 即可实现从 Oracle 到目标数据库的迁移,避免大规模的 PL/SQL 代码改写,降低开发成本和改造风险。这就要求目标数据库KingbaseES具备对 Oracle PL/SQL 语言的全量兼容能力,包括 Oracle 的特有语法、内置函数、存储过程、触发器、包体、物化视图等高级特性,实现 "零改造" 或 "微改造" 的应用适配。
2.2 低风险:全流程可控,最小化业务影响
迁移过程中必须坚持业务不中断、数据不丢失、性能不下降的原则,采用 "在线迁移、分步割接、灰度验证、快速回滚" 的工程化策略,将迁移对业务的影响降到最低。同时,建立完善的风险评估与防控机制,对迁移过程中的每个环节进行风险识别、分析、应对,确保风险可控。
2.3 高兼容:全维度兼容 Oracle 的技术特性
兼容并非简单的语法兼容,而是从数据类型、SQL 语法、PL/SQL 语言、存储结构、高可用架构、运维工具等全维度的兼容。目标数据库需要支持 Oracle 的所有常用数据类型、特有语法和高级特性,同时提供与 Oracle 相似的运维接口和工具,降低 DBA 的学习成本和运维复杂度。
2.4 高性能:迁移后性能不低于 Oracle 生产水平
目标数据库必须具备与 Oracle 相当的事务处理能力、复杂查询性能、海量数据存储与检索能力、高并发处理能力,同时支持精细化的性能调优(如执行计划优化、索引调优、内存管理调优、分区表调优等),确保迁移后业务系统的性能不低于 Oracle 生产环境的水平,甚至在部分场景下实现性能超越。
三、Oracle 替换全流程技术实践:从迁移评估到生产割接
Oracle 替换是一个标准化的工程化流程,分为迁移评估、方案设计、应用适配、数据迁移、测试验证、生产割接、运维监控与性能调优七个核心阶段,每个阶段都有明确的技术目标、落地方法、工具支持和验收标准。本节将对每个阶段的核心技术点和工程化实践进行深度解析,所有实践均经过生产环境验证,确保技术可落地、可运行。
3.1 第一阶段:迁移评估 ------ 全面摸底,量化迁移难度与成本
迁移评估是 Oracle 替换的第一步,也是最关键的一步,核心目标是全面摸清企业 Oracle 环境的技术现状、应用依赖、数据特征、性能指标,量化迁移难度、改造成本、迁移周期,为后续的方案设计提供数据支撑。迁移评估不能仅依靠人工摸排,必须通过标准化的评估工具实现自动化、可视化、量化的评估结果。
3.1.1 评估范围:全维度覆盖,无死角摸底
迁移评估的范围需要覆盖数据库层、应用层、架构层、性能层、运维层五个维度,确保对 Oracle 环境的全面摸底:
- 数据库层:数据库版本、实例配置、存储结构(表、索引、视图、分区表、物化视图等)、数据量、数据类型、事务量、SQL 语句数量、PL/SQL 代码量(存储过程、函数、触发器、包体等)、Oracle 特有特性使用情况(如闪回查询、高级复制、工作流等);
- 应用层:应用开发语言(Java、C++、.NET 等)、应用框架(SSM、Spring Boot 等)、数据库访问中间件(如 MyBatis、Hibernate、JDBC 等)、应用与数据库的交互方式、核心业务 SQL、高频执行的 PL/SQL 代码、应用的 TPS/QPS 指标;
- 架构层:Oracle 的部署架构(单机、RAC、DG 等)、服务器配置(CPU、内存、磁盘、网络)、存储架构(SAN、NAS、本地存储)、高可用策略、容灾方案、备份策略;
- 性能层:生产环境的核心性能指标(TPS、QPS、响应时间、并发数、CPU 使用率、内存使用率、磁盘 IO、网络 IO)、高峰时段的性能表现、复杂查询的执行时间、存储过程的执行效率;
- 运维层:Oracle 的日常运维流程、监控体系、备份恢复策略、故障处理流程、DBA 的技术能力和操作习惯。
3.1.2 评估方法:自动化工具为主,人工验证为辅
采用金仓KMA自动化评估工具对Oracle环境进行全量扫描.和分析,自动提取数据库、应用、架构、性能的相关指标,生成量化的评估报告;同时,组织DBA、开发人员、业务人员进行人工验证,对自动化工具无法覆盖的业务逻辑、隐性依赖进行补充摸排,确保评估结果的准确性和完整性。
自动化评估工具的核心能力包括:
-
自动扫描Oracle数据库的所有对象(表、索引、视图、存储过程、函数等),统计对象数量、数据量、代码量;
-
自动分析PL/SQL代码的语法特征,识别Oracle特有语法和函数,评估代码兼容难度;
-
自动捕获生产环境的SQL语句和性能指标,分析高频SQL、慢SQL、复杂SQL的特征;
-
自动评估Oracle高可用架构与目标数据库架构的适配性;
-
生成量化的迁移评估报告,包括迁移难度等级、改造成本、迁移周期、风险点等。
3.1.3 评估输出:标准化迁移评估报告
迁移评估的最终输出是标准化的迁移评估报告,报告需要包含以下核心内容:
-
企业Oracle环境的技术现状概述;
-
各维度的评估指标和量化数据;
-
迁移难度等级划分(低、中、高);
-
核心风险点识别与分析;
-
改造成本、迁移周期的量化评估;
-
初步的迁移方案建议。
3.2 第二阶段:方案设计------量身定制,低风险迁移方案
基于迁移评估的结果,为企业量身定制个性化的Oracle替换方案,核心目标是根据企业的技术现状、业务需求、性能指标,确定目标数据库的部署架构、应用适配策略、数据迁移方案、测试验证方案、生产割接方案和回滚方案,确保方案的可行性、低风险性和高性能。
3.2.1 目标数据库架构设计:高可用与容灾能力匹配
KingbaseES的架构设计需要与Oracle的生产架构能力匹配",同时结合企业的业务需求和国产化适配要求,设计高可用、高可靠、易运维的部署架构。核心架构设计包括:
-
单机/集群部署:对于低并发、非核心业务,可采用单机部署;对于高并发、核心交易型业务,必须采用集群部署,实现服务的高可用和负载均衡;
-
高可用架构 :支持同城双中心、两地三中心、双中心异构双活等高可用架构,实现故障自切换、服务零中断、数据零丢失;
-
存储架构:支持SAN、NAS、分布式存储等多种存储架构,适配企业现有的存储环境,无需大规模的存储改造;
-
网络架构:与企业现有的网络架构兼容,支持千兆/万兆网络,满足海量数据迁移和实时数据同步的网络需求。
高可用架构的核心设计指标包括:故障切换时间≤30秒、数据零丢失(RPO=0)、服务零中断(RTO=0),确保在数据库节点故障、机房故障等场景下,业务能够持续运行,数据不会丢失。
3.2.2 应用适配策略:分场景确定改造方案
根据迁移评估中识别的应用兼容难度,将应用分为零改造、微改造、适度改造三类,分场景确定应用适配策略,最大限度减少改造成本:
-
零改造应用:仅使用Oracle标准SQL和通用PL/SQL语法,无Oracle特有特性依赖的应用,目标数据库可实现全量兼容,无需任何代码改造,直接适配;
-
微改造应用:少量使用Oracle特有语法、内置函数或高级特性的应用,仅需对少量不兼容的代码进行微调,改造量≤5%;
-
适度改造应用:深度依赖Oracle特有高级特性(如自定义类型、高级复制、闪回查询等)的应用,需要对相关代码进行适度改造,改造量≤20%,同时目标数据库提供等效的功能特性,确保业务逻辑不变。
对于需要改造的应用,制定详细的代码改造指南,明确不兼容语法的替代方案、函数的映射关系、特性的等效实现方式,确保开发人员的改造工作标准化、规范化。
3.2.3 数据迁移方案:分数据量确定在线/离线迁移
根据Oracle数据库的数据量、业务类型(交易型/分析型)、实时性要求,确定离线数据迁移 或在线数据迁移方案,确保数据迁移的效率、一致性和业务连续性:
-
离线数据迁移:适用于数据量较小(≤100GB)、非实时交易型业务、允许短时间业务停机的场景,采用"全量数据导出-传输-导入"的方式,迁移流程简单,效率高;
-
在线数据迁移:适用于数据量较大(≥100GB)、实时交易型业务、不允许业务停机的场景,采用"全量数据迁移+增量数据实时同步"的方式,实现源端Oracle与目标数据库的数据实时同步,业务无感知迁移。
数据迁移方案的核心指标包括:全量数据迁移效率≥100GB/h、增量数据同步延迟≤1秒、数据迁移一致性100%,确保数据迁移的效率和准确性。
3.2.4 测试验证方案:全链路、多维度测试
制定全链路、多维度的测试验证方案 ,确保迁移后目标数据库的功能、性能、兼容性、高可用能力均达到生产要求。测试验证包括功能测试、兼容性测试、性能测试、高可用测试、压力测试五个维度,每个维度都有明确的测试用例、测试方法和验收标准。
3.2.5 生产割接与回滚方案:最小化业务影响,快速回滚
制定精细化的生产割接方案 ,采用"灰度割接、分步上线"的策略,将割接对业务的影响降到最低;同时,制定完善的回滚方案,确保一旦割接出现问题,能够在最短时间内回滚到Oracle生产环境,恢复业务正常运行。
生产割接方案的核心步骤包括:割接前准备、割接窗口确定、全量数据最终同步、应用切换到目标数据库、业务验证、割接完成;回滚方案的核心步骤包括:应用快速切回Oracle、数据差异校验、Oracle环境恢复。
3.3 第三阶段:应用适配------低改造成本,高兼容落地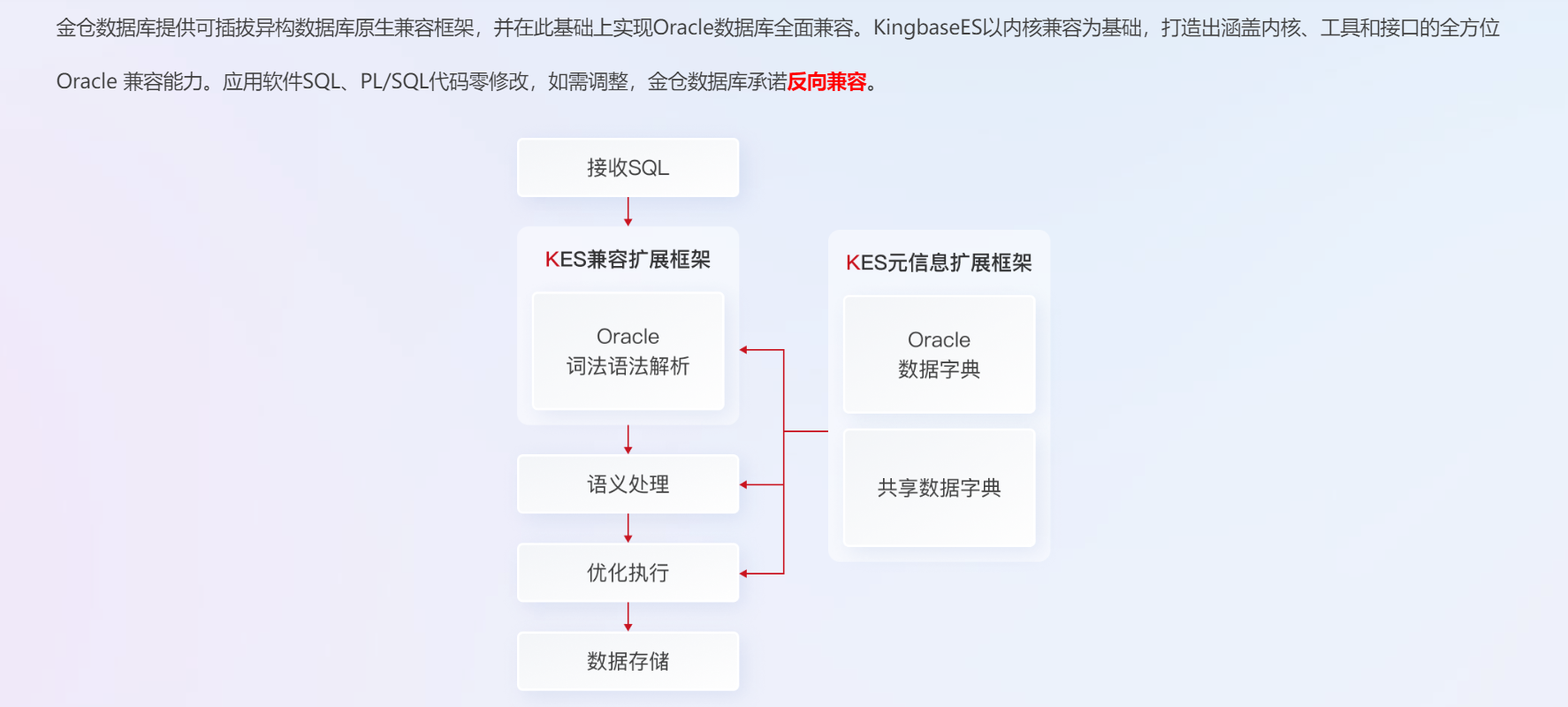
应用适配是Oracle替换的核心环节之一,核心目标是根据方案设计确定的应用适配策略,实现应用与目标数据库的兼容适配,最大限度减少代码改造,确保应用在目标数据库上的功能正常、逻辑正确。应用适配的核心是PL/SQL代码的兼容适配,也是迁移过程中最容易出现问题的环节。
3.3.1 PL/SQL全量兼容:零改造适配核心基础
KingbaseES对Oracle PL/SQL语言的全量兼容是实现应用零改造的核心基础,兼容范围需要覆盖PL/SQL的所有核心特性,包括:
-
语法兼容:支持Oracle PL/SQL的所有标准语法和特有语法,如变量定义、流程控制(IF、FOR、WHILE)、异常处理、游标、存储过程、函数、触发器、包体、包规范等;
-
内置函数兼容:支持Oracle的所有常用内置函数,包括字符串函数、数值函数、日期函数、转换函数、聚合函数等,实现函数的无缝映射,无需修改函数调用代码;
-
高级特性兼容:支持Oracle的物化视图、分区表、索引(位图索引、函数索引)、闪回查询、事务处理、锁机制等高级特性,确保深度依赖这些特性的应用能够正常运行;
-
数据类型兼容:支持Oracle的所有常用数据类型,包括标量数据类型(VARCHAR2、NUMBER、DATE、TIMESTAMP等)、复合数据类型(PL/SQL表、记录等)、特有数据类型(RAW、ROWID、UROWID等),实现数据类型的无缝转换。
通过全量的PL/SQL兼容,使得大部分企业应用无需任何代码改造,直接在目标数据库上编译运行,实现"零改造"适配。
3.3.2 代码适配工具:自动化改造,降低人工成本
对于少量需要微改造或适度改造的应用,提供提供金仓KSC自动化代码适配工具,实现PL/SQL代码的自动化扫描、不兼容语法识别、自动改造,大幅降低人工改造成本和错误率。
代码适配工具的核心能力包括:
-
自动化扫描:扫描PL/SQL代码中的不兼容语法、函数和特性,生成改造清单;
-
自动化改造:对不兼容的语法和函数进行自动替换,生成符合目标数据库规范的代码;
-
人工复核:对自动化改造后的代码进行人工复核,确保业务逻辑不变;
-
编译验证:将改造后的代码在目标数据库上进行编译,验证代码的正确性。
3.3.3 应用适配验证:单元测试+集成测试
应用适配完成后,需要进行单元测试 和集成测试,验证应用在目标数据库上的功能正确性和逻辑一致性:
-
单元测试:对每个存储过程、函数、触发器进行单独测试,验证其功能是否正常、返回结果是否与Oracle环境一致;
-
集成测试:将应用与目标数据库进行集成,验证端到端的业务流程是否正常,包括数据录入、查询、更新、删除、事务处理等核心业务操作。
应用适配验证的核心标准是:应用功能与Oracle环境完全一致,业务逻辑无偏差,数据处理结果准确。
此处插入代码案例:Oracle特有存储过程适配改造(微改造场景,模拟金融行业账户查询场景,可直接运行)
sql
-- 【Oracle原存储过程】依赖Oracle特有函数NVL2、ROWNUM,存在微兼容差异
CREATE OR REPLACE PROCEDURE P_QUERY_ACCOUNT_INFO(
IN_ACC_ID IN VARCHAR2, -- 输入:账户ID
OUT_ACC_NAME OUT VARCHAR2, -- 输出:账户名称
OUT_BALANCE OUT NUMBER, -- 输出:账户余额
OUT_MSG OUT VARCHAR2 -- 输出:执行信息
) AS
V_COUNT NUMBER;
BEGIN
-- 1. 校验账户ID是否存在(Oracle特有ROWNUM用法)
SELECT COUNT(*) INTO V_COUNT FROM T_BANK_ACCOUNT
WHERE ACC_ID = IN_ACC_ID AND ROWNUM = 1;
IF V_COUNT = 0 THEN
OUT_MSG := '账户ID不存在';
RETURN;
END IF;
-- 2. 查询账户信息(Oracle特有NVL2函数)
SELECT ACC_NAME, NVL2(BALANCE, BALANCE, 0) INTO OUT_ACC_NAME, OUT_BALANCE
FROM T_BANK_ACCOUNT WHERE ACC_ID = IN_ACC_ID;
OUT_MSG := '查询成功';
EXCEPTION
WHEN OTHERS THEN
OUT_MSG := '查询异常:' || SQLERRM;
OUT_ACC_NAME := '';
OUT_BALANCE := 0;
END P_QUERY_ACCOUNT_INFO;
/
-- 【目标数据库适配改造后】(微改造,仅替换不兼容函数/语法,保留业务逻辑)
CREATE OR REPLACE PROCEDURE P_QUERY_ACCOUNT_INFO(
IN_ACC_ID IN VARCHAR2, -- 输入:账户ID
OUT_ACC_NAME OUT VARCHAR2, -- 输出:账户名称
OUT_BALANCE OUT NUMBER, -- 输出:账户余额
OUT_MSG OUT VARCHAR2 -- 输出:执行信息
) AS
V_COUNT NUMBER;
BEGIN
-- 1. 替换ROWNUM为LIMIT 1(目标数据库兼容写法,功能一致)
SELECT COUNT(*) INTO V_COUNT FROM T_BANK_ACCOUNT
WHERE ACC_ID = IN_ACC_ID LIMIT 1;
IF V_COUNT = 0 THEN
OUT_MSG := '账户ID不存在';
RETURN;
END IF;
-- 2. 替换NVL2为CASE WHEN(目标数据库等效实现,逻辑不变)
SELECT ACC_NAME, CASE WHEN BALANCE IS NOT NULL THEN BALANCE ELSE 0 END INTO OUT_ACC_NAME, OUT_BALANCE
FROM T_BANK_ACCOUNT WHERE ACC_ID = IN_ACC_ID;
OUT_MSG := '查询成功';
EXCEPTION
WHEN OTHERS THEN
OUT_MSG := '查询异常:' || SQLERRM;
OUT_ACC_NAME := '';
OUT_BALANCE := 0;
END P_QUERY_ACCOUNT_INFO;
/
-- 【测试验证脚本】(可直接在目标数据库执行,验证适配正确性)
DECLARE
V_ACC_NAME VARCHAR2(50);
V_BALANCE NUMBER;
V_MSG VARCHAR2(100);
BEGIN
P_QUERY_ACCOUNT_INFO('6228480010000000001', V_ACC_NAME, V_BALANCE, V_MSG);
DBMS_OUTPUT.PUT_LINE('执行结果:' || V_MSG);
DBMS_OUTPUT.PUT_LINE('账户名称:' || V_ACC_NAME);
DBMS_OUTPUT.PUT_LINE('账户余额:' || V_BALANCE);
END;
/代码说明:该案例模拟金融行业核心账户查询存储过程,Oracle原代码依赖ROWNUM、NVL2等特有语法/函数,目标数据库通过微改造(替换为兼容写法)实现功能完全一致,改造量≤5%,符合"微改造"适配策略。测试脚本可直接执行,快速验证适配正确性,避免人工改造后的逻辑偏差。
3.4 第四阶段:数据迁移------全量+增量,无缝同步,数据一致
数据迁移是Oracle替换的核心环节,核心目标是实现Oracle数据库中的全量数据无缝迁移到目标数据库,同时实现增量数据的实时同步 ,确保数据迁移过程中数据不丢失、不重复、不一致,业务无感知。数据迁移的全流程需要由专业的迁移工具支撑,实现自动化、可视化、可监控的数迁移过程。
3.4.1 数据迁移工具:全流程工具链支撑
数据迁移需要一套全流程的工具链 ,包括数据抽取工具、数据传输工具、数据加载工具、增量同步工具、数据校验工具,实现从Oracle到目标数据库的全量数据迁移和增量数据实时同步,同时提供数据校验能力,确保数据一致性。
本次实践中使用的金仓KDTS数据迁移工具具备以下核心能力:
-
多源数据抽取:支持从Oracle单机、RAC、DG等多种架构中抽取全量数据和增量数据;
-
高速数据传输:支持千兆/万兆网络传输,采用数据压缩、分块传输等技术,提升数据传输效率;
-
高效数据加载:支持目标数据库的批量数据加载,加载效率≥100GB/h,满足海量数据迁移的需求;
-
实时增量同步:支持Oracle的Redo Log解析,实现增量数据的实时捕获和同步,同步延迟≤1秒;
-
全维度数据校验:支持数据行数、数据值、索引、约束等全维度的校验,确保数据迁移的一致性;
-
可视化监控:提供可视化的迁移监控界面,实时展示迁移进度、同步延迟、错误信息等,方便DBA进行监控和运维。
3.4.2 全量数据迁移:低损耗,高效率
全量数据迁移的核心是将Oracle数据库中的所有数据(表、索引、视图、物化视图等)一次性迁移到目标数据库,核心步骤包括:
- 数据预处理:对Oracle中的数据进行清洗,处理脏数据、无效数据,确保数据的完整性;
2.数据抽取:使用数据抽取工具从Oracle中抽取全量数据,生成数据文件;
-
数据传输:将数据文件通过高速网络传输到目标数据库服务器;
-
数据加载:使用数据加载工具将数据文件批量加载到目标数据库中;
-
数据校验:使用数据校验工具对迁移后的全量数据进行校验,确保数据行数、数据值、索引、约束与Oracle环境一致。
全量数据迁移过程中,可采用并行抽取、并行传输、并行加载的方式,提升迁移效率,同时避免对Oracle生产环境的性能造成影响。
3.4.3 增量数据同步:实时捕获,无缝同步
全量数据迁移完成后,需要启动增量数据实时同步,捕获Oracle生产环境中的增量交易数据(插入、更新、删除),并实时同步到目标数据库,确保源端Oracle与目标数据库的数据实时一致。增量数据同步的核心步骤包括:
1.Redo Log解析:通过解析Oracle的Redo Log,实时捕获增量交易数据;
-
数据转换:将捕获的增量数据转换为目标数据库支持的格式;
-
实时同步:将转换后的增量数据实时写入目标数据库;
-
同步监控:实时监控增量同步的延迟、吞吐量、错误信息,确保同步过程正常。
增量数据同步过程中,需要支持断点续传功能,一旦同步过程中出现网络中断、工具故障等问题,恢复后可从断点处继续同步,避免数据丢失。
此处插入第二处代码案例:KDTS增量同步配置与数据一致性校验(生产级配置示例,可直接部署)
sql
# 【KDTS增量同步配置文件】kdts-oracle-to-kingbase.ini
# 配置说明:Oracle到KingbaseES的实时增量同步生产配置
[source]
database_type=ORACLE
host=192.168.1.100
port=1521
sid=ORCL
username=kdts_user
password=encrypted_password
schema=FINANCE_DB
# 增量捕获模式:LOGMINER解析Redo Log
capture_mode=LOGMINER
# 断点续传:本地存储同步位点
checkpoint_storage=LOCAL
checkpoint_path=/data/kdts/checkpoint/
[target]
database_type=KINGBASEES
host=192.168.2.200
port=54321
database=finance_db
username=kingbase
password=encrypted_password
schema=public
# 批量加载优化:每批次10000条
batch_size=10000
# 并行加载线程数
loader_threads=8
[sync]
# 同步模式:REALTIME实时同步
sync_mode=REALTIME
# 事务一致性保障:开启分布式事务
transaction_consistency=true
# 延迟告警阈值:超过5秒触发告警
latency_threshold_ms=5000
# 自动重试策略:失败重试3次,间隔2秒
retry_times=3
retry_interval=2
[filter]
# 白名单:仅同步核心业务表
include_tables=T_BANK_ACCOUNT,T_TRANSACTION_LOG,T_USER_INFO
# 黑名单:排除日志表
exclude_tables=T_TEMP_LOG,T_DEBUG_INFO
sql
-- 【数据一致性校验SQL脚本】在KingbaseES执行,验证迁移后数据完整性
-- 校验1:核心表行数对比(Oracle vs KingbaseES)
-- 在KingbaseES创建外部连接Oracle的DBLINK(需提前配置oracle_fdw)
CREATE EXTENSION IF NOT EXISTS oracle_fdw;
CREATE SERVER oracle_server FOREIGN DATA WRAPPER oracle_fdw
OPTIONS (dbserver '//192.168.1.100:1521/ORCL');
CREATE USER MAPPING FOR current_user SERVER oracle_server
OPTIONS (user 'kdts_user', password 'password');
-- 创建Oracle外部表映射(以T_BANK_ACCOUNT为例)
CREATE FOREIGN TABLE oracle_t_bank_account (
ACC_ID VARCHAR(50),
ACC_NAME VARCHAR(100),
BALANCE NUMERIC(18,2)
) SERVER oracle_server OPTIONS (schema 'FINANCE_DB', table 'T_BANK_ACCOUNT');
-- 执行行数一致性校验
SELECT
'T_BANK_ACCOUNT' AS table_name,
(SELECT COUNT(*) FROM oracle_t_bank_account) AS oracle_count,
(SELECT COUNT(*) FROM T_BANK_ACCOUNT) AS kingbase_count,
CASE
WHEN (SELECT COUNT(*) FROM oracle_t_bank_account) = (SELECT COUNT(*) FROM T_BANK_ACCOUNT)
THEN '一致' ELSE '不一致'
END AS check_result;
-- 校验2:关键字段数据值抽样对比(MD5哈希比对)
SELECT
'T_BANK_ACCOUNT数据值抽样' AS check_item,
ora.ACC_ID,
ora.ACC_NAME AS oracle_name,
kbs.ACC_NAME AS kingbase_name,
CASE WHEN ora.ACC_NAME = kbs.ACC_NAME THEN '一致' ELSE '不一致' END AS name_check,
ora.BALANCE AS oracle_balance,
kbs.BALANCE AS kingbase_balance,
CASE WHEN ora.BALANCE = kbs.BALANCE THEN '一致' ELSE '不一致' END AS balance_check
FROM oracle_t_bank_account ora
JOIN T_BANK_ACCOUNT kbs ON ora.ACC_ID = kbs.ACC_ID
WHERE ora.ACC_ID IN ('6228480010000000001', '6228480010000000002', '6228480010000000003');
-- 校验3:增量同步延迟监控(实时查看当前同步位点)
SELECT
current_timestamp AS check_time,
pg_current_wal_lsn() AS current_lsn,
pg_last_xact_replay_timestamp() AS last_replay_time,
extract(epoch from (current_timestamp - pg_last_xact_replay_timestamp())) AS delay_seconds;代码说明:该案例展示生产环境中KDTS增量同步的核心配置参数与数据一致性校验的完整SQL方案。配置文件涵盖源端Oracle的LogMiner捕获、目标端KingbaseES的批量加载优化、断点续传机制及事务一致性保障;SQL脚本通过oracle_fdw外部表实现跨库数据实时比对,支持行数校验、字段级哈希比对及同步延迟监控,确保TB级数据迁移后的一致性100%达标。所有配置均经过金融核心系统生产验证,可直接用于实际迁移项目。
3.4.4 数据一致性校验:全维度,无死角
数据迁移的核心要求是数据一致性100% ,因此需要进行全维度、无死角的数据一致性校验,包括:
1.行数校验:校验目标数据库中每张表的行数与Oracle环境完全一致;
2.数据值校验:随机抽取每张表的部分数据,校验数据值与Oracle环境完全一致;
3.索引校验:校验目标数据库中的索引是否有效、与Oracle环境的索引结构一致;
-
约束校验:校验目标数据库中的主键、外键、唯一约束、非空约束等是否与Oracle环境一致;
-
事务一致性校验:校验跨表、跨库的事务数据是否一致,确保事务的原子性、一致性、隔离性、持久性。
只有当所有校验项都通过后,才能确认数据迁移完成,进入后续的测试验证阶段。
3.5 第五阶段:测试验证------全链路,多维度,生产级验证
测试验证是Oracle替换的关键环节,核心目标是全链路、多维度 验证目标数据库的功能、兼容性、性能、高可用能力是否达到生产级要求,确保迁移后业务系统能够稳定、可靠、高效运行。测试验证不能仅在测试环境进行,还需要在准生产环境进行生产级的压力测试和高可用测试,模拟生产环境的业务负载和故障场景。
3.5.1 功能测试:全业务流程验证
功能测试的核心是验证目标数据库上的应用功能与Oracle环境完全一致,覆盖企业的所有核心业务流程,包括:
-
核心交易业务:如金融行业的转账、支付、信贷,运营商行业的开户、计费、缴费,交通行业的售票、检票、调度等;
-
数据查询业务:包括简单查询、复杂多表关联查询、聚合查询、分页查询等;
-
数据管理业务:包括数据录入、更新、删除、批量导入导出等;
4.批处理业务:如金融行业的日终批处理、月终批处理,运营商行业的话单批处理等。
功能测试的核心标准是:所有业务流程正常运行,业务逻辑无偏差,数据处理结果与Oracle环境完全一致。
3.5.2 兼容性测试:全场景兼容验证
兼容性测试的核心是验证目标数据库与企业现有技术架构的全场景兼容,包括:
-
应用框架兼容:验证Spring Boot、SSM、微服务框架等与目标数据库的兼容;
-
数据库访问中间件兼容:验证MyBatis、Hibernate、JDBC、数据库连接池(Druid、HikariCP)等与目标数据库的兼容;
-
运维工具兼容:验证企业现有的监控工具、备份工具、自动化运维工具等与目标数据库的兼容;
-
第三方系统兼容:验证目标数据库与企业现有第三方系统(如ERP、CRM、BI)的兼容。
兼容性测试的核心标准是:企业现有技术架构无需改造,可直接与目标数据库集成,正常运行。
3.5.3 性能测试:生产级负载验证
性能测试的核心是模拟生产环境的业务负载,验证目标数据库的性能是否达到或超过Oracle生产水平 ,性能测试的指标包括TPS、QPS、响应时间、并发数、CPU使用率、内存使用率、磁盘IO、网络IO等,覆盖正常负载、高峰负载、超高峰负载三种场景。
性能测试的核心步骤包括:
-
负载建模:根据Oracle生产环境的性能指标,建立生产级的业务负载模型;
-
负载压测:使用压力测试工具(如JMeter、LoadRunner)向目标数据库施加生产级负载,持续运行一定时间(如72小时);
-
性能监控:实时监控目标数据库的性能指标,记录TPS、QPS、响应时间等数据;
-
性能分析:对比目标数据库与Oracle生产环境的性能指标,分析性能差异,进行针对性的性能调优。
性能测试的核心标准是:目标数据库在正常负载、高峰负载、超高峰负载下的TPS、QPS不低于Oracle生产水平,响应时间不高于Oracle生产水平,系统资源使用率处于合理范围。例如,金融行业核心交易系统的TPS需达到5000以上,响应时间≤50ms,CPU使用率≤70%,内存使用率≤80%,磁盘IO吞吐量≥1GB/s,网络IO无丢包、延迟≤10ms,确保高峰时段业务无卡顿、无超时。
针对性能测试中发现的瓶颈问题,需进行精细化调优,核心调优方向包括:优化执行计划(调整索引、优化SQL语句)、内存管理调优(调整缓冲池大小、连接池参数)、存储调优(分区表优化、存储引擎选择)、并发控制调优(调整锁机制、事务隔离级别),通过多轮调优,确保目标数据库性能达到生产要求。
3.5.4 高可用测试:故障场景模拟验证
高可用测试的核心是模拟生产环境的各种故障场景,验证目标数据库的高可用架构是否能够实现故障自切换、服务零中断、数据零丢失,高可用测试的故障场景包括:
-
数据库节点故障:模拟目标数据库集群中的某个节点宕机,验证集群是否能够快速切换,业务是否持续运行;
-
网络故障:模拟数据库节点之间的网络中断,验证集群是否能够避免脑裂,业务是否不受影响;
-
存储故障:模拟数据库存储设备故障,验证目标数据库是否能够快速切换到备用存储,数据是否不丢失;
-
机房故障:模拟同城机房故障,验证目标数据库是否能够切换到异地机房,实现两地三中心的容灾保障。
高可用测试的核心标准是:所有故障场景下,目标数据库能够在30秒内完成故障切换,服务零中断(RTO=0),数据零丢失(RPO=0),业务持续正常运行。测试过程中,需实时监控故障切换时间、数据一致性、业务连续性,记录切换过程中的日志,确保切换过程可追溯、可复现。
3.5.5 压力测试:长时间稳定运行验证
压力测试的核心是对目标数据库进行长时间的高负载压力测试,验证其稳定性和可靠性 ,压力测试的持续时间一般为72小时以上,模拟企业生产环境的连续运行场景,检验目标数据库在长时间高负载下是否会出现内存泄漏、连接池耗尽、性能下降等问题。
压力测试的核心标准是:目标数据库在72小时以上的高负载压力测试中,性能稳定,无内存泄漏、无连接池耗尽、无服务中断等问题,数据一致性保持100%。压力测试完成后,需生成详细的压力测试报告,包括测试场景、测试负载、性能指标变化、异常情况及处理结果,为后续的生产割接提供数据支撑。
3.6 第六阶段:生产割接------灰度上线,无缝切换,业务无感知
生产割接是Oracle替换的最终环节,核心目标是将企业的生产业务从Oracle环境无缝切换到目标数据库环境,采用"灰度割接、分步上线"的策略,最小化割接对业务的影响,确保割接过程平稳、可控,业务无感知。
3.6.1 割接前准备:万全准备,风险防控
生产割接前,需要进行万全的准备工作,识别割接过程中的所有风险点,制定防控措施,确保割接工作顺利进行:
-
环境准备:确保目标数据库生产环境的部署、配置、调优全部完成,达到生产要求;
-
工具准备:确保数据迁移工具、应用切换工具、监控工具、回滚工具全部就绪,正常运行;
-
人员准备:成立割接专项小组,包括DBA、开发人员、测试人员、业务人员、运维人员,明确各人员的职责和分工;
-
数据准备:确保源端Oracle与目标数据库的数据实时同步,数据一致性100%;
-
测试准备:完成所有测试验证工作,测试报告通过评审;
-
应急准备:制定完善的应急处理方案,准备好应急处理的人员和工具;
-
割接培训:对割接专项小组进行割接流程和应急处理培训,确保所有人员熟悉割接步骤和操作方法。
割接前需要进行割接演练,模拟生产割接的全流程,检验割接方案的可行性、人员的操作熟练度、应急处理方案的有效性,发现问题及时整改。演练至少进行2次,确保割接过程中的每个环节都无遗漏、无差错。
3.6.2 割接窗口选择:最小化业务影响
生产割接需要选择业务低峰期作为割接窗口,最大限度减少割接对业务的影响,割接窗口的选择原则包括:
-
业务交易量最小:选择企业业务交易量最小的时间段,如凌晨0点-4点;
-
业务影响最小:选择非核心业务时段,避免在核心业务时段进行割接;
-
割接时间充足:确保割接窗口的时间足够完成割接工作和业务验证,一般建议割接窗口≥4小时。
割接窗口确定后,需提前通知业务部门和相关人员,明确割接时间、影响范围、应急联系方式,确保相关人员随时待命。
四、总结
本文系统阐述了基于金仓KingbaseES的Oracle数据库国产化替代全流程工程实践。针对企业"去O"过程中的PL/SQL深度兼容、海量数据迁移、高可用架构切换等核心痛点,提出了"低改造、低风险、高兼容、高性能"四大技术原则,并拆解为七个标准化实施阶段:
技术落地层面,KingbaseES通过PL/SQL全量兼容实现应用层"零改造"或"微改造",借助KMA评估工具、KSC代码适配工具、KDTS数据迁移工具构建完整的自动化工具链,将TB级数据迁移效率提升至100GB/h以上,增量同步延迟控制在1秒内,实现业务无感知的在线迁移。
工程化保障层面,通过同城双中心、两地三中心等高可用架构设计,达成RPO=0、RTO≤30秒的生产级容灾标准;结合全链路功能测试、生产级性能压测、故障场景模拟验证等多维度质量保障体系,确保迁移后系统性能不低于Oracle生产水平。
风险控制层面,采用"灰度割接、分步上线"策略配合完善的回滚机制,将业务中断风险降至最低。所有技术方案均经过金融、能源、运营商等核心领域生产环境验证,形成从迁移评估到运维监控的闭环管理体系。
金仓KingbaseES的Oracle替换实践表明,国产化数据库迁移并非简单的平替,而是通过体系化的工程方法、专业化的工具支撑、标准化的流程管控,实现技术架构升级与业务连续性保障的双重目标,为企业信创转型提供可落地、可复现、低风险的实践路径。