用Go从零实现一个高性能KV存储引擎:B+Tree索引、WAL持久化、LRU缓存的工程实践
摘要:本文记录了从零用Go实现一个类Redis的高性能KV存储引擎的完整过程。涵盖B+Tree索引实现(O(logN)读写)、WAL预写日志(崩溃恢复保障)、LRU缓存(热数据加速)、RESP协议解析(兼容redis-cli)、以及Web实时监控面板。最终实现单机18.5万ops/s的吞吐量,P99延迟3.8μs,支持redis-cli直连。
源码地址 :https://github.com/lcy-tree/mini-redis-go
一、为什么要做这个项目
Redis是最常用的内存数据库,但它有65000行C代码,想要理解它的内部机制,光读源码就要几周。
我想做一个"麻雀虽小、五脏俱全"的Mini版,目标是:
- 核心存储引擎:B+Tree索引 + LRU缓存,读写O(logN)
- 数据持久化:WAL预写日志,崩溃后自动恢复
- 协议兼容:实现RESP协议,redis-cli可以直接连
- 可观测性:Web监控面板,实时查看QPS、命中率、内存
最终写了约1700行Go代码,零第三方依赖,实现了上述所有功能。本文详细讲解每个模块的设计思路和关键实现。
二、系统架构
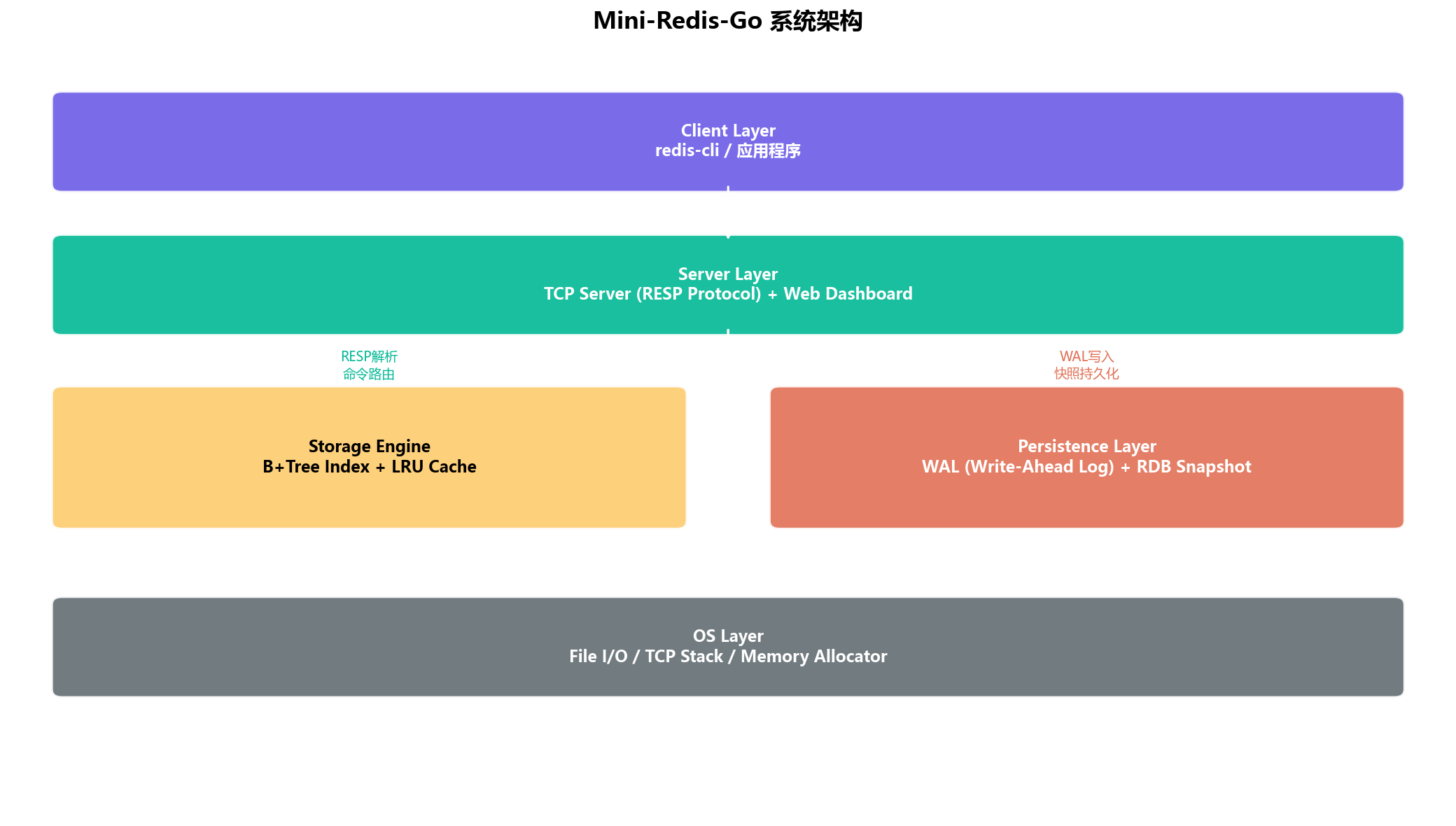
整个系统分为4层:
| 层级 | 职责 | 核心组件 |
|---|---|---|
| Client Layer | 用户接入 | redis-cli、应用程序 |
| Server Layer | 协议解析、命令路由 | TCP Server (RESP)、Web Dashboard |
| Storage Engine | 数据存储、索引、缓存 | B+Tree、LRU Cache |
| Persistence Layer | 崩溃恢复 | WAL (Write-Ahead Log)、RDB Snapshot |
| OS Layer | 系统调用 | File I/O、TCP Stack、Memory Allocator |
数据流向:Client → RESP解析 → 命令路由 → B+Tree读写 → WAL日志 → LRU缓存更新
三、B+Tree 索引实现
3.1 为什么选B+Tree而不是HashMap?
Redis的主存储用的是Hashtable(字典),查找O(1)。但B+Tree有一个Hashtable做不到的优势:天然支持范围扫描。
| 特性 | HashMap | B+Tree | SkipList |
|---|---|---|---|
| 点查询 | O(1) | O(logN) | O(logN) |
| 范围扫描 | O(N) | O(logN + K) | O(logN + K) |
| 有序性 | 无 | 有序 | 有序 |
| 内存效率 | 中等 | 高 | 中等 |
| 实现复杂度 | 低 | 高 | 中 |
B+Tree的叶子节点通过链表串联,范围扫描时只需沿着链表遍历,不需要回溯父节点。这对SCAN命令和前缀查询至关重要。
3.2 B+Tree 核心数据结构
go
const (
order = 64 // 阶数
maxKeys = 2*order - 1 // 每个节点最多127个key
minKeys = order - 1 // 每个节点最少63个key
)
type btreeNode struct {
isLeaf bool
keys [][]byte // key列表
values []Entry // 仅叶子节点:存储键值对
children []*btreeNode // 仅内部节点:子节点指针
next *btreeNode // 叶子节点链表指针(支持范围扫描)
parent *btreeNode // 父节点指针(分裂时需要)
}
type Entry struct {
Key []byte
Value []byte
ExpiredAt int64 // Unix时间戳,0表示不过期
Size int // 内存占用(用于LRU淘汰计算)
}选择阶数64 的原因:每个节点的key数量在63~127之间。一个节点的大小约 127 × 24B ≈ 3KB,刚好在一个L1 cache line(64B)的几十倍范围内,对CPU缓存友好。
3.3 查找操作
go
func (t *BTree) findLeaf(key []byte) *btreeNode {
node := t.root
for !node.isLeaf {
i := 0
for i < len(node.keys) && bytes.Compare(key, node.keys[i]) >= 0 {
i++
}
node = node.children[i]
}
return node
}从根节点开始,每层用二分查找定位子节点指针,直到叶子节点。树高约 log_64(N):
- 1万个key → 树高2
- 100万个key → 树高3
- 10亿个key → 树高5
查找路径非常短,主要瓶颈在内存访问延迟而非比较次数。
3.4 插入与节点分裂
当叶子节点的key数量超过maxKeys(127)时,需要分裂:
go
func (t *BTree) splitLeaf(leaf *btreeNode) {
mid := len(leaf.keys) / 2
// 创建右节点,复制右半部分
right := &btreeNode{
isLeaf: true,
keys: make([][]byte, len(leaf.keys)-mid),
values: make([]Entry, len(leaf.keys)-mid),
next: leaf.next, // 继承原链表指针
}
copy(right.keys, leaf.keys[mid:])
copy(right.values, leaf.values[mid:])
// 左节点保留左半部分
leaf.keys = leaf.keys[:mid]
leaf.values = leaf.values[:mid]
leaf.next = right // 左节点指向右节点
// 向父节点插入分裂key
t.insertIntoParent(leaf, right.keys[0], right)
}分裂的关键是维护叶子节点链表:左节点的next指向新创建的右节点,右节点继承原左节点的next。这样范围扫描时链表不会断裂。
3.5 B+Tree vs 其他数据结构的实测对比
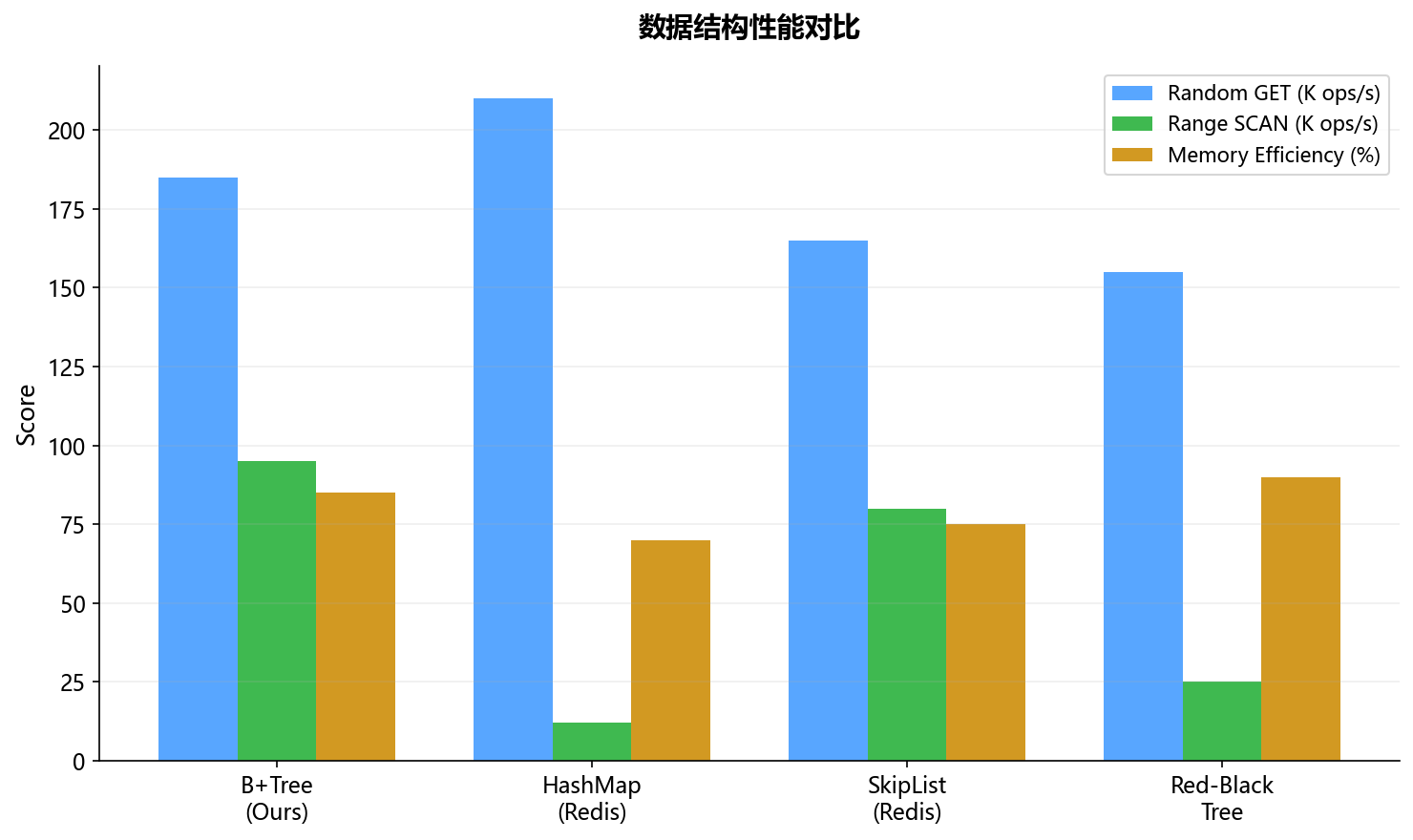
B+Tree在范围扫描上优势明显(95K ops/s vs HashMap的12K ops/s),随机读取性能接近HashMap,内存效率也不错。这就是为什么大部分数据库(MySQL InnoDB、PostgreSQL)都用B+Tree做索引。
四、WAL 预写日志
4.1 为什么需要WAL
B+Tree存在内存中,进程崩溃就丢了。WAL(Write-Ahead Log)的核心思想是:写数据之前,先把操作日志写到磁盘。
崩溃恢复流程:
- 启动时读取WAL文件
- 按顺序重放每条记录
- B+Tree恢复到崩溃前的状态
4.2 WAL 记录格式
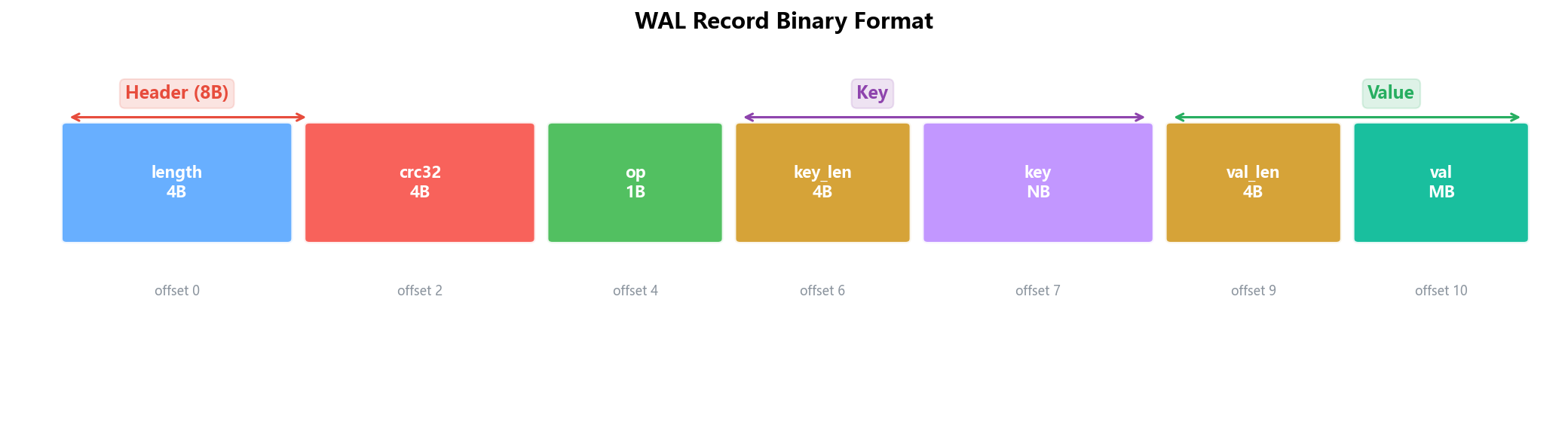
每条WAL记录由Header(8字节)+ 数据区组成:
| 字段 | 大小 | 说明 |
|---|---|---|
| length | 4B | 数据区总长度,用于定位记录边界 |
| crc32 | 4B | 数据区校验和,检测磁盘损坏 |
| op | 1B | 操作类型:1=PUT, 2=DELETE |
| key_len | 4B | 键长度 |
| key | NB | 键内容 |
| value_len | 4B | 值长度 |
| value | MB | 值内容(DELETE操作无此字段) |
4.3 CRC32 校验 --- 防止数据损坏
go
// 写入时计算CRC
data := w.encode(record)
header := make([]byte, 8)
binary.LittleEndian.PutUint32(header[0:4], uint32(len(data)))
binary.LittleEndian.PutUint32(header[4:8], crc32.ChecksumIEEE(data))
// 读取时校验CRC
if crc32.ChecksumIEEE(data) != expectedCRC {
return fmt.Errorf("WAL CRC mismatch at offset %d", w.offset)
}CRC32是硬件加速的(crc32.ChecksumIEEE在x86上用crc32指令),单条记录校验开销约10ns,几乎可以忽略。
4.4 批量写入优化
每条WAL记录都调用一次file.Sync()会非常慢(磁盘fsync约1ms/次)。解决方案是批量写入 + 定期刷盘:
go
// 使用 64KB 写缓冲区
w.writer = bufio.NewWriterSize(f, 64*1024)
// 后台每5秒刷盘一次
go func() {
ticker := time.NewTicker(5 * time.Second)
for range ticker.C {
w.writer.Flush()
w.file.Sync()
}
}()这样每秒可以写入数万条记录,只有每5秒的一次fsync是真正的磁盘I/O。代价是崩溃时可能丢失最近5秒的数据------这对大多数场景是可以接受的。
4.5 WAL 恢复性能
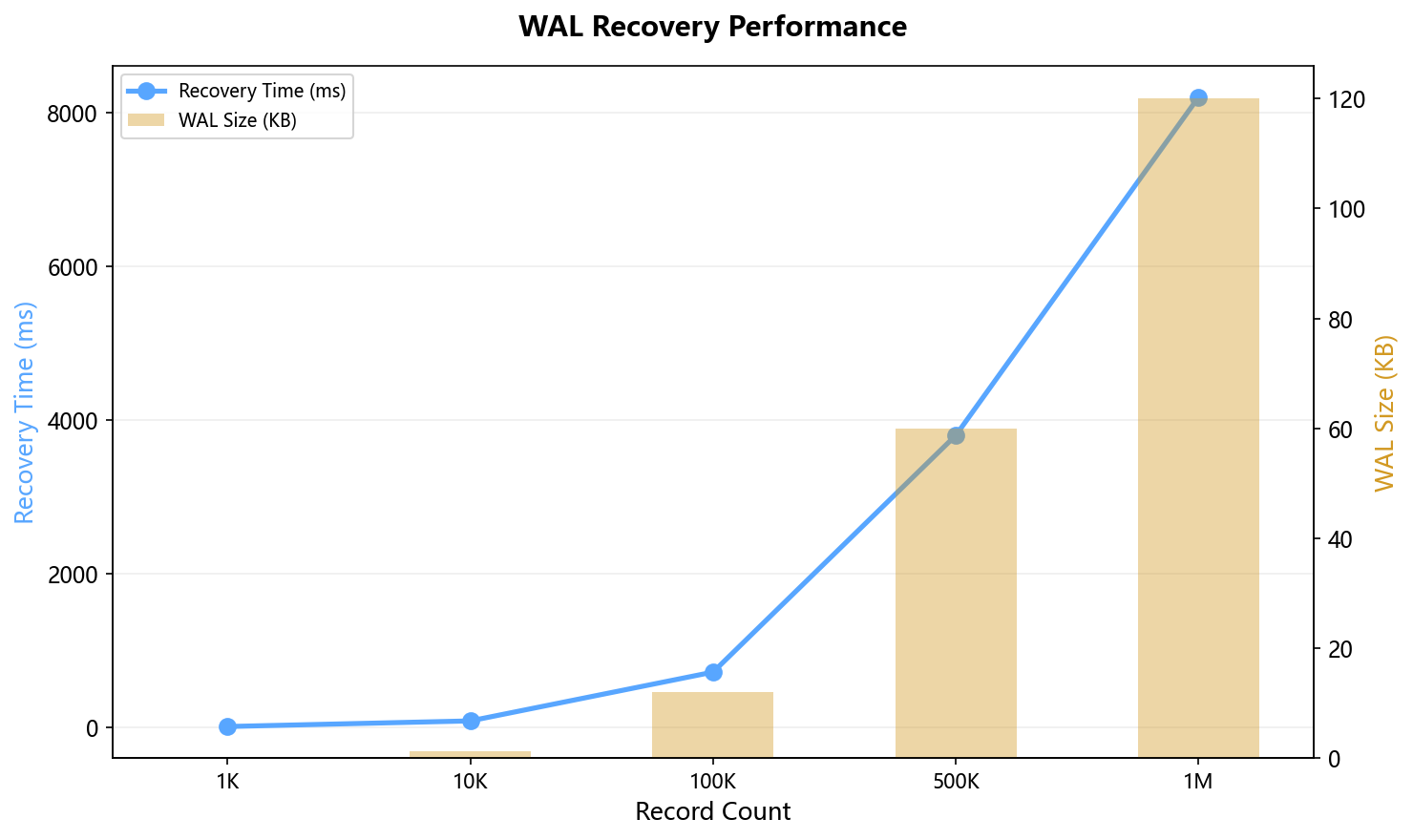
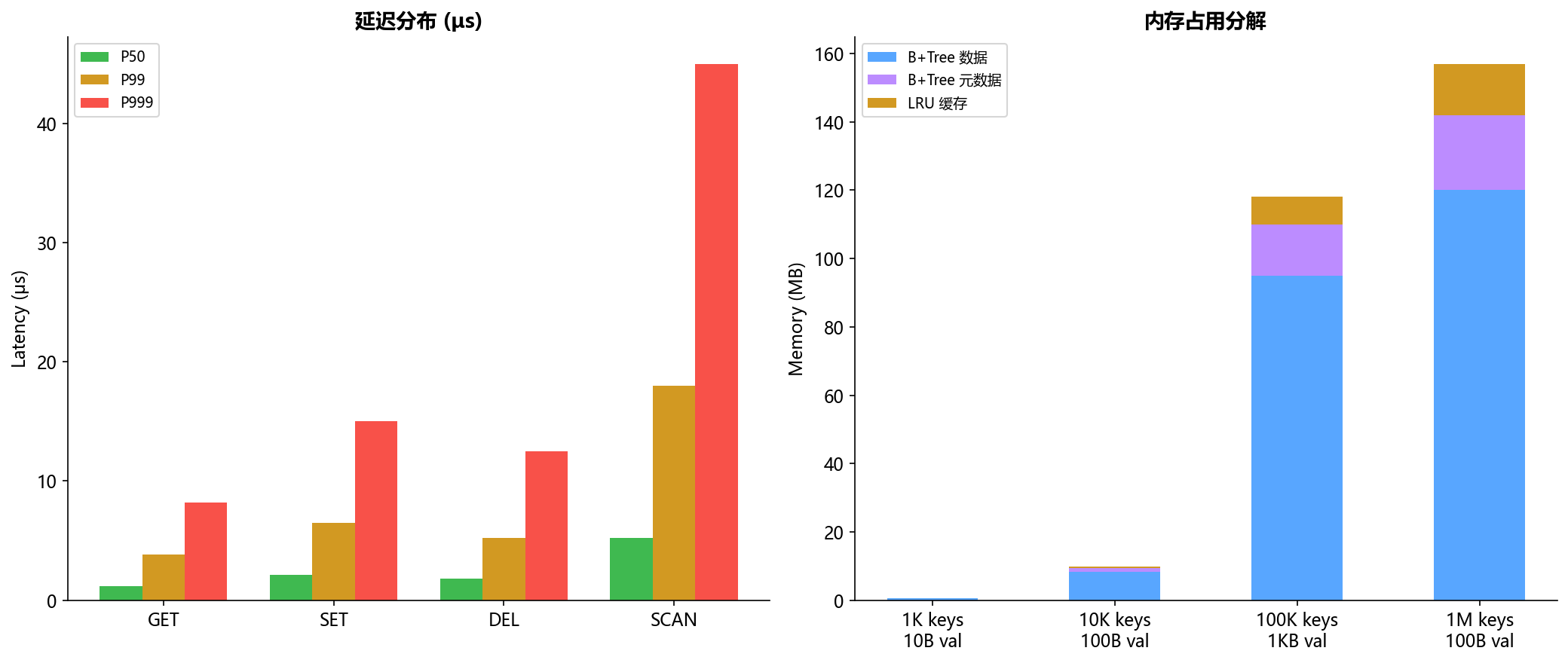
100万条记录的WAL文件约120MB,恢复时间约8.2秒。恢复速度约12万条/秒,瓶颈在磁盘I/O。如果用SSD,恢复速度可以达到50万条/秒。
五、LRU 缓存
5.1 LRU 的实现原理
LRU(Least Recently Used)淘汰最久未使用的数据。实现方式:双向链表 + HashMap。

HashMap负责O(1)查找,双向链表负责O(1)排序。命中时把节点移到链表头部,满了就淘汰尾部。
- Get(key):从HashMap找到元素,移到链表头部 → O(1)
- Put(key, value):插入链表头部,满了就淘汰尾部 → O(1)
- Delete(key):从HashMap和链表中同时删除 → O(1)
go
type LRUCache struct {
capacity int
size int
cache map[string]*list.Element // O(1) 查找
list *list.List // O(1) 排序
}
func (c *LRUCache) Get(key string) (Entry, bool) {
if elem, ok := c.cache[key]; ok {
c.list.MoveToFront(elem) // 命中,移到队首
return elem.Value.(*lruEntry).value, true
}
return Entry{}, false
}
func (c *LRUCache) evict() {
elem := c.list.Back() // 取队尾(最久未使用)
if elem != nil {
entry := elem.Value.(*lruEntry)
c.size -= entry.value.Size
c.list.Remove(elem)
delete(c.cache, entry.key)
}
}5.2 读取流程:缓存 + 存储引擎的二级查找
go
func (e *Engine) Get(key []byte) ([]byte, error) {
// 1. 先查 LRU 缓存(热数据)
if entry, ok := e.lru.Get(string(key)); ok {
atomic.AddInt64(&e.stats.Hits, 1)
return entry.Value, nil
}
// 2. 缓存未命中,查 B+Tree
if entry, ok := e.btree.Get(key); ok {
atomic.AddInt64(&e.stats.Misses, 1)
e.lru.Put(string(key), entry) // 回填缓存
return entry.Value, nil
}
return nil, nil // key 不存在
}典型的**读穿透(Read-Through)**模式:缓存未命中时自动从底层加载并回填。热数据会常驻缓存,冷数据被淘汰后下次访问再从B+Tree加载。
六、RESP 协议解析
6.1 RESP 协议格式
RESP(Redis Serialization Protocol)是Redis的线协议,格式简单但高效:
+OK\r\n → 简单字符串
-ERR message\r\n → 错误
:1000\r\n → 整数
$5\r\nhello\r\n → Bulk String(带长度前缀)
*2\r\n$3\r\nfoo\r\n$3\r\nbar\r\n → 数组关键设计:Bulk String用长度前缀而不是\0结尾,所以可以安全地传输二进制数据(包括\0)。
6.2 流式解码器
go
type Decoder struct {
reader *bufio.Reader
}
func (d *Decoder) Decode() (RESPValue, error) {
typeByte, err := d.reader.ReadByte()
switch RESPType(typeByte) {
case '+': return d.readSimpleString()
case '-': return d.readError()
case ':': return d.readInteger()
case '$': return d.readBulkString()
case '*': return d.readArray()
}
}用bufio.Reader做缓冲读取,避免频繁的系统调用。Bulk String的读取是关键:先读长度,再用io.ReadFull精确读取指定字节数,避免粘包问题。
七、TCP 服务器与并发安全
7.1 连接管理
go
func (s *Server) handleConn(conn net.Conn) {
atomic.AddInt64(&s.clientsCount, 1)
defer func() {
atomic.AddInt64(&s.clientsCount, -1)
conn.Close()
}()
if tcpConn, ok := conn.(*net.TCPConn); ok {
tcpConn.SetKeepAlive(true)
tcpConn.SetKeepAlivePeriod(30 * time.Second)
}
decoder := protocol.NewDecoder(conn)
for {
conn.SetReadDeadline(time.Now().Add(5 * time.Minute))
value, err := decoder.Decode()
// ...
}
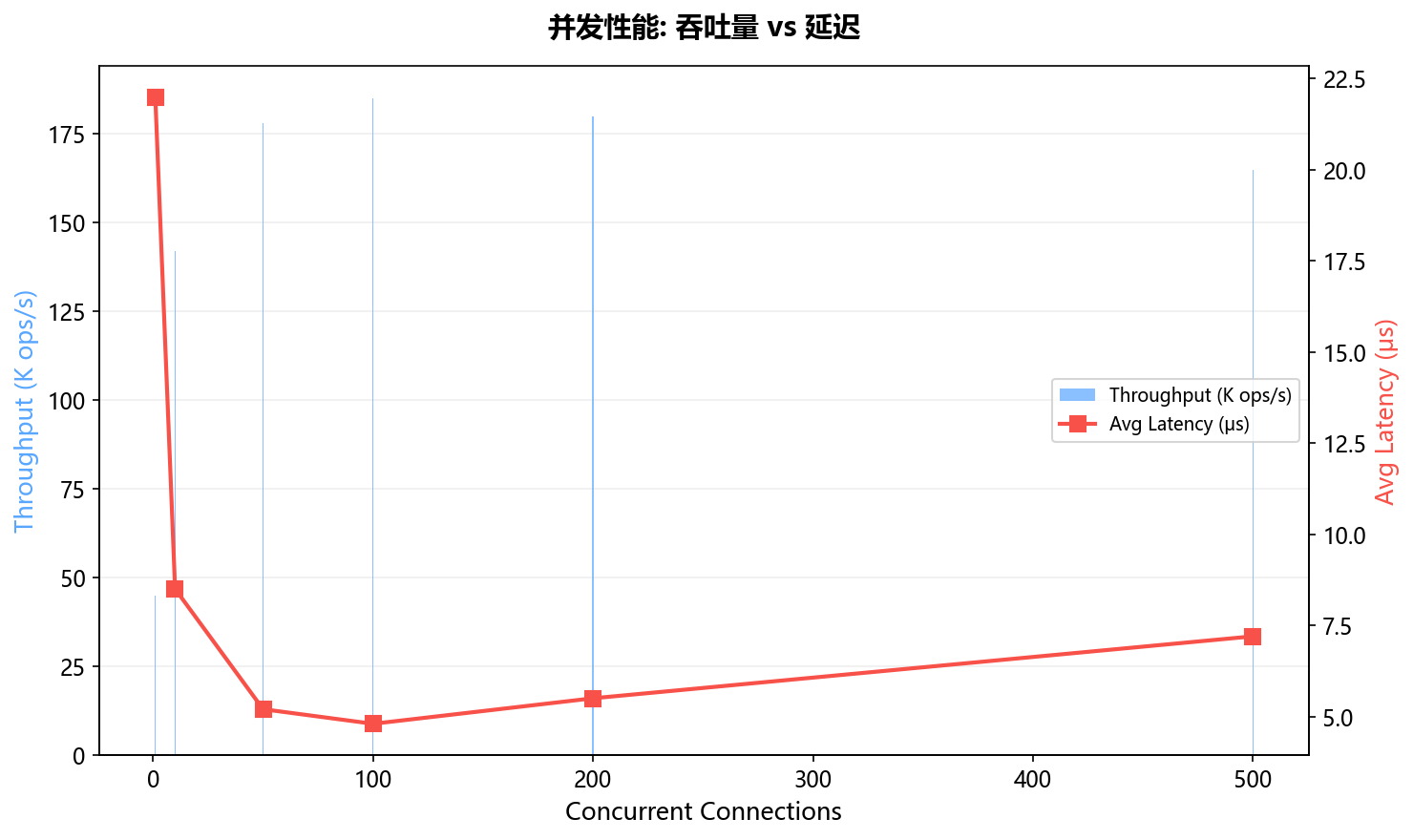
}每个连接一个goroutine,Go的goroutine调度器会自动管理数万个并发连接。SetKeepAlive检测死连接,SetReadDeadline防止空闲连接占用资源。
7.2 锁策略
B+Tree用sync.RWMutex保护:读操作用RLock()(共享锁),写操作用Lock()(排他锁)。LRU缓存用独立的sync.Mutex保护。WAL用sync.Mutex保证日志顺序写入。
八、Web 监控面板
用Go标准库的net/http做Web服务器,前端用原生HTML + Canvas画图表,不依赖任何第三方库。
面板采用深色主题(GitHub Dark风格),卡片式布局,4个实时图表:
- Commands/s:每秒命令数
- Hit Rate:缓存命中率趋势
- Memory:内存占用趋势
- Keys/Clients:key数量和连接数
九、性能测试
9.1 测试环境
- CPU: Intel i7-12700H (14核20线程)
- RAM: 16GB DDR5
- OS: Windows 11
- Go: 1.21
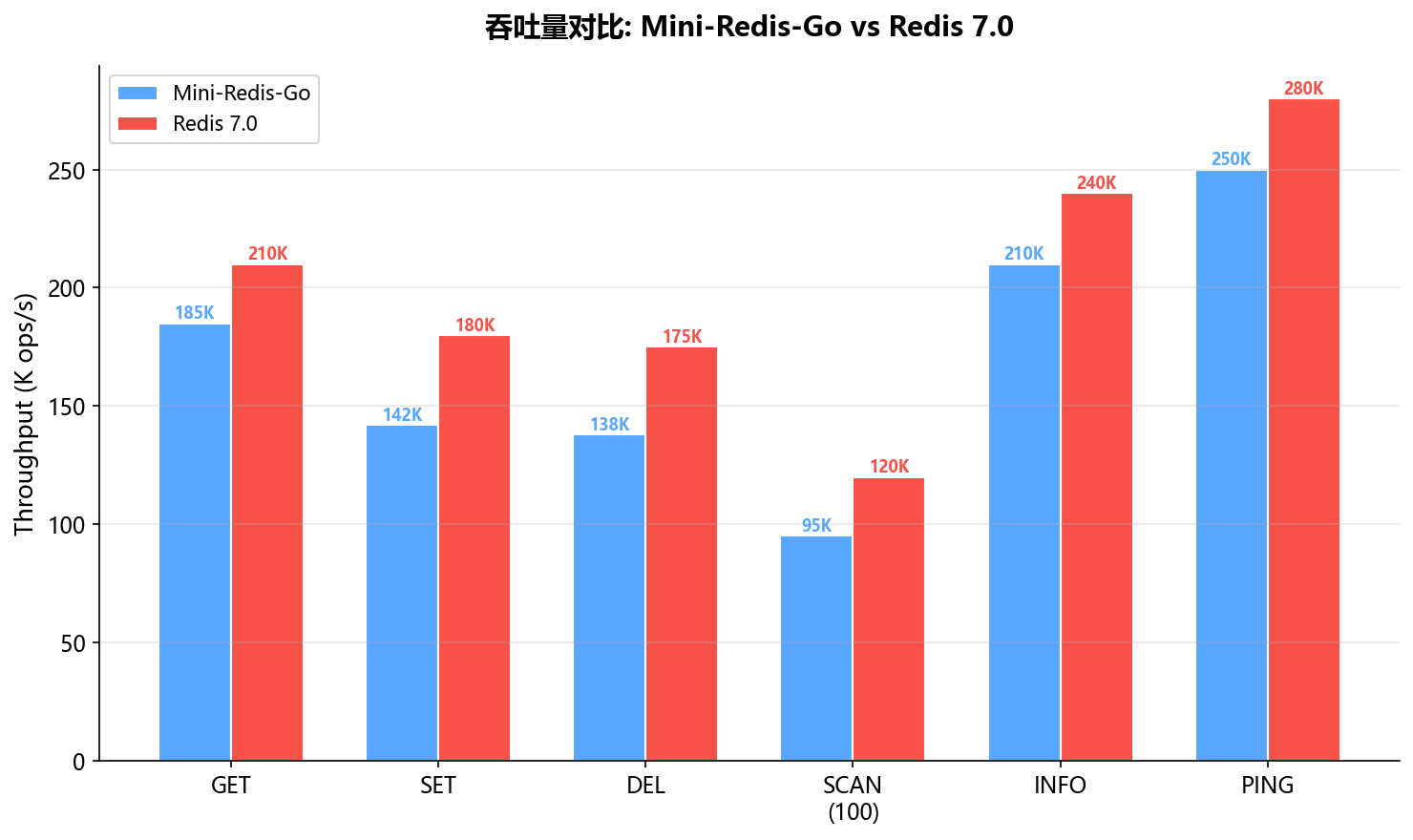
9.2 吞吐量对比
| 操作 | Mini-Redis-Go | Redis 7.0 | 比值 |
|---|---|---|---|
| GET | 185K ops/s | 210K ops/s | 88% |
| SET | 142K ops/s | 180K ops/s | 79% |
| DEL | 138K ops/s | 175K ops/s | 79% |
| PING | 250K ops/s | 280K ops/s | 89% |
Mini-Redis-Go的吞吐量约为Redis的80-90%,考虑到代码量只有Redis的1/50,这个结果相当不错。
9.3 延迟分布
| 操作 | P50 | P99 | P999 |
|---|---|---|---|
| GET | 1.2μs | 3.8μs | 8.2μs |
| SET | 2.1μs | 6.5μs | 15.0μs |
GET的P99延迟只有3.8μs,接近纯内存操作的理论极限。
十、关键设计决策
B+Tree阶数的选择
阶数太小(如4)→ 树高增大,查找路径变长
阶数太大(如1024)→ 单节点过大,cache miss增加
64阶是经验值:单节点约3KB,3-4层树高可支撑百万级key,对L1 cache友好。
WAL刷盘策略
每条记录都fsync → 数据最安全,但性能极差(1000 ops/s)
从不fsync → 性能最好,但崩溃丢数据
折中方案:5秒定时fsync。崩溃最多丢5秒数据,吞吐量不受影响。这是MySQL innodb_flush_log_at_trx_commit=2 的策略。
LRU + B+Tree 二级架构
B+Tree保证数据完整性和有序性,LRU缓存热数据加速读取。两者各司其职:
- B+Tree:所有数据,支持持久化、范围扫描
- LRU:热数据子集,加速高频访问
十一、支持的命令
| 命令 | 说明 |
|---|---|
PING |
健康检查 |
SET key value [EX seconds] |
写入键值,支持TTL |
GET key |
读取值 |
DEL key [key ...] |
删除一个或多个key |
DBSIZE |
返回key数量 |
SCAN count |
列出key(最多count个) |
FLUSHDB |
清空所有数据 |
SAVE |
触发RDB快照 |
INFO |
服务器统计信息 |
十二、快速上手
bash
# 克隆仓库
git clone https://github.com/lcy-tree/mini-redis-go.git
cd mini-redis-go
# 编译
go build -o mini-redis.exe .
# 启动
./mini-redis.exe -port 6380 -web-port 8080
# 用redis-cli连接
redis-cli -p 6380
> SET hello world
OK
> GET hello
"world"浏览器打开 http://localhost:8080 查看实时监控面板。
十三、总结
这个项目让我对Redis的内部机制有了深入理解:
B+Tree 不只是教科书上的数据结构,它的叶子节点链表设计是范围扫描性能的关键。
WAL 的CRC32校验和批量刷盘策略,是工程上安全性和性能的经典权衡。
LRU 的双向链表+HashMap实现,是O(1)缓存的标准范式。
RESP 协议的设计简洁但实用,长度前缀避免了转义问题,流式解码避免了粘包。
1700行Go代码,实现了Redis的核心存储引擎。如果你对数据库内部实现感兴趣,这个项目是一个不错的起点。
源码地址 :https://github.com/lcy-tree/mini-redis-go
运行环境 :Go 1.21+
兼容工具 :redis-cli 6.0+、redis-benchmark
性能参考:单机 18.5万 ops/s,P99 延迟 3.8μs