背景,汇总学习AI基础概念,做扫盲使用。
文章目录
-
- 一、AI相关基础概念
-
- [1. 人工智能AI---让机器模仿人类的智能行为(看、听、说、理解、推理、决策、创造)](#1. 人工智能AI---让机器模仿人类的智能行为(看、听、说、理解、推理、决策、创造))
- [2. AI的四次浪潮发展---符号主义/统计机器学习ML/深度学习DL/大语言模型LLM](#2. AI的四次浪潮发展---符号主义/统计机器学习ML/深度学习DL/大语言模型LLM)
- 二、大语言模型LLM(第四次AI浪潮)基础概念
-
- [1. 大语言模型LLM---一个超级大的、专门用来预测 "下一个词" 的神经网络函数](#1. 大语言模型LLM---一个超级大的、专门用来预测 “下一个词” 的神经网络函数)
- [2. LLM出现的背景---旧技术路线困境 与 Transformer出现+GPU算力的爆发](#2. LLM出现的背景---旧技术路线困境 与 Transformer出现+GPU算力的爆发)
- [3. Transformer---LLM基石,一个专门用来处理「序列数据」的神经网络架构](#3. Transformer---LLM基石,一个专门用来处理「序列数据」的神经网络架构)
- [4. 从「人类文字」到「LLM 计算」数据流水线---Token、Tokenizer、Token ID、Prompt、Context](#4. 从「人类文字」到「LLM 计算」数据流水线---Token、Tokenizer、Token ID、Prompt、Context)
- [5. LLM训练流程---预训练、后训练、微调、强化学习](#5. LLM训练流程---预训练、后训练、微调、强化学习)
- 三、大语言模型LLM软硬件层结构涉及概念
-
- [1. LLM软硬件层级总结---软件层/运算层/处理器层/核心加速单元/基础运算/物理底层](#1. LLM软硬件层级总结---软件层/运算层/处理器层/核心加速单元/基础运算/物理底层)
- [2. 运算层概念---矩阵运算、张量运算、卷积运算](#2. 运算层概念---矩阵运算、张量运算、卷积运算)
- [3. 处理器层概念---CPU、GPU、NPU、TPU、LPU](#3. 处理器层概念---CPU、GPU、NPU、TPU、LPU)
- [4. 核心加速单元---Tensor Core、AI Engine、FPU](#4. 核心加速单元---Tensor Core、AI Engine、FPU)
- [5. 基础运算层---ALU、MAC、乘法器、加法器](#5. 基础运算层---ALU、MAC、乘法器、加法器)
- 四、大语言模型LLM扩展优化与落地衍生相关技术
-
- [1. 智能体Agent---Agent=LLM+记忆+工具+规划,从"回答问题"变成"解决问题"](#1. 智能体Agent---Agent=LLM+记忆+工具+规划,从“回答问题”变成“解决问题”)
- [2. 模型上下文协议MCP---AI 与外部世界的统一连接标准,给Agent提供一套 "万能接口"](#2. 模型上下文协议MCP---AI 与外部世界的统一连接标准,给Agent提供一套 “万能接口”)
- [3. 检索增强生成RAG---LLM 的外部知识库,提高准确率和时效性](#3. 检索增强生成RAG---LLM 的外部知识库,提高准确率和时效性)
- 参考:
一、AI相关基础概念
1. 人工智能AI---让机器模仿人类的智能行为(看、听、说、理解、推理、决策、创造)
人工智能Artificial Intelligence。1956 年,在达特茅斯会议一群科学家提出"用机器模拟人类智能",这就是 AI 概念的起点。让机器模仿人类的智能行为,看、听、说、理解、推理、决策、创造。不是只会执行指令,而是能理解、能学习、能自己解决问题。在题案中最初几个关键目标:1)让机器使用语言(自然语言);2)让机器形成抽象概念;3)让机器解决原本只有人能解决的问题;4)让机器能够自己学习、自我改进。
最初的信念:人的大脑,本质也是一套复杂的 "计算系统"。既然是计算系统,就一定能用机器复现。
2. AI的四次浪潮发展---符号主义/统计机器学习ML/深度学习DL/大语言模型LLM
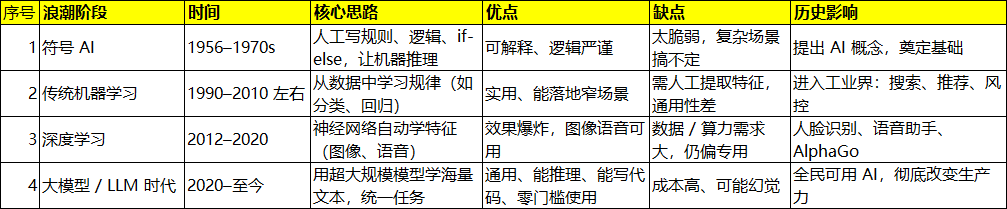
├── 符号AI(1956~1970s):人写规则 → 笨、不通用
├── 机器学习 ML(1990~2010s):数据学规律 → 专用、窄任务
├── 深度学习 DL(2012~2020s):神经网络学特征 → 图像语音可用
└── 大语言模型 LLM(2020~现在):统一文字/逻辑/推理/代码 → 通用智能
AI经历了四次发展浪潮,从 "人教规则" → 变成 "机器从海量数据里自己学会世界知识"。
二、大语言模型LLM(第四次AI浪潮)基础概念
1. 大语言模型LLM---一个超级大的、专门用来预测 "下一个词" 的神经网络函数
大型语言模型Large Language Model本质一个超级大的、专门用来预测 "下一个词" 的神经网络函数,主要目标是通过大规模的训练数据来学习自然语言的规律,并能够生成具有语义和语法正确性的文本。核心结构为 Transformer神经网络架构。
LLM 是怎么来的? 1) 把海量文字喂给它(书籍、网页、论文、代码、百科......);2) 让它做一个极其枯燥的任务(遮住一句话的最后一个词,让模型猜。猜错了就微调内部参数,猜对就保留。);3) 重复几百亿次 → 模型就 "懂了" 语言、逻辑、知识、代码。
LLM 为什么这么强? 1)小模型只会组词。大到一定规模后,突然出现:逻辑推理/代码能力/意图理解/常识;2)统一了所有任务,以前 AI 分:翻译、分类、摘要、对话、代码......现在全部统一成一种任务:预测下一个词。3)自然语言变成了 "通用接口",你不用写代码、配寄存器、画电路图。人类语言 = 最通用的编程接口。
LLM参数数量级。 单位B,代表Billion(10亿),参数 = 模型用来 "存知识、存规律、存结构" 的存储空间。参数到底 "存" 的是什么?不是存文字,而是存:词语之间的关系/语法结构/逻辑模式/代码规律/常识(比如天是蓝的、苹果是水果)/推理步骤(因为... 所以...)/参数越多,能存储的 "精细规律" 就越多。

LLM 本质:预测下一个词的概率;LLM= Transformer 结构 + 海量文本训练 + 超大参数
2. LLM出现的背景---旧技术路线困境 与 Transformer出现+GPU算力的爆发
人类想让机器理解语言,试了规则、统计、小模型全都不够强;之前所有路线,都解决不了「语言复杂 + 长程依赖 + 无法并行」三大死结。

直到 Transformer 解决了长上下文理解,又发现模型越大能力越强这条铁律;再加上 GPU 算力爆发、海量文本可获取;最终才走出了一条:用极端规模,直接从文本里学知识、学逻辑、学语言的路线,即LLM。
3. Transformer---LLM基石,一个专门用来处理「序列数据」的神经网络架构
Transformer是一种用于自然语言处理(NLP)和其他序列到序列(sequence-to-sequence)任务的深度学习模型架构,它在2017年由Vaswani等人首次提出。Transformer架构引入了最核心两个内容:a. 自注意力机制(self-attention mechanism),能让模型全局关联上下文彻底抛弃 循环 和 依次处理,采用一种能够一次性看到并处理整个序列中所有词的方法。 b. 多层网络堆叠,层越底层学语法、拼写,层越高层学逻辑、代码、推理、意图。形成了一个专门处理长文本序列的超级流水线。
Transformer解决了旧模型核心问题:1)长文本上下文记不住;2)不能并行训练跑得慢。所以它才成为LLM地基让大模型成为可能。
4. 从「人类文字」到「LLM 计算」数据流水线---Token、Tokenizer、Token ID、Prompt、Context
从「人类文字」到「LLM 计算」的完整数据流水线:用户输入 → Prompt → 历史对话 → Context→ Tokenizer → Token → Token ID → 送入 LLM→ 生成结果。大模型的任务就是算出当前这些token ID后,应该续写哪些token。

5. LLM训练流程---预训练、后训练、微调、强化学习
LLM 的训练就像培养一个人,整体流程如下:

从实用的视角,平时我们使用的AI,都走完预训练 → 微调 → 强化学习。如果我们要自己落地搭建一个现有的大模型使用,不用做预训练(太贵、最耗时,需要几个月甚至几年)只需要做 微调 / RAG 就够了。
三、大语言模型LLM软硬件层结构涉及概念
1. LLM软硬件层级总结---软件层/运算层/处理器层/核心加速单元/基础运算/物理底层
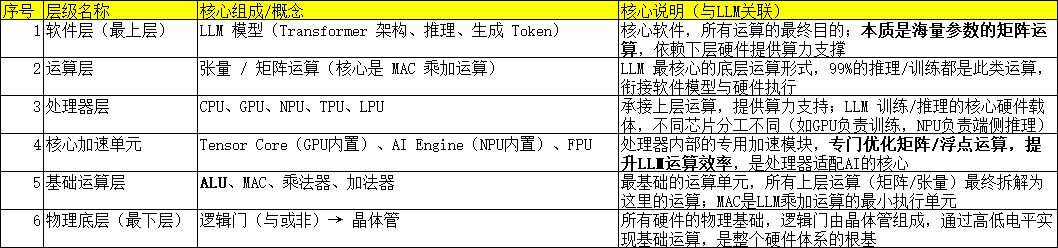
2. 运算层概念---矩阵运算、张量运算、卷积运算
运算层是LLM软件模型与硬件执行的核心衔接层,核心任务是执行LLM所需的底层运算,其中张量运算和矩阵运算是两大核心,二者紧密关联。
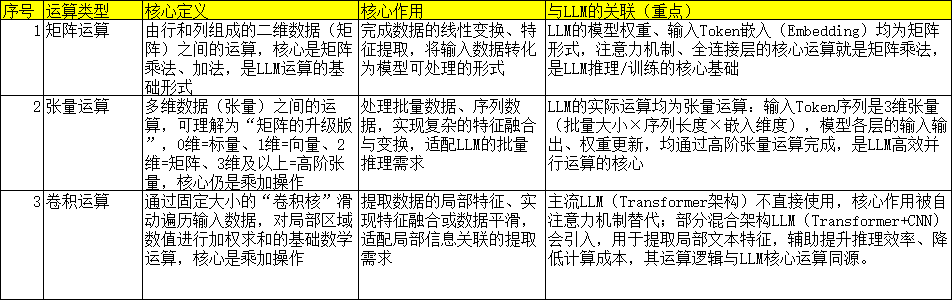
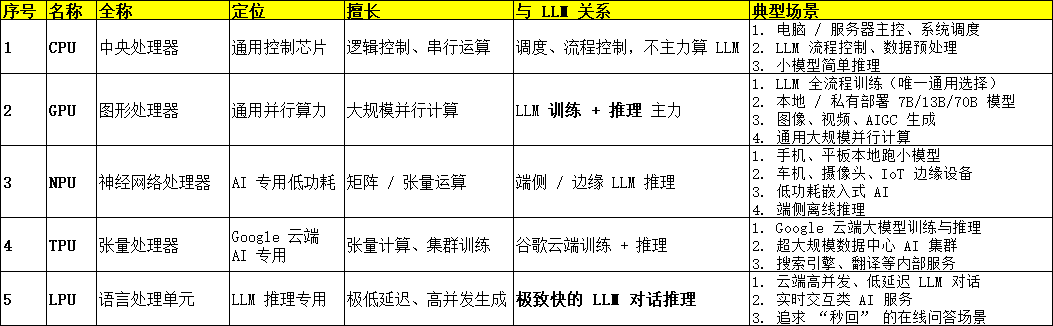
3. 处理器层概念---CPU、GPU、NPU、TPU、LPU
处理器层(CPU/GPU/NPU/TPU/LPU等)是LLM算力的核心载体,核心作用是承接运算层的张量/矩阵运算,为LLM的推理与训练提供基础算力支撑,与核心加速单元、基础运算层直接关联。
4. 核心加速单元---Tensor Core、AI Engine、FPU
核心加速单元是处理器层(CPU/GPU/NPU等)的内置专用模块,核心作用是优化LLM所需的张量/矩阵运算,提升运算效率、兼顾性能与功耗,与运算层的张量运算、矩阵运算直接关联。

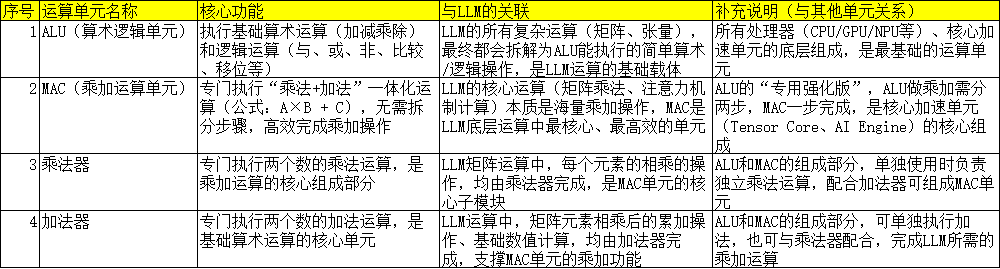
5. 基础运算层---ALU、MAC、乘法器、加法器
基础运算层(ALU、MAC、乘法器、加法器等)是所有运算的底层核心单元,核心作用是执行LLM所需的基础算术与乘加运算,将复杂的张量/矩阵运算拆解为简单可执行的操作
四、大语言模型LLM扩展优化与落地衍生相关技术
1. 智能体Agent---Agent=LLM+记忆+工具+规划,从"回答问题"变成"解决问题"
最早的含义Agent = 能行动的主体,来自拉丁语 agere,意思是「去做、去行动」。从早期的机器人、软件代理,它一直都在,只是能力一直有限。机器学习时代的 Agent 能学,但不懂沟通。大模型时代来了,Agent相当于LLM+记忆+工具+规划,大模型的推理能力足够强,能理解任务、分解目标,工具调用(Function Calling)机制稳定,AI 能主动"执行"操作。

Agent它不再只是一个聊天模型,而是一个能理解目标、规划路径、执行任务的自主系统
2. 模型上下文协议MCP---AI 与外部世界的统一连接标准,给Agent提供一套 "万能接口"
MCP(Model Context Protocol,模型上下文协议)是 Anthropic 在 2024 年底推出的AI 与外部世界的统一连接标准,就像 USB-C 让不同设备能够通过相同的接口连接一样。Agent 通过一套 MCP Client调用所有 MCP Server。我们在构造 prompt 时,没有MCP之前我们可能会人工从数据库中筛选或者使用工具检索可能需要的信息,手动粘贴到 prompt 中。随着我们要解决的问题越来越复杂,手工把信息引入到 prompt 中会变得越来越困难。为了克服手工 prompt 的局限性,许多 LLM 平台引入了 function call 功能(制允许模型在需要时调用预定义的函数来获取数据或执行操作)。但是 function call 也有其局限性,平台依赖性强,不同 LLM 平台的 function call API 实现差异较大,开发者在切换模型时需要重写代码,增加了适配成本。除此之外,还有安全性,交互性等问题。Anthropic 基于这样的痛点设计了 MCP,充当 AI 模型的"万能转接头",让 LLM 能轻松的获取数据或者调用工具。
一句话串起来:LLM 做 Function Calling 决策 → Agent 做规划 → 通过 MCP 协议调用各类 Tool →完成任务。
3. 检索增强生成RAG---LLM 的外部知识库,提高准确率和时效性
检索增强生成Retrieval-Augmented Generation,不是模型,不是算法,是一套方案 / 外挂模块。大型语言模型(LLM)面临两个问题,第一个问题是LLM会产生幻觉,第二个是LLM的知识中断。1)知识截止:当LLM返回的信息与模型的训练数据相比过时时,每个基础模型都有知识截止,这意味着其知识仅限于训练时可用的数据。2)幻觉:当模型自信地做出错误反应时,就会发生幻觉。RAG是一种结合了信息检索、文本增强和文本生成的自然语言处理(NLP)的技术。RAG的目的是通过从外部知识库检索相关信息来辅助大语言模型生成更准确、更丰富的文本内容。
RAG技术就像给AI装上 实时的百科全书,通过先查资料后回答的机制,让AI摆脱传统模型"知识遗忘困境"
参考:
闪客】一口气拆穿Skill/MCP/RAG/Agent/OpenClaw底层逻辑:https://www.bilibili.com/video/BV1ojfDBSEPv