概述
这一章主要是从memory角度来分析和优化算子的,用transposition的例子分析maxbandwidth rate对性能的影响。
重要概念
- 内存层次:
- 固定内存:
- 全局内存:
- 零拷贝内存:
- 统一内存寻址:
- 对齐与合并访问:
- AOS和SOA:
- bank conflict:此处放一个笛卡尔坐标下的bank conflict图简洁明了:
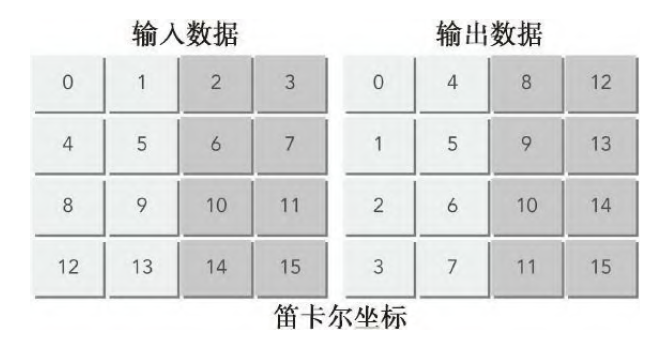
对于内存的分配和释放等等概念就是老生常谈的了,此处不放了。
transposition优化方法
transposition就是对矩阵进行转置。转置的方法有多种,下面分析一下不同的方法实现以及性能。
naive transposition
这种就直接跳过了,直接进行转置,分为按行转置和按列转置。
unrolling 展开相邻的元素
展开相邻的4个元素。这种方法下,按列转置的性能较好,ncu的memory性能报告:

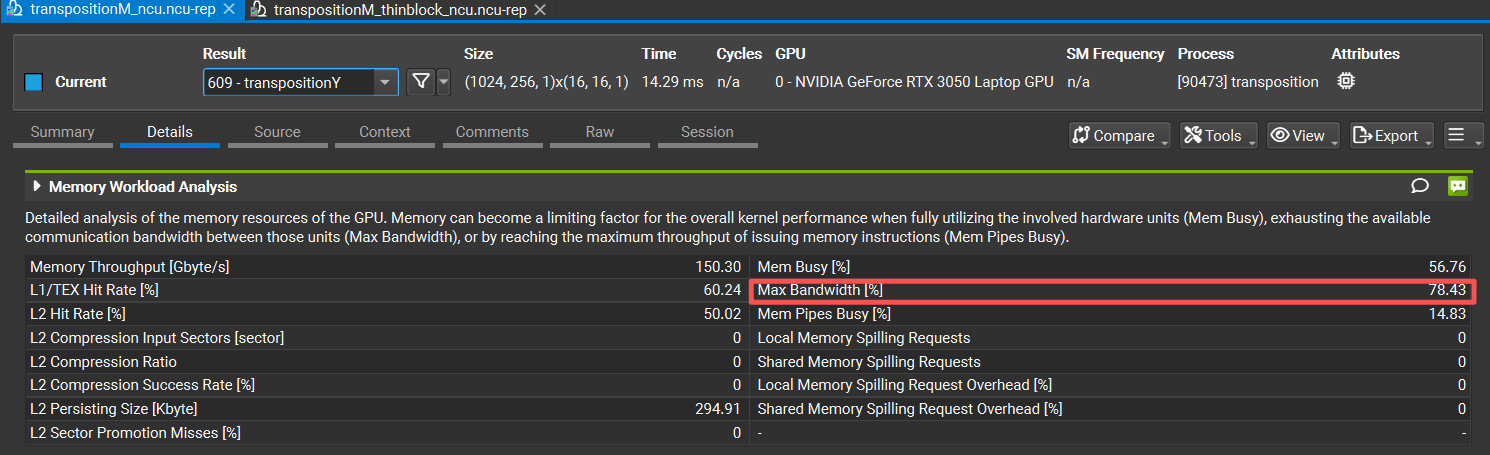
这种按列转置的性能已经很不错了,maxbandwidth rate已经接近80%。从书上看到其性能较好的原因是:
在缓存中执行了交叉读取。即使通过某一方式读入一级缓存中的数据没有都被这次访问使用到,这些数据仍留在缓存中,在以后的访问过程中可能发生缓存命中。
而按行转置可能会发生bank conflict,导致wrap中不同的线程访问同一块内存事务的地址,发生排队等待。其实后续的几种方法也是尽可能避免bank conflict,从而提高性能。
diagonal 使用对角坐标
这种方法主要是对blockIdx从笛卡尔坐标映射到对角坐标,进行交叉访存,尽量避免bank conflict。性能:
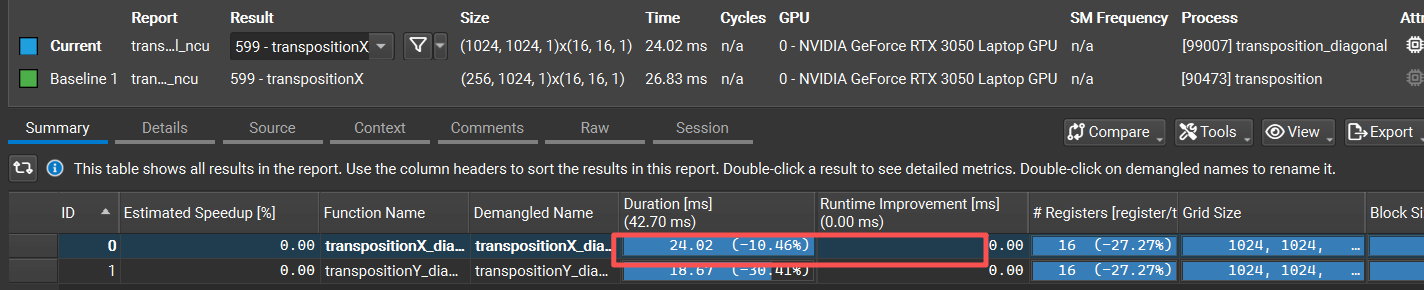
些许的提高了按行转置的性能,但是相对于按列转置还是有差距。(这种方法下的按列转置性能有所下降)
thin block + unrolling 瘦块和展开
很简单,在unrolling基础上将blocksize从16,16改成8,32
这种方法目前章节中性能超级好:
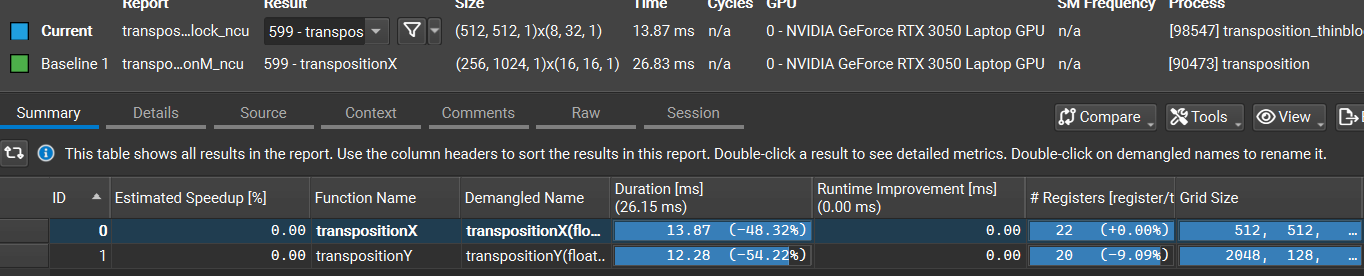
按行转置和按列转置的maxbandwidth rate达到了惊人的80%和91%!
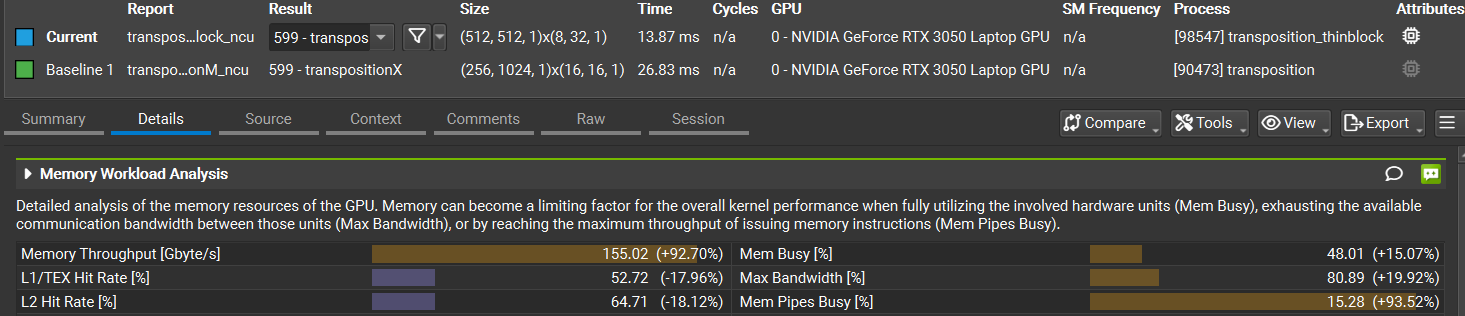
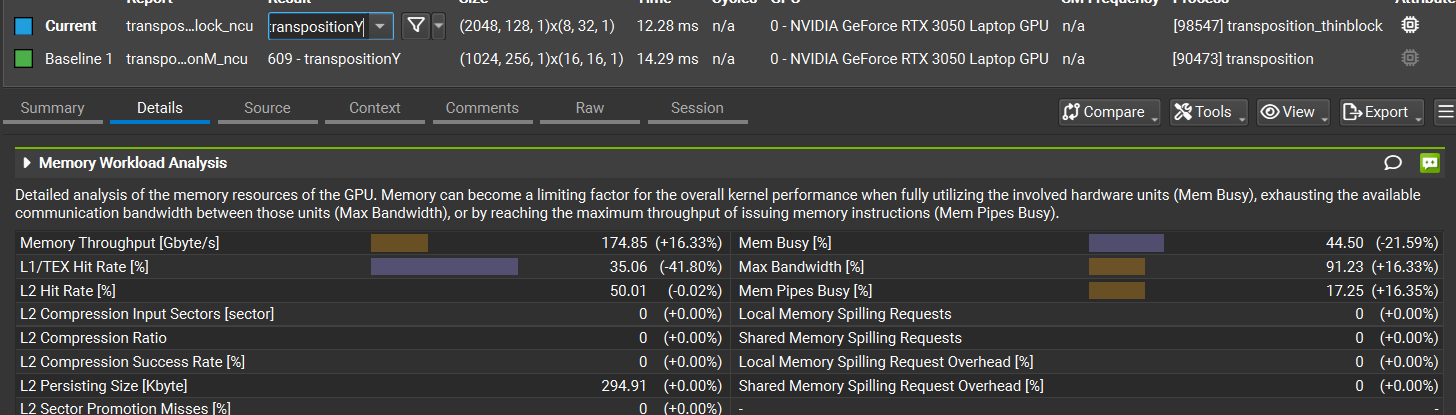
没想到就是改了一个blocksize就能有这么大的性能提升!
统一内存方法
这种方法优点在于,把数据放在了CPU上,避免了繁琐的在GPU上申请空间,使得代码简洁化。但是缺点也很明显,GPU需要多次从CPU上访存数据,造成性能的下降。
diagonal+unrolling
课后习题上的,还没调试出来,需要再熟悉一下GBD,预计效果会有些许提升。
此外还想到了diagonal+thin block+unrolling,方法真的很多,就算知道理论还是需要验证一下实际的效果,因为影响性能的因素真的很多。