1. Introduction
近年来,基于大语言模型(LLM)的代码智能体因其在处理复杂软件工程(SWE)任务方面所展现出的潜力而受到广泛关注(Anthropic, 2025a; Google, 2025; OpenAI, 2025),这一趋势在 SWE-bench(Jimenez et al., 2023)及其后续基准测试(Zhang et al., 2025)中得到了充分体现。然而,这些智能体的进一步发展从根本上受制于高质量训练数据的匮乏。与常规代码生成任务不同,软件工程任务要求智能体在可执行环境中运作,需要其在现有代码库中进行导航、管理依赖关系并满足测试套件的要求。上述内在复杂性使得对相关数据进行系统化整理与验证成为一项极具挑战性的工作。
当前构建 SWE 风格数据集的主流方法主要依赖于劳动密集型的人工整理(Pan et al., 2024),或基于简单 LLM 驱动(Badertdinov et al., 2025)与规则的合成方式(Guo et al., 2025b)。因此,现有数据集在规模、多样性和难度上往往存在明显局限,或缺乏可执行环境与完善的测试套件。尽管现实世界中存在大量可用的软件制品资源------包括代码仓库、问题跟踪记录和提交历史------但这些资源在构建大规模、真实性强的数据集方面仍在很大程度上未被充分利用,上述局限依然存在。系统化、自动化挖掘技术的缺失,由此造成了原始软件资源与构建大规模高质量训练数据之间明显的脱节。这一迫切需求驱动我们致力于开发一种自动化、可复现的数据集构建方法。
然而,SWE 数据集的自动化构建面临着独特且重大的挑战。首先,随着仓库多样性的增加,环境配置成为一大障碍,导致构建流程高度异构且往往十分脆弱(Froger et al., 2025),即便是经验丰富的开发者也难以正确完成配置。其次,真实世界的代码仓库往往缺乏充分且定义明确的单元测试。
尽管纳入这些仓库对于减少数据偏差、实现规模化至关重要,但生成完善的单元测试本身就是一个复杂问题,需要智能体进行交互式执行与自我纠错。最后,现实世界中相当一部分 Pull Request 要么缺乏有效的描述信息,要么本身并不适合用于 SWE 任务。
因此,生成高质量、自包含的问题描述颇具难度,需要智能体通过对沙箱环境的迭代探索来深入理解仓库上下文,从而推断任务意图。为应对上述挑战,本文提出 Scale-SWE------一个面向大规模高质量软件工程数据集构建的自动化沙箱多智能体工作流。
该系统协调三个专用智能体协同工作:环境构建智能体负责搭建隔离的 Docker 执行环境 an environment builder agent that sets up isolated Docker environments;单元测试生成智能体负责生成鲁棒的 **Pass-to-Pass(P2P)**与 **Fail-to-Pass(F2P)**测试用例a unit-test creator agent that generates robust Pass-to-Pass (P2P) and Fail-to-Pass (F2P) test cases;问题描述生成智能体则基于 Pull Request 内容撰写自包含的任务描述**a problem statement agent** that crafts self-contained task descriptions grounded in pull request content。
通过处理来自 5200 个代码仓库的 600 万条 Pull Request,该工作流生成了 10 万个经过验证的实例,构建出迄今为止规模最大的 SWE 数据集,即 Scale-SWE-Data。该数据集在仓库多样性方面超越了现有真实数据集,并在所需文件修改数量及单元测试的鲁棒性两个维度上充分体现了真实软件工程任务的复杂性。
为进一步验证 Scale-SWE-Data 在模型训练中的实用价值,我们使用 DeepSeek-V3.2 从 2.5 万个实例的子集中蒸馏出 71,498 条高质量轨迹。在该蒸馏数据上对 Qwen3-30A3B-Instruct 进行微调,得到我们的 Scale-SWE-Agent,该智能体在 SWE-Bench-Verified 上取得了显著的性能提升,解决率从 22% 提升至 60%。
这一结果充分印证了我们的数据集在训练和提升基于 LLM 的代码智能体方面的有效性。综上所述,本文的主要贡献如下:
- 我们提出了 Scale-SWE------一个面向大规模高质量软件工程数据集构建的自动化沙箱多智能体工作流。该系统系统性地协调三个专用智能体,分别负责环境配置、单元测试生成和问题描述合成。
- 我们构建了 Scale-SWE-Data------迄今为止规模最大的经过验证的 SWE 数据集,包含 10 万个真实世界实例。该数据集在仓库多样性和任务复杂度上均超越现有基准,可同时支持基于 LLM 的代码智能体的评估与训练。
- 我们从 Scale-SWE-Data 中蒸馏出 71,498 条高质量轨迹,并对 Qwen-30A3B-Instruct 进行微调,从而构建出 Scale-SWE-Agent。该智能体在 SWE-Bench-Verified 上取得了显著的性能提升,解决率达到 64%------相较于原始骨干模型实现了近三倍的提升。
2. Scale-SWE: Software Task Scaling
Scale-SWE 的核心理念是借助沙箱多智能体系统,自主地探索代码库并完成 SWE 数据的构建。每个 SWE 数据实例封装了以下必要组成部分:一个 Docker 镜像docker image 、一份问题描述problem statement,以及用于验证的单元测试(包含 F2P 和 P2P 两类测试用例)。与此前基于规则的构建方法相比,我们的沙箱多智能体系统具有显著更高的灵活性。
2.1. Sandboxed Multi-agent System
为实现软件工程任务自动化构建的规模化,我们开发了一套沙箱多智能体系统sandboxed multi-agent system。该框架通过多个智能体的协同配合,生成大量具备完整可执行环境的 SWE 数据。
2.1.1. The Overall Workflow
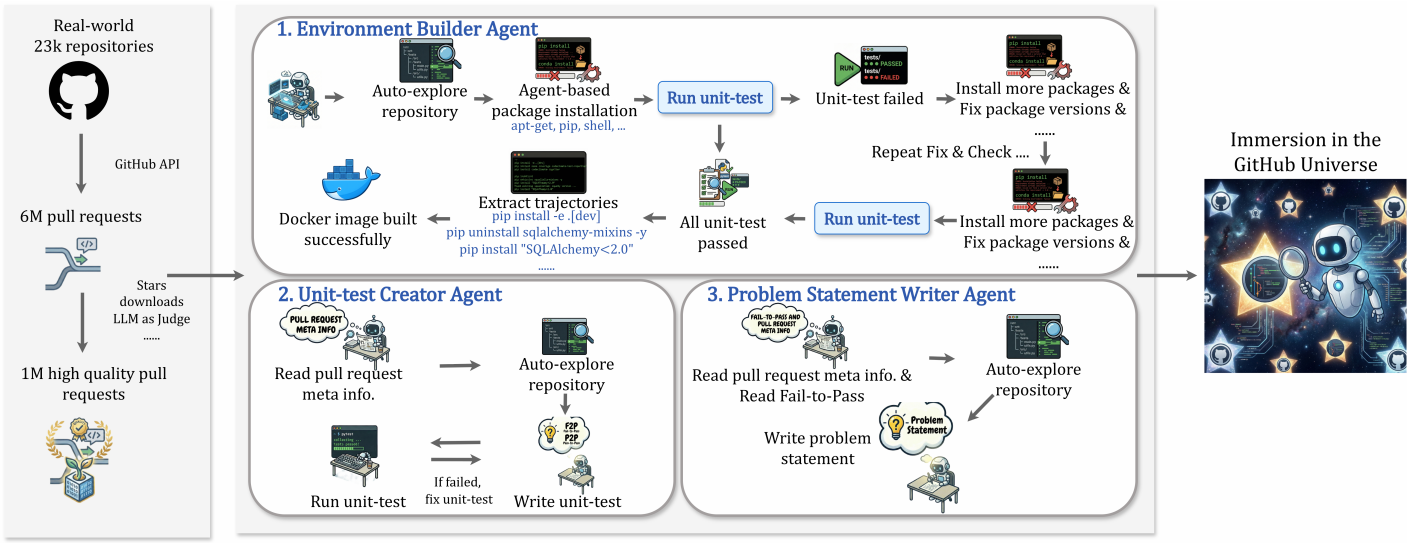
Figure 2 *|*The Sandboxed multi-agent system for Scale-SWE dataset construction. Starting from
millions of raw GitHub pull requests, the pipeline employs a series of autonomous agents to
transform high-quality PRs into executable software engineering tasks. The framework automates
environment setup, unit test generation (Fail-to-Pass/Pass-to-Pass), and formal problem statement synthesis, ensuring the scalability and reproducibility of the distilled trajectories.
如图 2 所示,我们的沙箱多智能体系统通过三个专用智能体的协同执行,实现了软件工程任务的自动化构建,这三个智能体分别为:环境构建智能体(Environment Builder Agent,EBA)、单元测试生成智能体(Unit-test Creator Agent,UCA)和问题描述撰写智能体(Problem Statement Writer Agent,PSWA)。
在该框架中,EBA 基于目标代码仓库生成可复现的 Docker 执行环境,为大规模任务验证提供隔离且一致的运行时支撑。UCA 基于 Pull Request 内容及仓库上下文,合成包含 Fail-to-Pass(F2P)和 Pass-to-Pass(P2P)两类测试用例的完整可执行测试套件,从而确保评估标准的鲁棒性。
最后,PSWA 以可执行测试套件为基础,生成高质量、自包含的问题描述,确保问题陈述与验证要求之间的语义一致性。
该系统基于 SWE-agent(Yang et al., 2024a)构建,并由 DeepSeek 语言模型系列(Liu et al., 2025)和 Gemini3-Pro(Google, 2025)提供支持。其中,任务实例的生成使用 DeepSeek v3.1 或 DeepSeek v3.2,PSWA 模块则采用 Gemini3-Pro。
2.1.2. Environment builder agent
EBA 旨在从目标源代码仓库出发,自动生成可复现的基于 Docker 的执行环境。通过提供隔离且可执行的沙箱环境,EBA 得以支持自动化软件工程工作流中测试样本的大规模构建与验证。
角色定义。Role Formulation. 我们将 EBA 的核心功能定义为:将初始的通用 Docker 环境转化为针对特定代码仓库定制的专用运行时容器。
该过程可形式化表示为:

其中,R 表示智能体用于推断依赖关系和配置逻辑的输入代码仓库,Dinit 为基础 Docker 镜像,Dfinal 为最终生成的功能完备、可直接使用的容器镜像。
构建过程。【Construction Process 】 在具体实现中,EBA 在包含已克隆仓库的基础 Docker 容器中完成初始化。随后,EBA 自主探索仓库结构,并分析 setup.py、pyproject.toml 和 README.md 等配置文件,以推断项目的依赖关系。
由于 Python 项目缺乏统一的配置规范,标准化的安装方式难以满足需求。因此,智能体必须解读项目专属文档,并通过解析终端反馈信息来交互式地解决依赖冲突。这种由反馈驱动的自主流程使得环境配置更加灵活,有效规避了静态规则方法(如预定义 pip install 命令)的固有局限。最终,我们从智能体的执行轨迹中提取所有已运行的命令,并借助 LLM 将其合成为可复现的 Dockerfile。
高效扩展环境多样性。Efficiently Scaling Environmental Diversity. 尽管为每个 Pull Request(PR)单独构建专属环境的思路直观易行,但对于大规模评估而言,其计算开销过于高昂,难以承受。为实现对多样化仓库的规模化覆盖,我们对每个仓库最多采样十个 PR,并通过 EBA 为其完整构建执行环境。这一采样策略在有效控制资源开销的同时,实现了对更广泛仓库的覆盖。
值得注意的是,十个 PR 并不只产生十个任务样本------若多个 PR 源自相近的运行时状态,它们可以共享同一执行环境,从而使得最终的测试样本数量远超独立构建的环境数量。具体而言,对于其余 PR,我们在与其"最近"的可用 Docker 环境中执行测试,其中"最近"由 PR ID 的接近程度来衡量(作为仓库时间线的代理指标)。
若某个 PR 在其最近可用环境中未能通过单元测试,则将其从最终数据集中剔除。否则,该 PR 及其关联的预建环境将作为有效的测试实例予以保留。平均而言,每个仓库贡献 19 个测试实例(见表 2),这极大地提升了环境复用率和数据集的整体多样性。
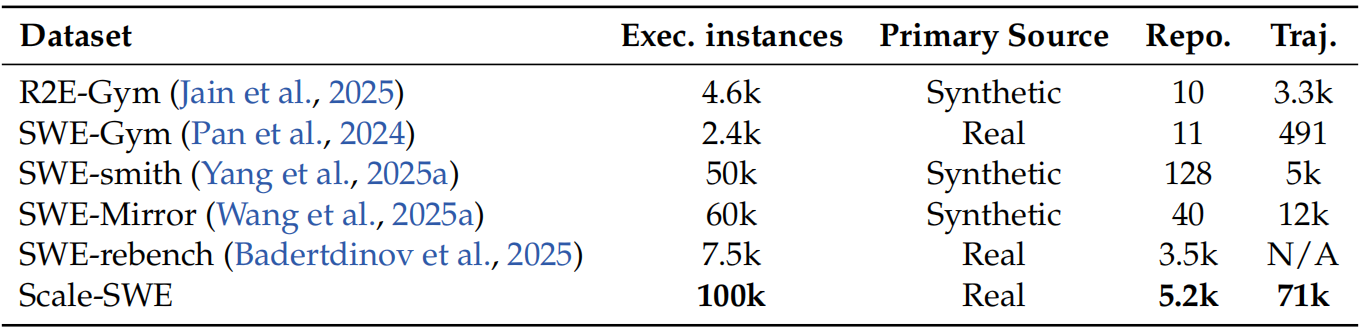
Table 2 *|*Comparison of Scale-SWE with existing software engineering (SWE) benchmarks. We
contrast datasets across key dimensions: the number of executable instances---defined as those
equipped with a Dockerized environment and validated via Fail-to-Pass (F2P) and Pass-to-Pass
(P2P) tests---primary data source, repository diversity, and trajectory count.
2.1.3. Unit-test creator agent
单元测试生成智能体(unit-test creator agent,UCA)旨在从目标源代码仓库及其关联的 Pull Request 中,自动生成完整且可执行的测试套件。通过将 PR 的语义信息与动态仓库上下文相融合,UCA 得以大规模构建经过验证的 Fail-to-Pass(F2P)和 Pass-to-Pass(P2P)测试用例,这对于鲁棒的软件工程任务评估至关重要。
角色定义(Role Formulation.)。 UCA 的核心功能是将所提供的 Pull Request 元数据及其关联的代码上下文,转化为一套完整的可执行单元测试。
该过程可形式化表示为:

其中,M 表示输入的 Pull Request 元数据(metadata)------包括标题title、描述description和差异补丁diff patches------为测试生成提供语义规范;R 为关联的源代码仓库,智能体通过分析其结构和逻辑来理解代码;Dfinal 为 EBA 构建的功能完备的 Docker 环境;U 为最终生成的可执行测试用例集合。
在本工作中,我们采用 SWE-bench 协议对单元测试进行分类,将其划分为两种类型:Fail-to-Pass(F2P)测试:该类测试在原始代码库上初始执行时会失败,在应用缺陷修复补丁后必须通过,用以验证修复的正确性;以及 Pass-to-Pass(P2P)测试:该类测试为已有的通过性测试,在修复前后均须保持通过状态,以确保不引入回归问题。
**构建过程。Construction Process.**大量 GitHub 仓库缺乏完善的单元测试,这使得自动化构建 Fail-to-Pass(F2P)和 Pass-to-Pass(P2P)两类测试用例,对于创建有效的软件工程(SWE)任务实例而言至关重要。UCA 首先对目标 PR 的结构化元数据进行分析,包括其标题、描述及差异补丁。这些输入为智能体理解拟议代码变更的意图和范围提供了必要的语义基础。
在此基础上,智能体对关联仓库进行自主遍历,以梳理目录结构、识别关键模块,并推断底层程序逻辑与依赖关系。然而,生成有效的单元测试是一项复杂的有状态挑战,不仅需要对代码进行静态理解,还需要对其行为进行动态验证。
智能体必须对跨文件交互、数据流、异常处理和边界情况进行推理------这些任务仅凭静态分析难以完成。为此,UCA 被部署于安全的沙箱执行环境中(具体而言,即 EBA 所构建的 Docker 容器 Dfinal)。该沙箱赋予智能体直接的实时代码执行权限,从而支持"执行---分析---优化execute-analyze-refine"的交互式闭环流程。
智能体因此能够动态运行所生成的测试用例,观察执行结果,并对测试逻辑、断言和测试夹具进行迭代修正。这种闭环、反馈驱动的方法使 UCA 能够生成鲁棒且可执行的测试套件。
2.1.4. Problem Statement Writer Agent
问题描述撰写智能体(*problem statement writer agent,*PSWA)旨在从原始 Pull Request 及其关联的测试套件中,自动合成高质量、自包含的任务描述。通过将问题叙述锚定于可执行的单元测试,PSWA 确保了问题规范与单元测试之间的语义一致性,从而生成表述明确、可求解的软件工程任务。
角色定义。Role Formulation. PSWA 的核心功能是根据 Pull Request 元数据及其对应的测试套件,生成不含解决方案泄露的规范化问题陈述。
该过程可形式化表示为:

其中,M 表示输入的 PR 元数据------包括标题、描述和差异补丁------为问题陈述的生成提供初始上下文基础;U 为 UCA 生成的可执行单元测试套件,用于确保问题陈述与实际验证要求保持一致;R 为关联的源代码仓库;Dfinal 为 EBA 构建的功能完备的 Docker 环境;S 为最终生成的规范化问题描述,在清晰阐明问题的同时不暴露实现细节,并与单元测试保持语义一致。
**构建过程。Construction Process.**直接将原始 PR 描述作为问题陈述存在根本性缺陷,原因在于其具有回顾性特征------这些描述往往在修复实施之后才被撰写,可能泄露解决方案细节或引用内部实现信息。此外,相当一部分高质量 PR 缺乏描述,或与原始问题报告存在脱节。为克服上述局限,PSWA 在初始化时同时接收 PR 元数据和 UCA 生成的可执行单元测试。
将测试套件纳入提示至关重要,因为 F2P 测试可能调用原始代码库中尚不存在的函数或类;生成的问题陈述必须明确阐明这些要求,以确保任务具有可解性。若缺乏这种对齐,仅从 PR 元数据推导出的描述往往会与测试所捕获的实际故障产生偏差。
因此,智能体合成一段连贯、自包含的叙述,明确阐述预期行为、测试所需的任何新接口,以及外部求解器所需的上下文信息------同时刻意省略任何关于实现方式的提示。该过程确保每个合成的任务实例在语义上精确且具备评估就绪性,从而实现从原始仓库数据大规模创建 SWE-bench 风格问题的目标。
对于 PSWA 模块,我们采用 Gemini3-Pro,因为实验结果表明,该模型能够生成更加一致、严谨的问题陈述,同时显著降低信息泄露的风险。
2.2. Data Processing数据处理.
确保高数据质量是构建可靠数据集的首要原则。本节将详细介绍为实现这一目标所采用的数据整理方法。
Repository Selection.仓库筛选。 为构建全面且高质量的语料库,我们从两个主要渠道获取代码仓库,如图 5 所示。首先,我们基于 Top PyPI Packages 的数据,识别出 Python 包索引(PyPI)上下载量最高的 15,000 个软件包所对应的代码仓库。
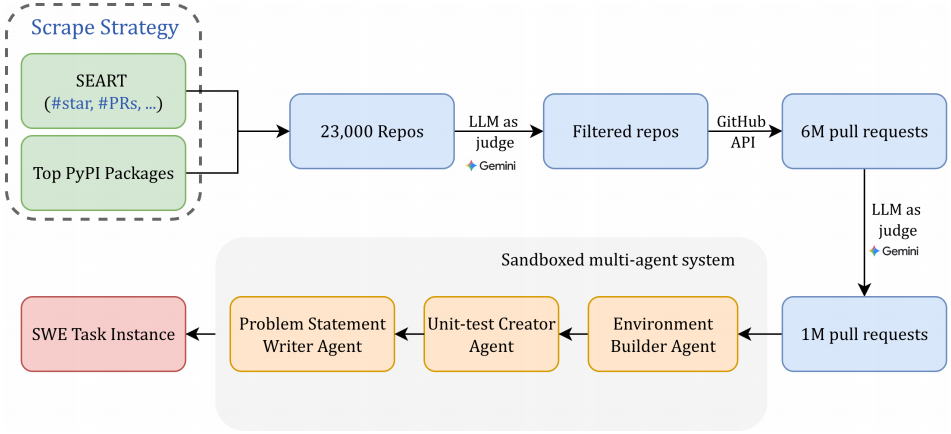
Figure 5 *|*Schematic workflow for automated Scale-SWE task synthesis. From an initial pool of
23k repositories and 6M pull requests, the pipeline utilizes LLM-as-a-judge to filter for quality and
relevance. The selected 1M pull requests are then transformed into formal software engineering
task instances via a sandboxed orchestration of specialized agents responsible for environment
building, test creation, and statement writing.
其次,为纳入 PyPI 以外的优质项目,我们通过 SEART 搜索引擎进行检索,筛选条件如下:主要编程语言为 Python、贡献者不少于 5 人、Star 数不少于 500,且创建日期在 2015 年 1 月 1 日至 2025 年 10 月 29 日之间。该查询共返回 9,062 个仓库。将上述两个来源合并后,初始候选仓库总数约为 23,000 个。
随后,我们应用**多阶段过滤流水线a multi-stage filtering pipeline**对候选仓库进行筛选。首先,为防止评估基准的数据泄露,我们排除了所有来自 SWE-Bench Verified 所列仓库的 PR。其次,我们进一步筛选,仅保留采用宽松型开源许可证的仓库。最后,考虑到部分仓库可能依赖 GPU、以教程为主或仅包含极少量源代码,我们对其进行了基于内容的过滤。
我们提取了所有剩余候选仓库的 README 文件,并采用 LLM 作为评判者(LLM-as-a-judge)的方式,自动排除被判定为不适合训练的仓库。
Pull Request 过滤Pull Request Filtering。 随后,我们提取了所有已合并至筛选后仓库"main"或"master"分支的 Pull Request,初步得到 600 万条记录。为确保数据质量,我们采用 LLM 作为评判者,基于可用元数据------包括 git diff、Pull Request 描述和合并提交信息------对低质量实例进行过滤。
防作弊机制Cheating Prevention.。 在评估阶段,必须防止模型利用 git 命令(如 git log --all)获取标准答案(Xiao et al., 2026)。为此,我们在任务环境初始化完成后立即执行一个清理脚本。该过程系统性地移除**任务父提交task's parent commit**之后的所有元数据。
具体操作包括:执行硬重置、删除所有远程引用和标签,并清除内部 git 文件(如 logs/、packed-refs 及各类 HEAD 文件),从而彻底消除任何未来解决方案历史的痕迹。
2.3. Dataset Quality Assurance数据集质量保障.
基于规则的检验Rule-based Check.。 我们基于测试结果实施了严格的过滤协议。我们仅保留满足以下条件的实例:(1)在原始存在缺陷的代码库上,所有 P2P 测试通过且所有 F2P 测试失败;(2)在应用标准补丁后,所有 P2P 和 F2P 测试均通过。
专家审核Expert Check. 我们邀请四名高年级博士生,采用交叉验证协议对随机抽取的 100 个实例进行人工审核。审核结果确认其中 94 个实例有效,具备正确的执行环境、单元测试和问题陈述。我们将这一高质量结果归因于以下三个关键因素:(1)我们采用最先进的模型(如 Gemini 3 Pro)来合成准确的问题陈述;(2)我们采用 LLM 作为评判者的方法,预先筛除低质量的仓库和 Pull Request;(3)我们对 P2P 和 F2P 测试强制执行固定的运行顺序,以防止测试污染------若执行顺序不固定,可能因环境污染而导致结果不一致。
2.4. Dataset Statistics and Trajectory Distillation
最终,我们基于智能体的构建流水线产出了 10 万个经过验证的实例,是迄今为止规模最大的经验证 SWE 基准数据集。借助大规模 GitHub 仓库的收集,所构建的数据集在仓库多样性方面显著超越现有 SWE 基准,详见表 2。
Table 2 *|*Comparison of Scale-SWE with existing software engineering (SWE) benchmarks. We
contrast datasets across key dimensions: the number of executable instances---defined as those
equipped with a Dockerized environment and validated via Fail-to-Pass (F2P) and Pass-to-Pass
(P2P) tests---primary data source, repository diversity, and trajectory count.
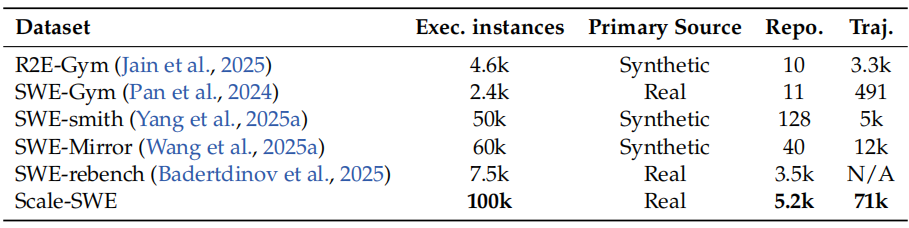
与以往通常依赖合成生成或有限真实来源的数据集不同,Scale-SWE 完全基于 5200 个真实仓库构建而成。这比规模次之的真实世界基准(SWE-rebench,包含 3500 个仓库)在仓库数量上提升了 50%。如此规模与多样性确保了我们的基准能够更好地反映真实软件工程任务的复杂性与多样性。Scale-SWE 的统计特征如表 1 所示。该数据集呈现出相当程度的软件工程挑战性。
Table 1 *|*Detailed statistics of the Scale-SWE dataset. We report the mean and percentiles (P50, P75, P95) for code modification metrics and test case distributions.
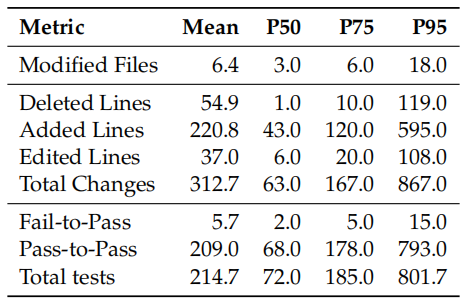
中位数实例需要修改至少 3 个文件并新增 43 行代码,充分体现了任务的复杂程度。为保障评估的鲁棒性,每个实例平均包含超过 200 个 Pass-to-Pass(P2P)测试(中位数为 68),为防止回归提供了有力保障;同时,每个实例平均包含 5.69 个 Fail-to-Pass(F2P)测试,用于验证 LLM 是否成功解决了特定问题。
为构建训练语料库,我们使用高性能专家模型 DeepSeek-V3.2 从 2.5 万个实例的子集中蒸馏智能体轨迹。对于每个实例,我们以 0.95 的温度系数进行五次独立采样,每次最多允许 100 轮交互。仅当轨迹最终提交的结果通过所有单元测试时,该轨迹才被视为有效。该流水线共产出 7.1 万条高质量轨迹,总计约 35 亿个 token。为确保比较的公平性,我们对 SWE-Smith 和 SWE-Gym 采用完全相同的流水线收集轨迹数据。
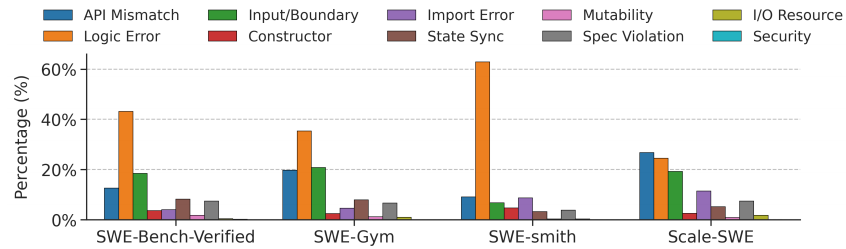
Figure 3 *|*Distribution of bug categories across different datasets. The bar chart compares the
percentage of ten bug types within SWE-bench Verified, SWE-Gym, SWE-smith, and Scale-SWE. The categories are defined as: API Mismatch (incompatible signatures or parameter errors); Logic Error (flawed conditionals or control flow); Input/Boundary (edge case mishandling or validation failures); Constructor (object initialization errors); Import Error (missing modules or undefined symbols); State Sync (inconsistent internal state); Mutability (unintended side effects); Spec Violation (non-compliance with protocols); I/O Resource (file system or stream errors); and Security (improper scoping or access control).
图 3 直观呈现了 Scale-SWE 在多样性方面的突出优势。以 SWE-smith 为代表的合成数据集存在明显的逻辑错误偏重倾向,未能涵盖大型代码库中常见的 API 不匹配或状态同步问题等复杂缺陷类型。类似地,SWE-Gym 尽管来源于真实世界,但由于仅限于 11 个代码仓库,其多样性同样十分有限。相比之下,Scale-SWE 在全部十个缺陷类别上实现了高度均衡的分布。
通过利用 5200 个真实仓库和自动化环境构建流水线,Scale-SWE 有效涵盖了从构造函数错误到安全漏洞的多种缺陷类型。这充分验证了扩大源仓库规模与自动化执行流水线对于合成能够真实反映软件演化规律的训练数据至关重要。我们采用 BugPilot(Sonwane et al., 2025)所提出的缺陷分类体系,并使用 DeepSeek v3.2 对训练实例进行自动标注。
3. Experiments
3.1. Experiment Setup
智能体脚手架Agent Scaffolding。 我们采用 OpenHands(Wang et al., 2025b)作为所有实验的统一智能体框架,这是一个开源的事件驱动平台。OpenHands 支持 LLM 智能体在沙箱容器内迭代地编辑文件、执行 shell 命令并进行网页浏览。我们选择该框架的原因在于,它已被证明能够在 SWE-Bench 等基准测试上建立鲁棒且可复现的基线结果。
智能体后训练Agent Post-training。 我们以 Qwen3-30B-A3B-Instruct(Team, 2025)为基础模型进行后训练。训练过程配置如下:学习率为 1e-5,批大小为 128,预热比例为 0.05,支持的最大上下文长度为 131,072。此外,我们应用损失掩码loss masking,将损失计算限制在产生格式规范动作的助手轮次上(Chen et al., 2025; Team et al., 2025b)。
评估基准与指标Evaluation Benchmarks and Metrics.。 我们在 SWE-bench Verified(Chowdhury et al., 2024)上进行评估,该基准包含 500 个经人工精心整理的高质量 Python 软件问题。我们报告解决率(%)作为评估指标,即模型成功生成正确解决方案的实例占比。值得注意的是,尽管模型训练时的序列长度为 131,072,我们在推理阶段将上下文限制扩展至 262,144,以处理规模更大的输入。
3.2. Experiment Results
Table 3 *|*Performance comparison on SWE-bench Verified. We categorize models into proprietary systems, open-source methods, and size-matched baselines.
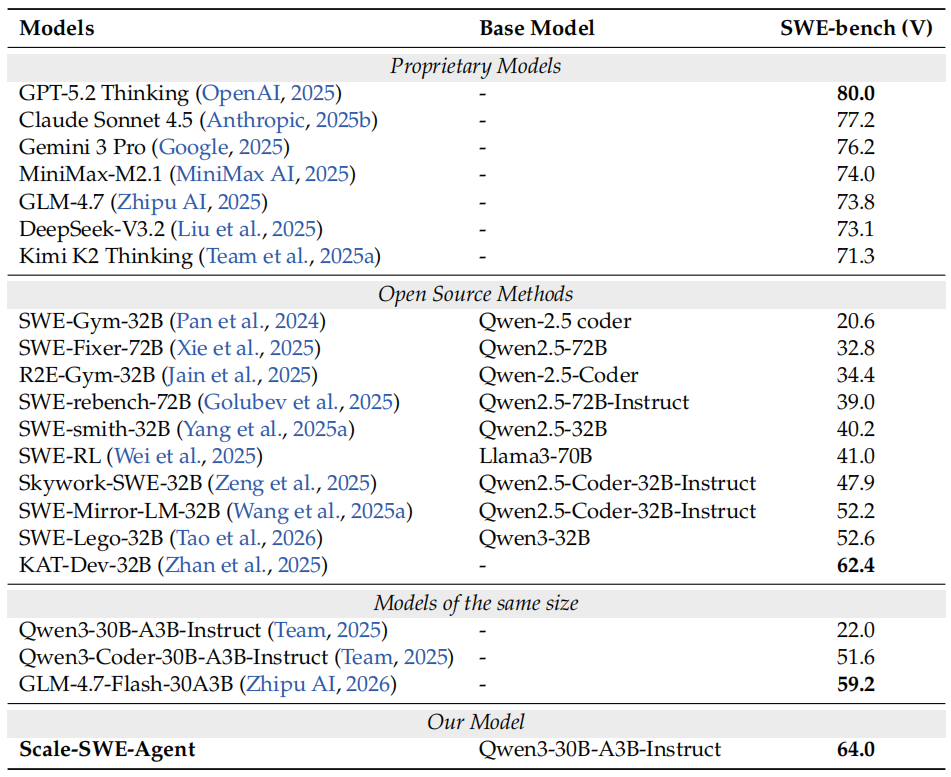
如表 3 所示,Scale-SWE Agent 在 SWE-bench Verified 上展现出卓越的性能表现。首先,就我们的规模化策略的效果而言,Scale-SWE Agent 相较于基础模型 Qwen3-30B-A3B-Instruct 实现了高达 42.0% 的绝对性能提升,将通过率从 22.0% 提升至 64.0%。其次,与同等规模的模型相比,我们的方法显著优于 Qwen3-Coder(51.6%)和 GLM-4.7-Flash(59.2%)等强劲竞争对手。此外,Scale-SWE Agent 展现出卓越的参数效率,超越了参数量远大于自身的模型,包括 SWE-RL(Llama3-70B)和 SWE-Fixer-72B。值得一提的是,Scale-SWE Agent 还超越了此前最先进的开源方法 KAT-Dev-32B(62.4%),并以超过 11% 的优势领先于 SWE-Mirror 和 SWE-Lego 等近期专用模型。上述结果充分验证了扩大 SWE 风格数据规模对于提升软件工程能力的有效性。