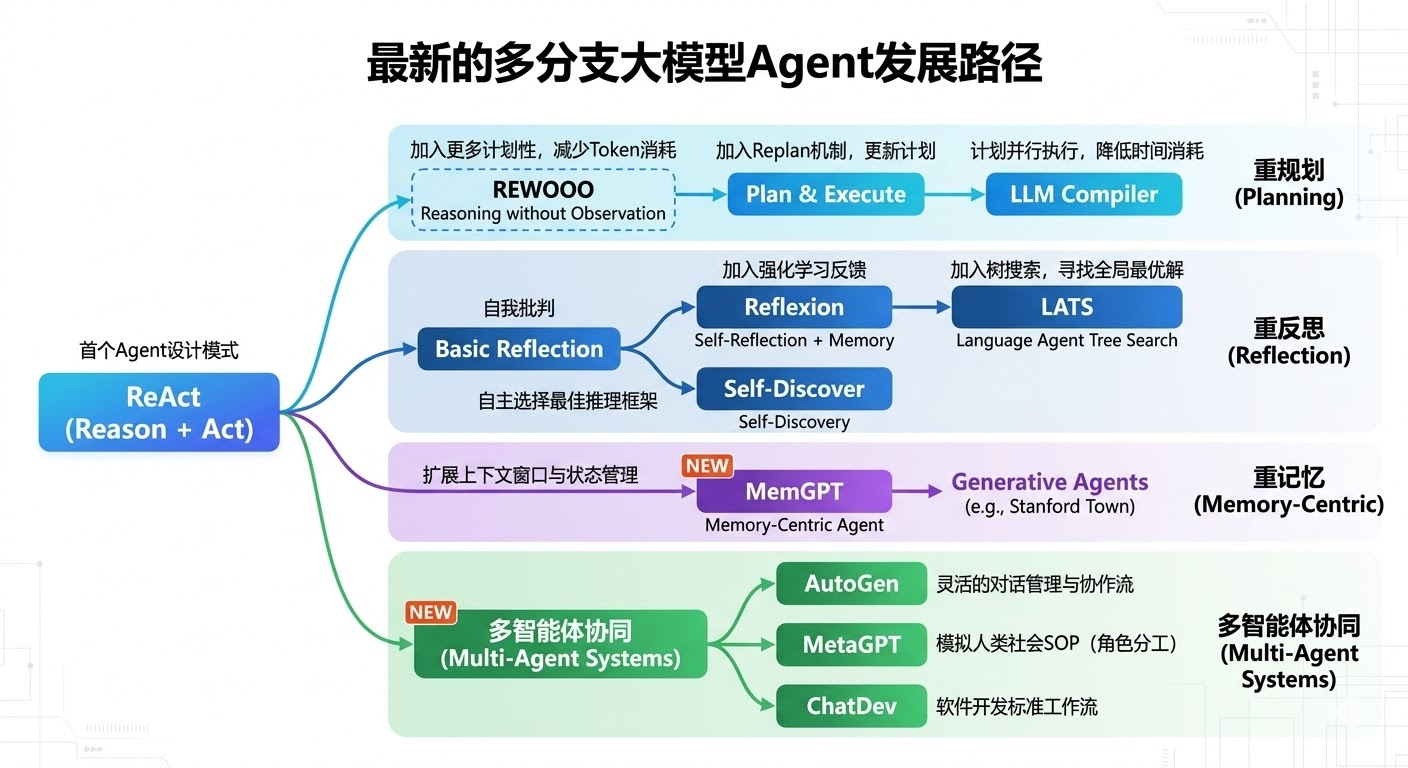
一、 各类Agent技术原理、场景与优缺点总结
🌟 奠基时代
1. ReAct (Reason + Act)
- 底层原理:交替进行"思考"和"行动"。LLM先输出一段思考(CoT),决定下一步调用什么工具,获取观察结果后,再进行下一轮思考,直到任务完成。
- 适用场景:简单的问答、基础的API调用、单步信息检索。
- 优点:符合直觉,能在执行过程中根据工具反馈动态调整动作。
- 缺点:Token消耗极大(每次循环都要带着前面的上下文);面对多步复杂任务容易"脱轨"或陷入死循环。
📈 分支一:重规划路径 (解决效率与长任务问题)
2. REWOO (Reasoning without Observation)
- 底层原理:将"规划"和"执行"完全解耦。LLM先一次性写好整个任务的执行计划(DAG图),并预留好变量。然后执行器按照计划调用工具,最后再将所有结果交给LLM总结。
- 适用场景:流程固定、步骤之间依赖关系明确的任务(如:先查天气,再查航班,最后写邮件)。
- 优点:大幅减少Token消耗和调用LLM的次数;避免了ReAct中某一步出错导致后续全盘崩溃。
- 缺点:缺乏动态调整能力。如果计划的第一步就彻底失败,后面的执行通常毫无意义。
3. Plan & Execute (Plan-and-Solve)
- 底层原理:一个"规划者"Agent将大任务拆分为子任务列表;一个"执行者"Agent按顺序完成子任务。通常还加入了一个"重规划(Re-plan)"机制,每完成一步都会更新剩余计划。
- 适用场景:复杂的数据分析、长篇内容生成、多步骤代码编写。
- 优点:擅长处理长周期任务,逻辑清晰,容错率比纯REWOO高。
- 缺点:串行执行,耗时(Latency)较长。
4. LLM Compiler
- 底层原理 :借鉴传统计算机编译器的原理,将自然语言任务编译成可以并行执行的工具调用图(DAG图)。
- 适用场景:包含多个独立子任务的查询(例如:"同时帮我查一下苹果、微软和谷歌今天的股价并对比")。
- 优点:极大地降低了任务执行的总体时间,效率极高。
- 缺点:对LLM提取依赖关系的能力要求极高;并非所有任务都能并行。
🪞 分支二:重反思路径 (解决幻觉与准确率问题)
5. Basic Reflection (自我反思)
- 底层原理:Agent生成初步答案后,系统提示它(或另一个Critic Agent)"检查上述答案是否有误",然后根据反馈重新生成答案。
- 适用场景:文本润色、代码纠错、逻辑推理题。
- 优点:实现简单,无需外部环境配合,能显著提升单次生成的质量。
- 缺点:如果LLM本身的认知有盲区,它可能会"认为错误的答案是正确的",导致无效反思甚至改错。
6. Self-Discover (自我发现)
- 底层原理:在解决问题之前,LLM先从一个"推理模块库"(如:批判性思维、分步拆解、逆向思维等)中,自主挑选并组合出最适合当前任务的"推理框架",然后再按照这个框架去执行。
- 适用场景:极具挑战性的逻辑推理、非常规的数理问题。
- 优点:针对不同任务做到"千人千面"的解题思路,极大提升了零样本(Zero-shot)能力。
- 缺点:前期寻找"解题框架"的开销较大。
7. Reflexion
- 底层原理:引入了强化学习中的试错机制和外部环境反馈(如代码编译器报错信息)。Agent执行后,根据失败的反馈生成一段**"反思经验 (Reflection)"并存入长期记忆**,在下一次尝试时带上这段经验避免踩坑。
- 适用场景:自动化编程(HumanEval)、网页自动化操作、游戏通关。
- 优点:具备了真正的"学习能力",可以通过多次Trial & Error解决极难的任务。
- 缺点:必须有能够提供明确成功/失败反馈的外部环境(Environment);多次试错成本高昂。
8. LATS (Language Agent Tree Search)
- 底层原理:这是目前单体Agent的集大成者。它将蒙特卡洛树搜索(MCTS)与ReAct、Reflexion结合。它在执行时会像下棋一样,同时向前探索多个可能的分支路径,对每个节点的收益进行评估反思,最终找到一条最优路径。
- 适用场景:极高难度的战略规划、复杂的数学证明、高级编程任务。
- 优点:准确率和问题解决率极高,代表了目前单体Agent的最高水平(SOTA)。
- 缺点:计算成本极其恐怖,生成一棵树可能需要消耗海量的Token和时间,不适合日常简单任务。
➕ 补充的分支:扩展Agent边界
9. 重记忆 (Memory-Centric) - 例如:MemGPT
- 底层原理:将LLM视为操作系统的CPU,将上下文窗口视为内存,将外部数据库视为硬盘。Agent被赋予了"翻阅"和"写入"外部存储的动作能力,通过分页加载机制绕过Token限制。
- 适用场景:AI伴侣、超长文档处理、长线剧情NPC。
- 优点:赋予了Agent"无限记忆"的错觉,能够维持长达数月的一致性对话。
- 缺点:检索(Retrieval)不够准确时会导致记忆错乱。
10. 多智能体协同 (Multi-Agent) - 例如:MetaGPT, AutoGen
- 底层原理:将复杂任务拆解给多个设定了不同System Prompt的Agent(如产品经理、程序员、测试员),它们在一个虚拟环境里通过自然语言互相交流、评审、辩论来共同完成任务。
- 适用场景:软件开发全流程、学术论文调研与撰写、复杂剧本杀模拟。
- 优点:利用交叉验证降低了单一LLM的幻觉;模拟人类社会的SOP(标准作业程序)非常有效。
- 缺点:沟通成本高(Agent互相说话很费Token);容易陷入"回音壁"效应(一群Agent互相赞同产生垃圾产出)。
总结来说:
如果是为了解决明确的工具链任务,走重规划 (Planning) 路线效率最高;如果是为了攻克高难度的逻辑与代码任务,走重反思 (Reflection/LATS) 路线成功率最高;如果是企业级复杂应用,通常需要结合多智能体 (Multi-Agent) 架构。