自从大模型诞生以来,我们主动或者被动接收到的信息越来越多,信息爆炸是我们每个人必须面对的问题。如果想提升自己的效率,就得从这些信息中精确筛选出有用的部分,避免自己被淹没在信息的海洋里。试想一下,比如你现在看到一篇文章,随手点了收藏,以为过后就会仔细去阅读,但是很多时候往往进了收藏夹之后就会吃灰。就算哪天真的想起来要看一下收藏夹的文章,如果收藏夹中已经有了大量的文章,且杂乱无序,这时候整理起来也费劲,往往会让人没有想看的欲望。
主流的个人知识库管理工具,主要还是利用了RAG的思想,即:上传文件,查询时检索片段,生成答案。这意味着每次提问,LLM都会重复执行一遍检索,然后根据上下文回答,整个过程没有积累,没有综合,更没有交叉引用。
一、LLM Wiki是什么
基本原理
LLM WiKi是Andrej Karpathy提出的一种基于LLM构建个人知识库的设想,这种构建的思路与RAG不同。当你添加一篇新资料时,LLM不只是索引它以备后用,而是阅读它、提取关键信息、并将其整合到现有 Wiki 中。这个过程会不断更新实体页面、修订主题摘要、标注新旧数据的矛盾之处、强化或修改正在演化的综合分析。
三层架构
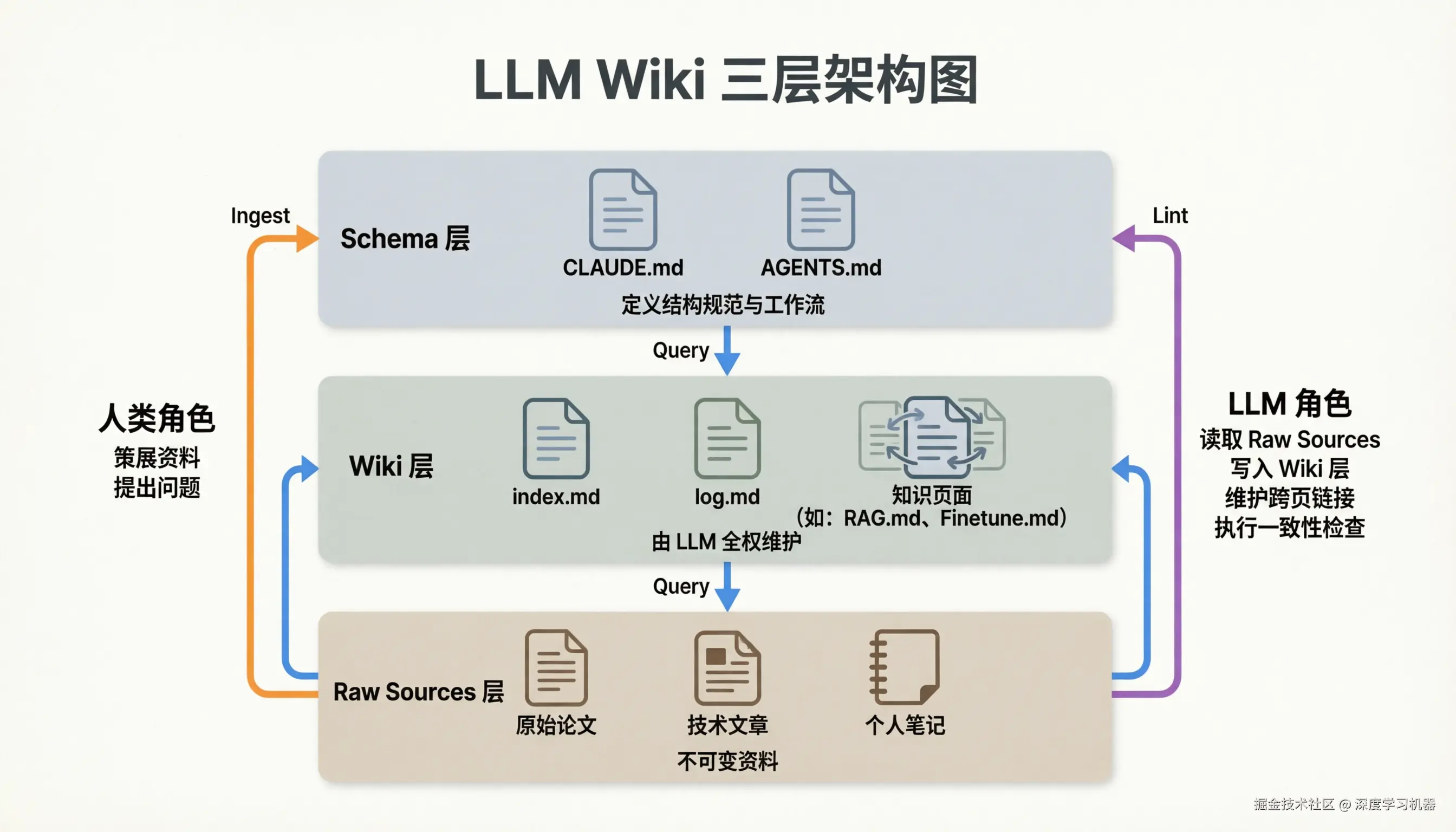
LLM Wiki由三层组成:
1. 原始资料层 (raw/)
上传的源文档集合,可以是文章、论文、图片等形式的数据。这些是不可变的,LLM只读不改,也被称为真相来源(source of truth)。
2. Wiki层 (wiki/)
由LLM生成和维护的Markdown文件目录。包括摘要、实体页面、概念页面、对比分析、综述等。完全由LLM来维护这个文件目录,包括创建页面、在新资料到来时更新、维护交叉引用、保持一致性等操作。
3. Schema层
一个配置文档(如 CLAUDE.md、AGENTS.md 或 SCHEMA.md),告诉LLMWiki的结构约定、工作流程。这是让 LLM 成为Wiki 维护者而非简单chatbot的关键。
三种核心操作
Ingest(摄入):添加新资料时,LLM阅读它、与你讨论要点、写摘要页、更新索引、更新相关实体和概念页面。
Query(查询):向Wiki 提问,然后LLM搜索相关页面、阅读后综合回答并附引用。好的回答可以作为新页面归档回 Wiki,这样随着交互的深入,知识也能复合积累。
Lint(维护):定期让LLM 对Wiki做健康检查,比如查找页面间矛盾、过时声明、孤立页面、缺失的交叉引用、可以通过搜索填补的数据空白。
与RAG的对比
| 维度 | RAG | LLM Wiki |
|---|---|---|
| 知识状态 | 无状态,每次重新检索 | 有状态,持续积累 |
| 处理时机 | 查询时(实时推导) | 摄入时(编译一次) |
| 交叉引用 | 无 | 自动维护 |
| 矛盾处理 | 不处理 | 主动标记 |
| 知识增长 | 线性(加文档数量) | 复合(综合 + 交叉链接) |
| 维护成本 | 低(只需索引) | 高(需要 LLM 编译) |
| 查询成本 | 高(每次检索+生成) | 低(读已编译页面) |
| 适合规模 | 大规模语料 | 中等规模深度研究 |
二、实践教程:搭建个人专用的LLM Wiki
下面我将以AI Agent 架构模式为研究主题,展示如何从零搭建一个LLM Wiki。
编写SCHEMA.md
SCHEMA.md是Agent的指导文件,告诉LLM如何处理Wiki,定义了所有约定。包含以下部分:
bash
# Wiki Schema
本文档定义了 Wiki 的结构约定、页面格式、工作流程和维护规则。
LLM Agent 在操作 Wiki 时必须遵循这些约定。
## 主题
## 目录结构
llm-wiki/
├── SCHEMA.md ← Wiki 约定(LLM + 人类共同维护)
├── raw/ ← 原始资料(不可变)
│ ├── articles/ ← 网络文章、博客
│ ├── papers/ ← 学术论文
│ ├── transcripts/ ← 播客/视频文字稿
│ └── notes/ ← 个人笔记
├── wiki/ ← 知识层(LLM 维护)
│ ├── index.md ← 内容目录
│ ├── log.md ← 操作日志
│ ├── overview.md ← 全局综述
│ └── pages/
│ ├── concepts/ ← 概念页
│ ├── entities/ ← 实体页(框架、工具、人物)
│ ├── comparisons/ ← 对比分析
│ └── synthesis/ ← 综合分析
└── output/ ← 生成产出物
## 页面格式
### Confidence 评分规则
## 命名约定
## 操作流程
### Ingest(摄入)
1. 将原始资料存入 `raw/` 对应子目录
2. 阅读资料,与用户讨论关键要点和强调方向
3. 创建或更新相关 Wiki 页面(一个 source 可能触及多个页面)
4. 为每个新增/修改的事实标注来源
5. 更新 `wiki/index.md`
6. 追加 `wiki/log.md` 条目
7. 运行 backlink audit:检查现有页面是否需要添加指向新内容的链接
### Query(查询)
1. 先读取 `wiki/index.md` 定位相关页面
2. 读取相关页面内容
3. 综合回答,附带 `[[page-link]]` 引用
4. 如果答案有价值,建议将其保存为新的 Wiki 页面
### Lint(维护)
检查项目:
- 🔴 错误:死链接、index.md 中缺失的页面
- 🟡 警告:孤立页面(无入链)、过时内容(source 超过 6 个月未更新)
- 🔵 信息:可以补充的交叉引用、建议创建的新页面
自动修复:
- 补充缺失的 index 条目
- 修复简单的链接错误
- 标记需要人工确认的矛盾
## Log 格式
## 演化规则该文件的核心是告诉Agent如何去进行WiKi的三种核心操作。
初始化目录
告诉Agent"初始化 wiki",它根据SCHEMA.md的指引,会创建完整的目录结构、空的index.md和log.md、以及初始的overview.md。
摄入第一篇资料
arduino
用户: 摄入这个项目 https://github.com/VectifyAI/OpenKBAgent会执行以下操作流程:
bash
1. 读取项目的README
2. 保存到 `raw/articles/2026-05-xx-openkb-vectifyai.md`
3. 展示关键要点(PageIndex、无向量检索、多格式支持等)
4. 创建多个 Wiki 页面:
- `concepts/llm-wiki-pattern.md` --- LLM Wiki 模式定义
- `concepts/vectorless-retrieval.md` --- 无向量检索概念
- `concepts/pageindex.md` --- PageIndex 工作原理
- `entities/openkb.md` --- OpenKB 项目实体页
5. 更新 index.md(添加 4 个条目)
6. 追加 log.md 操作记录在这次Ingest过程中,Agent共操作/生成了7个文件。
摄入第二篇资料
摄入第二篇资料(Hermes Agent)后,Wiki不仅在同样的位置多了几个页面,而且还:
- 已有的
llm-wiki-pattern.md被更新,添加了 Hermes 的引用 - 新概念页之间自动建立了交叉引用
overview.md的"当前认知"部分被扩展- 页面间形成了网状链接结构
这就是LLM WiKi的特点,能够实现复合增长,每篇新资料都让已有知识更丰富。
提问与回写
makefile
用户: LLM Wiki 和 Hermes Agent 有什么关联?Agent从Wiki中检索相关页面,综合出三层关联分析(比如Skills 兼容、记忆同源、自我改进闭环)。这个回答本身有价值,于是保存为 synthesis/llm-wiki-hermes-relationship.md。
好的回答不应该消失在聊天历史中,而应该成为Wiki的一部分。这与现在很多自进化的Agent的思想如出一辙。
使用效果
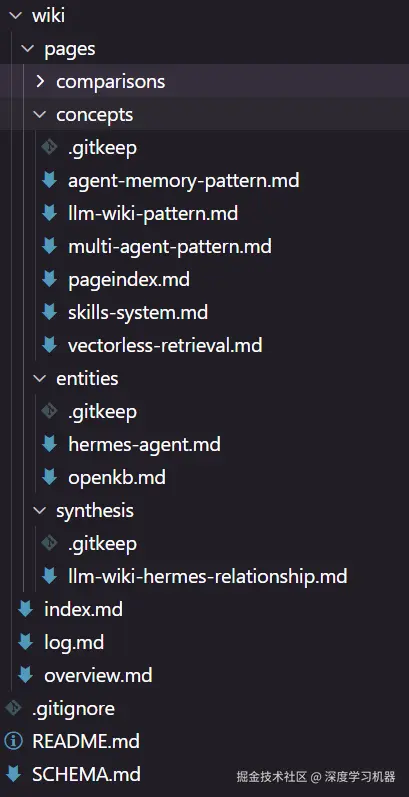
经过摄入2个来源后,Wiki中已有:
- 9个页面(包含6 概念 + 2 实体 + 1 综合分析)
- 自动维护的
index.md和log.md - 一个持续演化的
overview.md
三、使用心得与思考
与大多数LLM应用一样,大模型存在不少局限性,并不一定总能完美地对Wiki进行维护:
-
幻觉风险:LLM可能在摄入时引入原文没有的信息。通过增加Confidence 评分和citation audit能在一定程度上进行缓解。
-
一致性漂移:多次摄入后,不同页面的风格和深度可能不一致。
-
上下文限制 :当Wiki很大时,LLM无法一次读完所有页面。
index.md的设计变得非常关键。 -
判断力有限:什么值得成为独立页面、什么应该合并,LLM可能做得并不好。
维护知识库最繁琐的部分不是阅读或思考,反而是更新引用、保持摘要最新、标注矛盾等会让人感到麻烦。人类会因为维护负担增长快于价值而放弃Wiki,但是LLM不会厌倦。维护成本接近零,这就是LLM Wiki的根本价值。