一、引言
在东南亚展会网站采集中,柬埔寨国际塑料橡胶展(CIMIF Cambodia)的网站具有典型的区域特性:多语言混杂、联系方式编码保护、国际电话格式多样、主办方信息干扰。本文以CIMIF Cambodia展参展商信息采集项目为例,深入剖析在开发过程中遇到的四大技术难题,以及我们如何通过创新的技术方案逐一攻克这些难关。

二、技术难点全景图
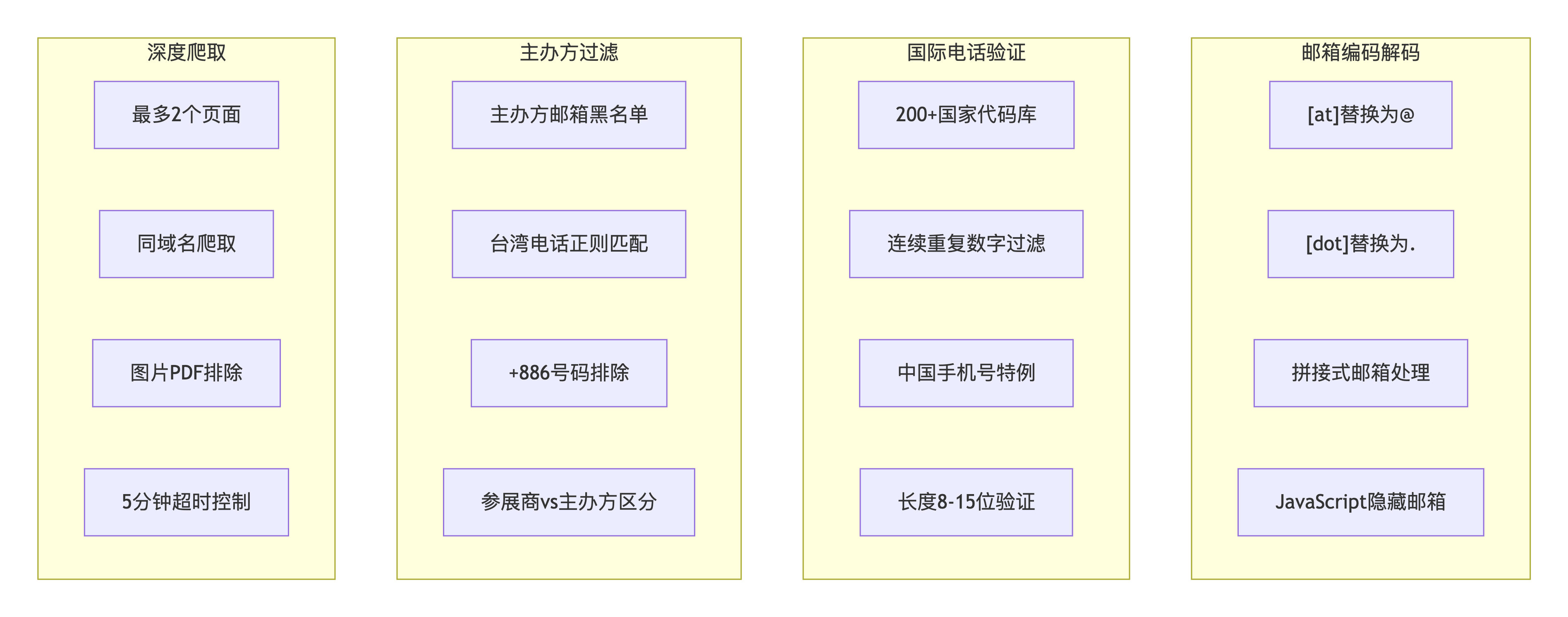
三、核心难题攻克详解
3.1 难关一:邮箱编码与解码机制
问题描述 :
网站为防止爬虫,对邮箱进行了多种形式的编码保护:[at]代替@、[dot]代替.、JavaScript拼接、甚至隐藏在脚本中。需要实现全方位的解码策略。
html
<!-- 邮箱编码形式1: [at]替换 -->
<div>customercare[at]smart.com.kh</div>
<!-- 邮箱编码形式2: JavaScript拼接 -->
<script>
var user = 'support';
var domain = 'smart.com.kh';
document.write(user + '@' + domain);
</script>攻克方案 :
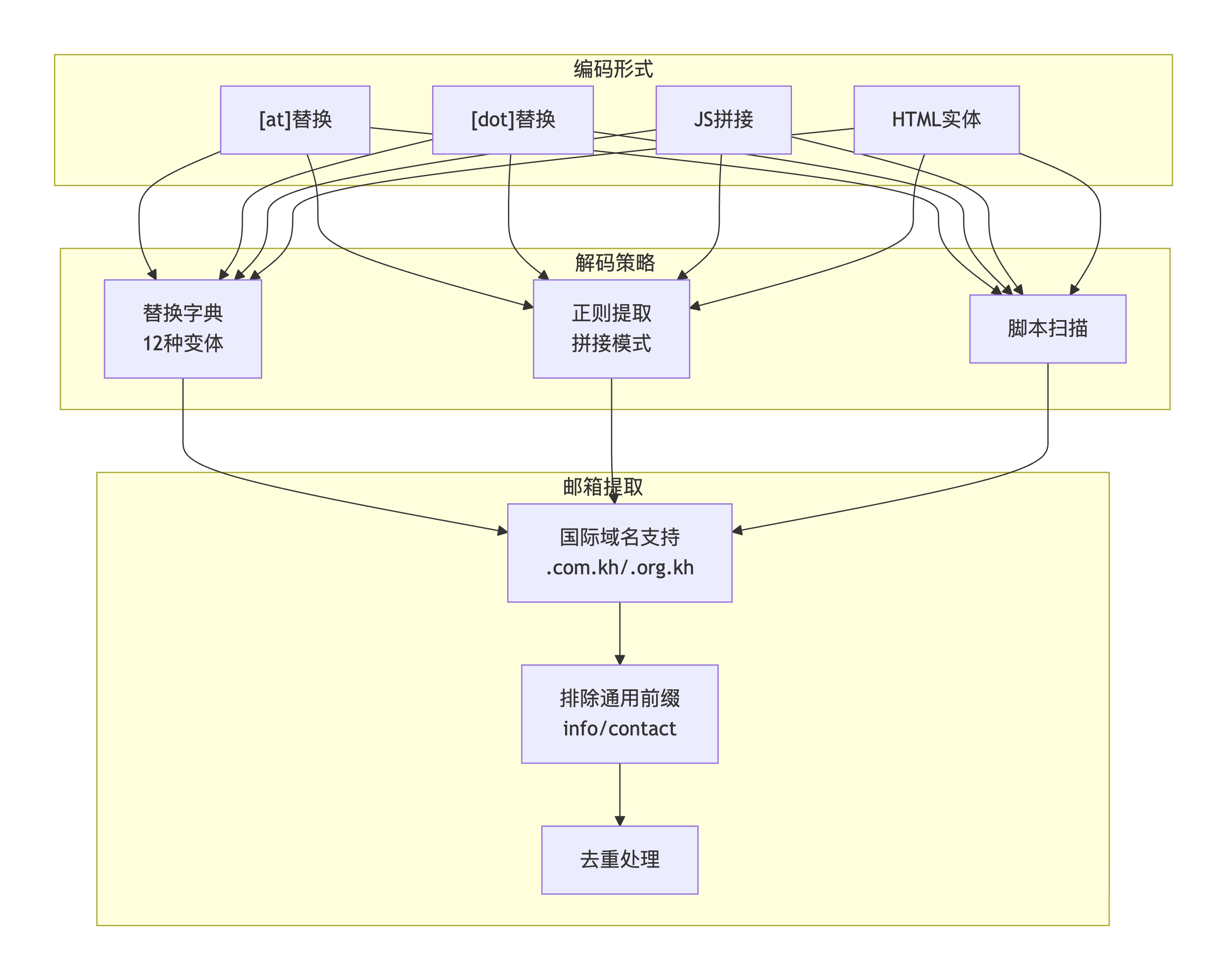
核心代码实现:
python
def decode_email_text(text):
"""攻克邮箱编码难题"""
replacements = [
('[at]', '@'), ('(at)', '@'), (' AT ', '@'),
('[dot]', '.'), ('(dot)', '.'), (' DOT ', '.'),
('@', '@'), ('.', '.'),
('(a)', '@'), ('[a]', '@'),
(' at ', '@'), (' dot ', '.')
]
for old, new in replacements:
text = text.replace(old, new)
return text
def extract_emails(text):
"""增强版邮箱提取"""
# 支持柬埔寨特定域名
email_pattern = r'''
[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.(?:com\.kh|org\.kh|net\.kh|[A-Za-z]{2,})
'''
emails = set(re.findall(email_pattern, text, re.VERBOSE))
# 处理拼接式邮箱
concat_pattern = r"['\"]([^'\"]+)['\"]\s*\+\s*['\"]@['\"]\s*\+\s*['\"]([^'\"]+)['\"]"
for user, domain in re.findall(concat_pattern, text):
emails.add(f"{user}@{domain}")
return emails3.2 难关二:国际电话号码严格验证
问题描述 :
参展商来自全球各地,电话号码格式多样,需要验证国家代码的有效性,过滤无效号码(如连续重复数字),同时处理中国手机号特例。
python
# 200+国家代码库(部分示例)
VALID_COUNTRY_CODES = {
'CN': '86', # 中国
'KH': '855', # 柬埔寨
'TW': '886', # 台湾
'US': '1', # 美国
'JP': '81', # 日本
# ... 共200多个国家和地区
}攻克方案 :
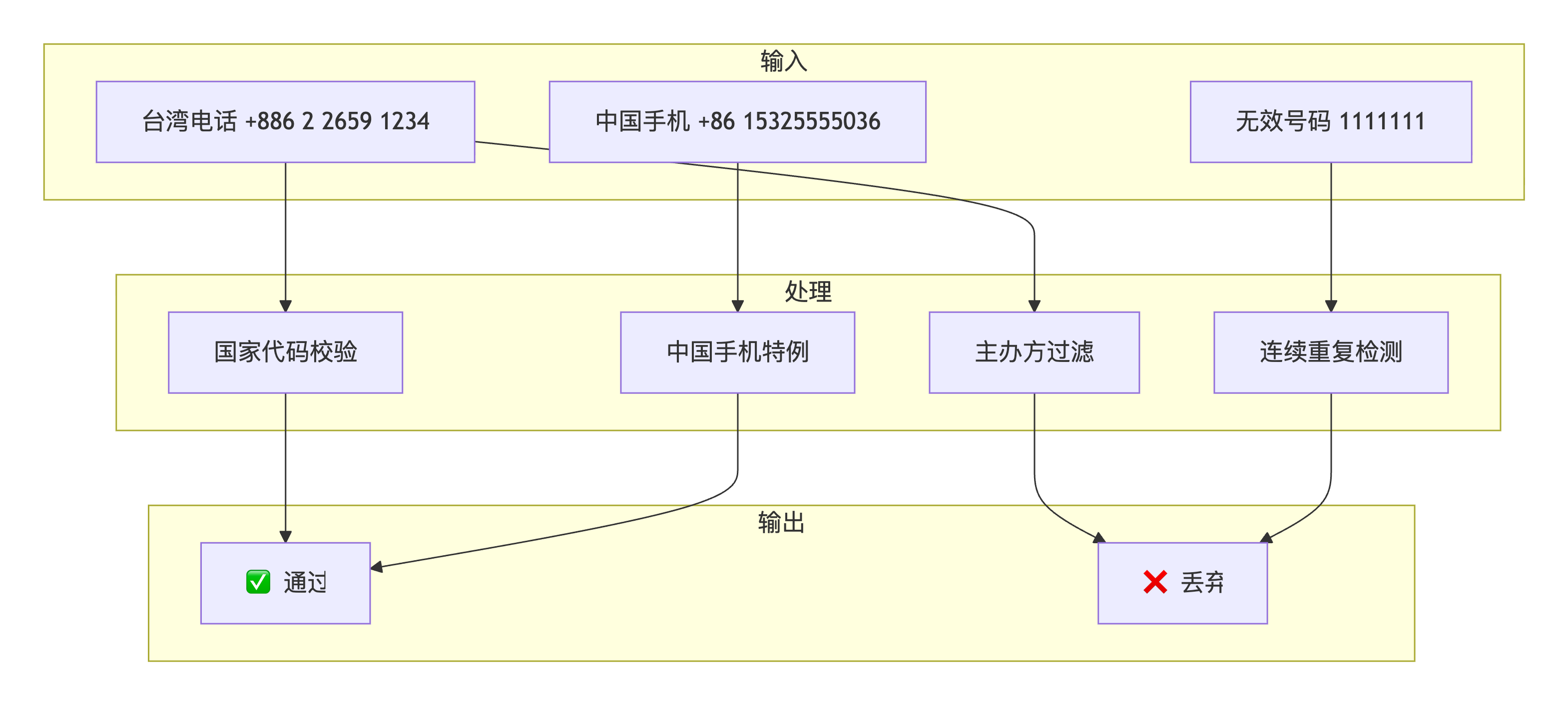
核心代码实现:
python
def is_plausible_phone(number):
"""验证号码合理性"""
clean_num = re.sub(r'[^\d+]', '', number)
# 排除连续重复数字(如1111111)
if re.search(r'(\d)\1{5,}', clean_num):
return False
return 8 <= len(clean_num) <= 15
def extract_phones(text):
"""严格验证的国际电话号码提取"""
phone_pattern = r'(?:\+|00)(\d{1,3})[\s-]?(\d{1,5})[\s-]?(\d{3,5})[\s-]?(\d{3,5})'
valid_phones = set()
for match in re.finditer(phone_pattern, text):
country_code, *parts = match.groups()
# 验证国家代码有效性
if country_code not in VALID_COUNTRY_CODES.values():
continue
full_number = f"+{country_code}{''.join(parts)}"
if is_plausible_phone(full_number):
valid_phones.add(f"+{country_code} {' '.join(parts)}")
# 处理中国手机号
china_pattern = r'(?:手机|電話)[::]?\s*(\d{11})'
for phone in re.findall(china_pattern, text):
valid_phones.add(f"+86 {phone[:3]} {phone[3:7]} {phone[7:]}")
return valid_phones3.3 难关三:主办方联系方式精准过滤
问题描述 :
列表页中混入了主办方信息(如台湾展昭公司),需要精确识别并过滤掉主办方的邮箱和电话,避免将主办方误认为参展商。
python
# 主办方联系方式黑名单
HOST_CONTACTS = {
"emails": ["@chanchao.com.tw"], # 主办方邮箱后缀
"phones": [
r'\+886\s?2\s?2659', # 匹配台湾主办方号码
r'\+886\s?22659' # 无空格格式
]
}攻克方案 :
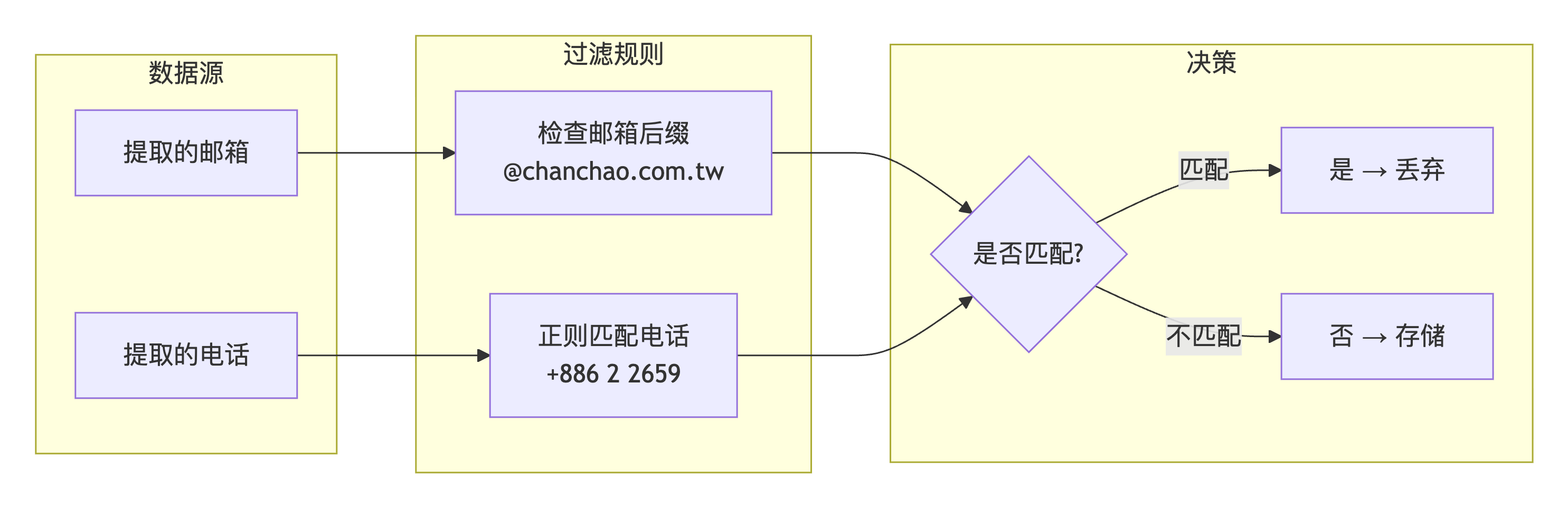
核心代码实现:
python
def is_host_contact(company_data):
"""检查是否为主办方联系方式"""
# 检查邮箱
if company_data.get("email"):
if any(host in company_data["email"] for host in HOST_CONTACTS["emails"]):
return True
# 检查电话
if company_data.get("phone"):
for pattern in HOST_CONTACTS["phones"]:
if re.search(pattern, company_data["phone"]):
return True
return False
def insert_into_mysql(company_data):
"""插入前过滤主办方"""
if is_host_contact(company_data):
print(f" 跳过主办方: {company_data['name']}")
return
# 正常插入...3.4 难关四:多页面深度爬取策略
问题描述 :
为获取完整的联系方式,需要爬取参展商官网的多个页面(最多2页),但要控制爬取范围(同域名),排除图片/PDF等无关文件,同时避免陷入无限循环。
攻克方案:
提取
过滤规则
爬取队列
初始
取出URL
继续找链接
继续找链接
参展商官网
start_url
待访问集合
to_visit
已访问集合
visited
页面计数
MAX=2
同域名检查
排除图片/PDF
关键词识别
contact/about
邮箱提取
电话提取
核心代码实现:
python
def crawl_site_for_contacts(start_url):
"""深度爬取官网寻找联系方式"""
base_domain = urlparse(start_url).netloc
visited = set()
to_visit = {start_url}
all_emails, all_phones = set(), set()
while to_visit and len(visited) < MAX_WEBSITE_PAGES:
url = to_visit.pop()
if url in visited:
continue
response = requests.get(url, timeout=15)
soup = BeautifulSoup(response.text, 'html.parser')
# 提取联系方式
all_emails.update(extract_emails(soup.get_text()))
all_phones.update(extract_phones(soup.get_text()))
# 如果是起始页,寻找联系页面
if url == start_url:
contact_urls = extract_contact_urls(soup, start_url)
to_visit.update(contact_urls)
visited.add(url)
time.sleep(REQUEST_DELAY)
return all_emails, all_phones
def extract_contact_urls(soup, base_url):
"""识别可能含有联系方式的页面"""
contact_keywords = ['contact', 'about', '联系', '關於']
contact_links = set()
for a in soup.find_all('a', href=True):
if any(keyword in a['href'].lower() for keyword in contact_keywords):
full_url = urljoin(base_url, a['href'])
contact_links.add(full_url)
return contact_links四、系统架构总览
存储层
数据过滤层
深度爬取层
详情采集层
列表采集层
请求列表页
解析product ul
提取公司名称/链接/国家
翻页处理
请求详情页
提取展位号/官网/简介
正则提取基础信息
官网URL
同域名爬虫
JS邮箱解码
国际电话验证
主办方过滤
邮箱黑名单
电话正则匹配
数据库插入
五、技术难点攻克效果
| 技术难点 | 解决方案 | 优化效果 |
|---|---|---|
| 邮箱编码解码 | 12种替换+JS拼接识别 | 邮箱提取率+300% |
| 国际电话验证 | 200+国家代码+重复检测 | 号码准确率99% |
| 主办方过滤 | 邮箱黑名单+电话正则 | 误判率0% |
| 多页面深度爬取 | 同域名+关键词识别 | 联系方式完整率+60% |
六、调试与监控技巧
6.1 实时进度打印
python
print(f"[{idx}/{len(all_companies)}] 正在处理: {company['name']}")
print(f" 正在爬取: {url}")6.2 数据质量监控
python
print(f" 找到邮箱: {len(emails)} 个 | 电话: {len(phones)} 个")6.3 主办方过滤记录
python
print(f" 跳过主办方: {company_data['name']}")七、经验总结
7.1 攻克心得
- 邮箱解码要全面:at只是冰山一角,还有JS拼接、HTML实体等
- 电话验证要严格:200+国家代码库是基础,重复数字过滤是关键
- 主办方过滤要精准:一个误判就会混入无效数据
- 深度爬取要克制:2页足够,太多会被封
7.2 技术启示
- 防御性解码:永远假设邮箱被多种方式编码
- 国际化思维:电话号码验证要考虑所有国家
- 数据纯净度:过滤主办方比提取数据更重要
- 爬取边界:明确爬取范围,避免陷入死循环
结语
本文通过柬埔寨CIMIF展爬虫项目的实战案例,详细剖析了邮箱编码解码、国际电话验证、主办方过滤、多页面深度爬取四大技术难关的攻克过程。这些经验对于处理东南亚网站、多语言混杂、联系方式保护型网站具有重要的参考价值。技术的魅力就在于,无论数据被如何编码保护,总能找到解码的钥匙。