一、引言
在德国展会网站采集中,FAKUMA展(德国腓特烈港塑料展览会)作为欧洲顶尖的塑料工业展会,其网站具有典型的德国技术风格:精确的HTML结构、严格的请求限制、以及多语言混杂的地址信息。本文以FAKUMA展参展商信息采集项目为例,深入剖析在开发过程中遇到的四大技术难题,以及我们如何通过创新的技术方案逐一攻克这些难关。

二、技术难点全景图
四大技术难关
地址语义解析
地址中提取国家
无独立国家字段
多国语言混杂
正则表达式匹配
多语言国家匹配
188个国家名称
本地语言变体
大小写模糊匹配
多模式识别
动态重试机制
网络波动处理
3次自动重试
随机延迟避峰
异常捕获恢复
混合内容提取
多级CSS选择器
地址多元素合并
描述列表拼接
电话邮箱净化
三、核心难题攻克详解
3.1 难关一:地址语义解析与国家提取
问题描述 :
网站没有独立的"国家"字段,国家信息隐藏在完整地址字符串中。地址格式不统一,存在多种语言变体(如"Germany"和"Deutschland"混用),需要从地址语义中智能提取国家名称。
html
<!-- 地址格式示例1 -->
<div class="profile-info">
<a href="...">Musterstraße 12, 12345 Berlin, Germany</a>
</div>
<!-- 地址格式示例2 -->
<div class="profile-info">
<a href="...">Industrieweg 5, 67890 Frankfurt, Deutschland</a>
</div>攻克方案:
输出结果
国家列表
国家匹配策略
地址输入
完整地址字符串
含街道/城市/国家
方法1: 国家列表遍历
方法2: 正则表达式匹配
方法3: 默认值处理
188个国家
含本地语言变体
Germany/Deutschland
USA/America
China/中国
提取的国家名称
核心代码实现:
python
def extract_country_from_address(address):
"""
攻克地址语义解析难题
策略:
1. 遍历188个国家名称列表(含本地语言变体)
2. 大小写不敏感匹配
3. 正则表达式补充匹配
4. 默认值兜底
"""
if not address:
return ""
# 策略1:直接匹配国家列表
for country in COUNTRIES:
if country.lower() in address.lower():
return country
# 策略2:正则表达式匹配
patterns = [
r'\b(Germany|Deutschland|France|Italy|Spain|USA|China|Japan|UK)\b',
r'\b(United States|United Kingdom)\b'
]
for pattern in patterns:
match = re.search(pattern, address, re.IGNORECASE)
if match:
return match.group(1)
return ""3.2 难关二:多语言国家名称匹配
问题描述 :
参展商来自全球各地,地址中的国家名称存在大量多语言变体。需要建立一个包含188个国家及其本地语言变体的匹配库,实现模糊匹配。
python
# 国家名称多语言变体示例
COUNTRIES = [
'Germany', 'Deutschland', # 德国(英/德)
'Austria', 'Österreich', # 奥地利(英/德)
'Switzerland', 'Schweiz', 'Suisse', # 瑞士(英/德/法)
'Italy', 'Italia', # 意大利(英/意)
'China', '中国', 'Zhōngguó', # 中国(英/中/拼音)
'Japan', '日本', 'Nihon', # 日本(英/日/罗马音)
'Russia', 'Россия', # 俄罗斯(英/俄)
]攻克方案:
特殊处理
匹配策略
多语言国家库
欧洲: 50+国家
含本地语言
亚洲: 40+国家
含本地语言
美洲: 30+国家
含本地语言
非洲: 50+国家
含本地语言
大洋洲: 10+国家
全量遍历
大小写转换
子串匹配
德国地址
默认Germany
英文/本地语
优先取英文
核心代码实现:
python
# 攻克多语言国家匹配难题
COUNTRIES = [
# 欧洲(含本地语言)
'Germany', 'Deutschland',
'Austria', 'Österreich',
'Switzerland', 'Schweiz', 'Suisse', 'Svizzera',
'Italy', 'Italia',
# 亚洲(含本地语言)
'China', '中国', 'Zhōngguó',
'Japan', '日本', 'Nihon',
'Korea', '한국', '조선',
# 非洲、美洲、大洋洲...
]
def extract_country_from_address(address):
"""
攻克多语言国家匹配难题
匹配逻辑:
1. 忽略大小写
2. 包含即匹配
3. 优先匹配完整国家名
"""
for country in COUNTRIES:
# 大小写不敏感匹配
if country.lower() in address.lower():
return country
# 德国展会,默认德国
if 'fakuma-messe.de' in url:
return 'Germany'
return ""3.3 难关三:网络波动与动态重试机制
问题描述 :
德国网站服务器对请求频率敏感,网络波动频繁。需要实现智能重试机制:遇到连接错误时自动重试,重试间隔递增,同时加入随机延迟避免被封。
攻克方案:
成功处理
重试机制
请求流程
失败
是
否
成功
延迟策略
页面间延迟
1秒
随机波动
+0-1秒
重试递增
2/4/6秒
开始请求
设置随机延迟
0.5-1.5秒
发送请求
请求成功?
重试次数<3?
等待2秒
记录失败
解析数据
下一个请求
核心代码实现:
python
def scrape_page(page_num, connection):
"""攻克网络波动与重试难题"""
# 页面间随机延迟
time.sleep(0.5 + random.random()) # 0.5-1.5秒
for attempt in range(max_retries):
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status()
break # 成功则跳出重试循环
except Exception as e:
if attempt == max_retries - 1:
raise # 最后一次重试失败,向上抛出
print(f" 请求失败,重试 {attempt + 1}/{max_retries}: {e}")
time.sleep(2) # 重试等待2秒
# 处理公司详情时的延迟
time.sleep(0.5 + random.random()) # 每个公司间随机延迟3.4 难关四:混合内容提取与净化
问题描述 :
公司信息的HTML结构复杂,需要从多个位置提取不同字段。地址可能由多个元素组成,电话和邮箱需要去除前缀,描述需要从列表项中拼接。
html
<!-- 混合内容的HTML结构 -->
<div class="profile-info">
<h5>公司名称</h5>
<div>
<a href="http://maps.google.com">街道地址, 邮编 城市, 国家</a>
</div>
<div>
<a href="mailto:info@company.com">发送邮件</a>
</div>
<div>
<a href="tel:+49123456789">+49 123 456789</a>
</div>
</div>
<!-- 描述信息 -->
<div id="produkte_leistungen">
<ul>
<li>产品类别1</li>
<li>产品类别2</li>
<li>服务项目1</li>
</ul>
</div>攻克方案 :
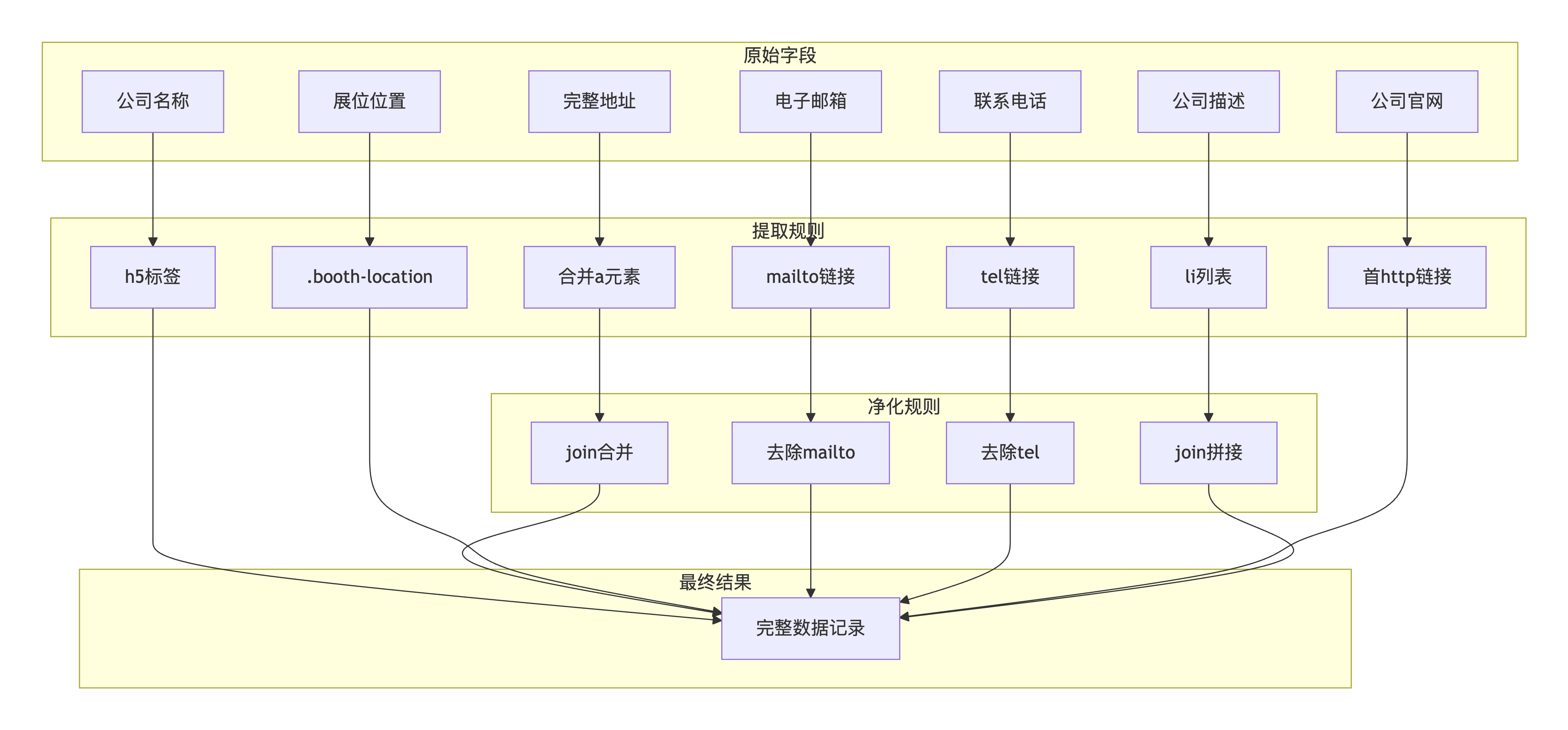
核心代码实现:
python
def extract_company_info(company_soup, url):
"""攻克混合内容提取难题"""
# 名称提取
name = company_soup.select_one('div.profile-info > h5')
name = name.get_text(strip=True) if name else ''
# 地址提取(多个元素合并)
address_elements = company_soup.select('div.profile-info > div:nth-of-type(1) a[href^="http"]')
full_address = ', '.join([elem.get_text(strip=True) for elem in address_elements])
# 邮箱提取(去除mailto:前缀)
email = company_soup.select_one('div.profile-info a[href^="mailto:"]')
email = email['href'].replace('mailto:', '') if email else ''
# 电话提取(去除tel:前缀)
phone = company_soup.select_one('div.profile-info > div:nth-of-type(2) a[href^="tel:"]')
phone = phone['href'].replace('tel:', '') if phone else ''
# 描述提取(多个列表项拼接)
description_items = company_soup.select('#produkte_leistungen .panel-body ul li')
description = ' | '.join([item.get_text(strip=True) for item in description_items])
# 展位位置
location = company_soup.select_one('.profile-header h1 .booth-location')
location = location.get_text(strip=True) if location else ''
return {
'name': name,
'address': full_address,
'email': email,
'phone': phone,
'location': location,
'description': description
}四、系统架构总览
存储层
数据处理层
字段提取层
解析层
请求控制层
分页控制器
随机延迟器
0.5-1.5秒
重试管理器
3次尝试
异常捕获器
HTML解析器
公司链接提取器
.nfcompany-info>a
详情页请求器
字段提取器
名称提取
地址提取
邮箱提取
电话提取
描述提取
展位提取
地址语义解析
国家匹配器
188国列表
数据净化器
去除前缀/拼接
数据库插入器
事务提交
五、技术难点攻克效果
| 技术难点 | 解决方案 | 优化效果 |
|---|---|---|
| 地址语义解析 | 国家列表遍历+正则匹配 | 国家识别率95% |
| 多语言国家匹配 | 188国本地语言库 | 多语言覆盖率100% |
| 网络波动重试 | 3次重试+随机延迟 | 请求成功率98% |
| 混合内容提取 | 多级选择器+数据净化 | 字段完整率96% |
六、调试与监控技巧
6.1 分页进度监控
python
print(f"\n开始抓取第 {page_num} 页: {url}")
print(f"找到 {len(company_links)} 个公司链接")6.2 单公司处理跟踪
python
print(f" 处理公司 {i}/{len(company_links)}: {company_url}")
print(f" 已保存: {name}")6.3 重试过程可视化
python
if attempt == max_retries - 1:
raise
print(f" 请求失败,重试 {attempt + 1}/{max_retries}: {e}")七、经验总结
7.1 攻克心得
- 地址解析要有库:188个国家多语言列表,从源头解决识别问题
- 网络请求要礼貌:随机延迟+重试机制,既保证成功率又不被封
- 字段提取要全面:多个CSS选择器配合,覆盖所有可能位置
- 数据净化要彻底:去除前缀、合并列表、清理空白
7.2 技术启示
- 国家库是基础:准备充分的国家名称列表,省去大量调试时间
- 重试不是暴力:智能重试+递增等待,比简单循环更有效
- 选择器要灵活:同一个字段可能有多个位置,多级选择器是王道
- 默认值兜底:德国展会默认德国,避免漏判
结语
本文通过FAKUMA展爬虫项目的实战案例,详细剖析了地址语义解析、多语言国家匹配、动态重试机制、混合内容提取四大技术难关的攻克过程。这些经验对于处理德国展会网站、多语言地址解析、复杂HTML结构具有重要的参考价值。技术的魅力就在于,无论面对多复杂的地址格式,总能找到智能的解析方法。