一、引言
1.1 核心概念定义
关系查询语言分为过程化与非过程化两大类:关系代数属于过程化语言,需明确指定操作的执行顺序;元组关系演算、域关系演算属于非过程化语言,仅描述查询结果的约束条件,不指定具体执行步骤。查询优化是数据库管理系统将非过程化查询转换为高效执行计划的核心模块,三者共同构成关系数据库查询处理的完整理论与工程体系。
1.2 软考定位
本知识点属于软考数据系统工程师考试中 "数据库系统原理" 模块的核心内容,历年考察占比约 5%-8%,题型覆盖选择题、案例分析题,核心考点包括元组演算的量词用法、演算与关系代数的等价性、查询优化准则的应用等,是区分考生理论深度的关键考点。
1.3 历史发展脉络
1970 年 E.F.Codd 提出关系模型时首次引入关系代数概念;1972 年 Codd 进一步提出元组关系演算,证明其与关系代数表达能力等价;1977 年 Ullman 提出域关系演算,完善了非过程化查询理论体系;20 世纪 80 年代后,基于代价的查询优化技术逐步成为商用数据库的标准实现,相关理论持续演进至今。
1.4 内容框架
本文将依次讲解两种关系演算的核心原理、实现对比、实际应用、查询优化架构设计及行业发展趋势,最后给出软考备考与工程实践建议。
二、核心技术原理:两类关系演算的逻辑基础
2.1 元组关系演算
2.1.1 基本定义与表达式结构
元组关系演算以元组为基本操作单元,标准表达式为{ t | P(t) },表示所有满足谓词条件 P (t) 的元组 t 的集合。其中 t 是元组变量,代表关系中的完整行记录,P (t) 是由原子公式和运算符组合而成的递归逻辑表达式。
2.1.2 三大原子公式
R (t):表示元组 t 是关系 R 中的合法元组,是元组归属的基础判断
t i θ c 或 c θ t i:θ 为比较运算符(>、=、<、≥、≤、≠),表示元组 t 的第 i 个分量与常量 c 满足指定比较关系,是单属性过滤的核心逻辑
t i θ u j:表示元组 t 的第 i 个分量与元组 u 的第 j 个分量满足指定比较关系,是多表关联条件的理论基础
2.1.3 量词的逻辑语义
存在量词∃:∃ t(P(t))表示存在至少一个元组 t 使得 P (t) 为真,对应 SQL 中的 EXISTS、IN 关键字,逻辑复杂度为 O (n),仅需遍历一次元组即可验证
全称量词∀:∀ t(P(t))表示所有元组 t 均满足 P (t) 为真,对应 SQL 中的 ALL 关键字,逻辑复杂度为 O (n),可通过德摩根定律等价转换为¬∃ t(¬P(t)),是软考的高频易错考点
2.1.4 表达能力边界
根据 Codd 的等价性定理,安全的元组关系演算与关系代数表达能力完全等价,不存在某种查询仅能用其中一种方式实现。
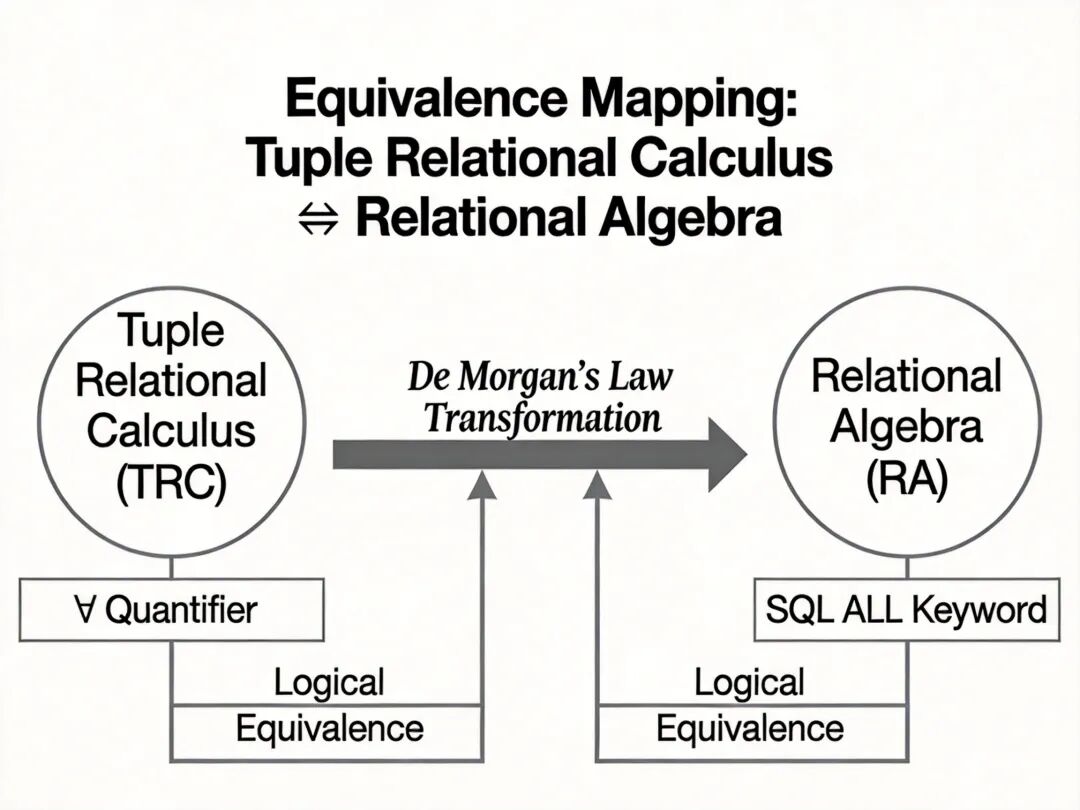
元组演算与关系代数的逻辑映射关系示意图
2.2 域关系演算
2.2.1 基本定义与表达式结构
域关系演算以属性值(域变量)为基本操作单元,标准表达式为{ | P(x₁,x₂,...,xₖ) },表示所有满足谓词条件 P 的域变量组合的集合。其中 x₁到 xₖ为独立的域变量,分别对应查询结果的不同属性列。
2.2.2 核心特征
域演算的原子公式结构与元组演算一致,仅将操作对象从元组分量替换为独立域变量,无需通过元组下标访问属性,语法更接近自然查询逻辑。典型的域演算实现是 QBE(查询示例)语言,是可视化查询工具的理论基础。
2.2.3 与元组演算的对比
| 对比维度 | 元组关系演算 | 域关系演算 |
|---|---|---|
| 操作单元 | 完整元组(行) | 单个属性值(域) |
| 变量访问方式 | t i 通过下标访问分量 | 直接使用独立域变量 |
| 适用场景 | 多表关联、复杂条件查询 | 单表查询、可视化查询系统 |
| 软考考察频率 | 高频 | 低频,仅考察基本概念 |
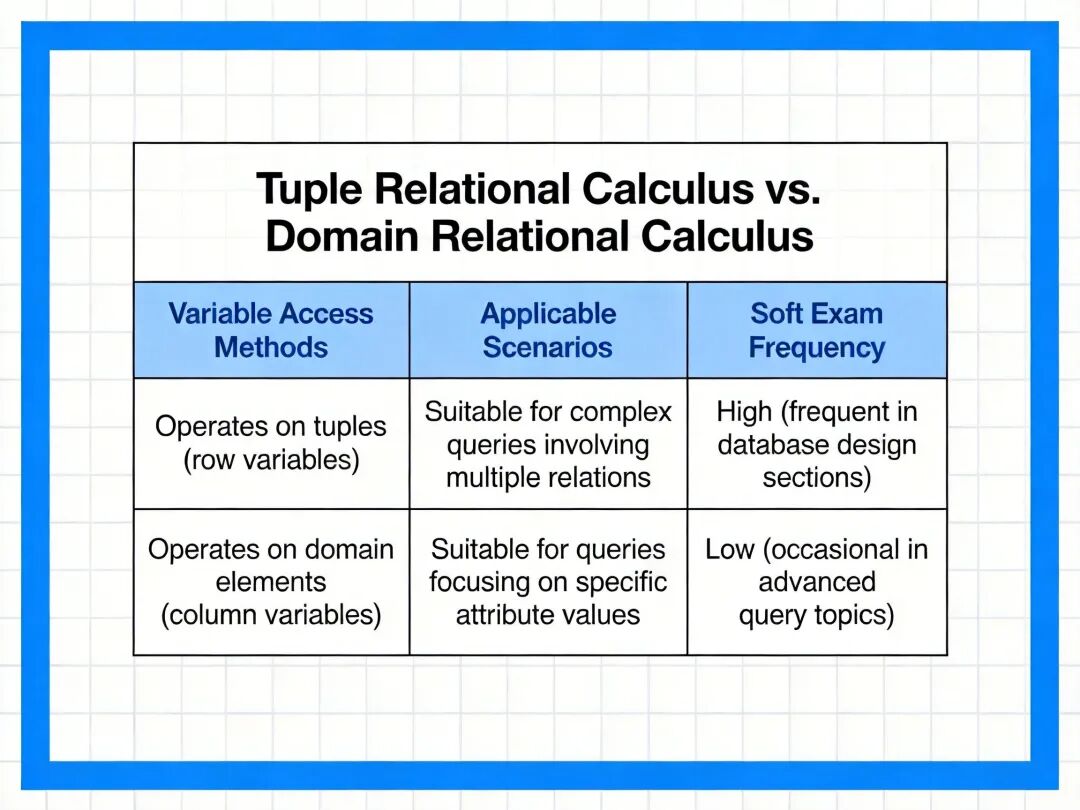
元组演算与域演算的结构对比表
三、实现方法与方案对比:查询优化的技术路径
3.1 代数优化(逻辑优化)
3.1.1 核心实现思路
基于关系代数的等价变换规则,对初始查询树进行重写,在不改变查询结果的前提下,降低中间结果的规模。核心是六大优化准则:
选择运算下推:将选择条件尽可能移到查询树的叶节点执行,是效率提升最显著的优化手段,平均可降低中间结果规模 1-2 个数量级
笛卡尔积合并为连接:将笛卡尔积操作与后续的等值选择条件合并为连接操作,避免生成全量笛卡尔积,对于百万级表可将运算时间从小时级降至秒级
投影运算合并:将投影操作与相邻的选择、连接运算合并执行,避免单独扫描关系进行列裁剪
公共子表达式复用:对多次出现的相同子查询结果进行物化存储,避免重复计算
连接顺序优化:优先执行选择率高的连接操作,减少后续连接的元组数量
选择 / 投影运算合并:将多个连续的选择条件、多个连续的投影操作合并为单次操作
3.1.2 适用场景
代数优化不依赖数据库的物理存储信息,属于通用优化策略,适用于所有关系数据库系统,是手动 SQL 优化的核心理论依据。
3.2 物理优化
3.2.1 核心实现思路
基于数据库的统计信息(表记录数、索引分布、数据离散度等),计算不同执行路径的代价,选择总代价最低的执行计划。主流代价模型综合考虑 CPU 代价、I/O 代价、内存代价、网络代价四个维度,其中 I/O 代价通常占总代价的 70% 以上。
3.2.2 典型实现方案
基于规则的优化(RBO):根据预设的优先级规则选择执行计划,如索引扫描优先级高于全表扫描,嵌套循环连接优先级高于排序合并连接,Oracle 10g 之前版本默认采用该方案
基于代价的优化(CBO):通过统计信息计算不同路径的代价,选择代价最低的方案,是当前 MySQL、PostgreSQL 等主流数据库的默认实现
3.2.3 方案对比
| 对比维度 | RBO | CBO |
|---|---|---|
| 实现复杂度 | 低 | 高 |
| 优化效果 | 依赖规则完善度,上限较低 | 依赖统计信息准确性,上限高 |
| 适用场景 | 简单查询、嵌入式数据库 | 复杂查询、企业级数据库 |
| 维护成本 | 低 | 高,需定期更新统计信息 |
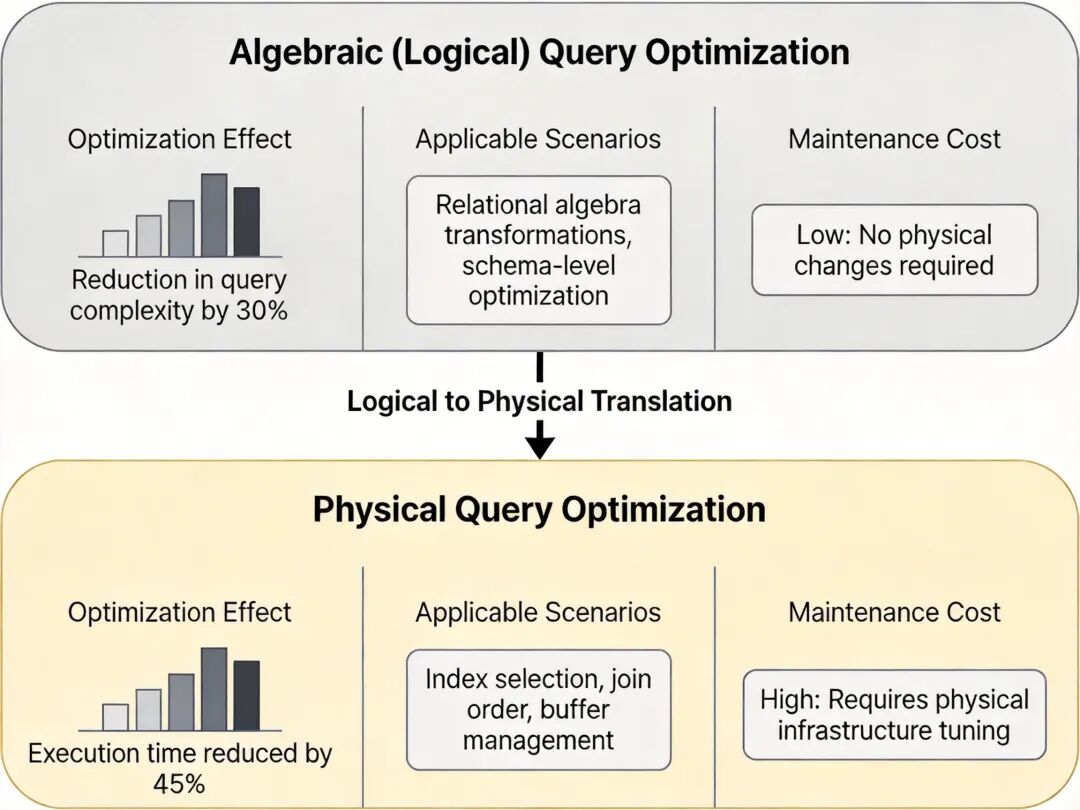
查询优化的两层技术架构图
四、实际应用与案例分析
4.1 元组演算的真题应用
2016 年软考第 37 题:已知关系 R (A,B,C)={(1,2,3),(4,5,6),(7,8,9),(10,11,12)},关系 S (D)={(3),(4),(5),(6)},求表达式T={t|R(t) ∧ ∀u(S(u) → t3 > u1)}的结果。
逻辑解析:R(t)表示元组 t 来自关系 R,∀u(S(u) → t3 > u1)表示对于 S 中所有元组 u,t 的第三个分量均大于 u 的第一个分量,等价于 t 3 大于 S 中 D 列的最大值
计算过程:S 中 D 列最大值为 6,R 中 C 列大于 6 的元组为 (7,8,9) 和 (10,11,12),最终答案为上述两个元组的集合4.2 查询优化的工程案例
某电商系统订单查询初始 SQL 为:
sql
SELECT o.order_id, u.user_name
FROM orders o, users u
WHERE o.user_id = u.user_id
AND o.create_time > '2024-01-01'
AND u.city = '上海';初始执行计划为:先对 orders 表(1000 万条)和 users 表(100 万条)做笛卡尔积,再过滤条件,执行时间 28 秒。
优化后执行计划遵循选择下推准则:
先过滤 users 表中 city=' 上海 ' 的记录,得到 1.2 万条结果
过滤 orders 表中 create_time>'2024-01-01' 的记录,得到 80 万条结果
对两个过滤后的结果按 user_id 做等值连接,执行时间降至 0.32 秒,性能提升 87.5 倍4.3 常见错误避坑
元组演算中全称量词与存在量词的混淆:将 "大于所有值" 错误理解为 "大于任意一个值",导致条件逻辑完全相反
查询优化中过度下推:将包含聚合函数、子查询的选择条件错误下推到子查询内部,导致查询结果错误
忽略统计信息更新:CBO 优化器统计信息过期时,会生成错误的执行计划,如对大表选择全表扫描而非索引扫描
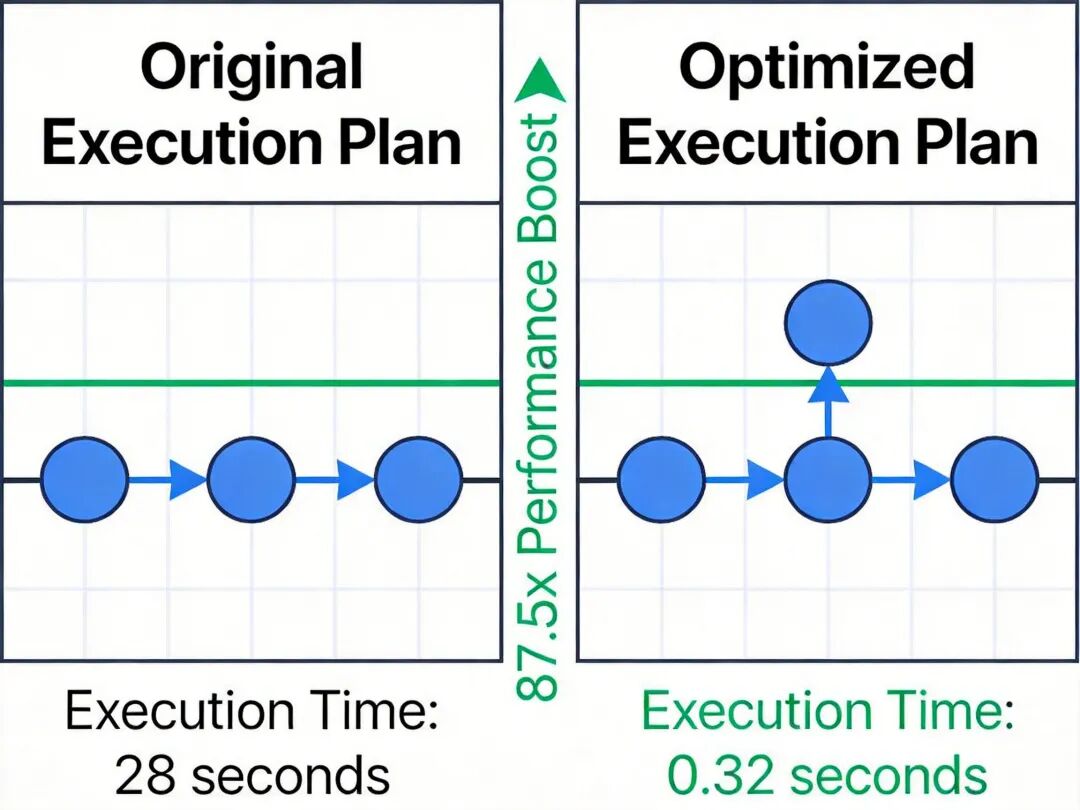
查询优化前后执行计划对比示意图
五、系统设计与架构:查询处理器的核心模块
5.1 查询处理器整体架构
数据库查询处理器分为四个核心模块,数据流依次为:
查询解析器:对输入的 SQL 语句进行语法解析、语义检查,生成初始查询树
逻辑优化器:应用代数优化规则对初始查询树进行等价重写,生成逻辑查询计划
物理优化器:基于统计信息生成多个候选物理执行计划,通过代价模型选择最优计划
执行引擎:按照最优执行计划调用存储引擎接口完成数据访问,返回查询结果
5.2 关键模块设计细节
统计信息模块:存储表的元组数、属性值分布、索引基数等信息,MySQL 通过ANALYZE TABLE命令更新统计信息,PostgreSQL 通过ANALYZE命令更新
代价估算模型:默认 I/O 代价为单次随机读 10ms,CPU 代价为单次元组比较 0.1ms,不同数据库可通过参数调整代价权重
计划缓存模块:将高频查询的执行计划缓存,避免重复优化开销,缓存命中率通常可达 90% 以上
5.3 高可用与扩展性设计
分布式查询优化:在分布式数据库中,优化器需额外考虑网络传输代价,优先选择本地计算减少数据跨节点传输,符合 CAP 理论中的网络分区容忍性要求
自适应查询优化:在查询执行过程中动态调整执行计划,修正统计信息误差导致的计划错误,是当前云原生数据库的核心优化方向
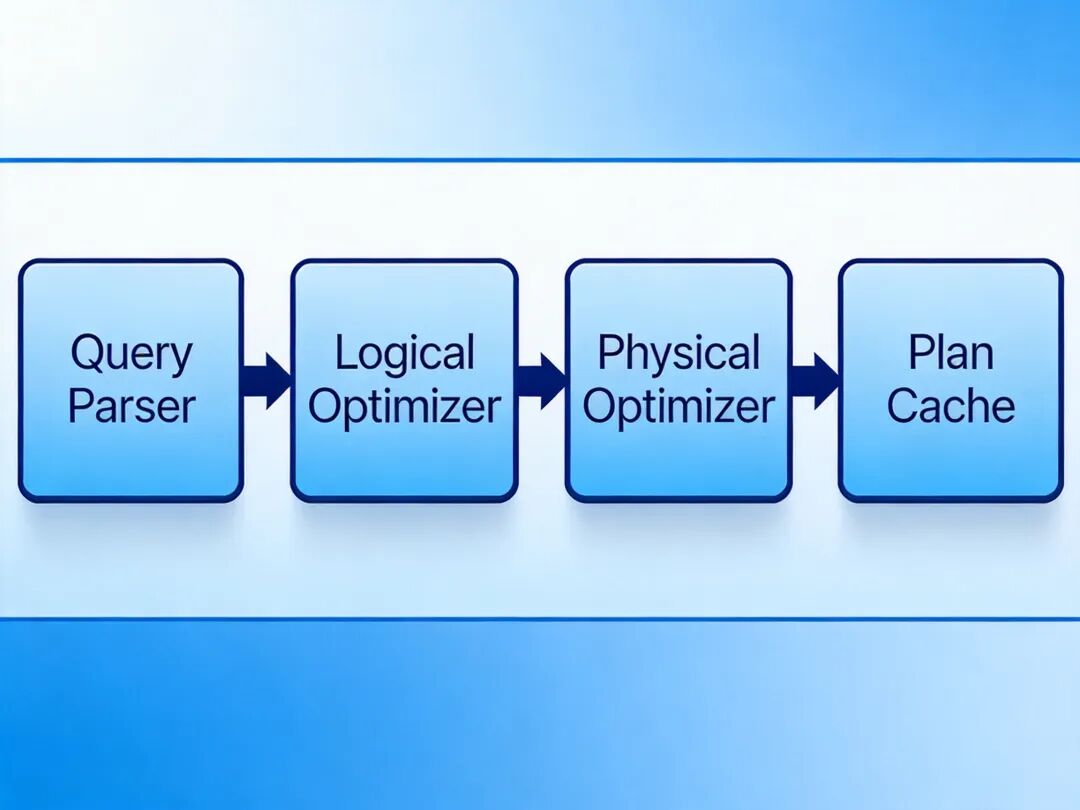
数据库查询处理器的分层架构图
六、前沿发展与趋势
6.1 技术演进动态
AI 驱动的查询优化:基于机器学习模型预测查询代价,替代传统的代价模型,可将复杂查询的优化准确率提升 30% 以上,代表产品如 Oracle 的自治数据库、阿里云 PolarDB 的 AI 优化器
实时查询优化:针对流处理场景的连续查询优化,通过动态调整窗口大小、过滤条件下推等技术,降低流处理的延迟,符合大数据实时分析的发展需求
跨模态查询优化:支持关系数据、半结构化数据、非结构化数据的统一查询优化,是多模数据库的核心技术能力
6.2 软考命题趋势
近年软考对本知识点的考察逐步从纯理论向实践应用倾斜,2022 年、2023 年连续出现结合实际 SQL 优化的案例分析题,未来将进一步强化查询优化在分布式数据库场景下的应用考察,要求考生掌握基本的分布式查询优化策略。
七、总结与建议
7.1 核心技术要点提炼
元组演算与域演算均属于非过程化查询语言,与关系代数表达能力等价,核心是掌握存在量词、全称量词的逻辑语义与等价转换
查询优化分为代数优化和物理优化两层,六大代数优化准则是 SQL 优化的通用依据,物理优化的核心是基于代价的执行计划选择
查询处理器的核心架构包括解析器、逻辑优化器、物理优化器、执行引擎四个模块,统计信息的准确性是优化效果的关键
7.2 软考考试重点提示
高频考点:元组演算的量词用法、查询优化准则的应用、不同执行计划的效率对比
易错点:全称量词的逻辑转换、查询优化准则的适用边界、关系代数与演算的等价性判断
备考策略:重点练习 2013-2023 年的相关真题,掌握将元组演算表达式转换为 SQL 语句、将初始查询树改写为优化后查询树的基本方法
7.3 工程实践建议
编写 SQL 时主动遵循优化准则:优先过滤大表、避免 SELECT *、谨慎使用多层嵌套子查询
定期更新数据库统计信息:生产环境每月至少执行一次统计信息更新,大表可适当提高更新频率
掌握执行计划分析能力:通过 EXPLAIN 命令查看执行计划,重点关注扫描类型、连接顺序、行数估算值与实际值的差异
避免过度依赖优化器:对于复杂查询,可通过 Hint 关键字手动指定执行计划,解决优化器决策错误的问题