目录
[1. 核心报头字段解析](#1. 核心报头字段解析)
[2. 分片机制深度学习(⭐⭐⭐)](#2. 分片机制深度学习(⭐⭐⭐))
[2.1 为什么要分片?](#2.1 为什么要分片?)
[2.2 接收方的拼装还原](#2.2 接收方的拼装还原)
[2.2.1 识别"同一个包裹"的碎片](#2.2.1 识别“同一个包裹”的碎片)
[2.2.2 分片的排序与重组逻辑](#2.2.2 分片的排序与重组逻辑)
[2.2.2.1 找到"火车头"(首片)](#2.2.2.1 找到“火车头”(首片))
[2.2.2.2 寻找"车厢"并无缝拼接(中间片)](#2.2.2.2 寻找“车厢”并无缝拼接(中间片))
[2.2.2.3 确认"车尾"(尾片)](#2.2.2.3 确认“车尾”(尾片))
[2.2.2.4 向上层交付](#2.2.2.4 向上层交付)
[2.3 异常处理机制(重组失败)](#2.3 异常处理机制(重组失败))
[1. 按类划分](#1. 按类划分)
[2. CIDR (无类别域间路由)](#2. CIDR (无类别域间路由))
[3. 私有IP与公网IP的诞生逻辑(⭐⭐⭐)](#3. 私有IP与公网IP的诞生逻辑(⭐⭐⭐))
[3.1 公网IP(外网IP)](#3.1 公网IP(外网IP))
[3.2 私有IP(内网IP)](#3.2 私有IP(内网IP))
[4. 解决IP耗尽的方案](#4. 解决IP耗尽的方案)
[4.1 动态分配IP (DHCP)](#4.1 动态分配IP (DHCP))
[4.2 NAT (网络地址转换) 技术 (⭐⭐⭐)](#4.2 NAT (网络地址转换) 技术 (⭐⭐⭐))
[4.2.1 NAT的基本原理](#4.2.1 NAT的基本原理)
[4.2.2 NAPT (网络地址端口转换)](#4.2.2 NAPT (网络地址端口转换))
[4.3 IPv6](#4.3 IPv6)
[4.3.1 地址容量](#4.3.1 地址容量)
[4.3.2 IPv6带来的技术变革](#4.3.2 IPv6带来的技术变革)
[4.3.3 为什么还没完全普及?](#4.3.3 为什么还没完全普及?)
[1. 路由器的多重身份(⭐⭐⭐)](#1. 路由器的多重身份(⭐⭐⭐))
[2. 工作原理](#2. 工作原理)
[1. IP的按类划分](#1. IP的按类划分)
[1.1 A类地址:巨无霸网段](#1.1 A类地址:巨无霸网段)
[1.2 B类地址:中坚力量](#1.2 B类地址:中坚力量)
[1.3 C类地址:遍地开花](#1.3 C类地址:遍地开花)
[1.4 D类地址:特殊的群发机制](#1.4 D类地址:特殊的群发机制)
[1.5 E类地址:未来的预留](#1.5 E类地址:未来的预留)
[1.6 计算主机数都要减 2(⭐⭐⭐)](#1.6 计算主机数都要减 2(⭐⭐⭐))
[2. 路由算法简述](#2. 路由算法简述)
[2.1 静态路由](#2.1 静态路由)
[2.2 动态路由](#2.2 动态路由)
[2.2.1 距离矢量算法 (Distance Vector) ------ "道听途说的传话筒"](#2.2.1 距离矢量算法 (Distance Vector) —— “道听途说的传话筒”)
[2.2.2 链路状态算法 (Link State) ------ "人人手持GPS全局地图"](#2.2.2 链路状态算法 (Link State) —— “人人手持GPS全局地图”)
[2.3 BGP (边界网关协议)](#2.3 BGP (边界网关协议))
一、宏观视角下的TCP与IP
在网络传输中,TCP和IP总是形影不离,但它们的职责有着本质的区别。
-
TCP的作用是"提供可靠性策略":它像是一个在幕后统筹规划的高管,负责制定超时重传、流量控制、拥塞控制等策略,确保数据"安全、无误"地送达。
-
IP协议的作用是"执行跨网络的数据交付":它像是一个使命必达的快递员,负责将数据从主机A实际运送到主机B。它不管数据丢不丢(那是TCP的事),它只负责"尽力而为"地赶路。
为了完成交付,IP协议需要解决两个核心问题:
-
源IP和目标IP:必须明确数据从哪里来,要发给全网唯一的谁。
-
定位逻辑 :
IP地址 = 目标网络号 + 目标主机号。IP协议会先根据"网络号"把数据送到目标所在的子网,再根据"主机号"在子网内找到具体的那台电脑。
二、IP报头与分片机制(⭐⭐⭐)
为了实现上述功能,IP协议会在数据的前面加上一个专属的"报头"(Header)。这个报头包含了快递的详细物流信息。

1. 核心报头字段解析
4位首部长度 :规定了IP报头的大小。和TCP一样,IP报头也有选项字段。它的取值范围是
0101到1111(即5-15),单位是4字节,所以IP报头长度在 20 到 60 字节之间。4位版本号:指明IP协议的版本,对于目前广泛使用的IPv4,这个值就是4。
8位服务类型 (TOS):其中4位用来表示请求的服务类型(最小延时、最大吞吐量、最高可靠性、最小成本)。这4个状态一般互相冲突,只能选其一。路由器在进行路径选择时,会参考这个字段来优化转发策略。
16位总长度:表示整个IP报文(报头 + 有效载荷)的总字节数。
8位生存时间 (TTL, Time To Live):防止迷路的报文在网络中无限循环。报文每经过一个路由器,TTL减1,减到0时该报文会被直接丢弃。网络中绝对不允许存在永远不消失的"游离报文"占用资源。
8位协议:指明了IP的有效载荷应该交给上层的哪个协议(例如,值为6代表TCP,17代表UDP)。
16位首部检验和:用于校验报头在传输过程中是否发生位反转等错误。
32位源IP & 32位目的IP:报文中最重要的信息,决定了数据包的路径选择。
2. 分片机制深度学习(⭐⭐⭐)
在报头中,有三个字段专门为分片服务:16位标识 、3位标志 、13位片偏移。
16位标识:同一个大报文切出来的所有小片,标识号是一样的。
3位标志 :其中有一位叫
MF (More Fragments),如果为1,说明后面还有分片;为0说明这是最后一片。13位片偏移:记录当前这个小片在原始大报文中的相对位置,确保接收端能按正确顺序拼接。
2.1 为什么要分片?
IP报文在网络层组装好后,并不能直接飞跃网线,而是必须继续向下交给数据链路层 (如MAC帧)。而数据链路层有**最大传输单元(MTU)**的限制(以太网通常是1500字节)。 如果网络层丢下来的IP报文比MTU大,数据链路层就会"咽不下去"。此时,IP层就必须将这个大报文切分成多个小片段,分别加上IP报头发送。接收端的IP层收到这些碎片后,再利用上述三个字段把它们重新拼装还原。
2.2 接收方的拼装还原
2.2.1 识别"同一个包裹"的碎片
IP协议首先要解决的问题是:分别哪些碎片是属于同一个原始大报文。
答案是提取四个核心维度的信息进行匹配:
(1)源IP地址 (2)目的IP地址
(3)8位协议 (比如都是交给TCP的)(4)16位标识(Identification)
只要这四个字段完全一致,接收方就可以100%确定:这些碎片来自于同一个被切割的原始大报文。接收方会在内存中为这个标识号开辟一个"重组缓冲区",把属于它的碎片都先暂存进来。
2.2.2 分片的排序与重组逻辑
接收方必须依靠 片偏移(Fragment Offset) 和 标志位(Flags) 来排序。
2.2.2.1 找到"火车头"(首片)
接收方会在缓冲区里寻找一个特殊的碎片:它的 片偏移量必须为 0。
偏移量为0,意味着这是原始报文的第一个切片。它包含了完整的、最原始的IP层以上的报头(比如TCP/UDP报头)。
2.2.2.2 寻找"车厢"并无缝拼接(中间片)
找到首片后,接收方通过计算首片中有效载荷的长度(总长度 - 报头长度),就能知道下一个碎片应该从哪里开始拼接。
注意一个细节 :13位片偏移的单位是 8字节。
假设首片的有效载荷是 1400 字节。那么下一个碎片的片偏移字段值就必须是
1400 / 8 = 175。接收方通过不断对比:
当前碎片的偏移量 == 前一个碎片的偏移量 + (前一个碎片的有效载荷长度 / 8),将后面乱序到达的碎片像拉链一样严丝合缝地扣在一起。
2.2.2.3 确认"车尾"(尾片)
接收方通过3位标志 中的 MF (More Fragments) 来判断是否全部集齐 。
只要碎片的
MF = 1,说明后面还有分片,继续等。当收到一个
MF = 0的碎片时,接收方就知道:"这就是最后一块拼图了!"如果从偏移量为0的首片,一直到
MF=0的尾片,中间的偏移量全部能无缝衔接,没有任何空隙,就宣告重组成功!
2.2.2.4 向上层交付
重组成功后,接收方会剥离掉所有后续碎片的IP报头,只保留首片的IP报头。然后修改首片IP报头的"总长度"字段,清除"分片标识"和"偏移量",恢复成它被切割前的样子,最后根据"8位协议"字段,将完整的数据载荷潇洒地交给上一层(如TCP/UDP)。
2.3 异常处理机制(重组失败)
在真实的工程实现中,必须考虑网络丢包的情况。如果一个原始报文被切成了5片,其中第3片在网络中丢失了,接收方的做法。
重组定时器(Reassembly Timer):当接收方收到第一个分片(不一定是首片,只要是这组分片的任意一个)时,就会启动一个定时器。
超时丢弃 :如果在定时器超时之前,没有收齐所有的分片(比如一直等不到偏移量能填补空缺的那个片),IP层会极其果断地将目前收集到的所有属于该报文的分片全部丢弃!
不负责重传 :IP协议只提供"尽力而为"的服务,它没有重传机制。
这引发了一个极其重要的网络性能问题:分片的代价是昂贵的! 只要有一个小分片丢失,整个巨大的IP报文就彻底作废,接收方全部丢弃。这会导致上层的TCP协议迟迟收不到确认,最终触发TCP的超时重传,把整个大报文重新发一遍(然后再次面临分片和丢包的风险)。所以在实际开发中,TCP协议会竭尽全力避免IP层进行分片!
三、IP地址的演进
IP地址本质上是一种有限的数字资源(IPv4总量约43亿)。如何分配这些资源,经历过一次巨大的变革。
1. 按类划分
早期,IP地址被简单粗暴地分为 A、B、C、D、E 五类。例如A类地址网络号只有8位,主机号高达24位,能容纳上千万台主机。 弊端:极度浪费。一个公司如果申请了B类地址,即使只有几百台电脑,也会独占6万多个IP,导致其他急需IP的人无址可用。
2. CIDR (无类别域间路由)
为了缓解浪费,引入了 32位子网掩码 (Subnet Mask)。
现在的模式是:IP地址 + 子网掩码。
子网掩码中连续为
1的部分代表网络号,连续为0的部分代表主机号。这样就可以打破原有的ABC类限制,灵活地按需划分网段大小。这就好比原本只能论"栋"卖楼,现在可以按"平米"精确切割了。
3. 私有IP与公网IP的诞生逻辑(⭐⭐⭐)
在早期,每一台接入互联网的设备都渴望拥有一个全球唯一的IP地址。但IP地址有限,为了省着点用,规定了"内外有别"的策略。
3.1 公网IP(外网IP)
定位:互联网上的"真实身份",全球唯一。
特性:能在互联网的骨干路由器上被识别和转发。如果把互联网比作全球快递网,公网IP就是能在全球地图上查到的精确地址(如某市某街道某号)。需要向运营商(ISP)花钱申请。
3.2 私有IP(内网IP)
为了让局域网内部也能通信,RFC 1918 专门划出了几段特殊的IP地址,供大家免费在内部使用。
常见私有网段:
10.0.0.0-10.255.255.255(大型企业常用)
172.16.0.0-172.31.255.255(Docker等虚拟化常用)
192.168.0.0-192.168.255.255(家庭路由器最常见)核心规则 :私有IP绝对不允许出现在公网的路由表中! 一旦运营商的路由器看到目标地址是私有IP,会直接丢弃。
特性 :因为上不了公网,所以私有IP可以在不同的局域网中重复使用 。你家电脑可以是
192.168.1.100,我家电脑也可以是它,只要不在同一个局域网内就不会冲突。
4. 解决IP耗尽的方案
4.1 动态分配IP (DHCP)
即使划分了私有IP,很多时候公网IP还是不够分。这时候,DHCP 就站了出来。
核心思想:时间复用,谁上网给谁用,不上网就收回。
工作机制:DHCP本质是一个自动分配IP地址的服务。当你拿着手机连上WiFi,或者把网线插上电脑时,你的设备会向局域网大喊一声:"谁能给我一个IP?"(DHCP Discover)。路由器上的DHCP服务器听到后,就会从地址池里"租"给你一个IP(包含子网掩码、网关、DNS等信息),租期到了或者你断网了,这个IP就会被回收,分配给下一个接入的人。
4.2 NAT (网络地址转换) 技术 (⭐⭐⭐)
4.2.1 NAT的基本原理
当内网主机(私有IP)向公网发送数据包时,作为网关的路由器,会把数据包IP报头中的"源IP(私有IP)"替换成路由器自己的"WAN口IP(公网IP)",然后再发出去。服务器回包时,路由器再把目标IP从"公网IP"替换回内网的"私有IP"。
4.2.2 NAPT (网络地址端口转换)
如果局域网里有10台电脑同时访问百度,百度把数据返回给路由器的公网IP时,路由器怎么知道这数据该还给内网的哪台电脑呢?这就需要结合传输层的端口号(Port) 来做区分,这就是 NAPT(Network Address Port Translation)。
完整的工作流程(以实际数据包为例):
- 出发 :内网主机A(
192.168.1.100)用端口5555向百度发请求。- 转换 :报文到达路由器。路由器将其修改为:源IP为路由器的公网IP(例如
203.0.113.5),并且分配一个新的端口(例如10001)。- 记录 :路由器在自己的NAT映射表 里记下一笔:
192.168.1.100:5555 <---> 203.0.113.5:10001。- 回应 :百度收到请求,以为是
203.0.113.5发来的,于是把网页数据回传给这个公网IP的10001端口。- 反转 :路由器收到数据,查阅刚才的NAT表,发现
10001端口对应的是内网的主机A。于是把目标IP修改回192.168.1.100:5555,成功交还给主机A。意义:通过NAPT,一个公网IP可以利用其65535个端口,理论上让内网数万台设备同时共享这一个公网IP上网。
4.3 IPv6
NAT虽然好用,但它打破了互联网最初设计的"端到端通信"理念 。因为内网主机躲在路由器后面,外网无法直接主动发起连接 去寻找内网主机(这也导致了早期的P2P下载、联机游戏常常遇到"NAT穿透"的难题)。为了彻底解决地址不够和NAT带来的副作用,IPv6 诞生了。
4.3.1 地址容量
IPv4地址是32位,而IPv6直接将地址长度扩展到了128位 。 它的容量高达 个。网络界有一句名言:"IPv6可以给地球上的每一粒沙子都分配一个IP地址。"
4.3.2 IPv6带来的技术变革
一旦IP地址不再稀缺,之前的很多妥协都可以被抛弃:
- 消灭NAT:不再需要复杂的内外网转换,每一台手机、每一台智能电视都可以拥有真正的公网IP,实现真正的"万物互联"和端到端直接通信。
- 内建安全性 :IPv6在设计之初就考虑了安全,原生支持IPsec,让数据在网络层的传输自带加密和身份认证。
- 更高效的路由:IPv6简化了报头结构(去掉了IPv4中一些不常用、需要路由器额外计算的字段,比如去掉了头部校验和分片机制的大修),让路由器的转发速度更快。
4.3.3 为什么还没完全普及?
因为IPv6和IPv4是不兼容的。要过渡到IPv6,需要全球的运营商、所有的路由器、各种操作系统、所有的应用软件全部进行升级或重构。这是一项长达数十年的浩大工程,目前我们正处于IPv4和IPv6双栈共存的漫长过渡期。
五、路由器的工作原理与路由表
没有联网的机器不需要IP地址;IP地址的本质是网络通信的坐标。 如前所述,IP地址 = 网络号 + 主机号。在同一个网段(子网)内,所有主机的网络号必须相同,但主机号必须唯一。
1. 路由器的多重身份(⭐⭐⭐)
了解IP,就绕不开路由器。路由器不仅仅是一个发WiFi的盒子:
它也是一台主机:路由器作为网络节点,同样配置有自己的IP地址。
它是跨网段的桥梁:一台路由器至少要连接两个以上的子网(比如家里的局域网和运营商的公网)。因此,它必须配置多个IP地址,每个接口对应一个子网。
它是子网的"第一人" :通常,路由器在一个子网中会占用第一个有效的IP地址(例如
192.168.1.1),也就是我们常说的"默认网关"。它的综合管理功能:除了核心的IP报文转发,现代路由器还能构建局域网,并充当DHCP服务器,自动给新接入的设备分配主机号。
2. 工作原理
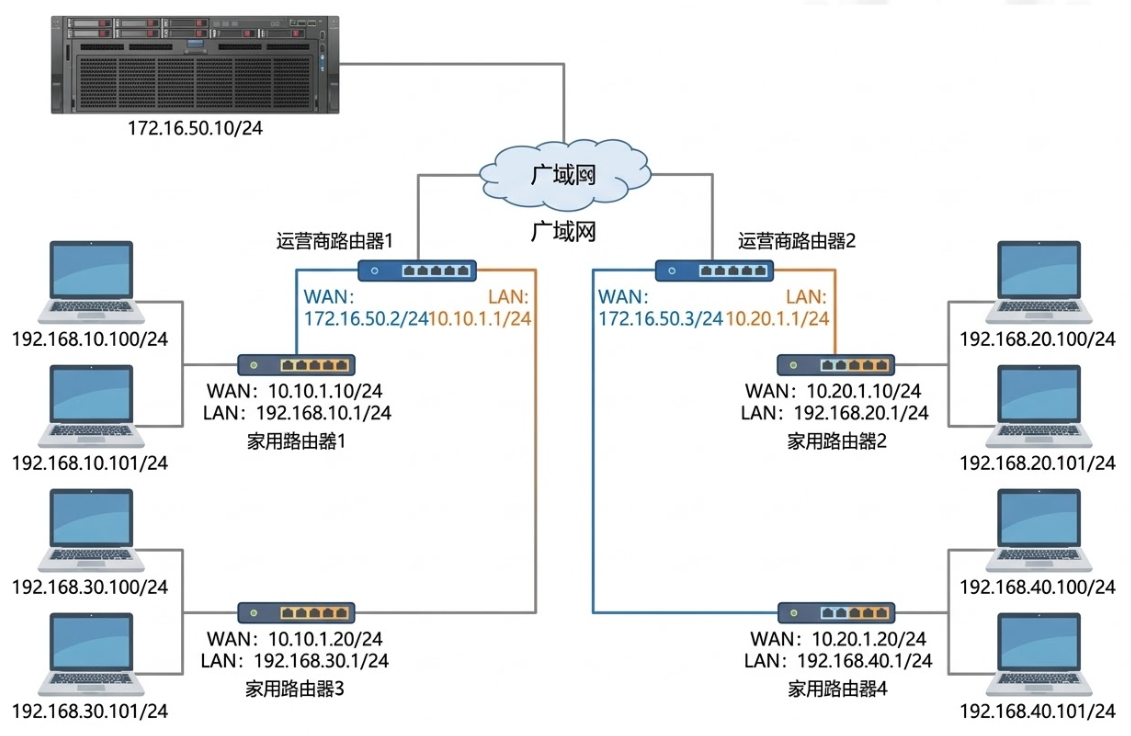
1.提取目标IP:设备会查看报文的目标IP。
2.匹配网段:用目标IP与路由表中的每一条子网掩码进行按位与运算,对比是否在已知的目标网段内。
3.给出下一跳 (Next Hop):
(1)命中:如果知道路怎么走,路由表会给出具体下一跳路由器的MAC地址,报文被精准投递到下一个站点。
(2)未命中 :如果路由器翻遍了表格也不知道这个IP在哪里,它就会使用默认路由 (Default Route, 通常是
0.0.0.0)。也就是把包裹丢给同一网段中级别更高、视野更广的上一级路由器(这就叫转入默认路由)。4.循环往复:一跳接一跳,一直到达拥有目标IP所在子网的入口路由器,最终投递给目标主机。
六、扩展学习
1. IP的按类划分
1.1 A类地址:巨无霸网段
-
前导码识别 :最高位固定为
0。 -
结构划分 :8位网络号 + 24位主机号。
-
地址范围 :
0.0.0.0到127.255.255.255。 -
默认子网掩码 :
255.0.0.0。 -
容量与特点 :A类地址的网络号极少(只有120多个),但每个网络能容纳的主机数量极为夸张,高达
(约1677万)台主机。通常只有跨国级的超大型网络或骨干网才会使用。
1.2 B类地址:中坚力量
-
前导码识别 :最高两位固定为
10。 -
结构划分 :16位网络号 + 16位主机号。
-
地址范围 :
128.0.0.0到191.255.255.255。 -
默认子网掩码 :
255.255.0.0。 -
容量与特点 :B类地址有1万多个网络,每个网络可以容纳
1.3 C类地址:遍地开花
-
前导码识别 :最高三位固定为
110。 -
结构划分 :24位网络号 + 8位主机号。
-
地址范围 :
192.0.0.0到223.255.255.255。 -
默认子网掩码 :
255.255.255.0。 -
容量与特点 :C类网络数量极其庞大(超过200万个),但每个网络只能容纳
1.4 D类地址:特殊的群发机制
-
前导码识别 :最高四位固定为
1110。 -
地址范围 :
224.0.0.0到239.255.255.255。 -
核心用途 :多播/组播(Multicast)地址 。它没有网络号和主机号的划分!它不指向某一台特定的计算机,而是指向"一组"计算机。当向一个D类地址发送数据时,加入该组的所有主机都能收到。常用于视频直播、路由协议更新(如OSPF)等场景。
1.5 E类地址:未来的预留
-
前导码识别 :最高四位固定为
1111。 -
地址范围 :
240.0.0.0到255.255.255.255。 -
核心用途:保留为科学研究和未来扩展使用。在一般的网络配置中,如果你试图将网卡的IP配置为E类地址,操作系统通常会报错拒绝。
-
特殊保留 :
255.255.255.255是一个特殊的受限广播地址,代表"当前局域网内的所有主机"。
1.6 计算主机数都要减 2(⭐⭐⭐)
-
主机号全为 0 的地址 :代表网络本身(网络号) ,不能分配给具体的主机。比如
192.168.1.0代表这个C类网段本身。 -
主机号全为 1 的地址 :代表定向广播地址 。向这个地址发数据,该网段内的所有主机都会收到。比如
192.168.1.255。
2. 路由算法简述
2.1 静态路由
原理 :网络管理员登录到路由器后台,一行一行手工敲入命令:"去往
192.168.2.0网段,请走10.0.0.2这个接口"。特点:绝对可靠,不占用网络额外带宽。
缺点:只适合极小型的网络。如果网络拓扑一变(比如某根网线断了),网管就得半夜爬起来重新改配置,在庞大的互联网中根本行不通。
2.2 动态路由
为了应对复杂的互联网,工程师们发明了动态路由协议。路由器之间会互相发送消息,自动学习并计算出最佳路径,生成路由表。主流的算法分为两大门派:
2.2.1 距离矢量算法 (Distance Vector) ------ "道听途说的传话筒"
代表协议:RIP (路由信息协议)
-
工作机制:每个路由器只知道自己和邻居的距离。它会定期把自己的"整张路由表"抄送给相邻的路由器。
-
生活类比:就像村口的情报传递。
-
路由器B告诉路由器A:"我到北京的距离是 2跳(经过2个路由器)"。
-
路由器A心里一算:"B是我的邻居(距离1跳),那经过B到北京就是
-
-
优缺点:算法非常简单,适合小网络。但由于是"道听途说",如果网络出现故障,坏消息传得很慢,容易产生"路由环路"(A以为B能到,B以为A能到,数据包在A和B之间死循环)。
2.2.2 链路状态算法 (Link State) ------ "人人手持GPS全局地图"
代表协议:OSPF (开放式最短路径优先)
-
工作机制 :每个路由器不再发送整张路由表,而是向全网广播"自己的邻居是谁,网线状态好不好,带宽是多少"(这就叫链路状态)。
-
生活类比:就像所有路由器都在朋友圈发了一个定位:"我旁边是张三和李四,路况畅通"。
-
全网每个路由器收集齐所有人的"朋友圈"后,就能在自己的内存里画出一张完整的、1:1的真实网络拓扑图(上帝视角)。
-
然后,每个路由器以自己为起点,在本地运行迪杰斯特拉 (Dijkstra) 最短路径算法,计算出到达每一个目的地的最优路线,最后写入路由表。
-
-
优缺点:收敛极快(一断网大家立刻知道),绝对不会产生环路,是目前企业内网和中大型网络的主流。缺点是对路由器的CPU和内存要求比较高(因为要在脑海里推演全网地图)。
2.3 BGP (边界网关协议)
刚才说的都是一个公司或一个组织内部的算法(IGP)。但在广袤的互联网中,是无数个大企业、大运营商连在一起的。
在不同运营商之间(比如中国电信和中国联通的边界路由器),使用的是 BGP 协议 。在这里,寻找"最短路径"不再是第一要务,最重要的是"策略与商业利益"(比如电信的数据不能随便走到联通的骨干网里去白嫖带宽)。BGP 是一种基于路径矢量的算法,是支撑整个现代互联网路由体系的基石。