文章目录
- 一、概述
- 二、输入
-
- [1.1 分词(Tokenization)](#1.1 分词(Tokenization))
-
- [2.1.1 分词流程](#2.1.1 分词流程)
- [2.1.2 分词方法](#2.1.2 分词方法)
- [2.2 词嵌入(Token Embedding)](#2.2 词嵌入(Token Embedding))
- [2.3 位置编码(Positional Encoding)](#2.3 位置编码(Positional Encoding))
- [2.4 最终输入](#2.4 最终输入)
- 三、注意力机制(Attention)
-
- [2.1 单头注意力(Single-Head Attention)](#2.1 单头注意力(Single-Head Attention))
- [2.2 多头注意力(Multi-Head Attention)](#2.2 多头注意力(Multi-Head Attention))
- [2.3 掩码多头注意力(Masked Multi-Head Attention)](#2.3 掩码多头注意力(Masked Multi-Head Attention))
- [2.4 编码器 - 解码器注意力(Encoder-Decoder Attention)](#2.4 编码器 - 解码器注意力(Encoder-Decoder Attention))
- 2.5总结
- 四、其他网络层
-
- [4.1 残差连接(Residual Connection)](#4.1 残差连接(Residual Connection))
- [4.2 Layer Norm](#4.2 Layer Norm)
- [4.3 前馈网络(FFN)](#4.3 前馈网络(FFN))
- [五、Encoder & Decoder](#五、Encoder & Decoder)
-
- [5.1 结构](#5.1 结构)
- [5.2 机器翻译举例](#5.2 机器翻译举例)
- 六、总结
一、概述
Transformer 是 2017 年由 Google 团队在《Attention Is All You Need》中提出的纯注意力机制序列建模架构,彻底抛弃 RNN/LSTM 的递归结构,以多头自注意力 + 前馈网络为核心,实现全局并行计算与长距离依赖建模,是 GPT、BERT、LLaMA 等大模型的基础。序列到序列(Seq2Seq)建模框架,最初用于机器翻译,现已覆盖 NLP、CV、语音、多模态等领域。
- trans- 表示 跨越、转换,
- form 表示 形式,
- 合起来就是 转换器 / 变换器。
原论文链接:https://arxiv.org/abs/1706.03762
Transformer演示链接:https://explainer.tubex.chat/
关键突破:
- 位置编码:弥补注意力无位置感知的缺陷。
- 全局注意力:直接建模任意两个 token 的依赖,解决长文本梯度消失问题。
- 无递归、全并行:输入序列可同时计算,训练速度远超 RNN。
二、输入
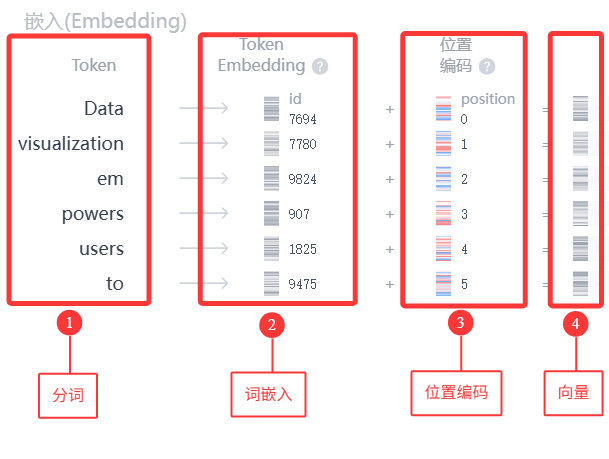
1.1 分词(Tokenization)
分词就是把文本拆成模型能处理的最小单元,即把单词变成 Token。
2.1.1 分词流程
- 文本清洗:处理大小写、标点、特殊符号。
- 预分词:按空格 / 标点把句子切成粗粒度片段。
- 子词拆分:用 BPE 把每个片段拆成子词。
- 映射 ID:把子词映射到词表中的数字 ID。
在实际模型中,分词后还会添加一些特殊 Token,填充到固定长度(比如 512、1024)
- CLS:BERT 用,放在句首,用于分类任务。
- SEP:BERT 用,用于分隔句子或作为句尾。
- <|endoftext|>:GPT 用,作为文本结束标记,也用于分隔不同文档。
- PAD:填充 Token,用于将不同长度的序列补齐到同一长度。
- UNK:未知 Token,用于处理词表外的字符 / 子词。
2.1.2 分词方法
空格分词(Word-level ):按空格、标点把句子切开,每个词就是一个 Token。
Artificial Intelligence is transforming the → "Artificial", "Intelligence", "is", "transforming", "the"
人工智能正在改变世界→ "人工智能", "正在", "改变", "世界"
- 优点:语义保留最完整,每个 Token 都有明确含义。
- 优点:实现简单,不需要复杂算法。
- 缺点:词表巨大,无法处理新词(transforming 和 transform 会被当成两个完全不同的词)
- 缺点:中文没有空格,完全不适用
字符级分词(Character-level):以单个字符(字母 / 汉字)为最小单位。
Art → "A", "r", "t"
人工智能 → "人", "工", "智", "能"
- 优点:词表极小,英语只需 26 个字母 + 标点,中文只需几千个常用汉字。
- 优点:能处理任何新词、生僻字甚至乱码。
- 缺点:序列太长(一句话变成几百个字符),模型计算成本高。
- 缺点:语义丢失,单个字符几乎没有意义,模型需要学习很长的依赖才能理解语义。
子词分词(Subword Tokenization):核心是把单词拆成有意义的子词,兼顾词表大小和新词处理能力。常见算法有三种:
BPE(Byte Pair Encoding):从字符开始,不断合并出现频率最高的字符对,直到词表达到预设大小。- 初始化:词表由所有单个字符组成。
- 统计:在语料库中统计所有相邻字符 / 子词对的出现频率。
- 合并:将频率最高的一对合并成一个新的子词,加入词表。
- 重复:不断重复步骤 2-3,直到词表大小达到预设上限(如 50257)。
- 初始词表:a, r, t, i, f, i, c, i, a, l, ...
- 高频合并:a+r→ar, ar+t→Art, i+f→if, ...
- 继续合并,直到得到 Art, ificial, Intelligence 这类子词 结果: Artificial → "Art", "ificial"
- 新词 transformingly → 拆成 "transform", "ing", "ly",模型能看懂
WordPiece:和 BPE 类似,但合并时不看频率,而是看语言模型概率增益,选择能最大程度提升模型概率的子词对进行合并。相比 BPE,更注重语义连贯性。
- 和 BPE 类似,但合并时看概率,而不是单纯频率。
- 会用 ## 标记后缀,比如: unhappiness → "un","happiness"、 happiness → "happy", "##ness"
SentencePiece:直接在字节(Byte)或 Unicode层面进行分词,完全不需要依赖预先的空格或分词结果。
2.2 词嵌入(Token Embedding)
模型给词表中每一个 Token ID(比如 2537、9362),都分配一个固定长度的数字向量,这个向量就是这个 Token 的语义密码。
- 训练模型前,先初始化一个 Embedding 矩阵,矩阵形状:词表大小, 嵌入维度
- 当输入 Token ID=2537 时,直接从 Embedding 矩阵中取出第 2537 行的向量,这就是 Art 的词嵌入向量。
- 初始的向量是随机的,模型训练时会不断调整这些向量:
- 语义相近的 Token(比如 cat 和 dog),它们的向量会变得 "离得近";
- 语义相反的 Token(比如 good 和 bad),向量会 "离得远";
- 模型可以通过计算向量之间的距离、相似度,来理解 Token 之间的语义关系。
2.3 位置编码(Positional Encoding)
Transformer 的核心是自注意力机制,它会一次性看完整句话的所有 Token,但自注意力没有顺序感,如果把 Token 顺序打乱,模型计算出的注意力权重完全一样,会误以为两句话语义相同。
例:我吃饭和饭吃我,token一样,顺序不一样,语义完全不一样。Transformer 需要加上位置编码的话,来区分上述的句子。
和 Token Embedding 类似,位置编码也是给每个位置分配一个固定长度的向量(维度和 Token Embedding 完全一样)
- 只附加位置信息,不改变 Token 语义:相加后,Token 的语义(Embedding)还在,只是多了我在第几位的信息。
- 只和位置有关,和 Token 本身无关:不管 Token 是 Art 还是 ificial,只要在位置 0,就加 pos0。
位置编码的两种主流实现方式:
固定位置编码:用三角函数公式提前计算好所有位置的向量,训练过程中不更新(固定不变)可学习位置编码:初始化一个和固定编码一样的位置向量表,本质就是一个可训练的矩阵,但训练过程中会跟着模型一起更新,模型会自己学出 "最优" 的位置向量,不用人为设计公式。
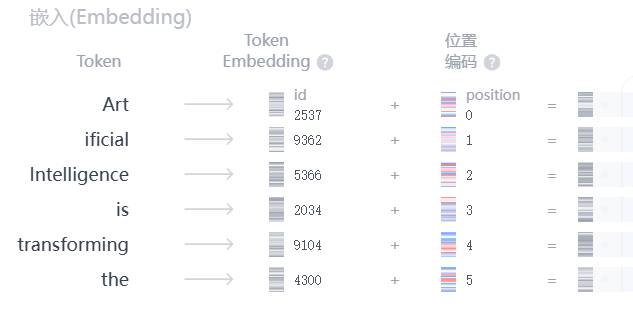
2.4 最终输入
对每个 Token,最终输入向量 = Token Embedding + Positional Encoding。这一步之后得到的一组向量序列,才会真正输入到 Transformer 的 Encoder/Decoder 中。
- Art(位置 0):向量 2537_emb + pos_0
- ificial(位置 1):向量 9362_emb + pos_1
假设处理后的向量维度为(1,768),如果像上述输入有6个token,则向量维度为(6,768)。
三、注意力机制(Attention)
自注意力机制是维度不变的特征提纯器:假设输入向量 (6, 768),输出的向量维度仍是 (6, 768),但过程中通过 QKV 与注意力分数,让每个 token 都吸收了整个序列的上下文信息,从而得到更丰富的语义特征。
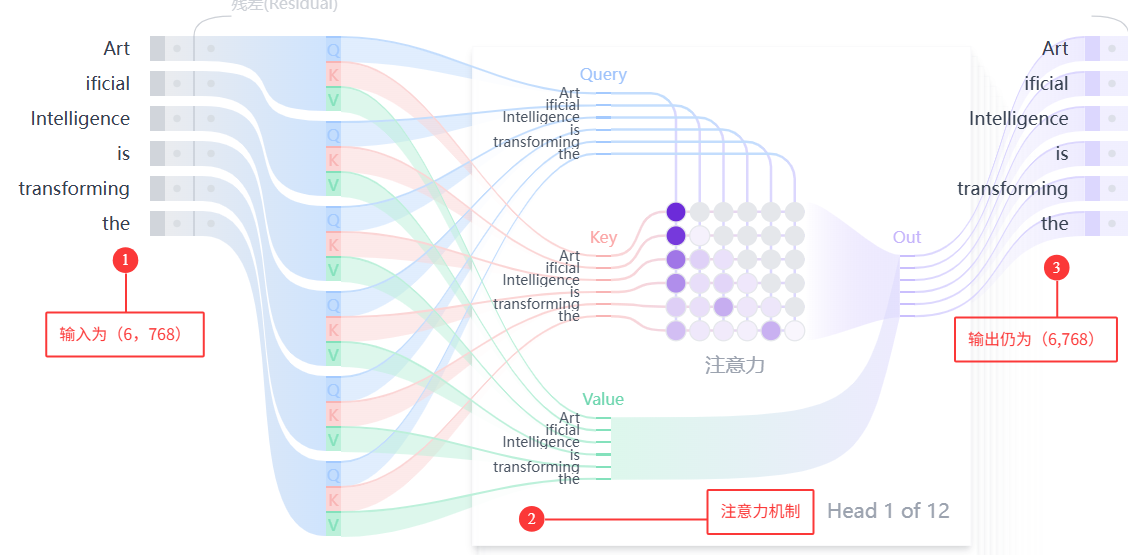
2.1 单头注意力(Single-Head Attention)
你去图书馆找书:
Q(Query)= 你要找的书的 "关键词"(比如 "2025 年人工智能入门")K(Key)= 图书馆里每本书的 "标签 / 索引"(比如每本书封面写的 "2023 AI 基础""2024 机器学习")V(Value)= 书里的实际内容(你真正想读的文字)
你拿自己的 Q(关键词),和所有书的 K(标签)对比,算二者相似度(哪些书和你要找的匹配),然后给匹配度高的书加权,把这些书的 V(内容)按权重拼起来,就是你想要的信息。
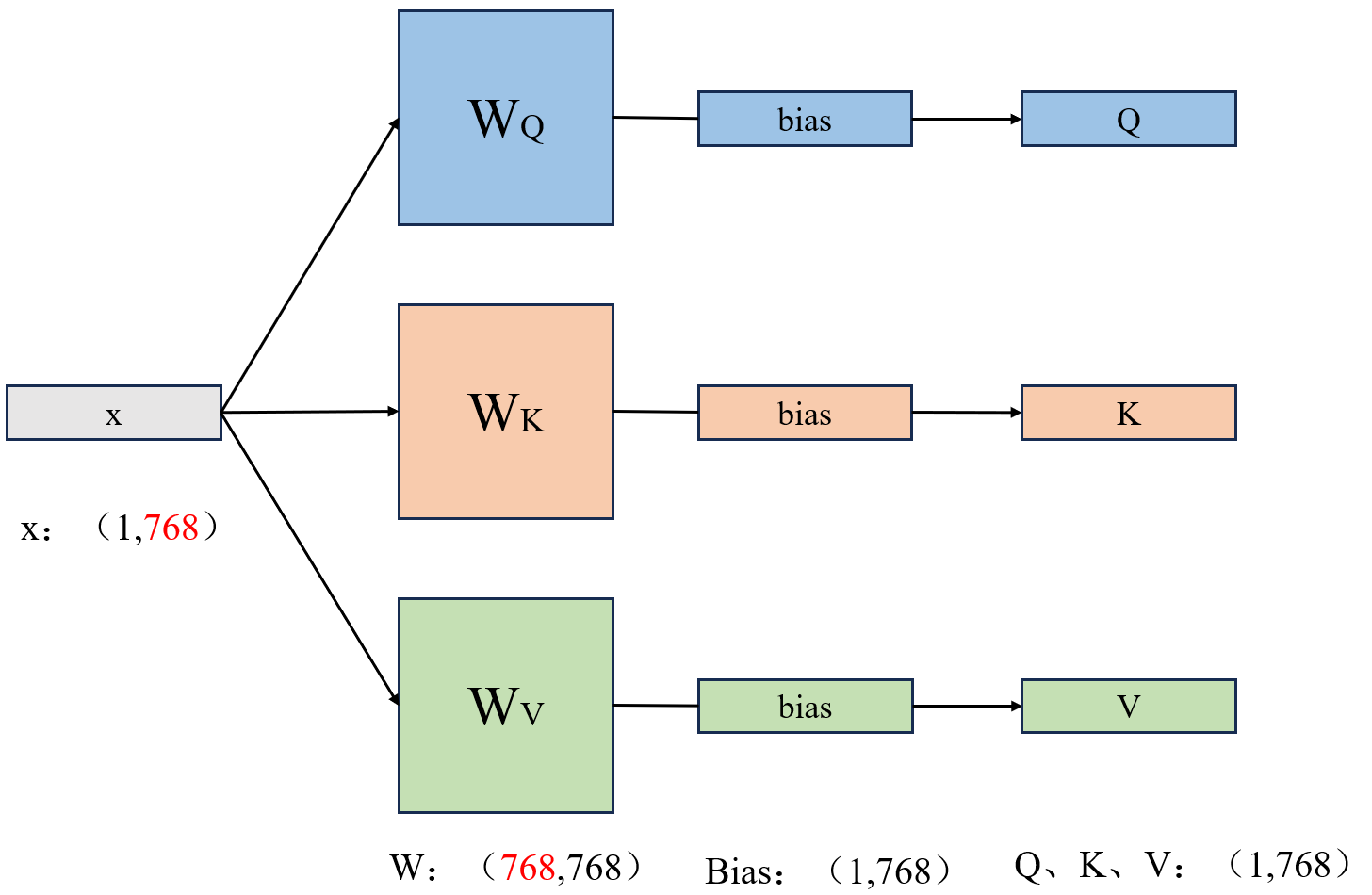
原始输入:每个 Token 是一个 (1,768) 维的向量(Embedding + 位置编码),这个向量同时包含语义信息和位置信息,但没有角色,给每个 Token 向量乘 3 个不同的权重矩阵,就得到 3 个新向量:
- Q:给 Token 赋予【查询者】角色 ------ 代表这个 Token 想找什么信息;
- K:给 Token 赋予【被查询者】角色 ------ 代表这个 Token 能提供什么信息;
- V:给 Token 赋予【信息提供者】角色 ------ 代表这个 Token 的核心语义内容。
Q = x ⋅ W Q 、 K = x ⋅ W K 、 V = x ⋅ W V Q=x·W_Q、K=x·W_K、V=x·W_V Q=x⋅WQ、K=x⋅WK、V=x⋅WV 权重W:训练前,这些矩阵的数值是随机初始化的,训练后,数值会被调整成能精准匹配语义的样子。
句子:Artificial Intelligence is transforming the world
- Token Intelligence 的 Q:我想找修饰我的词、动作相关的词;
- Token Artificial 的 K:我是修饰词,描述智能的属性,V:"我的语义是人工的
- Token transforming 的 K:我是动作,和智能相关",V:"我的语义是改变
- Intelligence 的 Q 匹配 Artificial 和 transforming 的 K,就能把这两个词的 V 拼过来,理解 "人工智能在改变世界"。
A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q K ⊤ d k ) V Attention(Q,K,V)=Softmax(\frac{Q K^\top}{\sqrt{d_k}} )V Attention(Q,K,V)=Softmax(dk QK⊤)V
Q-K 的内积就是语义相似度:内积越大,两个 Token 语义越相关- 训练初期:Q-K 匹配是随机的,模型不知道 "Artificial" 该匹配 "Intelligence";
- 训练后期:模型学会把【修饰词的 K 】调整成和【被修饰词的 Q 】更匹配,把【动作词的 K 】调整成和【主语的 Q 】更匹配;
- 最终,Q-K 匹配的结果就是语义相关度。
- d k d_k dk:Query/Key 的向量维度; d k : \sqrt{d_k}: dk :缩放因子,防止数值过大
Softmax 归一化:把相似度变成 0~1 的权重,权重和为 1,模型知道该重点关注哪些词加权求和 V:融合上下文语义,把相关词的 V(核心语义)按权重拼起来,每个 Token 都融合了整句话的上下文
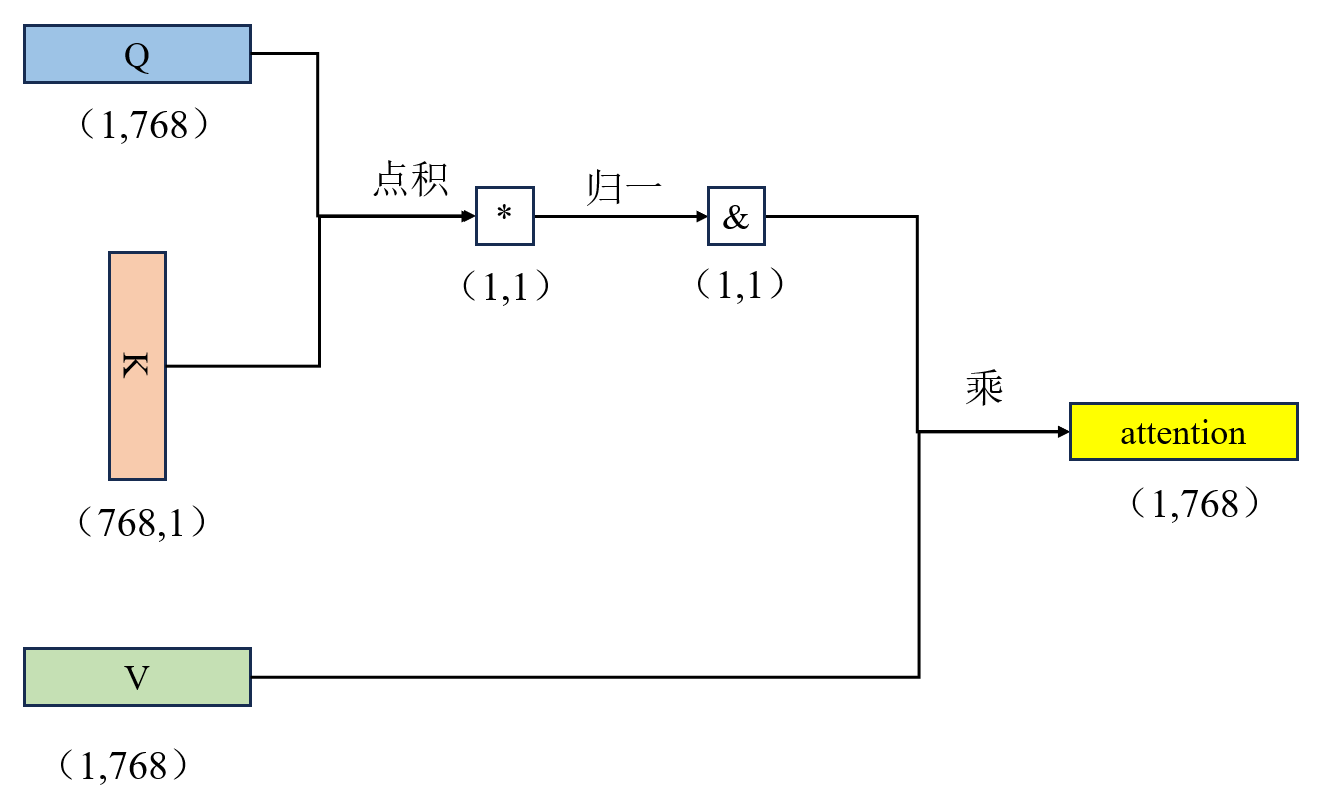
自注意力的核心是序列中每个 token(作为 Q),都要和序列中所有 token(作为 K/V)计算注意力,最终得到每个 token 的新表示。
- 如果输入为 6 个token,每个 token 维度为 768,Q矩阵和K矩阵的转置进行点乘后,得到维度为 (6,6) 的注意力分数矩阵,该矩阵的每一行对应一个 token 对所有 6 个 token 的关注度数值,每一列对应所有 token 对单个 token 的关注度数值。
- 随后对分数矩阵的每一行执行 Softmax 归一化,将分数转化为总和为 1 的注意力权重矩阵,维度仍为 (6,6)
- 最后将注意力权重矩阵与值矩阵 V 相乘,通过加权求和所有 token 的 V 值,生成最终的注意力输出矩阵,维度回归为 (6,768),与输入维度保持一致。
- 整个过程中,(6,6) 仅为中间表征 token 间关注关系的权重矩阵,核心目的是让每个 token 融合序列中所有 token 的信息,最终输出维度不变,仅更新 token 的语义表示。
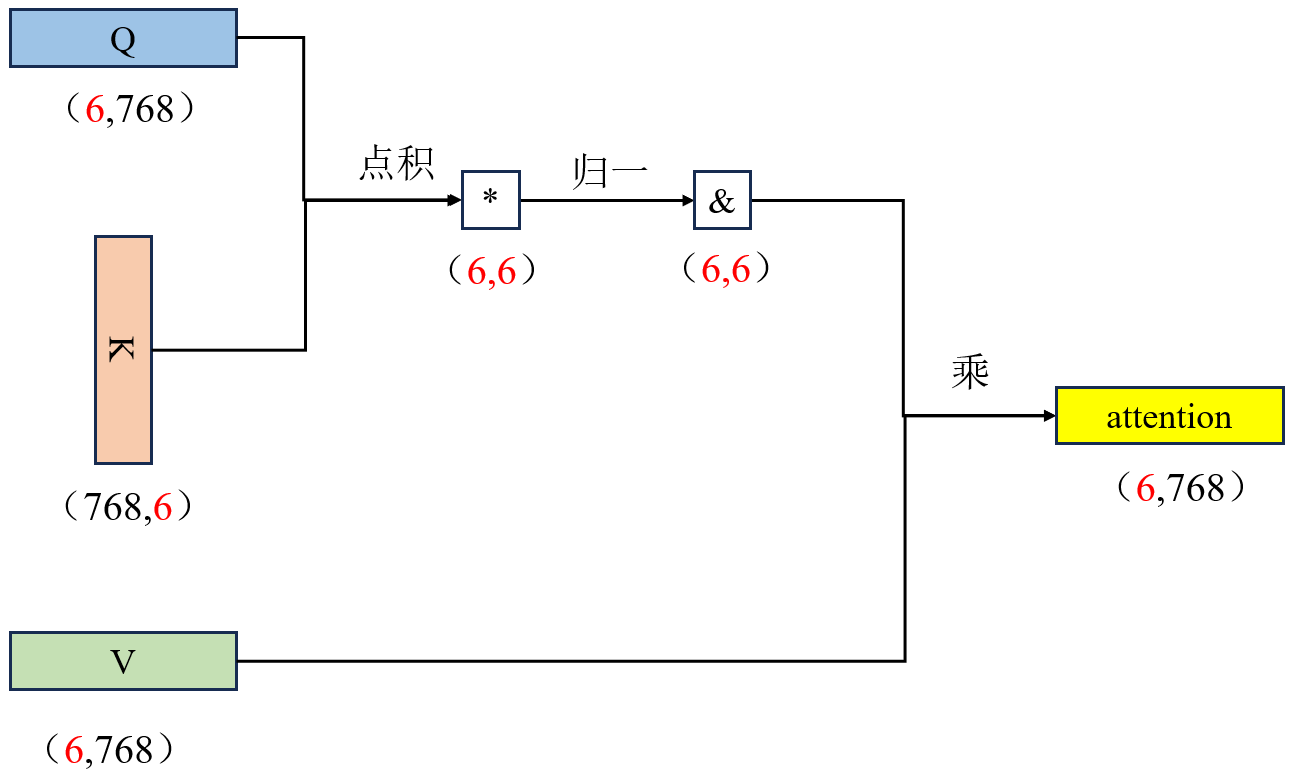
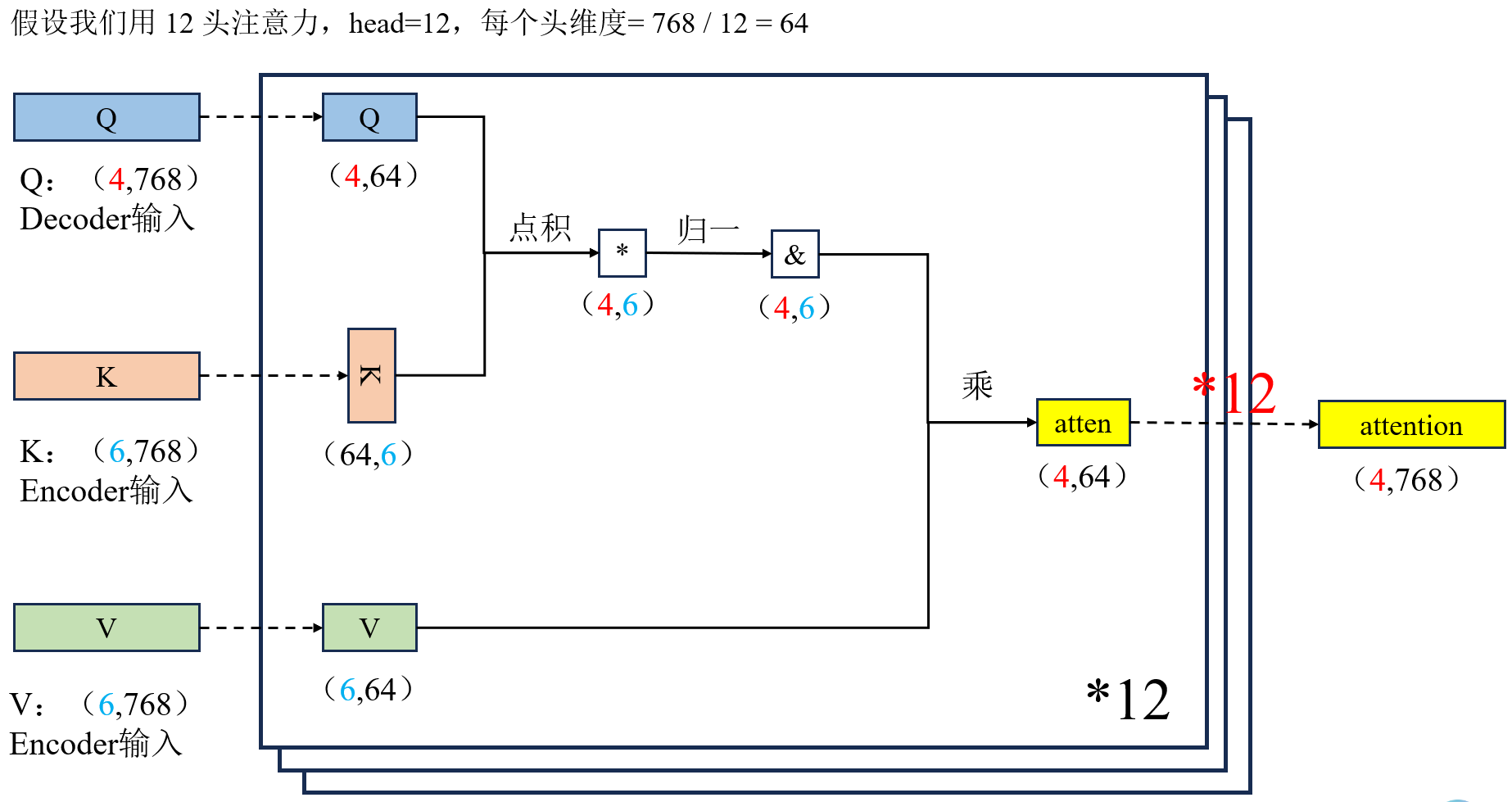
2.2 多头注意力(Multi-Head Attention)
- 单头只能从一个角度看句子。
- 多头能从多个角度看句子,每人关注不同重点,头 1:看主谓关系、头 2:看修饰关系、头 3:看远近关系、头 4:看逻辑关系,最后汇总。
如下图:
- 单头自注意力机制是:经过运算后直接输出为(1,768)
- 多头自注意力机制是:先将Q、K、V拆分成12个head(并不是简单的拆分,而是 Q/K/V 各有 12 组独立小权重),每一个head是(1,64),经过运算之后每个头输出形状为 (1, 64),12 个头拼接后还原为 (1, 768)。
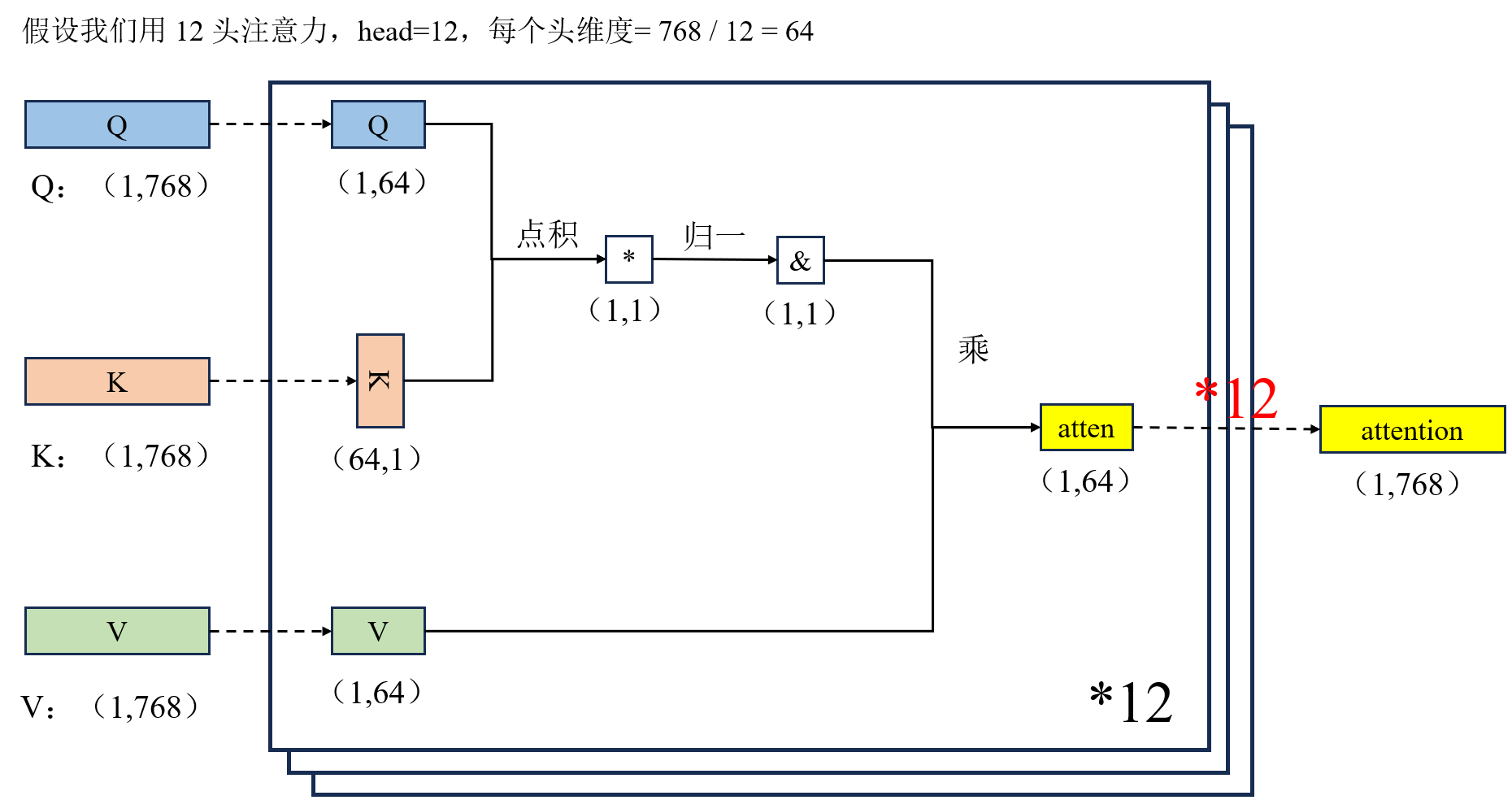
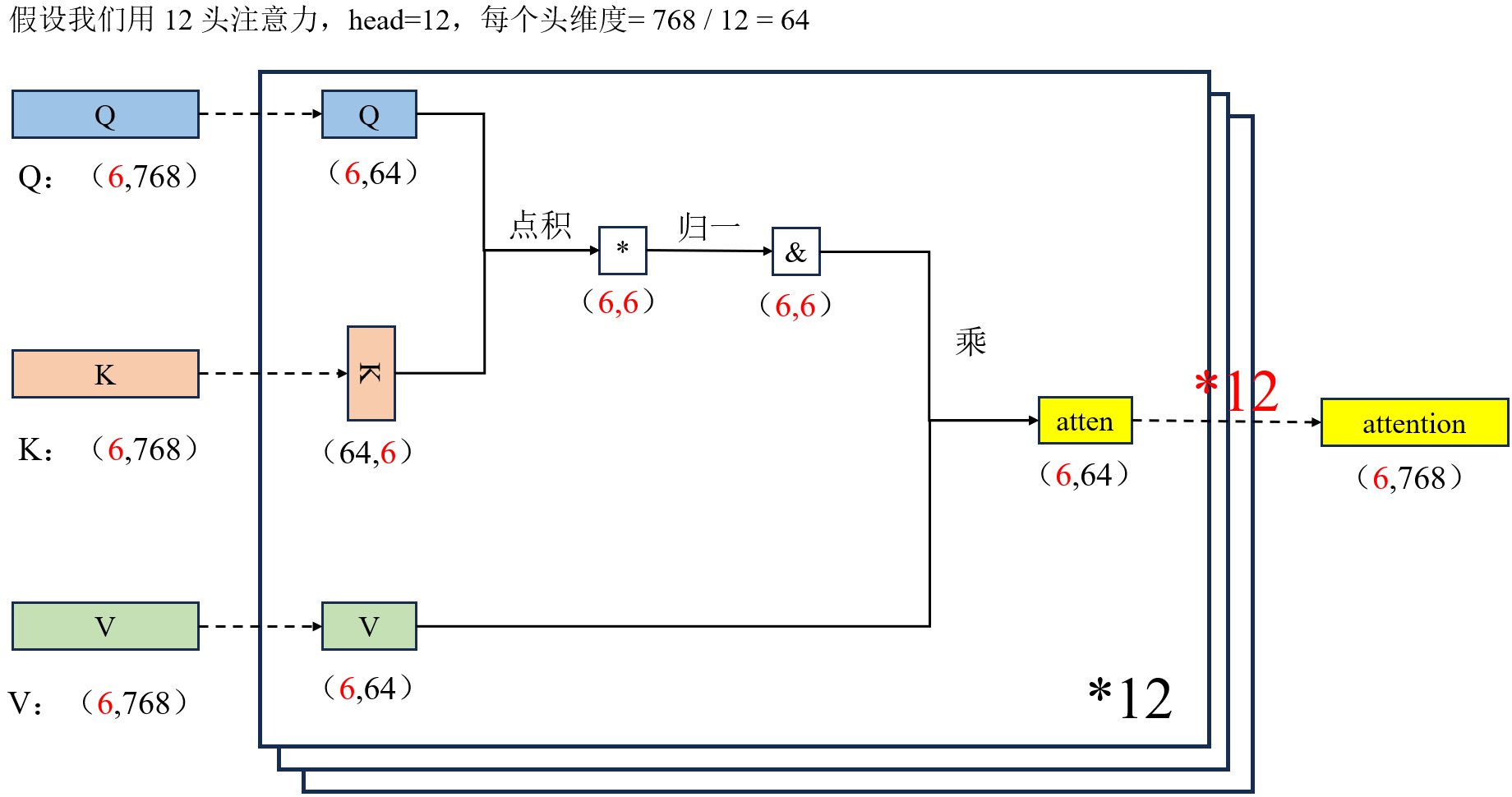
对于维度为 (6,768) 的输入序列(6 个 token,每个 token 为 768 维特征),多头自注意力机制通过拆分投影 + 多组并行计算 + 拼接融合的方式,在保持输入输出维度不变的前提下,从多视角提取上下文语义信息。
- 首先,输入分别通过 12 组独立的小权重矩阵,将 Q/K/V 从 (6,768) 投影为 (6,64)(因 dk=768/12=64),每组对应一个独立注意力头;
- 接着,对每个头单独计算注意力分数:将 K 转置后与 Q 做点积,得到 (6,6) 的分数矩阵,经 Softmax 归一化后得到 (6,6) 的注意力权重,再与 V 相乘,得到单头输出 (6,64);
- 随后,将 12 个独立头的输出 (6,64) 在最后一维拼接,得到 (6,768) 的中间结果,最后经线性层融合,输出最终的注意力表示 (6,768)。
- 整个过程中,12 组独立的小权重保证了模型能从多子空间捕捉不同语义依赖,而 (6,6) 的中间矩阵仅用于表征单头下 token 间的关注关系,最终输出维度与输入一致,实现了上下文信息的多视角融合与特征更新。
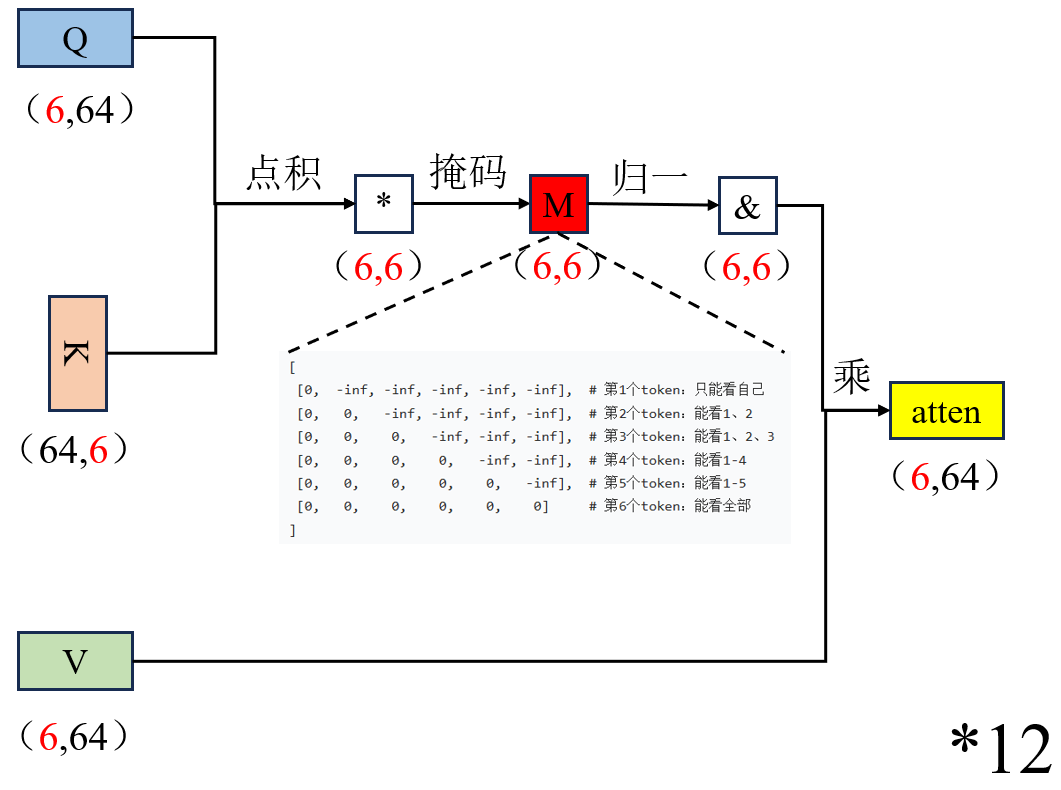
2.3 掩码多头注意力(Masked Multi-Head Attention)
掩码(Mask):在计算注意力分数时,将未来位置的分数置为负无穷,使模型在 Softmax 后无法分配任何权重给未来 token,从根本上杜绝偷看答案。
它在多头自注意力的基础上,加入了下三角掩码(Mask),强制模型只能关注当前及之前的 token,严格保证自回归生成的单向性。
- 在Q K点乘之后,softmax 之前,对未来位置加上一个下三角掩码:M 是上三角为负无穷,下三角为 0 的矩阵,强制每个位置只能看到左边及自己,看不到右边。
- 其他结构不变。
bash
# 原始注意力分数矩阵:
scores = [
[1.2, 0.8, 0.5, 0.3, 0.7, 0.4], # 第1个token对所有token的分数
[0.9, 1.5, 0.6, 0.8, 0.2, 0.5], # 第2个token对所有token的分数
[0.7, 0.4, 1.1, 0.9, 0.6, 0.8], # 第3个token对所有token的分数
[0.5, 0.8, 0.7, 1.3, 0.4, 0.6], # 第4个token对所有token的分数
[0.8, 0.6, 0.9, 0.5, 1.4, 0.7], # 第5个token对所有token的分数
[0.6, 0.7, 0.8, 0.9, 0.5, 1.0] # 第6个token对所有token的分数
]
# 6×6 掩码矩阵(mask):
mask = [
[0, -inf, -inf, -inf, -inf, -inf], # 第1行:仅第1列可见
[0, 0, -inf, -inf, -inf, -inf], # 第2行:仅1-2列可见
[0, 0, 0, -inf, -inf, -inf], # 第3行:仅1-3列可见
[0, 0, 0, 0, -inf, -inf], # 第4行:仅1-4列可见
[0, 0, 0, 0, 0, -inf], # 第5行:仅1-5列可见
[0, 0, 0, 0, 0, 0] # 第6行:全可见
]
# 分数矩阵 + 掩码矩阵(逐元素相加):
masked_scores = scores + mask = [
[1.2, -inf, -inf, -inf, -inf, -inf], # 第1行:仅第1列保留原始值
[0.9, 1.5, -inf, -inf, -inf, -inf], # 第2行:1-2列保留原始值
[0.7, 0.4, 1.1, -inf, -inf, -inf], # 第3行:1-3列保留原始值
[0.5, 0.8, 0.7, 1.3, -inf, -inf], # 第4行:1-4列保留原始值
[0.8, 0.6, 0.9, 0.5, 1.4, -inf], # 第5行:1-5列保留原始值
[0.6, 0.7, 0.8, 0.9, 0.5, 1.0] # 第6行:全保留
]
# Softmax归一化:
[
[1.000, 0.000, 0.000, 0.000, 0.000, 0.000],
[0.354, 0.646, 0.000, 0.000, 0.000, 0.000],
[0.309, 0.229, 0.462, 0.000, 0.000, 0.000],
[0.145, 0.252, 0.221, 0.382, 0.000, 0.000],
[0.198, 0.165, 0.224, 0.148, 0.265, 0.000],
[0.118, 0.132, 0.148, 0.166, 0.112, 0.324]
]2.4 编码器 - 解码器注意力(Encoder-Decoder Attention)
编码器 - 解码器注意力关注【Decoder 目标序列】与【Encoder 源序列】的跨序列关系,解决翻译 / 生成时的语义对齐问题(如生成中文 爱 时,精准匹配英文 love 的语义)。
- Decoder 以自身生成的内容为查询,到 Encoder 编码的源序列字典中查语义,实现跨序列的语义对齐。可以把Decoder 当做【翻译员】,Encoder 是 【双语词典】。翻译员想写 爱 ,就拿着 爱 的语义线索(Q)去词典里查(K),发现 love 最匹配,就把 love 的语义(V)重点拿过来,融入自己的翻译结果。
- 结构还是多头,只是来源变了:Q 来自 Decoder,K/V 来自 Encoder。无掩码,可完整关注 Encoder 的全部源序列
- 编码器 - 解码器注意力的最终输出维度必然和 Decoder 输入维度一致
2.5总结
| 注意力类型 | Q 来源 | K/V 来源 | 核心特点 | 应用位置 |
|---|---|---|---|---|
| 单头自注意力 | 自身序列 | 自身序列 | 单维度关注自身序列关系 | Encoder |
| 多头自注意力 | 自身序列 | 自身序列 | 多维度关注自身序列关系 | Encoder |
| 掩码多头自注意力 | 自身序列 | 自身序列 | 多维度 + 只能看过去(遮未来) | Decoder |
| 编码器 - 解码器注意力 | Decoder 序列 | Encoder 序列 | 多维度 + 跨序列查字典(对齐) | Decoder |
四、其他网络层
4.1 残差连接(Residual Connection)
残差连接(shortcut connection)是 Transformer 中保证深度网络可训练的核心组件,最早由 ResNet(2015 年)引入解决深度网络的【梯度消失 / 退化】问题,Transformer 将其与层归一化结合,成为每一层子模块(自注意力、前馈网络)的标配。
多头自注意力输出的是 (6, 768),但直接丢给下一层会有两个问题:
- 梯度消失 / 爆炸:模型堆叠多层后,梯度容易消失或爆炸,训练不稳定。
- 分布偏移:每层输出分布变化大,导致模型收敛慢、效果差。
残差连接能解决梯度问题,让梯度可以短路流过残差路径,避免深层梯度消失,保证模型能训练得很深。
对于一个子模块(比如 Transformer 中的自注意力层 / 前馈网络),设其输入为 x,子模块的变换为 F(x)(比如注意力计算、FFN),则残差连接的输出为:
y = x + F ( x ) y=x+F(x) y=x+F(x)
x:原始输入("直连路径")F(x):子模块的变换结果("残差路径")
网络无需学习【从 x 到目标输出的完整映射】,只需学习【x 到目标输出的残差 F(x)=y−x】
4.2 Layer Norm
归一化:解决分布偏移问题,把每一条数据的分布,强行拉成均值 0、方差 1 的标准正态分布。让训练更稳定,防止梯度消失 / 爆炸。形状不变:(6, 768) → (6, 768)。
BatchNorm:按 "特征" 归一化(同一列):对所有句子、所有词的 第 i 个特征 做归一化。LayerNorm:按 "样本" 归一化(同一行):对每一个词的 512 维向量自己做归一化!
LayerNorm让每一层输出分布稳定,不会越训越偏,不会爆炸 / 消失。配合残差连接,残差负责梯度直通,LayerNorm 负责分布稳定,让深层能训练。不依赖 batch 大小,句子长短不一也没事。每个 token 独立归一化
非常适合自注意力。
L a y e r N o r m ( x ) = γ ⋅ x − μ σ + β LayerNorm(x)=γ⋅\frac{x−μ}{σ} +β LayerNorm(x)=γ⋅σx−μ+β
- μ:当前样本所有维度的均值
- σ:当前样本所有维度的标准差
- γ、β:可学习的缩放和偏置参数,让模型恢复表达能力
4.3 前馈网络(FFN)
FFN 就是对每个 Token 的向量独立做一次小全连接网络,不是跨 Token 计算,而是内部变换。它不关心其他 Token,只处理每个 Token 自己的 768 维向量。
| 模块 | 作用 | 处理方式 |
|---|---|---|
| Self-Attention | 建模 token 之间的关系 | 跨 token 交互 |
| FFN | 对单个 token 特征提纯 | 每个 token 独立处理 |
对每个 Token 的向量做两次线性变换 + 一次非线性激活,让模型深度提取语义特征。
F F N ( x ) = L i n e a r 2 ( R e L u ( L i n e a r 1 ( x ) ) ) FFN(x)=Linear_2 (ReLu(Linear_1(x))) FFN(x)=Linear2(ReLu(Linear1(x)))
- 输入x:来自上一层残差连接和归一化后的向量(6, 768)。
- 第一层线性+ReLU:
- W1:(768, 2048)、b1:(2048),输出: y = W 1 ∗ x + b 1 y=W_1*x+b_1 y=W1∗x+b1,最终结果的维度为(6, 2048)
- 激活函数 ReLU,把负数清零,引入非线性,输出仍为 (6, 2048)
- 第二层线性:
- W2:(2048, 768)、b2:(768)、输出: y = W 2 ∗ x + b 2 y=W_2*x+b_2 y=W2∗x+b2,最终还原到与输入相同的维度(6, 768)
五、Encoder & Decoder
5.1 结构
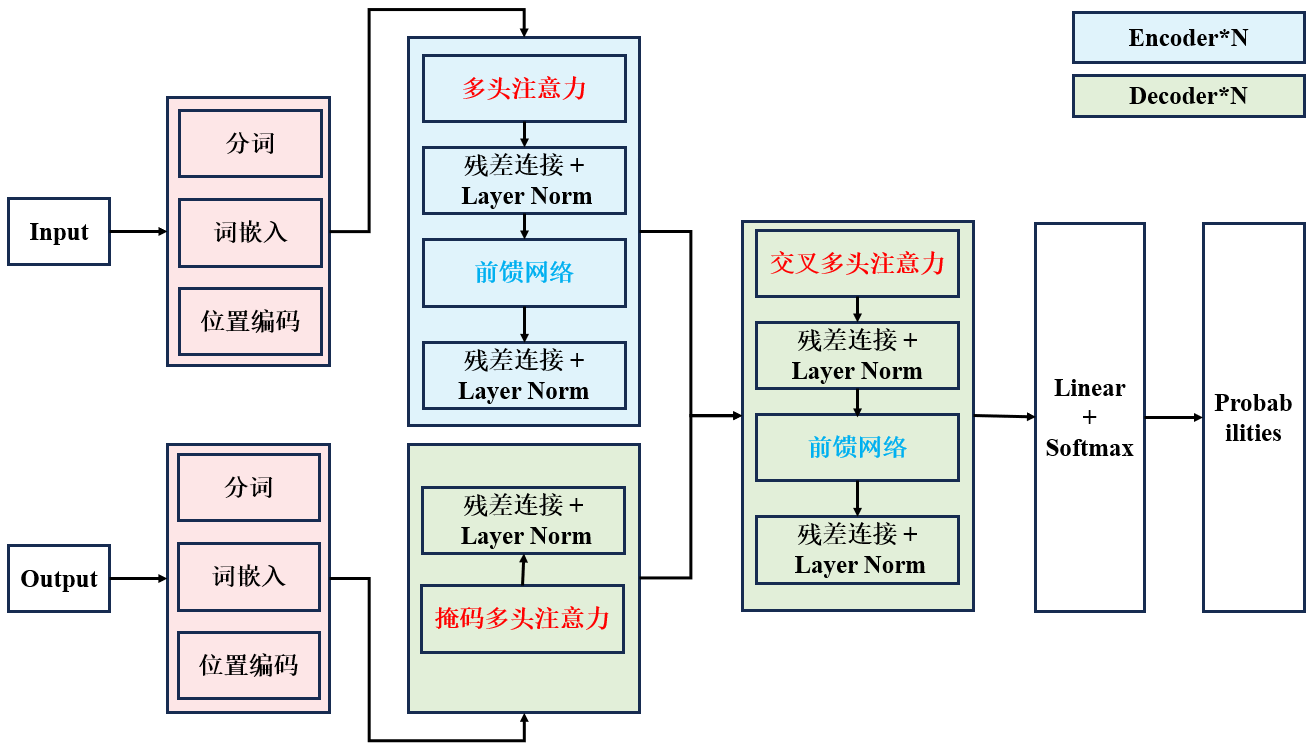
标准 Transformer 由输入 / 输出嵌入、位置编码、N 层编码器、N 层解码器、线性层与 Softmax 组成。
-
输入层:词嵌入将 token 转为向量,用正弦 / 余弦函数或可学习向量注入位置信息。
-
编码器(Encoder):上下文理解器。由 N 个相同层堆叠(论文 N=6),每层含:
- 1、多头自注意力(Multi-Head Self-Attention):无掩码,可关注所有 token。
- 2、残差连接 + 层归一化(Add & Norm):防梯度消失。
- 3、前馈网络(FFN):两层全连接 + ReLU/GELU,每个位置独立计算。
- 4、残差连接 + 层归一化(Add & Norm):防梯度消失。
-
解码器(Decoder):序列生成器,同样 N 层,每层含三部分:
- 1、掩码多头自注意力:用上三角掩码,禁止关注未来 token,保证自回归生成。
- 2、残差连接 + 层归一化(Add & Norm):防梯度消失。
- 3、编码器 - 解码器注意力:以解码器输出为 Q、编码器输出为 K/V,关联源与目标序列。
- 4、残差连接 + 层归一化(Add & Norm):防梯度消失。
- 5、前馈网络:两层全连接 + ReLU/GELU,每个位置独立计算。
- 6、残差连接 + 层归一化(Add & Norm):防梯度消失。
-
输出层:解码器输出经线性层映射到词表维度,再 Softmax 得到每个 token 的概率,取最大生成结果。
5.2 机器翻译举例
举例:
- 源句(Source):Artificial Intelligence is transforming the
- 目标句(Target):人工智能正在改变
- Encoder:处理输入序列(如源语言句子),输出上下文感知的特征表示。【看懂英文】
- Decoder:接收 Encoder 输出,逐步生成目标序列(如目标语言句子)。【生成中文】
源句:Artificial Intelligence is transforming the
- Encoder输入:
- 分词:Art、ificial、Intelligence、is、transforming、the(共 6 个 token)
- 词嵌入:每个 token 映射为 768 维向量,得到矩阵 X_emb ∈ (6, 768)
- 位置编码:注入位置信息,最终输入 X = X_emb + PE ∈ (6, 768)
- Encoder:
- 输入:X ∈ (6, 768)
- 单层 Encoder 结构(重复 N 次,如 N=12)
- 输出:memory ∈ (6, 768)(上下文特征矩阵),这是对整句英文的全局理解。
- Decoder输入:目标序列的已生成部分(词嵌入 + 位置编码),假设当前已生成前缀:人工。
- 已生成序列:"人", "工",分词后 2 个 token
- 词嵌入 + 位置编码,Y ∈ (2, 768)
- Decoder:
- 单层 Decoder 结构(重复 N 次,如 N=12),得到 Y_out ∈ (2, 768)
- 取最后一个 token 的向量 last_token ∈ (1, 768)
- 输出:
- 线性层映射到词表维度:logits ∈ (1, vocab_size)
- Softmax 得到概率分布,选取概率最高的 token,生成下一个字(如 智)
- 循环生成:将新生成的智加入已生成序列,重复上述流程,直到生成 结束符。
Encoder 的唯一任务是读懂源语言句子,所以输入是完整的源序列(英文句子),且模型能看到全部内容(双向注意力)。
- 输入是固定的、一次性喂给 Encoder的,模型能同时看到所有词,没有遮挡;
- Encoder 处理后输出一个语义向量矩阵,包含整个英文句子的语义,供 Decoder 查询。
Decoder 的任务是逐词生成目标语言句子,所以输入是目标序列的前缀(已生成的中文词),且模型只能看到已生成部分(掩码遮挡未来词)。Decoder 的输入分训练 / 推理两个阶段、由【已生成的目标序列】构成,核心是自回归------ 用过去生成的内容预测下一个内容。
训练阶段(有教师指导):训练时我们有完整的目标句标签(如 人工智能正在改变),为了让模型快速学习,会把完整目标序列一次性输入 Decoder,但通过掩码强制模型【假装只能看到前面的内容】。- 目标序列预处理
- 分词:【人,工,智,能,正,在,改,变】(共 8 个 token)。加特殊 token:开头加SOS(开始符),结尾加EOS(结束符),最终序列:【SOS,人,工,智,能,正,在,改,变,EOS】
- 词嵌入 + 位置编码:每个 token 转为 768 维向量,得到矩阵 Y ∈ (10, 768)(10 是 token 总数)。
- 输入 Decoder 的是移位后的目标序列
- Decoder 的输入不是完整的序列,而是去掉最后一个 token 的序列【SOS,人,工,智,能,正,在,改,变 】(9 个 token);
- 模型要预测的标签是去掉第一个 token 的序列:【人,工,智,能,正,在,改,变,EOS 】(9 个 token)。
- 掩码的作用(关键)
- 虽然输入了 9 个 token,但通过「上三角掩码」,模型在预测第 i 个 token 时,只能看到前 i-1 个 token:预测【人】时,只能看到 【SOS】;预测【工】时,只能看到【SOS,人】;预测【智】时,只能看到 【SOS,人,工】;... 以此类推,模拟只能看到过去、看不到未来的生成逻辑。
- 目标序列预处理
| 步骤 | 输入(人工给的标准答案) | 输出(模型要学的标准答案) |
|---|---|---|
| 第 1 步 | 【SOS】 | 【人】 |
| 第 2 步 | 【SOS,人】 | 【工】 |
| 第 3 步 | 【SOS,人,工】 | 【智】 |
推理阶段(无教师指导,真实生成):推理时我们没有目标句标签,只能从 【SOS】 开始,一步步生成,每一步的输入都是上一步生成的内容。- 第一步:初始输入
- Decoder 输入 = 【SOS】(仅 1 个 token),词嵌入 + 位置编码,Y₁ ∈ (1, 768);
- 模型结合 Encoder 输出(英文的 memory),预测下一个 token ,生成 【人】。
- 第二步:输入更新
- Decoder 输入 =【SOS,人】(2 个 token), 词嵌入 + 位置编码 ,Y₂ ∈ (2, 768);
- 模型结合 Encoder 输出(英文的 memory),预测下一个 token ,生成 【工】。
- 第三步:继续更新
- Decoder 输入 = 【SOS,人,工】(3 个 token),词嵌入 + 位置编码 → Y₃ ∈ (3, 768);
- 模型结合 Encoder 输出(英文的 memory),预测下一个 token ,生成 【智】。
- 循环直到结束:每次把新生成的 token加入输入序列,直到模型生成【 EOS】(结束符),停止生成。
- 第一步:初始输入
在推理阶段,Transformer会一步错步步错:
| 步骤 | 当前 Decoder 输入 | 应该对齐的英文 | 实际注意力对齐 | 模型应该输出 | 模型实际输出 | 错误说明 |
|---|---|---|---|---|---|---|
| 1 | 【SOS】 | Artificial | Artificial | 人 | 人 | 正确 |
| 2 | 【SOS,人】 | Artificial | Artificial | 工 | 工 | 正确 |
| 3 | 【SOS,人,工】 | Intelligence | Intelligence | 智 | 智 | 正确 |
| 4 | 【SOS,人,工,智】 | Intelligence | Intelligence对齐失败 | 能 | 障 | 凑成智障 |
| 5 | 【SOS,人,工,智,障】 | is | is | 正 | 正 | 跟着错 |
| 6 | 【SOS,人,工,智,障,正】 | is | is | 在 | 在 | 继续错 |
| 7 | 【SOS,人,工,智,障,正,在】 | transforming | transforming | 改 | 改 | 继续 |
| 8 | 【SOS,人,工,智,障,正,在,改】 | transforming | transforming | 变 | 变 | 完成 |
六、总结
整体结构:Transformer = Encoder(编码器) + Decoder(解码器)
- Encoder:理解输入句子,提取全局上下文。
- Decoder:根据 Encoder 的理解,自回归生成输出句子。
Encoder 做什么?
- 两层子结构:多头自注意力 + FFN
- 注意力是双向的,可以看整个句子。
- 输出一个语义记忆矩阵(memory),交给 Decoder。
Decoder 做什么
- 三层子结构:掩码自注意力 + 交叉注意力 + FFN
- 掩码自注意力:只能看前面,不能看未来,保证生成合法。
- 交叉注意力(Cross-Attention):拿中文去查英文,实现翻译对齐。
- 一步只生成一个词 / 字,错了就一路错到底(自回归)。