为什么我们需要更好的优化器?
训练神经网络的本质是在一个极其复杂的"损失地形"中寻找最低点。想象你蒙着眼睛站在一片起伏的山地中,唯一的线索是脚下的坡度------你需要靠"感觉"一步步走到谷底。这就是梯度下降在做的事情。
但原始的梯度下降(SGD)有两个致命缺陷:
- 震荡问题:在狭长的山谷中,SGD 会像弹球一样左右反弹,纵向推进极其缓慢。
- 一刀切的学习率:所有参数共享同一个步长,但实际上不同参数的"地形"差异巨大------有的平坦如湖面,有的陡峭如悬崖。
Adam 正是为了同时解决这两个问题而诞生的。
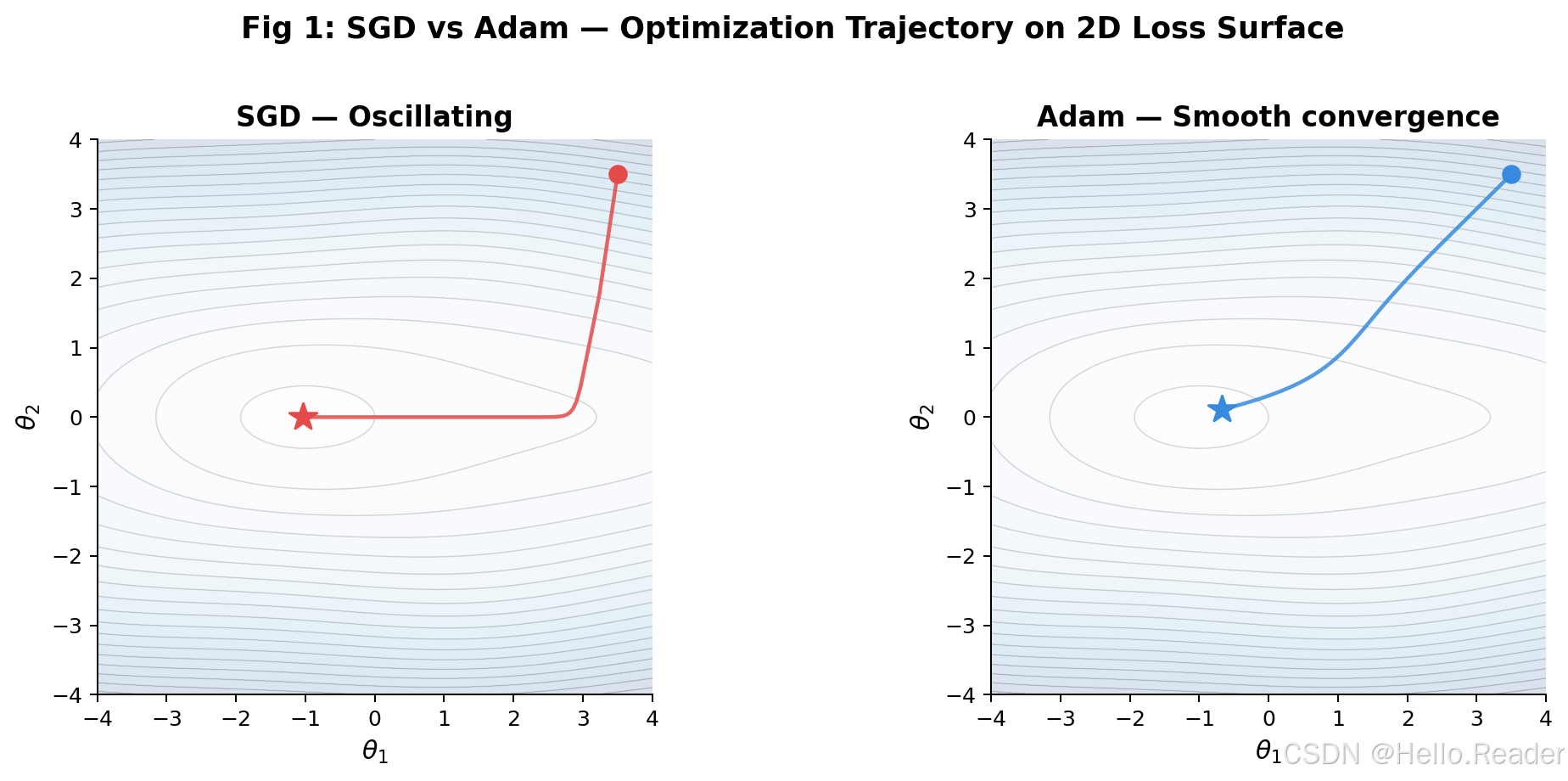
Adam 的两大核心武器
Adam 的全称是 Adaptive Moment Estimation(自适应矩估计),名字中藏着它的两个核心机制。
武器一:一阶矩(动量)------记住方向
Adam 维护一个梯度的指数加权移动平均 ,称为一阶矩(first moment) mtm_tmt:
mt=β1⋅mt−1+(1−β1)⋅gt m_t = \beta_1 \cdot m_{t-1} + (1 - \beta_1) \cdot g_t mt=β1⋅mt−1+(1−β1)⋅gt
其中 gtg_tgt 是当前时刻的梯度,β1\beta_1β1 通常取 0.9。
直觉理解:这就像一个滚下山坡的球。球不会在每一个小坑前停下来,而是积累了"惯性"------如果前面好几步都在往同一个方向走,球的速度就越来越快。反过来,如果方向频繁变化(震荡),正负梯度会互相抵消,自动减速。
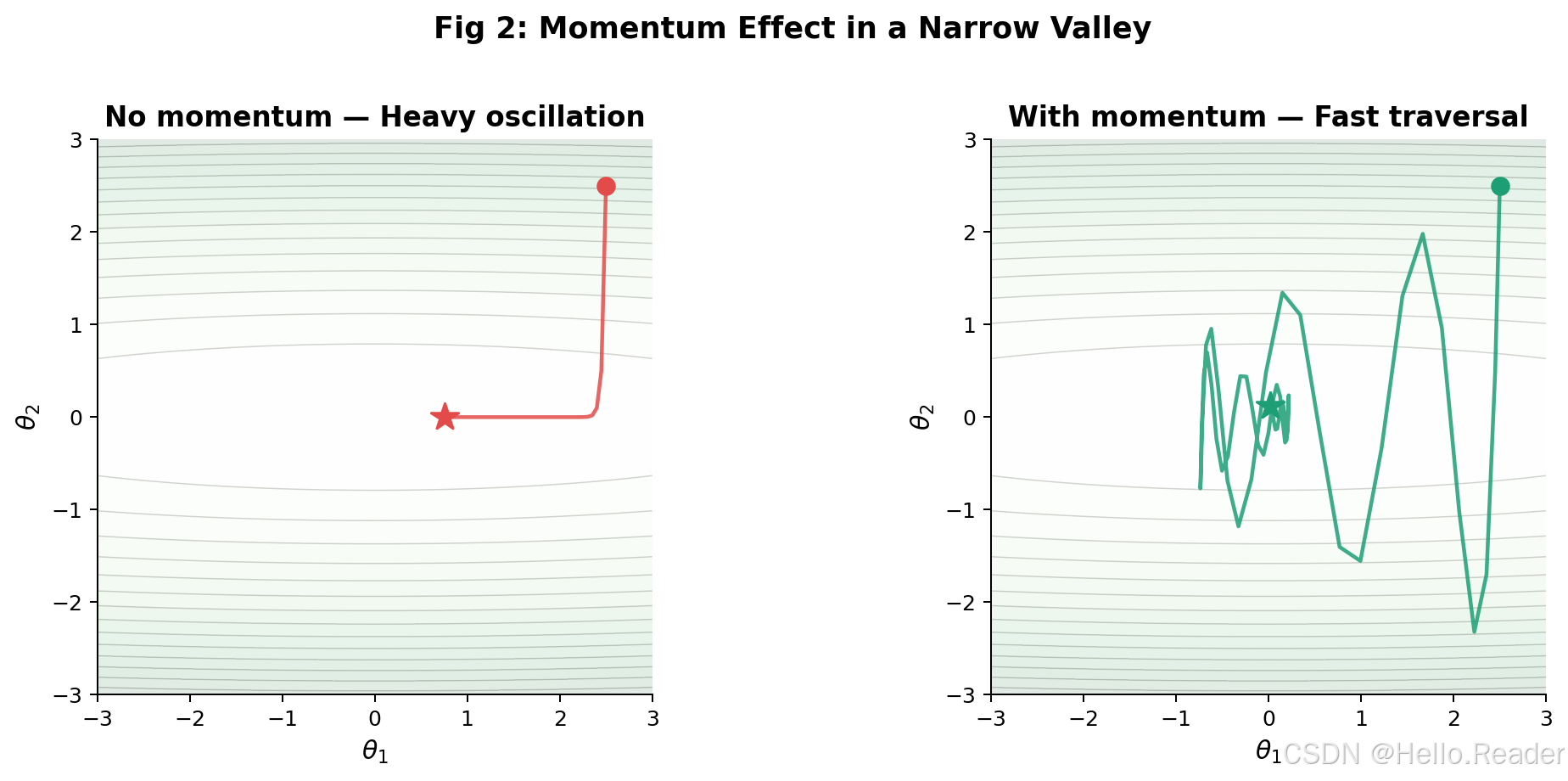
武器二:二阶矩(自适应学习率)------感知地形
Adam 还维护一个梯度平方的指数加权移动平均 ,称为二阶矩(second moment) vtv_tvt:
vt=β2⋅vt−1+(1−β2)⋅gt2 v_t = \beta_2 \cdot v_{t-1} + (1 - \beta_2) \cdot g_t^2 vt=β2⋅vt−1+(1−β2)⋅gt2
其中 β2\beta_2β2 通常取 0.999。
直觉理解 :vtv_tvt 衡量的是"这个参数历史上波动有多剧烈"。波动大(vtv_tvt 大)说明地形崎岖,Adam 就自动缩小步长,小心翼翼地走。波动小(vtv_tvt 小)说明地形平坦,Adam 就放心地迈大步。这就是"自适应学习率"的含义------每个参数都有自己专属的步长。
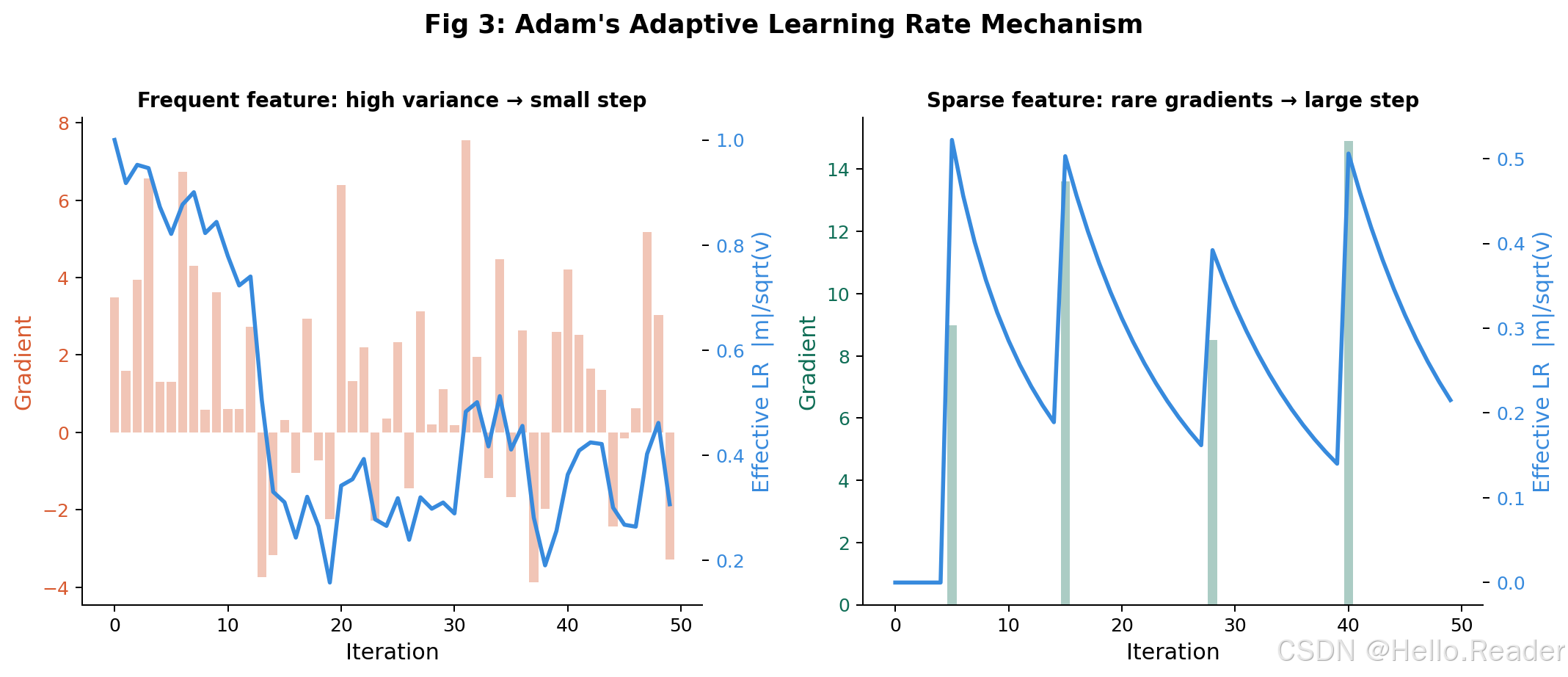
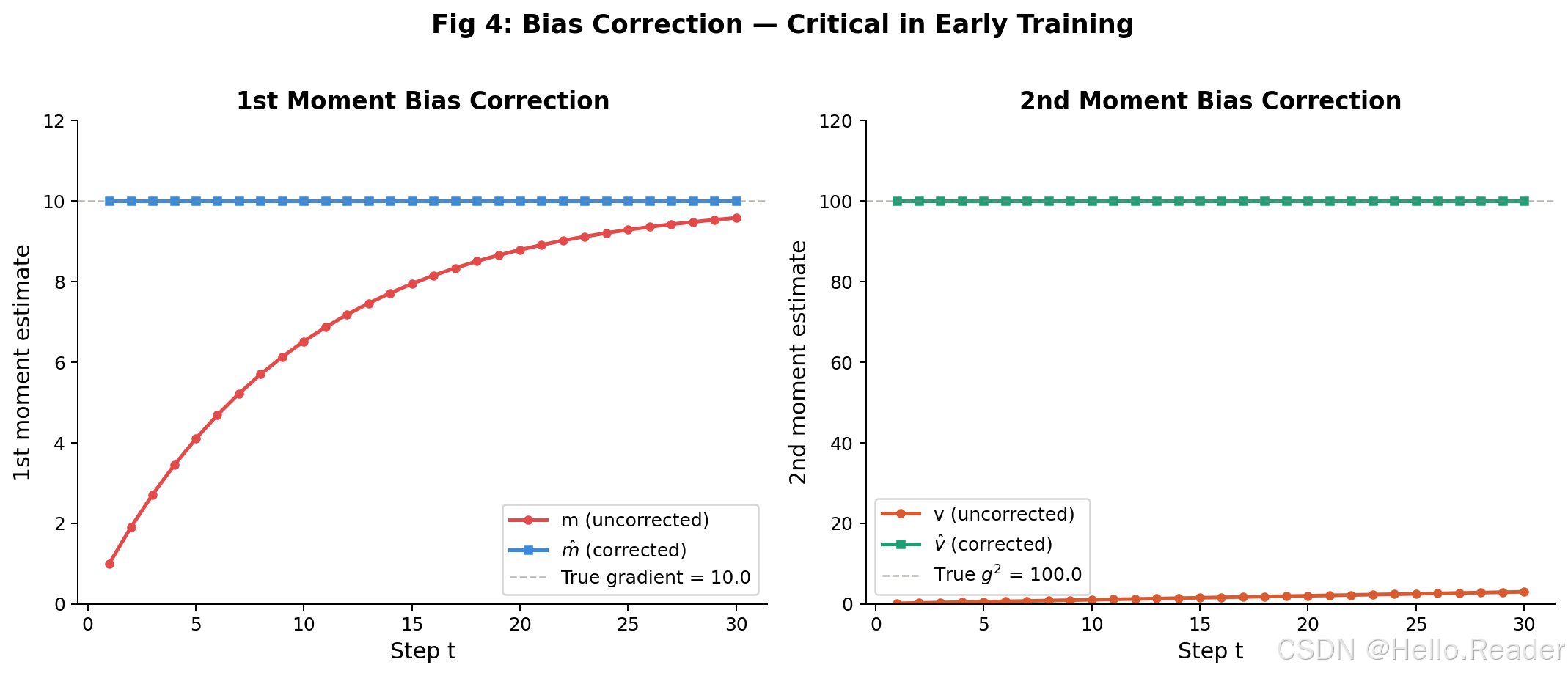
偏差修正:被忽视的关键细节
如果你只看到上面两个公式就动手实现 Adam,训练初期会遇到一个诡异的问题------更新量极其微小,模型几乎不动。原因在于 mtm_tmt 和 vtv_tvt 初始化为 0,而前几步的加权平均会严重偏向零。
来看一个具体的例子。假设真实梯度恒为 10,β1=0.9\beta_1 = 0.9β1=0.9:
| 时刻 ttt | mtm_tmt(无修正) | m^t\hat{m}_tm^t(修正后) |
|---|---|---|
| 1 | 1.0 | 10.0 |
| 2 | 1.9 | 10.0 |
| 3 | 2.71 | 10.0 |
| 10 | 6.51 | 10.0 |
没有修正的 mtm_tmt 在第 1 步只有真实值的 10%!偏差修正公式非常简洁:
m^t=mt1−β1t,v^t=vt1−β2t \hat{m}_t = \frac{m_t}{1 - \beta_1^t}, \quad \hat{v}_t = \frac{v_t}{1 - \beta_2^t} m^t=1−β1tmt,v^t=1−β2tvt
当 t=1t=1t=1 时,1−0.91=0.11 - 0.9^1 = 0.11−0.91=0.1,所以 m^1=1.0/0.1=10.0\hat{m}_1 = 1.0 / 0.1 = 10.0m^1=1.0/0.1=10.0,完美修正。随着 ttt 增大,βt→0\beta^t \to 0βt→0,修正因子趋近于 1,自然消失。
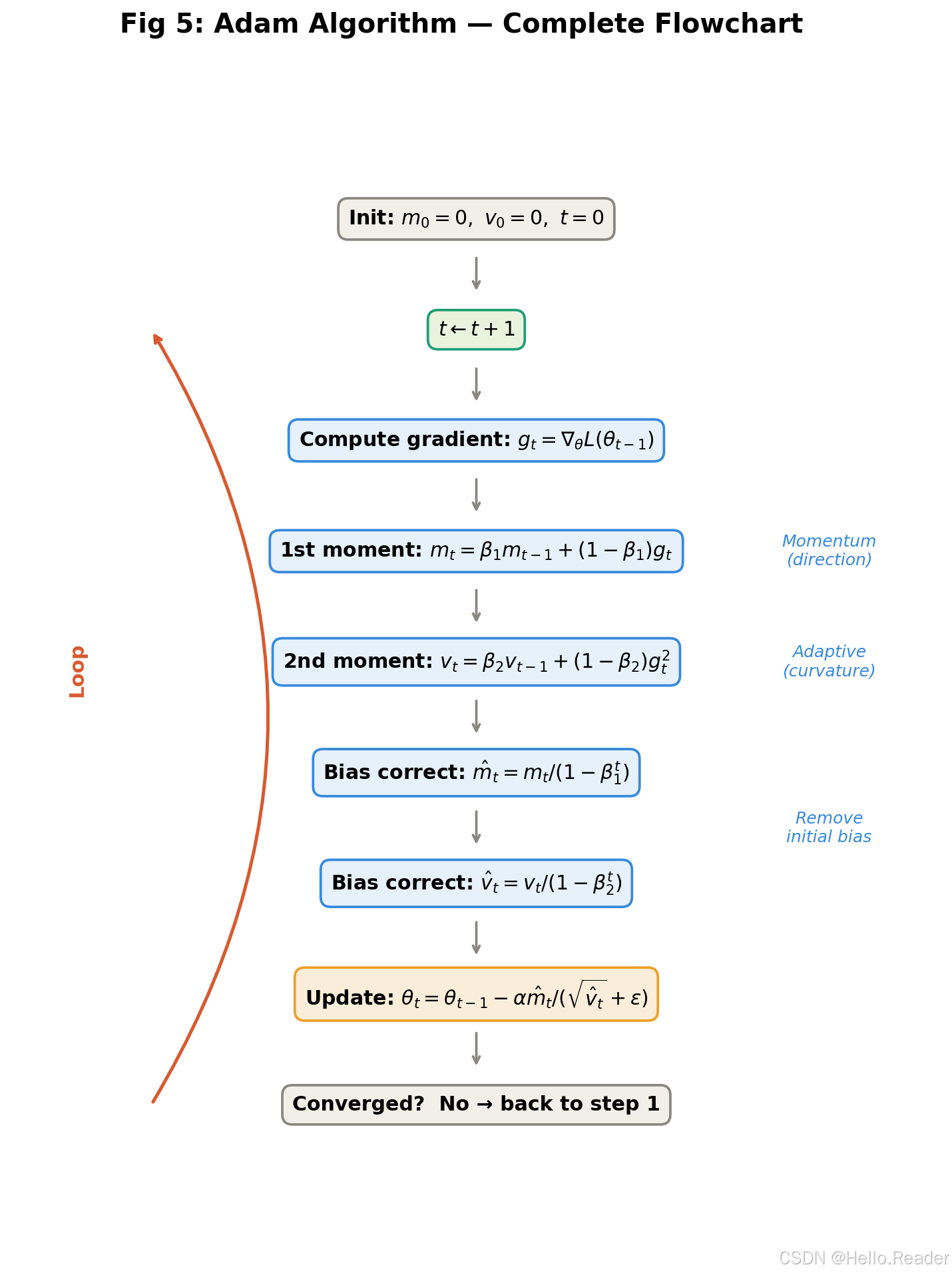
完整的 Adam 算法
将以上所有组件组装起来,就是完整的 Adam:
输入 :学习率 α\alphaα(默认 0.001),衰减系数 β1=0.9\beta_1 = 0.9β1=0.9,β2=0.999\beta_2 = 0.999β2=0.999,数值稳定项 ϵ=10−8\epsilon = 10^{-8}ϵ=10−8
初始化 :m0=0m_0 = 0m0=0,v0=0v_0 = 0v0=0,t=0t = 0t=0
每次迭代:
- t←t+1t \leftarrow t + 1t←t+1
- gt←∇θL(θt−1)g_t \leftarrow \nabla_\theta L(\theta_{t-1})gt←∇θL(θt−1) (计算梯度)
- mt←β1⋅mt−1+(1−β1)⋅gtm_t \leftarrow \beta_1 \cdot m_{t-1} + (1 - \beta_1) \cdot g_tmt←β1⋅mt−1+(1−β1)⋅gt (更新一阶矩)
- vt←β2⋅vt−1+(1−β2)⋅gt2v_t \leftarrow \beta_2 \cdot v_{t-1} + (1 - \beta_2) \cdot g_t^2vt←β2⋅vt−1+(1−β2)⋅gt2 (更新二阶矩)
- m^t←mt/(1−β1t)\hat{m}_t \leftarrow m_t / (1 - \beta_1^t)m^t←mt/(1−β1t) (偏差修正)
- v^t←vt/(1−β2t)\hat{v}_t \leftarrow v_t / (1 - \beta_2^t)v^t←vt/(1−β2t) (偏差修正)
- θt←θt−1−α⋅m^t/(v^t+ϵ)\theta_t \leftarrow \theta_{t-1} - \alpha \cdot \hat{m}_t / (\sqrt{\hat{v}_t} + \epsilon)θt←θt−1−α⋅m^t/(v^t +ϵ) (更新参数)
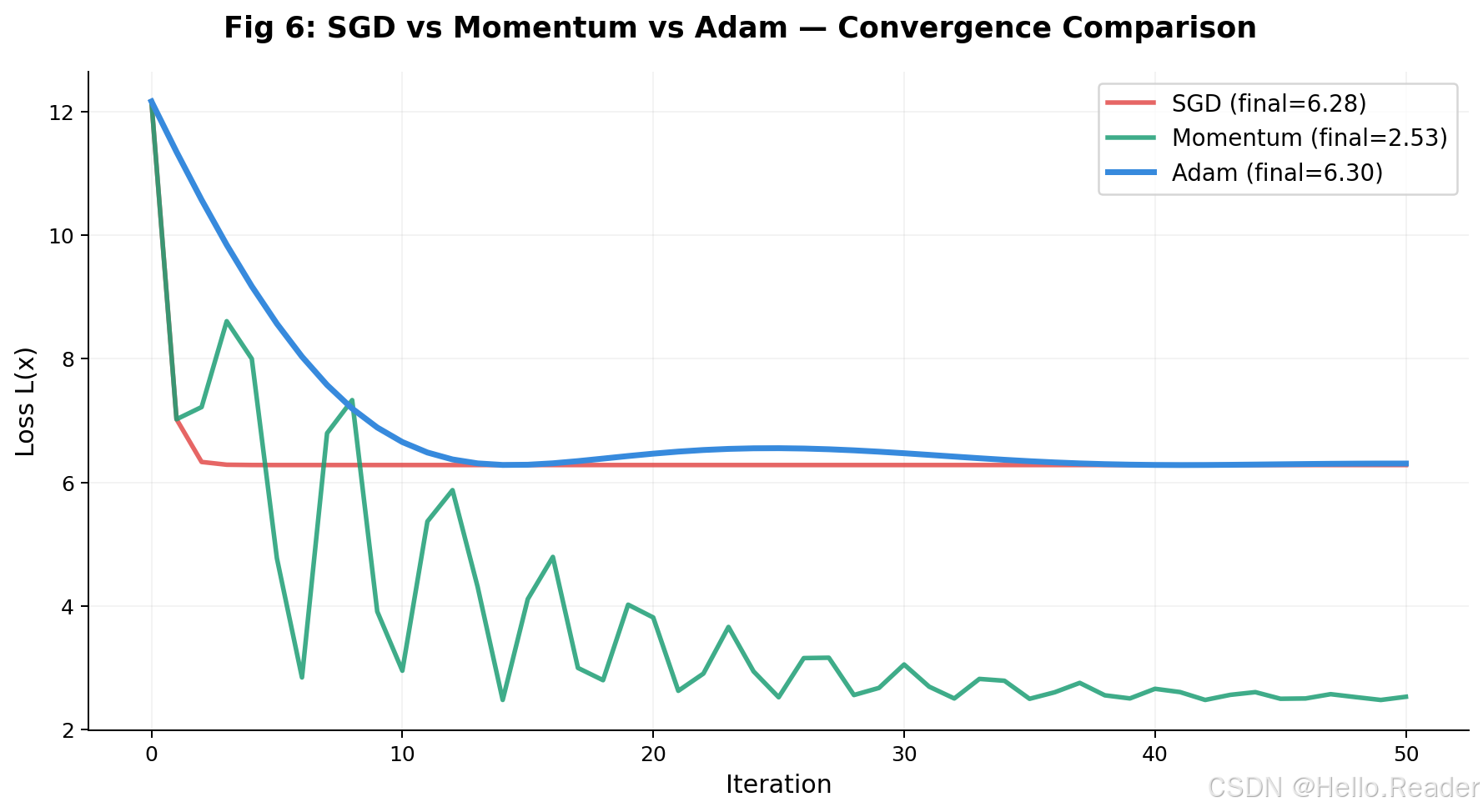
实战对比:SGD vs Momentum vs Adam
下面用一个具体的损失函数 L(x)=0.5x2+3sin(1.5x)+5L(x) = 0.5x^2 + 3\sin(1.5x) + 5L(x)=0.5x2+3sin(1.5x)+5 来对比三种优化器的表现。起始点 x0=4.0x_0 = 4.0x0=4.0,学习率 α=0.1\alpha = 0.1α=0.1。
SGD
每一步的更新量完全取决于当前梯度,没有任何记忆。在这个包含多个局部波动的函数上,SGD 的收敛路径充满了锯齿和犹豫。
SGD + Momentum
加入动量后,优化器获得了"惯性"。它能更快地穿越小幅波动区域,但在急转弯处有时会冲过头。
Adam
同时拥有动量和自适应学习率。在训练初期,偏差修正确保更新量合理;在收敛后期,v^t\sqrt{\hat{v}_t}v^t 自然增大,步长自动缩小,实现"精确着陆"。
Adam 的超参数怎么调?
在绝大多数情况下,Adam 论文推荐的默认值就够用了:
| 超参数 | 默认值 | 作用 | 调参建议 |
|---|---|---|---|
| α\alphaα | 0.001 | 全局学习率 | 最需要调的参数,通常在 10−410^{-4}10−4 到 10−210^{-2}10−2 之间搜索 |
| β1\beta_1β1 | 0.9 | 一阶矩衰减率 | 几乎不需要改,极少数情况下可试 0.95 |
| β2\beta_2β2 | 0.999 | 二阶矩衰减率 | 通常不需要改,训练不稳定时可试 0.99 |
| ϵ\epsilonϵ | 10−810^{-8}10−8 | 数值稳定项 | 基本不需要动 |
一句话总结:只调学习率,其他保持默认。
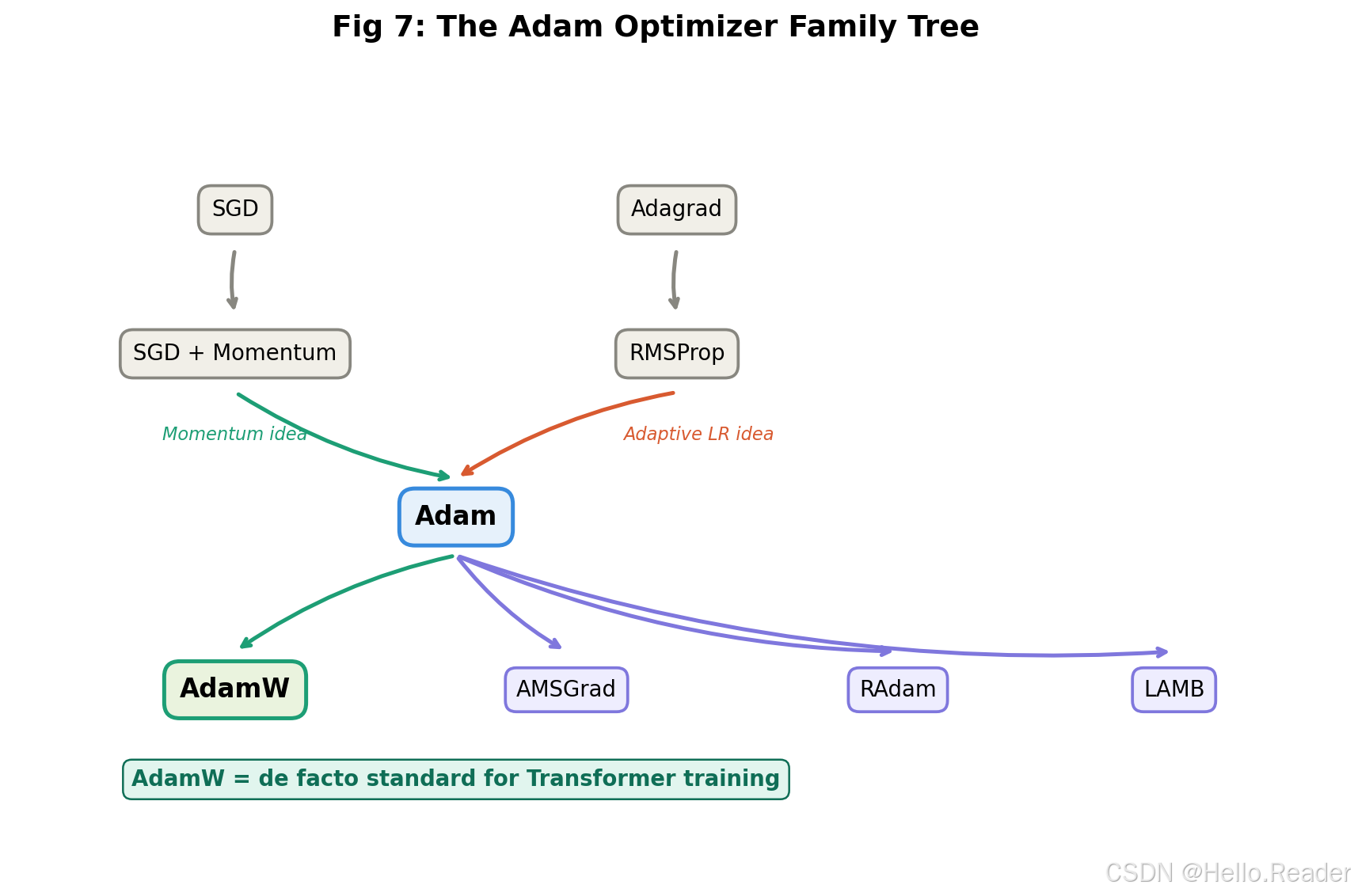
Adam 的局限与变体
Adam 并非万能。以下是一些已知问题及对应的改进方案。
泛化性能差距
多项研究发现,在某些任务上(特别是计算机视觉),经过精心调参的 SGD + Momentum 最终能达到比 Adam 更好的测试精度。这被认为与 Adam 倾向于找到"尖锐"的极小值有关,而 SGD 更容易找到"平坦"的极小值,后者泛化能力更强。
权重衰减的纠正------AdamW
原始 Adam 中加入 L2 正则化时,正则项会被自适应学习率缩放,导致正则效果被削弱。AdamW 将权重衰减从梯度更新中解耦出来,直接在参数上执行衰减,修正了这一问题。目前 AdamW 已经成为 Transformer 模型训练的事实标准。
其他变体
- AMSGrad:修正 Adam 在某些凸优化场景中不收敛的理论缺陷
- RAdam:自动预热学习率,消除了手动设置 warmup 的需要
- LAMB / LARS:面向大 batch 训练的 Adam 变体,在分布式训练中广泛使用
用 PyTorch 实现 Adam
在实际项目中,你几乎不需要手写 Adam,PyTorch 已经提供了高度优化的实现:
python
import torch
import torch.nn as nn
model = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
# 使用 Adam
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
# 使用 AdamW(推荐用于 Transformer)
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3, weight_decay=0.01)
# 训练循环
for epoch in range(num_epochs):
for batch_x, batch_y in dataloader:
optimizer.zero_grad()
loss = criterion(model(batch_x), batch_y)
loss.backward()
optimizer.step()如果你想从零理解内部机制,以下是 Adam 的纯 Python 实现:
python
import numpy as np
class Adam:
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999, eps=1e-8):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.eps = eps
self.m = None # 一阶矩
self.v = None # 二阶矩
self.t = 0 # 时间步
def step(self, params, grads):
if self.m is None:
self.m = np.zeros_like(params)
self.v = np.zeros_like(params)
self.t += 1
# 更新一阶矩和二阶矩
self.m = self.beta1 * self.m + (1 - self.beta1) * grads
self.v = self.beta2 * self.v + (1 - self.beta2) * grads ** 2
# 偏差修正
m_hat = self.m / (1 - self.beta1 ** self.t)
v_hat = self.v / (1 - self.beta2 ** self.t)
# 参数更新
params -= self.lr * m_hat / (np.sqrt(v_hat) + self.eps)
return params总结
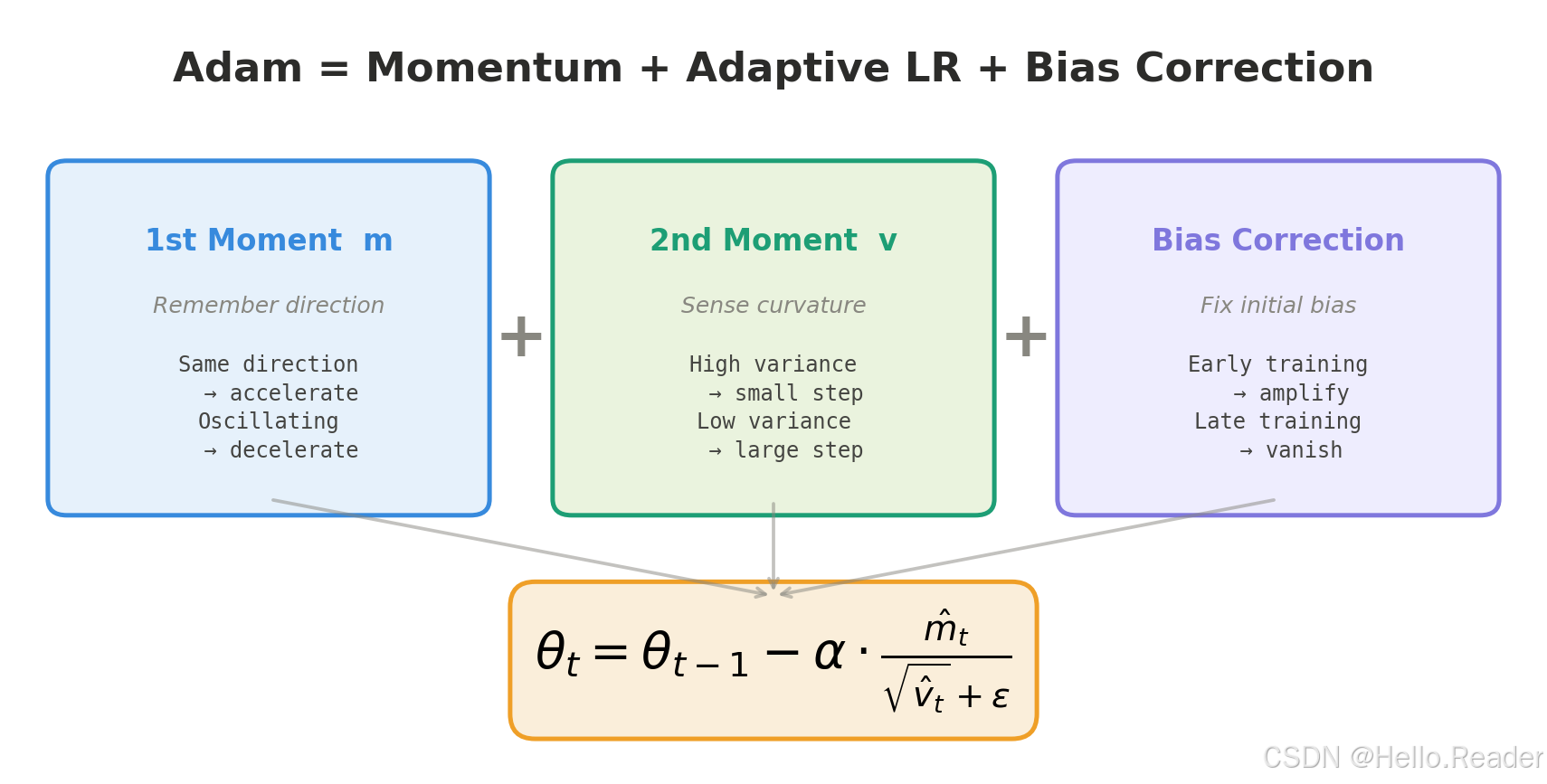
Adam 之所以能成为深度学习中最流行的优化器,是因为它优雅地融合了两个关键思想:
- 动量(一阶矩):赋予优化过程"记忆",在一致方向上加速,在震荡方向上减速。
- 自适应学习率(二阶矩):让每个参数拥有独立的、根据历史波动自动调整的学习率。
- 偏差修正:确保训练初期的估计值准确可靠。
最终的更新公式 θt=θt−1−α⋅m^t/(v^t+ϵ)\theta_t = \theta_{t-1} - \alpha \cdot \hat{m}_t / (\sqrt{\hat{v}_t} + \epsilon)θt=θt−1−α⋅m^t/(v^t +ϵ) 用分子的动量加速收敛,用分母的自适应缩放避免震荡,两者相辅相成。
对于大多数深度学习任务,Adam(或 AdamW)配合默认超参数就是一个极好的起点。当你需要榨取最后一点性能时,再考虑精细调参或切换到其他优化器。
l=images%2Ffig8-adam-summary.png&pos_id=img-f5uzDdNU-1773539023992)
参考文献
- Kingma, D. P., & Ba, J. (2015). Adam: A Method for Stochastic Optimization. ICLR 2015.
- Loshchilov, I., & Hutter, F. (2019). Decoupled Weight Decay Regularization. ICLR 2019.
- Reddi, S. J., Kale, S., & Kumar, S. (2018). On the Convergence of Adam and Beyond. ICLR 2018.