ICCV 2025 录用论文
https://iccv.thecvf.com/Conferences/2025/AcceptedPapers
检索关键词:【Image Fusion】
文章目录
-
- [ICCV 2025 录用论文](#ICCV 2025 录用论文)
- 录用情况-预览
- [01 Revisiting Image Fusion for Multi-Illuminant White-Balance Correction](#01 Revisiting Image Fusion for Multi-Illuminant White-Balance Correction)
- [02 Balancing Task-invariant Interaction and Task-specific Adaptation for Unified Image Fusion](#02 Balancing Task-invariant Interaction and Task-specific Adaptation for Unified Image Fusion)
- [03 Hipandas: Hyperspectral Image Joint Denoising and Super-Resolution by Image Fusion with the Panchromatic Image](#03 Hipandas: Hyperspectral Image Joint Denoising and Super-Resolution by Image Fusion with the Panchromatic Image)
- [04 Highlight What You Want: Weakly-Supervised Instance-Level Controllable Infrared-Visible Image Fusion](#04 Highlight What You Want: Weakly-Supervised Instance-Level Controllable Infrared-Visible Image Fusion)
- [05 LUT-Fuse: Towards Extremely Fast Infrared and Visible Image Fusion via Distillation to Learnable Look-Up Tables](#05 LUT-Fuse: Towards Extremely Fast Infrared and Visible Image Fusion via Distillation to Learnable Look-Up Tables)
- [06 DreamFuse: Adaptive Image Fusion with Diffusion Transformer](#06 DreamFuse: Adaptive Image Fusion with Diffusion Transformer)
- [07 AMDANet: Attention-Driven Multi-Perspective Discrepancy Alignment for RGB-Infrared Image Fusion and Segmentation](#07 AMDANet: Attention-Driven Multi-Perspective Discrepancy Alignment for RGB-Infrared Image Fusion and Segmentation)
- [08 UniFuse: A Unified All-in-One Framework for Multi-Modal Medical Image Fusion Under Diverse Degradations and Misalignments](#08 UniFuse: A Unified All-in-One Framework for Multi-Modal Medical Image Fusion Under Diverse Degradations and Misalignments)
- [09 MMAIF: Multi-task and Multi-degradation All-in-One for Image Fusion with Language Guidance](#09 MMAIF: Multi-task and Multi-degradation All-in-One for Image Fusion with Language Guidance)
- [10 The Source Image is the Best Attention for Infrared and Visible Image Fusion](#10 The Source Image is the Best Attention for Infrared and Visible Image Fusion)
- [11 Retinex-MEF: Retinex-based Glare Effects Aware Unsupervised Multi-Exposure Image Fusion](#11 Retinex-MEF: Retinex-based Glare Effects Aware Unsupervised Multi-Exposure Image Fusion)
录用情况-预览
ICCV 2025 录用论文中,以 "Image Fusion"为关键词共检索到 11 篇相关论文 。从单位来看,主要来自 中国高校与研究机构以及部分欧洲高校 ,例如 西安交通大学、西北工业大学、哈尔滨工业大学、武汉大学、电子科技大学、吉林大学、清华大学、昆明理工大学、大连民族大学、中北大学、合肥工业大学、澳门大学 等,同时也包含 ETH Zurich、达姆施塔特工业大学、巴塞罗那自治大学、伯明翰大学、约克大学 等国际机构,以及 鹏城实验室、字节跳动、Vector Institute、中国科学院计算技术研究所 等科研与产业机构。
从研究主题来看,这些工作主要集中在 红外与可见光图像融合、统一图像融合框架、多曝光融合、高光谱与全色融合、医学多模态融合以及可控/语言引导融合等方向 ,同时也呈现出明显的新趋势,例如 扩散模型(DiT)融合、语言或文本引导融合、退化感知融合、实时融合(LUT)、统一多任务融合以及融合+下游任务(如分割)等研究方向 ,体现出当前图像融合研究正在从传统单任务融合逐渐向 统一框架、可控交互、多任务和生成式模型融合发展。
01 Revisiting Image Fusion for Multi-Illuminant White-Balance Correction

题目:Revisiting Image Fusion for Multi-Illuminant White-Balance Correction
编号:Poster Session 2 & Exhibit Hall with Coffee Break | Exhibit Hall I #307
单位:计算机视觉中心、巴塞罗那自治大学、约克大学、向量研究所、达姆施塔特工业大学、马德里自治大学
代码:https://revisitingmiwb.github.io
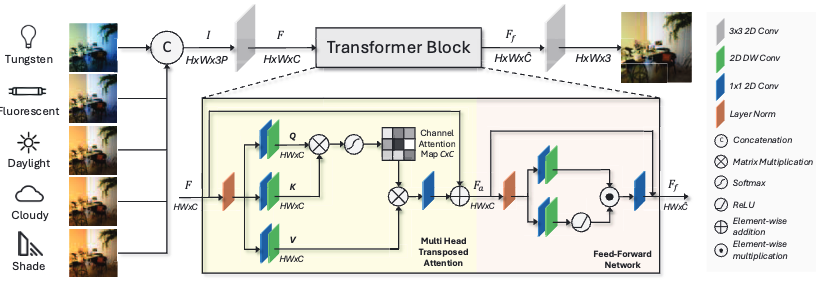
摘要:白平衡(White Balance,WB)在多光源条件下的校正一直是计算机视觉中的一个重要挑战。近年来,一些研究探索了基于融合(fusion-based)的策略,即通过神经网络对输入图像的多个 sRGB 版本进行线性加权融合,这些 sRGB 图像分别由不同的预设白平衡参数处理得到。然而,我们发现这类方法仍然存在一定局限。此外,现有的融合方法主要依赖 sRGB 白平衡数据集,但这些数据集缺乏真正适用于多光源场景的训练数据。为解决上述问题,本文提出了两项关键贡献:首先,设计了一种高效的基于 Transformer 的模型,用于有效建模不同 sRGB 白平衡预设之间的空间依赖关系,从而显著提升传统线性融合方法的性能;其次,构建了一个大规模多光源数据集,其中包含超过 16,000 张 sRGB 图像,每张图像均通过五种不同的白平衡设置进行渲染,并提供对应的白平衡校正图像。实验结果表明,在该多光源图像融合数据集上,所提出的方法相较于现有技术最高可实现 100% 的性能提升。
02 Balancing Task-invariant Interaction and Task-specific Adaptation for Unified Image Fusion

题目:Balancing Task-invariant Interaction and Task-specific Adaptation for Unified Image Fusion
编号:Poster Session 3 & Exhibit Hall | Exhibit Hall I #118
单位:哈尔滨工业大学、武汉大学
代码:https://github.com/huxingyuabc/TITA
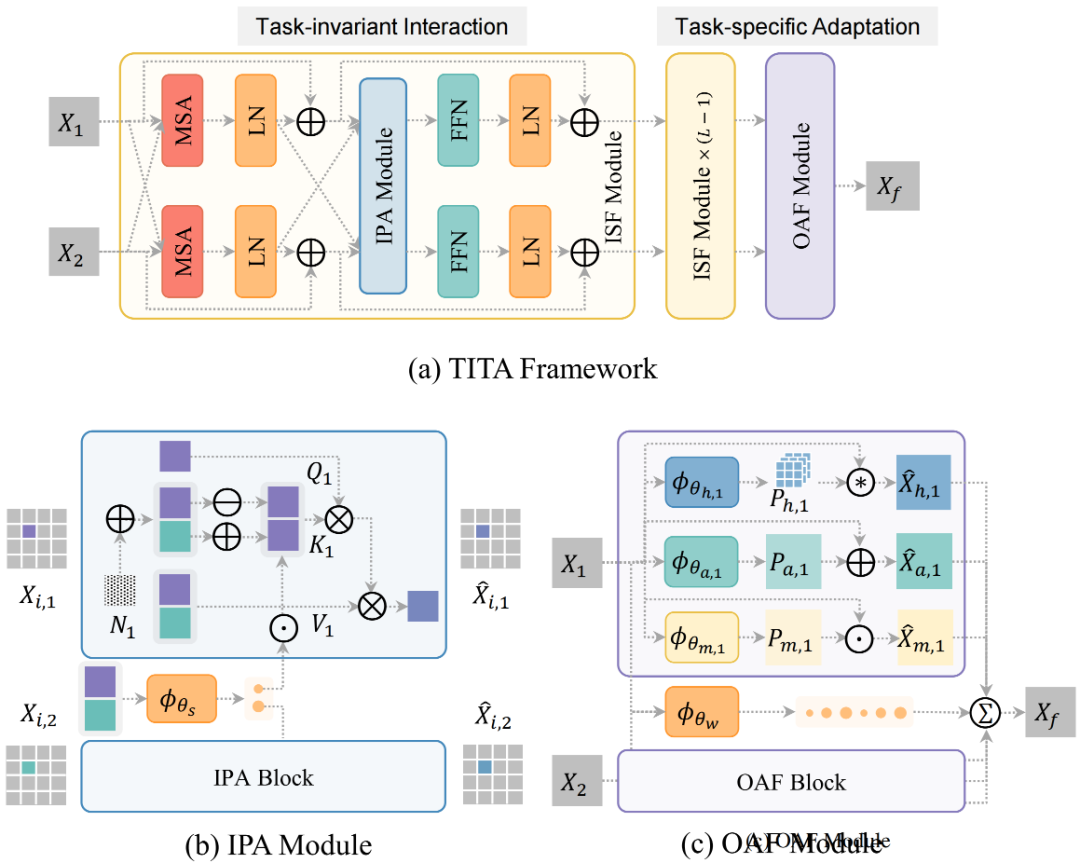
摘要:统一图像融合(Unified Image Fusion)旨在将多源图像中的互补信息进行整合,通过一个统一的框架提升图像质量,并能够适用于多种不同的融合任务。尽管将所有融合任务视为一个统一问题有助于实现任务无关知识的共享,但这种方式往往忽略了不同任务的特定特性,从而限制了整体性能。现有的一些通用图像融合方法通过显式的任务识别机制,使模型能够适应不同的融合任务,但这种在推理阶段对任务信息的依赖会限制模型对未见融合任务的泛化能力。为了解决这些问题,本文提出了一种新的统一图像融合框架"TITA",能够在任务不变交互(Task-invariant Interaction)与任务特定自适应(Task-specific Adaptation)之间实现动态平衡。在任务不变交互方面,提出了交互增强像素注意力模块(Interaction-enhanced Pixel Attention, IPA),以强化像素级交互,从而更有效地提取多源图像中的互补信息;在任务特定自适应方面,设计了基于操作的自适应融合模块(Operation-based Adaptive Fusion, OAF),根据任务属性动态调整不同操作的权重。此外,本文还引入快速自适应多任务优化策略(Fast Adaptive Multitask Optimization, FAMO),以缓解多任务联合训练过程中不同任务之间的梯度冲突问题。大量实验结果表明,TITA 在三种图像融合场景中不仅能够取得与专用方法相当的性能,同时还在未见过的融合任务上表现出良好的泛化能力。
03 Hipandas: Hyperspectral Image Joint Denoising and Super-Resolution by Image Fusion with the Panchromatic Image

题目:Hipandas: Hyperspectral Image Joint Denoising and Super-Resolution by Image Fusion with the Panchromatic Image
编号:Poster Session 3 & Exhibit Hall | Exhibit Hall I #188
单位:西北工业大学、苏黎世联邦理工学院、西安交通大学、澳门科技大学、西安交通大学
代码:https://github.com/shuangxu96/Hipandas
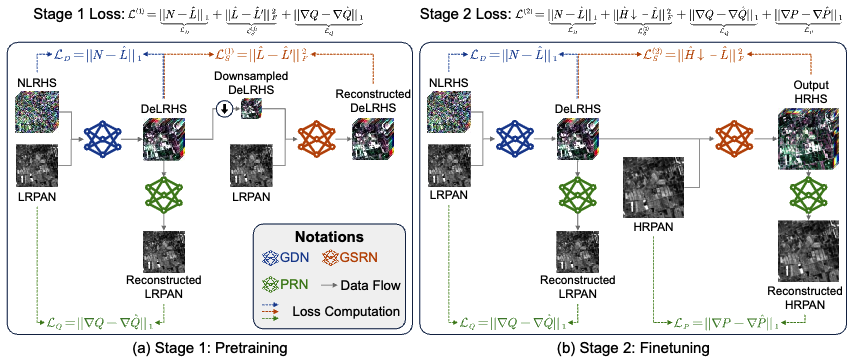
摘要:由于成像设备的限制,高光谱图像(Hyperspectral Images,HSIs)通常存在噪声较大且空间分辨率较低的问题。近年来发射的新型卫星能够同时获取高光谱图像(HSI)和全色图像(Panchromatic,PAN),从而可以通过融合 PAN 图像实现高光谱图像的去噪与超分辨率重建,得到更加干净且高分辨率的图像。然而,以往研究通常将这两个任务视为相互独立的过程进行处理,从而导致误差逐步累积。为此,本文提出了一种新的学习范式------高光谱图像联合全色去噪与全色锐化方法(Hyperspectral Image Joint Pandenoising and Pansharpening,Hipandas),用于从带噪低分辨率高光谱图像(NLRHS)和高分辨率 PAN 图像中重建高质量的高光谱图像。所提出的无监督 Hipandas 框架由引导去噪网络、引导超分辨率网络以及 PAN 重建网络组成,并结合高光谱图像低秩先验以及新提出的细节导向低秩先验进行建模。由于多个网络之间相互耦合,使得训练过程较为复杂,因此本文采用两阶段训练策略以确保模型能够有效收敛。实验结果表明,在模拟数据集和真实数据集上的实验中,该方法均优于现有最先进算法,能够生成更加准确且视觉效果更好的高分辨率高光谱图像。
04 Highlight What You Want: Weakly-Supervised Instance-Level Controllable Infrared-Visible Image Fusion

题目:Highlight What You Want: Weakly-Supervised Instance-Level Controllable Infrared-Visible Image Fusion
编号:Poster Session 3 & Exhibit Hall | Exhibit Hall I #248
单位:大连民族大学、澳门大学、清华大学
代码:https://github.com/GMY628/RIS-Fuse
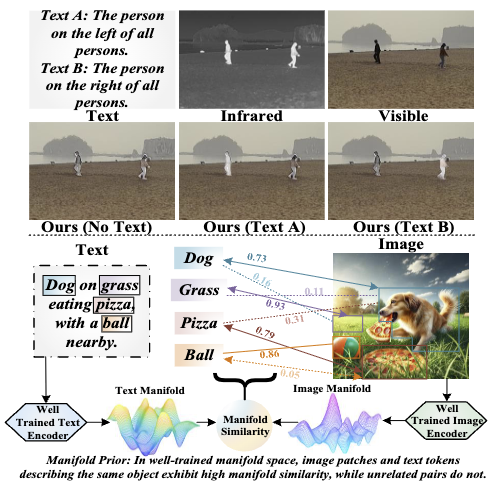
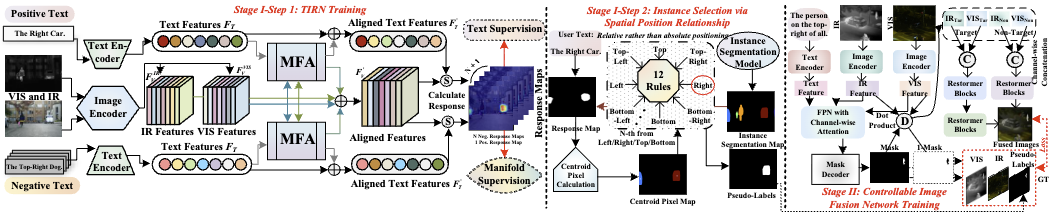
摘要:红外与可见光图像融合(VIS-IR)旨在整合两种源图像中的互补信息,以生成细节更加丰富的融合图像。然而,大多数现有融合模型缺乏可控性,难以根据用户需求定制融合结果。为了解决这一问题,本文提出了一种新的弱监督、实例级可控融合模型 ,能够根据输入文本自适应地突出用户指定的目标实例。该模型由两个阶段组成:伪标签生成阶段 和融合网络训练阶段 。在第一阶段,在观测到的多模态流形先验的指导下,利用文本信息和流形相似性作为联合监督信号,以弱监督方式训练文本到图像响应网络(Text-to-Image Response Network,TIRN),使其能够从实例分割结果中识别出被文本引用的语义级目标。为了实现 TIRN 中文本与图像特征的对齐,本文提出了多模态特征对齐模块(Multimodal Feature Alignment,MFA),通过流形相似性引导注意力权重分配,从而实现图像 patch 与文本嵌入之间的精确对应。此外,利用空间位置关系从多个语义目标中准确选择被引用的实例。在第二阶段,融合网络以源图像和文本作为输入,并利用生成的伪标签作为监督,对目标区域和非目标区域分别采用不同的融合策略。实验结果表明,该方法在融合性能上达到当前最先进水平,同时能够准确突出用户指定的目标实例。
05 LUT-Fuse: Towards Extremely Fast Infrared and Visible Image Fusion via Distillation to Learnable Look-Up Tables

题目:LUT-Fuse: Towards Extremely Fast Infrared and Visible Image Fusion via Distillation to Learnable Look-Up Tables
编号:Poster Session 3 & Exhibit Hall | Exhibit Hall I #429
单位:武汉大学、东南大学
代码:https://github.com/zyb5/LUT-Fuse
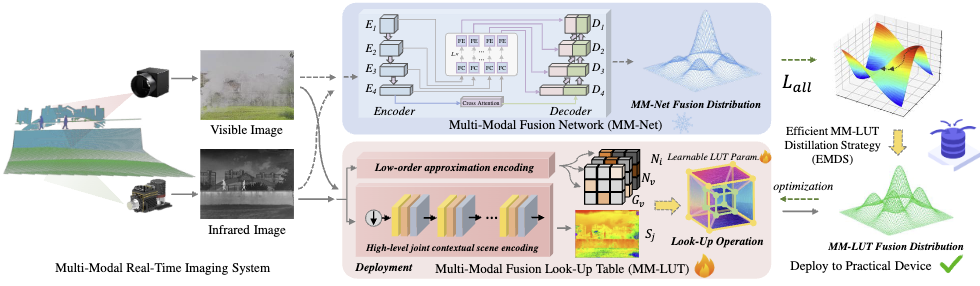
摘要:当前红外与可见光图像融合的先进研究主要集中在提升融合性能上,但往往忽视了其在实时融合设备中的应用需求。针对这一问题,本文提出了一种通过蒸馏学习可学习查找表(Lookup Table)的极高速融合方法,称为 LUT-Fuse ,专门用于图像融合任务。首先,设计了一种查找表结构,该结构结合了低阶近似编码 与高层联合上下文场景编码 ,从而更加适用于多模态融合任务。此外,考虑到多模态图像融合缺乏真实标注(ground truth),本文提出了一种高效的 LUT 蒸馏策略 ,以替代传统的基于量化的 LUT 方法。通过将多模态融合网络(MM-Net)的性能蒸馏到 MM-LUT 模型中,所提出的方法在效率与性能方面均取得了显著提升。与当前轻量级最先进(SOTA)的融合算法相比,该方法通常只需不到十分之一的运行时间,并能够在各种应用场景中保持较高的运行速度,即使在低功耗移动设备上也能高效运行。大量实验结果验证了该融合方法在性能、可靠性和稳定性方面的优势。
06 DreamFuse: Adaptive Image Fusion with Diffusion Transformer

题目:DreamFuse: Adaptive Image Fusion with Diffusion Transformer
编号:Poster Session 4 & Exhibit Hall with Coffee Break | Exhibit Hall I #231
单位:中山大学、鹏城实验室、字节跳动智能创作团队、广东省大数据分析与处理重点实验室
代码:https://ll3rd.github.io/DreamFuse/
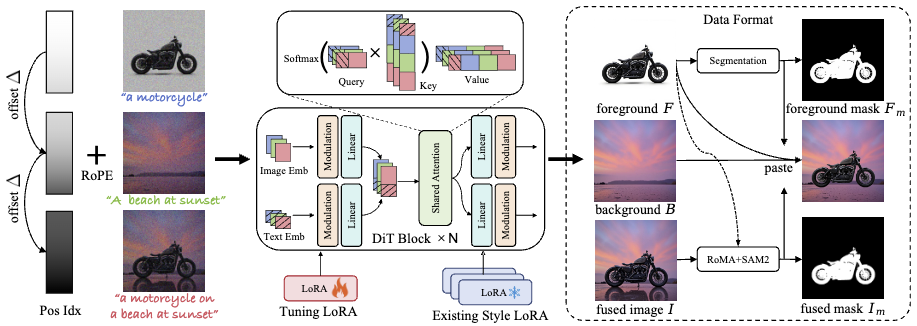
摘要:图像融合旨在将前景对象与背景场景无缝整合,从而生成真实且协调的融合图像。不同于现有方法通常直接将前景对象插入背景中,自适应且具有交互性的融合仍然是一项具有挑战但极具吸引力的任务。这类任务要求前景能够根据背景环境进行调整或与其发生交互,从而实现更加自然和一致的融合效果。为了解决这一问题,本文提出了一种人机协同(human-in-the-loop)的迭代式数据生成流程 ,利用少量初始数据并结合多样化的文本提示,生成涵盖多种场景与交互方式的融合数据集,例如物体放置、手持、穿戴以及风格迁移等。在此基础上,本文提出了一种名为 DreamFuse 的新方法,该方法基于 Diffusion Transformer(DiT)模型 ,能够同时利用前景和背景信息生成一致且协调的融合图像。DreamFuse 通过 位置仿射机制(Positional Affine) 将前景的尺寸和位置注入到背景特征中,并通过共享注意力机制实现有效的前景--背景交互。此外,本文还引入由人类反馈指导的 局部化直接偏好优化(Localized Direct Preference Optimization) 对 DreamFuse 进行进一步优化,从而提升背景一致性与前景融合的自然度。DreamFuse 在实现高质量融合的同时,还能够泛化到基于文本驱动的融合图像属性编辑任务。实验结果表明,该方法在多项评价指标上均优于当前最先进的方法。
07 AMDANet: Attention-Driven Multi-Perspective Discrepancy Alignment for RGB-Infrared Image Fusion and Segmentation

题目:AMDANet: Attention-Driven Multi-Perspective Discrepancy Alignment for RGB-Infrared Image Fusion and Segmentation
编号:Poster Session 3 & Exhibit Hall | Exhibit Hall I #59
单位:吉林大学、教育部知识驱动人机智能工程研究中心、中国科学院计算技术研究所、伯明翰大学
代码:https://github.com/Zhonghaifeng6/AMDANet
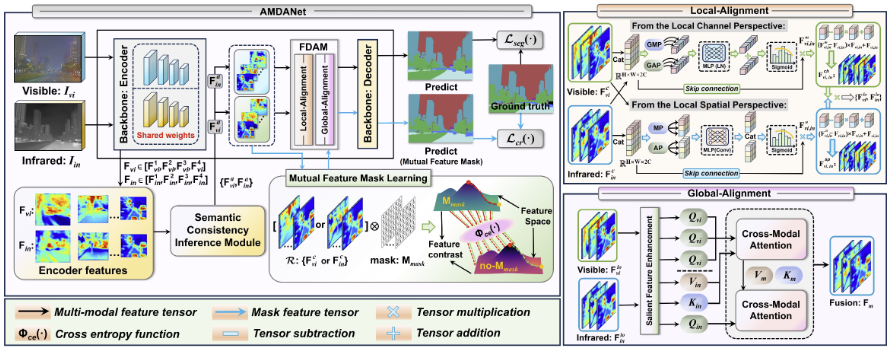
摘要:多模态语义分割的挑战在于,在不同模态视觉特征差异显著的情况下,构建具有语义一致性且易于分割的多模态融合特征。现有方法通常通过构建跨模态自注意力融合框架或引入额外的多模态融合损失函数来实现融合特征的学习。然而,这些方法往往忽视了融合过程中不同模态之间特征差异所带来的问题。为实现更加精确的分割,本文提出了一种注意力驱动的多模态差异对齐网络 (Attention-Driven Multimodal Discrepancy Alignment Network,AMDANet)。AMDANet 通过重新分配注意力权重来降低差异特征的显著性,并利用低权重特征作为线索缓解不同模态之间的差异,从而实现多模态特征的有效对齐。此外,为了简化特征对齐过程,本文引入了一种语义一致性推理机制 ,用于揭示网络对特定模态的内在偏置,从而在基础层面压缩跨模态特征差异。大量实验结果表明,在 FMB、MFNet 和 PST900 数据集上,AMDANet 的 mIoU 分别提升 3.6%、3.0% 和 1.6%,显著优于当前最先进的方法。
08 UniFuse: A Unified All-in-One Framework for Multi-Modal Medical Image Fusion Under Diverse Degradations and Misalignments

题目:UniFuse: A Unified All-in-One Framework for Multi-Modal Medical Image Fusion Under Diverse Degradations and Misalignments
编号:Poster Session 3 & Exhibit Hall | Exhibit Hall I #399
单位:昆明理工大学、哈尔滨工业大学(深圳)、合肥工业大学
代码:https://github.com/slrl123/UniFuse
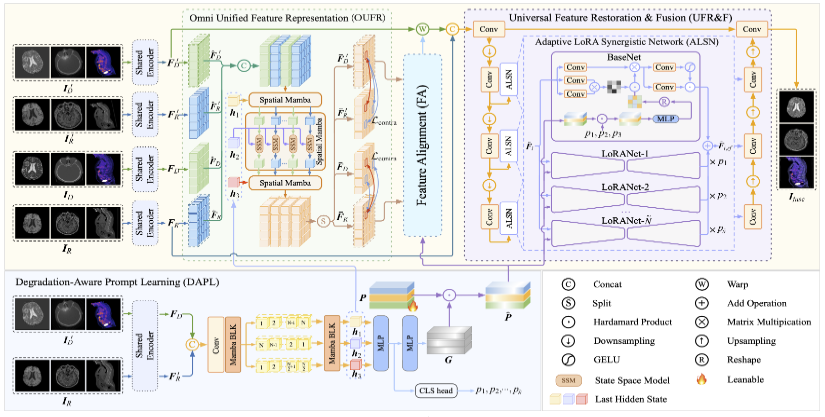
摘要:当前多模态医学图像融合通常假设源图像具有较高质量且在像素级别上完全对齐,其性能高度依赖这些条件,一旦面对存在配准误差或退化的医学图像时,融合效果往往会明显下降。为了解决这一问题,本文提出了一种通用融合框架 UniFuse 。该方法通过引入退化感知提示学习模块(degradation-aware prompt learning) ,能够从输入图像中融合多方向信息,并将跨模态对齐与图像恢复过程进行关联,在统一框架下实现两者的联合优化。此外,本文设计了 Omni Unified Feature Representation(全向统一特征表示) 方案,利用 Spatial Mamba 对多方向特征进行编码,从而在特征对齐过程中缓解不同模态之间的差异。为了在 All-in-One 的配置下实现同时恢复与融合,本文进一步提出了 Universal Feature Restoration & Fusion 模块 ,其中引入基于 LoRA 原理的 Adaptive LoRA Synergistic Network(ALSN)。通过 ALSN 的自适应特征表示能力以及退化类型引导,实现了在单阶段框架下的联合恢复与融合。与传统的分阶段方法相比,UniFuse 在一个统一框架中同时完成对齐、恢复与融合。多个数据集上的实验结果表明,该方法在性能上优于现有方法,并展现出显著的优势。
09 MMAIF: Multi-task and Multi-degradation All-in-One for Image Fusion with Language Guidance

题目:MMAIF: Multi-task and Multi-degradation All-in-One for Image Fusion with Language Guidance
编号:Poster Session 3 & Exhibit Hall | Exhibit Hall I #164
单位:电子科技大学、四川省多灾种预警重点实验室
代码:https://github.com/294coder/MMAIF
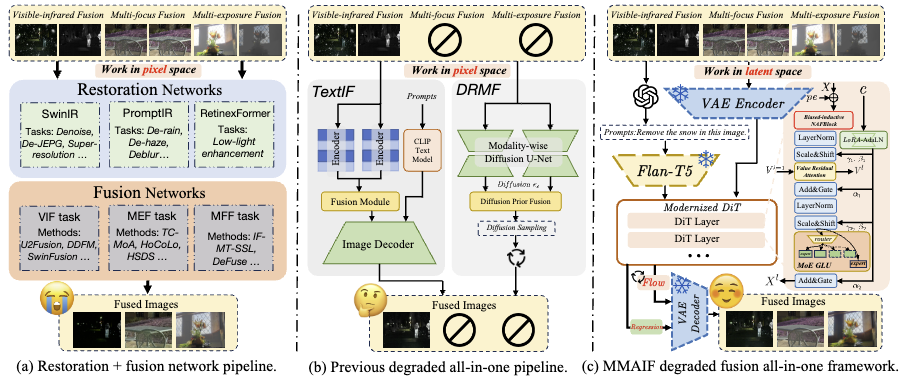
摘要:图像融合是一项基础的低层视觉任务,其目标是将多个图像序列整合为单一输出,同时尽可能保留输入图像中的信息。然而,现有方法仍然存在若干显著局限:① 通常需要针对特定任务或特定数据集训练专门模型;② 忽视真实场景中的图像退化(如噪声),在处理退化输入时性能容易下降;③ 多数方法在像素空间中进行处理,使得注意力机制计算开销较大;④ 缺乏用户交互能力。为解决这些问题,本文提出了一种统一的多任务、多退化、语言引导的图像融合框架 。该框架包含两个关键组件:首先,设计了一种实用的退化生成流程 ,用于模拟真实世界中的图像退化,并生成交互式提示以指导模型学习;其次,构建了一种在**潜空间(latent space)**中运行的 Diffusion Transformer(DiT) 全能模型,通过结合退化输入和生成的提示信息,生成高质量的融合图像。此外,本文还对原始 DiT 架构进行了系统性改进,使其更加适用于图像融合任务。在此基础上,提出了两种模型版本:基于回归(Regression-based) 和 基于流匹配(Flow Matching-based) 的变体。大量定性与定量实验结果表明,该方法能够有效克服上述问题,并在性能上优于现有的"恢复+融合"方法以及其他一体化融合框架。
10 The Source Image is the Best Attention for Infrared and Visible Image Fusion

题目:The Source Image is the Best Attention for Infrared and Visible Image Fusion
编号:Poster Session 3 & Exhibit Hall | Exhibit Hall I #331
单位:中北大学、山西省机器视觉与虚拟现实重点实验室、山西省视觉信息处理与智能机器人工程研究中心
代码:https://github.com/Afreshbird/SIBA
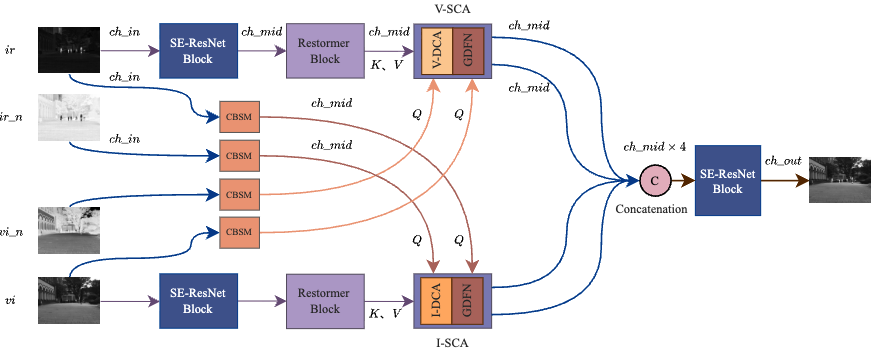
摘要:红外与可见光图像融合(Infrared and Visible Image Fusion,IVF)旨在融合不同模态图像的优势信息,以生成更优质的融合结果。本文首次揭示了红外图像所具有的内在"注意力特性",这种特性直接来源于其物理属性(如热分布),并且可以自然地与注意力机制建立联系,这一点在图像分类模型的梯度加权类激活映射(Grad-CAM)可视化分析中得到了验证。为了在图像融合中充分利用这一特性,本文提出了源红外交叉注意力(Source Infrared-Cross Attention,I-SCA),并进一步扩展到可见光模态,提出源可见光交叉注意力(Source Visible-Cross Attention,V-SCA)。I-SCA 与 V-SCA 的联合使用能够有效缓解红外与可见光融合中长期存在的问题,例如多模态特征交互不足以及融合不充分等。此外,本文还设计了一个辅助模块 CBSM,用于增强通道与特征图空间信息,并抑制源图像中的冗余和误导信息,从而进一步提升 I-SCA 与 V-SCA 的效果。具体而言,经过 CBSM 处理的原始图像被直接作为查询(query),而另一模态的中间特征则作为键(key)和值(value)输入到 I-SCA 和 V-SCA 中。不同于将图像划分为 patch 或限制在局部窗口内计算的注意力机制,本文提出的交叉注意力模块通过对整个图像空间进行全局建模,并以线性复杂度实现更加平滑且鲁棒的图像融合。在三个常用公开数据集上的实验结果表明,该方法优于当前最先进的方法。
11 Retinex-MEF: Retinex-based Glare Effects Aware Unsupervised Multi-Exposure Image Fusion

题目:Retinex-MEF: Retinex-based Glare Effects Aware Unsupervised Multi-Exposure Image Fusion
编号:Poster Session 2 & Exhibit Hall with Coffee Break | Exhibit Hall I #209(javascript:😉
单位:西安交通大学、苏黎世联邦理工学院、西北工业大学
代码:https://github.com/HaowenBai/Retinex-MEF
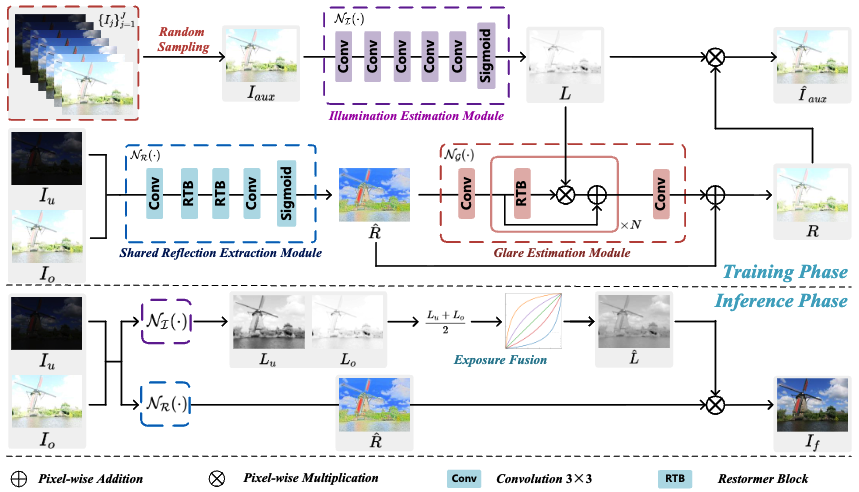
摘要:多曝光图像融合(Multi-Exposure Image Fusion,MEF)旨在将同一场景的多张不同曝光图像合成为一张曝光均衡的图像。Retinex 理论通过将图像分解为照明(illumination)与场景反射(reflectance)两个部分,为在不同曝光条件下保持场景一致性并实现有效信息融合提供了自然的理论框架。然而,传统方法通常采用像素级的照明与反射相乘方式进行重建,这种方式难以有效建模由过曝光引起的眩光(glare)效应。为了解决这一问题,本文提出了一种无监督且可控的多曝光融合方法 Retinex-MEF。具体而言,该方法将多曝光图像分解为多个独立的照明分量以及一个共享的反射分量,并对过曝光产生的眩光效应进行有效建模。共享反射分量通过双向损失(bidirectional loss)进行学习,从而能够有效缓解眩光问题。此外,本文还提出了一种可控的曝光融合准则,使模型在保持图像对比度的同时实现全局曝光调节,从而突破传统固定曝光水平的限制。在多个数据集上的大量实验,包括欠曝光与过曝光融合、曝光可控融合以及极端曝光一致场景融合,均验证了该方法在图像分解与灵活融合方面的有效性。