一. 引言
代码源:https://github.com/li554/COFNet
COFNet面向 RGB--Thermal 多光谱目标检测 ,认为"跨模态融合"里最关键的不是把特征拼起来,而是让融合过程显式聚焦在目标区域(object region) ,避免背景主导的无效交互;因此它用 box-level mask(由GT框构造) 来"指哪打哪"地引导跨模态注意力融合,并进一步用对比学习把"模态特征 ↔ mask特征"在表示空间里对齐,增强目标响应与跨模态一致性。
本笔记聚焦其如何引导模态进行对齐,减小背景噪声干扰。
二. 方法总览
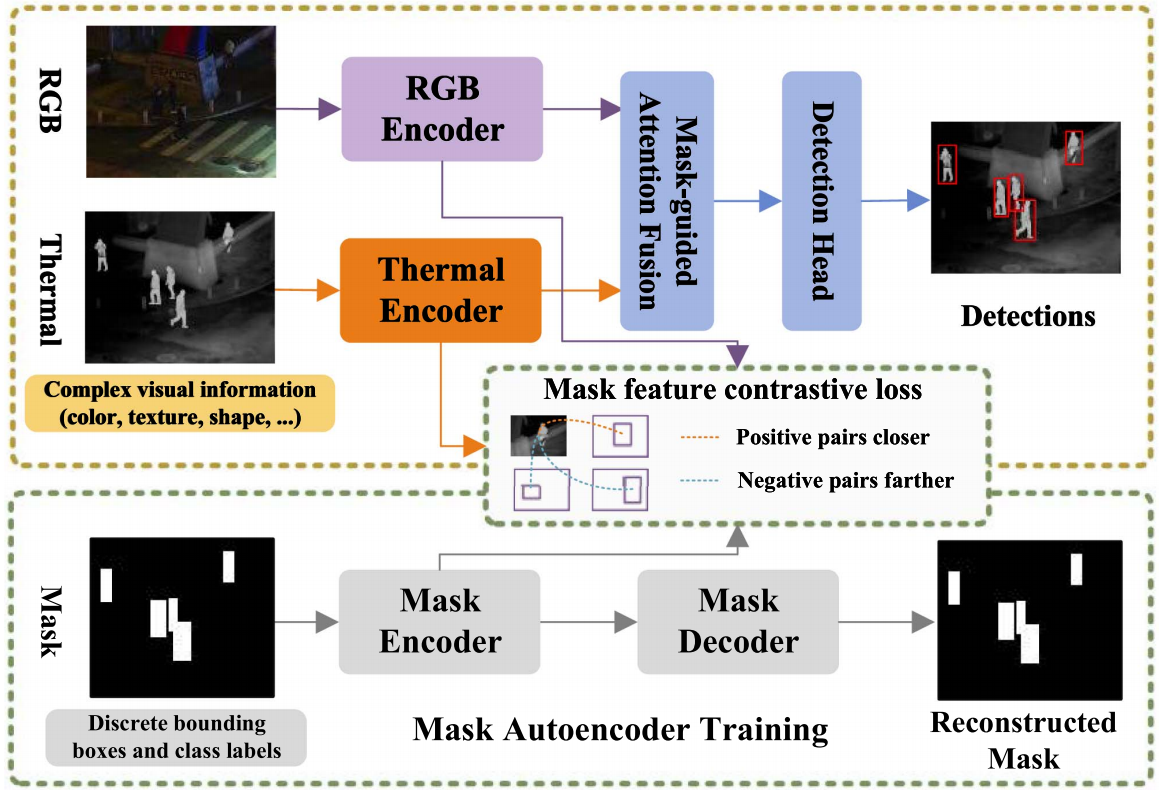
COFNet 设计了一个掩码block ,在RGB(Visible) 和Thermal(Infrared) 编码特征后引入该模块,以显式利用目标区域先验约束跨模态特征交互,使融合过程更加关注目标区域并抑制背景干扰,从而缓解跨模态不一致带来的伪响应问题。
三. 结构细节
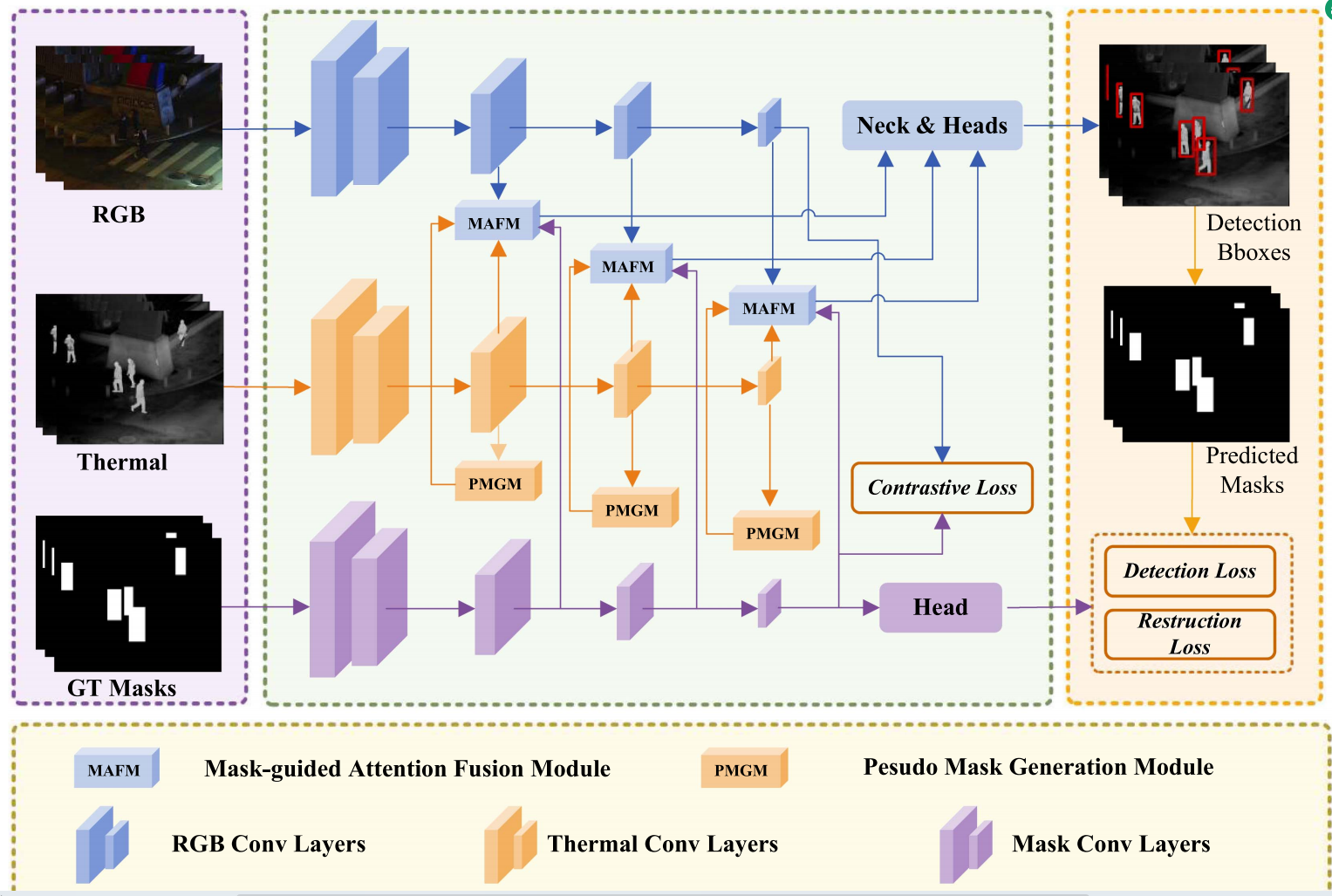
3.1. 三路输入
COFNet 采用 三路输入结构 ,分别对应 可见光图像(RGB) 、红外图像(Thermal) 以及 目标区域掩码(Mask)。其中,RGB 与 Thermal 图像分别通过结构相同但参数独立的编码网络提取多尺度特征,以充分保留各自模态的成像特性;掩码分支则用于提供显式的目标区域先验,引导后续跨模态特征交互聚焦于关键区域而非背景区域。
对于其特有的Mask分支------这是 COFNet 的"重点分支"
输入:
训练时:GT box 生成的二值 mask
推理时:PMGM 预测的 pseudo mask
经 Mask Conv Layers 编码
目的不是做分割,而是:
提供"哪里是目标"的显式空间先验
3.2. 掩码生成
在训练阶段,COFNet 利用标注框生成 box-level ground-truth mask 作为监督信号;在推理阶段,为避免训练--推理不一致问题,引入 Pseudo Mask Generation Module(PMGM) 从 RGB 与 Thermal 特征中自适应生成伪掩码。该模块通过对两模态特征进行可学习加权融合,并结合轻量卷积与空间注意机制,预测与目标区域相关的显著性掩码,从而在无标注条件下为后续融合提供可靠的目标先验。
PMGM 的内容:
输入:来自 RGB + Thermal 的中间特征
输出 :该尺度下的 Predicted Mask
用途:
推理阶段 → 给 MAFM 用
训练阶段 → 和 GT Mask 做 Reconstruction Loss
关键设计点:
PMGM 的 loss 不反向影响 RGB/Thermal 主干
它是一个"只负责学 mask、不干扰主干特征"的辅助模块
从工程视角看,COFNet 的整体设计显式面向测试阶段:由于推理时无法获得 GT 掩码,作者引入 PMGM 模块 ,使模型能够仅依赖 RGB 与 Thermal 特征自适应生成目标区域掩码。该掩码并不用于直接预测检测框坐标,而是作为跨模态注意力的空间先验 ,约束注意力计算主要发生在目标区域,从而强化目标特征、抑制背景干扰。与 YOLO 等检测头不同,PMGM 预测的是密集的区域显著性分布而非稀疏的 bbox 回归结果,其作用是服务于特征融合而非直接完成检测任务。
3.3. 注意力引导
基于生成的掩码特征,COFNet 设计了 Mask-Guided Attention Fusion Module(MAFM)。该模块在跨模态注意力计算过程中对 Query 进行掩码加权,使跨模态相关性建模主要集中于目标区域。通过双向 cross-attention 机制,RGB 特征与 Thermal 特征在掩码约束下相互补充,从而有效抑制背景区域带来的跨模态干扰,并缓解由模态差异引起的伪响应问题。
MAFM 的输入(从图中箭头可见)
RGB 特征(同尺度)
Thermal 特征(同尺度)
Mask(GT 或 PMGM)
MAFM 干的不是"融合特征",而是:
掩码引导的跨模态注意力交互
具体机制(对应论文):
Mask 不直接乘在特征上
而是:
作用在 Attention 的 Query 上
控制"哪些空间位置参与跨模态相关性计算"
也就是说:
不是"把背景 mask 掉",
而是"不让背景参与跨模态对齐"。这是一个非常重要的区别。
3.4. 多尺度融合
为充分利用不同尺度下的目标信息,COFNet 在多个特征层级上重复应用掩码引导的跨模态融合策略。融合后的多尺度特征通过特征金字塔结构进行整合,并送入检测头进行最终预测。该多尺度融合设计使模型能够同时兼顾小目标与大目标检测性能,在复杂场景下保持稳定且鲁棒的多光谱目标检测效果。
四. 重点解析
4.1. MAFM
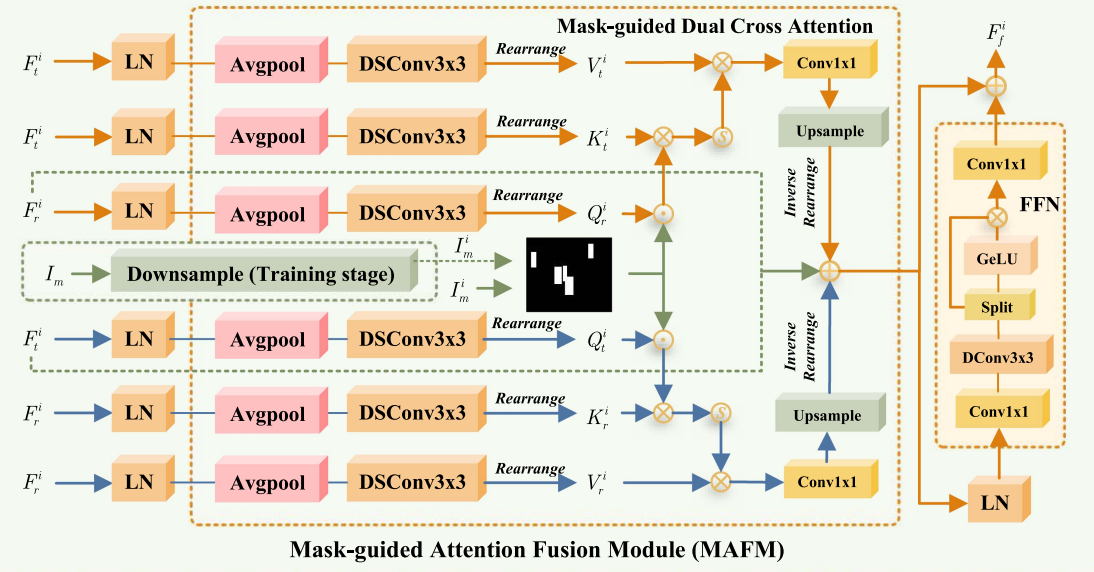
如图可知,MAFM 由三条分支构成 ,其中两条分支在结构上呈完全对称设计。为消除跨模态融合过程中潜在的模态偏置,MAFM 在跨模态注意力计算时 显式交换 Thermal 与 RGB 特征的角色 ,分别用于生成 Query 和 Key,同时在 Value 的构建中 均衡地使用 RGB 或 Thermal 特征 ,避免某一模态在信息注入过程中长期处于主导地位。该设计思想与我们此前分析的 Fusion-Mamba 中"对称双分支、主辅可交换的跨模态状态建模"高度一致,其核心目标均在于通过结构对称性抑制模态先验偏置,提升跨模态信息交互的鲁棒性笔记:Cross Modal Fusion-Mamba-CSDN博客。
此外,在进入注意力计算之前,光学特征需经过 Layer Normalization(LN) 以统一不同模态特征的数值尺度,并通过 平均池化(Average Pooling) 降低空间分辨率,从而减轻注意力计算的复杂度。随后,特征通过卷积映射与 rearrange 操作 被重排为序列形式,以满足注意力机制对矩阵输入的要求。该预处理过程本质上是一次 从二维特征图到序列表示的结构化转换,其目的并非改变特征语义,而是为后续跨模态相关性建模提供稳定、可控的计算形式。
对于 PMGM 生成或预测的掩码信息,其在进入 MAFM 前通常只需做尺度对齐(如下采样/插值),随后会被复制为两份 分别作用于两条对称的跨模态注意力分支:一份用于 RGB→Thermal 的 cross-attention(对 RGB 的 Query 加权),另一份用于 Thermal→RGB 的 cross-attention(对 Thermal 的 Query 加权)。这样做的目的在于保证两条分支在同一目标先验约束下进行交互,从而统一"关注区域",抑制背景区域参与跨模态相关性计算,并避免因分支约束不一致而引入的模态偏置。
4.2. PMGM
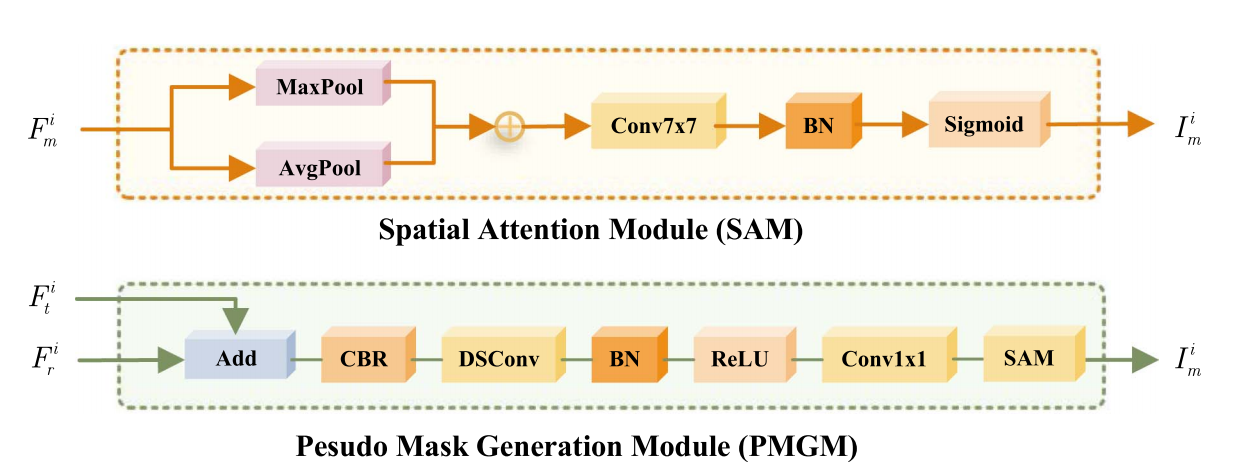
如图可知,PMGM 由一条主干掩码生成分支与一个空间注意力子模块SAM 级联构成,其核心目标是在推理阶段不依赖 GT mask 的前提下,仅利用 RGB 与 Thermal 的编码特征 自适应生成目标区域的伪掩码,从而消除训练阶段"有掩码引导"与测试阶段"无掩码先验"之间的结构不一致问题。具体而言,PMGM 的输入为同尺度下的两模态特征RGB和Thermal, 首先通过 Add 操作进行逐元素叠加得到融合响应,以在不引入额外注意力权重的情况下汇聚两模态的目标显著性线索。
随后,融合特征依次经过 CBR(Conv--BN--ReLU) 与 DSConv(Depthwise Separable Conv) 进行通道调整与局部空间结构建模,其中 DSConv 以较低的参数量引入必要的空间归纳偏置,使得目标区域响应在空间上更连续、边界更稳定,从而为后续掩码预测提供更加结构化的特征基础。
在完成局部结构建模后,PMGM 通过 Conv1×1 将特征进一步投影到单通道掩码表示空间,形成初始的掩码特征图。然而,该初始响应仍可能受到局部噪声或背景高响应的干扰,因此作者进一步引入 SAM 对其进行空间注意力增强:具体地,SAM 对同时执行 AvgPool 与 MaxPool 两条并行路径,以分别刻画"整体响应趋势"与"局部峰值显著性",并将两者相加后送入 Conv7×7 进行更大感受野的空间聚合;该 7×7 卷积能够在区域尺度上强化目标内部的一致性并抑制零散噪声响应,随后通过 BN 与 Sigmoid 将输出归一化到 0,1 区间,最终得到可直接用于注意力引导的伪掩码。
其中 SAM 的引入使得掩码预测不再仅依赖点状响应,而是更倾向于输出具有区域一致性的目标先验,从而在后续 MAFM 的跨模态注意力交互中提供更加稳定的空间约束。进一步地,由于 PMGM 在各尺度均可生成对应的伪掩码,该伪掩码能够与多尺度特征保持一致的空间对齐关系,为多层级的掩码引导融合提供统一的先验支撑。