LLM Agent架构演进之 Basic Reflection 解析
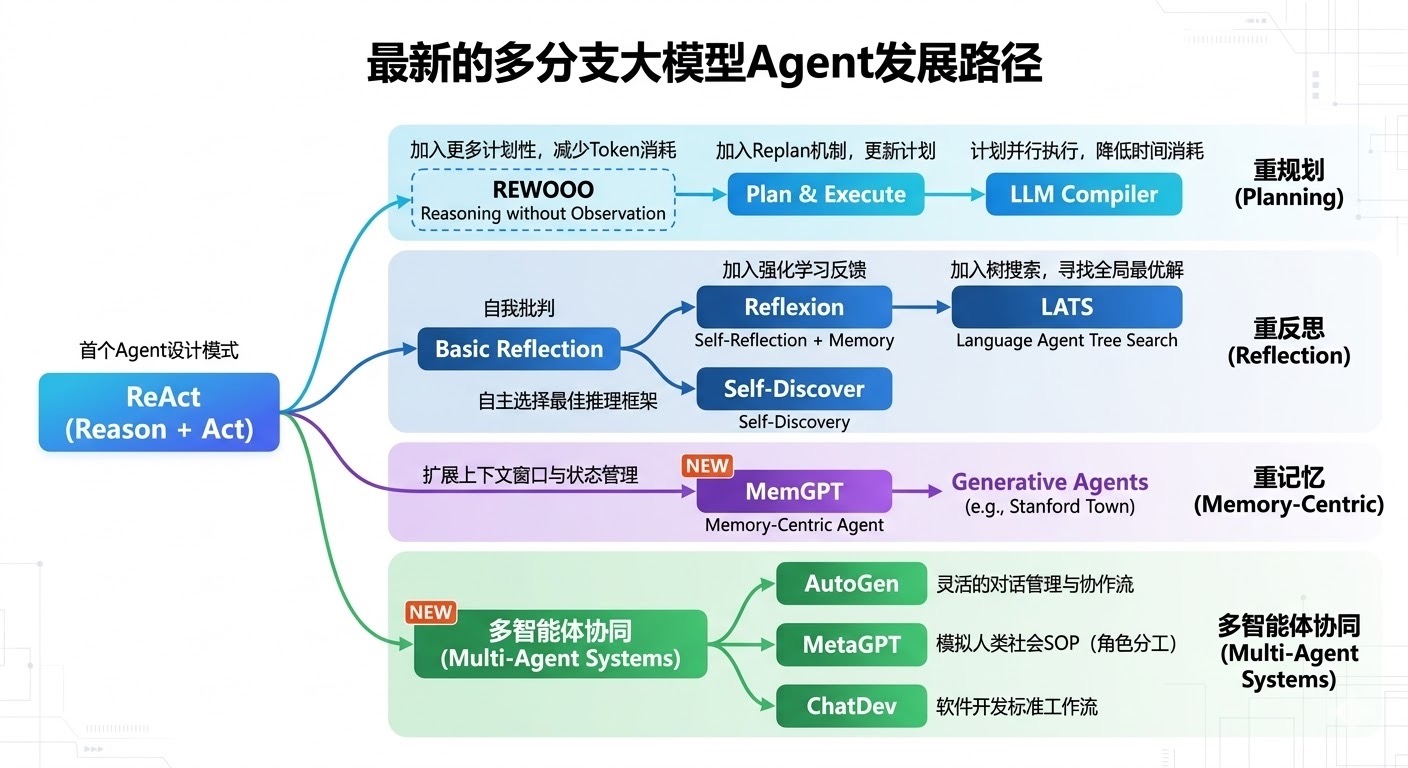
从"多分支大模型Agent发展路径"图中,我们可以清晰地看到:所有的现代Agent范式都起源于ReAct (Reason + Act)。
然而,ReAct存在一个致命缺陷:开环控制(Open-loop Control) 。一旦模型在某一步推理错误,它很容易在错误的道路上越走越远,无法自我纠正。为了解决这个问题,Agent发展出了四大分支,其中一条极其重要的主线就是 重反思(Reflection) 范式。
一、 来龙去脉:为什么我们需要 Basic Reflection?
1. ReAct 的痛点
在传统的 ReAct 模式下,模型的生成概率可以表示为:
P(at∣x,h<t)=LLM(x,h<t)P(a_t | x, h_{<t}) = \text{LLM}(x, h_{<t})P(at∣x,h<t)=LLM(x,h<t)
其中 xxx 是输入,h<th_{<t}h<t 是之前的历史轨迹(包含思考、行动和观察)。如果 at−1a_{t-1}at−1 是一个"幻觉"或低效动作,ReAct 并没有原生的机制去主动审视这个动作本身,它只会顺着这个错误的上下文继续生成。
2. Basic Reflection 的诞生
为了打破这种"单向生成"的局限,研究人员引入了 "双系统(Dual-System)" 的思想(借鉴自丹尼尔·卡尼曼的《思考,快与慢》)。
- System 1 (Generator): 负责快速生成初步答案或行动计划(类似最初的ReAct)。
- System 2 (Reflector / Critic): 负责对生成的答案进行评估、寻找漏洞,并给出具体的修改建议。
通过引入 Reflection,我们将原本的开环系统变成了闭环系统(Closed-loop System) 。其数学本质是一个迭代优化过程(Iterative Refinement) 。
假设第 kkk 次生成的草稿为 yky_kyk,反思模块生成的批判反馈为 rkr_krk,则第 k+1k+1k+1 次生成的过程可以表示为:
yk+1∼Pθ(y∣x,yk,rk)y_{k+1} \sim P_\theta(y | x, y_k, r_k)yk+1∼Pθ(y∣x,yk,rk)
这种机制强迫模型在最终输出前进行"深思熟虑",极大地提高了回答的准确率和鲁棒性。
二、 核心组件与 LangGraph 底层代码解析
Basic Reflection 的核心组件包含三个:状态(State) 、生成器(Generator Node) 、反思器(Reflector Node)。
1. 定义图的状态 (Graph State)
状态是 LangGraph 运转的血液。对于 Reflection,我们需要记录初始请求、当前草稿、反馈意见以及迭代次数。
python
from typing import TypedDict, Annotated
import operator
# 1. 定义Agent的全局状态
class ReflectionState(TypedDict):
task: str # 用户原始任务
draft: str # Generator生成的当前草稿/答案
critique: str # Reflector给出的批判与修改建议
iterations: int # 记录循环次数,防止死循环2. 生成器节点 (Generator Node)
生成器负责根据任务和(可选的)历史反馈来生成内容。
python
def generator_node(state: ReflectionState) -> ReflectionState:
task = state["task"]
critique = state.get("critique", "")
iterations = state.get("iterations", 0)
# 构建Prompt:如果有critique,则要求模型根据critique进行修改
if critique:
prompt = f"Task: {task}\nPrevious Draft: {state['draft']}\nCritique: {critique}\nPlease revise the draft to address the critique."
else:
prompt = f"Task: {task}\nPlease generate a comprehensive answer."
# 调用LLM生成 (伪代码)
new_draft = llm.predict(prompt)
# 更新状态
return {"draft": new_draft, "iterations": iterations + 1}3. 反思器节点 (Reflector Node)
反思器是整个范式的灵魂。它需要以极其严苛的视角审视草稿。
python
def reflector_node(state: ReflectionState) -> ReflectionState:
task = state["task"]
draft = state["draft"]
prompt = f"Task: {task}\nDraft: {draft}\n" \
f"You are a strict reviewer. Evaluate the draft. " \
f"If it is perfect, respond with exactly 'PASS'. " \
f"Otherwise, point out the flaws and provide actionable advice."
critique = llm.predict(prompt)
return {"critique": critique}4. 构建条件边与计算图 (Building the Graph)
这是面试官最看重的地方:如何控制流转?
python
from langgraph.graph import StateGraph, END
def should_continue(state: ReflectionState) -> str:
# 终止条件:1. 评估通过; 2. 达到最大迭代次数
if "PASS" in state["critique"] or state["iterations"] >= 3:
return END
return "generate"
# 初始化图
workflow = StateGraph(ReflectionState)
# 添加节点
workflow.add_node("generate", generator_node)
workflow.add_node("reflect", reflector_node)
# 定义边
workflow.set_entry_point("generate")
workflow.add_edge("generate", "reflect")
workflow.add_conditional_edges(
"reflect",
should_continue,
{
END: END,
"generate": "generate"
}
)
# 编译图
app = workflow.compile()三、 常见疑难杂症 (QA)
Q1:Reflection 过程中,经常出现模型陷入"死循环"或"自己同意自己(Sycophancy)",怎么解决?
- 底层剖析: 当 Generator 和 Reflector 使用同一个同等参数量的模型(如全都用 GPT-3.5),模型容易产生"确认偏误(Confirmation Bias)"。它无法发现自己认知盲区内的错误。
- 解法:
- 非对称模型架构(Asymmetric Modeling): 使用小模型(如 LLaMA-8B)作为 Generator 追求速度和低成本;使用大模型(如 GPT-4 / Claude 3 Opus)作为 Reflector 把控质量。
- 模型多角色扮演: 当只允许使用同一个模型时,可以为模型设定不同的角色来有效缓解模型的"自我认知缺陷"问题,比如要求reflection模型扮演批"判性评价官"角色。
- 引入外部工具(即下一篇文章介绍的 Reflection Agent): Reflector 不要仅仅基于内部权重(Parametric Knowledge)去判断,而是应该调用代码解释器执行一下,或者调用搜索引擎(如
Google Search)验证 Fact。通过客观的 Ground Truth 来打破死循环。
Q2:如何设计 Reflector 的 Prompt 才能让反馈更加有效(Actionable)?
- 底层剖析: 很多时候 Reflector 会给出空洞的反馈,比如"你的回答不够好,请重新生成"。这种反馈不仅无效,还会浪费 Token。
- 解法:
- 结构化输出(Structured Output): 强制 Reflector 输出 JSON,包含
[Flaw_Type, Location, Suggestion, Score],强制其具象化错误。 - 多维度评分(Multi-aspect Evaluation): 在 Prompt 中引入具体的 Rubric(评分量表)。例如,要求分别从
Relevance,Coherence,Factuality三个维度进行打分:Score=w1⋅Srel+w2⋅Scoh+w3⋅SfacScore = w_1 \cdot S_{rel} + w_2 \cdot S_{coh} + w_3 \cdot S_{fac}Score=w1⋅Srel+w2⋅Scoh+w3⋅Sfac。
- 结构化输出(Structured Output): 强制 Reflector 输出 JSON,包含
Q3:引入 Reflection 后,Agent的响应延迟(Latency)和成本(Token Cost)翻倍,如何权衡?
- 解法:
- 动态触发机制(Dynamic Triggering): 不是所有的 Query 都需要 Reflection。可以先用一个极低成本的分类器/规则引擎判断任务难度。简单对话直接 bypass 返回,只有涉及复杂推理(代码编写、数据分析)时,才激活 Reflection 图谱。
- 蒸馏优化(Distillation): 将经过多次 Reflection 得到的优质
(Input, Refined Output)收集起来,通过 SFT(监督微调)蒸馏给 Generator 模型。最终目标是提升 Generator 第一遍的准确率(Zero-shot accuracy),从而在部署时逐渐减少 Reflection 循环被触发的概率。