深度解析 LLM Agent 核心架构:Plan & Execute 范式的演进与底层原理
本文将结合最新的多分支大模型 Agent 发展路径,剖析 重规划(Planning) 分支中的核心中坚力量:Plan & Execute 范式。
一、 来龙去脉:为什么我们需要 Plan & Execute?
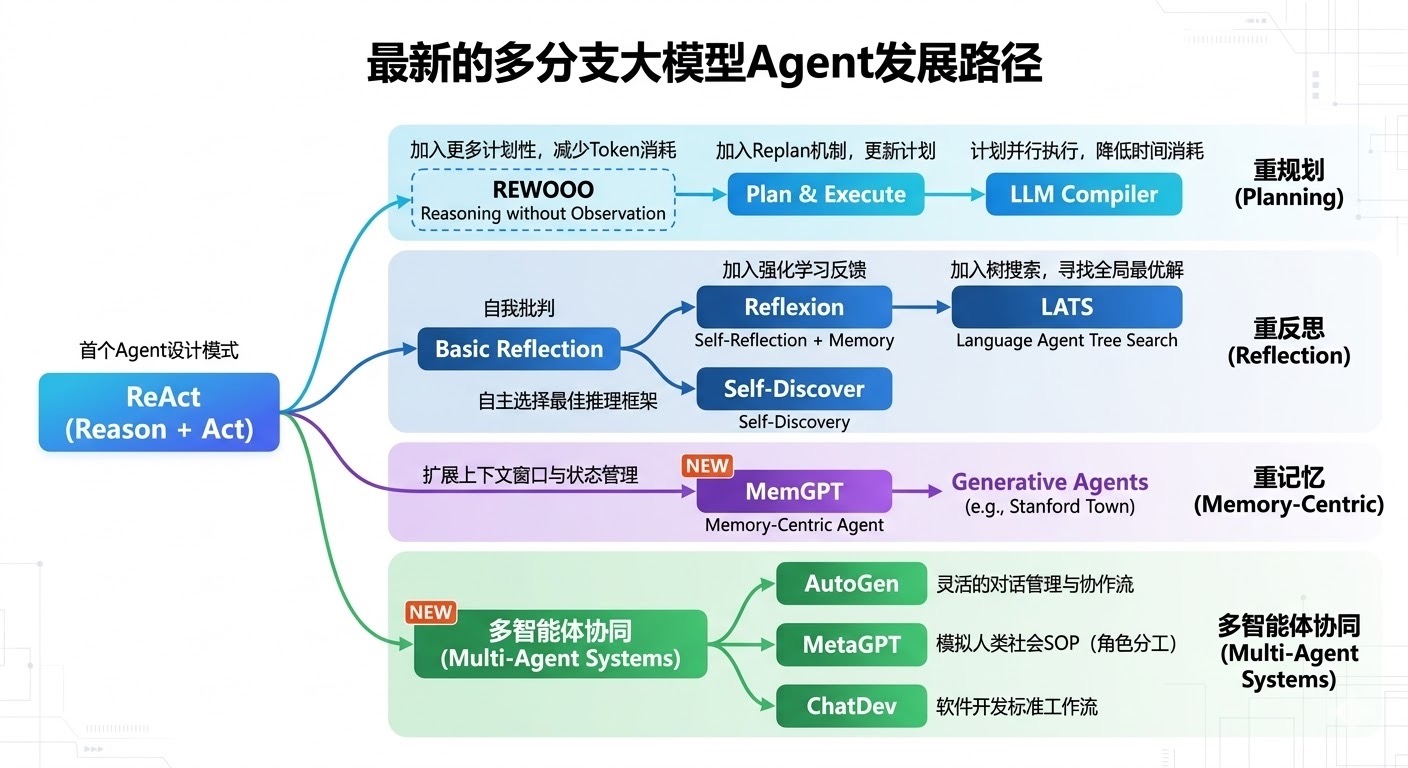
要理解一个技术的底层逻辑,首先要明白它解决了上一代技术的什么痛点。结合发展路径图,我们可以清晰地看到 Planning 分支的演进路线:ReAct → \rightarrow → REWOO → \rightarrow → Plan & Execute → \rightarrow → LLM Compiler。
1. 鼻祖的困境:ReAct (Reason + Act)
ReAct 是首个广泛应用的 Agent 设计模式。它的核心逻辑是交替进行"思考"和"行动":
状态更新公式: C o n t e x t t = C o n t e x t t − 1 + T h o u g h t t + A c t i o n t + O b s e r v a t i o n t 状态更新公式:Context_{t} = Context_{t-1} + Thought_t + Action_t + Observation_t 状态更新公式:Contextt=Contextt−1+Thoughtt+Actiont+Observationt
痛点:
- Token 消耗呈指数级爆炸:每执行一步,之前所有的思考、动作和冗长的观察结果都要重新输入给 LLM。随着步数增加,不仅极度消耗 Token,还容易触发上下文窗口限制(Context Window Overflow)。
- "走一步看一步"的短视问题:ReAct 缺乏全局规划能力,很容易陷入局部最优解,或者在死胡同里无限循环打转。
2. 矫枉过正的尝试:REWOO (Reasoning without Observation)
为了解决 ReAct 的 Token 消耗和短视问题,学术界提出了 REWOO。它主张把"计划"和"执行"完全剥离:先让 LLM 一次性生成所有步骤的计划,然后按照计划按部就班地执行,期间不再观察环境并进行思考。
底层缺陷:
极大地降低了 Token 消耗,但容错率几乎为零。一旦计划的第二步执行失败(例如 API 宕机或返回异常),后续的所有步骤都会因为依赖断裂而全部崩溃。
3. 中庸之道的诞生:Plan & Execute
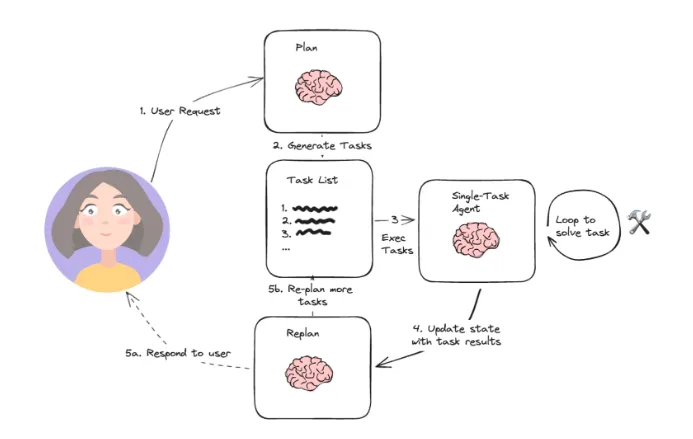
为了在 全局视野(REWOO 的优点) 和 动态纠错(ReAct 的优点) 之间寻找完美的平衡,Plan & Execute 架构应运而生。它不仅包含了全局的规划,还巧妙地加入了 Replan(重规划)机制来更新计划。
二、 Plan & Execute 的运转机制
一个标准的 Plan & Execute Agent 通常由三个核心模块构成:
1. Planner(规划器):大脑的全局视野
Planner 的目标是接收用户的宏大目标(Goal),并将其拆解为一系列有序的子任务(Sub-tasks)。
P l a n = F p l a n n e r ( G o a l ) = { t a s k 1 , t a s k 2 , ... , t a s k n } Plan = \mathcal{F}_{planner}(Goal) = \{task_1, task_2, \dots, task_n\} Plan=Fplanner(Goal)={task1,task2,...,taskn}
注意: planner阶段没有考虑不同step之间的参数依赖(即上一个步骤的执行结果作为下一个步骤的入参)。仅仅将不同step的执行上下文(context)往下传递,本质上executor的上下文还是类似于ReAct,只不过多了一个独立的replanner来规避 ReAct 范式下容易迷失在某个步骤的缺陷。
经典的plan阶段的prompt:
For the given objective, come up with a simple step by step plan.
This plan should involve individual tasks, that if executed correctly will yield the correct answer.
Do not add any superfluous steps.
The result of the final step should be the final answer.
Make sure that each step has all the information needed - do not skip steps.中文版:
对于给定的目标,请制定一个简单的循序渐进的计划。
该计划应包含多个独立任务,如果这些任务被正确执行,将得出正确的答案。
请勿添加任何多余的步骤。
最后一步的结果应为最终答案。
请确保每个步骤都包含所需的所有信息------不要跳过任何步骤。大模型输出示例:
[
"1. 使用数据库查询技能(Skill)获取 'dws_sales_summary' 表的表结构和字段描述。",
"2. 根据表结构编写 SQL 语句,计算 2025 年第四季度各业务线的总营收。",
"3. 执行该 SQL 语句并提取查询结果。",
"4. 将查询结果整理成最终的营收汇总分析报告返回。"
]2. Executor(执行器):专注局部的打工人
Executor 不需要知道全局的宏大目标,它就像一个流水线工人,只负责接收当前的任务 t a s k i task_i taski 并调用工具去完成它。不同于ReWOO范式,此处的Executor会拉起一个Agent(一般是ReAct Agent)挂载对应工具去执行,增强工具执行异常的处理。
R e s u l t i = F e x e c u t o r ( t a s k i , C o n t e x t ) Result_i = \mathcal{F}_{executor}(task_i, Context) Resulti=Fexecutor(taski,Context)
- 对比优势:因为 Executor 只需要专注于当前的小任务,所以我们可以为它配备较小的模型(如 7B 的微调模型),或者只给它传入与当前任务相关的极简 Context,从而大幅降低推理成本和延迟。
3. Replanner(重规划器):动态纠错的灵魂
这是 Plan & Execute 区别于 REWOO 的核心所在。当一个子任务执行完毕后,Replanner 会根据执行结果 R e s u l t i Result_i Resulti 和原计划,重新评估接下来的步骤。
P l a n n e w = F r e p l a n n e r ( P l a n o l d , R e s u l t i , G o a l ) Plan_{new} = \mathcal{F}{replanner}(Plan{old}, Result_i, Goal) Plannew=Freplanner(Planold,Resulti,Goal)
Replanner 有三种常见的决策:
- 继续:结果符合预期,将下一个任务出栈并交给 Executor。
- 修正(Replan) :结果偏离预期(例如工具调用失败),Replanner 会修改后续的 t a s k i + 1 task_{i+1} taski+1 到 t a s k n task_n taskn,甚至插入新的补救任务。
- 终止:目标已达成,提前结束。
典型的replanner prompt:
For the given objective, come up with a simple step by step plan.
This plan should involve individual tasks, that if executed correctly will yield the correct answer. Do not add any superfluous steps.
The result of the final step should be the final answer. Make sure that each step has all the information needed -- do not skip steps.
Your objective was this:
{input}
Your original plan was this:
{plan}
You have currently done the follow steps:
{past_steps}
Update your plan accordingly. If no more steps are needed and you can return to the user, then respond with that. Otherwise, fill out the plan. Only add steps to the plan that still NEED to be done. Do not return previously done steps as part of the plan.Replanner的主要任务是根据子任务的执行结果,更新计划。
Replanner和Planner的prompt模板非常相似,但是约束了Replanner的目标任务、原始Plan、已执行的步骤、以及更新计划。
比如更新计划,我们要求"根据执行的步骤更新计划。如果不需要更多步骤,直接可以返回给用户;否则就填写计划,并向计划中添加仍需完成的步骤,不要将之前完成的步骤作为计划的一部分返回"
4. LangGraph实现的一个workflow
python
g = StateGraph(PlanExecuteState)
g.add_node("plan", planner_node)
g.add_node("execute", executor_node)
g.add_node("judge", judge_node)
g.add_node("replan", replanner_node)
g.set_entry_point("plan")
# Plan & Execute with a judge (no replanning unless needed):
# plan -> execute -> judge -> (execute next | replan | end)
g.add_conditional_edges("plan", router_after_plan, {"execute": "execute", "end": END})
g.add_edge("execute", "judge")
g.add_conditional_edges("judge", router_after_judge, {"execute": "execute", "replan": "replan", "end": END})
g.add_edge("replan", "execute")
return g.compile()三、 常见问题QA
问题 1:在 Plan & Execute 架构中,如何避免 Replanner 陷入无限重规划的"死循环"?
解析 :这是 Agent 落地时最常见的翻车场景。LLM 发现任务失败 → \rightarrow → 重新生成相同的计划 → \rightarrow → 再次失败。
破局方案:
- 引入强规则控制(Rule-based constraints):在系统层设置最大重试次数(Max Retries)和最大执行步骤上限。
- 结合 Reflection(反思机制) :将发展图谱中的"重反思"分支技术引入进来。在 Replan 时,强制要求 LLM 输出
Thought: 为什么上一次执行失败了?这次的计划与上次有何不同?,利用文本生成的思维链打破重复采样的困境。 - 动态增加温度(Dynamic Temperature):如果在某一节点反复失败,可以在生成新计划时适当调高 Temperature,增加探索(Exploration)的多样性。
问题 2:Executor 在执行子任务时,如何有效地进行状态管理(State Management)以避免上下文超限?
解析 :如果把之前所有步骤的 Result 都无脑塞给 Executor,就又倒退回了 ReAct 的痛点。
破局方案:
- 结合 Memory-Centric(重记忆机制):如图谱中展示的,引入类似 MemGPT 的机制。构建一个外部的工作区(Workspace/Scratchpad)。
- KV 读写分离:Planner 定义数据依赖时,指定 Executor 只去读取(Read)特定的变量。Executor 执行完后,将长文本结果压缩(Summarize)或存储为 Key-Value 对存入内存字典中,只把简短的状态码或摘要传递给后续任务。
问题 3:如何评估一个 Planner 的好坏?
破局方案 :
不能仅仅看最终任务是否成功,还需要从以下几个维度构建评估集:
- 有效性(Validity):规划出的任务步骤是否符合逻辑因果关系(比如不能先分析数据,再下载数据)。
- 精简性(Efficiency):生成的计划是否包含了多余的、不产生实际价值的"废动作"。
- 工具对齐率(Tool Alignment):规划出的子任务,是否能够精准映射到当前 Executor 实际拥有的工具库中(不能规划出系统不支持的动作)。
四、 总结与展望:走向多任务与多智能体
Plan & Execute 通过引入计划、执行、重规划的解耦,极大地提升了 Agent 处理复杂长链路任务的能力。
然而,技术的发展永不止步。正如开篇图谱所示,Plan & Execute 进一步发展,就演变成了 LLM Compiler :既然计划已经拆解好了,而且我们知道了任务之间的 DAG 依赖关系,为什么不让那些没有前后依赖关系的子任务 并行执行(Parallel Execution) 呢?这就将进一步降低 Agent 的时间消耗(Latency)。
同时,如果把 Executor 模块替换成不同的专业角色,Plan & Execute 的架构就能平滑地过渡到 多智能体协同(Multi-Agent Systems,如 AutoGen / MetaGPT) 领域,由一个 Manager Agent 负责 Plan,多个 Worker Agents 负责 Execute。